通过OpenCL内核代码猜测设备寄存器个数
在OpenCL标准中,没有给出查看计算设备一共有多少寄存器,至少能分配给每个work-item多少寄存器使用的特征查询。而由于一个段内核代码是否因寄存器紧缺而导致性能严重下降也是一个比较重要的因素,因此我这边提供一个比较基本的方法来猜测当前计算设备至少能为每个work-item分配多少可用的寄存器。
这个方法的思路是,先定义四个临时变量,然后在一个大规模循环里面做一定规模的计算。然后把时间统计出来。随后,再定义八个临时变量,仍然,在与前者相同次数的循环里做一定规模的计算,再把时间统计出来。一般,如果寄存器不爆,或者由于Cache的缘故,性能影响不大的话,两者消耗时间一般在2倍左右。如果后者比前者超了2.2倍以上,那么我们即可认为寄存器爆了~
这个方法对于一般的GPU更有用些。由于CPU往往拥有L1 Data Cache,当寄存器不够用的时候,编译器会将不太常用的数据放到栈中,而栈在此时往往能获得高命中率的Cache访问,因此性能不会过受影响。而GPU端当寄存器不够用时,编译器往往会采取将不常用数据直接存放到VRAM中,而对外部VRAM的访问往往是比较慢的,因此,如果临时变量太多,使得频繁访问外部存储器,会使得整体计算性能大幅下降。当然,现在不少GPU也有了L1 Cache,但是空间也十分有限。因此,这里用“猜”这个词~🙂
下面先提供四个临时变量的kernel代码:
kernel void QueryRegisterCount(__global int *pInOut)
{int index = get_global_id(0);int i0 = pInOut[(index * 4 + 0) * 4];int i1 = pInOut[(index * 4 + 1) * 4];int i2 = pInOut[(index * 4 + 2) * 4];int i3 = pInOut[(index * 4 + 3) * 4];for(int i = 0; i < 100000; i++){i1 += i0 << 1;i2 += i1 << 1;i3 += i2 << 1;i0 += i3 << 1;i1 += i0 >> 1;i2 += i1 >> 1;i3 += i2 >> 1;i0 += i3 >> 1;i1 += i0 >> 2;i2 += i1 >> 2;i3 += i2 >> 2;i0 += i3 >> 2;i1 += i0 >> 3;i2 += i1 >> 3;i3 += i2 >> 3;i0 += i3 >> 3;}pInOut[(index * 4 + 0) * 4] = i0;pInOut[(index * 4 + 1) * 4] = i1;pInOut[(index * 4 + 2) * 4] = i2;pInOut[(index * 4 + 3) * 4] = i3;
}
再提供八个临时变量的kernel代码:
kernel void QueryRegisterCount(__global int *pInOut)
{int index = get_global_id(0);int i0 = pInOut[(index * 8 + 0) * 4];int i1 = pInOut[(index * 8 + 1) * 4];int i2 = pInOut[(index * 8 + 2) * 4];int i3 = pInOut[(index * 8 + 3) * 4];int i4 = pInOut[(index * 8 + 4) * 4];int i5 = pInOut[(index * 8 + 5) * 4];int i6 = pInOut[(index * 8 + 6) * 4];int i7 = pInOut[(index * 8 + 7) * 4];for(int i = 0; i < 100000; i++){i1 += i0 << 1;i2 += i1 << 1;i3 += i2 << 1;i4 += i3 << 1;i5 += i4 << 1;i6 += i5 << 1;i7 += i6 << 1;i0 += i7 << 1;i1 += i0 >> 1;i2 += i1 >> 1;i3 += i2 >> 1;i4 += i3 >> 1;i5 += i4 >> 1;i6 += i5 >> 1;i7 += i6 >> 1;i0 += i7 >> 1;i1 += i0 >> 2;i2 += i1 >> 2;i3 += i2 >> 2;i4 += i3 >> 2;i5 += i4 >> 2;i6 += i5 >> 2;i7 += i6 >> 2;i0 += i7 >> 2;i1 += i0 >> 3;i2 += i1 >> 3;i3 += i2 >> 3;i4 += i3 >> 3;i5 += i4 >> 3;i6 += i5 >> 3;i7 += i6 >> 3;i0 += i7 >> 3;}pInOut[(index * 8 + 0) * 4] = i0;pInOut[(index * 8 + 1) * 4] = i1;pInOut[(index * 8 + 2) * 4] = i2;pInOut[(index * 8 + 3) * 4] = i3;pInOut[(index * 8 + 4) * 4] = i4;pInOut[(index * 8 + 5) * 4] = i5;pInOut[(index * 8 + 6) * 4] = i6;pInOut[(index * 8 + 7) * 4] = i7;
}
而像16个、32个临时变量的方法依此类推~
然后,给出主机端代码:
/** Prepare for running an OpenCL kernel program to get register count *//*Step 4: Creating command queue associate with the context.*/commandQueue = clCreateCommandQueue(context, device, CL_QUEUE_PROFILING_ENABLE, NULL);/*Step 5: Create program object */// Read the kernel code to the bufferkernelPath = [[NSBundle mainBundle] pathForResource:@"reg" ofType:@"ocl"];aSource = [[NSString stringWithContentsOfFile:kernelPath encoding:NSUTF8StringEncoding error:nil] UTF8String];kernelLength = strlen(aSource);program = clCreateProgramWithSource(context, 1, &aSource, &kernelLength, NULL);/*Step 6: Build program. */status = clBuildProgram(program, 1, &device, NULL, NULL, NULL);/*Step 7: Initial inputs and output for the host and create memory objects for the kernel*/const size_t memSize = global_work_size[0] * 1024 * 4 * 4;cl_int *orgBufer = (cl_int*)malloc(memSize);memset(orgBufer, 1, memSize);outputMemObj = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, memSize, orgBufer, NULL);/*Step 8: Create kernel object */kernel = clCreateKernel(program, "QueryRegisterCount", NULL);/*Step 9: Sets Kernel arguments.*/status |= clSetKernelArg(kernel, 0, sizeof(outputMemObj), &outputMemObj);/*Step 10: Running the kernel.*/for(int i = 0; i < 5; i++){NSTimeInterval beginTime = [[NSProcessInfo processInfo] systemUptime];status |= clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, global_work_size, local_work_size, 0, NULL, NULL);clFinish(commandQueue);NSTimeInterval endTime = [[NSProcessInfo processInfo] systemUptime];NSLog(@"Time spent: %f", endTime - beginTime);}free(orgBufer);if(status != CL_SUCCESS){NSLog(@"Program built failed!");return;}clReleaseMemObject(outputMemObj);clReleaseProgram(program);clReleaseKernel(kernel);clReleaseCommandQueue(commandQueue);clReleaseContext(context);
以上由于是在macOS下开发的,因此直接用Objective-C文件读写更方便些。但是大部分都是C代码,很容易读懂。
其中,最后一断代码中,我们做5次循环,统计时间。我们比较的时候往往选出5次执行时间中最小耗费的时间进行比较。
在2013年的MacBook Air中的Intel HD 5000中的测试结果为:
- 四个临时变量耗费:0.061020秒
- 八个临时变量耗费:0.121868秒
- 十六个临时变量耗费:0.243470秒
- 三十二个临时变量耗费:0.719506秒
很显然,我们可以猜得,Intel HD Graphics 5000至少可以为每个work-item分配16个寄存器。
我们如果要用在实际应用场合,可以通过动态生成kernel字符串依次执行进行检测,直到相邻两段kernel的执行时间超过2.2倍,那么我们即可终止。
相关文章:

通过OpenCL内核代码猜测设备寄存器个数
在OpenCL标准中,没有给出查看计算设备一共有多少寄存器,至少能分配给每个work-item多少寄存器使用的特征查询。而由于一个段内核代码是否因寄存器紧缺而导致性能严重下降也是一个比较重要的因素,因此我这边提供一个比较基本的方法来猜测当前计…...

C# + .Net6 实现TensorFlow图片分类
微软官网上发现一篇很有意思的文档:教程:用于对图像进行分类的 ML.NET 分类模型 - ML.NET | Microsoft Learn 这篇教程写的很学院派,但有点碎,属于上课不能打一秒钟瞌睡的那种。好在还是给出了完整的代码:samples/Pro…...

Ngnix负载均衡和高可用集群及搭建与相关理论
Ngnix负载均衡和高可用集群及搭建与相关理论 全文目录 Ngnix负载均衡和高可用集群及搭建与相关理论高可能保持原理配置 keepalived:配置keepalived的IP将外部域名解析到Keepalived的虚拟IP上如何验证配置的正确性Nginx专用调试工具ngx_conf_t如何对前后端多台服务器…...
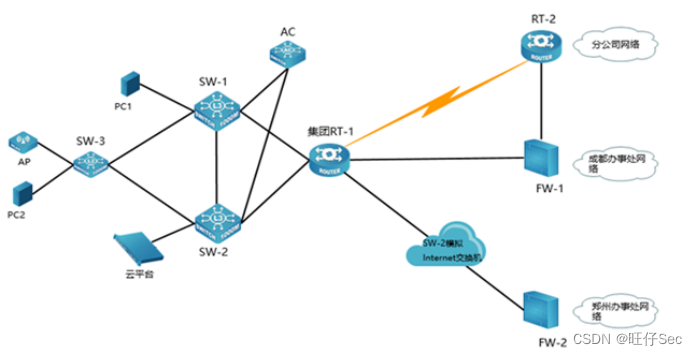
2022年宜昌市网络搭建与应用竞赛样题(三)
网络搭建与应用竞赛样题(三) 技能要求 (总分1000分) 竞赛说明 一、竞赛内容分布 “网络搭建与应用”竞赛共分三个部分,其中: 第一部分:网络搭建及安全部署项目(500分࿰…...
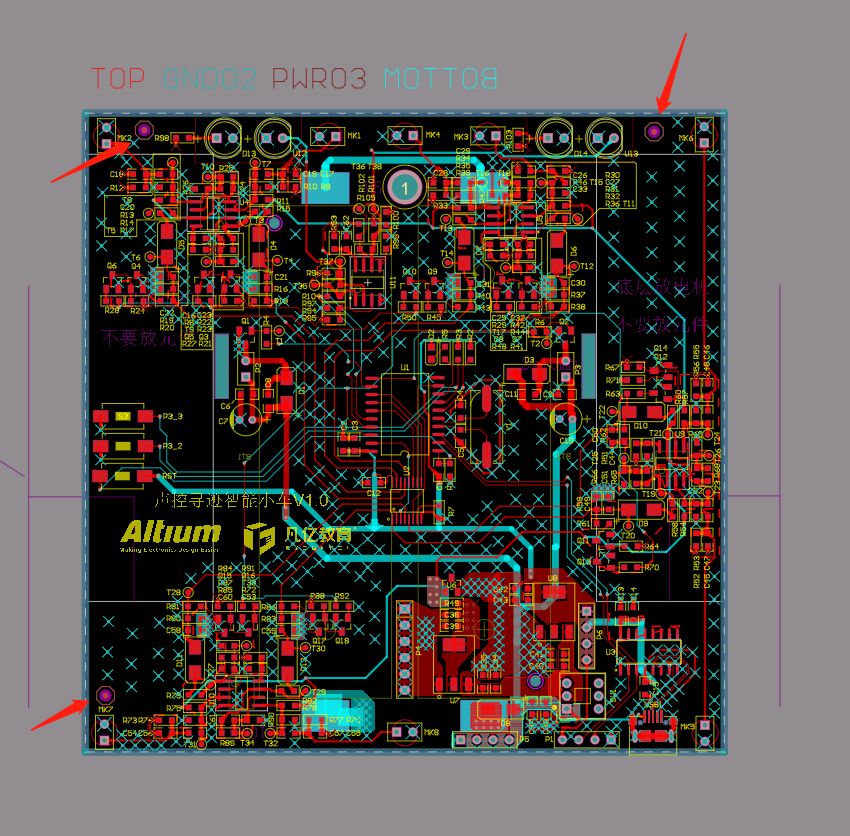
为什么PCB设计完成后需要放置mark点
PCB设计中的Mark点是指一些标记点,通常用于促进PCB制造和组装过程中的准确性和一致性。这些标记点在制造过程中可以帮助操作员进行自动化定位,从而确保所有部件都被正确组装到其正确位置,这对于确保产品的质量和可靠性至关重要。 下面&#…...

代理IP:IP代理技术与Socks5协议
代理IP是一种用于隐藏真实IP地址的技术,它可以将请求发送至代理服务器,再由代理服务器转发请求至目标网站。代理服务器会在请求过程中替换真实IP地址,从而保护用户的隐私和安全。在网络爬虫、反爬虫、匿名访问等场景中,代理IP技术…...

如何让java程序员生涯更顺利?我聊聊提升技术水平的五个方面
今天我想和大家聊聊程序员职业发展的问题。相信大家都知道,IT公司因为各种原因裁员,对程序员的前途发展都是不利的。特别是等到你30多岁,上有老下有小,仍然要加班,与年轻人竞争体力和智力,这是很艰难的。如…...
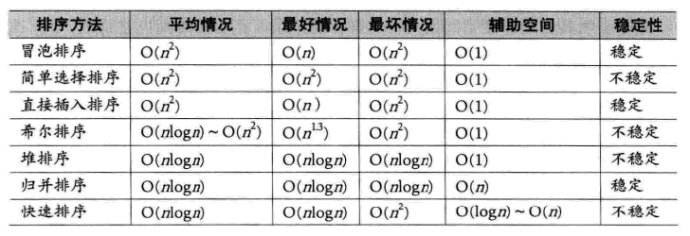
快速排序、希尔排序、归并排序、堆排序、插入排序、冒泡排序、选择排序(递归、非递归)C语言详解
1.排序的概念及其运用 1.1排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录&a…...

ChatGPT一键私有部署,全网可用,让访问、问答不再受限,且安全稳定!
前言 ChatGPT由于在访问上有一些限制,使用并不便利。目前国内可以直接访问的大部分是调用API返回结果,我们去使用时总会有次数限制,而且它们可能随便崩掉。 其实,目前我们访问过的大部分国内的网页包括UI,其实是套用了…...
自学黑客(网络安全),一般人我劝你还是算了吧
一、自学网络安全学习的误区和陷阱 1.不要试图先成为一名程序员(以编程为基础的学习)再开始学习 我在之前的回答中,我都一再强调不要以编程为基础再开始学习网络安全,一般来说,学习编程不但学习周期长,而…...
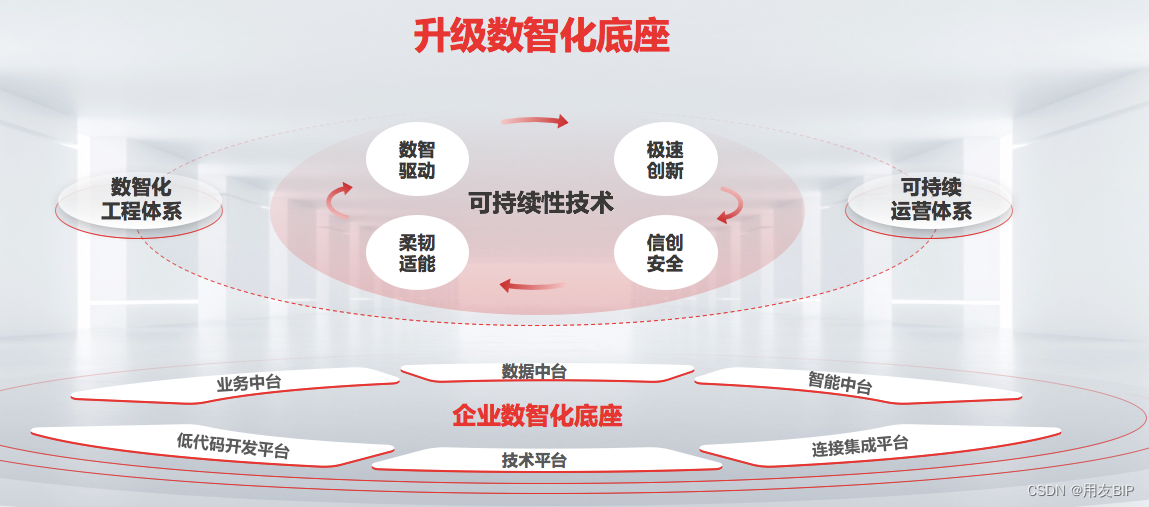
盘“底座”,盘出新生意经
本文转自首席信息官 作者 徐蕊 导读 卖“底座”,这是一门新的生意,也是用友与友商差异化的商业竞争优势所在。 大型企业都在建“数智化底座” 有这样两类企业,他们截然不同,但在数智化的建设上殊途同归。 随着中国经济的发展&a…...

《花雕学AI》Poe:一个让你和 AI 成为朋友的平台,带你探索 ChatGPT4 和其他 八种AI 模型的奥秘
你是否曾经梦想过,能够在一个平台上,和多种不同的 AI 模型进行有趣、有用、有深度的对话,甚至还能轻松地把你的对话分享给其他人?如果你有这样的梦想,那么 Poe 一站式 AI 工具箱就是你的不二之选! Poe 是国…...
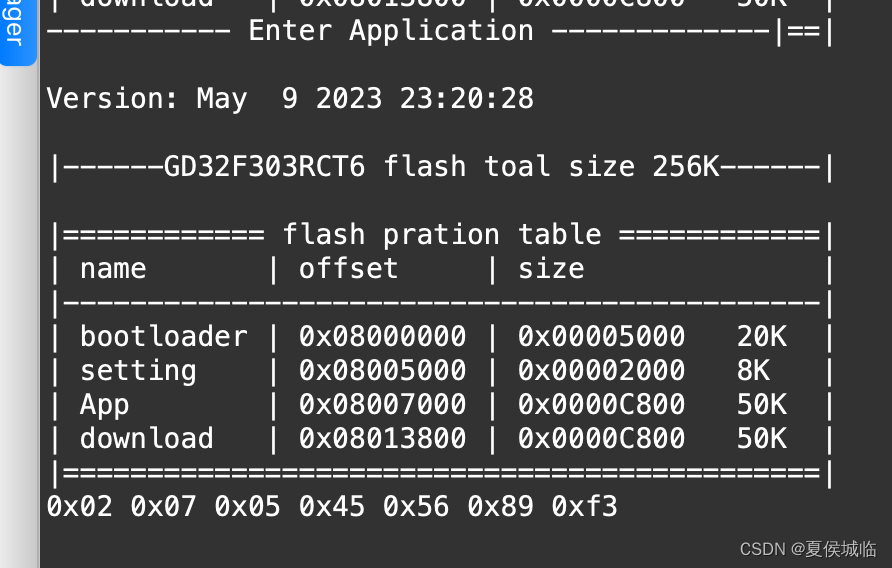
单片机GD32F303RCT6 (Macos环境)开发 (十五)—— i2c1采用DMA方式的读写函数
i2c1采用DMA方式的读写函数 1、关于i2c1的DMA的映射如图 2、关于代码的宏定义配置 Application目录的Makefile中 ENABLE_I2C_TEST yes才会编译I2C1的相关代码。 同时修改i2c.h文件,定义I2C1_MODE为I2C1_MODE_DMA,这样i2c1的配置为dma模式。 #define …...

通知短信 API 技术细节以及发送流程机制原理解析
引言 短信是一种简单、直接、高效的通信方式,被广泛应用于各个领域。在移动互联网时代,短信成为了客户服务、政府通知、公共服务等方面的重要工具。为了更好地利用短信这种通信方式,通知短信 API应运而生。短信API可以帮助企业、政府和应用程…...

Protobuf: 高效数据传输的秘密武器
当涉及到网络通信和数据存储时,数据序列化一直都是一个重要的话题;特别是现在很多公司都在推行微服务,数据序列化更是重中之重,通常会选择使用 JSON 作为数据交换格式,且 JSON 已经成为业界的主流。但是 Google 这么大…...
第五十四章 Unity 移动平台输入(下)
本章节我们介绍一个模拟器插件。这种插件比较多,比如EasyTouch,Lean Touch,Joystick Pack等等。EasyTouch是一个使用非常广泛的插件,支持点击,拖拽,遥感等很多常用功能。不过遗憾的是,该插件已经…...

KD305Y带吸收比极化指数兆欧表
一、概述 KD305Y绝缘电阻测试仪对众多的电力设备如:电缆、电机、发电机、变压器、互感器、高压开关、避雷器等要求做一系列的绝缘性能试验,首先是要做绝缘电阻测试。近年来随着电力事业的飞速发展,大容量设备的使用不断增加,用普通的兆欧表无…...
磁盘空间不足怎么办?释放磁盘空间的4种方法
虽然现在硬盘的空间越来越大,但是在这个数据爆炸的时代中,总是会觉得存储空间不够用,一不注意磁盘就满了,那么除了清空回收站、卸载某些程序外,还能怎么释放磁盘空间呢? 方案一:禁用休眠 休眠是…...
ChatGPT调教指北,技巧就是效率!
技巧就是效率 很多人都知道ChatGPT很火很强,几乎无所不能,但跨越了重重门槛之才有机会使用的时候却有些迷茫,一时间不知道如何使用它。如果你就是把他当作一个普通的智能助手来看待,那与小爱同学有什么区别?甚至还差劲…...
——init进程对子进程的监控)
Android启动流程(五)——init进程对子进程的监控
init进程会读取rc文件,然后孵化很多其他系统服务进程,为防止子进程死亡后称为僵尸进程,init需要监测子进程是否死亡,如果死亡,则清除子进程资源,并重新拉起进程。 system/core/init/init.cpp InstallSigna…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...