GPT-3 论文阅读笔记
GPT-3模型出自论文《Language Models are Few-Shot Learners》是OpenAI在2020年5月发布的。
论文摘要翻译:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调(fine-tuning),在许多NLP任务和基准测试上取得了实质性的进展。虽然这种方法在架构上通常与任务无关,但它对特定任务仍然需要有数千或数万个实例的微调数据集。相比之下,人类通常只能通过几个例子或简单的指令来执行一项新的语言任务,而当前的NLP系统在很大程度上仍然很难做到这一点。在本文中我们表明扩大语言模型的规模大大提高了任务无关的、few-shot的性能,有时与之前最先进的微调方法相比仍具有竞争力。具体来说,我们训练了GPT-3,这是一个具有1750亿个参数的自回归语言模型,比以前的任何非稀疏语言模型大10倍以上,并测试其在few-shot场景下的性能。对于所有任务,GPT-3在没有任何梯度更新或微调的情况下应用,任务和few-shot说明完全通过文本与模型交互。GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问答和完形填空任务,以及一些需要动态推理或领域自适应的任务,如解读单词、在句子中使用新词或执行三位数算术。同时,我们还讨论了GPT-3在few-shot学习仍然困难的一些数据集,以及GPT-3在大型网络语料库上训练时面临方法论问题的数据集。最后,我们发现GPT-3可以生成新闻文章的样本,人类评估人员很难将其与人类撰写的文章区分开来,我们讨论了这一发现和GPT-3的更广泛的社会影响。
在论文引言部分正式定义了在GPT-2就提过的不需要fine-tuning直接使用模型完成任务的思路,将其称为“In-context learning”:把预训练模型的输入当做特定任务的说明,也就是将自然语言指令、以及任务的几个示例(或0个示例)一起作为模型的输入,希望模型通过预测后面要输出什么来完成接下来的任务实例。
Recent work [ RWC+19] attempts to do this via what we call "in-context learning", using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
论文的第2部分,先定义了Few-Shot(FS)、One-Shot(1S)、Zero-Shot(0S),这三种方式都不允许对模型参数进行更新, 并用下图进行了示意,
Few-Shot(FS):对于指定的任务提供K个示例样本给模型,一般是10-100,因为模型的上下文token为2048,太多个样本就放不进模型里。
One-Shot(1S):对于指定的任务提供恰好1个示例样本给模型, 区分一次性和少样本和零样本的原因是它与一些任务被传达给人类的方式最匹配。例如,当要求人类在人工服务(例如 Mechanical Turk)上生成数据集时,通常会展示该任务。相比之下,如果没有给出示例,有时很难传达任务的内容或格式
Zero-Shot(0S):不提供任何示例样本给模型,只将任务描述输入到模型。
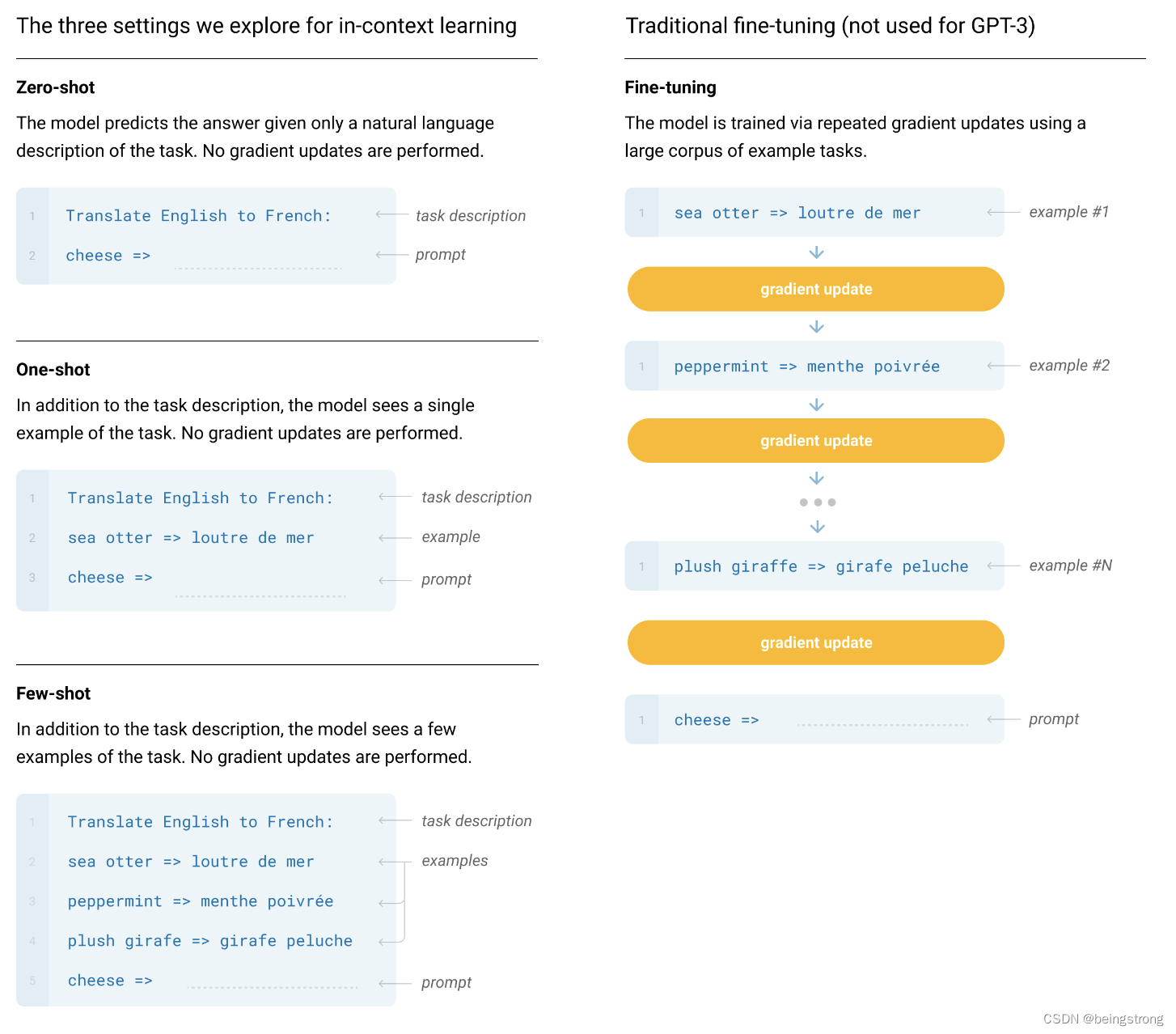
原论文中的Figure 2.1
论文中图2 说明了在不对模型做任何梯度更新和微调的情况下:1. 提供额外的自然语言描述可以提高模型效果(就是提供prompt); 2. 提供越多的样本数K也可以提高模型效果; 3. 模型大小的增加能显著提高few-shot的效果
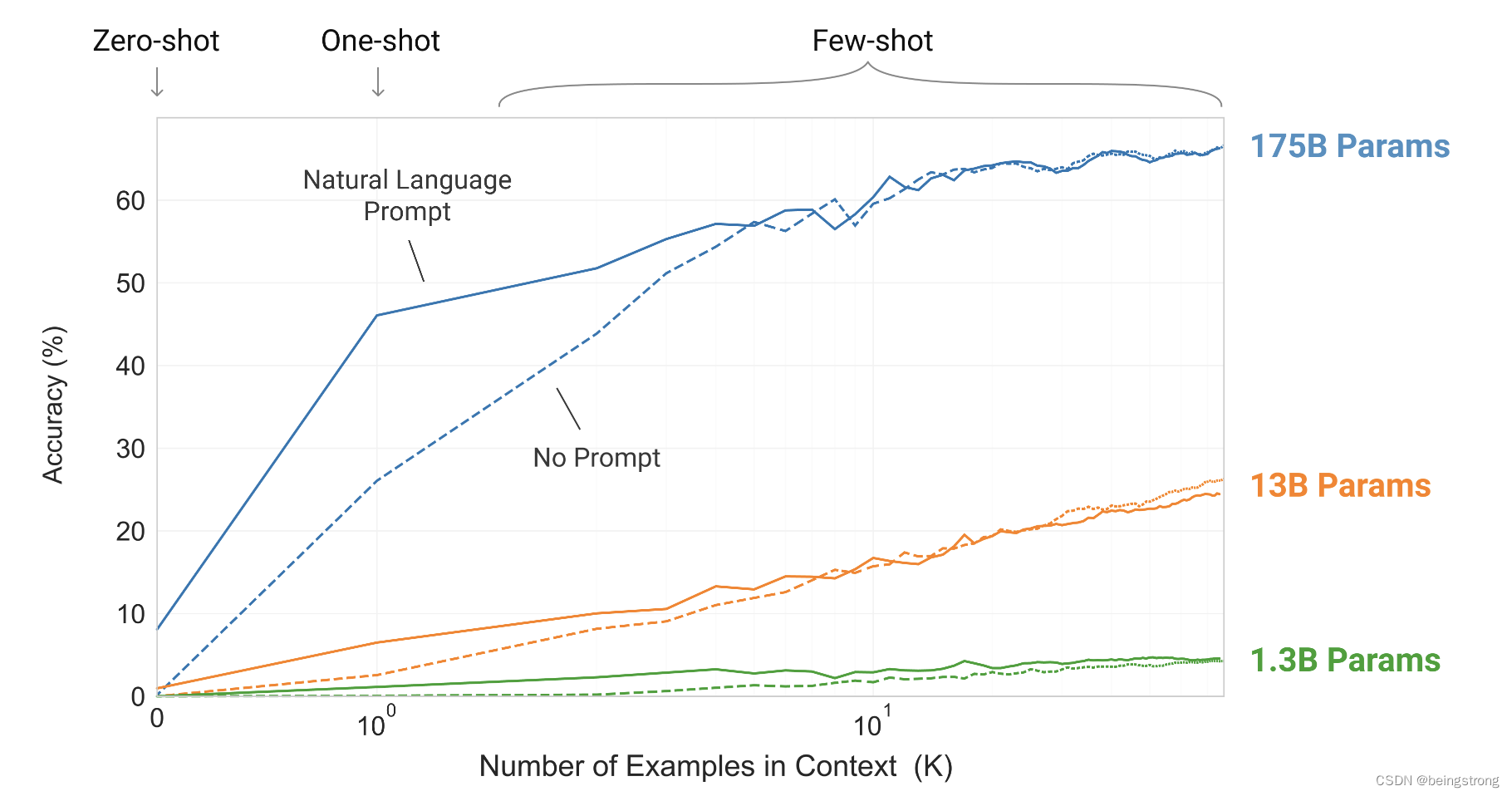
原论文中的Figure 1.2
GPT-3 模型和架构:
- GPT-3的模型与GPT-2 几乎一样,只有一个例外:像Sparse Transformer 一样在transformer 中使用dense and locally banded sparse attention patterns。
- 一共训练了如下表所示的8个模型,最大的有1750亿个参数的模型被称为GPT-3,所有模型的上下文窗口token大小为n_{ctx} = 2048。下表中
是模型参数,
是模型的层数,d_{model} 是每一个块的参数大小, n_{heads} 是多头注意力的个数,d_head是每个注意力头的大小。
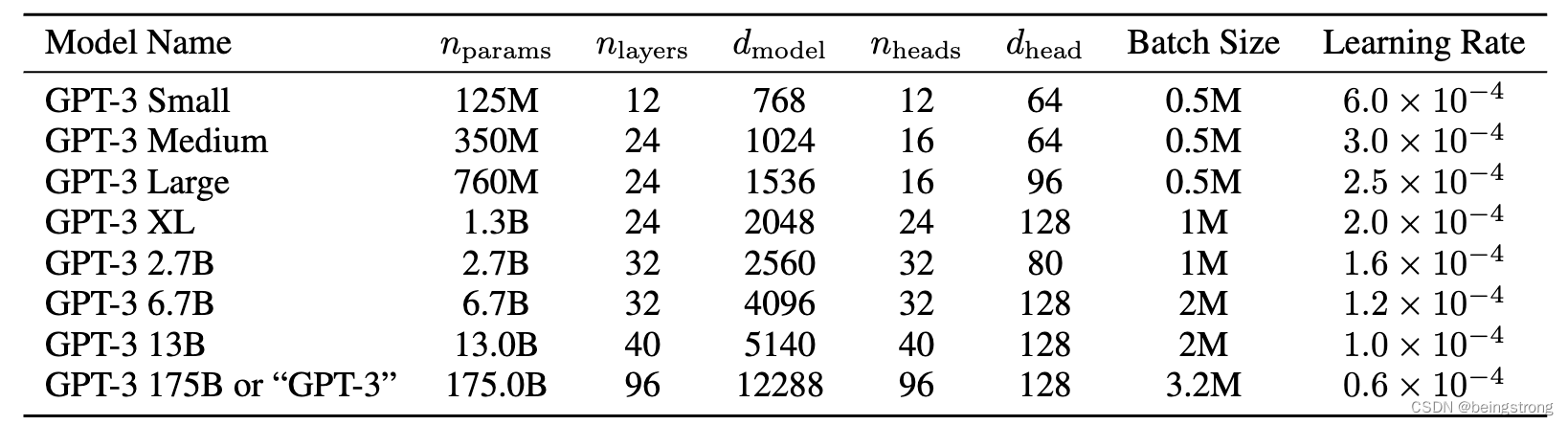 原论文中的表2.1
原论文中的表2.1
训练数据集:
数据集使用Common Crawl dataset,因为大小足够大到训练GPT-3,但是Common Crawl dataset的质量比较低,使用3个步骤来提到数据集的质量:
(1)下载 Common Crawl 2016 - 2019共41个shards的数据,根据与一系列高质量参考语料库的相似性过滤了掉部分语料
-
使用逻辑回归训练了一个分类器,用WebText, Wikiedia 和 web books的语料当做正样本,使用没有过滤过的 Common Crawl当做负样本, 特征由spark标准分词器和HashingTF生成。然后使用这个分类器来预测Common Crawl的样本,得到一个分数,如果np.random.pareto(α) > 1 − document_score 就保留样本,选取了α=9,目的是留下大部分分类器评分高的文档,但是仍然包含了一些在分布外的文档。α是根据分类器在WebText上的分数分布来选取的。(并发现通过分布之外生成样本的损失来衡量的话,re-weighting 策略是增加了样本质量的)
(2)在文档级别、数据集内部和数据集之间执行了模糊重复数据消除,以防止冗余,并保持我们的作为过拟合的准确度量的验证集的完整性。
- 使用spark的10 hashes的MinHashLSH 来对每个数据集进行模糊去重。将WebText从Common Crawl模糊移除,减少了10%左右的数据
(3)将已知的高质量参考语料库添加到训练组合中,以增强Common Crawl并增加其多样性,训练时各训练集的比例如下表
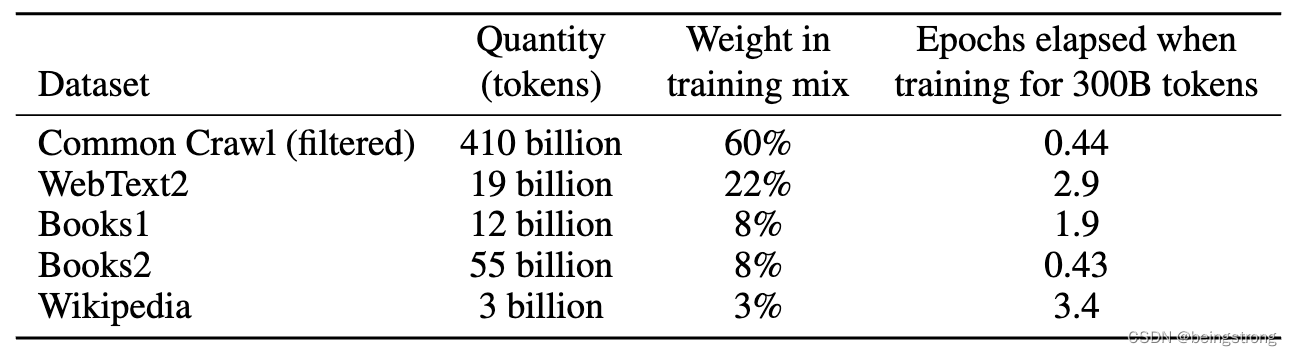 原论文中的Table 2.2
原论文中的Table 2.2
另外作者提到在训练过程中,数据集不是按大小成比例采样的,而是认为质量更高的数据集应该被更频繁地采样,因此CommonCrawl和Books2数据集在训练期间被采样不到一次,但其他数据集被采样2-3次。
训练过程:
- 如上表中示意的,更大的模型会使用更大的batch size,同时使用更小的学习率。 使用训练过程中的梯度噪声尺度来指导选择batch size
- 使用
的Adam 学习器
- clip the global norm of the gradient at 1.0
- use cosine decay for learning rate down to 10% of its value, over 260 billion tokens (after 260 billion tokens, training continues at 10% of the original learning rate. There is a linear LR warmup over the first 375 million tokens
- gradually increase the batch size linearly from a small value(32k tokens) to the full value over the first 4-12 billion tokens of training, depending on the model size.
- all models use weight decay of 0.1 to provide a small amount of regulation
- data are sampled without replacement during training to minimize overfitting
- 为了提高计算效率,所有训练样本的序列长度都是n_{ctx} = 2048, 当文档的长度小于2048时,将多个文档合并成一个。对于由多个文档组成的序列,没有使用特殊的掩码,而是在一个文档结束处放置了一个结束符。
- 使用混合模型并行方法来训练,训练是在Microsoft 提供的V100 GPU上进行的。 (a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network)
论文中的图3.1说明把模型参数增加2个数量级后,还是基本符合幂率分布(power-law)规律的
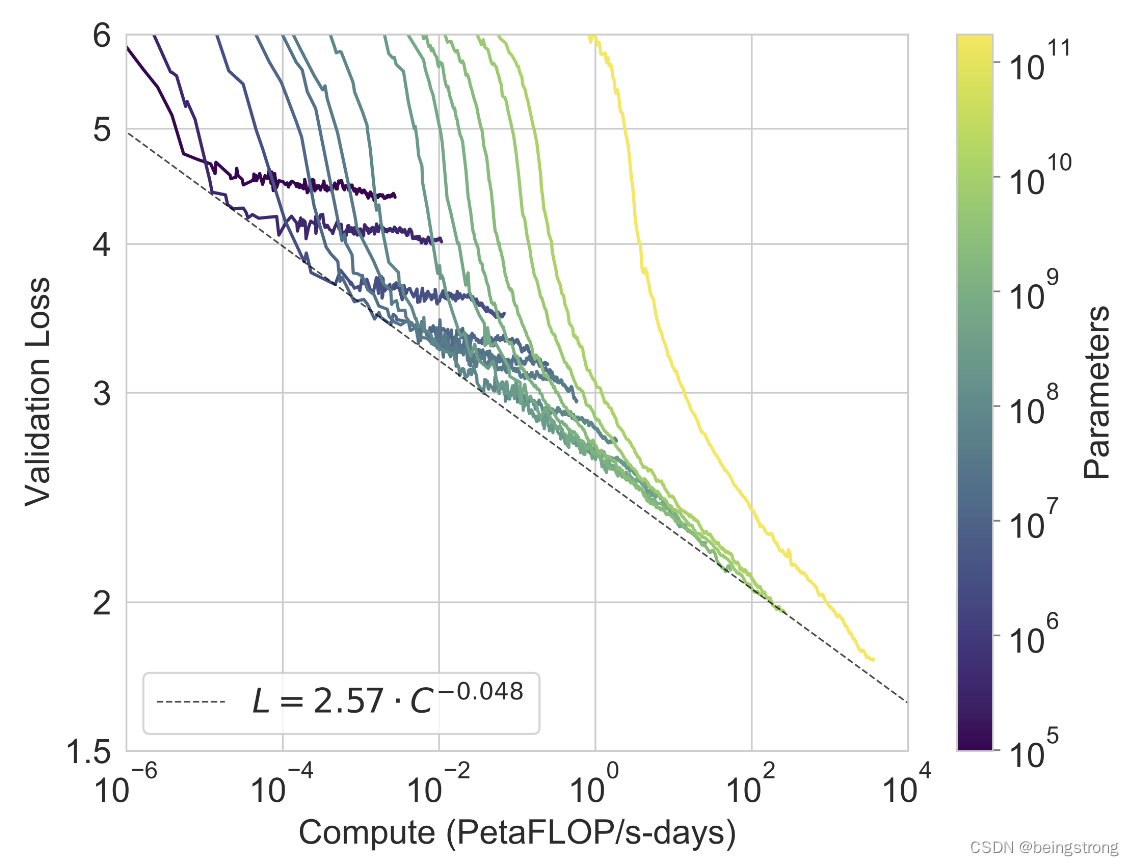
原论文中的Figure 3.1
论文第三部分是GPT-3模型在各个数据集上的效果;第四部分讨论了大模型是否仅仅是记住了训练样本;第五部分讨论模型的局限性;第6部分讨论大模型更广泛的影响,如被不良使用,公平及偏见、能耗使用。
参考资料
1. Brown, TomB., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” arXiv: Computation and Language.
相关文章:
GPT-3 论文阅读笔记
GPT-3模型出自论文《Language Models are Few-Shot Learners》是OpenAI在2020年5月发布的。 论文摘要翻译:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调(fine-tuning),在许多NLP任务和基准测试上…...

方案解析丨数字人主播如何成为电商直播新标配
浙江省政府办公厅近日印发《关于进一步扩大消费促进高质量发展若干举措》支持电子商务直播发展。抢抓电子商务直播快速发展机遇,发展数字人虚拟主播、元宇宙新消费场景等新业态新模式。 随着电商直播快速发展,企业怎么高效地实现引流获客,成为…...

Python最全迭代器有哪些?
python中迭代器的使用是最广泛的,凡是使用for语句,其本质都是迭代器的应用。 从代码角度看,迭代器是实现了迭代器协议的对象或类。迭代器协议方法主要是两个: __iter__()__next__() __iter__()方法返回对象本身,他是…...

ESP32 网络计时器,包含自动保存
简介 本代码是基于ESP32开发板实现的一个计时器功能,具备倒计时、计时器时长选择、显示当前时间、有源蜂鸣器报警等功能。代码中使用了WiFi网络连接、NTP时间同步、EEPROM存储等功能。通过按钮控制计时器的开始、停止和计时器时长的选择。 运行原理概述 在ESP32开…...

【ChatGPT】阿里版 ChatGPT 突然官宣意味着什么?
Yan-英杰的主页 悟已往之不谏 知来者之可追 C程序员,2024届电子信息研究生 目录 阿里版 ChatGPT 突然官宣 ChatGPT 技术在 AI 领域的重要性 自然语言生成 上下文连续性 多语言支持 ChatGPT 未来可能的应用场景 社交领域 商业领域 编辑 医疗领域…...

IPEmotion控制模块-PID循环应用
IPEmotion专业版、开发版支持控制模块,并且该模块支持函数发生器、PID控制器、路由器、序列控制和序列控制块以及参考曲线生成器。本文主要针对PID(P:Proportional control 比例控制;I:Integral control 积分控制&…...
)
【元分析研究方法】学习笔记2.检索文献(含100种学术文献搜索清单链接)
检索文献 该步骤的作用该步骤中需要注意的问题该步骤中部分知识点我的收获 参考来源:库珀 (Cooper, H. M. )., 李超平, & 张昱城. (2020). 元分析研究方法: A step-by step approach. 中国人民大学出版社. 该步骤的作用 1.识别相关文献的来源; 2.识别…...

题目:16版.自由落体
1、实验要求 本实验要求:模拟物体从10000米高空掉落后的反弹行为。 1-1. 创建工程并配置环境: 1-1.1. 限制1. 工程取名:SE_JAVA_EXP_E009。 1-1.2. 限制2. 创建包,取名:cn.campsg.java.experiment。 1-1.3. 限制3. 创建…...
视频可视化搭建项目,通过简单拖拽方式快速生产一个短视频
一、开源项目简介 《视搭》是一个视频可视化搭建项目。您可以通过简单的拖拽方式快速生产一个短视频,使用方式就像易企秀或百度 H5 等 h5 搭建工具一样的简单。目前行业内罕有关于视频可视化搭建的开源项目,《视搭》是一个相对比较完整的开源项目&#…...

network-1 4 layer internet model
4layer model applicationtransport tcp: transmission control protocol enable correct in-order delivery of data, running on top of the network layer service.udp: user datagram protocolnetwork packet:data、from、tonetwork->linkiplink source en…...

计算机网络笔记(横向)
该笔记也是我考研期间做的整理。一般网上的笔记是按照章节纪录的,我是按照知识点分类纪录的,大纲如下: 文章目录 1. 各报文1.1 各报文头部详解1.2 相关口诀 2. 各协议2.1 各应用层协议使用的传输层协议与端口2.2 各协议的过程2.2.1 数据链路层…...

0.redis-实践
1.redis内存设置多少,默认是0,不限制 2.如何配置,修改内存大小 1) 查看最大占用内存 # maxmeory <bytes> 或者 config get maxmemory 2) 默认内存多少可以用: 64位系统下不限制,32位下最多3G 3) 如何配置: 默认总内存的3/4 4) 如何修改…...
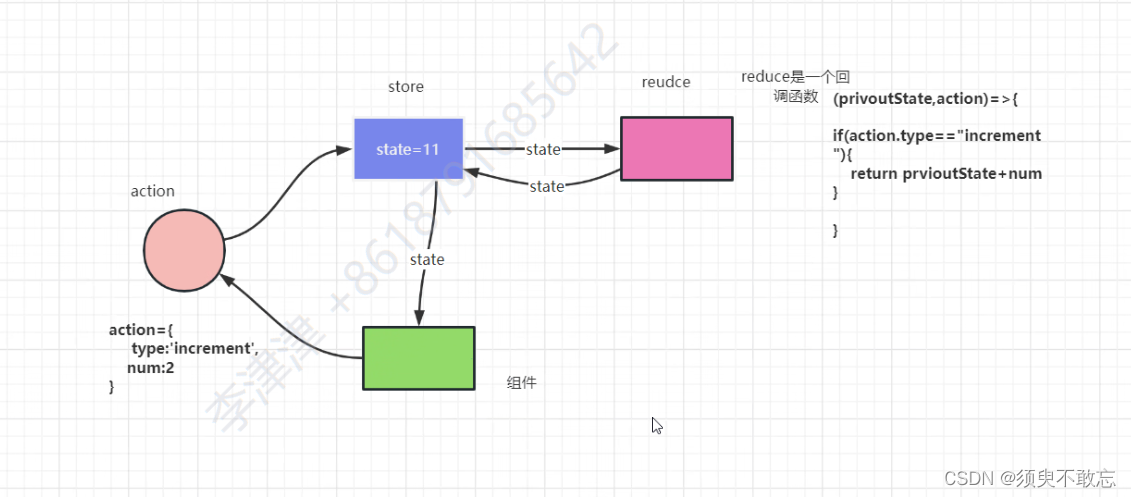
Redux的基本使用,从入门到入土
目录 一、初步使用Redux 1.安装Redux 2.配置状态机 二、Redux的核心概念 1.工作流程 2.工作流程 三、优化Redux 1.对action进行优化 2.type常量 3.reducer优化 四、react-redux使用 1.安装react-redux 2.全局注入store仓库 3.组件关联仓库 五、状态机的Hook 1.u…...
GDOUCTF2023-部分re复现
目录 [GDOUCTF 2023]Check_Your_Luck [GDOUCTF 2023]Tea [GDOUCTF 2023]doublegame [GDOUCTF 2023]Check_Your_Luck 打开题目是一串代码,明显的z3约束器求解 直接上脚本 import z3 from z3 import Reals z3.Solver() vReal(v) xReal(x) yReal(y) wReal(w) zRea…...
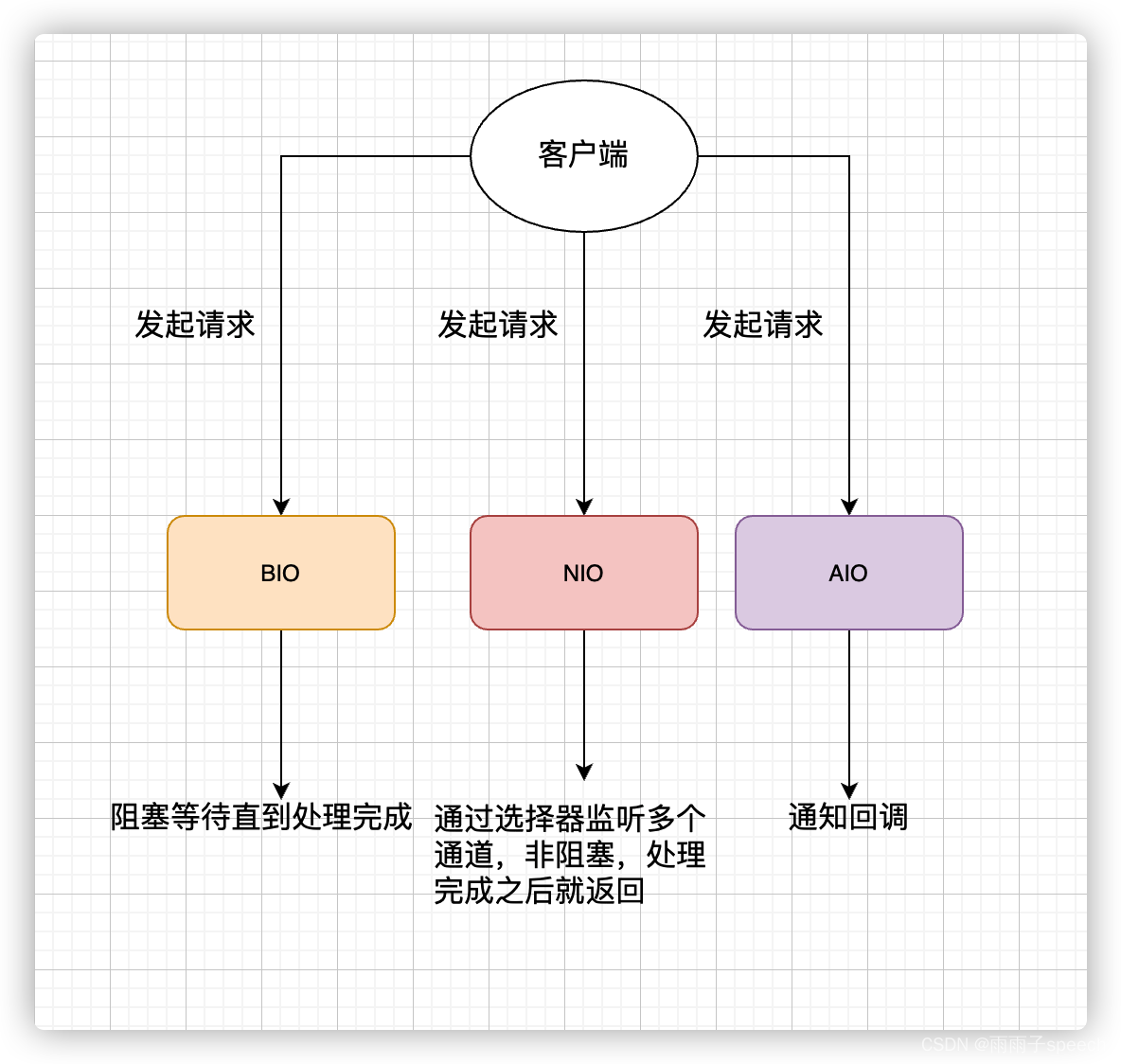
Java学习17(IO模型详解)
1、何为IO? I/O(Input/Outpu) 即输入/输出 。 从计算机结构的角度来解读一下 I/O。 根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。 输入设备(比如键盘&am…...
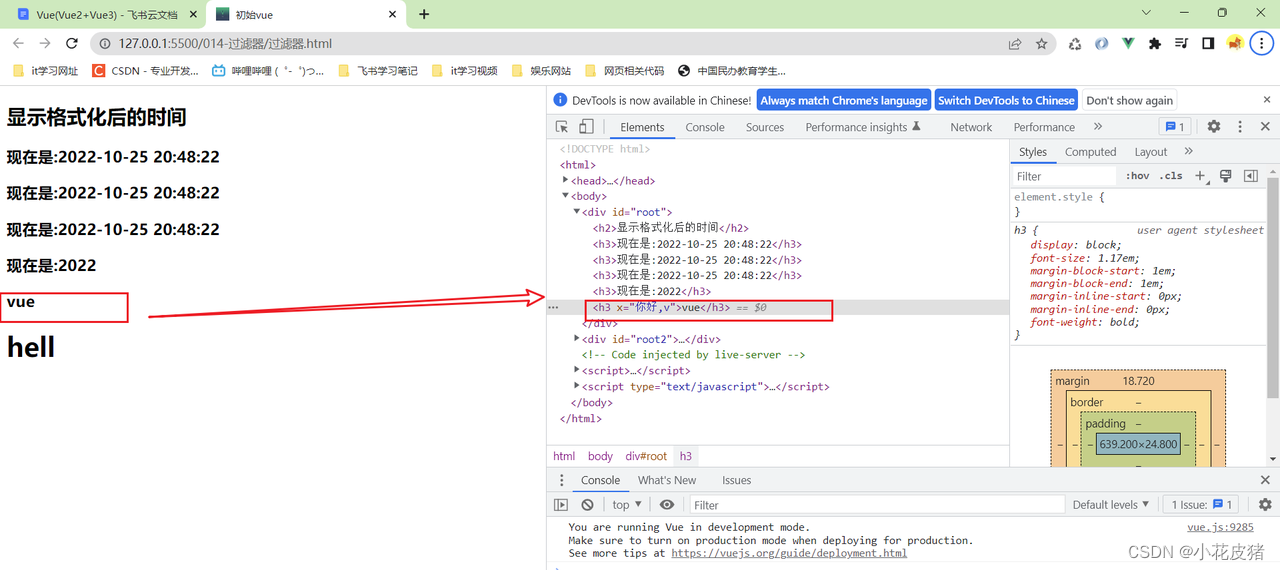
Vue-全局过滤器以及进阶操作
前言 上篇文件讲述了,Vue全局过滤器的基本使用:Vue过滤器的基本使用 本篇将延续上文,讲述vue中过滤器的进阶操作 过滤器传参 如果有一天,多个地方使用过滤器,而且需要传递参数,那么可以这么写 多个过滤…...
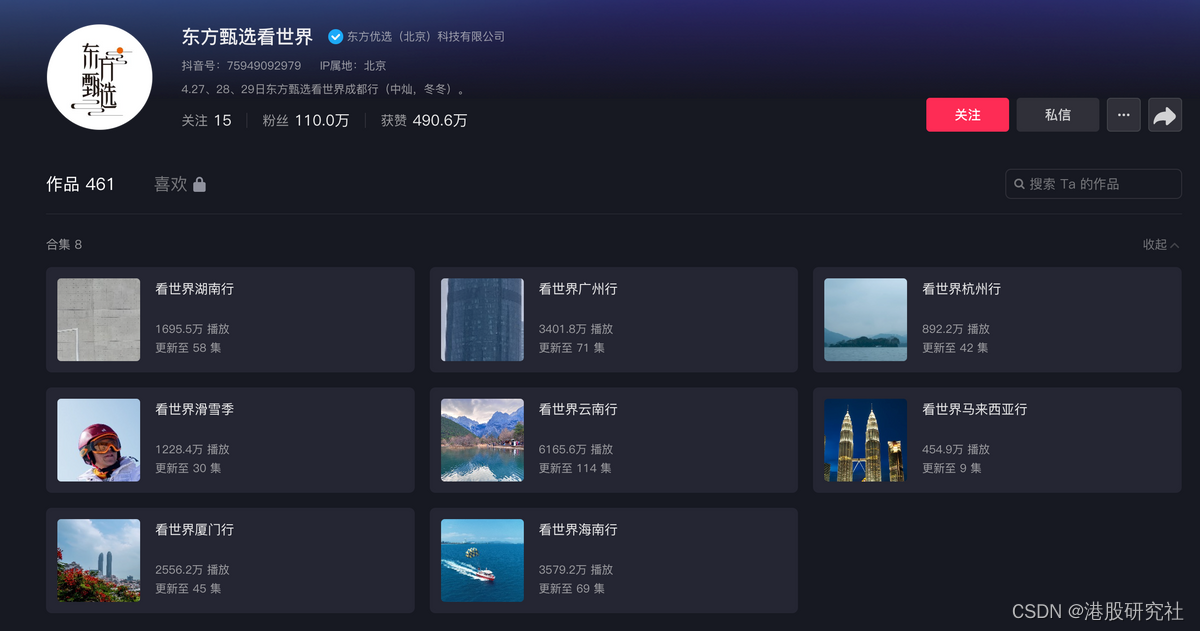
财报解读:涅槃重生之后,新东方还想再造一个“文旅甄选”?
新东方逐渐走出了“微笑曲线”。 图源:新东方2023财年Q3财报 2023年4月19日,新东方披露了2023财年Q3财报(截至2023年2月28日止),营收7.5亿美元,同比增长22.8%;归母净利润为8165万美元ÿ…...
)
华为OD机试 - 过滤组合字符串(Python)
题目描述 每个数字关联多个字母,关联关系如下: 0 关联 “a”,”b”,”c” 1 关联 “d”,”e”,”f” 2 关联 “g”,”h”,”i” 3 关联 “j”,”k”,”l” 4 关联 “m”,”n”,”o” 5 关联 “p”,”q”,”r” 6 关联 “s”,”t” 7 关联 “u”,”v” 8 关联 “w”,”x” 9 …...
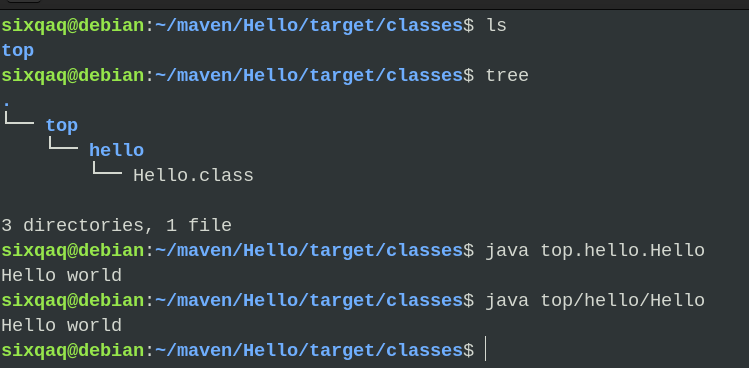
maven简单使用
实验课的作业用一大堆框架/库,统统要用maven管理。 头一次用,真痛苦。 所幸得以解决,maven真香~ 一步一步来。 1. maven 不是java人,只能说说粗浅的理解了。 简单来说,maven是一个管理项目的工具&…...

HTML学习笔记一
目录 HTML学习笔记 一、HTML标签 1、HTML语法规范 1.1标签的语法概述 1.2标签关系 2、HTML基本结构标签 2.1第一个HTML 2.2基本结构标签总结 3、开发工具 4、HTML常用标签 4.1标签的语义 4.2标题标签 4.3段落和换行标签 4.4文本格式化标签 4.5div和span标签 4.…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
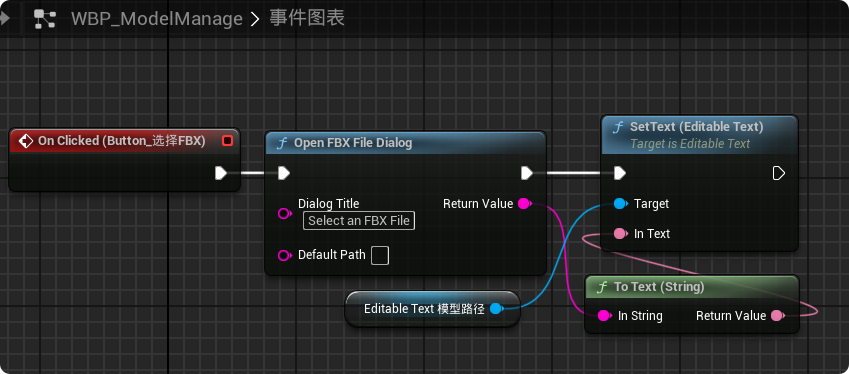
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...
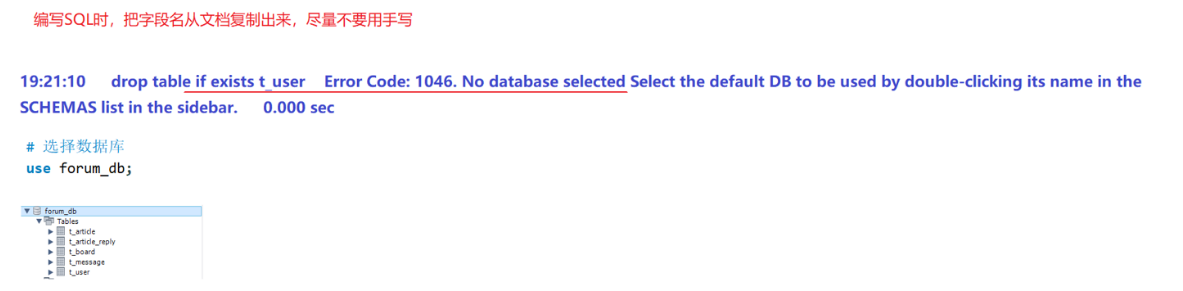
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...