云原生时代顶流消息中间件Apache Pulsar部署实操-上
文章目录
- 安装
- 运行时Java版本推荐
- Locally Standalone集群
- 启动
- 验证
- 部署分布式集群
- 部署说明
- 初始化集群元数据
- 部署BookKeeper
- 部署Broker
- Admin客户端和验证
- Tiered Storage(层级存储)
- 概述
- 支持分级存储
- 何时使用
- 工作原理
安装
运行时Java版本推荐

Locally Standalone集群
启动
# 下载最新版本为2.11.0,需要Java 17
wget https://archive.apache.org/dist/pulsar/pulsar-2.11.0/apache-pulsar-2.11.0-bin.tar.gz
# 解压
tar xvfz apache-pulsar-2.11.0-bin.tar.gz
# 进入根目录
cd apache-pulsar-2.11.0
# 目录结构
ls -1F
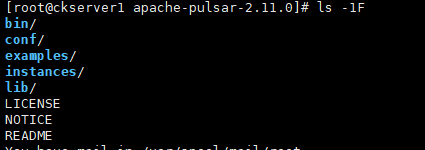
- bin:pulsar入口点脚本,以及许多其他命令行工具。
- conf:配置文件,包括pulsar示例pulsar函数示例实例使用的broker.conf
- examples:函数示例。
- lib:使用的jar。
- instances:函数的实例。
# 启动
bin/pulsar standalone
# 要将服务作为后台进程运行,可以使用下面命令
bin/pulsar -daemon start standalone
查看日志可以看到本地的pulsar standalone 集群启动成功日志
Pulsar集群启动时,会创建以下目录
- data:BookKeeper和RocksDB创建的所有数据。
- logs:所有服务日志。
公共/默认名称空间是在启动Pulsar集群时创建的。此名称空间用于开发目的。所有Pulsar主题都在名称空间中管理。
验证
- 创建主题
bin/pulsar-admin topics create persistent://public/default/test-topic1
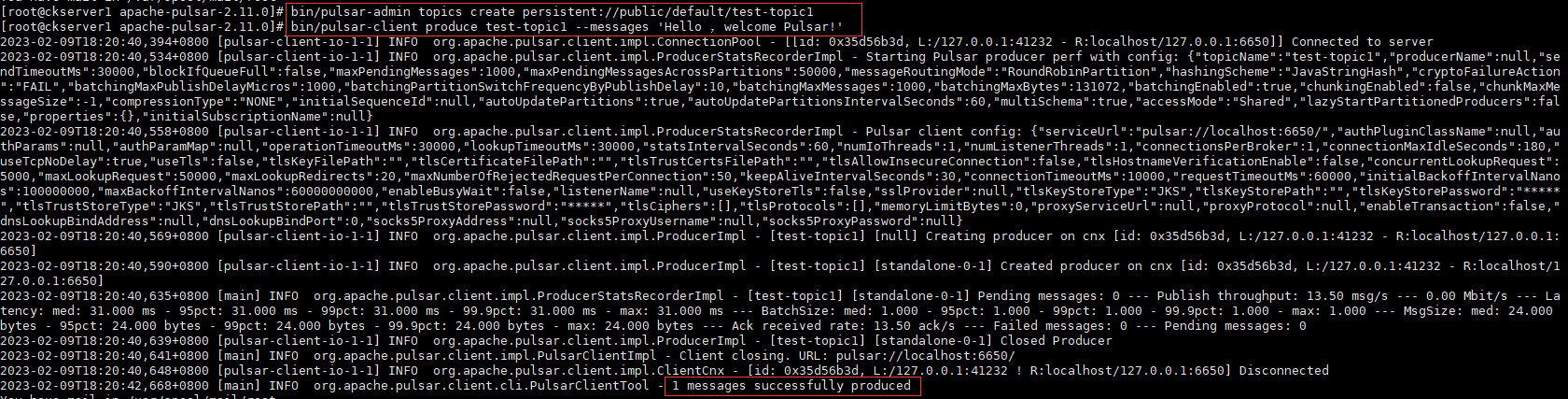
- 写入消息
bin/pulsar-client produce test-topic1 --messages 'Hello ,welcome Pulsar!'
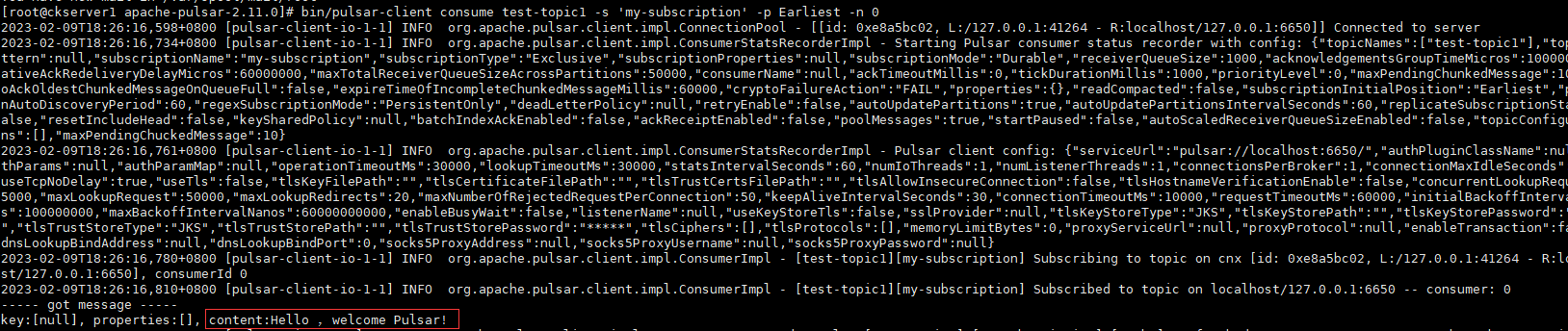
- 读消息
bin/pulsar-client consume test-topic1 -s 'my-subscription' -p Earliest -n 0
部署分布式集群
部署说明
这里使用Pulsar二进制包部署,不同于K8S部署集群,为了可以更好理解Pulsar架构。Pulsar实例由多个Pulsar 集群共同工作组成。可以跨数据中心或地理区域分布集群,并使用地理复制在它们之间复制集群。搭建Pulsar集群至少需要3个组件:ZooKeeper集群、BookKeeper集群、Broker集群。
- 3个节点ZooKeeper集群。建议生产部署两个独立的ZooKeeper集群,一个Local用于实例中的每个集群,另一个Configuration Store用于实例级任务。如果部署单集群实例,则不需要配置存储的单独集群。但如果部署了一个多集群实例,应该为配置任务建立一个单独的ZooKeeper集群。
- Local ZooKeeper运行在集群级别,提供特定于集群的配置管理和协调。每个Pulsar集群需要一个专用的ZooKeeper集群。
- Configuration Store在实例级上操作,并为整个系统(因此跨集群)提供配置管理。一个独立的机器集群或本地ZooKeeper使用的相同的机器可以提供配置存储仲裁。
- 3个节点BookKeeper集群。
- 3个节点Pulsar节点集群(Broker是Pulsar自身的实例)。
Pulsar的安装包已经包含搭建分布式集群所需的组件库,无需单独下载ZooKeeper和BookKeeper的安装包。但在实际中,zookeeper并不仅仅应用在pulsar上,之前介绍很多大数据组件依赖zookeeper,因此我们也使用外置的zookeeper环境。需要apache-zookeeper-3.8.0以上版本,我这里是apache-zookeeper-3.8.1。下面使用上面Standalone的下载的apache-pulsar-2.11.0-bin.tar.gz来部署分布式集群。
初始化集群元数据
只需要初始化一次接口,可以使用pulsar CLI工具的initialize-cluster-metadata命令初始化该元数据
bin/pulsar initialize-cluster-metadata \--cluster pulsar-cluster \--metadata-store zk1:2181,zk2:2181,zk3:2181 \--configuration-metadata-store zk1:2181,zk2:2181,zk3:2181 \--web-service-url http://hadoop1:8080/ \--web-service-url-tls https://hadoop1:8443/ \--broker-service-url pulsar://hadoop1:6650/ \--broker-service-url-tls pulsar+ssl://hadoop1:6651/ bin/pulsar initialize-cluster-metadata \--cluster pulsar-cluster \--metadata-store hadoop1:2181 \--configuration-metadata-store hadoop1:2181 \--web-service-url http://hadoop1:8080/ \--web-service-url-tls https://hadoop1:8443/ \--broker-service-url pulsar://hadoop1:6650/ \--broker-service-url-tls pulsar+ssl://hadoop1:6651/
初始化命令的参数说明
- 集群的名称
- 本地元数据存储集群的连接字符串
- 整个实例的配置存储连接字符串
- 集群的web服务URL
- 支持与集群中的代理交互的代理服务URL
初始化成功日志如下
部署BookKeeper
BookKeeper为Pulsar提供持久消息存储。每个pulsar broker 都需要自己的bookies集群。BookKeeper集群与Pulsar集群共享一个本地ZooKeeper仲裁。
bookies主机负责在磁盘上存储消息数据。为了让bookie提供最佳的性能,拥有合适的硬件配置对bookie来说是必不可少的。以下是bookies硬件容量的关键维度。
- 磁盘I/O读写容量
- 存储容量
通过配置文件conf/bookeeper.conf配置BookKeeper bookies。配置每个bookie最重要的方面是确保zkServers参数被设置为Pulsar集群的本地ZooKeeper的连接字符串。vim conf/bookkeeper.conf
# 修改本地地址
advertisedAddress=hadoop1
zkServers=zk1:2181,zk2:2181,zk3:2181
# 可以以两种方式启动一个bookie:在前台或作为后台守护进程启动。使用pulsar-daemon命令行工具在后台启动一个bookie:
bin/pulsar-daemon start bookie
# 你可以使用BookKeeper shell的bookiesanity命令来验证bookie是否正常工作,.这个命令在本地bookie上创建一个新的分类账,写一些条目,读回来,最后删除分类账。
bin/bookkeeper shell bookiesanity
# 在您启动了所有的bookie之后,可以在任何bookie节点上使用BookKeeper shell的simpletest命令,以验证集群中的所有bookie都在运行。
bin/bookkeeper shell simpletest --ensemble <num-bookies> --writeQuorum <num-bookies> --ackQuorum <num-bookies> --numEntries <num-entries>


其他bookie服务器也是同样配置(但需修改本地地址)和启动。
部署Broker
设置了ZooKeeper,初始化了集群元数据,并启动了BookKeeper bookie,就可以部署代理了。
修改配置文件 vi conf/broker.conf
clusterName=pulsar-cluster
advertisedAddress=hadoop1
zookeeperServers=zk1:2181,zk2:2181,zk3:2181
configurationStoreServers=zk1:2181,zk2:2181,zk3:2181
# 启动broker,bin/pulsar broker为前台启动
./bin/pulsar-daemon start broker
其他broker服务器也是同样配置(但需修改本地地址)和启动。查看broker的列表
./bin/pulsar-admin brokers list pulsar-cluster

Admin客户端和验证
# 可以配置客户端机器,这些客户端机器可以作为每个集群的管理客户端。可以使用conf/client.conf配置文件配置admin客户端。
serviceUrl=http://hadoop1:8080/
- 创建租户
bin/pulsar-admin tenants create itxs-tenant \
--allowed-clusters pulsar-cluster \
--admin-roles test-admin-role

- 创建namespace命名空间
bin/pulsar-admin namespaces create itxs-tenant/myns
- 测试生产者和消费者
# 启动一个消费者,在主题上创建一个订阅并等待消息:
bin/pulsar-perf consume persistent://itxs-tenant/myns/test-topic1
# 启动一个生产者,以固定的速率发布消息,并每10秒报告一次统计数据:
bin/pulsar-perf produce persistent://itxs-tenant/myns/test-topic1
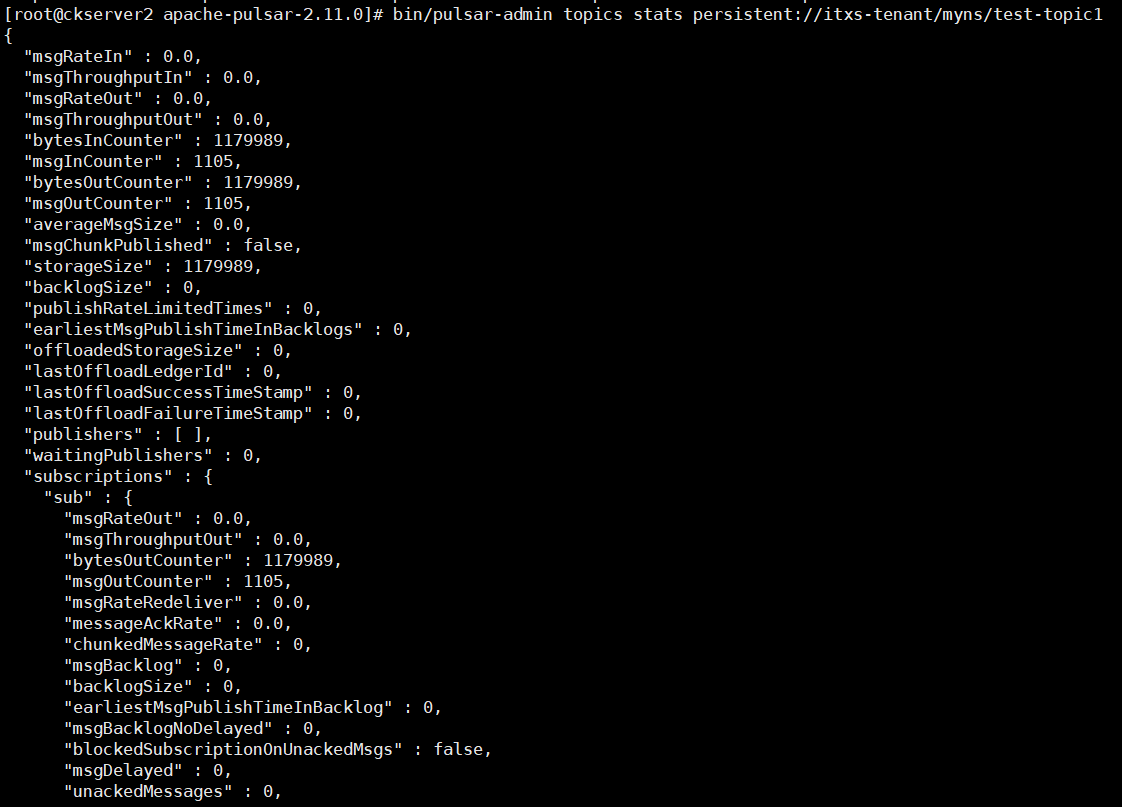
# 报告主题统计信息:
bin/pulsar-admin topics stats persistent://itxs-tenant/myns/test-topic1
生产者的日志如下

消费者的日志如下
主题统计信息的日志如下
Tiered Storage(层级存储)
概述
Pulsar的分层存储特性允许将旧的积压数据从BookKeeper转移到长期和更便宜的存储中,同时允许客户端访问积压数据。
以流的方式永久保留原始数据,分区容量不再限制,充分利用云存储或现在廉价存储(例如HDFS),数据统一,客户端无需关心数据究竟存在哪里。
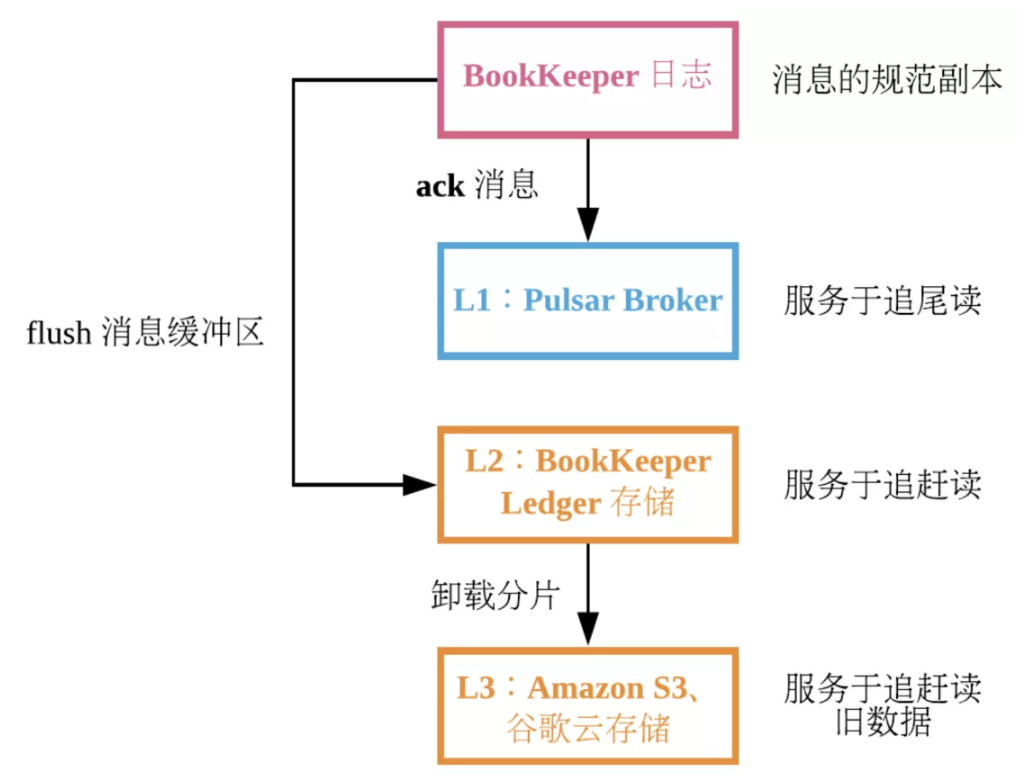
- 第一级:通过BookKeeper 预写日志
- 第二级: Pulsar broker,可用于追尾读。提交消息后,可以直接将消息发给所有与此 topic 相关的订阅者,而不必使用磁盘。
- 第三级: BookKeeper 节点上的 ledger 存储磁盘。将消息写入 BookKeeper 节点上的日志时,同时也写入到定期 flush 的 ledger 存储磁盘的内存缓冲区。BookKeeper 节点使用此磁盘提供读操作。
- 在 Pulsar 中,从内存缓冲区读消息很少见。追尾 consumer 通常直接从 Pulsar 的缓存中读消息。追赶 consumer 通常请求很早之前的消息,因此这些消息一般不存储在内存缓冲区。Ledger 存储磁盘服务于追赶读。Ledger 存储磁盘采用的存储消息的格式不仅保证在同一 topic 上尽可能按顺序读取,还优化了在同一磁盘上存储多个不同 topic 的能力。由于 ledger 存储磁盘与日志磁盘相互隔离,读操作不会影响日志磁盘中按顺序写入的性能。
- 如果为 Pulsar 配置了“分层存储”,则最后一级缓存为长期存储。分层存储允许用户对 topic backlog 中的较旧部分采用更节约成本的存储形式。分层存储利用了消息的不可变性,但粒度更大,因为在长期存储中单独存储每条消息会很浪费空间。Pulsar topic 日志由分片组成,每个分片默认对应一个包含 50000 条消息的序列。活跃分片只有一个,活跃分片之前的分片将关闭。当分片关闭时,无法继续添加新消息。假定分片中的单条消息不可变,并且单条消息的偏移量不可变,则此分片不可变。因此可以复制不可变对象到想要的任何位置。
- 要在 Pulsar 中使用分层存储,用户必须使用基于时间或基于大小的策略来配置 topic 命名空间以卸载分片。当命名空间中的 topic 达到策略中定义的阈值时,Pulsar broker 将 topic 日志中最旧的分片复制到长期存储中,直到该 topic 低于策略阈值。经过一段时间后,Pulsar 从 BookKeeper 中删除原来的分片,以释放磁盘空间。
- 第四级:Pulsar 支持将 Amazon S3 和 S3 兼容的对象存储用于长期存储,也支持 Azure 存储,并且从 Pulsar 2.2.0 起支持谷歌云存储。
支持分级存储
- 分级存储使用Apache jclouds支持Amazon S3、GCS(谷歌云存储)、Azure和阿里云OSS进行长期存储。
- 分级存储使用Apache Hadoop支持文件系统进行长期存储
何时使用
当你有一个主题,并且你想要在很长一段时间内保持一个很长的待办事项列表时,应该使用分层存储。例如,如果有一个包含用于训练推荐系统的用户操作的主题,希望长时间保留该数据,以便在更改推荐算法时可以根据完整的用户历史重新运行它。
工作原理
Pulsar中的主题由日志支持,称为托管分类账。这个日志由一个有序的段列表组成。脉冲星只写入日志的最后一段。所有之前的片段都是密封的。段内的数据是不可变的。这被称为面向段的体系结构。
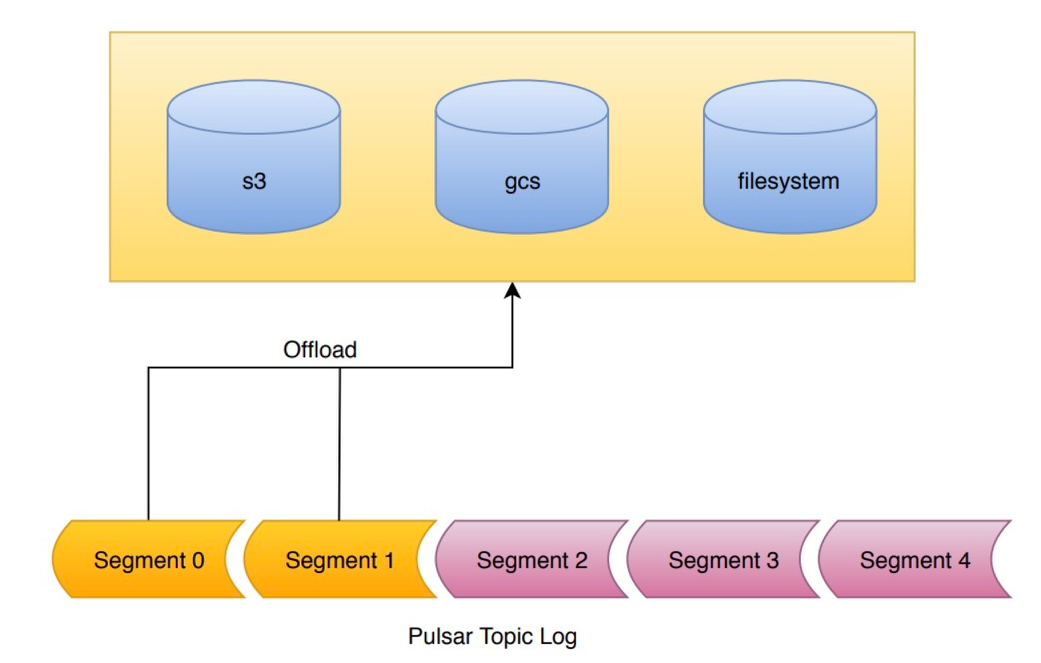
- 分层存储卸载机制利用了面向段的架构。当请求卸载时,日志段被逐个复制到分级存储中。写入分级存储的日志的所有段(除了当前段)都可以卸载。
- 写入BookKeeper的数据默认复制到3台物理机上。然而,一旦一个段被密封在BookKeeper中,它就变得不可变,可以复制到长期存储中。长期储存有潜力实现显著的成本节约。
- 在将分类帐卸载到长期存储之前,您需要为云存储服务配置桶、凭据和其他属性。此外,Pulsar使用多部分对象上传分段数据,代理可能会在上传数据时崩溃。建议为bucket添加一个生命周期规则,使其在一天或两天后过期未完成的多部分上传,以避免为未完成的上传收取费用。此外,可以手动(通过REST API或CLI)或自动(通过CLI)触发卸载操作。
- 在将分类账卸载到长期存储后,仍然可以使用Pulsar SQL查询卸载的分类账中的数据。
了解层级存储的基础知识后本篇先到此,下一篇将实战介绍层级存储、Pulsar IO、Pulsar Functions、Pulsar SQL、Transactions的操作和示例演示。
本人博客网站IT小神 www.itxiaoshen.com
相关文章:
云原生时代顶流消息中间件Apache Pulsar部署实操-上
文章目录安装运行时Java版本推荐Locally Standalone集群启动验证部署分布式集群部署说明初始化集群元数据部署BookKeeper部署BrokerAdmin客户端和验证Tiered Storage(层级存储)概述支持分级存储何时使用工作原理安装 运行时Java版本推荐 Locally Standalone集群 启动 # 下载…...

Python实现基于openCV+百度智能云平台实现《1:N人脸考勤机》文章最后附带源码!
目录 一、 项目介绍 1.1 项目名称 1.2 项目简介 1.3 项目物料 1.4 技术栈 二、 项目架构 三、项目细节 3.1 环境搭建 3.2 利用opencv实现摄像头调取及相关图像的采集 3.3 利用aips上传图像和结果返回 3.4 结果优化和处理 3.5 可扩展性 3.6 遗留问题和…...

因为锁的问题,我们被扣了1万
前言 春节放假期间,一个项目上的积分接口被刷,而且不止一个人在刷,并且东西也被兑走,放假晚上被人叫起来排查问题,通过这个人的积分明细观察,基本一秒就能获取一次,远远超过了积分规则限定的次…...
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER)
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER) 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置(ADC唤醒无法使用、低功耗模式无法烧录…...

浏览器渲染中的相关概念
渲染 渲染流水线 构建 DOM 树 输入:HTML 文档;处理:HTML 解析器解析;输出:DOM 数据解构。 样式计算 输入:CSS 文本;处理:属性值标准化,每个节点具体样式(…...

【MySQL】数据类型
1、数据类型描述 类型类型举例整数类型TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT浮点类型FLOAT、DOUBLE定点数类型DECIMAL位类型BIT日期时间类型YEAR、TIME、DATE、DATETIME、TIMESTAMP文本字符串类型CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT枚举类…...

L2-037 包装机
一种自动包装机的结构如图 1 所示。首先机器中有 N 条轨道,放置了一些物品。轨道下面有一个筐。当某条轨道的按钮被按下时,活塞向左推动,将轨道尽头的一件物品推落筐中。当 0 号按钮被按下时,机械手将抓取筐顶部的一件物品&#x…...
MySQL -查询日志、二进制日志、错误日志、慢查询日志
文章目录1.错误日志2.二进制日志3.查询日志4.慢查询日志1.错误日志 错误日志是 MySOL中最重要的日志之一,它记录了当 mvsald 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息当数据库出现任何故障导致无法正常使用时,建议…...

TCP实现可靠传输的实现
TCP实现可靠传输的实现 目录TCP实现可靠传输的实现ARQ协议停止等待协议(古老)连续ARQ协议累计重传(回退N帧的ARQ协议)缓存确认(选择重传ARQ协议)超时重传的时间选择TCP的流量控制零窗口探测报文段Nagle算法…...

2/14考试总结
时间安排 7:30–7:50 看题,T1可能是个数据结构之类的东西,T2是 dp ,T3 构造。 7:50–8:20 T3,仿照样例的构造,可以通过一部分测试点。 8:20–9:20 T1,发现题目实际上要求子树内各儿子的深度信息,可以 dsu ,对于不能暴…...

程序环境和预处理详解
文章目录一、程序环境1.1 - 翻译环境1.1.1 - 编译1.1.1.1 - 预编译(预处理)1.1.1.2 - 编译1.1.1.3 - 汇编1.1.2 - 链接1.2 - 执行环境二、预处理详解2.1 - 预定义符号2.2 - #define2.2.1 - #define 定义标识符2.2.1.1 - 语法2.2.1.2 - 建议2.2.2 - #defi…...

The Social-Engineer Toolkit(社会工程学工具包)互联网第一篇全模块讲解
一、工具介绍 Social-Engineer Toolkit 是一个专为社会工程设计的开源渗透测试框架,可以帮助或辅助你完成二维码攻击、可插拔介质攻击、鱼叉攻击和水坑攻击等。SET 本身提供了大量攻击选项,可让您快速进行信任型攻击,也是一款高度自定义工具…...
Windows11去掉不满足系统要求的提示水印
我的电脑是LEGION的拯救者R70002021,预装的是Windows 11 家庭中文版,没有折腾重装过系统,今天突然注意到右下角出现了这个提示:“不满足系统要求。转到’设置"了解详细信息”。 在进入设置 - 系统 面板中也提示不满足系统要…...

JavaScript 计时事件
JavaScript 计时事件 通过使用 JavaScript,我们有能力做到在一个设定的时间间隔之后来执行代码,而不是在函数被调用后立即执行。我们称之为计时事件。 在 JavaScript 中使用计时事件是很容易的,两个关键方法是: setInterval() - 间隔指定的…...
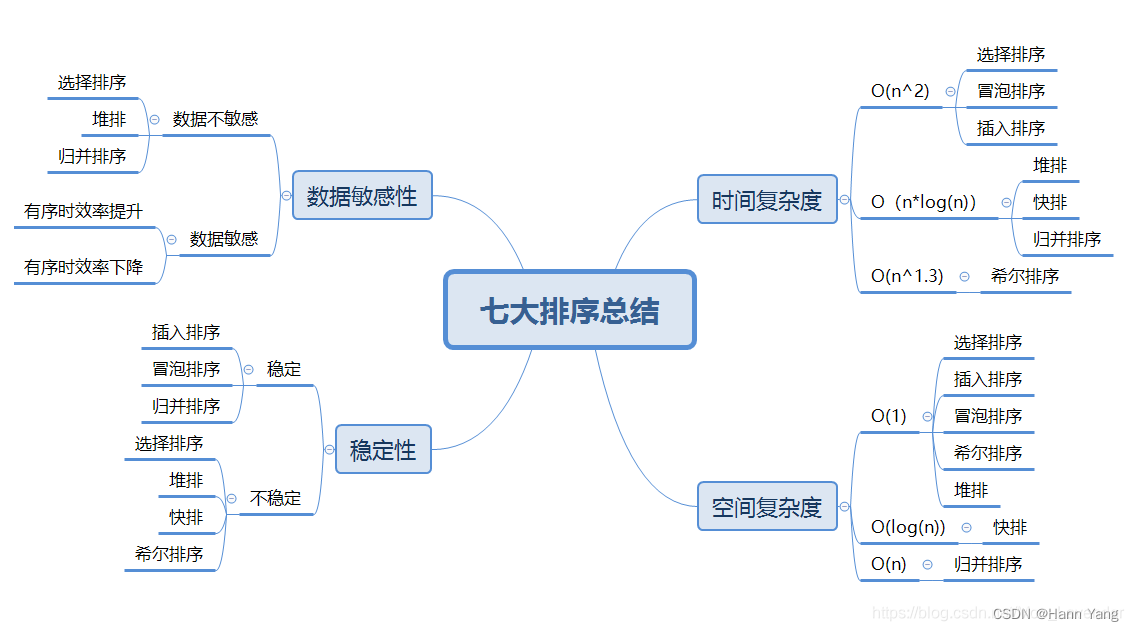
七大排序算法的多语言代码实现
文章目录 前言 一、排序算法 1.原理简述 2.分类与复杂度 二、实例代码 1.冒泡排序 C Python Java Golang Rust Dephi 2.选择排序 C Python Java Golang Rust Dephi 3.插入排序 C Python Java Golang Rust Dephi 4.希尔排序 编辑 C Python Java Gola…...

【基础算法】表达式计算
中缀表达式:我们平常见到的正常数学式子 后缀表达式:12-3* 后缀表达式对于计算机很容易计算,只需要从头部扫描字符串。然后遇到数字就入栈,遇到运算符就取出栈顶的两个数进行运算。最后把运算结果入栈,最后栈中就会剩一个数为答…...
动态规划问题
目录 一、动态规划简介 二、利用动态规划解决问题 1、斐波拉契序列 2、拆分词句 3、三角形最小路径和 4、不同的路径数目(一) 5、带权值的最小路径和 6、求路径ii 7、01背包 8、不同子序列 9、编辑距离 10、分割回文串 一、动态规划…...

【MySQL进阶】 存储引擎 索引
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
5 款最好的免费 SSD 数据恢复软件
SSD(固态硬盘)提供比传统硬盘更快的读/写速度,使启动、软件加载和游戏启动更快。因此,在我们选择存储设备时,它是一个极好的选择。但是,它仍然存在数据丢失的风险。假设您是受害者之一,正在寻找…...
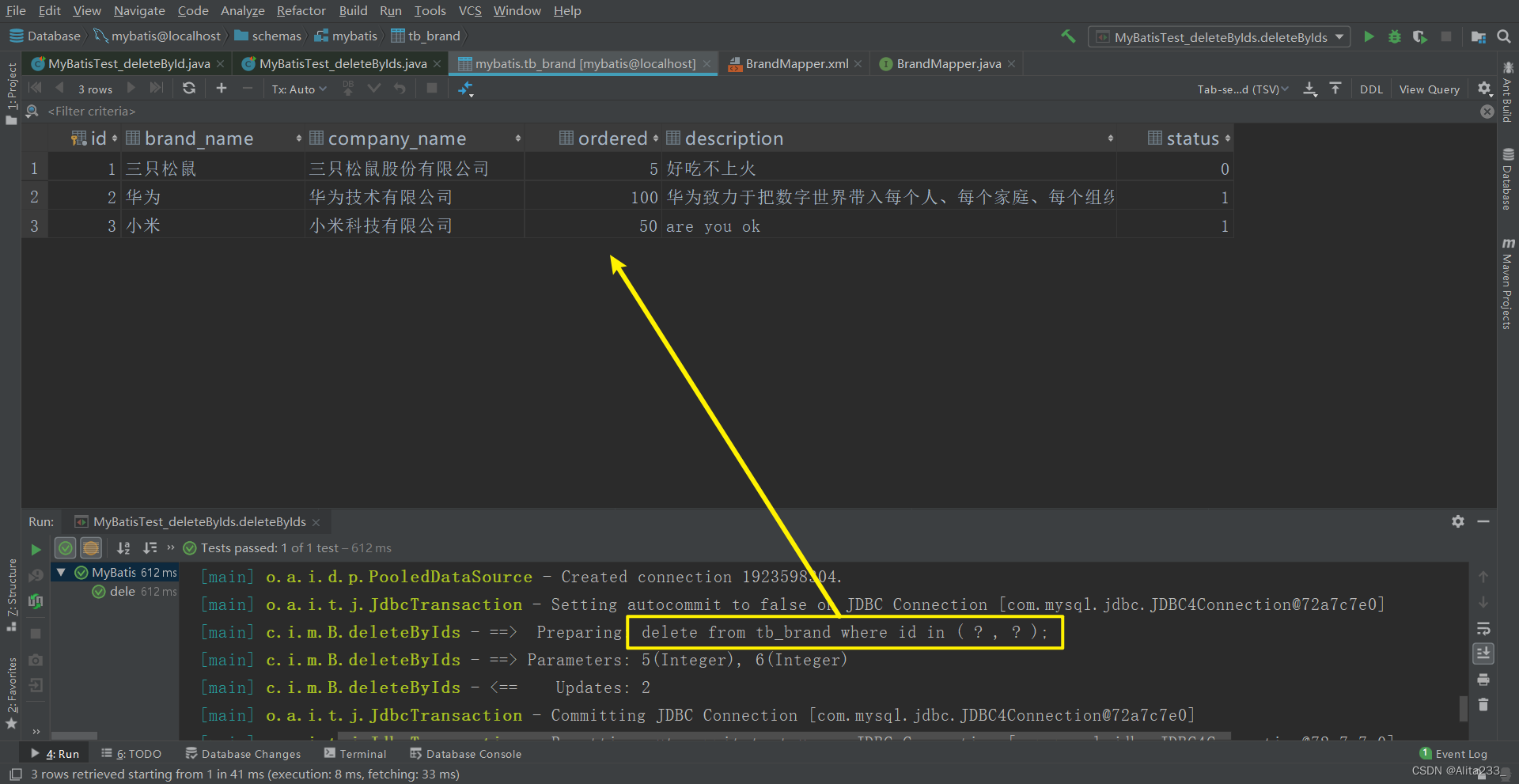
MyBatis案例 | 使用映射配置文件实现CRUD操作——删除数据
本专栏主要是记录学习完JavaSE后学习JavaWeb部分的一些知识点总结以及遇到的一些问题等,如果刚开始学习Java的小伙伴可以点击下方连接查看专栏 本专栏地址:🔥JavaWeb Java入门篇: 🔥Java基础学习篇 Java进阶学习篇&…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...
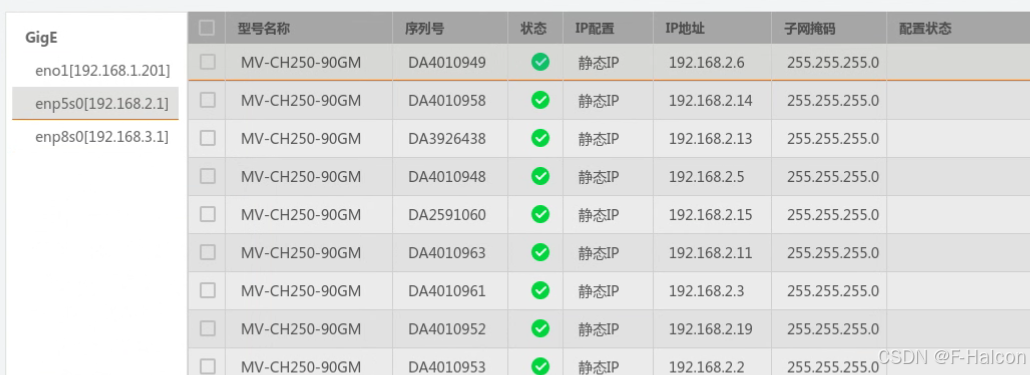
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...