Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练
1、鸢尾花数据iris.csv

iris数据集是机器学习中一个经典的数据集,由英国统计学家Ronald Fisher在1936年收集整理而成。该数据集包含了3种不同品种的鸢尾花(Iris Setosa,Iris Versicolour,Iris Virginica)各50个样本,每个样本包含了花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)四个特征。
iris数据集的主要应用场景是分类问题,在机器学习领域中被广泛应用。通过使用iris数据集作为样本集,我们可以训练出一个分类器,将输入的新鲜鸢尾花归类到三种品种中的某一种。iris数据集的特征数据已经被广泛使用,也是许多特征选择算法和模型选择算法的基础数据集之一。
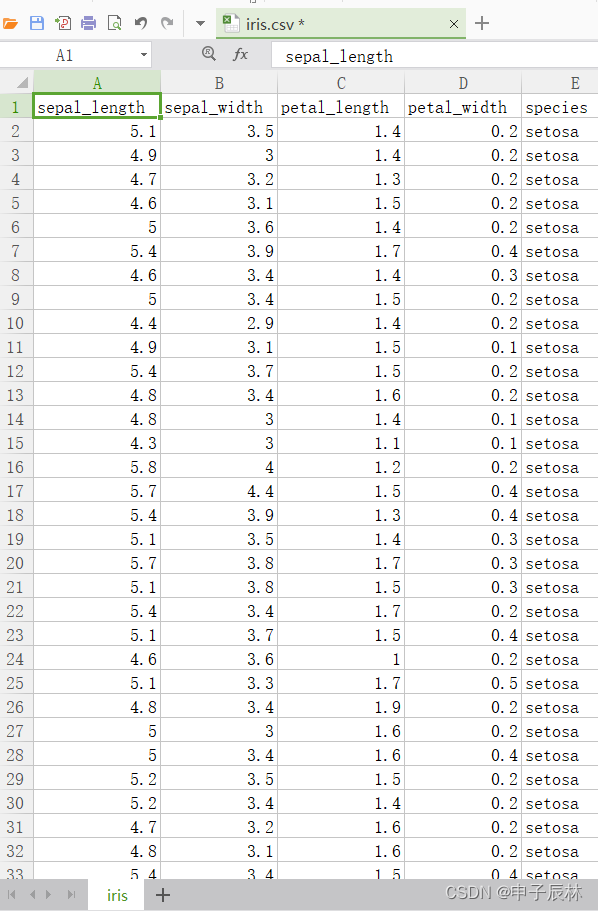
总共150条数据
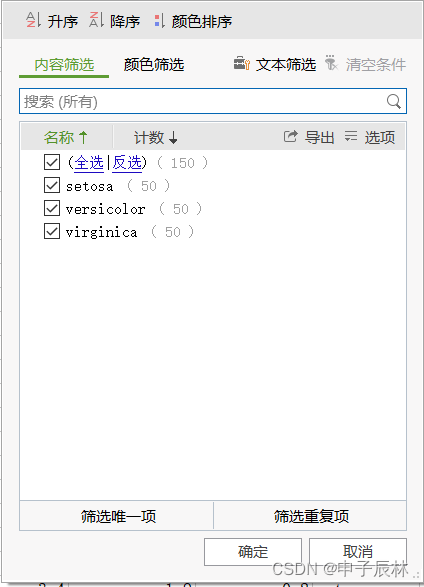
数据分布均匀,每种分类50条数据。
2、Transformer模型 CPU版本
# -*- coding:utf-8 -*-
import torch # 导入 PyTorch 库
from torch import nn # 导入 PyTorch 的神经网络模块
from sklearn import datasets # 导入 scikit-learn 库中的 dataset 模块
from sklearn.model_selection import train_test_split # 从 scikit-learn 的 model_selection 模块导入 split 方法用于分割训练集和测试集
from sklearn.preprocessing import StandardScaler # 从 scikit-learn 的 preprocessing 模块导入方法,用于数据缩放print("# 加载鸢尾花数据集")
# 加载鸢尾花数据集,这个数据集在机器学习中比较著名
iris = datasets.load_iris()
X = iris.data # 对应输入变量或属性(features),含有4个属性:花萼长度、花萼宽度、花瓣长度 和 花瓣宽度
y = iris.target # 对应目标变量(target),也就是类别标签,总共有3种分类print("拆分训练集和测试")
# 把数据集按照80:20的比例来划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)print("数据缩放")
# 对训练集和测试集进行归一化处理,常用方法之一是StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)print("数据转tensor类型")
# 将训练集和测试集转换为PyTorch的张量对象并设置数据类型
X_train = torch.tensor(X_train).float()
y_train = torch.tensor(y_train).long()
X_test = torch.tensor(X_test).float()
y_test = torch.tensor(y_test).long()# 定义 Transformer 模型
class TransformerModel(nn.Module):def __init__(self, input_size, num_classes):super(TransformerModel, self).__init__()# 定义 Transformer 编码器,并指定输入维数和头数self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_size, nhead=1)self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=1)# 定义全连接层,将 Transformer 编码器的输出映射到分类空间self.fc = nn.Linear(input_size, num_classes)def forward(self, x):# 在序列的第2个维度(也就是时间步或帧)上添加一维以适应 Transformer 的输入格式x = x.unsqueeze(1)# 将输入数据流经 Transformer 编码器进行特征提取x = self.encoder(x)# 通过压缩第2个维度将编码器的输出恢复到原来的形状x = x.squeeze(1)# 将编码器的输出传入全连接层,获得最终的输出结果x = self.fc(x)return xprint("创建模型")
# 初始化 Transformer 模型
model = TransformerModel(input_size=4, num_classes=3)print("定义损失函数和优化器")
# 定义损失函数(交叉熵损失)和优化器(Adam)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)print("训练模型")
# 训练模型,对数据集进行多次迭代学习,更新模型的参数
num_epochs = 100
for epoch in range(num_epochs):# 前向传播计算输出结果outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播,更新梯度并优化模型参数optimizer.zero_grad()loss.backward()optimizer.step()# 打印每10个epoch的loss值if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')print("测试模型")
# 测试模型的准确率
with torch.no_grad():# 对测试数据集进行预测,并与真实标签进行比较,获得预测outputs = model(X_test)_, predicted = torch.max(outputs.data, 1)accuracy = (predicted == y_test).sum().item() / y_test.size(0)print(f'Test Accuracy: {accuracy:.2f}')
控制台输出:
# 加载鸢尾花数据集
拆分训练集和测试
数据缩放
数据转tensor类型
创建模型
定义损失函数和优化器
训练模型
Epoch [10/100], Loss: 0.5863
Epoch [20/100], Loss: 0.3978
Epoch [30/100], Loss: 0.2954
Epoch [40/100], Loss: 0.1765
Epoch [50/100], Loss: 0.1548
Epoch [60/100], Loss: 0.1184
Epoch [70/100], Loss: 0.0847
Epoch [80/100], Loss: 0.2116
Epoch [90/100], Loss: 0.0941
Epoch [100/100], Loss: 0.1062
测试模型
Test Accuracy: 0.97
正确率97%
3、Transformer模型 GPU版本
# -*- coding:utf-8 -*-
import torch # 导入 PyTorch 库
from torch import nn # 导入 PyTorch 的神经网络模块
from sklearn import datasets # 导入 scikit-learn 库中的 dataset 模块
from sklearn.model_selection import train_test_split # 从 scikit-learn 的 model_selection 模块导入 split 方法用于分割训练集和测试集
from sklearn.preprocessing import StandardScaler # 从 scikit-learn 的 preprocessing 模块导入方法,用于数据缩放print("# 检查GPU是否可用")
# Check if GPU is available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print("# 加载鸢尾花数据集")
# 加载鸢尾花数据集,这个数据集在机器学习中比较著名
iris = datasets.load_iris()
X = iris.data # 对应输入变量或属性(features),含有4个属性:花萼长度、花萼宽度、花瓣长度 和 花瓣宽度
y = iris.target # 对应目标变量(target),也就是类别标签,总共有3种分类print("拆分训练集和测试")
# 把数据集按照80:20的比例来划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)print("数据缩放")
# 对训练集和测试集进行归一化处理,常用方法之一是StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)print("数据转tensor类型")
# 将训练集和测试集转换为PyTorch的张量对象并设置数据类型,加上to(device)可以运行在GPU上
X_train = torch.tensor(X_train).float().to(device)
y_train = torch.tensor(y_train).long().to(device)
X_test = torch.tensor(X_test).float().to(device)
y_test = torch.tensor(y_test).long().to(device)# 定义 Transformer 模型
class TransformerModel(nn.Module):def __init__(self, input_size, num_classes):super(TransformerModel, self).__init__()# 定义 Transformer 编码器,并指定输入维数和头数self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_size, nhead=1)self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=1)# 定义全连接层,将 Transformer 编码器的输出映射到分类空间self.fc = nn.Linear(input_size, num_classes)def forward(self, x):# 在序列的第2个维度(也就是时间步或帧)上添加一维以适应 Transformer 的输入格式x = x.unsqueeze(1)# 将输入数据流经 Transformer 编码器进行特征提取x = self.encoder(x)# 通过压缩第2个维度将编码器的输出恢复到原来的形状x = x.squeeze(1)# 将编码器的输出传入全连接层,获得最终的输出结果x = self.fc(x)return xprint("创建模型")
# 初始化 Transformer 模型
model = TransformerModel(input_size=4, num_classes=3).to(device)print("定义损失函数和优化器")
# 定义损失函数(交叉熵损失)和优化器(Adam)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)print("训练模型")
# 训练模型,对数据集进行多次迭代学习,更新模型的参数
num_epochs = 100
for epoch in range(num_epochs):# 前向传播计算输出结果outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播,更新梯度并优化模型参数optimizer.zero_grad()loss.backward()optimizer.step()# 打印每10个epoch的loss值if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')print("测试模型")
# 测试模型的准确率
with torch.no_grad():# 对测试数据集进行预测,并与真实标签进行比较,获得预测outputs = model(X_test)_, predicted = torch.max(outputs.data, 1)accuracy = (predicted == y_test).sum().item() / y_test.size(0)print(f'Test Accuracy: {accuracy:.2f}')
控制台输出:
# 检查GPU是否可用
# 加载鸢尾花数据集
拆分训练集和测试
数据缩放
数据转tensor类型
创建模型
定义损失函数和优化器
训练模型
Epoch [10/100], Loss: 0.6908
Epoch [20/100], Loss: 0.4861
Epoch [30/100], Loss: 0.3541
Epoch [40/100], Loss: 0.2136
Epoch [50/100], Loss: 0.2149
Epoch [60/100], Loss: 0.1263
Epoch [70/100], Loss: 0.1227
Epoch [80/100], Loss: 0.0685
Epoch [90/100], Loss: 0.1775
Epoch [100/100], Loss: 0.0889
测试模型
Test Accuracy: 0.97
正确率:97%
4、代码说明
在这段代码中,我们首先通过 torch.cuda.is_available() 检查GPU是否可用,如果GPU可用,则将计算转移到GPU,以便更快地训练模型。
然后使用 datasets.load_iris() 函数加载鸢尾花数据集。对于机器学习任务,我们通常会将数据集分成训练集和测试集,以便评估模型的性能。在本例中,使用 train_test_split() 方法将数据集分成训练集和测试集。
接下来,我们使用 StandardScaler 对数据进行缩放,以获得更好的模型性能。然后将数据集转换为PyTorch tensor格式,并使用 to() 将它们移动到GPU上(如果存在)。
然后定义了一个类名为 TransformerModel 的模型,并继承了 nn.Module。这个模型包括 TransformerEncoder 层、全局平均池化层和线性层。在这个模型中,输入是一组4维数值(表示鸢尾花的4种特征),输出需要有3个类别,因此最后一层的输出大小设置为3。
接下来,我们初始化模型并将其移动到GPU上,之后定义损失函数和优化器以进行模型的优化。在每个迭代步骤内进行前向传递、反向传递和梯度更新,同时打印出损失值以便调试和优化模型。经过若干次迭代后,我们使用测试集对模型进行测试,最后输出测试集的精度值。
相关文章:
Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练
1、鸢尾花数据iris.csv iris数据集是机器学习中一个经典的数据集,由英国统计学家Ronald Fisher在1936年收集整理而成。该数据集包含了3种不同品种的鸢尾花(Iris Setosa,Iris Versicolour,Iris Virginica)各50个样本&am…...

【运动规划算法项目实战】如何实现简单的状态机
文章目录 简介一、状态机1.1 简介1.2 原理介绍1.3 使用方法二、行为树2.1 简介2.2 原理介绍2.3 使用方法三、如何实现一个简单的状态机四、其他的决策模型简介四、总结简介 在机器人算法中,状态机和行为树是常用的两种设计模式。它们能够帮助机器人在复杂的环境中更好地执行任…...

JavaScript实现用while语句计算1+n的和的代码
以下为用while语句计算1n的和实现结果的代码和运行截图 目录 前言 一、实现用while语句计算1n的和 1.1运行流程及思想 1.2代码段 1.3 JavaScript语句代码 1.4运行截图 【附加】用while计算110的和 1.1代码段 1.3 运行截图 前言 1.若有选择,您可以在目录里…...
Three.js教程:顶点索引复用顶点数据
推荐:将 NSDT场景编辑器 加入你3D工具链 其他工具系列: NSDT简石数字孪生 顶点索引复用顶点数据 通过几何体BufferGeometry的顶点索引属性BufferGeometry.index可以设置几何体顶点索引数据,如果你有WebGL基础很容易理解顶点索引的概念&#…...
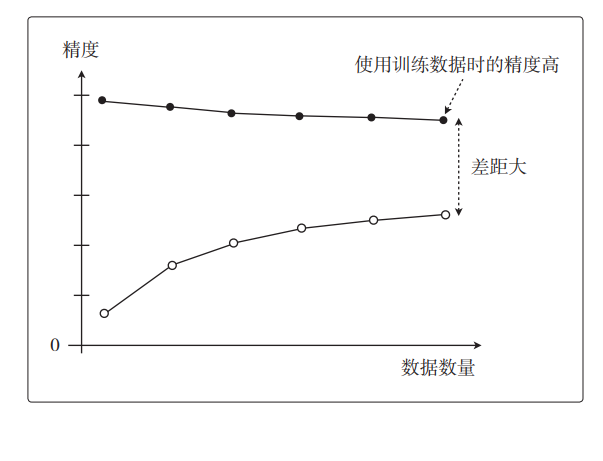
机器学习中的数学——学习曲线如何区别欠拟合与过拟合
通过这篇博客,你将清晰的明白什么是如何区别欠拟合与过拟合。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言&…...
【Java】类和对象,封装
目录 1.类和对象的定义 2.关键字new 3.this引用 4.对象的构造及初始化 5.封装 //包的概念 //如何访问 6.static成员 7.代码块 8.对象的打印 1.类和对象的定义 对象:Java中一切皆对象。 类:一般情况下一个Java文件一个类,每一个类…...

Python小姿势 - 知识点:
知识点: Python的字符串格式化 标题: Python字符串格式化实例解析 顺便介绍一下我的另一篇专栏, 《100天精通Python - 快速入门到黑科技》专栏,是由 CSDN 内容合伙人丨全站排名 Top 4 的硬核博主 不吃西红柿 倾力打造。 基础知识…...

【Python】【进阶篇】9、Django路由系统精讲
目录 Django路由系统精讲1. Django 路由系统应用1)配置第一个URL实现页面访问2)正则与正则分组使用3)正则捕获组使用 2. path()与re_path() Django路由系统精讲 在《URL是什么》一节中,我们对 URL 有了基本的认识,在本…...
在Linux操作系统上部署wgcloud监控
1.wgcloud监控介绍 1.1 介绍 这是一款开源的主机监控系统,可以支持主机各种指标监测(cpu使用率,cpu温度,内存使用率,磁盘容量空间,磁盘IO,硬盘SMART健康状态,系统负载ÿ…...

浙大的SAMTrack,自动分割和跟踪视频中的任何内容
Meta发布的SAM之后,Meta的Segment Anything模型(可以分割任何对象)体验过感觉很棒,既然能够在图片上面使用,那肯定能够在视频中应用,毕竟视频就是一帧一帧的图片的组合。 果不其然浙江大学就发布了这个SAMTrack,就是在…...
Spring第三方资源配置管理
Spring第三方资源配置管理 1. 管理DataSource连接池对象1.1 管理Druid连接池【重点】1.2 管理c3p0连接池 2. 加载properties属性文件【重点】2.1 基本用法2.2 配置不加载系统属性2.3 加载properties文件写法 说明:以管理DataSource连接池对象为例讲解第三方资源配置…...

网络编程代码实例:多进程版
文章目录 前言代码仓库内容代码(有详细注释)server.cclient.cMakefile 结果总结参考资料作者的话 前言 网络编程代码实例:多进程版。 代码仓库 yezhening/Environment-and-network-programming-examples: 环境和网络编程实例 (github.com)E…...

一家传统制造企业的上云之旅,怎样成为了数字化转型典范?
众所周知,中国是一个制造业大国。在想要上云以及正在上云的企业当中,传统制造企业也占据了相当大的比例。 那么这类企业在实施数字化转型的时候,应该如何着手?我们不妨来看看一家传统制造企业的现身说法。 国茂股份的数字化转型诉…...

C++入门(C++)
目录 命名空间 1、命名空间的定义 2、命名空间的使用 1、加名空间名称和作用域限定符 2、使用using namespace 命名空间引入 3、使用using将命名空间中某个成员引入 C的输入与输出 缺省参数 1、缺省参数的概念 2、缺省参数分类 1、全缺省参数 2、半缺省参数 函数重载 1、函数重…...

Linux 利用网络同步时间
yum -y install ntp ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ntpdate ntp1.aliyun.com 创建加入crontab echo "*/20 * * * * /usr/sbin/ntpdate -u ntp.api.bz >/dev/null &" >> /var/spool/cron/rootntp常用服务器 中国国家授…...

炫技亮点 SpringBoot下消灭If Else,让你的代码更亮眼
文章目录 背景案例第一阶段 萌芽第二阶段 屎上雕花第三阶段 策略工厂模式重构第四阶段 优化 总结 背景 大家好,我是大表哥laker。今天,我要和大家分享一篇关于如何使用策略模式和工厂模式消除If Else耦合问题的文章。这个方法能够让你的代码更加优美、简…...
免费ChatGPT接入网站-网站加入CHATGPT自动生成关键词文章排名
网站怎么接入chatGPT 要将ChatGPT集成到您的网站中,需要进行以下步骤: 注册一个OpenAI账户:访问OpenAI网站并创建一个账户。这将提供访问API密钥所需的身份验证凭据。 获取API密钥:在您的OpenAI控制台中,您可以找到您…...

PostgreSQL的数据类型有哪些?
数据类型分类 分类名称说明与其他数据库的对比布尔类型PG支持SQL标准的boolean数据类型与MySQL中的bool、boolean类型相同,占用1字节存储空间数值类型整数类型有2字节的smallint、4字节的int、8字节的bigint;精确类型的小数有numeric;非精确…...

Android 9.0 系统开机自启动第三方app
1.前言 在9.0的系统rom定制化开发中,在framework定制话的功能开发中,在内置的app中,有时候在系统开机以后会要求启动第三方app的功能,所以这就需要在监听开机完成的广播,然后在启动第三方app就可以了,接下来就需要在系统类中监听开机完成的广播流程来实现功能 2.系统开…...

一些想法:关于学习一门新的编程语言
很多人可能长期使用一种编程语言,并感到很有成就感和舒适感,发现学习一种新的编程语言的想法令人生畏而痛苦。或者可能知道并使用多种编程语言,但有一段时间没有学习新的语言。更或者可能只是好奇别人是如何潜心学习新的编程语言并迅速取得成…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...