大数据 | 实验二:文档倒排索引算法实现
文章目录
- 📚实验目的
- 📚实验平台
- 📚实验内容
- 🐇在本地编写程序和调试
- 🥕代码框架思路
- 🥕代码实现
- 🐇在集群上提交作业并执行
- 🥕在集群上提交作业并执行,同本地执行相比即需修改路径。
- 🥕修改后通过expoet,导出jar包,关注 Main-Class 的设置!
- 🥕在终端依次输入以下指令,完成提交
📚实验目的
倒排索引(Inverted Index)被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,是目前几乎所有支持全文索引的搜索引擎都需要依赖的一个数据结构。通过对倒排索引的编程实现,熟练掌握 MapReduce 程序在集群上的提交与执行过程,加深对 MapReduce 编程框架的理解。
📚实验平台
- 操作系统:Linux
- Hadoop 版本:3.2.2
- JDK 版本:1.8
- Java IDE:Eclipse
📚实验内容
关于倒排索引
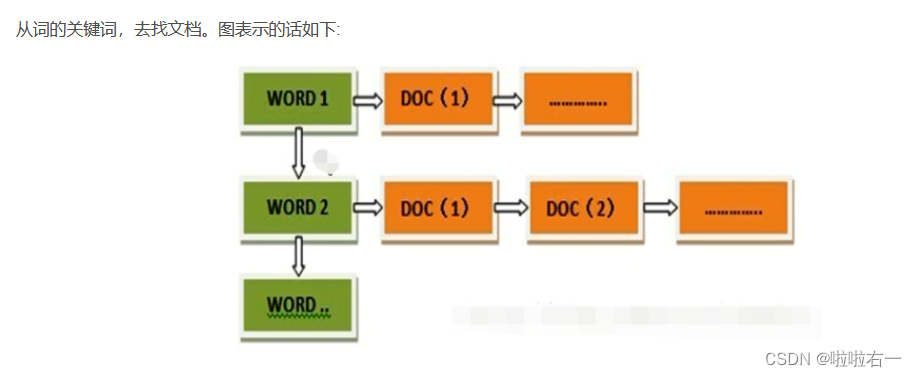
🐇在本地编写程序和调试
在本地 eclipse 上编写带词频属性的对英文文档的文档倒排索引程序,要求程序能够实现对 stop-words(如 a,an,the,in,of 等词)的去除,能够统计单词在每篇文档中出现的频率。文档数据和停词表可在此链接上下载,在伪分布式环境下完成程序的编写和调试。
🥕代码框架思路
- Map():对输入的Text切分为多个word。这里的
Map()包含setup()和map()。每一次map都伴随着一次setup,进行停词,筛选那些不需要统计的。 - Combine():将Map输出的中间结果
相同key部分的value累加,减少向Reduce节点传输的数据量。 - Partition():为了
将同一个word的键值对发送到同一个Reduce节点,对key进行临时处理。将原key的(word, filename)临时拆开,使Partitioner只按照word值进行选择Reduce节点。基于哈希值的分片方法。 - Reduce():利用每个Reducer接收到的键值对中,word是排好序的,来进行最后的整合。将word#filename拆分开,
将filename与累加和拼到一起,存在str中。每次比较当前的word和上一次的word是否相同,若相同则将filename和累加和附加到str中,否则输出:key:word,value:str,并将新的word作为key继续。 - 上述reduce()只会在遇到新word时,处理并输出前一个word,故对于最后一个word还需要额外的处理。
重载cleanup(),处理最后一个word并输出

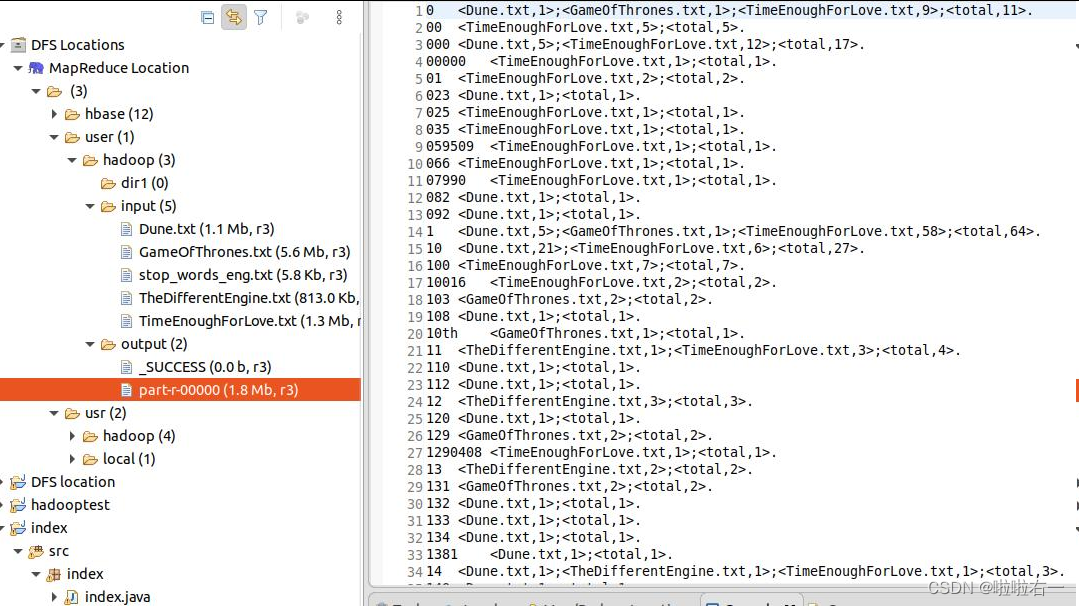
倒排索引的Map、Combiner、Partitioner部分就和上图一样
- 一个Map对应一个Combiner,借助Combiner对Map输出进行一次初始整合
- 一个Combiner又对应一个Partitioner,Partitioner将同一个word的键值对发送到同一个Reduce节点
🥕代码实现
(关注本地路径)
package index;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
import java.util.Vector;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;public class index
{public static class Map extends Mapper<Object, Text, Text, IntWritable> {/*** setup():读取停词表到vector stop_words中*/Vector<String> stop_words;//停词表protected void setup(Context context) throws IOException {stop_words = new Vector<String>();//初始化停词表Configuration conf = context.getConfiguration();//读取停词表文件BufferedReader reader = new BufferedReader(new InputStreamReader(FileSystem.get(conf).open(new Path("hdfs://localhost:9000/user/hadoop/input/stop_words_eng.txt"))));String line;while ((line = reader.readLine()) != null) {//按行处理StringTokenizer itr=new StringTokenizer(line);while(itr.hasMoreTokens()){//遍历词,存入vectorstop_words.add(itr.nextToken());}}reader.close();}/*** map():对输入的Text切分为多个word* 输入:key:当前行偏移位置 value:当前行内容* 输出:key:word#filename value:1*/protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {FileSplit fileSplit = (FileSplit) context.getInputSplit();String fileName = fileSplit.getPath().getName();//获取文件名,转换为小写String line = value.toString().toLowerCase();//将行内容全部转为小写字母//只保留数字和字母String new_line="";for(int i = 0; i < line.length(); i ++) {if((line.charAt(i)>=48 && line.charAt(i)<=57) || (line.charAt(i)>=97 && line.charAt(i)<=122)) {//按行处理new_line += line.charAt(i);} else {//其他字符保存为空格new_line +=" ";}}line = new_line.trim();//去掉开头和结尾的空格StringTokenizer strToken=new StringTokenizer(line);//按照空格拆分while(strToken.hasMoreTokens()){String str = strToken.nextToken();if(!stop_words.contains(str)) {//不是停词则输出key-value对context.write(new Text(str+"#"+fileName), new IntWritable(1));}}}}public static class Combine extends Reducer<Text, IntWritable, Text, IntWritable> {/*** 将Map输出的中间结果相同key部分的value累加,减少向Reduce节点传输的数据量* 输入:key:word#filename value:1* 输出:key:word#filename value:累加和(词频)*/protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum ++;}context.write(key, new IntWritable(sum));}}public static class Partition extends HashPartitioner<Text, IntWritable> {/*** 为了将同一个word的键值对发送到同一个Reduce节点,对key进行临时处理* 将原key的(word, filename)临时拆开,使Partitioner只按照word值进行选择Reduce节点* 基于哈希值的分片方法*/public int getPartition(Text key, IntWritable value, int numReduceTasks) {//第三个参数numPartitions表示每个Mapper的分片数,也就是Reducer的个数String term = key.toString().split("#")[0];//获取word#filename中的wordreturn super.getPartition(new Text(term), value, numReduceTasks);//按照word分配reduce节点 }}public static class Reduce extends Reducer<Text, IntWritable, Text, Text> {/*** Reduce():利用每个Reducer接收到的键值对中,word是排好序的,来进行最后的整合* 将word#filename拆分开,将filename与累加和拼到一起,存在str中* 每次比较当前的word和上一次的word是否相同,若相同则将filename和累加和附加到str中,否则输出:key:word,value:str,并将新的word作为key继续* 输入:* key value* word1#filename 1 [num1,num2,...]* word1#filename 2 [num1,num2,...]* word2#filename 1 [num1,num2,...]* 输出:* key:word value:<filename1,词频><filename2,词频>...<total,总词频>*/private String lastfile = null;//存储上一个filenameprivate String lastword = null;//存储上一个wordprivate String str = "";//存储要输出的value内容private int count = 0;private int totalcount = 0;protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {String[] tokens = key.toString().split("#");//将word和filename存在tokens数组中if(lastword == null) {lastword = tokens[0];}if(lastfile == null) {lastfile = tokens[1];}if (!tokens[0].equals(lastword)) {//此次word与上次不一样,则将上次的word进行处理并输出str += "<"+lastfile+","+count+">;<total,"+totalcount+">.";context.write(new Text(lastword), new Text(str));//value部分拼接后输出lastword = tokens[0];//更新wordlastfile = tokens[1];//更新filenamecount = 0;str="";for (IntWritable val : values) {//累加相同word和filename中出现次数count += val.get();//转为int}totalcount = count;return;}if(!tokens[1].equals(lastfile)) {//新的文档str += "<"+lastfile+","+count+">;";lastfile = tokens[1];//更新文档名count = 0;//重设count值for (IntWritable value : values){//计数count += value.get();//转为int}totalcount += count;return;}//其他情况,只计算总数即可for (IntWritable val : values) {count += val.get();totalcount += val.get();}}/*** 上述reduce()只会在遇到新word时,处理并输出前一个word,故对于最后一个word还需要额外的处理* 重载cleanup(),处理最后一个word并输出*/public void cleanup(Context context) throws IOException, InterruptedException {str += "<"+lastfile+","+count+">;<total,"+totalcount+">.";context.write(new Text(lastword), new Text(str));super.cleanup(context);}}public static void main(String args[]) throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");if(args.length != 2) {System.err.println("Usage: Relation <in> <out>");System.exit(2);}Job job = Job.getInstance(conf, "InvertedIndex");//设置环境参数job.setJarByClass(index.class);//设置整个程序的类名job.setMapperClass(Map.class);//设置Mapper类job.setCombinerClass(Combine.class);//设置combiner类job.setPartitionerClass(Partition.class);//设置Partitioner类job.setReducerClass(Reduce.class);//设置reducer类job.setOutputKeyClass(Text.class);//设置Mapper输出key类型job.setOutputValueClass(IntWritable.class);//设置Mapper输出value类型FileInputFormat.addInputPath(job, new Path(args[0]));//输入文件目录FileOutputFormat.setOutputPath(job, new Path(args[1]));//输出文件目录System.exit(job.waitForCompletion(true) ? 0 : 1);//参数true表示检查并打印 Job 和 Task 的运行状况}}
⭐补充:当我们新建一个Package和Class后运行时,可能会出现如下报错(主要是在MapReduce编程输入输出里会遇到)

⭐解决办法:
- “Run As”选中“Run Configurations…”

- 然后在“Arguments”里输入
input output,然后再run就行了。

🐇在集群上提交作业并执行
集群的服务器地址为 10.102.0.198,用户主目录为/home/用户名,hdfs 目录为/user/用户名。集群上的实验文档存放目录为 hdfs://10.102.0.198:9000/input/. 英文停词表文件存放位置为hdfs://10.102.0.198:9000/stop_words/stop_words_eng.txt。
🥕在集群上提交作业并执行,同本地执行相比即需修改路径。

🥕修改后通过expoet,导出jar包,关注 Main-Class 的设置!
- 选中index.java右键Export。
- 如下图选中
JAR file后点Next。
- 确认选中index及其src,
JAR的命名要和class名一样,比如这里是index.java,就是class index,也就是index.jar。然后点Next。

- 到如下页面,再点Next。
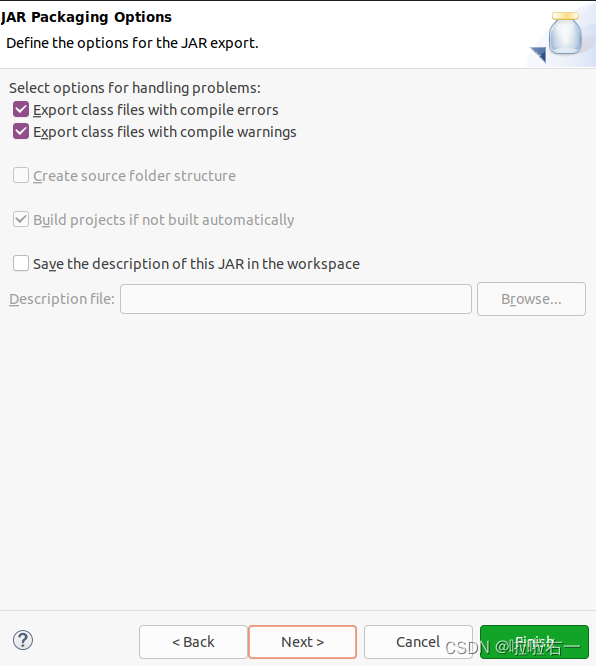
- 在
Main class那点Browse,选中index。
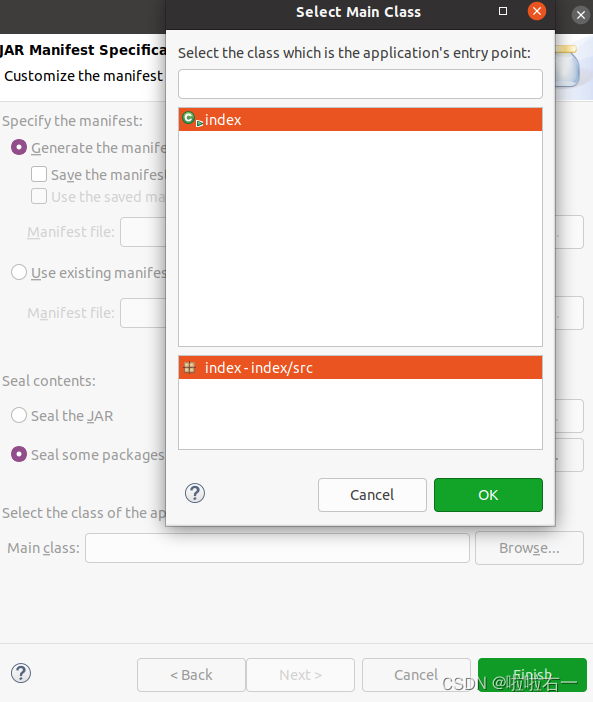
- 如下图。

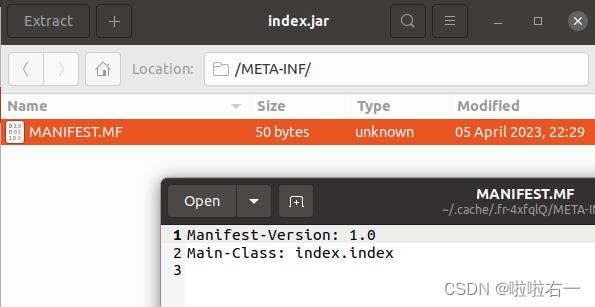
- 最后点finish完成导出,可在文件夹里找到index.jar。双击index.jar,在它的
METS-INT里头查看Main-Class是否设置成功。

🥕在终端依次输入以下指令,完成提交
- 使用
scp InvertedIndex.jar 用户名@10.102.0.198:/home/用户名命令将本地程序提交到 Hadoop 集群 - 通过
ssh 用户名@10.102.0.198命令远程登录到 Hadoop 集群进行操作; - 使用
hadoop jar InvertedIndex.jar /input /user/用户名/output命令在集群上运行 Hadoop 作业,指定输出目录为自己 hdfs 目录下的 output。 - 使用
diff 命令判断自己的输出结果与标准输出的差异
scp index.jar bigdata_学号@10.102.0.198:/home/bigdata_学号
ssh bigdata_学号@10.102.0.198
hadoop jar index.jar /input /user/bigdata_学号/output
diff <(hdfs dfs -cat /output/part-r-00000) <(hdfs dfs -cat /user/bigdata_学号/output/part-r-00000)
在浏览器中打开 http://10.102.0.198:8088,可以查看集群上作业的基本执行情况。

相关文章:
大数据 | 实验二:文档倒排索引算法实现
文章目录 📚实验目的📚实验平台📚实验内容🐇在本地编写程序和调试🥕代码框架思路🥕代码实现 🐇在集群上提交作业并执行🥕在集群上提交作业并执行,同本地执行相比即需修改…...

Java文档注释-JavaDoc标签
标签含义author指定作者{code}使用代码字体以原样显示信息,不处理HTML样式deprecated指定程序元素已经过时{docRoot}指定当前文档的根目录路径exception标识由方法或构造函数抛出的异常{inheritDoc}从直接超类中继承注释{link}插入指向另外一个主题的内联链接{linkp…...

黑盒测试过程中【测试方法】详解5-输入域,输出域,猜错法
在黑盒测试过程中,有9种常用的方法:1.等价类划分 2.边界值分析 3.判定表法 4.正交实验法 5.流程图分析 6.因果图法 7.输入域覆盖法 8.输出域覆盖法 9.猜错法 黑盒测试过程中【测试方法】讲解1-等价类,边界值,判定表_朝一…...
在Python中的使用)
Python学习之sh(shell脚本)在Python中的使用
文章目录 前言一、sh是什么?二、使用步骤1.安装2.使用示例3.使用sh执行命令4.关键字参数5.查找命令6.Baking参数 前言 本文章向大家介绍[Python库]分析一个python库–sh(系统调用),主要内容包括其使用实例、应用技巧、基本知识点…...

追求卓越:编写高质量代码的方法和技巧
本文讨论了编写高质量代码的重要性,并详细介绍了高质量代码的特征、编程实践技巧和软件工程方法论。通过遵循这些原则和实践,程序员可以编写出更稳定、可维护和可扩展的代码。 一、 前言 写出高质量代码是每个程序员的追求和目标。高质量的代码可以使程…...
(最终篇))
MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)
目录 前言 几个高频面试题目 如何评价一个光源的好坏? 如何依靠光源增强图像对比度?...
【老王读SpringMVC-3】根据 url 是如何找到 controller method 的?
前面分析了 request 与 handler method 映射关系的注册,现在再来分析一下 SpringMVC 是如何根据 request 来获取对应的 handler method 的? 可能有人会说,既然已经将 request 与 handler method 映射关系注册保存在了 AbstractHandlerMethodMapping.Ma…...
人机交互到艺术设计及玫瑰花绘制实例
Python库之图形用户界面 Riverbank Computing | Introduction Welcome to wxPython! | wxPython Overview — PyGObject Python库之游戏开发 https://www.pygame.org/news Panda3D | Open Source Framework for 3D Rendering & Games python.cocos2d.org Python库之…...

多臂老虎机问题
1.问题简介 多臂老虎机问题可以被看作简化版的强化学习问题,算是最简单的“和环境交互中的学习”的一种形式,不存在状态信息,只有动作和奖励。多臂老虎机中的探索与利用(exploration vs. exploitation)问题一直以来都…...

DNS 查询原理详解
DNS(Domain Name System)是互联网上的一种命名系统,它将域名转换为IP地址。在进行DNS查询时,先要明确需要查询的主机名,然后向本地DNS服务器发出查询请求。 1. 本地DNS服务器查询 当用户在浏览器中输入一个URL或者点…...
浅谈软件测试工程师的技能树
软件测试工程师是一个历史很悠久的职位,可以说从有软件开发这个行业以来,就开始有了软件测试工程师的角色。随着时代的发展,软件测试工程师的角色和职责也在悄然发生着变化,从一开始单纯的在瀑布式开发流程中担任测试阶段的执行者…...

转型产业互联网,新氧能否再造辉煌?
近年来,“颜值经济”推动医美行业快速发展,在利润驱动下,除了专注医美赛道的企业之外,也有不少第三方互联网平台正强势进入医美领域,使以新氧为代表的医美企业面对不小发展压力,同时也展现出强大的发展韧性…...
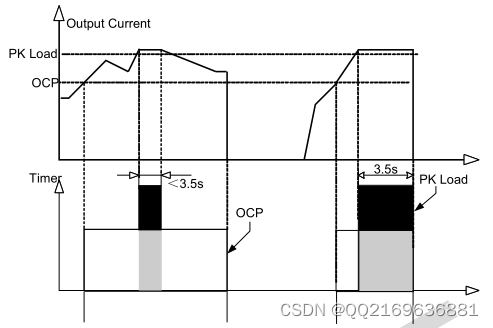
CRE66365 应用资料
CRE66365是一款高度集成的电流模式PWM控制IC,为高性能、低待机功耗和低成本的隔离型反激转换器。在正常负载条件下,AC输入高电压下工作在QR模式。为了最大限度地减少开关损耗,QR 模式下的最大开关频率被内部限制为 77kHz。当负载较低时&#…...
vue3快速上手学习笔记,还不快来看看?
Vue3快速上手 1.Vue3简介 2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王)耗时2年多、2600次提交、30个RFC、600次PR、99位贡献者github上的tags地址:https://github.com/vuejs/vue-next/release…...

HDU 5927 Auxiliary Set
原题链接: https://acm.hdu.edu.cn/showproblem.php?pid5927 题意: 有一颗根节点是1的树,其中有重要的点和不重要的点,重要的点需满足以下两个条件至少一个: 1.本来就是重要的点 2.是两个重要的点的最近共同祖先 有t…...

24:若所有参数皆需类型转换,请为此采用non-member函数
令class支持隐式类型转换通常是个糟糕的主意。 这条规则有其例外,最常见的例外是在建立数值类型时。 例,假设你设计一个class用来表现有理数,则允许整数“隐式转换”为有理数就很合理。 class Rational{ public:Rational(int numerator0,i…...
-详解-编译-安装-支持GDB-添加环境检查-添加版本号-生成安装包)
CMake(2)-详解-编译-安装-支持GDB-添加环境检查-添加版本号-生成安装包
目录 1.什么是CMake 1.1 编译流程CMakeLists.txt a) 最简单 demo1 b) 常用demo2 c) 单目录,源文件-输出文件 DIR_SRCS中 d)多目录,多源文件 1.2.执行命令: 1.3.自定义编译选项 2.安装和测试 3.支持GDB 4.添加环境检查 5.添加…...
)
java面试题(redis)
目录 1.redis主要消耗什么物理资源? 2.单线程为什么快 3.为什么要使用Redis 4.简述redis事务实现 5.redis缓存读写策略 6.redis除了做缓存,还能做些什么? 7.redis主从复制的原理 8.Redis有哪些数据结构?分别有哪些典型的应…...

Vue组件懒加载
组件懒加载 前言 组件懒加载最常用于异步加载大型/复杂组件或在需要时才进行加载 Vue 2和Vue 3均支持组件懒加载,本文将介绍如何在Vue 2和Vue 3中实现组件懒加载,和一些使用场景 1️⃣方法一:使用Webpack的代码分割能力 Vue 2和Vue 3都可以…...

Qt音视频开发42-网络推流(视频推流/本地摄像头推流/桌面推流/网络摄像头转发推流等)
一、前言 上次实现的文件推流,尽管优点很多,但是只能对现在存在的生成好的音视频文件推流,而现在更多的场景是需要将实时的视频流重新推流分发,用户在很多设备比如手机/平板/网页/电脑/服务器上观看,这样就可以很方便…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...