分布式消息队列Kafka(三)- 服务节点Broker
1.Kafka Broker 工作流程
(1)zookeeper中存储的kafka信息
1)启动 Zookeeper 客户端。
[zrclass@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
2)通过 ls 命令可以查看 kafka 相关信息。
[zk: localhost:2181(CONNECTED) 2] ls /kafka

(2)Kafka中两种Leader的概念
kafka集群中有2个种leader,一种是broker的leader即controller leader,还有一种就是partition中的副本的leader
1)Controller leader
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这些每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader
2) Replication leader
为了实现高可用,保证集群中的某个节点发生故障时,且节点上的partition 数据不丢失且kafka能正常提供服务,kafka提供副本机制,topic内的每个分区可以设置若干个副本(包含leader和follower); 消息的读写只会发生在leader副本上。
(3)Kafka Broker 总体工作流程

(4)模拟 Kafka 上下线,Zookeeper中数据变化
1)查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids [0, 1, 2]
2)查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller {"version":1,"brokerid":0,"timestamp":"1637292471777"}
3)查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state {"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18," isr":[0,1,2]}
4)停止 hadoop104 上的 kafka。
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
5)再次查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/ids [0, 1]
6)再次查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller {"version":1,"brokerid":0,"timestamp":"1637292471777"}
7)再次查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state {"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18," isr":[0,1]}
(5)Broker重要参数


2.kafka副本
(1)Kafka 副本作用:提高数据可靠性。
(2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会 增加磁盘存储空间,增加网络上数据传输,降低效率。
(3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
(4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR, In-Sync Replicas (同步副本集 ),表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR, ( Out-Sync Relipcas ),表示 Follower 与 Leader 副本同步时,延迟过多的副本。
3.kafka分区副本的选举流程
(1)Kafka选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群 broker 的上下线,所有 topic 的分区副本分配和副本 Leader 选举等工作。 Controller 的信息同步工作是依赖于 Zookeeper 的。

(2)模拟kafka的Follewer和Leader故障
1)创建一个新的 topic,4 个分区,4 个副本
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --topic test --partitions 4 --replication-factor 4
Created topic test.
2)查看 Leader 分布情况
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 3 Replicas: 3,0,2,1 Isr: 3,0,2,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,1,2
Topic: test Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0,3
3)停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR
[zrclass@hadoop105 kafka]$ bin/kafka-server-stop.sh
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,2,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,0
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,2
Topic: test Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0
4)停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况
如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR
[zrclass@hadoop104 kafka]$ bin/kafka-server-stop.sh
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1
Topic: test Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0
5)启动 hadoop105 的 kafka 进程,并查看 Leader 分区情况
Follower重新向leader发送通信请求或同步数据,Follower重新加入到ISR
[zrclass@hadoop105 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3
Topic: test Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3
6)启动 hadoop104 的 kafka 进程,并查看 Leader 分区情况
Follower重新向leader发送通信请求或同步数据,Follower重新加入到ISR
[zrclass@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3,2
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3,2
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3,2
Topic: test Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3,2
7)停止掉 hadoop103 的 kafka 进程,并查看 Leader 分区情况
Leader 发生故障之后,就会从 ISR 中选举新的 Leader,按照AR(分区中所有副本)的排列顺序轮询,即控制台中Replicas所展示的顺序轮询
[zrclass@hadoop103 kafka]$ bin/kafka-server-stop.sh
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
Topic: test TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,3,2
Topic: test Partition: 1 Leader: 2 Replicas: 1,2,3,0 Isr: 0,3,2
Topic: test Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,2
Topic: test Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 0,3,2
(3)Leader 和 Follower 故障处理细节
1)Follower故障处理细节

2)Leader故障处理细节

(4)kafka分区副本的分配
如果 kafka 服务器只有 4 个节点,那么设置 kafka 的分区数大于服务器台数,在 kafka
底层如何分配存储副本呢?
1)创建 16 分区,3 个副本
创建一个新的 topic,名称为 second。
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 16 --replication-factor 3 --topic second
查看分区和副本情况。
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic second
Topic: second4 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 2 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 3 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
Topic: second4 Partition: 4 Leader: 0 Replicas: 0,2,3 Isr: 0,2,3
Topic: second4 Partition: 5 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: second4 Partition: 6 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: second4 Partition: 7 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: second4 Partition: 8 Leader: 0 Replicas: 0,3,1 Isr: 0,3,1
Topic: second4 Partition: 9 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: second4 Partition: 10 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: second4 Partition: 11 Leader: 3 Replicas: 3,2,0 Isr: 3,2,0
Topic: second4 Partition: 12 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 13 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 14 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 15 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
总结
1.kafka的副本数量不能大于broker节点数量。kafka的副本数量和HDFS的副本数量是有区别的。(1)HDFS的副本数量表示为最大副本数量,当DataNode节点数量小于设置的副本数量时没有任何问题,当新增DataNode时候如果副本数量没达到要求会自动复制副本。(2)而kafka的副本数量表示为该topic的副本数量,当副本数量大于broker节点数量时会报错,这是因为分区是以目录存储在各个broker节点的data目录下,命名为:topicName-分区编号。当副本数量大于broker节点时就表示在同一个Broker节点的data目录下有两个一样的文件夹,这是不允许的。
2.kafka的分区数量可以大于broker节点数量,当分区数量大于broker节点数量时,在broker节点的data目录下会有同一个topic的两个分区的数据,如:topicName-0,topicName-1。(5)手动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:创建一个新的topic,4个分区,两个副本,名称为three。将 该topic的所有副本都存储到broker0和broker1两台服务器上。

手动调整分区副本存储的步骤如下:
1)创建一个新的 topic,名称为 three。
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 4 --replication-factor 2 --topic three
2)查看分区副本存储情况。
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic three
3)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
[zrclass@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[
{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}
]
}
4)执行副本存储计划。
[zrclass@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
5)验证副本存储计划。
[zrclass@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
6)查看分区副本存储情况。
[zrclass@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic three
4.kafka文件存储
(1)topic数据存储机制
Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数 据。Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制, 将每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该 文件夹的命名规则为:topic名称+分区序号,例如:first-0。

(2)topic数据存储位置
1)启动生产者,并发送消息。
[zrclass@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first\>hello world
2)查看 hadoop102(或者 hadoop103、hadoop104)的/opt/module/kafka/datas/first-1 (first-0、first-2)路径上的文件。
[zrclass@hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
3)直接查看 log 日志,发现是乱码。
[zrclass@hadoop104 first-1]$ cat 00000000000000000092.log CYnF|©|©ÿÿÿÿÿÿÿÿÿÿÿÿÿÿ"hello world
4)通过工具查看 index 和 log 信息。
[zrclass@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index Dumping ./00000000000000000000.index
offset: 3 position: 152[zrclass@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.logDumping datas/first-0/00000000000000000000.log
Starting offset: 0baseOffset: 0 lastOffset: 1 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1636338440962 size: 75 magic: 2 compresscodec: none crc: 2745337109 isvalid: truebaseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 75 CreateTime: 1636351749089 size: 77 magic: 2 compresscodec: none crc: 273943004 isvalid: truebaseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 152 CreateTime: 1636351749119 size: 77 magic: 2 compresscodec: none crc: 106207379 isvalid: truebaseOffset: 4 lastOffset: 8 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 229 CreateTime: 1636353061435 size: 141 magic: 2 compresscodec: none crc: 157376877 isvalid: truebaseOffset: 9 lastOffset: 13 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 370 CreateTime: 1636353204051 size: 146 magic: 2 compresscodec: none crc: 4058582827 isvalid: true
(3)index文件和log文件详解

相关文章:
分布式消息队列Kafka(三)- 服务节点Broker
1.Kafka Broker 工作流程 (1)zookeeper中存储的kafka信息 1)启动 Zookeeper 客户端。 [zrclasshadoop102 zookeeper-3.5.7]$ bin/zkCli.sh 2)通过 ls 命令可以查看 kafka 相关信息。 [zk: localhost:2181(CONNECTED) 2]…...

蠕动泵说明书_RDB
RDB_2T-S蠕 动 泵 概述 蠕动灌装泵是一种高性能、高质量的泵。采用先进的微处理技术及通讯方式做成的控制器和步进电机驱动器,配以诚合最新研制出的泵头,使产品在稳定性、先进性和性价比上达到一个新的高度。适用饮料、保健品、制药、精细化工等诸流量…...

浅谈react如何自定义hooks
react 自定义 hooks 简介 一句话:使用自定义hooks可以将某些组件逻辑提取到可重用的函数中。 自定义hooks是一个从use开始的调用其他hooks的Javascript函数。 下面以一个案例: 新闻发布操作,来简单说一下react 自定义 hooks。 不使用自定义hooks时 …...
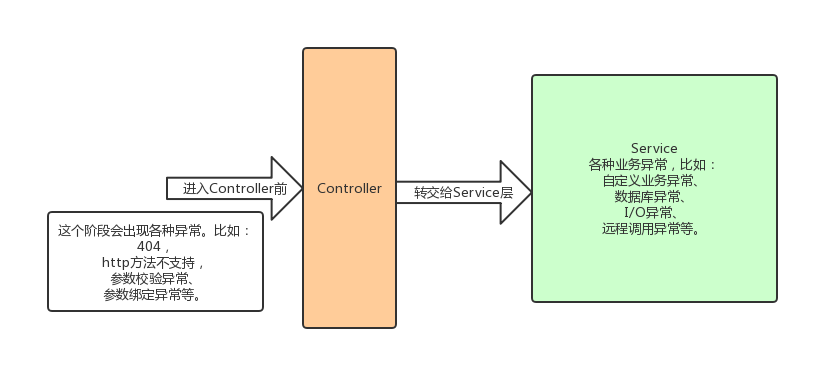
如何优雅的写个try catch的方式!
软件开发过程中,不可避免的是需要处理各种异常,就我自己来说,至少有一半以上的时间都是在处理各种异常情况,所以代码中就会出现大量的try {...} catch {...} finally {...} 代码块,不仅有大量的冗余代码,而…...
海尔智家:智慧场景掌握「主动」权,用户体验才有话语权
2023年1月,《福布斯》AI专栏作家Rob Toews发布了年度AI发展预测,指出人工智能的发展将带来涉及各行业、跨学科领域的深远影响。变革将至,全球已掀起生成式AI热,以自然语言处理为代表的人工智能技术在快速进化,积极拥抱…...

基于铜锁,在前端对登录密码进行加密,实现隐私数据保密性
本文将基于 铜锁(tongsuo)开源基础密码库实现前端对用户登录密码的加密,从而实现前端隐私数据的保密性。 首先,铜锁密码库是一个提供现代密码学算法和安全通信协议的开源基础密码库,在中国商用密码算法,例…...

LVS的小总结
LVS的工作模式及其工作过程: LVS 有三种负载均衡的模式,分别是VS/NAT(nat 模式)、VS/DR(路由模式)、VS/TUN(隧道模式)。 1、NAT模式(NAT模式) 原理&#x…...
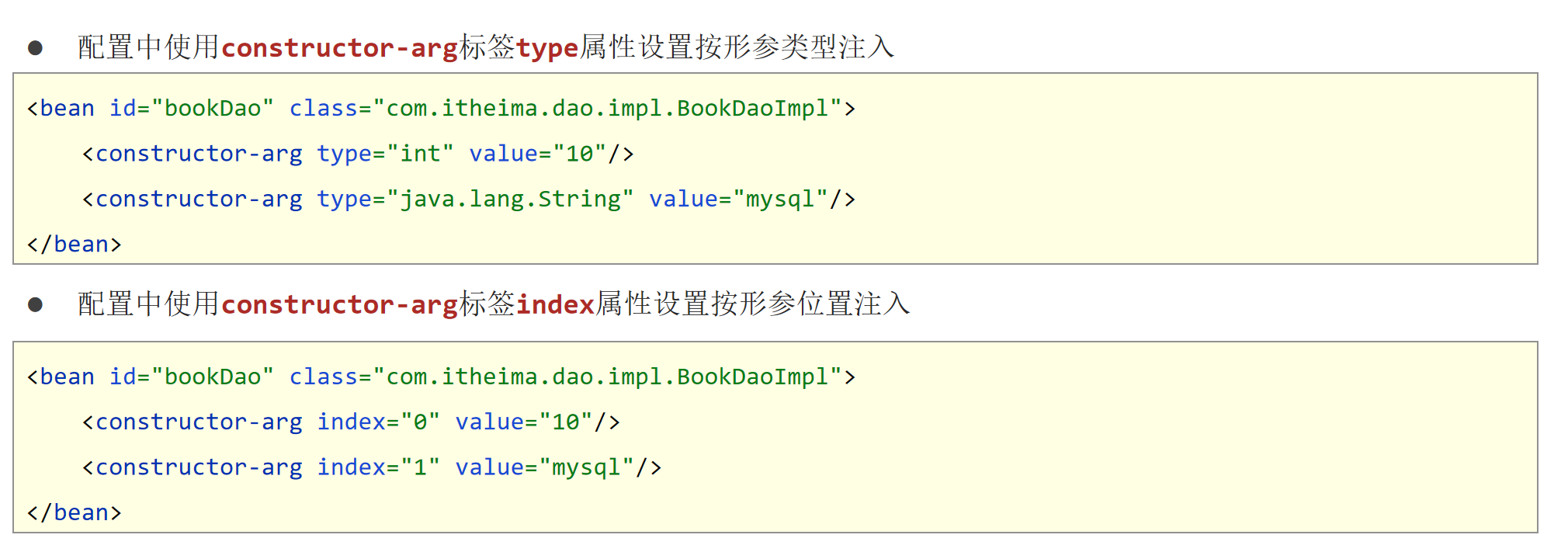
Spring依赖注入(DI配置)
Spring依赖注入 1. 依赖注入方式【重点】1.1 依赖注入的两种方式1.2 setter方式注入问题导入引用类型简单类型 1.3 构造方式注入问题导入引用类型简单类型参数适配【了解】 1.4 依赖注入方式选择 2. 依赖自动装配【理解】问题导入2.1 自动装配概念2.2 自动装配类型依赖自动装配…...
绘声绘影2023简体中文版新功能介绍
会声会影是一款专业的数字音频工作站软件,它提供强大的音频编辑和制作功能,被广泛应用于音乐创作、录音棚录制以及现场演出等领域。会声会影的最新版本会声会影2023将于2022年底发布,主要功能和新功能详述如下: 会声会影2023主要功能: 1. 直观易用的界面:会声会影采用简洁而不…...

一个好的前端开发人员必须掌握的前端代码整洁与开发技巧
前端代码整洁与开发技巧 为保证前端人员在团队项目开发过程中的规范化、统一化,特建立《前端代码整洁与开发技巧》文档,通过代码简洁推荐、开发技巧推荐等章节来帮助我们统一代码规范和编码风格,从而提升项目的可读性和可维护性。 目录 …...

【别再困扰于LeetCode接雨水问题了 | 从暴力法=>动态规划=>单调栈】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
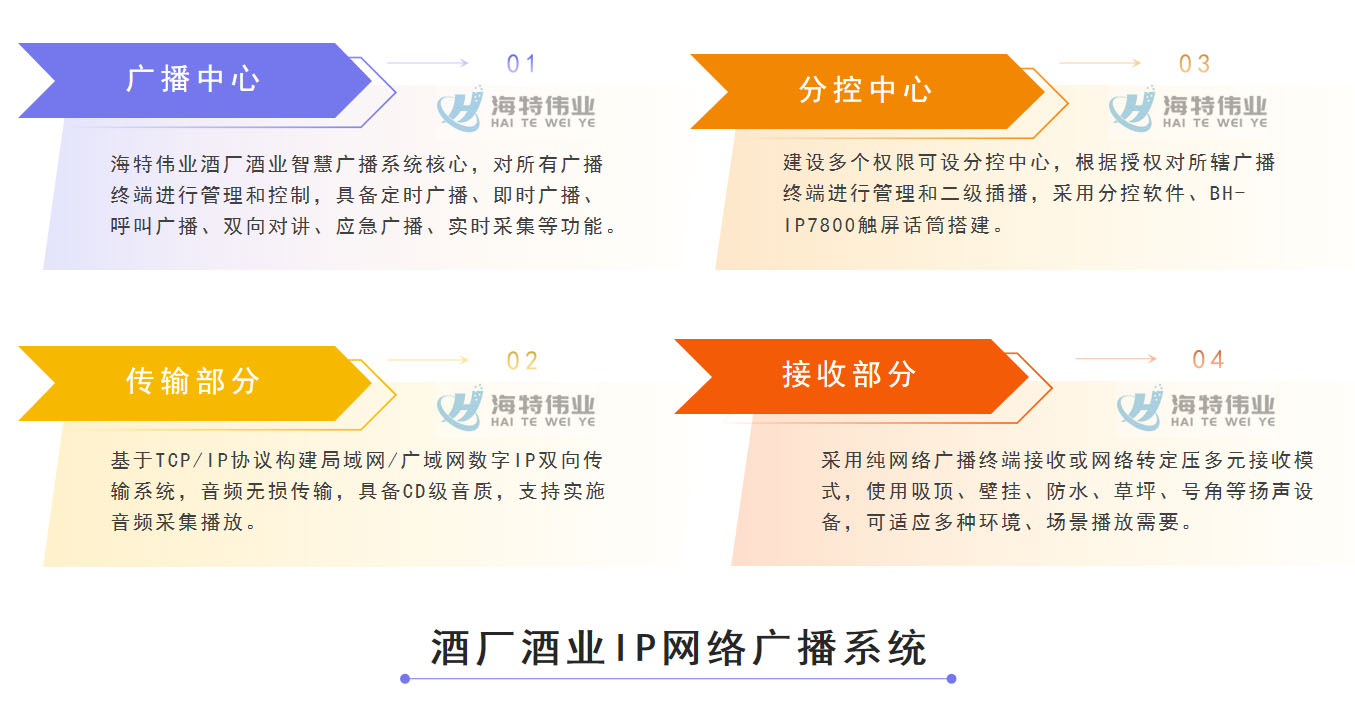
酒厂酒业IP网络广播系统建设方案-基于局域网的新一代交互智慧酒厂酒业IP广播设计指南
酒厂酒业IP网络广播系统建设方案-基于局域网的新一代交互智酒业酒厂IP广播系统设计指南 由北京海特伟业任洪卓发布于2023年4月25日 一、酒厂酒业IP网络广播系统建设需求 随着中国经济的快速稳步发展,中国白酒行业也迎来了黄金时期,产品规模、销售业绩等…...

OpenHarmony JS Demo开发讲解
项目结构 打开entry→src→main→js,工程的开发目录如图所示 其中, i18n文件夹:用于存放配置不同语言场景的资源,比如应用文本词条,图片路径等资源。en-US.json文件定义了在英文模式下页面显示的变量内容,…...
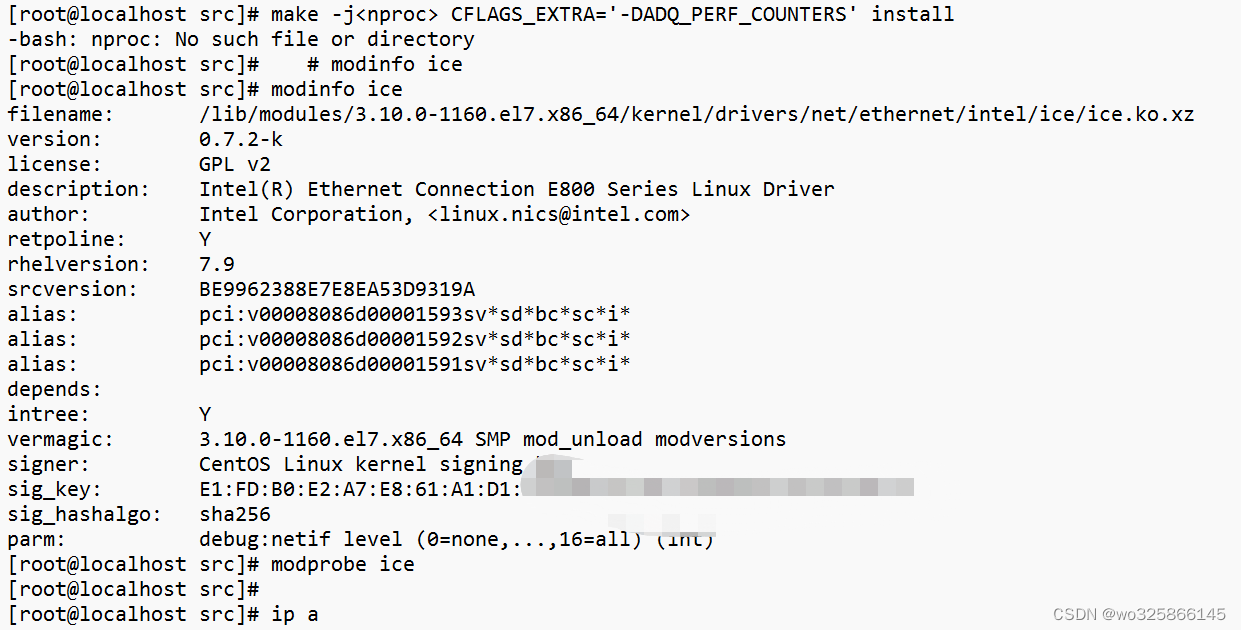
CentOS系统安装Intel E810 25G网卡驱动
因特尔网卡驱动给的都是二进制包,需要编译环境。 首先去Intel下载最新的驱动 E810驱动下载:https://www.intel.com/content/www/us/en/download/19630/intel-network-adapter-driver-for-e810-series-devices-under-linux.html?wapkwe810 里面有三个驱…...

Java经典的String面试题
Java经典的Spring面试题 String是基本数据类型吗? String你是基本数据类型String是可变的话? String是final类型的,不可变怎么比较两个字符串的值一样,怎么比较两个字符串是否同一对象? 比较字符串的值是否相同用equa…...

c# 结构体与类区别
在 C# 中,结构体(struct)和类(class)都是用户自定义类型,它们具有一些共同的特性,比如可以定义字段、属性、方法等。但它们也有一些区别。 下面是一些结构体和类的区别: 定义方式不…...

使用 patch 命令打补丁
之前的这篇文章 git 导出差异 diff 文件 写了导出 diff 、patch 文件。 拿到 patch 文件,用 patch 命令可以快速的把修改内容合入,合入后在 git 上是已修改的状态,如需提交还要 add 、commit 。 patch 语法 patch --help 可以看到 Usage:…...

C++——类和对象[上]
目录 1.初识面向对象 2.类的引入 3.类的定义 4.成员变量的命名规则 5.类的实例化 6.类对象模型 7.this指针 1.初识面向对象 C语言是一门面向过程的语言,它关注的是完成任务所需要的过程;C是一门面向对象的语言,将一个任务分为多个对…...
MySQL日志
目录 一 关于mysql的设计和运行逻辑 二 MySQL的三类日志 三 对于日志的利用 插入查询 1 备份 2 删除重复数据 一 关于mysql的设计和运行逻辑 mysql在启动的时候非常占空间,需要申请很大的空间,但是有时候内存并没有那么多,所以OS会把my…...

TinyURL 的加密与解密、猜数字游戏、 Fizz Buzz、相对名次----2023/4/28
TinyURL 的加密与解密----2023/4/28 TinyURL 是一种 URL 简化服务, 比如:当你输入一个 URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk 。请你设计一个类来加密与解密 TinyURL 。 加…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...

GeoServer发布PostgreSQL图层后WFS查询无主键字段
在使用 GeoServer(版本 2.22.2) 发布 PostgreSQL(PostGIS)中的表为地图服务时,常常会遇到一个小问题: WFS 查询中,主键字段(如 id)莫名其妙地消失了! 即使你在…...

深度解析云存储:概念、架构与应用实践
在数据爆炸式增长的时代,传统本地存储因容量限制、管理复杂等问题,已难以满足企业和个人的需求。云存储凭借灵活扩展、便捷访问等特性,成为数据存储领域的主流解决方案。从个人照片备份到企业核心数据管理,云存储正重塑数据存储与…...

Qt Quick Controls模块功能及架构
Qt Quick Controls是Qt Quick的一个附加模块,提供了一套用于构建完整用户界面的UI控件。在Qt 6.0中,这个模块经历了重大重构和改进。 一、主要功能和特点 1. 架构重构 完全重写了底层架构,与Qt Quick更紧密集成 移除了对Qt Widgets的依赖&…...

初探用uniapp写微信小程序遇到的问题及解决(vue3+ts)
零、关于开发思路 (一)拿到工作任务,先理清楚需求 1.逻辑部分 不放过原型里说的每一句话,有疑惑的部分该问产品/测试/之前的开发就问 2.页面部分(含国际化) 整体看过需要开发页面的原型后,分类一下哪些组件/样式可以复用,直接提取出来使用 (时间充分的前提下,不…...

篇章一 论坛系统——前置知识
目录 1.软件开发 1.1 软件的生命周期 1.2 面向对象 1.3 CS、BS架构 1.CS架构编辑 2.BS架构 1.4 软件需求 1.需求分类 2.需求获取 1.5 需求分析 1. 工作内容 1.6 面向对象分析 1.OOA的任务 2.统一建模语言UML 3. 用例模型 3.1 用例图的元素 3.2 建立用例模型 …...