初识大模型——大语言模型 LLMBook 学习(一)
1. 大模型发展历程
🔹 1. 早期阶段(1950s - 1990s):基于规则和统计的方法
代表技术:
-
1950s-1960s:规则驱动的语言处理
- 早期的 NLP 主要依赖 基于规则的系统,如 Noam Chomsky 提出的 生成语法(Generative Grammar)。
- 这些系统使用手工编写的规则来解析和生成句子,但扩展性差。
-
1970s-1990s:统计语言模型(Statistical Language Models, SLM)
- 1980s 以后,随着计算能力的提高,研究者开始使用 统计方法 处理语言,如 n-gram 语言模型。
- 1990s,隐马尔可夫模型(HMM) 和 条件随机场(CRF) 被广泛用于语音识别和词性标注。
🔹 2. 机器学习时代(2000s - 2018s):神经网络与深度学习
代表技术:
-
2000s:基于神经网络的 NLP
- 2003 年,Bengio 等人提出神经网络语言模型(Neural Language Model, NLM),引入了**词向量(Word Embeddings)**的概念。
- 2013 年,Google 的 Word2Vec 算法问世,使得词向量学习成为 NLP 研究的标准方法。
-
2014-2017:RNN、LSTM、Seq2Seq 和 Attention
- 2014 年,循环神经网络(RNN) 和 长短时记忆网络(LSTM) 被用于机器翻译。
- 2015 年,Google 提出了 Seq2Seq 模型,用于机器翻译和文本摘要。
- 2017 年,Google 发表论文《Attention Is All You Need》,提出 Transformer 模型,彻底改变 NLP 领域。
🔹 3. 预训练大模型时代(2018 - 至今):Transformer 和大规模语言模型
代表技术:
-
2018 年:BERT(Google)
- Google 发表 BERT(Bidirectional Encoder Representations from Transformers),首次引入 双向 Transformer 预训练,显著提升 NLP 任务的表现。
-
2019 年:GPT-2(OpenAI)
- OpenAI 推出 GPT-2(Generative Pre-trained Transformer 2),展示了强大的文本生成能力,但由于担心滥用,最初未完全公开。
-
2020 年:GPT-3(OpenAI)
- GPT-3 具有 1750 亿参数,是当时最大的语言模型,能够执行多种 NLP 任务,如写作、翻译、编程等。
-
2021 年:T5、GPT-3.5、Codex
- Google 推出 T5(Text-to-Text Transfer Transformer),强调统一 NLP 任务的架构。
- OpenAI 发布 Codex,用于代码生成,并成为 GitHub Copilot 的核心技术。
-
2022 年:GPT-4、PaLM、BLOOM
- OpenAI 发布 GPT-4,具备更强的推理能力和多模态(文字+图片)处理能力。
- Google 推出 PaLM(Pathways Language Model),支持更大的数据规模和更广泛的任务。
- 由多个研究机构联合开发的 BLOOM 模型,作为开源替代方案。
-
2023-2024 年:GPT-4 Turbo、Gemini、Claude
- OpenAI 推出 GPT-4 Turbo,在 GPT-4 的基础上优化了速度和成本。
- Google DeepMind 发布 Gemini 1.5,支持更长的上下文窗口(100 万 token)。
- Anthropic 公司推出 Claude 3,在推理和多模态能力上有所提升。
🔹 未来趋势
- 更大规模、更高效的模型:模型参数越来越大,但也在优化计算效率,如 Mixture-of-Experts(MoE)架构。
- 多模态 AI:不仅支持文本,还能理解和生成图像、音频、视频等内容。
- 个性化 AI:未来的 AI 可能会根据用户习惯进行个性化调整,提高交互体验。
- 更强的推理与规划能力:AI 可能会发展出更复杂的逻辑推理和长期规划能力。
- 更安全和可控的 AI:随着 AI 能力增强,如何避免滥用和确保安全性成为重要研究方向。
大语言模型具有以下能力:
- 范围广泛的世界知识
- 较强的人类指令遵循能力
- 改进的复杂任务推理能力
- 较强的通用任务解决能力
- 较好的人类对齐能力
- 较强的多轮对话交互能力
这些能力使得大语言模型在知识问答、任务执行、逻辑推理、对话交互等方面表现出色,并推动 AI 技术在各个领域的应用与发展。 🚀
2. 大模型的到来引发的变革
大语言模型(LLM,如 GPT-4、Gemini、Claude 等)的发展,不仅提升了人工智能的能力,还在多个领域引发了深远的变革。以下是主要影响:

1. 人工智能应用的普及
🚀 传统 AI 向通用 AI 过渡
- 过去的 AI 主要是 专用 AI(如语音助手、搜索引擎、翻译工具)。
- 大模型推动了 通用 AI(AGI)的发展,使 AI 能够处理更广泛的任务,如写作、编程、推理、创意生成等。
✅ 影响:
- AI 由“工具”向“智能助手”转变,能自主执行复杂任务。
- AI 进入日常生活,如智能客服、虚拟助理、AI 生成内容(AIGC)。
2.生产力革命
📈 提高工作效率,改变工作方式
- 自动化办公:AI 生成报告、邮件、PPT,提升效率。
- 智能编程:AI 辅助代码开发(如 GitHub Copilot),减少重复劳动。
- 数据分析:AI 处理大规模数据,提高商业决策能力。
✅ 影响:
- 减少重复性工作,让人类专注于创造性任务。
- 降低技术门槛,让非专业人士也能利用 AI 进行复杂任务。
3.产业变革
🏭 传统行业的智能化升级
- 媒体与内容创作:AI 生成文章、视频、音乐(AIGC)。
- 教育:智能辅导、个性化学习、自动批改作业。
- 医疗:AI 辅助诊断、药物研发、健康管理。
- 法律:合同审查、法律咨询自动化。
- 金融:智能投顾、风险评估、自动交易。
✅ 影响:
- AI 让企业 降本增效,提高竞争力。
- 传统行业加速 数字化转型,催生新商业模式。
4.人才市场的变化
👨💻 AI 取代部分岗位,催生新职业
- 减少低端重复性工作(如数据录入、基础客服)。
- 催生新职业(如 AI 提示工程师、AI 伦理专家)。
- 要求更高的技能(如 AI 驱动的决策、创造性思维)。
✅ 影响:
- 部分岗位被 AI 替代,需要 提升技能 适应变化。
- 人机协作成为主流,AI 辅助人类完成更复杂的任务。
5.信息传播与认知变革
🌍 AI 影响人类获取和理解信息的方式
- 搜索引擎升级:AI 直接回答问题,减少传统搜索需求。
- 个性化推荐:AI 根据用户偏好提供精准内容。
- 信息生成:AI 生成新闻、报告、社交媒体内容。
✅ 影响:
- 加速信息传播,但也带来 虚假信息 风险。
- 改变学习方式,知识获取更加高效。
6.伦理与安全挑战
⚠️ AI 发展带来的风险
- 假信息泛滥:AI 生成的假新闻、深度伪造(deepfake)可能误导公众。
- 数据隐私问题:AI 需要大量数据,可能涉及隐私泄露。
- 算法偏见:AI 可能继承训练数据中的偏见,影响公平性。
- 滥用问题:AI 可能被用于诈骗、恶意攻击等。
✅ 影响:
- 需要 加强 AI 监管,制定 伦理规范。
- 促进 可信 AI 发展,确保 AI 透明、公正、安全。
7.科研与技术创新
🧠 AI 促进科学研究
- 加速新药研发:AI 预测分子结构,缩短研发周期。
- 物理与天文:AI 处理大规模数据,加速科学发现。
- 数学与理论研究:AI 辅助证明数学定理。
✅ 影响:
- AI 成为 科研助手,加速突破前沿科技。
- 促进 跨学科融合,推动新技术发展。
大模型的到来不仅是 AI 领域的技术突破,更是 社会、经济、文化 领域的深刻变革。它提升了生产力,改变了产业格局,同时也带来了新的挑战和机遇。未来,我们需要 合理利用 AI,推动技术向更加 安全、透明、可控 的方向发展。🚀
3. 大模型技术基础

1.大模型的定义
- 大语言模型 指的是 参数规模极大(通常数十亿到万亿级)的 预训练语言模型,能够理解和生成自然语言。
- 这些模型通过 大规模数据训练,具备 广泛的知识 和 语言理解能力。
2.大模型的架构
- 主要采用 Transformer 解码器架构
- Transformer 是目前最先进的深度学习架构之一,具有 并行计算能力强、长距离依赖建模能力强 等特点。
- 其中,大模型通常使用 解码器(Decoder) 结构,而非完整的编码器-解码器结构。
3.大模型的训练过程

训练过程分为 两大阶段:
🔹 预训练(Pre-training)—— 训练基础能力

- 数据:使用 海量文本数据(如书籍、论文、网页、对话等)。
- 优化目标:预测下一个词(Next Token Prediction)。
- 结果:训练出 基础模型(Base Model),具备 语言理解和生成能力,但尚未针对具体任务优化。
🔹 后训练(Fine-tuning)—— 增强任务能力

- 数据:使用 大量指令数据(如人类指令、对话数据、任务示例等)。
- 优化方法:
- SFT(Supervised Fine-Tuning):监督微调,让模型更好地遵循人类指令。
- RLHF(Reinforcement Learning with Human Feedback):基于人类反馈的强化学习,使模型的回答更符合人类偏好。
- 结果:训练出 指令模型(Instruct Model),能够更好地执行 特定任务(如问答、代码生成、写作等)。
拓展定律

核心观点
更大的模型(更多参数)+ 更多数据 + 更强算力 = 更强的 AI 能力
通过扩展 计算量(Compute)、数据规模(Dataset Size) 和 模型参数(Parameters),可以系统性地降低模型的 测试损失(Test Loss),提升模型的表现。
1. 计算量(Compute)
计算量越大,模型训练得越充分,损失下降。
但计算量的 回报递减,即增加计算量带来的收益逐渐减少。
2. 数据规模(Dataset Size)
训练数据越多,模型的泛化能力越强,损失下降更快。
但如果数据质量低,单纯增加数据可能不会带来提升。
3. 模型参数(Parameters)
更大的模型(更多参数)通常表现更好,但前提是有足够的数据和计算资源支持。过大的模型如果数据不足,可能会导致 过拟合(overfitting)。
-
大模型为何有效?
- 过去 AI 发展依赖于 算法优化,但大模型时代,规模扩展(Scaling)成为核心驱动力。
- 只要 数据、算力、模型规模 继续增长,AI 仍能不断进步。
-
GPT-4、Gemini 等大模型的成功
- 这些模型的进化路径符合 扩展定律,即通过 增加参数、数据、算力 来提升能力。
- 例如 GPT-4 相比 GPT-3,主要是 参数规模更大、数据更多、训练更充分,因此表现大幅提升。
-
未来发展趋势
- 目前的大模型仍在 扩展阶段,但未来可能会遇到 数据瓶颈 或 计算成本过高 的问题。
- 研究人员正在探索 更高效的训练方法,如 混合专家模型(MoE)、自监督学习优化 等,以减少计算成本。
涌现能力
📌 什么是涌现能力?
涌现能力(Emergent Abilities) 指的是 在小型模型中不存在,但在大规模模型中突然出现的能力。
1. 涌现能力的定义
- 原始论文定义:
“在小型模型中不存在,但在大模型中出现的能力。”
- 这意味着 某些复杂任务的能力 只有当模型达到 足够大的规模 时才会突然显现,而不是随着规模线性增长。
2.涌现能力的特点
- 非线性增长:随着模型规模扩大,某些能力不会逐步提升,而是在 达到某个临界点 后突然跃升。
- 超越随机水平:在小模型中,模型的表现接近随机水平,但在大模型中,表现远超随机猜测。
- 任务多样性:涌现能力可以体现在 数学推理、自然语言理解(NLU)、上下文推理 等多个任务上。
3. 论文中的实验结果

-
数学运算(Mod. Arithmetic)
- 小模型几乎无法完成数学计算,但当模型规模达到 (10^{22}) 级别时,准确率突然大幅提升。
-
多任务自然语言理解(Multi-task NLU)
- 小模型的表现接近随机水平,但大模型在理解复杂语境时表现显著提升。
-
上下文词义理解(Word in Context)
- 只有当模型达到一定规模时,才能正确理解 同一个词在不同上下文中的含义。
某些能力只有当模型足够大时才会涌现,而不是随着规模逐步提升。
- 只有当模型达到一定规模时,才能正确理解 同一个词在不同上下文中的含义。
涌现能力的影响
-
大模型的突破:
- 过去,AI 主要依赖 手工设计规则 或 小规模模型优化,但涌现能力表明 规模本身就是一种优化手段。
- 只要 增加参数、数据和计算量,AI 可能会自动学会某些复杂能力。
-
AI 发展趋势:
- 未来 AI 可能会继续展现 更多未曾预料的能力,比如更强的推理、规划、甚至自主学习能力。
- 研究人员需要探索 如何控制和利用这些能力,避免不可预测的风险。
4.大模型核心技术解析

1.规模扩展(Scaling)
- 扩展定律(Scaling Laws) 表明,增加模型参数、数据规模和计算量,可显著提升模型能力。
- 关键点:参数规模增大(如 GPT-3 → GPT-4)、数据规模扩展、计算能力提升(GPU/TPU)。
2.数据工程(Data Engineering)
- 数据数量、质量和预处理方法 直接决定模型性能。
- 关键点:海量高质量数据、数据清洗与增强、去噪处理。
3.高效预训练(Efficient Pre-training)
- 大模型训练需要强大计算资源,需建立高效、可扩展训练架构。
- 关键点:分布式训练、混合精度计算(FP16/FP8)、自监督学习。
4.能力激发(Capability Activation)
- 基础模型需微调(Fine-tuning) 以适应特定任务。
- 关键点:微调、对齐技术(RLHF)、提示工程(Prompt Engineering)。
5.人类对齐(Human Alignment)
- 防止错误、有害或偏见内容,确保 AI 可靠性。
- 关键点:安全性优化、减少幻觉(Hallucination)、伦理与公平性。
6.工具使用(Tool Use)
- 结合外部工具增强能力,拓展应用范围。
- 关键点:代码执行(Python、SQL)、搜索引擎集成、插件(Plugins)。
5.GPT和DeepSeek介绍
1. GPT体系

2.GPT发展历程

1. GPT-1(2018):开创预训练 + 微调范式
🔹 关键优化点
- 引入 Transformer 架构:相比 RNN 和 LSTM,Transformer 具备 更强的并行计算能力,提升了训练效率。
- 自回归预训练(Autoregressive Pre-training):使用 无监督学习 训练,预测下一个词(Next Token Prediction)。
- 微调(Fine-tuning):在特定任务(如问答、情感分析)上进行微调,提高模型的任务适应性。
- 参数规模:1.17 亿(1.17B)。
🔹 局限性
- 数据规模较小(仅使用 BookCorpus 训练)。
- 未使用大规模互联网数据,知识覆盖有限。
- 缺乏对齐技术,容易生成不准确或不安全的内容。
2.GPT-2(2019):扩大规模,提升文本生成能力
🔹 关键优化点
- 大规模数据训练:使用 WebText 数据集,涵盖更广泛的文本内容。
- 参数规模大幅增长:
- GPT-2 小型版:1.5 亿(0.15B)
- GPT-2 完整版:15 亿(1.5B)
- 更自然的文本生成:生成的文本连贯性和上下文理解能力显著提升。
- 零样本(Zero-shot)、少样本(Few-shot)学习:在 没有微调的情况下 也能完成部分任务。
🔹 局限性
- 仍然存在幻觉(Hallucination),容易生成不真实的内容。
- 缺乏人类对齐(Alignment),可能生成有害或偏见内容。
- 计算成本较高,训练难度增加。
3.GPT-3(2020):参数暴涨,涌现能力初现
🔹 关键优化点
- 参数规模爆炸式增长:
- GPT-3:1750 亿(175B)参数,远超 GPT-2。
- 更强的涌现能力(Emergent Abilities):
- 数学运算、代码生成、逻辑推理 等能力显著增强。
- 少样本学习(Few-shot Learning)能力提升:
- 通过 提示工程(Prompt Engineering),模型可以在 几乎不需要微调的情况下 解决复杂任务。
- 更丰富的数据训练:
- 训练数据涵盖 书籍、论文、代码、新闻、对话 等多种文本来源。
🔹 局限性
- 仍然缺乏 RLHF(人类反馈强化学习),容易生成不安全或有害内容。
- 计算成本极高,推理速度较慢。
- 幻觉问题依然存在,在事实性任务上仍有错误。
4.InstructGPT(2022):引入 RLHF,提高对齐性
🔹 关键优化点
- 引入人类反馈强化学习(RLHF):
- 通过 人类评分数据 训练模型,使其更符合人类期望。
- 减少有害内容,提高回答的安全性和准确性。
- 优化对话能力:
- 更自然、更符合用户意图,减少胡编乱造的情况。
- 成为 ChatGPT 的基础:
- InstructGPT 是 ChatGPT 的前身,使 AI 更适合对话交互。
🔹 局限性
- 仍然存在幻觉问题,但比 GPT-3 有所改善。
- 对话能力增强,但仍然无法进行深度推理和长期记忆。
4.GPT-4(2023):多模态增强,推理能力升级
🔹 关键优化点
- 引入多模态能力(Multimodal):
- 支持图像输入,可以理解图片内容(如 OpenAI 的 GPT-4V)。
- 推理能力大幅提升:
- 更强的逻辑推理、数学计算和代码生成能力。
- 更长的上下文窗口,可以处理更长的文本输入。
- 更强的对齐技术:
- 优化 RLHF 训练,减少幻觉,提高事实性回答的准确率。
- 更安全的内容生成,降低偏见和错误信息。
🔹 局限性
- 仍然无法完全消除幻觉问题,在部分领域仍可能生成错误信息。
- 计算成本极高,推理速度仍然有限。
- 对话记忆仍然有限,无法进行长期上下文追踪。
6.GPT-4.5 / GPT-5(未来预测)
🔹 可能的优化点
- 更长的上下文窗口(如 100K+ tokens)。
- 更强的多模态能力(结合视频、音频、3D 视觉等)。
- 更高效的推理能力(更接近 AGI)。
- 更低的计算成本,使 AI 更容易普及。
- 更强的个性化与记忆能力,可以长期记住用户的偏好和对话历史。
3.DeepSeek技术
发展历程

改进点


DeepSeek-V3

DeepSeek-R1

参考文献
Datawhale大模型组队学习地址
相关文章:
初识大模型——大语言模型 LLMBook 学习(一)
1. 大模型发展历程 🔹 1. 早期阶段(1950s - 1990s):基于规则和统计的方法 代表技术: 1950s-1960s:规则驱动的语言处理 早期的 NLP 主要依赖 基于规则的系统,如 Noam Chomsky 提出的 生成语法&…...

LabVIEW伺服阀高频振动测试
在伺服阀高频振动测试中,闭环控制系统的实时性与稳定性至关重要。针对用户提出的1kHz控制频率需求及Windows平台兼容性问题,本文重点分析NI PCIe-7842R实时扩展卡的功能与局限性,并提供其他替代方案的综合对比,以帮助用户选择适合…...

AI编程工具-(七)
250309,10这几天都在用通义灵码搞做建模分析。 感想,指令越具体,实现效果越好。 依然是之前的时许数据,这几天分析效果没有提升。 画的几个有意思的图表和效果 主要觉得这图好看,提示词不复杂。 预测效果 预测准确性提升不大聊…...

什么是一致性模型,在实践中如何选择?
一、一致性模型 1、强一致性(Strong Consistency) ①定义:强一致性意味着在分布式系统中的每个读取操作,都能读取到最近写入的数据。也就是说,所有节点都始终保持相同的数据状态。 ②特点:写操作对所有节点立即可见,所有的读取操作在任何节点上都能看到最新的写入。 …...

Python项目-智能家居控制系统的设计与实现
1. 引言 随着物联网技术的快速发展,智能家居系统已经成为现代家庭生活的重要组成部分。本文将详细介绍一个基于Python的智能家居控制系统的设计与实现过程,该系统能够实现对家庭设备的集中管理和智能控制,提升家居生活的便捷性和舒适度。 2…...

RDP连接无法复制粘贴问题的排查与解决指南
RDP连接无法复制粘贴问题的排查与解决指南 问题描述注意事项排查原因检查RDP剪贴板进程是否正常检查组策略设置检查权限和安全设置检查网络连接 解决方式重启rdpclip.exe进程启用RDP剪贴板重定向调整组策略设置检查并调整安全设置更新驱动程序和系统检查网络连接使用其他远程连…...
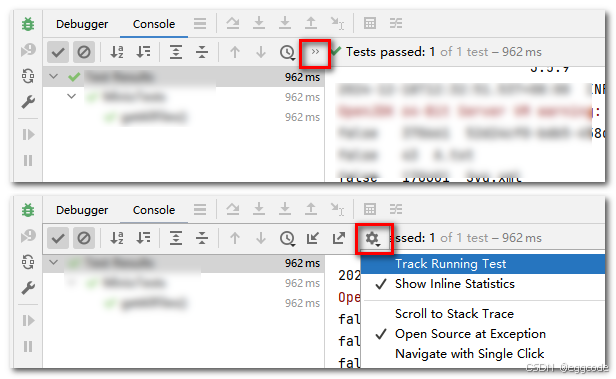
IDEA与Maven使用-学习记录(持续补充...)
1. 下载与安装 以ideaIU-2021.3.1为例,安装步骤: 以管理员身份启动ideaIU-2021.3.1修改安装路径为:D:\Program Files\JetBrains\IntelliJ IDEA 2021.3.1勾选【创建桌面快捷方式】(可选)、【打开文件夹作为项目】&…...

Go 语言封装 HTTP 请求的 Curl 工具包
文章目录 Go 语言封装 HTTP 请求的 Curl 工具包🏗️ 工具包结构简介核心结构体定义初始化函数 🌟 功能实现1. 设置请求头2. 构建请求3. 发送请求4. 发送 GET 请求5. 发送 POST 请求6. 发送 PUT 请求7. 发送 DELETE 请求8. 读取响应体 💡 实现…...
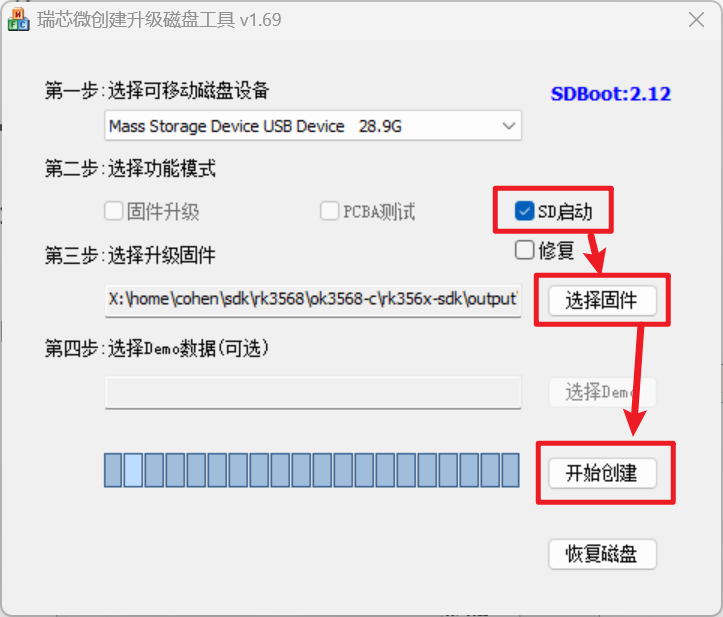
RK3568 SD卡调试记录
文章目录 1、环境介绍2、概念理清3、原理图查看4、dts配置5、验证6、SD卡启动6.1、启动优先级6.2、启动流程6.2.1、Maskrom(Boot ROM)启动优先级6.2.2、Pre-loader(SPL)启动优先级 6.3、如何从sd卡启动?6.3.1、制作sd启动卡6.3.2、sd卡启动 7、总结 1、环境介绍 硬…...

高效获取历史行情数据:xtquant的实战应用
高效获取历史行情数据:xtquant的实战应用 🚀量化软件开通 🚀量化实战教程 在量化交易领域,历史行情数据是构建和测试交易策略的基础。无论是回测策略的有效性,还是进行市场分析,高质量的历史数据都是不可…...

【python爬虫】酷狗音乐爬取练习
注意:本次爬取的音乐仅有1分钟试听,仅作学习爬虫的原理,完整音乐需要自行下载客户端。 一、 初步分析 登陆酷狗音乐后随机选取一首歌,在请求里发现一段mp3文件,复制网址,确实是我们需要的url。 复制音频的…...

阿里云 DataWorks面试题集锦及参考答案
目录 简述阿里云 DataWorks 的核心功能模块及其在企业数据治理中的作用 简述 DataWorks 的核心功能模块及其应用场景 解释 DataWorks 中工作空间、项目、业务流程的三层逻辑关系 解释 DataWorks 中的 “节点”、“工作流” 和 “依赖关系” 设计 解释 DataWorks 中 “周期任…...
uniapp+Vue3 开发小程序的下载文件功能
小程序下载文件,可以先预览文件内容,然后在手机上打开文件的工具中选择保存。 简单示例:(复制到HBuilder直接食用即可) <template><view class"container-detail"><view class"example…...

Apache Log4j 2
目录 1. Apache Log4j 2 简介 1.1 什么是Log4j 2? 1.2 Log4j 2 的主要特性 2. Log4j 2 的核心组件 2.1 Logger 2.2 Appender 2.3 Layout 2.4 Filter 2.5 Configuration 3. Log4j 2 的配置 4. Log4j 2 的使用示例 4.1 Maven 依赖 4.2 示例代码 4.3 输出…...
4.2.2 ArrayList类
ArrayList类与List类的用法差不多,提供的方法也差不多。但是与List不同的是,ArrayList可以包含任意类型的数据,但是相应的,要使用包含的数据,就必须对数据做相应的装箱和拆箱(关于装箱和拆箱,请…...

L1-088 静静的推荐
L1-088 静静的推荐 - 团体程序设计天梯赛-练习集 (pintia.cn) 题解 这里代码很简单,但是主要是循环里面的内容很难理解,下面是关于循环里面的内容理解: 这里 n 10 表示有 10 个学生,k 2 表示企业接受 2 批次的推荐名单&#…...

普及听力保健知识竞赛
普及听力保健知识竞赛 热点指数:★★★ 日期:3月3日 关键词:爱耳护耳、听力健康、耳部保健、听力科普 适合行业:医疗健康、健康护理、教育培训、公益组织 推荐功能:答题、H5宣传 宣传方向:广泛普及听力…...

小结: IGMP协议
IGMP(Internet Group Management Protocol)协议详解 IGMP(Internet Group Management Protocol)是IPv4 组播(Multicast)通信的控制协议,主要用于主机和路由器之间的组播成员管理。IGMP 允许主机…...
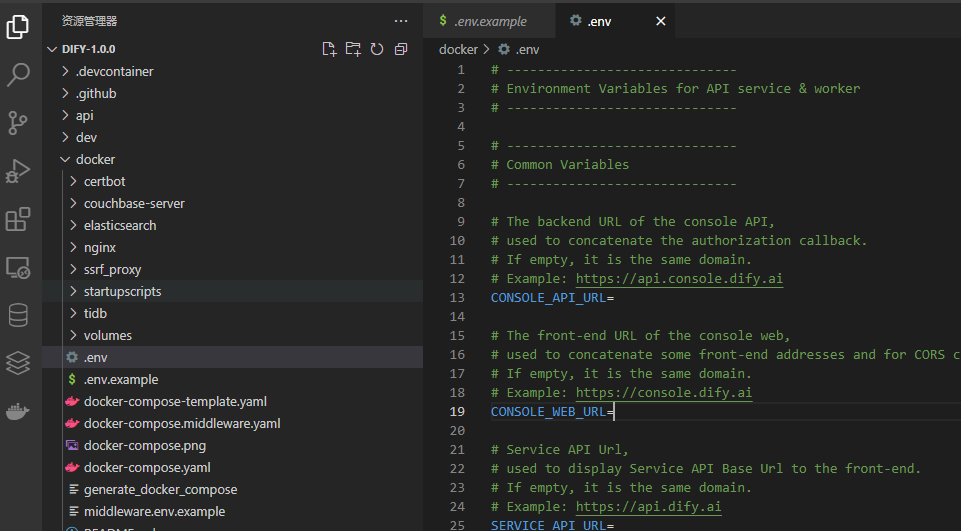
Dify 本地部署教程
目录 一、下载安装包 二、修改配置 三、启动容器 四、访问 Dify 五、总结 本篇文章主要记录 Dify 本地部署过程,有问题欢迎交流~ 一、下载安装包 从 Github 仓库下载最新稳定版软件包,点击下载~,当然也可以克隆仓库或者从仓库里直接下载zip源码包。 目前最新版本是V…...
)
ConcurrentHashMap从源码总结使用注意事项(源码)
ConcurrentHashMap实现原理 目录 ConcurrentHashMap实现原理核心源码解读(1)数据结构: 采用数组链表/红黑树(2)初始化(3)并发扩容(4)put 操作流程(5)计数 siz…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...
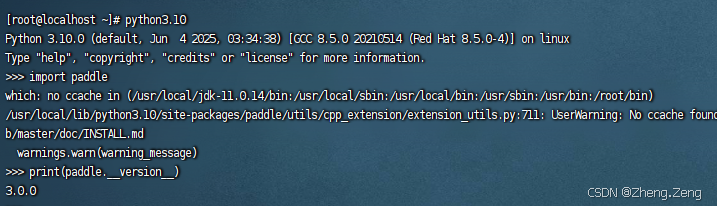
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...
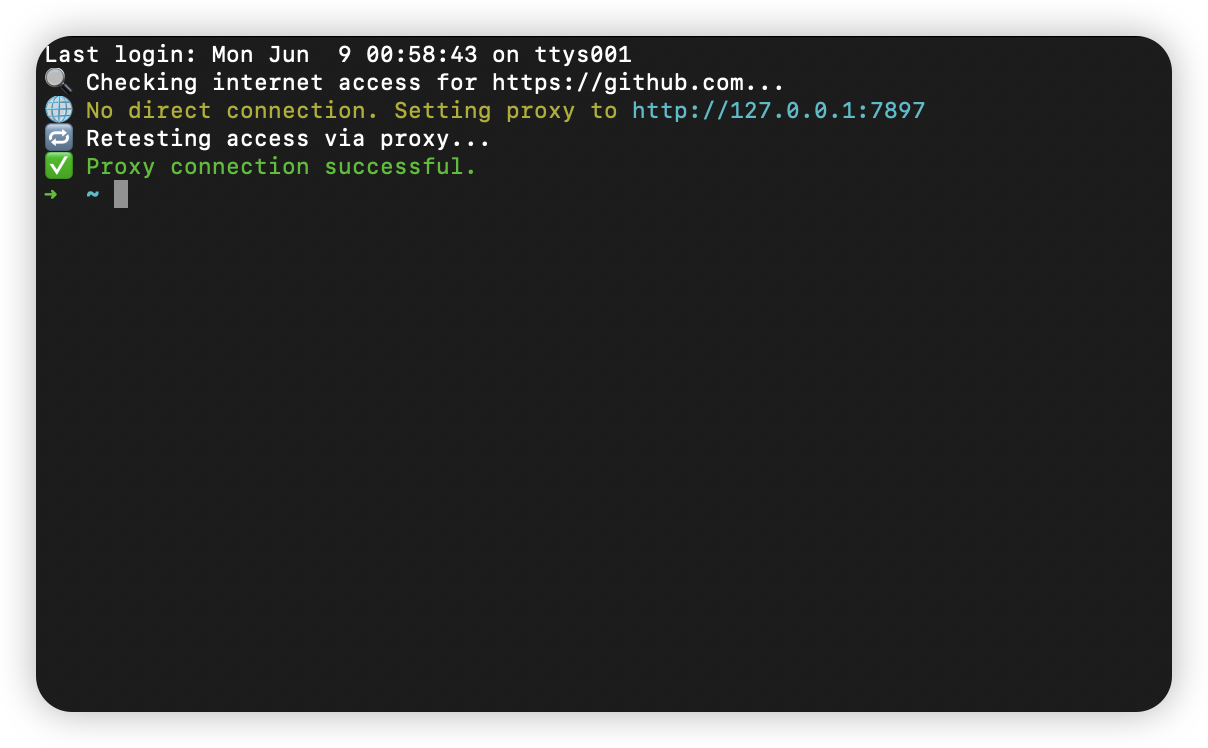
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...
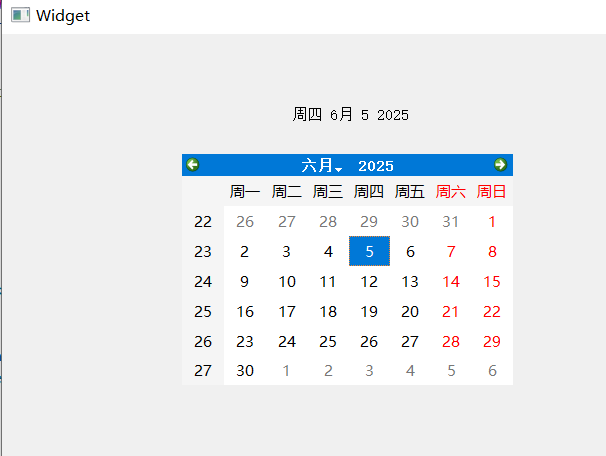
【QT控件】显示类控件
目录 一、Label 二、LCD Number 三、ProgressBar 四、Calendar Widget QT专栏:QT_uyeonashi的博客-CSDN博客 一、Label QLabel 可以用来显示文本和图片. 核心属性如下 代码示例: 显示不同格式的文本 1) 在界面上创建三个 QLabel 尺寸放大一些. objectName 分别…...
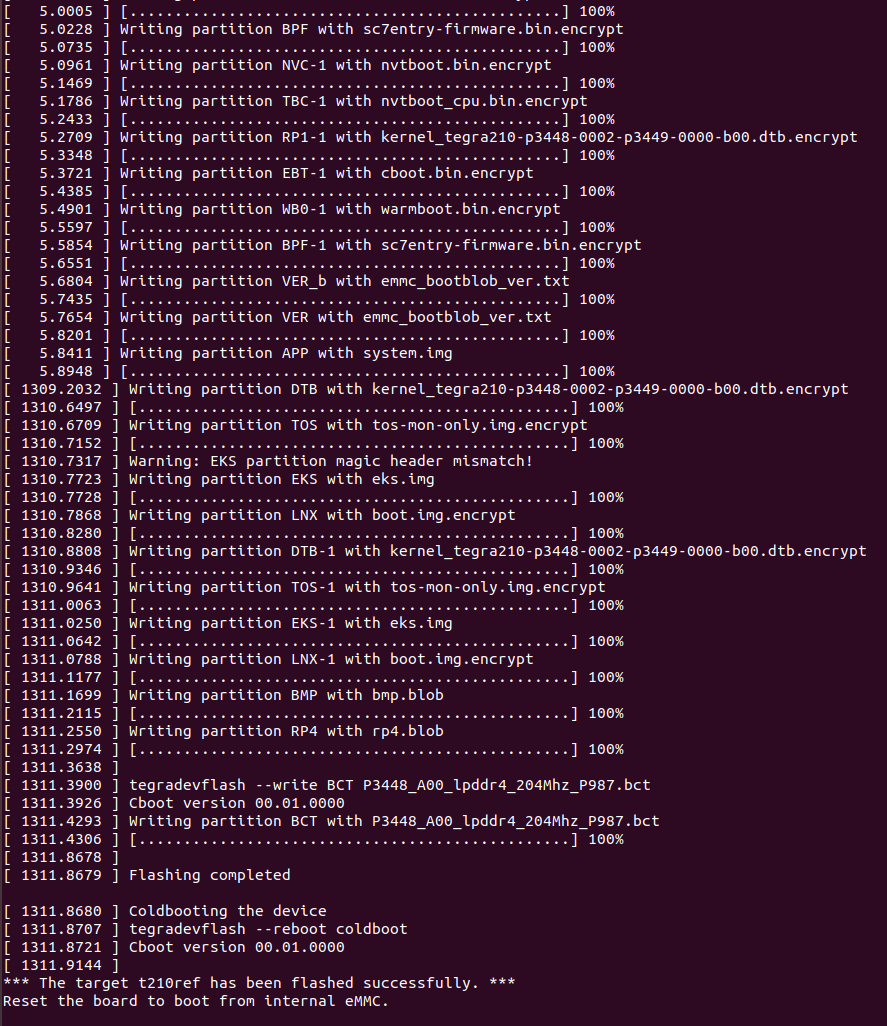
新版NANO下载烧录过程
一、序言 搭建 Jetson 系列产品烧录系统的环境需要在电脑主机上安装 Ubuntu 系统。此处使用 18.04 LTS。 二、环境搭建 1、安装库 $ sudo apt-get install qemu-user-static$ sudo apt-get install python 搭建环境的过程需要这个应用库来将某些 NVIDIA 软件组件安装到 Je…...