Xpath学习笔记
Xpath原理:先将HTML文档转为XML文档,再用xpath查找HTML节点或元素
什么是xml?
1、xml指可扩展标记语言
2、xml是一种标记原因,类似于html
3、xml的设计宗旨是传输数据,而非显示数据
4、xml标签需要我们自己自定义
5、xml被设计为具有自我描述性
xml和html的区别?
1、xml被设计为传输和存储数据,其焦点是数据的内容
2、html是显示数据以及如何更好的显示数据
# xml文档示例
# 这里面的标签都是自定义的
<?xml version="1.0" encoding="utf-8"?>
<bookstore><book category="cooking"><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price></book><book category="children"><title lang="en">Harry Potter</title><author>J K. Rowing</author><year>2005</year><price>29.99</price></book><book category="web"><title lang="en">XQuery Kick Start</title><author>James McGovern</author><author>Per Bothner</author><author>Kurt Cagle</author><author>James Linn</author><year>2005</year><price>49.99</price></book><book category="web" cover="paperback"><title lang="en">Learning XML</title><author>Erik T. Ray</author><year>2003</year><price>39.95</price></book></bookstore>
1、父(parent)
每个元素及属性都有一个父
下面xml例子中,book元是title,author,year,price元素的父
<?xml version="1.0" encoding="utf-8"?><book><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price>
</book>
2、子(children)
元素节点可能有零个,一个或者多个子
在下面的例子中title,author,year,price都是book元素的子
<?xml version="1.0" encoding="utf-8"?><book><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price>
</book>
3、同胞(sibling)
拥有相同的父的节点
在下面例子中title,author,year,price元素都是同胞
<?xml version="1.0" encoding="utf-8"?><book><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price>
</book>
4、先辈(ancestor)
某节点的父、父的父,等等
下面例子中,title元素的先辈是book和bookstore
<?xml version="1.0" encoding="utf-8"?><bookstore><book><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price>
</book></bookstore>
5、后代
某节点的子,子的子,等等
下面例子中,bookstore后代是book,title,author,year,price元素
<?xml version="1.0" encoding="utf-8"?><bookstore><book><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price>
</book></bookstore>
什么是xpath
xpath(xml path language)是一门在xml文档中查找信息的语言,可以用来在xml文档对元素和属性进行遍历
xml path language:xml路径语言
选取节点
xpath使用路径表达式来选取xml文档中的节点或者节点集,这些路径表达式和我们在常规表达式和我们在常规的电脑文件系统里看到的表达式非常相似
下面列出了最常用的路径表达式:
表达式 描述
nodename 选取此节点的所有子节点
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置
. 选取当前节点
… 选取当前节点的父节点
@ 选取属性
在下面表格中,我们列出了一些路径表达式以及表达式的结果:
bookstore 选取bookstore元素的所有子节点
/bookstore 选取根元素bookstore。注释:假如路径起始于正斜杠(/)则此路径始终代表到某元素的绝对路径
bookstore/book 选取属于bookstore的子元素的所有book元素
//book 选取所有book子元素,而不管他们在文档中的位置
bookstore//book 选取属于bookstore元素的后代的所有book元素,而不管他们位于bookstore之下的什么位置
…@lang 选取名为lang的所有属性
选取位置节点
xpath通配符可用来选取未知的xml元素
通配符 描述
-
匹配任何元素的节点
@* 匹配任何属性的节点
node() 匹配任何类型的节点
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果
/bookstore/* 选取bookstore元素的所有子节点
//* 选取文档中的所有元素
html/node()/meta/@* 选取HTML下面任意节点下的meta节点的所有属性
//title[@*] 选取所有带有属性的title元素
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果
路径表达式 结果
//book/title|//book/price 选取book元素的所有title和price元素
//title|//price 选取文档中的所有title和price元素
/bookstore/book/title|//price 选取属于bookstore元素的book元素的所有title元素,以及文档中的所有price元素
这些就是xpath的语法内容妙哉运用到python抓取是要先转换为xml
lxml库
1、lxml库是一个HTML/xml的解析器,主要功能是如何解析和提取HTML/xml数据
2、lxml和正则一样,都是通过c语言实现的,他是一款高性能的python html/xml的解析器,我们可以利用之前所学习的xpath语法,来快速定位特定元素以及节点信息
3、lxml python 的官方文档:http://lxml.de/index/html
4、需要安装c语言库 pip install lxml
初步使用
我们利用它来解析HTML代码,简单示例:
html = '''
<div class="Sq_leftNav_forum"><ul class="Sq_lineBox Sq_leftNav_forumList"><li><a href="/shuo/forum/00B002">找对象</a></li><li><a href="/shuo/forum/001002">新鲜事</a></li><li><a href="/shuo/forum/001004">同城互助</a></li><li><a href="/shuo/forum/007005">同城活动</a></li><li><a href="/shuo/forum/00D001">虞城有爱</a></li><li><a href="/shuo/forum/010004">二手闲置</a></li><li><a href="/shuo/forum/010001">找工作</a></li><li><a href="/shuo/forum/00B001">情感</a></li><li><a href="/shuo/forum/002001001">美食</a></li></ul>
</div>
'''
# 使用lxml的etree模块
from lxml import etree# 利用etree.HTML()构造一个xpath解析对象(转为xml文档)
xml_doc = etree.HTML(html)
# print(xml_doc)# etree.tostring()输出修正后的HTML代码
html_doc = etree.tostring(xml_doc)
# print(html_doc) # 自动补全了body,html标签
# print(type(html_doc)) # bytes类型print(html_doc.decode('utf-8')) # 利用decode()方法将其转成str类型
print(type(html_doc.decode('utf-8')))
<html><body><div class="Sq_leftNav_forum"><ul class="Sq_lineBox Sq_leftNav_forumList"><li><a href="/shuo/forum/00B002">找对象</a></li><li><a href="/shuo/forum/001002">新鲜事</a></li><li><a href="/shuo/forum/001004">同城互助</a></li><li><a href="/shuo/forum/007005">同城活动</a></li><li><a href="/shuo/forum/00D001">虞城有爱</a></li><li><a href="/shuo/forum/010004">二手闲置</a></li><li><a href="/shuo/forum/010001">找工作</a></li><li><a href="/shuo/forum/00B001">情感</a></li><li><a href="/shuo/forum/002001001">美食</a></li></ul>
</div>
</body></html>
<class 'str'>
文件读取
除了直接读取字符串,lxml还支持从文件里读取内容,我们新建一个hello.html
from lxml import etree
# etree.parse()读取外部文件
html = etree.parse('./hello.html')
# print(type(html))
# print(html)# 调用tostring()方法即可输出修正后的HTML代码
result = etree.tostring(html)
# print(result)
print(result.decode('utf-8'))
<div class="Sq_leftNav_forum"><ul class="Sq_lineBox Sq_leftNav_forumList"><li><a href="/shuo/forum/00B002">找对象</a></li><li><a href="/shuo/forum/001002">新鲜事</a></li><li><a href="/shuo/forum/001004">同城互助</a></li><li><a href="/shuo/forum/007005">同城活动</a></li><li><a href="/shuo/forum/00D001">虞城有爱</a></li><li><a href="/shuo/forum/010004">二手闲置</a></li><li><a href="/shuo/forum/010001">找工作</a></li><li><a href="/shuo/forum/00B001">情感</a></li><li><a href="/shuo/forum/002001001">美食</a></li></ul>
</div>
html = '''
<div><ul><li class="Sq_leftNav_forum1"><a href="/shuo/forum/00B002">找对象</a></li><li class="Sq_leftNav_forum2"><a href="/shuo/forum/001002">新鲜事</a></li><li class="Sq_leftNav_forum1"><a href="/shuo/forum/001004">同城互助</a></li><li class="Sq_leftNav_forum2"><a href="/shuo/forum/007005">同城活动</a></li><li class="Sq_leftNav_forum1"><a href="/shuo/forum/00D001">虞城有爱</a></li></ul>
</div>
'''
from lxml import etreehtml_doc = etree.HTML(html) # xml
result = html_doc.xpath('//li')
# print(result)
for i in result:r = etree.tostring(i).decode('utf-8')print(r)
<li class="Sq_leftNav_forum1"><a href="/shuo/forum/00B002">找对象</a></li><li class="Sq_leftNav_forum2"><a href="/shuo/forum/001002">新鲜事</a></li><li class="Sq_leftNav_forum1"><a href="/shuo/forum/001004">同城互助</a></li><li class="Sq_leftNav_forum2"><a href="/shuo/forum/007005">同城活动</a></li><li class="Sq_leftNav_forum1"><a href="/shuo/forum/00D001">虞城有爱</a></li>
2、继续获取
- 标签的所有class属性
-
html_doc = etree.HTML(html) # xml result = html_doc.xpath('//li/@class') print(result)['Sq_leftNav_forum1', 'Sq_leftNav_forum2', 'Sq_leftNav_forum1', 'Sq_leftNav_forum2', 'Sq_leftNav_forum1']3、获取
- 标签下的标签里的所有href
-
html_doc = etree.HTML(html) # xml result = html_doc.xpath('//li/a/@href') print(result)['/shuo/forum/00B002', '/shuo/forum/001002', '/shuo/forum/001004', '/shuo/forum/007005', '/shuo/forum/00D001']4、继续获取
- 标签下href为/shuo/forum/00B002的标签的文本内容
-
html_doc = etree.HTML(html) # xml result = html_doc.xpath('//li/a[@href="/shuo/forum/00B002"]/text()') print(result)['找对象']注意:只要涉及到条件,加[]
只要获取属性值,加@
通过text()取内容
相关文章:

Xpath学习笔记
Xpath原理:先将HTML文档转为XML文档,再用xpath查找HTML节点或元素 什么是xml? 1、xml指可扩展标记语言 2、xml是一种标记原因,类似于html 3、xml的设计宗旨是传输数据,而非显示数据 4、xml标签需要我们自己自定义 5、x…...
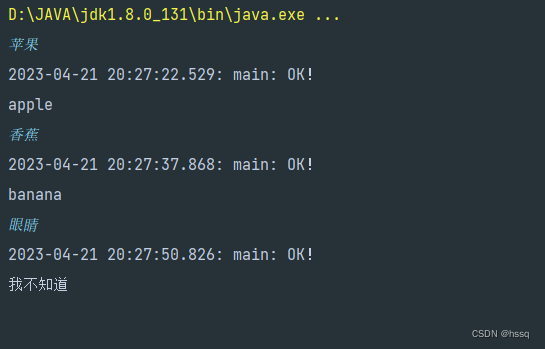
网络编程之 Socket 套接字(使用数据报套接字和流套接字分别实现一个小程序(附源码))
文章目录 1. 什么是网络编程2. 网络编程中的基本概念1)发送端和接收端2)请求和响应3)客户端和服务端4)常见的客户端服务端模型 3. Socket 套接字1)Socket 的分类2)Java 数据报套接字通信模型3)J…...

What Are Docker Image Layers?
Docker images consist of multiple layers that collectively provide the content you see in your containers. But what actually is a layer, and how does it differ from a complete image? In this article you’ll learn how to distinguish these two concepts and…...

范数详解-torch.linalg.norm计算实例
文章目录 二范数F范数核范数无穷范数L1范数L2范数 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 范数是一种数学概念,可以将向量或矩阵映射到非负实数上,通常被…...

postgresdb备份脚本
以下是一个简单的postgresdb备份脚本示例: 复制 #!/bin/bash # 设置备份目录和文件名 BACKUP_DIR/path/to/backup BACKUP_FILEdb_backup_$(date %F_%H-%M-%S).sql # 设置数据库连接参数 DB_HOSTlocalhost DB_PORT5432 DB_NAMEmydatabase DB_USERmyusername DB_PA…...

MATLAB程序员投简历的技巧解析,如何写出有亮点的简历
如果你想在简历中展示你的项目经验,一定要有亮点。一个导出的 Excel 文件过大导致浏览器卡顿的例子就是一个很好的亮点。你可以在简历中写明这个例子。如果面试官问起,可以用浏览器的原理来解释。浏览器内核可以简单地分为以下 5 个线程:GUI …...

颜色空间转换RGB-YCbCr
颜色空间 颜色空间(Color Space)是描述颜色的一种方式,它是一个由数学模型表示的三维空间,通常用于将数字表示的颜色转换成可见的颜色。颜色空间的不同取决于所选的坐标轴和原点,以及用于表示颜色的色彩模型。在计算机…...

年薪40万程序员辞职炒股,把一年工资亏光了,得了抑郁症,太惨了
年薪40万的程序员辞职全职炒股 把一年的工资亏光了 得了抑郁症 刚才在网上看了一篇文章 是一位北京的一位在互联网 大厂上班的程序员 在去年就是股市行情比较好的时候 他买了30多万股票 结果连续三个月都赚钱 然后呢 他是就把每天就996这种工作就辞掉了 然后在家全是炒股 感觉炒…...
10分钟如何轻松掌握JMeter使用方法?
目录 引言 安装jmeter HTTP信息头管理器 JMeter断言 HTTP请求默认值来代替所有的域名与端口 JSON提取器来替换变量 结语 引言 想要了解网站或应用程序的性能极限,JMeter是一个不可或缺的工具。但是,对于初学者来说,该如何上手使用JMe…...
[NLP]如何训练自己的大型语言模型
简介 大型语言模型,如OpenAI的GPT-4或Google的PaLM,已经席卷了人工智能领域。然而,大多数公司目前没有能力训练这些模型,并且完全依赖于只有少数几家大型科技公司提供技术支持。 在Replit,我们投入了大量资源来建立从…...
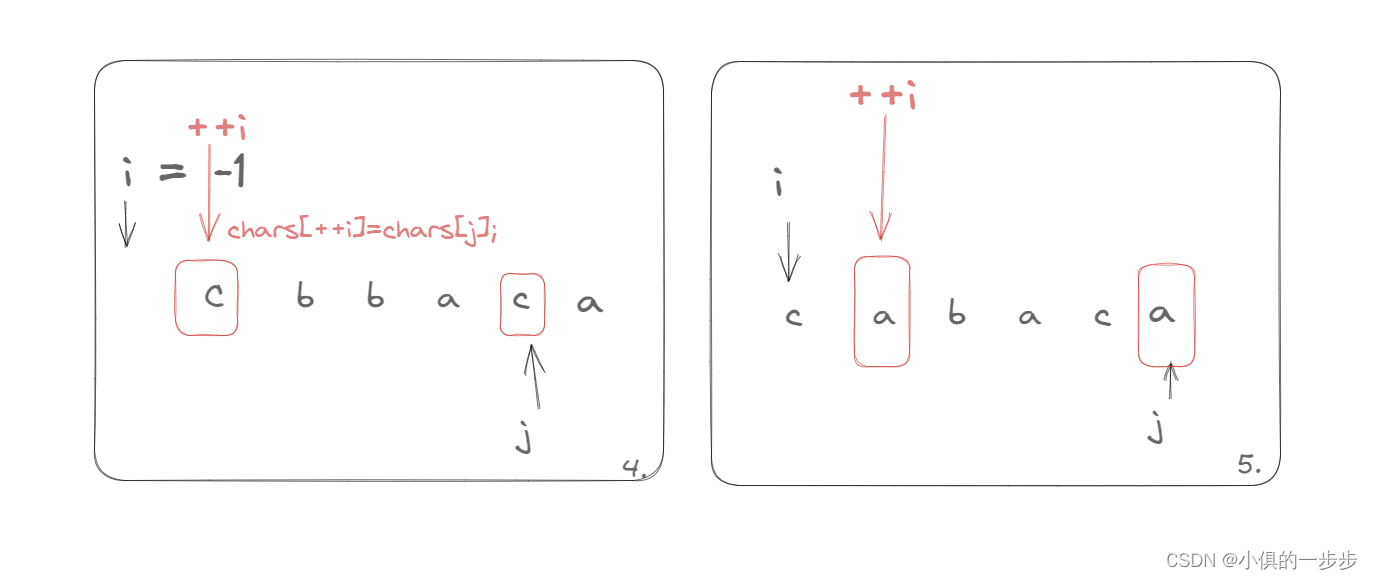
LeetCode1047. 删除字符串中的所有相邻重复项
1047. 删除字符串中的所有相邻重复项 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反复执行重复项删除操作,直到无法继续删除。 在完成所有重复项删除操作后返回最终的字符串。答案保证唯一…...
)
3。数据结构(3)
嵌入式软件开发第三部分,各类常用的数据结构及扩展,良好的数据结构选择是保证程序稳定运行的关键,(1)部分包括数组,链表,栈,队列。(2)部分包括树,…...

QT停靠窗口QDockWidget类
QT停靠窗口QDockWidget类 QDockWidget类简介函数和方法讲解 QDockWidget类简介 QDockWidget 类提供了一个部件,它可以停靠在 QMainWindow 内或作为桌面上的顶级窗口浮动。 QDockWidget 提供了停靠窗口部件的概念,也称为工具面板或实用程序窗口。 停靠窗…...

【LeetCode】139. 单词拆分
139. 单词拆分(中等) 思路 首先将大问题分解成小问题: 前 i 个字符的子串,能否分解成单词;剩余子串,是否为单个单词; 动态规划的四个步骤: 确定 dp 数组以及下标的含义 dp[i] 表示 s…...

【三维重建】NeRF原理+代码讲解
文章目录 一、技术原理1.概览2.基于神经辐射场(Neural Radiance Field)的体素渲染算法3.体素渲染算法4.位置信息编码(Positional encoding)5.多层级体素采样 二、代码讲解1.数据读入2.创建nerf1.计算焦距focal与其他设置2.get_emb…...
IntelliJ IDEA 社区版2021.3配置SpringBoot项目详细教程及错误解决方法
目录 一、SpringBoot的定义 二、Spring Boot 优点 三、创建一个springboot的项目 四、使用IDEA创建SpringBoot失败案例 一、SpringBoot的定义 Spring 的诞⽣是为了简化 Java 程序的开发的,⽽ Spring Boot 的诞⽣是为了简化 Spring 程序开发的。 Spring Boot 翻…...
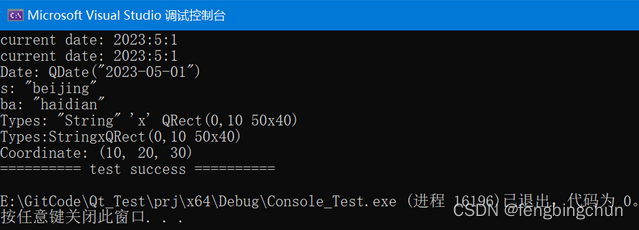
Qt中QDebug的使用
QDebug类为调试信息(debugging information)提供输出流。它的声明在<QDebug>中,实现在Core模块中。将调试或跟踪信息(debugging or tracing information)写出到device, file, string or console时都会使用QDebug。 此类的成员函数参考:https://doc…...

vue使用路由的query配置项时如何清除地址栏的参数
写vue项目时,如果想通过路由的query配置项把参数从一个组件传到另一个组件,但是又不希望?idxxx显示在地址栏(如:http://localhost:8080/test?idxxx的?idxxx),该怎么做: 举一个案例࿱…...
)
Redis-列表(List)
Redis列表(List) 介绍 单键多值Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)它的底层实际是个双向链表,对两端的操作性能很高,通过索…...

ripro主题修改教程-首页搜索框美化教程
先看效果图: 我们来看怎么实现: 1、找到wp-content/themes/ripro/assets/css/diy.css并将下面的内容整体复制进去并保存 /*首页搜索框*/ .bgcolor-fff {background-color: #fff; } .row,.navbar .menu-item-mega>.sub-menu{margin-left:-10px;margin-right:-10px;} .home…...

简单介绍C语言中的字符串函数
1.首先给出字符分类函数这几个就简单过一下,不做重点说明。这两个为字符转换函数,顾名思义,没什么好介绍的;接下来简单介绍几个字符串函数:strlen.strcpy.strcat.strstr.strncpy.strncat.memcpy.memmove;strlen:求字符…...

灵毓秀-牧神-造相Z-Turbo进阶玩法:结合提示词生成不同风格的灵毓秀
灵毓秀-牧神-造相Z-Turbo进阶玩法:结合提示词生成不同风格的灵毓秀 1. 认识灵毓秀-牧神-造相Z-Turbo 1.1 模型特点概述 灵毓秀-牧神-造相Z-Turbo是一款基于Xinference部署的专用文生图模型,专注于生成《牧神记》中灵毓秀这一角色的高质量图像。相比通…...

影刀+即刻:碎片化信息自动归类的联动玩法
影刀与即刻联动实现信息自动归类影刀RPA作为自动化工具,与即刻APP的推送功能结合,可高效管理碎片化信息。以下为具体实现方法:创建即刻机器人 在即刻APP中创建自定义机器人,设置关键词触发规则。例如设置"#工作""#…...

嵌入式开发必知:原码、反码与补码详解
1. 为什么嵌入式开发必须掌握原码、反码和补码作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多因为不理解底层数据表示而导致的诡异bug。记得刚入行时,我调试一个温度传感器项目,当温度低于零度时,读取的数值总是偏差127度。…...

LimeReport:终极跨平台Qt报表生成解决方案
LimeReport:终极跨平台Qt报表生成解决方案 【免费下载链接】LimeReport Report generator for Qt Framework 项目地址: https://gitcode.com/gh_mirrors/li/LimeReport LimeReport 是一款专为 Qt 开发者设计的开源报表生成库,提供完整的报表设计、…...
)
python异常模拟工具类(异常生成工具类)
文章目录创建代码类使用主要是做测试的时候方便,创建代码类 1、新建python文件exception_mock_utils.py,代码为: import random import time from typing import Any, Optionalclass ExceptionMockUtils:"""异常模拟工具类用…...

终端里的“皇帝新衣”:扒开 Claude Code 的源码,我看到了 Agent 的求生欲
下午三点,阳光斜着打在机械键盘的侧边,你刚解决完一个诡异的内存溢出,正打算接杯咖啡。 顺手更新了 Anthropic 刚发布的 Claude Code,这个号称能直接在终端里帮你写代码、改 bug、跑测试的“神级工具”。 [外链图片转存中…(img…...

Multisim仿真避坑指南:振幅调制器设计时,如何搞定静态工作点和输出幅度?
Multisim仿真实战:振幅调制器设计的5个关键调试技巧 在电子工程课程设计中,振幅调制器是一个经典但充满挑战的项目。许多学生在Multisim仿真阶段就会遇到各种问题——静态工作点不稳定、输出波形失真、峰峰值不达标...这些问题往往让初学者感到挫败。本文…...

Linux 内核中的信号处理:从发送到捕获
Linux 内核中的信号处理:从发送到捕获 引言 作为一名深耕操作系统和嵌入式开发的工程师,我深知通知机制的重要性。在系统开发中,及时的通知可以帮助系统快速响应事件。在 Linux 内核中,信号是一种重要的进程间通信机制,…...

3大优化方案让经典游戏重获新生:WarcraftHelper解决老游戏新设备适配难题
3大优化方案让经典游戏重获新生:WarcraftHelper解决老游戏新设备适配难题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 当你在4K显示器上…...