微服务学习——分布式搜索
初识elasticsearch
什么是elasticsearch
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
elasticsearch的发展
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址: https://lucene.apache.orgl。
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
Lucene的缺点:
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
2004年Shay Banon基于Lucene开发了Compass
2010年Shay Banon重写了Compass,取名为Elasticsearch。
官网地址: https://www.elastic.co/cn/目前最新的版本是:8.7.0
相比与lucene,elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
为什么学习elasticsearch?
搜索引擎技术排名:
- Elasticsearch:开源的分布式搜索引擎
- Splunk:商业项目
- Solr: Apache的开源搜索引擎
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、
系统监控等功能
什么是elastic stack (ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
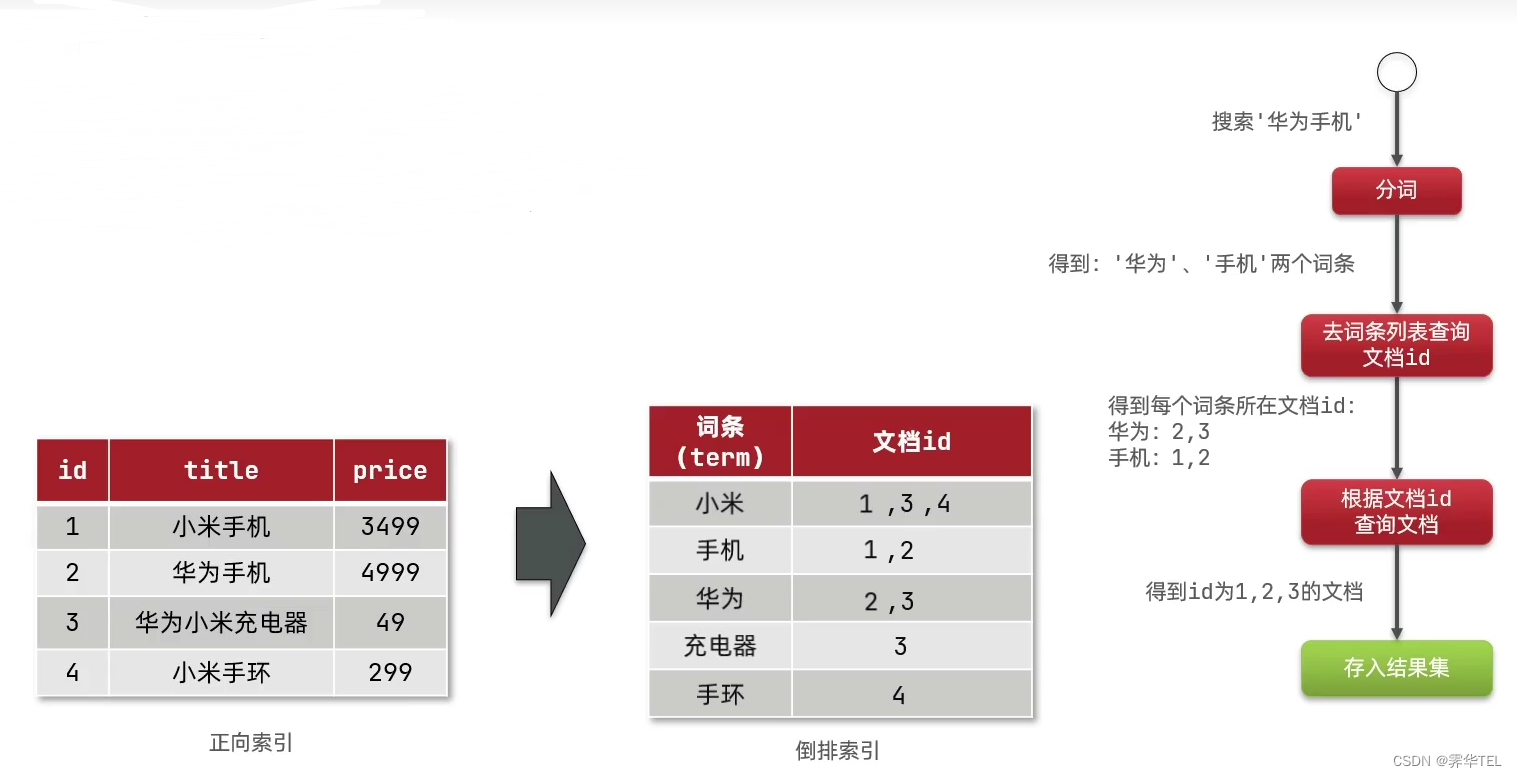
正向索引和倒排索引
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:

elasticsearch采用倒排索引:
- 文档( document) :每条数据就是一个文档
- 词条(term) :文档按照语义分成的词语
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包
含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。
索引(lndex)
- 索引(index) :相同类型的文档的集合
- 映射(mapping) :索引中文档的字段约束信息,类似表的结构约束

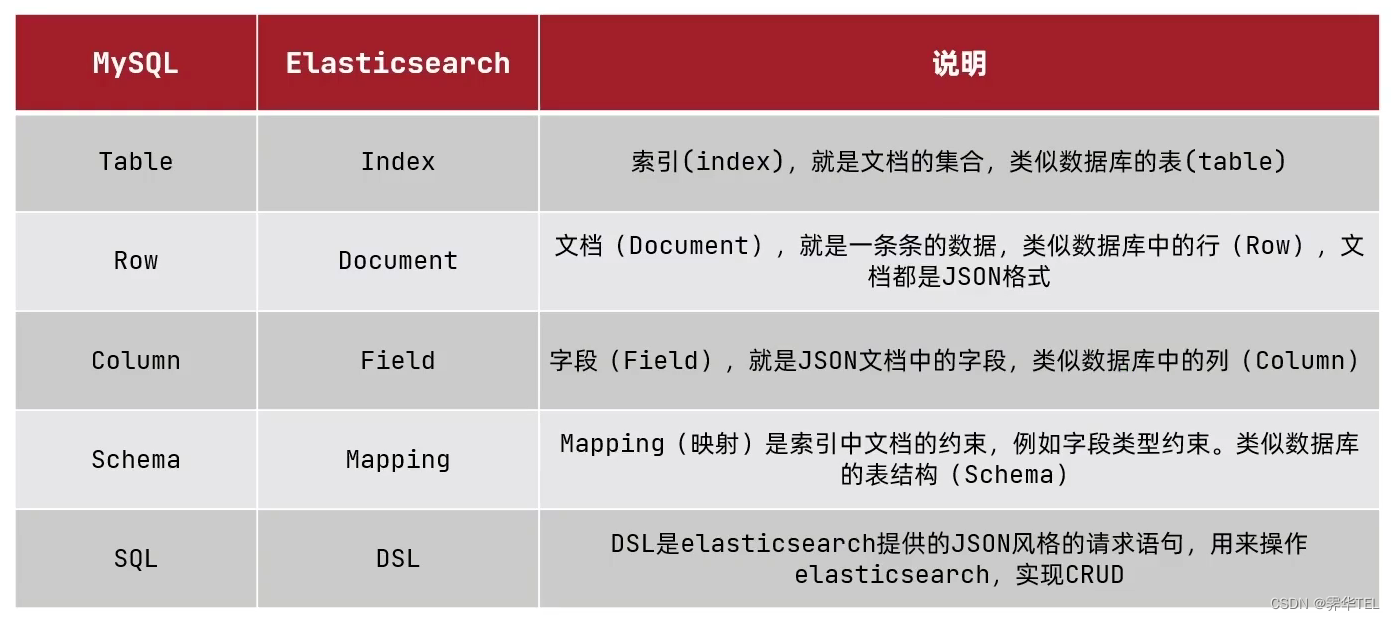
概念对比
架构
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算

- 文档:一条数据就是一个文档,es中是Json格式
- 字段:Json文档中的字段
- 索引:同类型文档的集合
- 映射:索引中文档的约束,比如字段名称、类型
elasticsearch与数据库的关系:
- 数据库负责事务类型操作
- elasticsearch负责海量数据的搜索、分析、计算
安装elasticsearch、kibana
1.部署单点es
1.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
1.2.加载镜像
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。将镜像上传到虚拟机中,然后运行命令加载即可:
# 导入数据
docker load -i es.tar
同理还有kibana的tar包也需要这样做。
1.3.运行
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
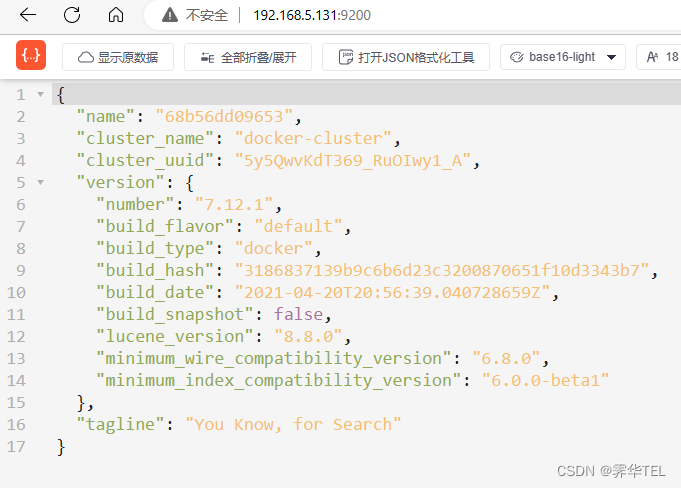
在浏览器中输入:http://ip地址:9200 即可看到elasticsearch的响应结果:
2.部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
2.1.部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

此时,在浏览器输入地址访问:http://ip地址:5601,即可看到结果
2.2.DevTools
kibana中提供了一个DevTools界面:
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
分词器
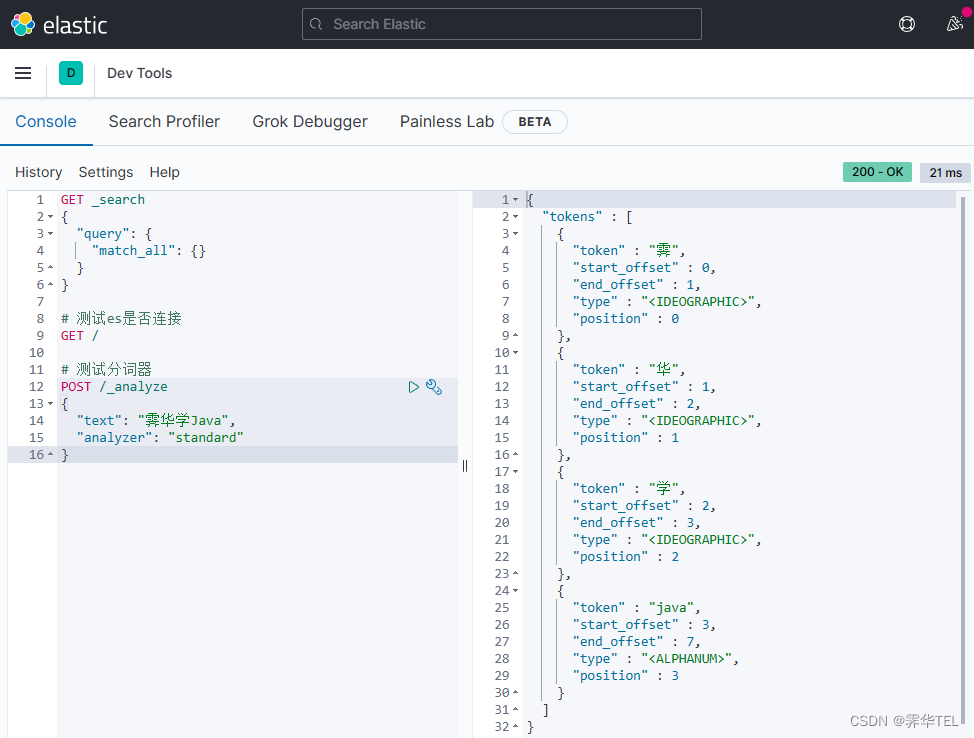
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。我们在kibana的DevTools中测试:
# 测试分词器
POST /_analyze
{"text": "霁华学Java","analyzer": "standard"
}
语法说明:
- POST:请求方式
- /_analyze:请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充
- 请求参数,json风格:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
处理中文分词,一般会使用IK分词器。https://github.com/medcl/elasticsearch-analysis-ik
安装IK分词器
1.在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
2.离线安装ik插件(推荐)
1)查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
[{"CreatedAt": "2023-04-29T04:11:49+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
2)解压缩分词器安装包
下面我们需要把ik分词器解压缩,重命名为ik
3)上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data :
4)重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
5)测试:
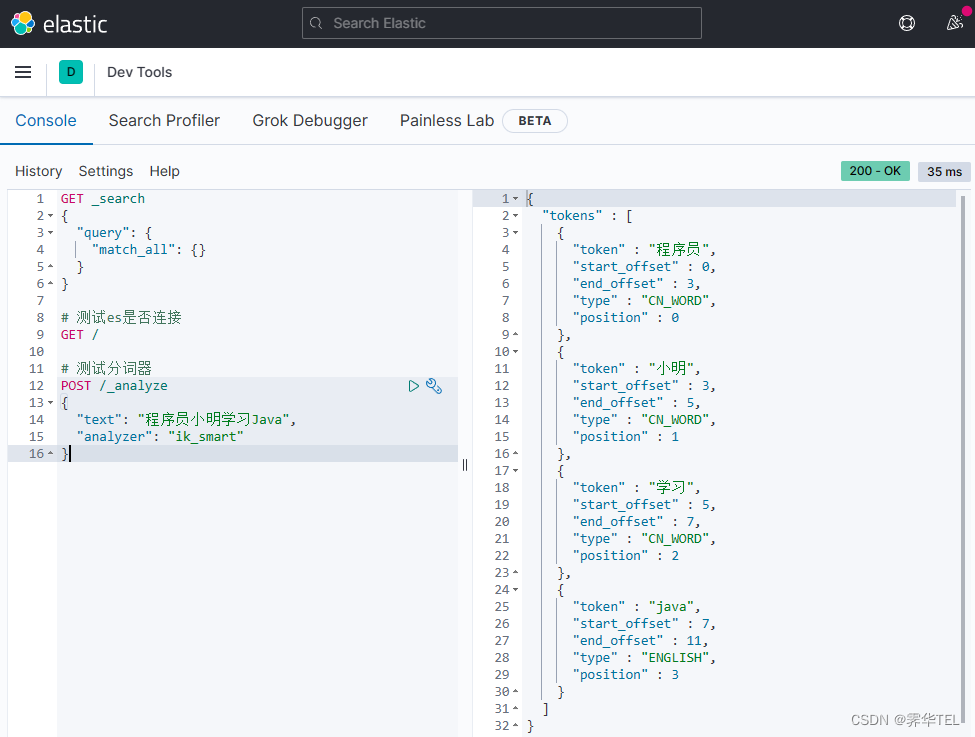
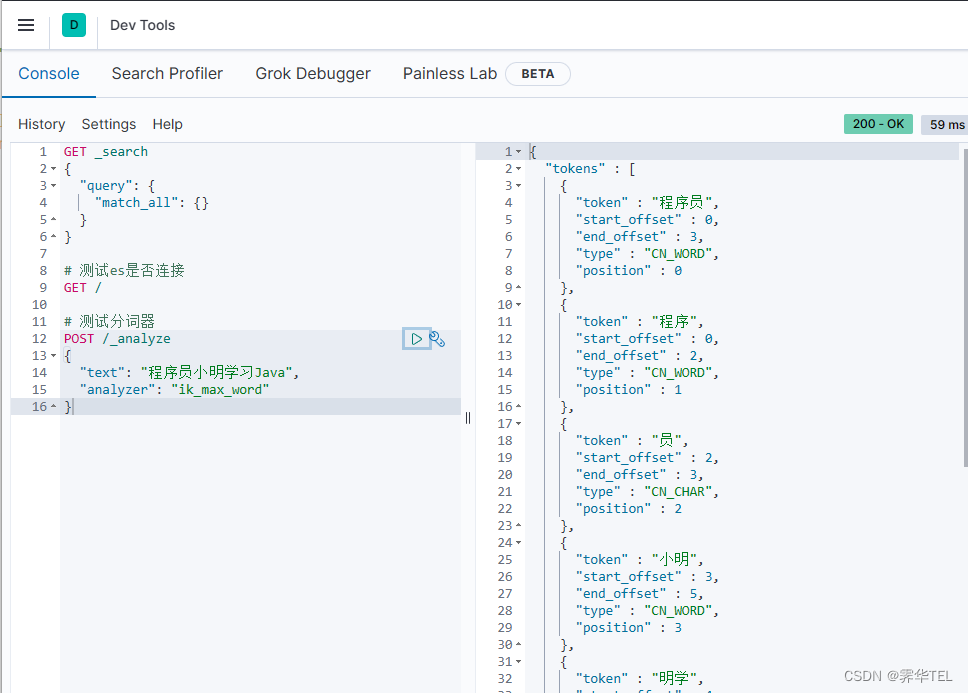
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
ik分词器-拓展词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IKAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry>
</properties>
然后在名为ext.dic的文件中,添加想要拓展的词语即可:
白嫖
鸡你太美
奥力给
ik分词器-停用词库
要禁用某些敏感词条,只需要修改一个ik分词器目录中的config目录中的IKAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.</entry>
</properties>
然后在名为stopword.dic的文件中,添加想要拓展的词语即可:
的
了
哦
嗯
啊
索引库操作
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串: text (可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔: boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:
{"mappings": {"properties": {"字段名": {"type": "text","analyzer ": "ik_smart"},"字段名2": {"type": "keyword","index": "false"},"字段名3": {"properties": {"子字段": {"type ": "keyword"}}},// ...略}}
}
例如:
# 创建索引库
PUT /jihua
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
查看、删除索引库
- 查看索引库语法:
GET /索引库名
- 删除索引库的语法:
DELETE /索引库名
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT/索引库名/ _mapping
{"properties" : {"新字段名":{"type" : "integer"}}
}
例如:
# 修改索引库
PUT /jihua/_mapping
{"properties": {"age": {"type": "integer"}}
}
文档操作
新增文档
新增文档的DSL语法如下:
POST /索引库名/_doc/文档id
{"字段1":"值1","字段2":"值2","字段3": {"子属性1":"值3","子属性2":"值4"},//...
}
例如:
# 插入文档
POST /jihua/_doc/1
{"info": "这里是介绍信息","email": "","name": {"firstName": "ji","lastName": "hua"},"age": 21
}
查询文档
查看文档语法:
GET /索引库名/_doc/文档id
删除文档
DELETE /索引库名/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档
# 修改文档
PUT /jihua/_doc/1
{"字段1":"值1","字段2":"值2",// ...略
}
方式二:增量修改,修改指定字段值
# 修改文档
POST /_update/_doc/1
{"doc":{"字段名":"新的值"}
}
RestClient操作索引库
什么是RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
官方文档地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html
案例
利用JavaRestClient实现创建、删除索引库,判断索引库是否存在
根据课前资料提供的酒店数据创建索引库,索引库名为hotel,mapping属性根据数据库结构定义。
基本步骤如下:
-
导入课前资料Demo
-
分析数据结构,定义mapping属性
mapping要考虑的问题:
字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?ES中支持两种地理坐标数据类型:
- geo_point:由纬度(latitude)和经度( longitude)确定的一个点。例如:“32.8752345,120.2981576”
- geo_shape:有多个geo_point组成的复杂几何图形。例如一条直线,
“LINESTRING (-77.03653 38.897676,-77.009051 38.889939)”
字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段。示例:
"all": {"type" : "text","analyzer" : "ik_max_word" }, "brand": {"type " : "keyword","copy_to": "all" }最终的mapping:
# 酒店的mapping PUT /hotel {"mappings": {"properties": {"id": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword","copy_to": "all"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"business": {"type": "keyword","copy_to": "all"},"location": {"type": "geo_point"},"pic": {"type": "keyword","index": false},"all": {"type": "text","analyzer": "ik_max_word"}}} } -
初始化JavaRestClient
-
引入es的RestHighLevelclient依赖:
<!--elasticsearch--> <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version> </dependency> -
因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version> </properties> -
初始化RestHighLevelClient:
package cn.itcast.hotel;import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient client;@Testvoid testInit() {System.out.println(client);}@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.5.131:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();} }
-
-
利用JavaRestClient创建索引库
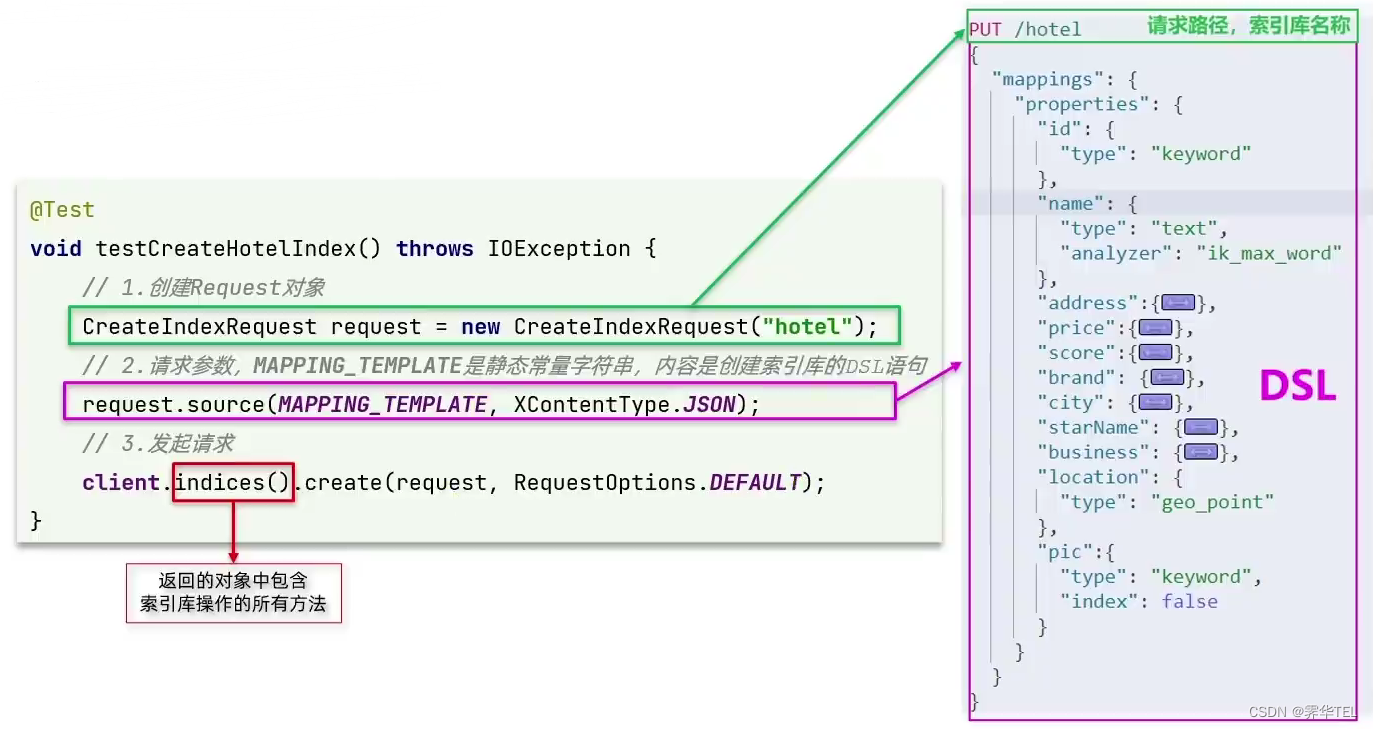
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\": {\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\": {\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\": {\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"starName\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\": {\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\": {\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
@Test
void createHotelIndex() throws IOException {//1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");//2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);//3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
-
利用JavaRestClient删除索引库
@Test void testDeleteHotelIndex() throws IOException {//1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");//2.发送请求client.indices().delete(request, RequestOptions.DEFAULT); } -
利用JavaRestClient判断索引库是否存在
@Test void testExistsHotelIndex() throws IOException {//1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");//2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);//3.输出System.err.println(exists?"索引库已经存在!" : "索引库不存在!"); }
RestClient操作文档
案例1
利用JavaRestClient实现文档的CRUD
去数据库查询酒店数据,导入到hotel索引库,实现酒店数据的CRUD。基本步骤如下:
-
初始化JavaRestClient
新建一个测试类,实现文档相关操作,并且完成JavaRestClient的初始化
public class ElasticsearchDocumentTest {//客户端private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.5.131:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();} } -
利用JavaRestClient新增酒店数据
先查询酒店数据,然后给这条数据创建倒排索引,即可完成添加:
@Test void testAddDocument() throws IOException {//根据id查询酒店数据Hotel hotel = hotelService.getById(61083L);//转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);//1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());//2.准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);//3.发送请求client.index(request, RequestOptions.DEFAULT); } -
利用JavaRestClient根据id查询酒店数据
根据id查询到的文档数据是json,需要反序列化为java对象:
@Test void testGetDocumentById() throws IOException {//1.创建request对象GetRequest request = new GetRequest("hotel", "61083");//2.发送请求,得到结果GetResponse response = client.get(request, RequestOptions.DEFAULT);//3.解析结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc); } -
利用JavaRestClient删除酒店数据
修改文档数据有两种方式:
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档(同新增)
方式二:局部更新。只更新部分字段:
@Test void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("hotel", "61083");// 2.准备请求参数request.doc("price", "952","starName", "四钻");// 3.发送请求client.update(request, RequestOptions.DEFAULT); } -
利用lavaRestClient修改酒店数据
@Test void testDeleteDocument() throws IOException {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", "61083");// 2.发送请求client.delete(request, RequestOptions.DEFAULT); }
案例2
利用JavaRestClient批量导入酒店数据到ES
需求:批量查询酒店数据,然后批量导入索引库中
思路:
- 利用mybatis-plus查询酒店数据
- 将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
- 利用JavaRestClient中的Bulk批处理,实现批量新增文档
@Test
void testBulkRequest() throws IOException {//批量查询数据库List<Hotel> hotels = hotelService.list();// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备参数,添加多个新增的Requestfor (Hotel hotel : hotels) {//转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);//创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
t
DeleteRequest request = new DeleteRequest(“hotel”, “61083”);
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
## 案例2利用JavaRestClient**批量导入**酒店数据到ES需求:批量查询酒店数据,然后批量导入索引库中
思路:1. 利用mybatis-plus查询酒店数据
2. 将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
3. 利用JavaRestClient中的Bulk批处理,实现批量新增文档```java
@Test
void testBulkRequest() throws IOException {//批量查询数据库List<Hotel> hotels = hotelService.list();// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备参数,添加多个新增的Requestfor (Hotel hotel : hotels) {//转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);//创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
相关文章:
微服务学习——分布式搜索
初识elasticsearch 什么是elasticsearch elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。 elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域…...
ChatGPT根据销售数据、客户反馈、财务报告,自动生成报告,并根据不同利益方的需要和偏好进行调整?
该场景对应的关键词库(24个): 汇报对象身份(下属、跨部门平级、领导)、销售数据(销售额、销售量、销售渠道)、财务报告(营业收入、净利润、成本费用)、市场分析…...
Flask开发之环境搭建
目录 1、安装flask 2、创建Flask工程 编辑 3、初始化效果 4、运行效果 5、设置Debug模式 6、设置Host 7、设置Port 8、在app.config中添加配置 1、安装flask 如果电脑上从没有安装过flask,则在命令行界面输入以下命令: pip install flask 如果电…...

Java集合框架与ArrayList、LinkedList的区别
文章目录 Java集合框架与ArrayList、LinkedList的区别集合框架ArrayList特点操作 LinkedList特点操作 区别代码实践注意事项 Java集合框架与ArrayList、LinkedList的区别 在Java中,集合框架是非常重要的一部分。集合框架提供了各种数据结构和算法,可以方…...

python-pandas库
目录 目录 目录 1.pandas库简介(https://www.gairuo.com/p/pandas-overview) 2.pandas库read_csv方法(https://zhuanlan.zhihu.com/p/340441922?utm_mediumsocial&utm_oi27819925045248) 1.pandas库简介(http…...
C++学习day--01 C生万物
1、C/C学习中遇到的问题: 1. 大部分初学者,学习 C/C 都是从入门到放弃。 C/C太难吗? 2. 90% 以上的初学者,学完 C/C 以后,考试完了,书看完了, 但还是不会做项目 是学的不够好吗࿱…...

链表及链表的常见操作和用js封装一个链表
最近在学数据结构和算法,正好将学习的东西记录下来,我是跟着一个b站博主学习的,是使用js来进行讲解的,待会也会在文章后面附上视频链接地址,大家想学习的可以去看看 本文主要讲解单向链表,双向链表后续也会…...

源码安装工具checkinstall使用
每当从源码包编译程序时,安装过程很愉快,但当你想删除时,就很费脑筋了,你可能要去找你当时编译的目录执行make unistall,当然更可能的是,你早就把源码包给删除了,对于强迫症来说,这显…...
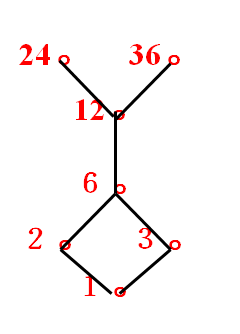
离散数学集合论
集合论 主要内容 集合基本概念 属于、包含幂集、空集文氏图等 集合的基本运算 并、交、补、差等 集合恒等式 集合运算的算律,恒等式的证明方法 集合的基本概念 集合的定义 集合没有明确的数学定义 理解:由离散个体构成的整体称为集合,…...

TypeScript 基础
类型注解 类型注解:约束变量的类型 示例代码: let age:number 18 说明:代码中的 :number 就是类型注解 解释:约定了类型,就只能给变量赋值该类型的值,否则,就会报错 错误演示:…...

MySQL InnoDB引擎 和 Oracle SGA
MySQL InnoDB引擎和Oracle SGA有以下异同: 异同点: 两者都是用来管理数据存储和访问的。 它们都可以通过调整参数来优化性能。 它们都支持事务处理和ACID属性。 它们都可以通过备份和恢复来保护数据。 异点: MySQL InnoDB引擎是一种存储…...
JAVA开发与运维(web生产环境部署)
web生产环境部署,往往是分布式,和开发环境或者测试环境我们一般使用单机不同。 一、部署内容 1、后端服务 2、后台管理系统vue 3、小程序 二、所需要服务器 5台前端服务器 8台后端服务 三、所需要的第三方组件 redismysqlclbOSSCDNWAFRocketMQ…...

普通人,自学编程,5个必备步骤
天给大家分享个干货哈 普通人自学编程 想学成找到一份工作甚至进大厂 非常有效且必备的5个步骤 文章最后 还给大家提供了一些免费的学习资料 记得提前收藏起来 相信很多人在最开始学编程的时候 上来就是去网上找一套视频 或者买一本书直接开干 这种简单粗暴的方法其实是不对的 …...

kubernetes安全框架RBAC
目录 一、Kubernetes 安全概述 二、鉴权、授权和准入控制 2.1 鉴权(Authentication) 2.2 授权(Authorization) 2.3 准入控制 三、基于角色的权限访问控制: RBAC 四、案例:为指定用户授权访问不同命名空间权限 一、Kubernetes 安全概述 K8S安全控…...
)
【大数据面试题大全】大数据真实面试题(持续更新)
【大数据面试题大全】大数据真实面试题(持续更新) 1)Java1.1.Java 中的集合1.2.Java 中的多线程如何实现1.3.Java 中的 JavaBean 怎么进行去重1.4.Java 中 和 equals 有什么区别1.5.Java 中的任务定时调度器 2)SQL2.1.SQL 中的聚…...

Linux [常见指令 (1)]
Linux常见指令 ⑴ 1. 操作系统1.1什么事操作系统1.2选择指令的原因 2.使用工具3.Linux的指令操作3.1mkdir指令描述:用法:例子 mkdir 目录名例子 mkdir -p 目录1/ 目录2/ 目录3 3.2 touch指令描述:用法:例子 touch 文件 3.2pwd指令描述:用法:例子 pwd 3.4cd指令描述:用法:例子 c…...
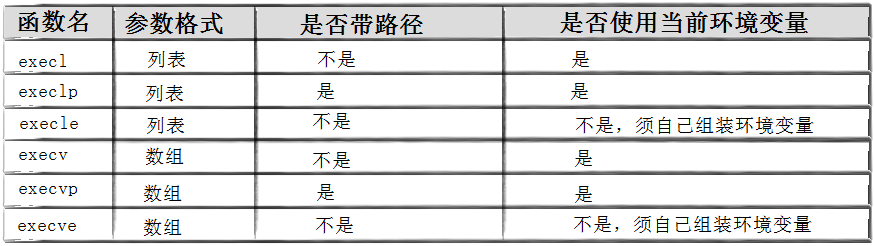
进程控制下篇
进程控制下篇 1.进程创建 1.1认识fork / vfork 在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程 #include<unistd.h> int main() {pid_t i fork;return 0; }当前进程调用fork,…...

PS学习笔记(零基础PS学习教程)
很多新手学习PS不知从何下手,做设计的第一阶段肯定是打牢基础,把工具用熟练;本期特别为大家整理了PS入门的学习笔记,把每个工具的用法整理了下来,在使用过程中有哪里不清楚的可以翻看来看看~ 一、ps的工作界面的介绍 …...

如何构建数据血缘系统
1、明确需求,确定边界 在进行血缘系统构建之前,需要进行需求调研,明确血缘系统的主要功能,从而确定血缘系统的最细节点粒度,实体边界范围。 例如节点粒度是否需要精确到字段级,或是表级。一般来说&#x…...

IPsec中IKE与ISAKMP过程分析(主模式-消息3)
IPsec中IKE与ISAKMP过程分析(主模式-消息1)_搞搞搞高傲的博客-CSDN博客 IPsec中IKE与ISAKMP过程分析(主模式-消息2)_搞搞搞高傲的博客-CSDN博客 阶段目标过程消息IKE第一阶段建立一个ISAKMP SA实现通信双发的身份鉴别和密钥交换&…...

Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器
Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器 1. 引言 做视频的朋友们,不知道你们有没有过这样的经历:用AI工具生成了视频字幕,时间轴对得总差那么一点,要么是话还没说完字幕就跳了,要么是沉默…...

告别Zabbix!轻量级监控神器Netdata在Ubuntu 22.04上的花式玩法
告别Zabbix!轻量级监控神器Netdata在Ubuntu 22.04上的花式玩法 1. 为什么Netdata正在重新定义监控体验 凌晨三点,服务器告警短信惊醒睡梦中的你。手忙脚乱连上VPN,却发现只是Zabbix又一个误报——这样的场景是否似曾相识?传统监控…...

【自动驾驶】从贝叶斯到卡尔曼:线性滤波的数学之美与实践之路
1. 贝叶斯概率:理解不确定性的语言 想象你正在雾天开车,前方隐约有个模糊的影子。你的大脑会快速判断:那可能是一个行人(60%概率),也可能只是路标(40%概率)。这种在不确定环境中做判…...

WAF工程师实战笔记:如何用Suricata规则精准识别哥斯拉、冰蝎、蚁剑的Webshell流量
WAF工程师实战笔记:Suricata规则精准识别主流Webshell流量 在安全运维的日常工作中,Webshell流量的检测始终是一场攻防对抗的持久战。面对哥斯拉、冰蝎、蚁剑等主流Webshell管理工具不断升级的流量混淆技术,传统的特征匹配方法往往力不从心。…...

nlp_structbert_sentence-similarity_chinese-large赋能微信小程序:实现文本查重功能
nlp_structbert_sentence-similarity_chinese-large赋能微信小程序:实现文本查重功能 最近和一位做在线教育的朋友聊天,他提到一个挺头疼的问题:批改学生作文时,经常发现不同学生提交的作业内容高度相似,甚至有大段雷…...

Xinference-v1.17.1GPU算力优化:显存自动分片+KV Cache压缩,72B模型显存占用降40%
Xinference v1.17.1 GPU算力优化:显存自动分片KV Cache压缩,72B模型显存占用降40% 1. 引言:大模型部署的显存困境与曙光 如果你尝试过在单张消费级显卡上部署一个超过70B参数的大语言模型,大概率会看到一个熟悉的错误提示&#…...

AudioSeal实战教程:Python API调用AudioSeal模型实现批量音频水印处理
AudioSeal实战教程:Python API调用AudioSeal模型实现批量音频水印处理 1. 项目概述与核心价值 AudioSeal是Meta开源的专业级音频水印系统,专门用于AI生成音频的检测和溯源。这个工具能帮助内容创作者、平台运营者和版权方解决一个关键问题:…...

手把手教你用MusePublic:快速生成艺术感时尚人像的保姆级教程
手把手教你用MusePublic:快速生成艺术感时尚人像的保姆级教程 你是不是也曾经被那些充满艺术感的时尚人像照片惊艳到,心里想着“要是我也能做出这样的作品就好了”?但一看到复杂的AI绘画工具,光是安装部署就让人头大,…...

造相Z-Image文生图模型快速试用:10秒生成高清图片,简单易用
造相Z-Image文生图模型快速试用:10秒生成高清图片,简单易用 1. 快速体验:10秒生成你的第一张AI画作 1.1 一键部署模型 在CSDN星图镜像市场找到"造相 Z-Image 文生图模型(内置模型版)v2"镜像,点…...

零知识证明终极指南:Awesome ZKP项目快速入门教程
零知识证明终极指南:Awesome ZKP项目快速入门教程 【免费下载链接】awesome-zero-knowledge-proofs A curated list of awesome things related to learning Zero-Knowledge Proofs (ZKP). 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-zero-knowledge-p…...