3. SQL底层执行原理详解
一条SQL在MySQL中是如何执行的
- 1. MySQL的内部组件结构
- 1.1 Server层
- 1.2 Store层
- 2. 连接器
- 3. 分析器
- 4. 优化器
- 5. 执行器
- 6. bin-log归档
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
1. MySQL的内部组件结构
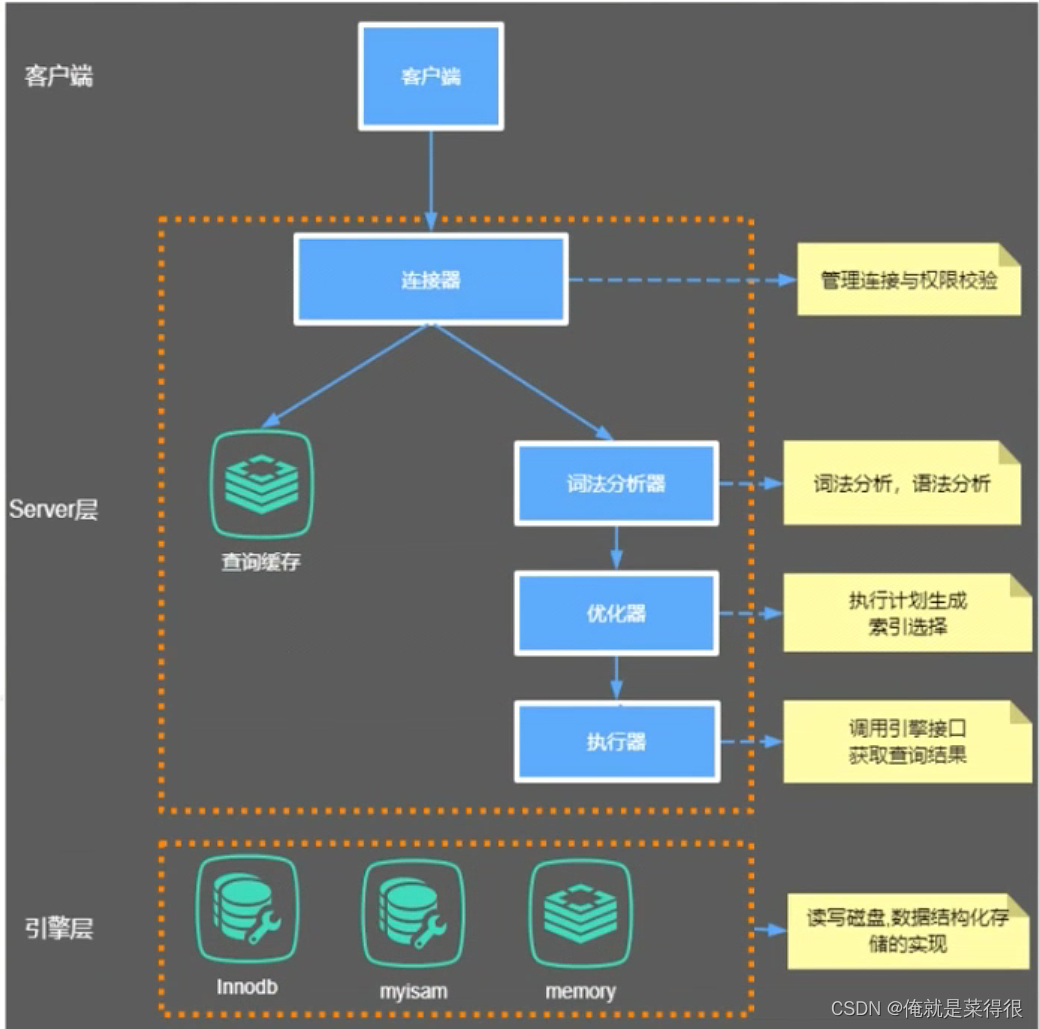
大体来说,MySQL可以分为Server层和存储引擎层两部分。
1.1 Server层
主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
1.2 Store层
MySQL的存储引擎采用的是插拔式的,我们可以自己扩充或者选择合适的。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定表的存储引擎类型,默认会给你设置存储引擎为InnoDB。
本次使用的DDL:
CREATE TABLE `test` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
下面我们重点来分析连接器、查询缓存、分析器、优化器、执行器分别主要干了哪些事情。
2. 连接器
我们知道由于MySQL是开源的,他有非常多种类的客户端:navicat,mysql front,jdbc,SQLyog等非常丰富的客户端,这些客户端要向mysql发起通信都必须先跟Server端建立通信连接,而建立连接的工作就是有连接器完成的。
第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:
mysql ‐h host[数据库地址] ‐u root[用户] ‐p root[密码] ‐P 3306
连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
1、如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
2、如果用户名密码认证通过,连接器会到权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。用户的权限表在系统表空间的mysql的user表中。
mysql客户端和服务端是长连接,默认时间是8个小时。即8个小时内如果我们不做什么事情,连接依然会被保持。超过8个小时候,连接会断掉。
mysql本身维护着一个user表,来记录用户的权限。Host表示哪些主机可以连接,“%”表示任意主机都可以连接。

修改user密码
mysql> CREATE USER 'username'@'host' IDENTIFIED BY 'password'; //创建新用户mysql> grant all privileges on *.* to 'username'@'%'; //赋权限,%表示所有(host)mysql> flush privileges //刷新数据库mysql> update user set password=password(”123456″) where user=’root’;(设置用户名密码)mysql> show grants for root@"%"; 查看当前用户的权限
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。文本中这个
图是 show processlist 的结果,其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。
如果我们排查问题的时候看到某个阻塞的连接,想要关闭,可以使用kill命令来直接关闭:
kill [id]
客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值
是 8 小时。查看wait_timeout:
mysql> show global variables like "wait_timeout";
mysql>set global wait_timeout=28800; 设置全局服务器关闭非交互连接之前等待活动的秒数
如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
开发当中我们大多数时候用的都是长连接,把连接放在Pool内进行管理,但是长连接有些时候会导致 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这类问题呢?
定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection
来重新初始化连接资 源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态
查询缓存
mysql>show databases; 显示所有数据库
mysql>use dbname; 打开数据库
mysql>show tables; 显示数据库mysql中所有的表
mysql>describe user; 显示表mysql数据库中user表的列信息
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以
key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查
询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
缓存默认是关闭的,其实这个缓存有时候不是那么好用。在mysql5.8以及以后的版本中,这个缓存已经被删除了。
大多数情况查询缓存就是个鸡肋,为什么呢?
因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率
会非常低。
一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典
表,那这张表上的查询才适合使用查询缓存。好在 MySQL 也提供了这种“按需使用”的方式。你可以将my.cnf参数
query_cache_type 设置成 DEMAND。
my.cnf#query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才缓存query_cache_type=2
这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下
面这个语句一样:
mysql> select SQL_CACHE * from test where ID=5;
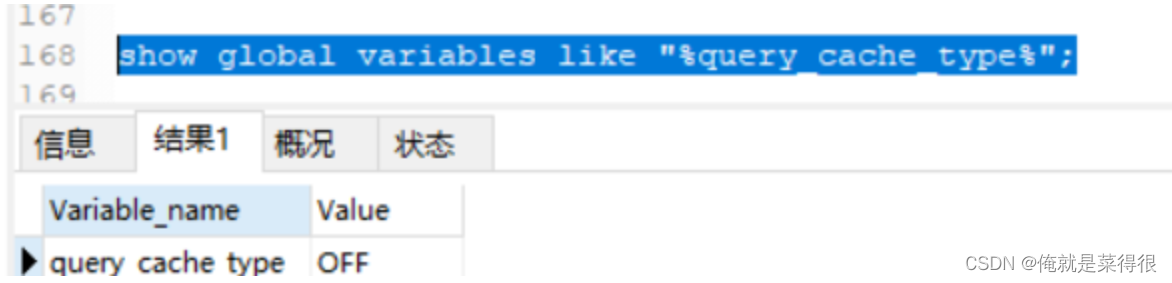
查看当前mysql实例是否开启缓存机制,可以看到,默认是关闭的:
mysql> show global variables like "%query_cache_type%";
监控查询缓存的命中率:
mysql> show status like'%Qcache%'; //查看运行的缓存信息
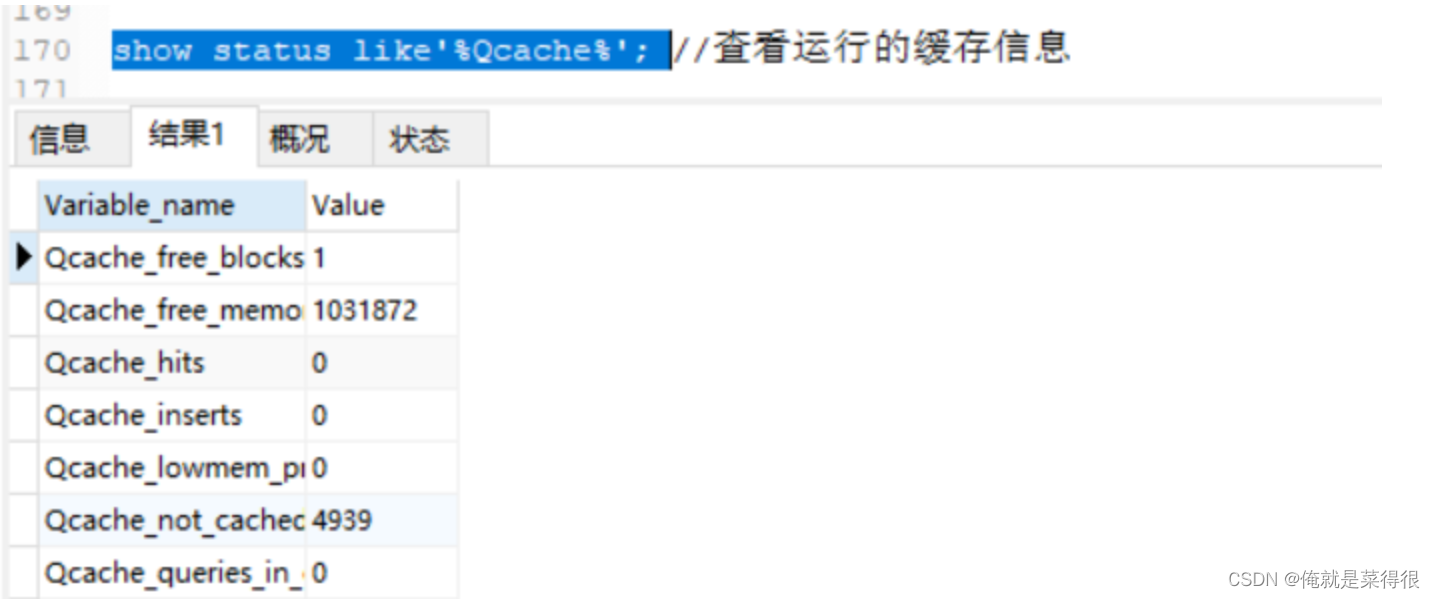
- Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片过多了,可能在一定的时间进行整理。
- Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,DBA可以根据实际情况做出调整。
- Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越 理想。
- Qcache_inserts: 表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert到查询缓存中。这样的情况的次数,次数越多,表示查询缓存应用到的比较少,效果也就不理想。当然系统刚启动后,查询缓存是空的,这很正常。
- Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的 调整缓存大小。
- Qcache_not_cached: 表示因为query_cache_type的设置而没有被缓存的查询数量。
- Qcache_queries_in_cache:当前缓存中缓存的查询数量。
- Qcache_total_blocks:当前缓存的block数量。
mysql8.0已经移除了查询缓存功能
其实在存储引擎中,也是存在缓存的。比如InnoDB引擎中就存在一个Buffer Pool来缓存热点数据,通过LRU淘汰策略。
3. 分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是
什么,代表什么。
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了"rom"。
mysql> select * fro test where id=1;ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'fro test where id=1' at line 1
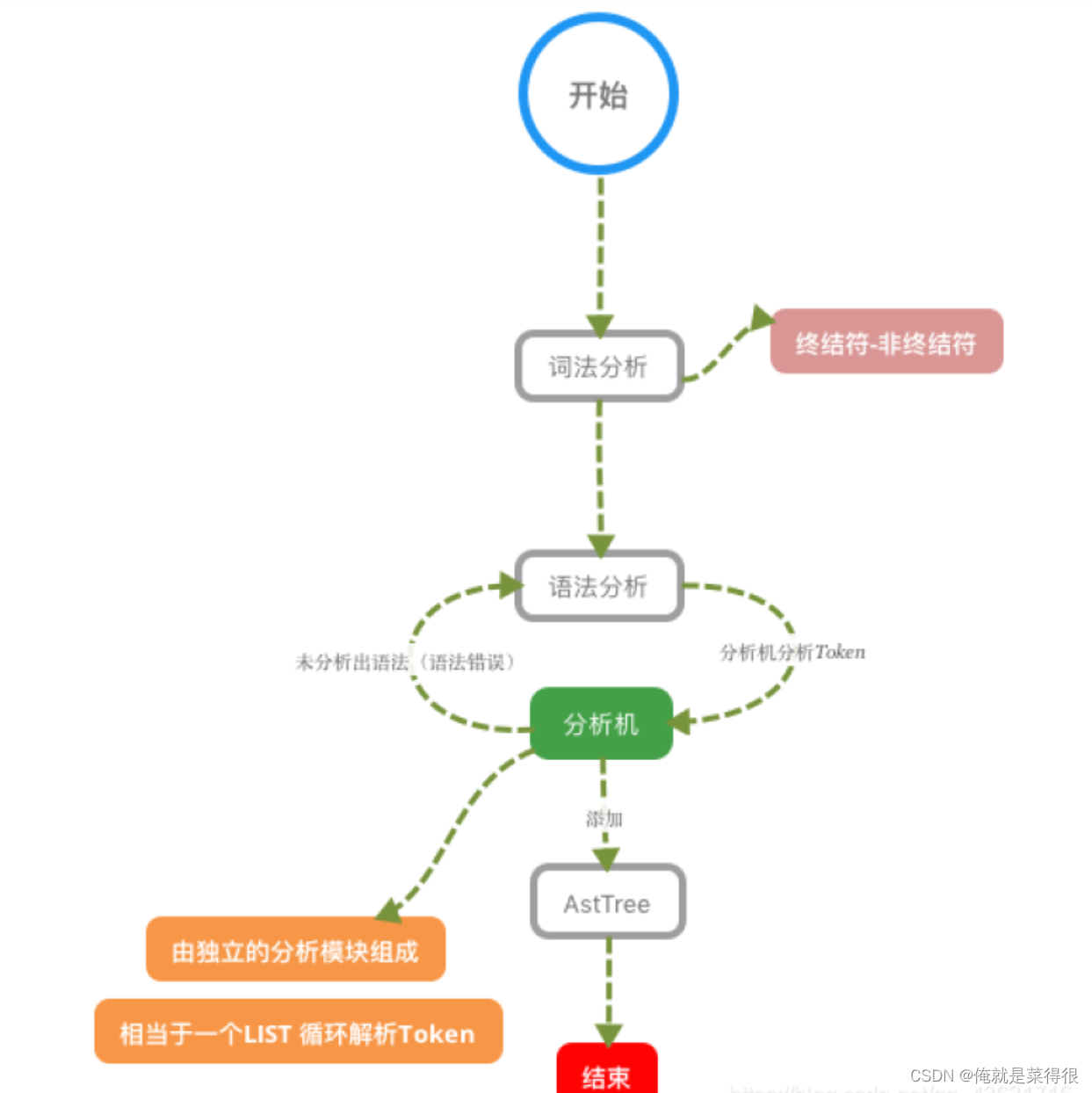
词法分析器原理
词法分析器分成6个主要步骤完成对sql语句的分析:
1、词法分析
2、语法分析
3、语义分析
4、构造执行树
5、生成执行计划
6、计划的执行
下图是SQL词法分析的过程步骤:
SQL语句的分析分为词法分析与语法分析,mysql的词法分析由MySQLLex[MySQL自己实现的]完成,语法分析由Bison生
成。关于语法树大家如果想要深入研究可以参考这篇wiki文章:https://en.wikipedia.org/wiki/LR_parser。那么除了Bison外,Java当中也有开源的词法结构分析工具例如Antlr4,ANTLR从语法生成一个解析器,可以构建和遍历解析树,可以在IDEA工具当中安装插件:antlr v4 grammar plugin。经过bison语法分析之后,会生成一个这样的语法树:
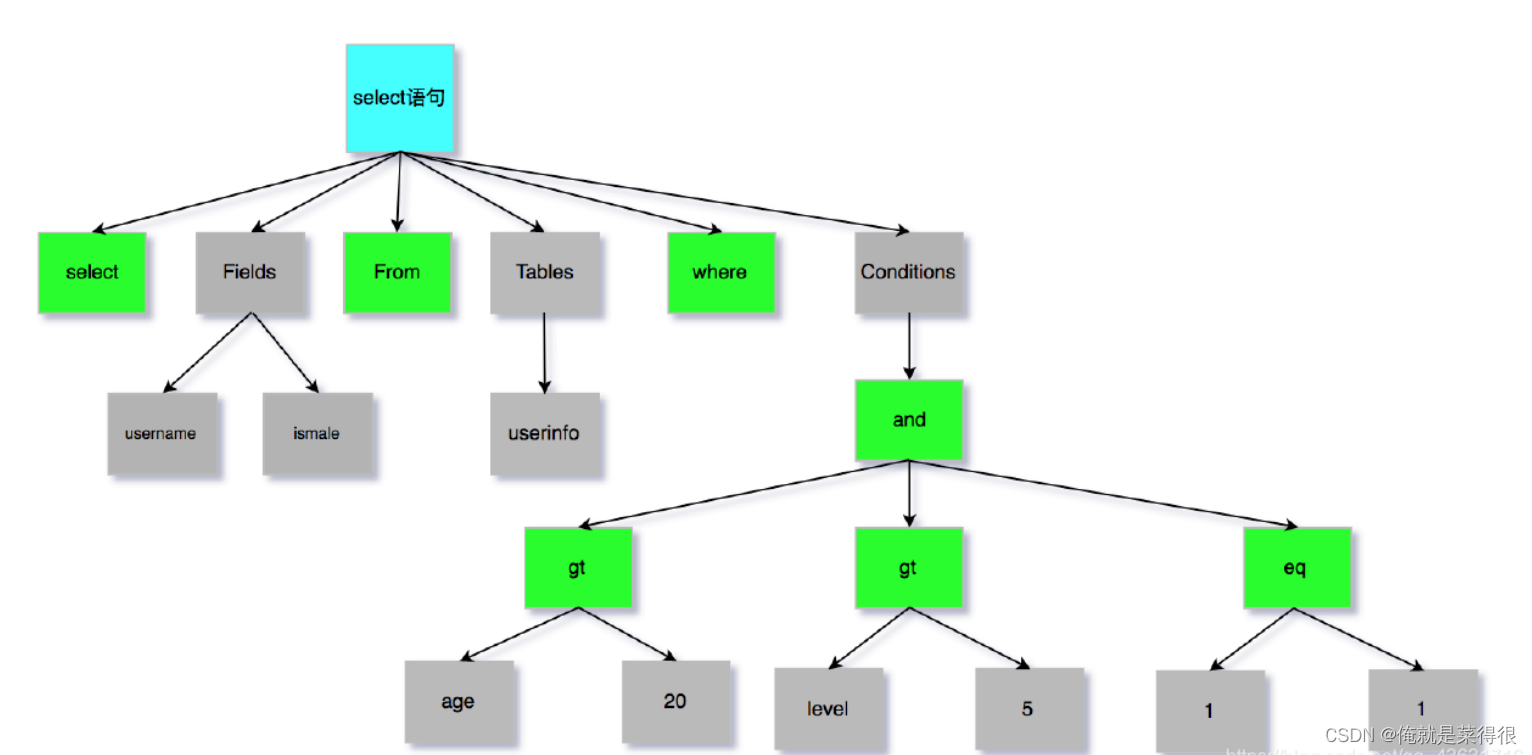
至此我们分析器的工作任务也基本圆满了。接下来进入到优化器。
4. 优化器
可以参考这个更加详细的文章,记录了查询优化器的工作原理: 查询优化器工作原理:https://blog.csdn.net/qq_43631716/article/details/106650336
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接
顺序。比如你执行下面这样的语句,这个语句是执行两个表的 join:
mysql> select * from test1 join test2 using(ID) where test1.name=yangguo and test2.name=xiaolongnv;
既可以先从表 test1 里面取出 name=yangguo的记录的 ID 值,再根据 ID 值关联到表 test2,再判断 test2 里面 name的
值是否等于 yangguo。
也可以先从表 test2 里面取出 name=xiaolongnv 的记录的 ID 值,再根据 ID 值关联到 test1,再判断 test1 里面 name
的值是否等于 yangguo。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。如果你还有一些疑问,比如优化器是怎么选择索引的,有没有可能选择错等等.
5. 执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
mysql> select * from test where id=1;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。你会在数据库的慢查询日志中看到一个rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。
6. bin-log归档
删库是不需要跑路的,因为我们的SQL执行时,会将sql语句的执行逻辑记录在我们的bin-log当中,什么是bin-log呢?
binlog是Server层实现的二进制日志,他会记录我们的crud操作。Binlog有以下几个特点:
- Binlog在MySQL的Server层实现(引擎共用)
- Binlog为逻辑日志,记录的是一条语句的原始逻辑
- Binlog不限大小,追加写入,不会覆盖以前的日志
如果,我们误删了数据库,可以使用binlog进行归档!要使用binlog归档,首先我们得记录binlog,因此需要先开启MySQL的binlog功能。
配置my.cnf:
# 配置开启binloglog‐bin=/usr/local/mysql/data/binlog/mysql‐bin# 注意5.7以及更高版本需要配置本项:server‐id=123454(自定义,保证唯一性);#binlog格式,有3种statement,row,mixed# statement: 记录的是sql语句本身的逻辑(记录的是产生结果的过程)(可能出现主从数据不一致) 占用的资源较少# row: 记录的是当前sql语句执行前后的结果 (记录的是产生的结果) 占用资源较多@ minxed:两种综合起来,binlog‐format=ROW#表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定sync‐binlog=1binlog命令:
mysql> show variables like '%log_bin%'; 查看bin‐log是否开启
mysql> flush logs; 会多一个最新的bin‐log日志
mysql> show master status; 查看最后一个bin‐log日志的相关信息
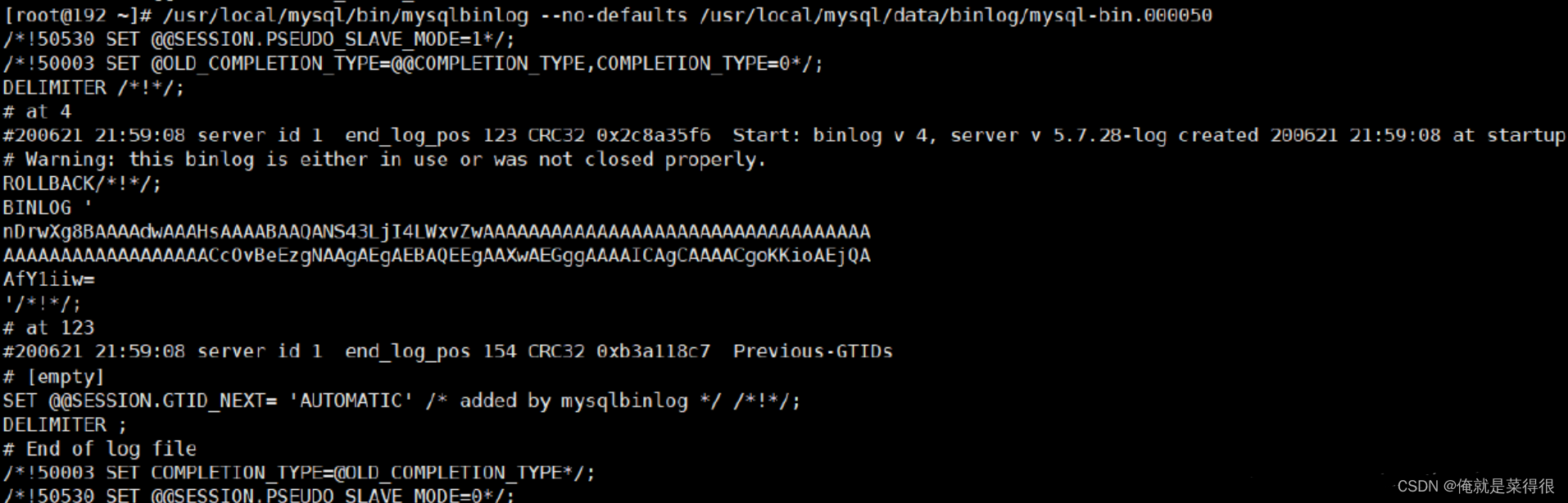
mysql> reset master; 清空所有的bin‐log日志查看binlog内容:
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 查看binlog内容binlog里的内容不具备可读性,所以需要我们自己去判断恢复的逻辑点位,怎么观察呢?看重点信息,比如begin,commit这种关键词信息,只要在binlog当中看到了,你就可以理解为begin-commit之间的信息是一个完整的事务逻辑,然后再根据位置position判断恢复即可。binlog内容如下:
归档测试准:
1、定义一个存储过程,写入数据
drop procedure if exists tproc;
delimiter $$
create procedure tproc(i int)
begin
declare s int default 1;
declare c char(50) default repeat('a',50);
while s<=i do
start transaction;
insert into test values(null,c);
commit;
set s=s+1;
end while;
end$$
delimiter ;2、删除数据
mysql> truncate test;3、利用binlog归档
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysqlbin.000001 |mysql ‐uroot ‐p tuling(数据库名)4、归档完毕,数据恢复
相关文章:
3. SQL底层执行原理详解
一条SQL在MySQL中是如何执行的 1. MySQL的内部组件结构1.1 Server层1.2 Store层 2. 连接器3. 分析器4. 优化器5. 执行器6. bin-log归档 本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。 1. MySQL的内部组件结…...
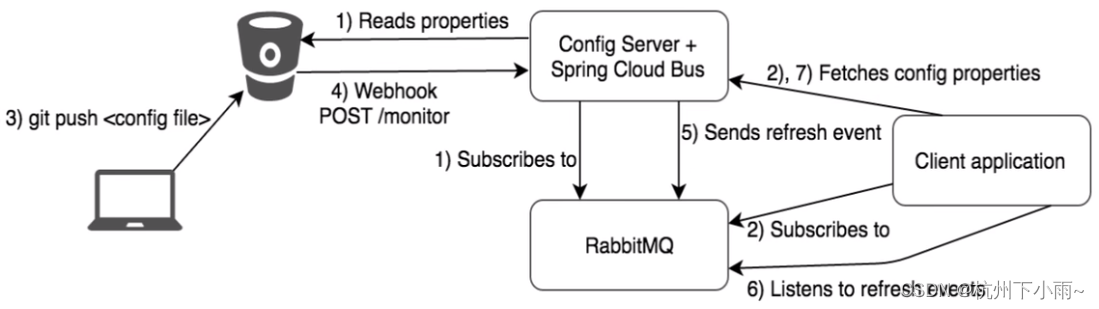
Bus动态刷新
Bus动态刷新全局广播配置实现 启动 EurekaMain7001ConfigcenterMain3344ConfigclientMain3355ConfigclicntMain3366 运维工程师 修改Gitee上配置文件内容,增加版本号发送POST请求curl -X POST "http://localhost:3344/actuator/bus-refresh" —次发送…...

逆波兰式的写法
一、什么是波兰式,逆波兰式和中缀表达式 6 *(37) -2 将运算数放在数值中间的运算式叫做中缀表达式 - * 6 3 7 2 将运算数放在数值前间的运算式叫做前缀表达式 6 3 7 * 2 - 将运算数放在数值后间的运算式叫做后缀表达式 二、生成逆波兰表达式 6 *(37) -2 生成…...

Linux系统日志介绍
Linux系统日志都是放在“/var/log”目录下面,各个日志文件的功能: /var/log/messages — 包括整体系统信息,其中也包含系统启动期间的日志。此外,mail,cron,daemon,kern和auth等内容也记录在va…...
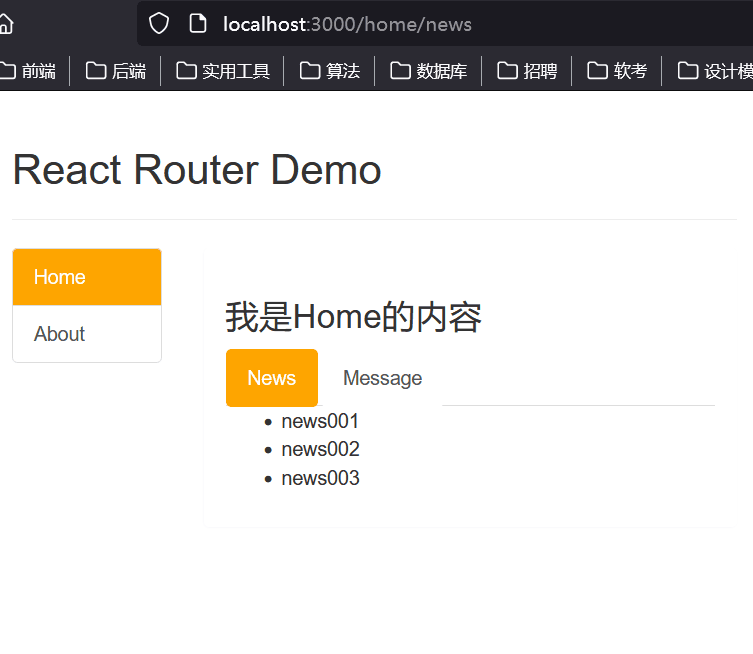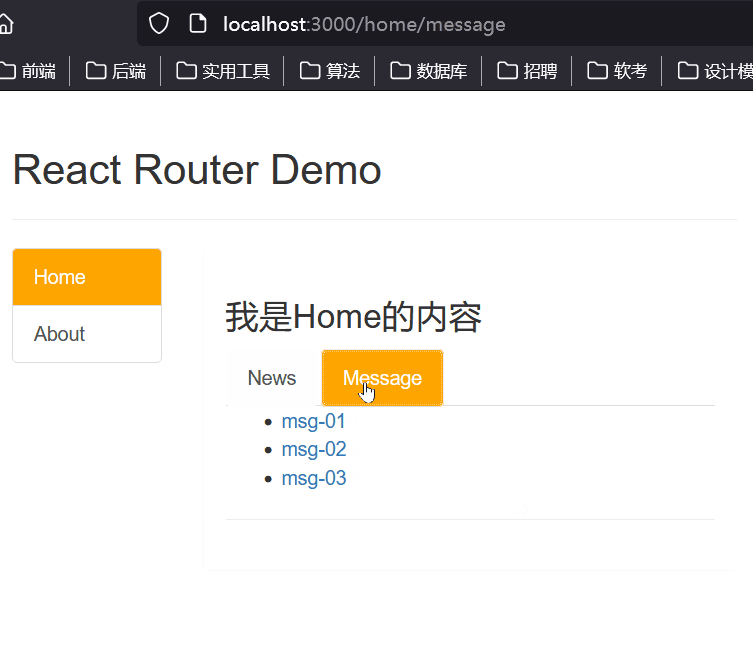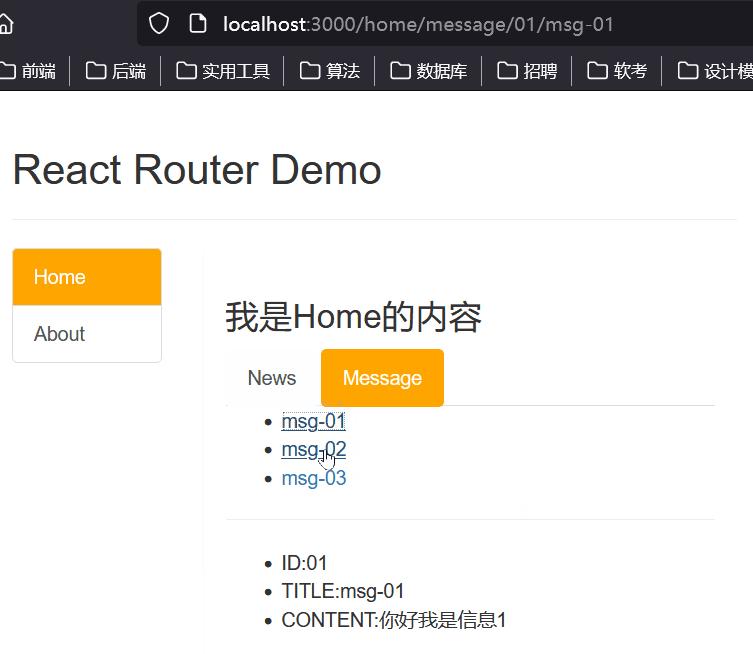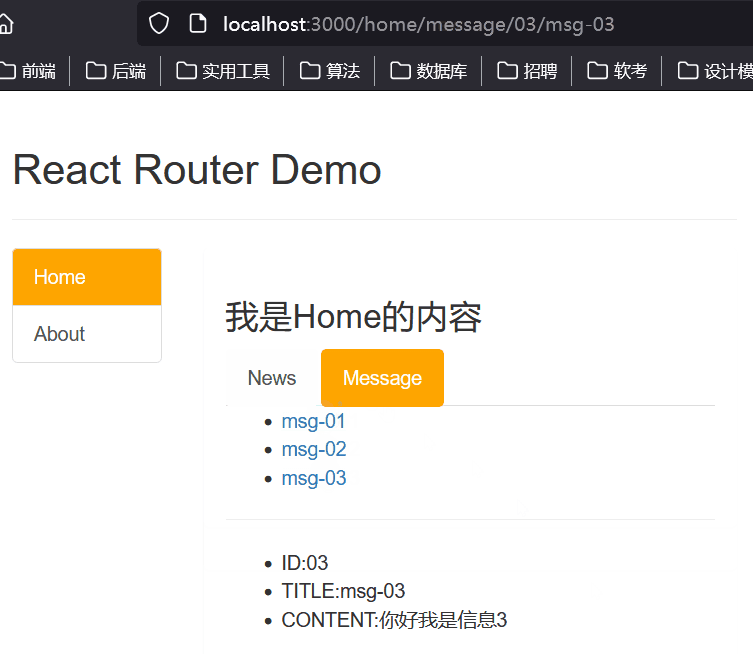
第三十二章 React路由组件的简单使用
1、NavLink的使用 一个特殊版本的 Link,当它与当前 URL 匹配时,为其渲染元素添加样式属性 <NavLink className"list-group-item" to"/home">Home</NavLink> <NavLink className"list-group-item" to&quo…...

“裸奔”时代下,我们该如何保护网络隐私?
当我们在互联网上进行各种活动时,我们的个人信息和数据可能会被攻击者窃取或盗用。为了保护我们的隐私和数据安全,以下是一些实用的技巧和工具,可以帮助您应对网络攻击、数据泄露和隐私侵犯的问题: 使用强密码:使用独特…...

c#笔记-方法
方法 方法定义 方法可以将一组复杂的代码进行打包。 声明方法的语法是返回类型 方法名 括号 方法体。 void Hello1() {for (int i 0; i < 10; i){Console.WriteLine("Hello");} }调用方法 方法的主要特征就是他的括号。 调用方法的语法是方法名括号。 He…...
)
054、牛客网算法面试必刷TOP101--堆/栈/队列(230509)
文章目录 前言堆/栈/队列1、BM42 用两个栈实现队列2、BM43 包含min函数的栈3、BM44 有效括号序列4、BM45 滑动窗口的最大值5、BM46 最小的K个数6、BM47 寻找第K大7、BM48 数据流中的中位数8、BM49 表达式求值 其它1、se基础 前言 提示:这里可以添加本文要记录的大概…...
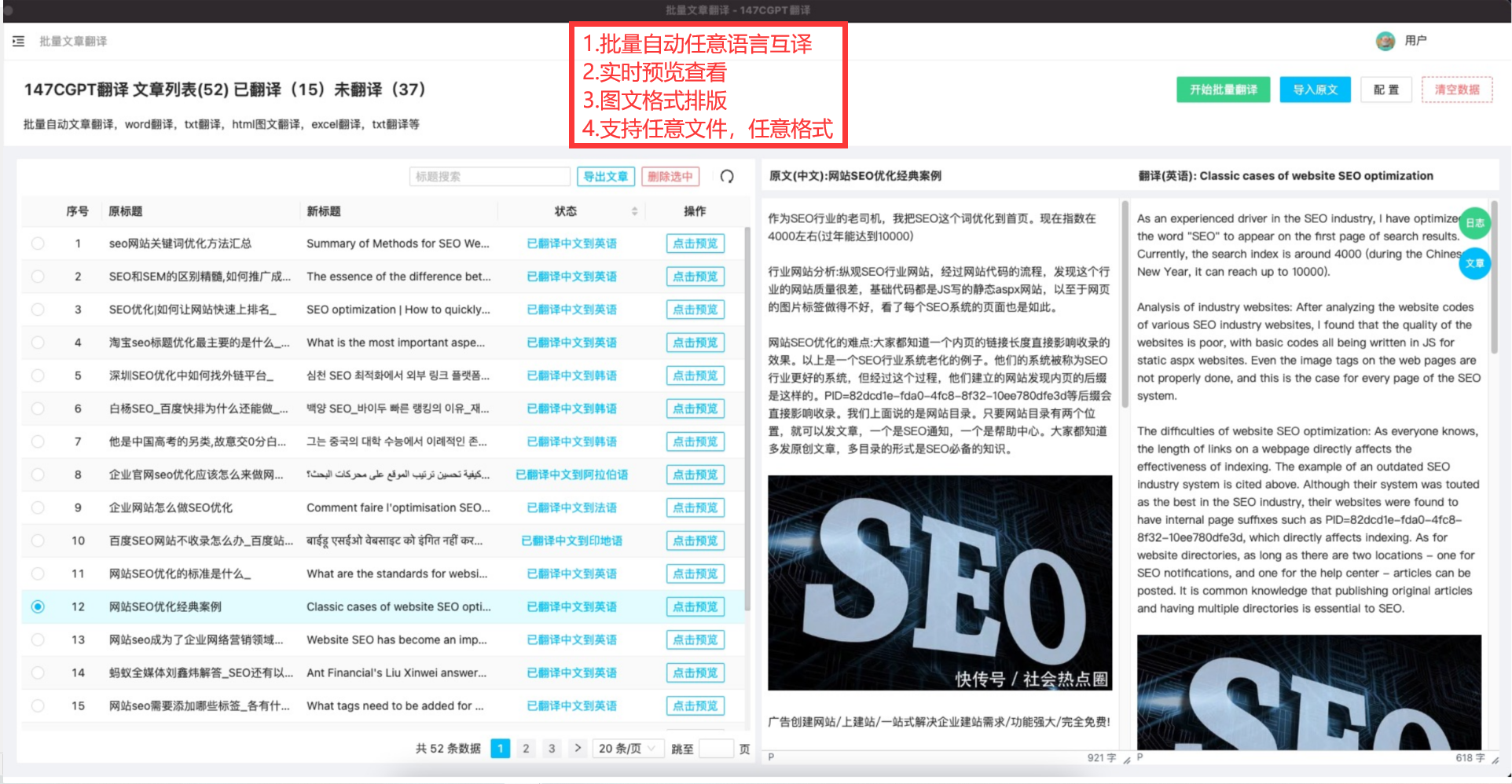
怎么让chatGTP写论文-chatGTP写论文工具
chatGTP如何写论文 ChatGPT是一个使用深度学习技术训练的自然语言处理模型,可以用于生成自然语言文本,例如对话、摘要、文章等。作为一个人工智能技术,ChatGPT可以帮助你处理一些文字内容,但并不能代替人类的创造性思考和判断。以…...

springboot 断点上传、续传、秒传实现
文章目录 前言一、实现思路二、数据库表对象二、业务入参对象三、本地上传实现三、minio上传实现总结 前言 springboot 断点上传、续传、秒传实现。 保存方式提供本地上传(单机)和minio上传(可集群) 本文主要是后端实现方案&…...
2023河南省赛vp题解
目录 A题: B题 C题 D题 E题 F题 G题 H题 I题 J题 K题 L题 A题: 1.思路:考虑暴力枚举和双hash,可以在O(n)做完。 2.代码实现: #include<bits/stdc.h> #define sz(x) (int) x.size() #define rep(i,z,…...

港科夜闻|香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地。“港科资管通领航基金”28日在香港成立,将致力于推动高校科研成果转化,助力香港国际创科中心建设。…...

Neo4j 笔记
启动命令 neo4j console Cypher句法由四个不同的部分组成, 每一部分都有一个特殊的规则: start——查找图形中的起始节点。 match——匹配图形模式, 可以定位感兴趣数据的子图形。 where——基于某些标准过滤数据。 return——返回感兴趣的…...
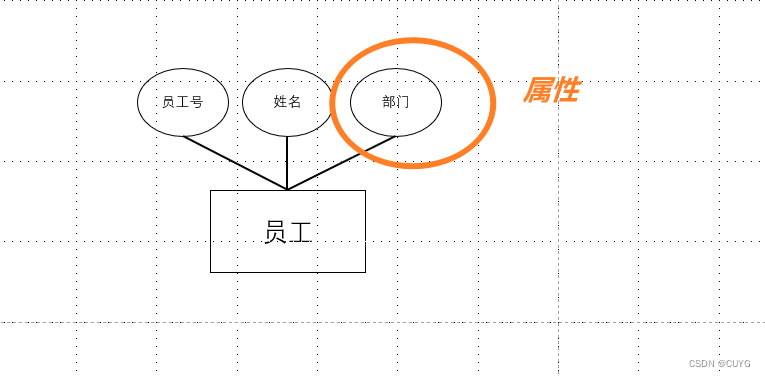
数据库基础应用——概念模型
1、实体(Entity) 客观存在并可相互区别的事物称为实体。实体可以是人、物、对象、概念、事物本身、事物之间的联系。(例如一名员工、一个部门、一辆汽车等等。) 2、属性(Attributre) 实体所具有的每个特性称为属性。(例如:员工由员…...

【学姐面试宝典】前端基础篇Ⅴ——JS深浅拷贝、箭头函数、事件监听等
前言 博主主页👉🏻蜡笔雏田学代码 专栏链接👉🏻【前端面试专栏】 今天继续学习前端面试题相关的知识! 感兴趣的小伙伴一起来看看吧~🤞 文章目录 什么是事件监听事件委托以及冒泡原理介绍一下 promise&#…...

最新研究,GPT-4暴露了缺点!无法完全理解语言歧义!
夕小瑶科技说 原创作者 |智商掉了一地、Python自然语言推理(Natural Language Inference,NLI)是自然语言处理中一项重要任务,其目标是根据给定的前提和假设,来判断假设是否可以从前提中推断出来。然而,由于…...

商业数据挖掘-第一章-数据探索式分析-1
数据探索最基本的步骤之一是获取对数据的基本描述,通过获取对数据的基本描述从而获得对数据的基本感觉。下面的一些方法用于帮助我们认识数据。 我们使用波士顿房价预测的数据集进行实验 DataFrame.describe():查看数据的基本分布,具体是对每列数据进行统计,统计值包含频…...

MybatisPlus是否防止SQL注入?
问 如果我希望使用mybatisplus同时也进行防SQL注入操作,应该怎么处理? 答 如果你想在使用 MyBatis-Plus 进行数据库操作的同时也进行防 SQL 注入处理,可以采用以下两种方式: 使用 #{} 占位符:在 QueryWrapper 或 Up…...
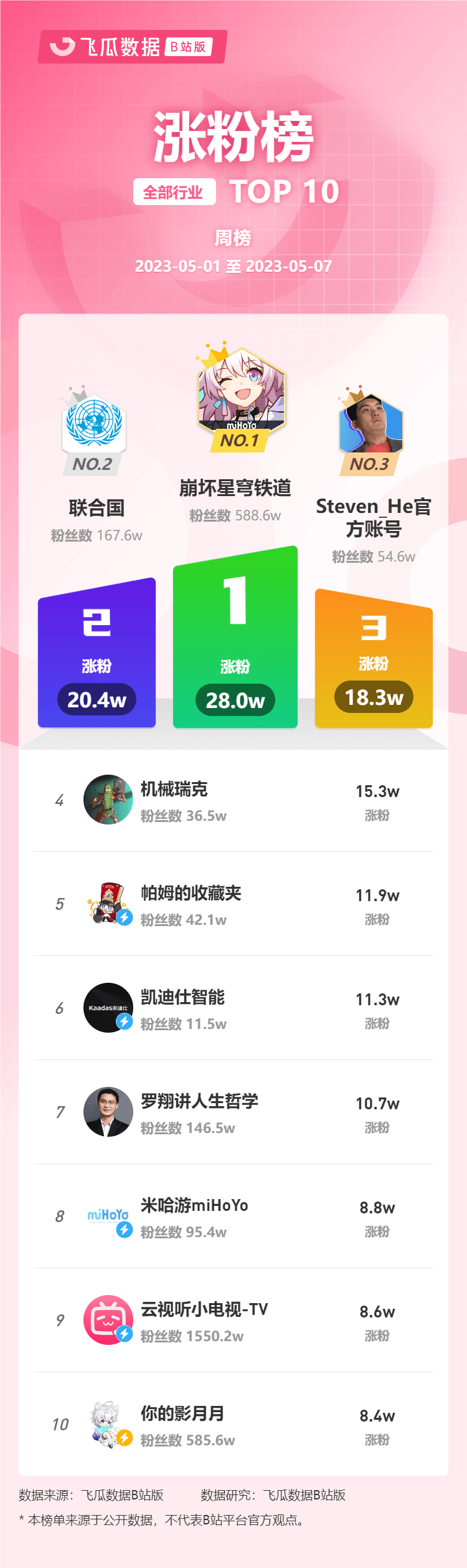
5月第1周榜单丨飞瓜数据B站UP主排行榜(哔哩哔哩平台)发布!
飞瓜轻数发布2023年5月1日-5月7日飞瓜数据UP主排行榜(B站平台),通过充电数、涨粉数、成长指数三个维度来体现UP主账号成长的情况,为用户提供B站号综合价值的数据参考,根据UP主成长情况用户能够快速找到运营能力强的B站…...

数据的插入删除和更新
在之前我们就已经学过了数据的插入,在这里再进行一点内容的补充: 在insert语句中,value子句中参数的顺序与表中各个列的顺序是一一对应的。 mysql> insert into first_table(second_column, first_column) values(aaa, 1); Query OK, 1 r…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
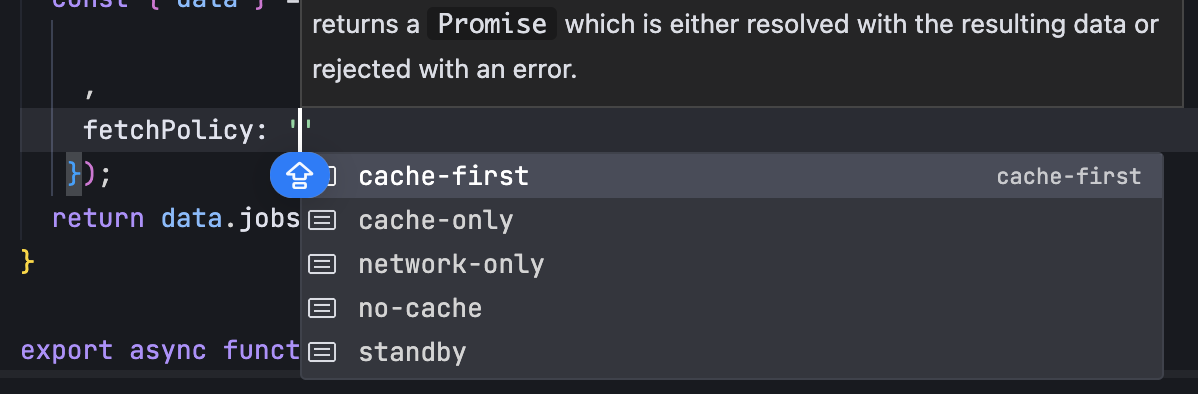
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...