ConcurrentHashMap从源码总结使用注意事项(源码)
ConcurrentHashMap实现原理
目录
- ConcurrentHashMap实现原理
- 核心源码解读
- (1)数据结构: 采用数组+链表/红黑树
- (2)初始化
- (3)并发扩容
- (4)put 操作流程
- (5)计数 size
- (6)get 操作
- (7)remove 操作
- (8)遍历操作
- 基于源码总结一些使用注意事项
主要特点:
- 使用Node数组作为桶数组,每个桶可能是一个链表或者红黑树。
- 通过CAS和synchronized实现线程安全,每个桶的头节点作为锁,减小锁的粒度。
- 扩容时支持多线程协同工作,分片迁移数据。
- volatile变量保证内存可见性,get操作无需加锁。
- 使用计数器(如baseCount和CounterCell)来高效统计元素数量。
核心源码解读
(1)数据结构: 采用数组+链表/红黑树
- 链表长度 ≥8 且数组长度 ≥64 时,链表转为红黑树(
TREEIFY_THRESHOLD) - 红黑树节点数 ≤6 时退化为链表(
UNTREEIFY_THRESHOLD)
提前看看几个使用较多的方法:
// 计算 Node hash 哈希值:将原始哈希码 key.hashCode() 的高低位混合,减少哈希冲突
static final int spread(int h) {return (h ^ (h >>> 16)) & HASH_BITS; // 高位参与运算,HASH_BITS 屏蔽负数标记
}// 哈希值定位数组索引,使用 tabAt 方法保证内存可见性
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {// 通过 Unsafe.getObjectVolatile 直接读取内存中的最新值,无需加锁return (Node<K,V>) U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}// 通过 CAS(比较并交换)操作原子性地更新哈希表中指定位置的节点。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v) {return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
特殊Node hash值,hash 小于0表示扩容节点/红黑树
// (1) 扩容节点(ForwardingNode):若遇到 ForwardingNode(哈希值 MOVED = -1)
static final int MOVED = -1; // hash for forwarding nodes
// (2) 红黑树(TreeBin):若节点为 TreeBin(哈希值 TREEBIN = -2)
static final int TREEBIN = -2; // hash for roots of trees
sizeCtl 状态管理:(状态控制变量,用于管理哈希表的初始化、扩容状态及扩容触发阈值)
sizeCtl >= 0:表示扩容阈值(元素总数>= sizeCtl时,触发扩容);sizeCtl = -1:表示哈希表正在初始化;sizeCtl < -1:表示正在扩容,存储扩容标识(resizeStamp),低16位存储当前参与扩容的线程数
/*** The number of bits used for generation stamp in sizeCtl.
**/
private static int RESIZE_STAMP_BITS = 16;/*** The bit shift for recording size stamp in sizeCtl.*/
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;// 高16位存储标识
static final int resizeStamp(int n) {return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}// 低16位存储协助线程数,扩容时示例:
U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
(2)初始化
延迟初始化:首次调用 put 时通过 initTable() 初始化数组,利用 sizeCtl 变量(volatile)控制状态:负数表示正在初始化或扩容,正数为扩容阈值。
// 默认构造器,do nothing
public ConcurrentHashMap() {
}final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)// 初始化数组tab = initTable();...
}private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {// sizeCtl小于0,等待其他线程完成初始化if ((sc = sizeCtl) < 0)Thread.yield(); else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { // CAS 竞争初始化权 try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;// 创建 Node 数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2); // 更新阈值}} finally {sizeCtl = sc;}break;}}return tab;
}
(3)并发扩容
通过 transfer() 方法迁移数据,多线程协作处理不同桶区间。扩容期间查询操作通过 ForwardingNode find() 转发到新数组进行查询。
主要扩容场景:
(1)addCount()更新元素总数时,发现元素总数超过扩容阈值sizeCtl;
(2)树化前,单个哈希桶的链表长度 >= 8,但数组长度 < 64, 优先扩容;
(3)插入元素时遇到 ForwardingNode,协助扩容、数据迁移**;**
…
// putVal 会触发扩容 / 协助扩容
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)...else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {...}else if ((fh = f.hash) == MOVED)// MOVED 表示当前正在扩容,当前线程协助迁移数据并扩容//(3)插入元素时遇到 ForwardingNode,协助扩容、数据迁移;tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {... put逻辑 ...}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)// (2)树化前,单个哈希桶的链表长度 >= 8,但数组长度 < 64, 优先扩容;treeifyBin(tab, i);...}} }// 增/减数量// (1)addCount()更新元素总数时,发现元素总数超过扩容阈值;addCount(1L, binCount);return null;
}/**(1) addCount()更新元素总数时,发现元素总数超过扩容阈值,开始扩容;@param check : 是否需要检查扩容(通常插入操作check>=0,删除操作可能为-1)
**/
private final void addCount(long x, int check) {CounterCell[] as; long b, s;if ((as = counterCells) != null ||... 计数逻辑 ...}// 检查并触发扩容if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;while (s >= (long)(sc = sizeCtl) && //元素总数超过阈值sizeCtl,在上次扩容时确定 2n*0.75(tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) { // 未达最大容量// 生成扩容标识int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;// sizeCtl小于0,已有其他线程在扩容if (sc < 0) {// 检查扩容是否已完成或协助线程数已达上限(避免过度竞争)if (sc == rs + MAX_RESIZERS || // 协助线程数是否超限sc == rs + 1 || // 扩容已完成(线程数归零)(nt = nextTable) == null || transferIndex <= 0)break;// 尝试通过 CAS 增加协助线程数(sizeCtl +1)if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 当前无扩容,尝试发起新扩容,SIZECTL 低十六位存储扩容线程数,初始设置为2(= 扩容线程数1 + 1),后续扩容完成则是0+1=1,对应上面 sc == rs + 1 判断扩容是否已完成else if (U.compareAndSwapInt(this, SIZECTL, sc, rs + 2))transfer(tab, null);...}}
}/**(2)树化前,单个哈希桶的链表长度 >= 8,但数组长度 < 64, 优先扩容;
**/
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;if (tab != null) {// 单个哈希桶的链表长度 >= 8,但数组长度 < 64, 优先扩容;if ((n = tab.length) < MIN_TREEIFY_CAPACITY)tryPresize(n << 1);else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {... 树化 ...}}
}// 尝试扩容
private final void tryPresize(int size) {// 计算目标容量(确保是2的幂)int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);int sc;while ((sc = sizeCtl) >= 0) {Node<K,V>[] tab = table; int n;// 哈希表未初始化时先进行初始化if (tab == null || (n = tab.length) == 0) {...}else if (c <= sc || n >= MAXIMUM_CAPACITY)break; // 目标容量 <= 当前阈值 或 已达最大容量,直接退出else if (tab == table) { // 确认当前 table 未被其他线程替换int rs = resizeStamp(n); // 生成扩容唯一标识(与容量相关)if (sc < 0) { // sizeCtl小于0 已有其他线程在扩容Node<K,V>[] nt; // 新表// 校验扩容是否可参与:// 1. 扩容标识是否匹配,防止不同容量扩容冲突// 2. 协助线程数是否超限(sc == rs + 1)// 3. nextTable 是否还在// 4. 是否还有待迁移的桶(transferIndex > 0)if ((sc >>> RESIZE_STAMP_SHIFT) != rs || // 扩容标识是否匹配,防止不同容量扩容冲突sc == rs + 1 || // 扩容已完成(线程数归零)sc == rs + MAX_RESIZERS || // 协助线程数是否超限(nt = nextTable) == null || // nextTable 是否还在transferIndex <= 0) // 是否还有待迁移的桶(transferIndex > 0)break;// CAS操作 增加协助线程数,成功后参与迁移if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 当前无扩容,尝试发起新扩容,SIZECTL 低十六位存储扩容线程数,初始设置为2(= 扩容线程数1 + 1),后续扩容完成则是0+1=1,对应上面 sc == rs + 1 判断扩容是否已完成else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 启动迁移,nextTable 由 transfer 初始化transfer(tab, null); }}
}/** 插入元素时遇到 ForwardingNode,协助扩容、数据迁移;
**/
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;// 检查到:当前表非空,且当前节点为 ForwardingNode(当前为迁移标记节点),且 ForwardingNode 中提取新表 nextTable 不为空,开始协助扩容迁移if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// 传入tab长度,生成唯一标识当前扩容阶段的戳记,避免不同扩容操作混淆(用于区分不同扩容阶段)int rs = resizeStamp(tab.length) << RESIZE_STAMP_SHIFT;// 新/旧数组未被替换,扩容中(sizeCtl 为负数)while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {// 检查扩容是否已完成或协助线程数已达上限(避免过度竞争)if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||transferIndex <= 0)break;// 尝试通过 CAS 增加协助线程数(sizeCtl +1)if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab); // 调用数据迁移方法break;}}return nextTab;}// 若不符合上述if判断,表示没有扩容或者扩容已完成,返回当前 table 即可return table;
}
核心扩容方法,
// 核心扩容逻辑:扩容、迁移数据
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;// static final int NCPU = Runtime.getRuntime().availableProcessors();// 计算每个线程处理的桶区间大小 stride(最小为 MIN_TRANSFER_STRIDE=16)if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 初始化新数组(仅由第一个发起扩容的线程执行) if (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")// 扩容为原来两倍Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;// 迁移起始位置(从最后一个桶开始)transferIndex = n;}// 新数组大小int nextn = nextTab.length;// 创建 ForwardingNode 扩容ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);boolean advance = true; // 标记是否继续分配任务boolean finishing = false; // 标记是否迁移完成// 开始分配任务并迁移数据for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// ------------------------ 不同线程竞争桶区间分配任务 ------------------------while (advance) {int nextIndex, nextBound;// 当前区间未处理完 或 迁移已完成, 退出循环if (--i >= bound || finishing)advance = false;// transferIndex <= 0 无剩余任务,后续退出迁移else if ((nextIndex = transferIndex) <= 0) { // nextIndex 从最后一个桶开始(上述赋值:transferIndex = n)// 标记i=-1i = -1;advance = false;}// CAS竞争任务区间(transferIndex从nextIndex更新为nextBound)else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,// 每个线程处理的桶区间大小 stride,往前推进nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {// 竞争区间 [bound, i] 处理这个区间的扩容迁移任务bound = nextBound;i = nextIndex - 1;advance = false;}}// ------------------------ 迁移完成检查 ------------------------if (i < 0 || i >= n || i + n >= nextn) {int sc;// 最终完成, 更新全局变量if (finishing) { nextTable = null; // 设置 nextTable 为空table = nextTab; // 替换为新数组sizeCtl = (n << 1) - (n >>> 1); // 新阈值(2n * 0.75)return;}// CAS减少协助线程数if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 若自己是最后一个线程,触发最终检查if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;// 设置 finishing为truefinishing = advance = true;i = n; // recheck before commit}}// 对于空桶,标记为已迁移else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);// 跳过已迁移节点else if ((fh = f.hash) == MOVED)advance = true; // already processedelse {// ------------------------ 迁移 ------------------------synchronized (f) {// 锁定当前节点,避免并发修改if (tabAt(tab, i) == f) {// 二次校验防止并发修改Node<K,V> ln, hn;// fh >= 0 处理链表节点if (fh >= 0) { // 通过 runBit 和 lastRun 快速分割链表,避免逐个节点重新散列。// 这里为什么是 fh & n? 详见下述解释int runBit = fh & n; //计算散列位(0或n),判断低位ln还是扩容后的高位hnNode<K,V> lastRun = f;// 遍历链表,找到最后一段连续相同散列位的节点,主要目的是直接复用 lastRun 之后的节点,减少新建节点开销for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}// lastRun 是低位元素if (runBit == 0) {ln = lastRun;hn = null;}// lastRun 是高位元素else {hn = lastRun;ln = null;}// 迁移 lastRun 之前的节点,到 扩容后的高位/原低位for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;// 低位迁移if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}setTabAt(nextTab, i, ln); // 原位isetTabAt(nextTab, i + n, hn); // 偏移i+nsetTabAt(tab, i, fwd); // 标记旧桶为已迁移advance = true;}// 处理树节点(逻辑类似,需考虑树化或链表化)else if (f instanceof TreeBin) {...}}}}}
}
- runBit 为什么是通过
int runBit = fh & n来作为切割依据?
容量是2的幂时,计算key的桶位置是用位操作,即通过 hash & (n-1) 确定的,
假设原容量是n=16,二进制是10000,n-1=1111。此时hash & 1111得到的是0到15的位置。
扩容后的容量是32,二进制是100000,n-1=11111。新的位置是hash & 11111,也就是0到31。
原来的位置是 hash & 1111,而新的位置可能是原来的位置或者原来的位置+16(例如,如果hash的第5位是1的话,如10010,则这个必然在高位)。所以新的位置其实是原位置或者原位置加n。这时候,只需要判断hash的某一位是否为1,就能确定节点应该放在原位还是高位。具体来说,这个位就是n对应的二进制位。
比如,n=16时,二进制是10000,所以检查hash的第5位是否为1,如果是,则新位置是原位置+16,否则保持原位。
ForwardingNode 内部类表示迁移节点,可通过 nextTable访问新数组,
static final class ForwardingNode<K,V> extends Node<K,V> {final Node<K,V>[] nextTable; // 指向新表的引用// 需要指定扩容后的新数组 nextTableForwardingNode(Node<K,V>[] tab) {super(MOVED, null, null, null);this.nextTable = tab;}// 迁移节点查找,访问新数组 nextTableNode<K,V> find(int h, Object k) {// loop to avoid arbitrarily deep recursion on forwarding nodesouter: for (Node<K,V>[] tab = nextTable;;) {Node<K,V> e; int n;if (k == null || tab == null || (n = tab.length) == 0 ||(e = tabAt(tab, (n - 1) & h)) == null)return null;for (;;) {int eh; K ek;if ((eh = e.hash) == h &&((ek = e.key) == k || (ek != null && k.equals(ek))))return e;if (eh < 0) {if (e instanceof ForwardingNode) {tab = ((ForwardingNode<K,V>)e).nextTable;continue outer;}elsereturn e.find(h, k);}if ((e = e.next) == null)return null;}}}
}
(4)put 操作流程
主要流程:
(1)通过 spread 通过原始hash code 计算哈希 hash,让高位16位也参与计算确保哈希均匀分布;
(2)根据Hash查找对应的桶位置 (n - 1) & hash, 若没有冲突直接插入新节点new Node<K,V>(hash, key, value, null);
(3-1)若当前桶位置发生Hash冲突,且fh >= 0表示为链表,遍历链表插入/更新;
(3-2)若当前桶位置发生Hash冲突,且Node为红黑树,调用红黑树插入方法;
(4)判断链表长度是否大于 TREEIFY_THRESHOLD = 8,执行扩容或者链表树化;
(5)统计元素总数并且检查是否超过阈值需要扩容;
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();// (1) 计算哈希, 确保哈希均匀分布int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)...// (2) 定位桶位:(n - 1) & hash 确定数组索引else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// CAS 插入:若桶为空,通过 casTabAt 原子插入新节点if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break;}else if ((fh = f.hash) == MOVED)...else {V oldVal = null;// (3) 同步锁处理冲突:// 若桶非空,使用 synchronized 锁定头节点,遍历链表/红黑树插入或更新值synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) { // (3-1) 链表处理binCount = 1;// 遍历链表插入/更新for (Node<K,V> e = f;; ++binCount) {K ek;// 查找到了key,直接设置返回if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}// 哈希冲突 - 继续遍历链表查找Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) { // (3-2) 调用红黑树插入方法Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)// 树化treeifyBin(tab, i);if (oldVal != null)// put 返回旧值return oldVal;break;}}}// 增/减总数统计addCount(1L, binCount);return null;
}private final void addCount(long x, int check) {CounterCell[] as; long b, s;if ((as = counterCells) != null ||// 尝试无竞争更新 baseCount!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {// 若 counterCells 已初始化或 CAS更新 baseCount 失败, 都说明已存在竞争CounterCell a; long v; int m;boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 || // CounterCell数组未初始化(a = as[ThreadLocalRandom.getProbe() & m]) == null || // 当前线程的Cell未分配(ThreadLocalRandom.getProbe():获取当前线程的哈希码,用于在 CounterCell 数组中选择一个槽位,减少不同线程竞争同一Cell的概率)!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {// CAS更新Cell值失败// 初始化Cell、扩容Cell数组等fullAddCount(x, uncontended);return;}if (check <= 1)return;s = sumCount();}if (check >= 0) {... 检查并扩容逻辑 ...s = sumCount();...}
}
baseCount 是基础的计数器变量,但在高并发下频繁 CAS 更新会导致性能问题(可能导致U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x) 频繁失败),因此引入 CounterCell 数组分散线程竞争。
例如,在jdk8的时候是有引入一个类Striped64,其中LongAdder和DoubleAdder就是对这个类的实现。这两个方法都是为解决高并发场景而生的。(是AtomicLong的加强版,AtomicLong在高并发场景性能会比LongAdder差。但是LongAdder的空间复杂度会高点)
ConcurrentHashMap 高并发下更新元素计数 的核心方法 fullAddCount 借鉴了 LongAdder 的分段计数思想,避免所有线程竞争同一变量,分散到不同 CounterCell 槽位,减少 CAS 冲突。主要流程:
(1)未初始化counterCells数组,cas加锁初始化数组并插入新的 CounterCell(x) ;
(2-1)已初始化,若线程probe对应槽位上为空,cas加锁插入新的 CounterCell(x)**;
(2-2)已初始化,若线程probe对应槽位上不为空,cas加锁更新 CounterCell(x) 计数;
(3)若(2-2)更新失败表示存在冲突 collide=true,翻倍扩容数组,最大容量为 NCPU(与CPU核心数对齐);
(4)兜底策略 - 当 CounterCell 初始化或扩容失败时,回退到无锁更新 baseCount;
// 设计借鉴了 LongAdder 的分段计数思想,通过分散竞争来优化性能
private final void fullAddCount(long x, boolean wasUncontended) {int h; // 当前线程的 probe(哈希值),用于定位 CounterCell 数组的槽位,减少竞争// probe未初始化,强制初始化if ((h = ThreadLocalRandom.getProbe()) == 0) {ThreadLocalRandom.localInit(); // force initializationh = ThreadLocalRandom.getProbe();wasUncontended = true;}boolean collide = false; // 标记槽位是否冲突(是否需要扩容)for (;;) {CounterCell[] as; CounterCell a; int n; long v;// counterCells数组已初始化if ((as = counterCells) != null && (n = as.length) > 0) {// (1) CounterCell数组对应位置槽位为空,尝试创建新Cell(初始值为x)并插入数组if ((a = as[(n - 1) & h]) == null) { // 当前槽位为空if (cellsBusy == 0) { // cellsBusy == 0 无其他线程在修改数组// 创建CounterCellCounterCell r = new CounterCell(x); if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { // CAS加锁 CELLSBUSYboolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;if ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r; // 插入新CounterCell created = true;}} finally {cellsBusy = 0; // 释放锁 CELLSBUSY}if (created)break;continue; // Slot is now non-empty}}collide = false;}else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehashelse if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) // CAS更新Cell值+xbreak;else if (counterCells != as || n >= NCPU) // 数组已扩容或达到数量上限collide = false; // 无需继续扩容 else if (!collide)collide = true; // 上面cas更新 CELLVALUE 失败,标记冲突,下次循环可能触发扩容else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { // CAS加锁扩容try {if (counterCells == as) {// 数组未被其他线程修改CounterCell[] rs = new CounterCell[n << 1];// 容量翻倍for (int i = 0; i < n; ++i) // 逐个复制旧元素rs[i] = as[i];counterCells = rs;// 更新新的CounterCell数组}} finally {cellsBusy = 0;// 释放锁 CELLSBUSY}collide = false;// 重置冲突标志continue; // Retry with expanded table}h = ThreadLocalRandom.advanceProbe(h); // 更新线程哈希值 probe,减少后续冲突}// counterCells数组未初始化,初始化CounterCell并插入else if (cellsBusy == 0 && counterCells == as &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {// cas加锁boolean init = false;try { // Initialize tableif (counterCells == as) {CounterCell[] rs = new CounterCell[2];// 初始容量为2rs[h & 1] = new CounterCell(x);counterCells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}// 兜底策略:当 CounterCell 初始化或扩容失败时,回退到无锁更新 baseCountelse if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))break; // Fall back on using base}
}
(5)计数 size
将全局计数(baseCount)和分片计数(CounterCell 数组)结合。
/**返回 int 类型,最大值为 Integer.MAX_VALUE
**/
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}/**ConcurrentHashMap-only methods支持返回 long 类型,推荐优先使用
**/
public long mappingCount() {long n = sumCount();return (n < 0L) ? 0L : n; // ignore transient negative values
}/*** 遍历 CounterCell 数组,累加所有单元格的值到 baseCount,得到当前总元素数 s
**/
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
(6)get 操作
- 无锁读取:依赖
volatile修饰的Node.val和Node.next保证可见性 - 扩容兼容性:若遇到
ForwardingNode,通过其find()方法在新数组中查找数据
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {if ((eh = e.hash) == h) {// 头节点匹配直接返回if ((ek = e.key) == key || (ek != null && key.equals(ek)))// 无锁读取return e.val;}// 处理特殊节点(如红黑树或 ForwardingNode)else if (eh < 0)// 调用红黑树或扩容节点的查找逻辑return (p = e.find(h, key)) != null ? p.val : null;// 头节点不匹配,链表读取while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))// 命中链表中的某个节点return e.val;}}return null;
}
(7)remove 操作
主要流程:
(1)通过 spread 通过原始hash code 计算哈希 hash,让高位16位也参与计算确保哈希均匀分布;
(2)根据Hash查找对应的桶位置 (n - 1) & hash, 若没有返回 null;
(3)若当前桶位置正在扩容,协助迁移数据helpTransfer后重试;
(4)加锁处理链表/树,匹配键值,删除节点;
(5)更新元素总数-1;
public V remove(Object key) {return replaceNode(key, null, null);
}/*** Implementation for the four public remove/replace methods:* Replaces node value with v, conditional upon match of cv if* non-null. If resulting value is null, delete.* cv: 非 null 时,只有旧值匹配 cv 时才操作*/
final V replaceNode(Object key, V value, Object cv) {int hash = spread(key.hashCode());for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 若表未初始化或桶为空,直接退出if (tab == null || (n = tab.length) == 0 ||(f = tabAt(tab, i = (n - 1) & hash)) == null)break;// 若桶正在扩容(MOVED状态),协助扩容后重试else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;boolean validated = false;// 加锁处理链表或树synchronized (f) {if (tabAt(tab, i) == f) {// 链表处理if (fh >= 0) {validated = true;for (Node<K,V> e = f, pred = null;;) {K ek;// 匹配键值if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {V ev = e.val;// cv若非空判断cv是否匹配if (cv == null || cv == ev ||(ev != null && cv.equals(ev))) {oldVal = ev;if (value != null)e.val = value;// 替换值else if (pred != null)pred.next = e.next;// 删除中间节点elsesetTabAt(tab, i, e.next);// 删除头节点}break;}pred = e;if ((e = e.next) == null)break;}}// 树处理逻辑else if (f instanceof TreeBin) {validated = true;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(hash, key, null)) != null) {V pv = p.val;if (cv == null || cv == pv ||(pv != null && cv.equals(pv))) {oldVal = pv;if (value != null)p.val = value;else if (t.removeTreeNode(p))setTabAt(tab, i, untreeify(t.first));}}}}}// 操作处理完成后,if (validated) {if (oldVal != null) {if (value == null)addCount(-1L, -1); // 若是删除,更新元素计数-1return oldVal;}break;}}}return null;
}
(8)遍历操作
以遍历键值对 entrySet 举例,keySet() 与 values() 同理,
public Set<Map.Entry<K,V>> entrySet() {EntrySetView<K,V> es;return (es = entrySet) != null ? es : (entrySet = new EntrySetView<K,V>(this));
}
EntrySetView 的迭代器(EntryIterator)是弱一致性的,允许遍历过程中其他线程并发修改数据,不会抛出 ConcurrentModificationException。
弱一致性体现:Traverser 在初始化或恢复状态时,保存的是遍历开始时的哈希表引用(tab)。即使其他线程触发了扩容(生成新表更新了table),迭代器仍可能继续遍历旧表的部分数据,直到遇到 ForwardingNode 才会切换到新表。这意味着遍历结果可能是新旧表的混合视图。
static final class EntrySetView<K,V> extends CollectionView<K,V,Map.Entry<K,V>>implements Set<Map.Entry<K,V>>, java.io.Serializable {private static final long serialVersionUID = 2249069246763182397L;// 初始化会保存ConcurrentHashMap的引用EntrySetView(ConcurrentHashMap<K,V> map) { super(map); }.../*** @return an iterator over the entries of the backing map*/public Iterator<Map.Entry<K,V>> iterator() {ConcurrentHashMap<K,V> m = map;Node<K,V>[] t;int f = (t = m.table) == null ? 0 : t.length;return new EntryIterator<K,V>(t, f, 0, f, m);}...
}
迭代器实现:
// entry迭代器,继承自 EntryIterator -> BaseIterator -> Traverser
static final class EntryIterator<K,V> extends BaseIterator<K,V>implements Iterator<Map.Entry<K,V>> {EntryIterator(Node<K,V>[] tab, int index, int size, int limit,ConcurrentHashMap<K,V> map) {super(tab, index, size, limit, map);}/**next 实现**/public final Map.Entry<K,V> next() {Node<K,V> p;if ((p = next) == null)throw new NoSuchElementException();K k = p.key;V v = p.val;lastReturned = p;advance();return new MapEntry<K,V>(k, v, map);}
}// 进入父类 Traverser, Traverser 是用于 并发安全遍历哈希表 的核心内部类,实现了推进数组遍历的方法 advance
static class Traverser<K,V> {Node<K,V>[] tab; // 当前遍历的哈希表(可能在遍历过程中切换到扩容后的新表)Node<K,V> next; // 当前遍历到的节点,用于链式推进。TableStack<K,V> stack, spare; // stack 保存遍历状态的栈(用于处理 ForwardingNode 跳转到新表的情况)int index; // 当前遍历的桶索引(动态调整,可能跨新旧表)int baseIndex; // 初始表的起始索引int baseLimit; // 初始表的结束索引final int baseSize; // 初始表的容量Traverser(Node<K,V>[] tab, int size, int index, int limit) {this.tab = tab;this.baseSize = size;this.baseIndex = this.index = index;this.baseLimit = limit;this.next = null;}/*** 推进遍历(1)若当前节点是链表或树节点,直接移动到下一个节点。(2)若遇到 ForwardingNode,切换到新表并保存旧表状态到栈。(3)恢复状态:当新表遍历到边界时,弹出栈顶状态,恢复旧表的遍历。(4)跨段遍历:通过 index += baseSize 实现逻辑分片遍历,避免遗漏旧表数据。*/final Node<K,V> advance() {Node<K,V> e;if ((e = next) != null)e = e.next; // 移动到链表/树的下一个节点for (;;) {Node<K,V>[] t; int i, n; // must use locals in checksif (e != null)return next = e; // 更新next为当前节点,并返回// 遍历完成或表为空,返回nulif (baseIndex >= baseLimit || (t = tab) == null ||(n = t.length) <= (i = index) || i < 0)return next = null;// hash小于0,处理特殊节点(ForwardingNode / TreeBin)if ((e = tabAt(t, i)) != null && e.hash < 0) {if (e instanceof ForwardingNode) {tab = ((ForwardingNode<K,V>)e).nextTable;// tab 切换到新表e = null;pushState(t, i, n); // 保存当前表的状态到栈continue;// 重新循环处理新表}else if (e instanceof TreeBin)e = ((TreeBin<K,V>)e).first;// 获取树的第一个节点elsee = null;}if (stack != null)recoverState(n); // 弹出栈顶状态,恢复旧表遍历else if ((index = i + baseSize) >= n)index = ++baseIndex; // visit upper slots if present}}/*** 遇到 ForwardingNode 时,将当前表的遍历状态(表引用、索引、容量)压入栈,以便后续恢复*/private void pushState(Node<K,V>[] t, int i, int n) {TableStack<K,V> s = spare; // reuse if possibleif (s != null)spare = s.next;elses = new TableStack<K,V>();s.tab = t;// 旧数组s.length = n;// 旧数组长度s.index = i;// 当前遍历的索引s.next = stack;stack = s;// 更新栈顶}/*** 当新表遍历完成后,从栈中弹出旧表状态,恢复索引和表引用,继续遍历旧表的剩余部分** @param n length of current table*/private void recoverState(int n) {TableStack<K,V> s; int len;while ((s = stack) != null && (index += (len = s.length)) >= n) {n = len;index = s.index;tab = s.tab;s.tab = null;TableStack<K,V> next = s.next;s.next = spare; // save for reusestack = next;spare = s;}if (s == null && (index += baseSize) >= n)index = ++baseIndex;}
}
基于源码总结一些使用注意事项
(1)ConcurrentHashMap 明确禁止 null 键和值,使用时会直接抛出 NullPointerException;
(2)size():返回 int,可能溢出(当键值对超过 Integer.MAX_VALUE 时),推荐优先使用mappingCount()。注意计数均为近似值,高并发情况下不保证绝对精确;
(3)根据场景调整好初始容量和负载因子,避免频繁扩容(触发 transfer 方法重组数据、扩容期间会产生更多CPU时间片占用以及内存占用);
(4)ConcurrentHashMap 是弱一致性的迭代器**,** 迭代器不保证实时反映所有并发修改,并发修改也不会抛出异常,因此最终迭代的结果可能包含了新旧数据两部分。
相关文章:
)
ConcurrentHashMap从源码总结使用注意事项(源码)
ConcurrentHashMap实现原理 目录 ConcurrentHashMap实现原理核心源码解读(1)数据结构: 采用数组链表/红黑树(2)初始化(3)并发扩容(4)put 操作流程(5)计数 siz…...
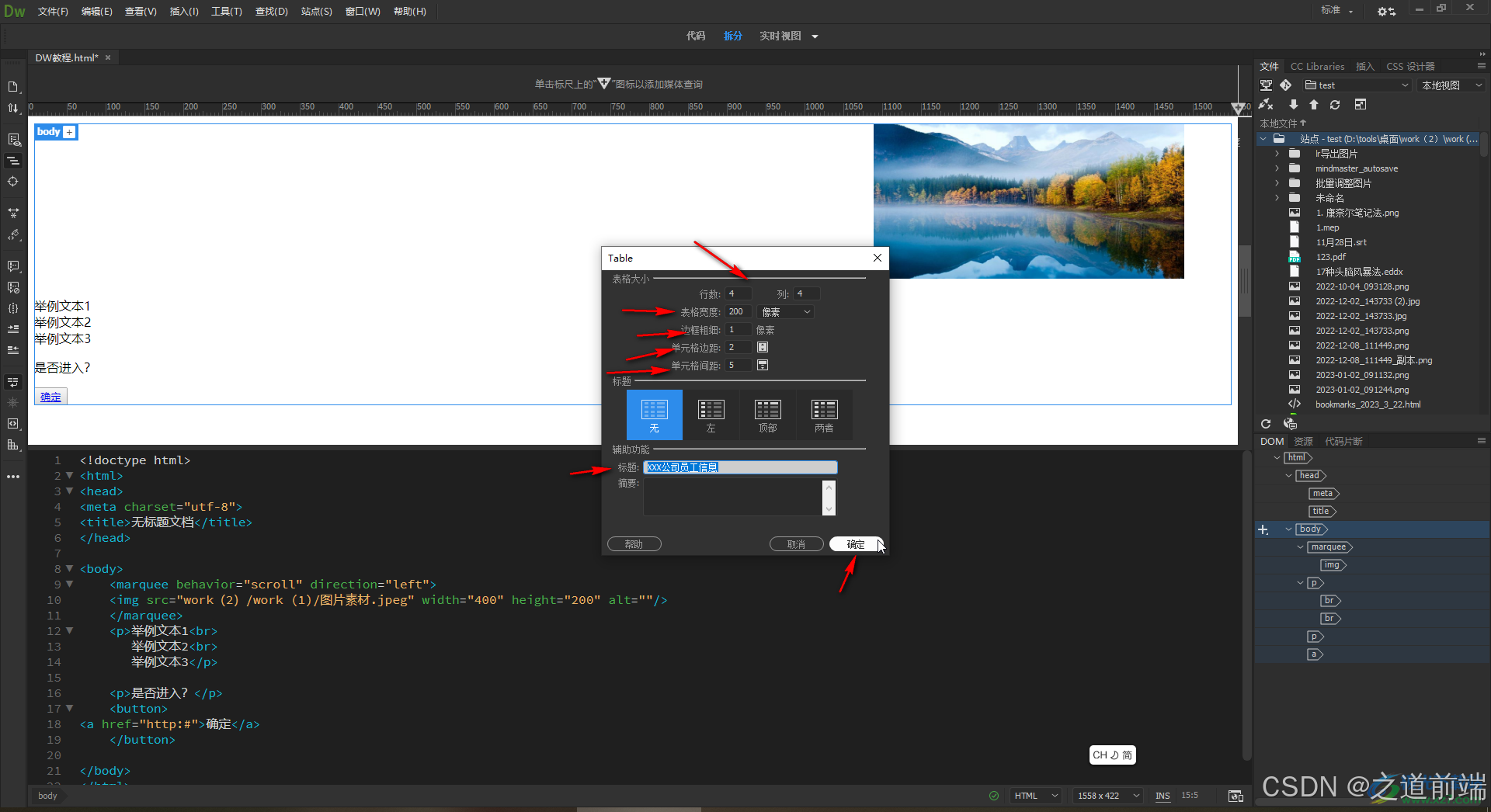
前端 UI 框架发展史
上一小节我们了解了前端 UI 框架的作用和意义,接下来我们再来了解前端 UI 框架的发展历史。 虽然是讲历史,但我不想讲得太复杂,也不打算搞什么编年史记录啥的,毕竟我们不是来学历史的。 我会简单描述一下前端 UI 框架的发展历程…...
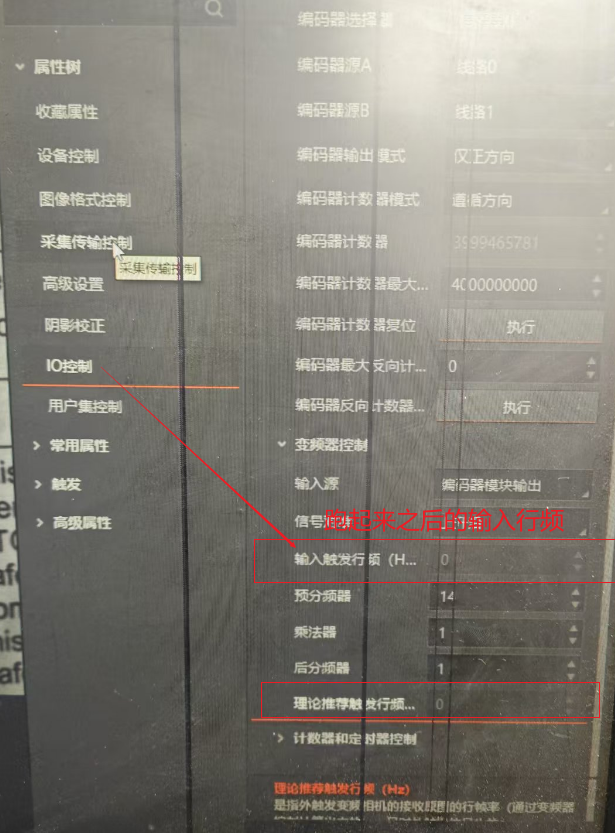
【工控】线扫相机小结 第五篇
背景介绍 线扫相机通过光栅尺的脉冲触发, 我在调试线扫过程中,发现图像被拉伸,预设调节分配器。图像正常后,我提高的相机的扫描速度(Y轴动的更快了)。 动的更快的发现,图像变短了(以…...

AI与SEO关键词智能解析
内容概要 人工智能技术正重塑搜索引擎优化的底层逻辑,其核心突破体现在关键词解析维度的结构性升级。通过机器学习算法对海量搜索数据的动态学习,AI不仅能够识别传统TF-IDF模型中的高频词汇,更能捕捉语义网络中隐含的关联特征。下表展示了传…...
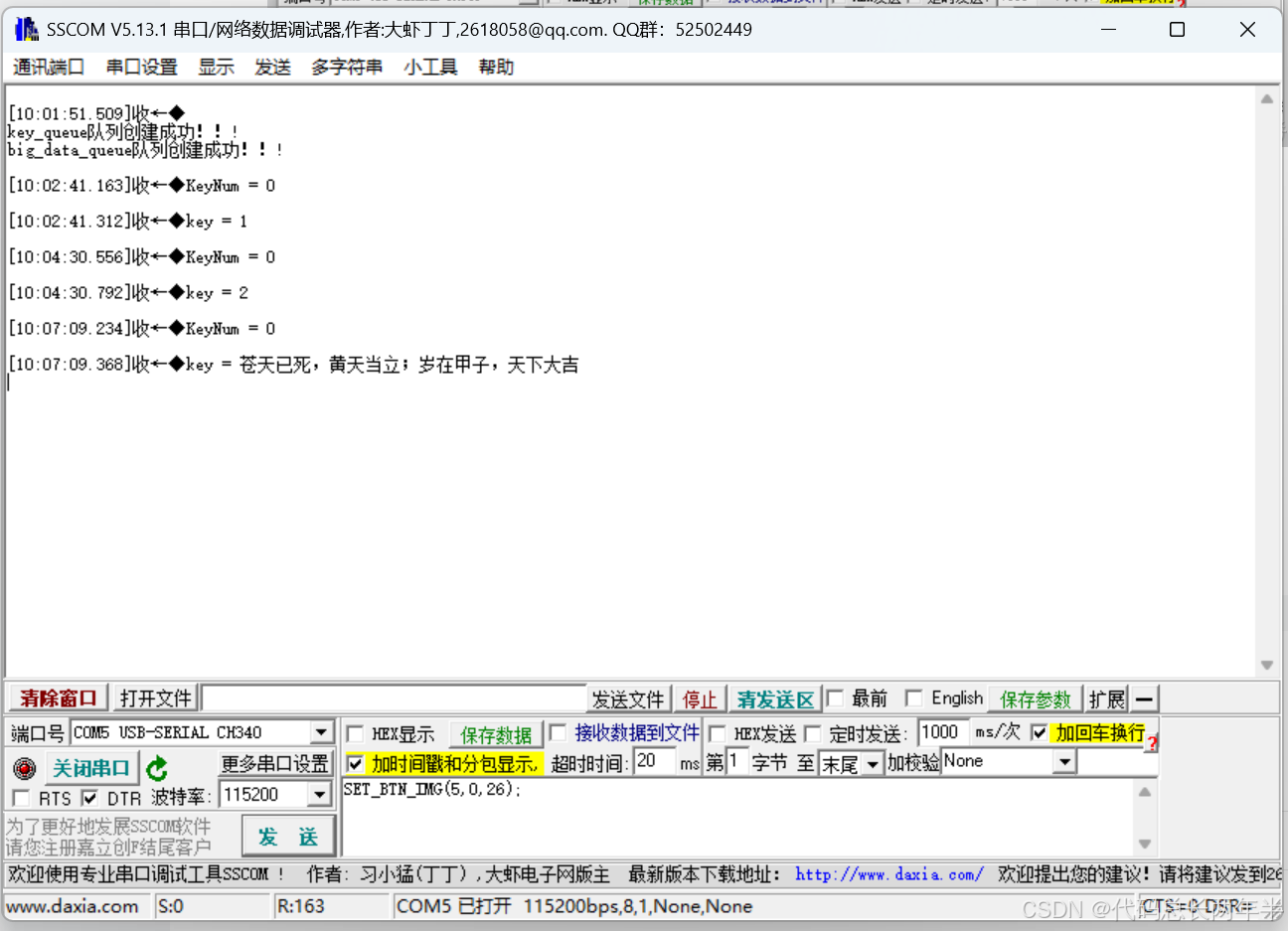
STM32---FreeRTOS消息队列
一、简介 1、队列简介: 队列:是任务到任务,任务到中断、中断到任务数据交流的一种机制(消息传递)。 FreeRTOS基于队列,实现了多种功能,其中包括队列集、互斥信号量、计数型信号量、二值信号量…...

开关模式电源转换器 EMI/EMC 的集成仿真
介绍 在电力电子领域,电磁干扰 (EMI) 和电磁兼容性 (EMC) 问题可以决定设计的成败。开关模式电源转换器虽然高效且紧凑,但却是电磁噪声的常见来源,可能会对附近的组件和系统造成严重破坏。随着…...
)
Java虚拟机之垃圾收集(一)
目录 一、如何判定对象“生死”? 1. 引用计数算法(理论参考) 2. 可达性分析算法(JVM 实际使用) 3. 对象的“缓刑”机制 二、引用类型与回收策略 三、何时触发垃圾回收? 1. 分代回收策略 2. 手动触发…...

linux---天气爬虫
代码概述 这段代码实现了一个天气查询系统,支持实时天气、未来天气和历史天气查询。用户可以通过终端菜单选择查询类型,并输入城市名称来获取相应的天气信息。程序通过 TCP 连接发送 HTTP 请求,并解析返回的 JSON 数据来展示天气信息。 #in…...

字节顺序(大小端序)
在弄明白字节顺序之前先了解一下一些基础概念. 基础概念 字节(byte): 字节是计算机中数据处理的基本单位,通常由8个位组成,即1字节等于8位。一个字节可以存储一个ASCII码,两个字节可以存放一个汉字国标…...

可复用的 Vue 轮播图组件
大家好,今天我想和大家分享一下如何开发一个通用的 Vue 轮播图组件。轮播图在各种网站中都很常见,无论是展示产品、活动还是文章,都能派上用场。我们今天要实现的这个组件会具备良好的可配置性和易用性,同时保证代码的可维护性。 …...

AI编程: 一个案例对比CPU和GPU在深度学习方面的性能差异
背景 字节跳动正式发布中国首个AI原生集成开发环境工具(AI IDE)——AI编程工具Trae国内版。 该工具模型搭载doubao-1.5-pro,支持切换满血版DeepSeek R1&V3, 可以帮助各阶段开发者与AI流畅协作,更快、更高质量地完…...

Linux红帽:RHCSA认证知识讲解(五)从红帽和 DNF 软件仓库下载、安装、更新和管理软件包
Linux红帽:RHCSA认证知识讲解(五)从红帽和 DNF 软件仓库下载、安装、更新和管理软件包 前言一、DNF 软件包管理基础1.1 核心操作命令安装软件包卸载软件包重新安装软件包 1.2 软件仓库原理 二、配置自定义软件仓库步骤 1:清理默认…...

云上特权凭证攻防启示录:从根账号AK泄露到安全体系升级的深度实践
事件全景:一场持续17分钟的云上攻防战 2025年3月9日15:39,阿里云ActionTrail日志突现异常波纹——根账号acs:ram::123456789:root(已脱敏)从立陶宛IP(164.92.91.227)发起高危操作。攻击者利用泄露的AccessKey(AK)在17分钟内完成侦察→提权→持久化攻击链,完整操作序列…...

从3b1b到课堂:教育3D化的理想与现实鸿沟
从3b1b到课堂:教育3D化的理想与现实鸿沟 3Blue1Brown(3b1b)凭借精妙的三维动画与直观的知识可视化,重新定义了数学教育的可能性。然而,当前教育实践中,3D技术的渗透仍显不足,多数课堂停留在平面…...

FPGA入门教程
引言 FPGA(Field-Programmable Gate Array,现场可编程门阵列)是一种灵活且强大的硬件设备,广泛应用于数字电路设计、信号处理、嵌入式系统等领域。与传统的ASIC(专用集成电路)不同,FPGA允许用户…...

Liunx系统 : 进程间通信【IPC-Shm共享内存】
文章目录 System V共享内存创建共享内存shmget 控制共享内存shmctl shm特性 System V System V是Liunx中的重要的进程间通信机制,它包括(shm)共享内存,(msg)消息队列和(sem)信号量。…...

KafkaRocketMQ
Kafka 消息生产与消费流程 1. 消息生产 生产者创建消息: 指定目标 Topic、Key(可选)、Value。可附加 Header 信息(如时间戳、自定义元数据)。 选择分区(Partition): 若指定 Key&am…...

HarmonyOS Next 中的状态管理
在声明式UI编程框架中,UI是程序状态的运行结果,用户构建了一个UI模型,其中应用的运行时的状态是参数。当参数改变时,UI作为返回结果,也将进行对应的改变。这些运行时的状态变化所带来的UI的重新渲染,在ArkU…...

基于qiime2的16S数据分析全流程:从导入数据到下游分析一条龙
目录 创建metadata 把数据导入qiime2 去除引物序列 双端合并 (dada2不需要) 质控 (dada2不需要) 使用deblur获得特征序列 使用dada2生成代表序列与特征表 物种鉴定 可视化物种鉴定结果 构建进化树(ITS一般不构建进化树…...
)
【软件测试开发】:软件测试常用函数1.0(C++)
1. 元素的定位 web⾃动化测试的操作核⼼是能够找到⻚⾯对应的元素,然后才能对元素进⾏具体的操作。 常⻅的元素定位⽅式⾮常多,如id,classname,tagname,xpath,cssSelector 常⽤的主要由cssSelector和xpath…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...