【单层神经网络】softmax回归的从零开始实现(图像分类)
softmax回归
该回归分析为后续的多层感知机做铺垫
基本概念
softmax回归用于离散模型预测(分类问题,含标签)
softmax运算本质上是对网络的多个输出进行了归一化,使结果有一个统一的判断标准,不必纠结为什么要这么算
网络结构:
- 多输入多输出,单层神经网络,输出神经元与输入全连接
- 一组输入x为n维行向量,输入矩阵为a*n,a为样本个数
- 一组输出o为m维行向量,输出矩阵为a*m
- 偏置是m维行向量
- 权重矩阵W为n*m的矩阵(n行=输入个数,m列=输出个数)
- 网络输出:
Y = softmax(O)
O = X*W + b
交叉熵损失函数
核心:
- 交叉熵只关心对正确类别的预测概率
- 最小化交叉熵损失函数 等价于 最大化似然函数,二者出自不同学科,但在数学上描述了同一个对象
- 可以使用准确率评价模型表现
完整程序及注释
完整softmax图像分类实现
import d2lzh as d2l
from mxnet import autograd, nd
'''
基础参数声明
'''
batch_size = 256
# 创建两个迭代器,用于对mnist数据集进行小批量随机采样
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)num_inputs = 28*28 # 将二维图片变成一维向量后的长度
num_outputs = 10 # 输出数量
W = nd.random.normal(loc=0, scale=0.01, shape=(num_inputs, num_outputs))
b = nd.zeros(num_outputs)
W.attach_grad()
b.attach_grad()'''
训练必要方法声明
'''
# 指数化+归一化 = softmax运算
def softmax(X):X_exp = X.exp()partition = X_exp.sum(axis=1, keepdims=True)return X_exp / partition# 将二维图片变成一维向量(改变模型形式),并为每个特征分配权重和偏置
# nd.dot(X.reshape((-1, num_inputs)), W) + b 的输出是一个矩阵,行数等于小批量中的样本数,列数等于输出的类别数量
# 每一行中数值最大的那一项,代表模型认为该样本属于这一类的概率最大
def net(X):return softmax(nd.dot(X.reshape((-1, num_inputs)), W) + b)# y是正确的标签号,y_hat是样本对各个类型的预测概率
# 该函数返回各个概率中正确标签的概率值,并进行exp()运算
def cross_entropy(y_hat, y):return -nd.pick(y_hat, y).log() # .log()方法将pick()的返回的每个元素进行exp运算# 计算样本集的准确率
def accuracy(y_hat, y):return (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar()# 小批量对data_iter进行遍历,最后统计准确率
def evaluate_accracy(data_iter, net):acc_sum, n = 0.0, 0for X, y in data_iter: # X是特征,y是标签y = y.astype("float32")# 取出每一行中数字最大的那一项的索引号,并和标签y比较,再对该次小批量求和,累加acc_sum += (net(X).argmax(axis=1) == y).sum().asscalar()n += y.sizereturn acc_sum / n'''
训练函数
'''
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, trainer=None):for epoch in range(num_epochs):train_l_sum, train_acc_sum, n = 0.0, 0.0, 0for X, y in train_iter:with autograd.record():y_hat = net(X)l = loss(y_hat, y).sum() # 调用时, 传入交叉熵损失函数l.backward()if trainer == None:d2l.sgd(params, lr, batch_size)else:trainer.step(batch_size)y = y.astype("float32")train_l_sum += l.asscalar() # 总损失train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar() # 总准确率n += y.sizetest_acc = evaluate_accracy(test_iter, net)# 打印平均损失和平均准确率(训练集和测试集)print('epoch %d, loss %.4f, train_acc %.4f, test_acc %.4f'% (epoch+1, train_l_sum/n, train_acc_sum/n, test_acc)) '''
开始训练,一般在第9轮左右准确率逼近峰值,85%左右
想要更高的准确率,需要更好的模型和寻优算法
'''
if __name__ == "__main__":num_epochs, lr = 20, 0.1train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
查看数据集
from matplotlib import pyplot as plt
from mxnet.gluon import data as gdata# 展示FashionMNIST数据集
mnist_train = gdata.vision.FashionMNIST(train=True)
mnist_test = gdata.vision.FashionMNIST(train=False)
print(len(mnist_train))
print(len(mnist_test))feature, label = mnist_train[19]
print(label)
img = feature
# 将 MXNet NDArray 转换为 NumPy 数组,并调整维度顺序以匹配图像格式
img_np = img.asnumpy().squeeze() # 移除单维度条目plt.imshow(img_np, cmap='gray')
plt.axis('off')
plt.show()
呈现效果
我训练了8次就手动让它中止了

具体程序解释
-
net(X)
X.reshape((-1, num_inputs)):
这是将X重新塑形的操作。这里的reshape函数用于改变X的形状而不改变其数据。
参数(-1, num_inputs)告诉函数自动计算该维度的大小以使总元素数量保持不变,而另一维度则指定为num_inputs。
-1在这里作为一个占位符,指示系统根据原张量中的元素数量和另一个指定的维度大小自动推断出这一维度的具体值。简单来说,这段代码的作用是将输入数据X拉平成一维向量,以便与权重矩阵W进行点积运算。如果你的输入是一批二维图片,这一步会将每张图片转换为一维向量形式,使得它们能够通过全连接层。
-
nd.pick()
用于从一个多维数组中根据指定的索引挑选元素
举例:import mxnet as mx data = mx.nd.array([[1, 2], [3, 4]]) index = mx.nd.array([1, 0]) picked_elements = mx.nd.pick(data, index, axis=1)print(picked_elements.asnumpy())在这个例子中,data 是一个二维 NDArray,而 index 是一个一维数组,指示了在 axis=1(行)上希望选取的元素索引。
nd.pick 函数会根据给定的索引数组 index,从 data 的指定维度(通过 axis 参数指定)中挑选出相应的元素。具体来说:mx.nd.array创建了两个行向量,用[1, 0]和axis=1索引的是 第0行中的第1个 和 第1行中的第0个 元素
-
accuracy(y_hat, y)
- y_hat.argmax(axis=1)
使用 argmax 函数找到 y_hat 中每一行(即每个样本)的最大值对应的索引。 - (y_hat.argmax(axis=1) == y.astype(‘float32’)):
进行逐元素比较,判断预测的类别是否等于实际类别,返回bool类型 - .mean():
计算上述布尔数组的平均值。由于 True 在数值计算中被视为 1,False 视为 0,因此平均值实际上就是预测正确的样本比例,即准确率。 - .asscalar():
将结果从 NDArray 转换为 Python 标量(如 float)
- y_hat.argmax(axis=1)
相关文章:
【单层神经网络】softmax回归的从零开始实现(图像分类)
softmax回归 该回归分析为后续的多层感知机做铺垫 基本概念 softmax回归用于离散模型预测(分类问题,含标签) softmax运算本质上是对网络的多个输出进行了归一化,使结果有一个统一的判断标准,不必纠结为什么要这么算…...

使用开源项目:pdf2docx,让PDF转换为Word
目录 1.安装python 2.安装 pdf2docx 3.使用 pdf2docx 转换 PDF 到 Word pdf2docx:GitCode - 全球开发者的开源社区,开源代码托管平台 环境:windows电脑 1.安装python Download Python | Python.org 最好下载3.8以上的版本 安装时记得选择上&#…...

保姆级教程Docker部署KRaft模式的Kafka官方镜像
目录 一、安装Docker及可视化工具 二、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 三、集群部署 四、部署可视化工具 1、创建挂载目录 2、运行Kafka-ui容器 3、Compose运行Kafka-ui容器 4、查看Kafka-ui运行状态 …...

ChatGPT提问技巧:行业热门应用提示词案例--咨询法律知识
ChatGPT除了可以协助办公,写作文案和生成短视频脚本外,和还可以做为一个法律工具,当用户面临一些法律知识盲点时,可以向ChatGPT咨询获得解答。赋予ChatGPT专家的身份,用户能够得到较为满意的解答。 1.咨询法律知识 举…...

openRv1126 AI算法部署实战之——Tensorflow模型部署实战
在RV1126开发板上部署Tensorflow算法,实时目标检测RTSP传输。视频演示地址 rv1126 yolov5 实时目标检测 rtsp传输_哔哩哔哩_bilibili 一、准备工作 从官网下载tensorflow模型和数据集 手动在线下载: https://github.com/tensorflow/models/b…...

STM32 TIM定时器配置
TIM简介 TIM(Timer)定时器 定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断 16位计数器、预分频器、自动重装寄存器的时基单元,在72MHz计数时钟下可以实现最大59.65s的定时 不仅具备基本的定时中断功能ÿ…...

51单片机 05 矩阵键盘
嘻嘻,LCD在RC板子上可以勉强装上,会有一点歪。 一、矩阵键盘 在键盘中按键数量较多时,为了减少I/O口的占用,通常将按键排列成矩阵形式;采用逐行或逐列的“扫描”,就可以读出任何位置按键的状态。…...

SSRF 漏洞利用 Redis 实战全解析:原理、攻击与防范
目录 前言 SSRF 漏洞深度剖析 Redis:强大的内存数据库 Redis 产生漏洞的原因 SSRF 漏洞利用 Redis 实战步骤 准备环境 下载安装 Redis 配置漏洞环境 启动 Redis 攻击机远程连接 Redis 利用 Redis 写 Webshell 防范措施 前言 在网络安全领域࿰…...

kubernetes学习-配置管理(九)
一、ConfigMap (1)通过指定目录,创建configmap # 创建一个config目录 [rootk8s-master k8s]# mkdir config[rootk8s-master k8s]# cd config/ [rootk8s-master config]# mkdir test [rootk8s-master config]# cd test [rootk8s-master test…...

python 语音识别
目录 一、语音识别 二、代码实践 2.1 使用vosk三方库 2.2 使用SpeechRecognition 2.3 使用Whisper 一、语音识别 今天识别了别人做的这个app,觉得虽然是个日记app 但是用来学英语也挺好的,能进行语音识别,然后矫正语法,自己说的时候 ,实在不知道怎么说可以先乱说,然…...

一文速览DeepSeek-R1的本地部署——可联网、可实现本地知识库问答:包括671B满血版和各个蒸馏版的部署
前言 自从deepseek R1发布之后「详见《一文速览DeepSeek R1:如何通过纯RL训练大模型的推理能力以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》」,deepseek便爆火 爆火以后便应了“人红是非多”那句话,不但遭受各种大规模攻击,即便…...

[mmdetection]fast-rcnn模型训练自己的数据集的详细教程
本篇博客是由本人亲自调试成功后的学习笔记。使用了mmdetection项目包进行fast-rcnn模型的训练,数据集是自制图像数据。废话不多说,下面进入训练步骤教程。 注:本人使用linux服务器进行展示,Windows环境大差不差。另外࿰…...

1. Kubernetes组成及常用命令
Pods(k8s最小操作单元)ReplicaSet & Label(k8s副本集和标签)Deployments(声明式配置)Services(服务)k8s常用命令Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。自2014年发布以来,K8s迅速成为容器编排领域的行业标准,被…...

linux下ollama更换模型路径
Linux下更换Ollama模型下载路径指南 在使用Ollama进行AI模型管理时,有时需要根据实际需求更改模型文件的存储路径。本文将详细介绍如何在Linux系统中更改Ollama模型的下载路径。 一、关闭Ollama服务 在更改模型路径之前,需要先停止Ollama服务。…...

本地Ollama部署DeepSeek R1模型接入Word
目录 1.本地部署DeepSeek-R1模型 2.接入Word 3.效果演示 4.问题反馈 上一篇文章办公新利器:DeepSeekWord,让你的工作更高效-CSDN博客https://blog.csdn.net/qq_63708623/article/details/145418457?spm1001.2014.3001.5501https://blog.csdn.net/qq…...

【自学笔记】Git的重点知识点-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Git基础知识Git高级操作与概念Git常用命令 总结 Git基础知识 Git简介 Git是一种分布式版本控制系统,用于记录文件内容的改动,便于开发者追踪…...

[EAI-028] Diffusion-VLA,能够进行多模态推理和机器人动作预测的VLA模型
Paper Card 论文标题:Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression 论文作者:Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chao…...

实现数组的扁平化
文章目录 1 实现数组的扁平化1.1 递归1.2 reduce1.3 扩展运算符1.4 split和toString1.5 flat1.6 正则表达式和JSON 1 实现数组的扁平化 1.1 递归 通过循环递归的方式,遍历数组的每一项,如果该项还是一个数组,那么就继续递归遍历,…...
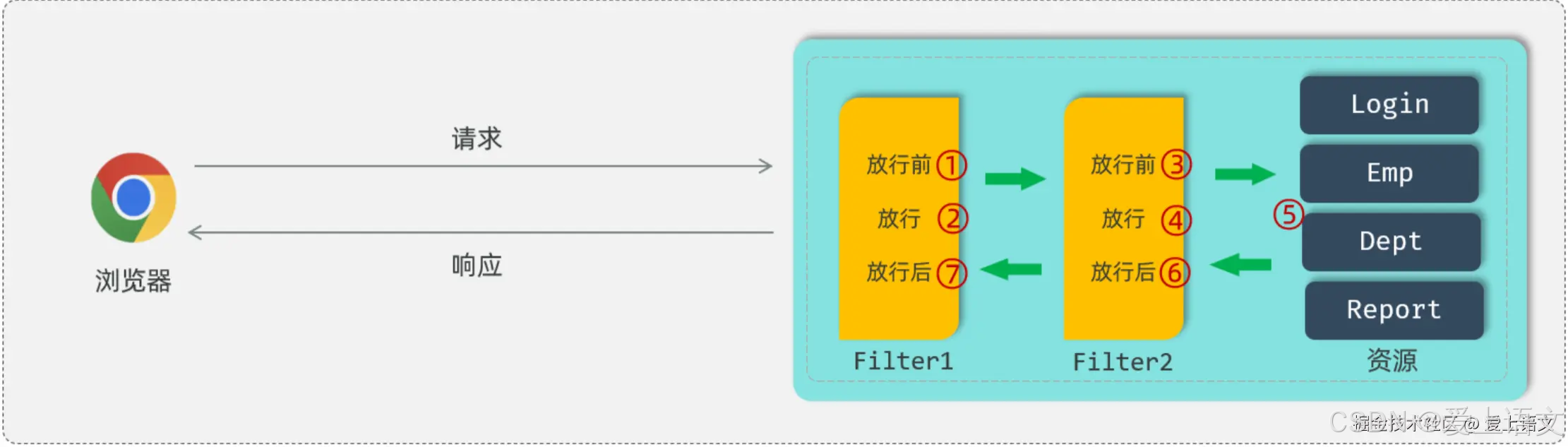
登录认证(5):过滤器:Filter
统一拦截 上文我们提到(登录认证(4):令牌技术),现在大部分项目都使用JWT令牌来进行会话跟踪,来完成登录功能。有了JWT令牌可以标识用户的登录状态,但是完整的登录逻辑如图所示&…...

pytorch实现门控循环单元 (GRU)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 特性GRULSTM计算效率更快,参数更少相对较慢,参数更多结构复杂度只有两个门(更新门和重置门)三个门(输入门、遗忘门、输出门)处理长时依赖一般适…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...

SpringCloud优势
目录 完善的微服务支持 高可用性和容错性 灵活的配置管理 强大的服务网关 分布式追踪能力 丰富的社区生态 易于与其他技术栈集成 完善的微服务支持 Spring Cloud 提供了一整套工具和组件来支持微服务架构的开发,包括服务注册与发现、负载均衡、断路器、配置管理等功能…...

linux设备重启后时间与网络时间不同步怎么解决?
linux设备重启后时间与网络时间不同步怎么解决? 设备只要一重启,时间又错了/偏了,明明刚刚对时还是对的! 这在物联网、嵌入式开发环境特别常见,尤其是开发板、树莓派、rk3588 这类设备。 解决方法: 加硬件…...