ChatGPT的强化学习部分介绍——PPO算法实战LunarLander-v2
PPO算法
近线策略优化算法(Proximal Policy Optimization Algorithms) 即属于AC框架下的算法,在采样策略梯度算法训练方法的同时,重复利用历史采样的数据进行网络参数更新,提升了策略梯度方法的学习效率。 PPO重要的突破就是在于对新旧新旧策略器参数进行了约束,希望新的策略网络和旧策略网络的越接近越好。 近线策略优化的意思就是:新策略网络要利用到旧策略网络采样的数据进行学习,不希望这两个策略相差特别大,否则就会学偏。PPO依然是openai在2017年提出来的,论文地址
PPO-clip的损失函数,其中损失包含三个部分:
- clip部分:加权采样后的优势值越好(可理解层价值网络的评分),同时采样通过clip防止新旧策略网络相差过大
- VF部分: 价值网络预测的价值和环境真是的回报值越接近越好
- S 部分:策略网络输出策略的熵值,越大越好,这个explore的思想,希望策略网络输出的动作分布概率不要太集中,提高了每个动作都有机会在环境中发生的可能。
实战部分
导入必要的包
%matplotlib inline
import matplotlib.pyplot as pltfrom IPython import displayimport numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
from tqdm.notebook import tqdm
准备环境
准备好openai开发的LunarLander-v2的游戏环境。
seed = 543
def fix(env, seed):env.action_space.seed(seed)torch.manual_seed(seed)np.random.seed(seed)random.seed(seed)
import gym
import random
env = gym.make('LunarLander-v2' ,render_mode='rgb_array')
fix(env, seed) # fix the environment Do not revise this !!!
下面是采用代码去输出 环境的 观测值,一个8维向量,动作是一个标量,4选一。
- 该环境共有 8 个观测值,分别是: 水平坐标 x; 垂直坐标 y; 水平速度; 垂直速度; 角度; 角速度; 腿1触地; 腿2触地;
- 可以采取四种离散的行动,分别是: 0 代表不采取任何行动 1.代表主引擎向左喷射 2 .代表主引擎向下喷射 3 .代表主引擎向右喷射
- 环境中的 reward 大致是这样计算: 小艇坠毁得到 -100 分; 小艇在黄旗帜之间成功着地则得 100~140 分; 喷射主引擎(向下喷火)每次 -0.3 分; 小艇最终完全静止则再得 100 分
随机动作玩5把
env.reset()img = plt.imshow(env.render())done = False
rewords = []
for i in range(5):env.reset()[0]img = plt.imshow(env.render())total_reward = 0done = Falsewhile not done:action = env.action_space.sample()observation, reward, done, _ , _= env.step(action)total_reward += rewardimg.set_data(env.render())display.display(plt.gcf())display.clear_output(wait=True)rewords.append(total_reward)
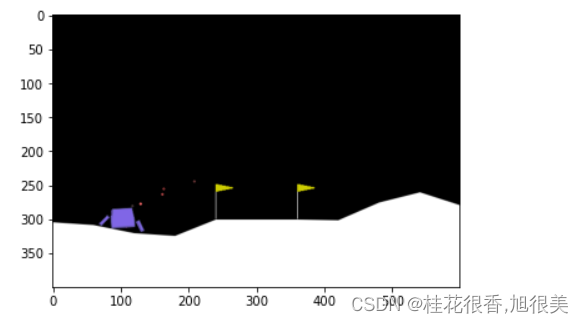
只有一把分数是正的,只有一次平安落地,小艇最终完全静止

搭建PPO agent
class Memory:def __init__(self):self.actions = []self.states = []self.logprobs = []self.rewards = []self.is_terminals = []def clear_memory(self):del self.actions[:]del self.states[:]del self.logprobs[:]del self.rewards[:]del self.is_terminals[:]class ActorCriticDiscrete(nn.Module):def __init__(self, state_dim, action_dim, n_latent_var):super(ActorCriticDiscrete, self).__init__()# actorself.action_layer = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, action_dim),nn.Softmax(dim=-1))# criticself.value_layer = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 1))def act(self, state, memory):state = torch.from_numpy(state).float()action_probs = self.action_layer(state)dist = Categorical(action_probs)action = dist.sample()memory.states.append(state)memory.actions.append(action)memory.logprobs.append(dist.log_prob(action))return action.item()def evaluate(self, state, action):action_probs = self.action_layer(state)dist = Categorical(action_probs)action_logprobs = dist.log_prob(action)dist_entropy = dist.entropy()state_value = self.value_layer(state)return action_logprobs, torch.squeeze(state_value), dist_entropyclass PPOAgent:def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):self.lr = lrself.betas = betasself.gamma = gammaself.eps_clip = eps_clipself.K_epochs = K_epochsself.timestep = 0self.memory = Memory()self.policy = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)self.policy_old = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)self.policy_old.load_state_dict(self.policy.state_dict())self.MseLoss = nn.MSELoss()def update(self): # Monte Carlo estimate of state rewards:rewards = []discounted_reward = 0for reward, is_terminal in zip(reversed(self.memory.rewards), reversed(self.memory.is_terminals)):if is_terminal:discounted_reward = 0discounted_reward = reward + (self.gamma * discounted_reward)rewards.insert(0, discounted_reward)# Normalizing the rewards:rewards = torch.tensor(rewards, dtype=torch.float32)rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)# convert list to tensorold_states = torch.stack(self.memory.states).detach()old_actions = torch.stack(self.memory.actions).detach()old_logprobs = torch.stack(self.memory.logprobs).detach()# Optimize policy for K epochs:for _ in range(self.K_epochs):# Evaluating old actions and values : 新策略 重用 旧样本进行训练 logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)# Finding the ratio (pi_theta / pi_theta__old): ratios = torch.exp(logprobs - old_logprobs.detach())# Finding Surrogate Loss:计算优势值advantages = rewards - state_values.detach()surr1 = ratios * advantages ### 重要性采样的思想,确保新的策略函数和旧策略函数的分布差异不大surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages ### 采样clip的方式过滤掉一些新旧策略相差较大的样本loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy# take gradient stepself.optimizer.zero_grad()loss.mean().backward()self.optimizer.step()# Copy new weights into old policy:self.policy_old.load_state_dict(self.policy.state_dict())def step(self, reward, done):self.timestep += 1 # Saving reward and is_terminal:self.memory.rewards.append(reward)self.memory.is_terminals.append(done)# update if its timeif self.timestep % update_timestep == 0:self.update()self.memory.clear_memory()self.timstamp = 0def act(self, state):return self.policy_old.act(state, self.memory)
训练PPO agent
state_dim = 8 ### 游戏的状态是个8维向量
action_dim = 4 ### 游戏的输出有4个取值
n_latent_var = 256 # 神经元个数
update_timestep = 1200 # 每多少补跟新策略
lr = 0.002 # learning rate
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO 论文中表明0.2效果不错
random_seed = 1 agent = PPOAgent(state_dim ,action_dim,n_latent_var,lr,betas,gamma,K_epochs,eps_clip)
# agent.network.train() # Switch network into training mode
EPISODE_PER_BATCH = 5 # update the agent every 5 episode
NUM_BATCH = 200 # totally update the agent for 400 timeavg_total_rewards, avg_final_rewards = [], []# prg_bar = tqdm(range(NUM_BATCH))
for i in range(NUM_BATCH):log_probs, rewards = [], []total_rewards, final_rewards = [], []values = []masks = []entropy = 0# collect trajectoryfor episode in range(EPISODE_PER_BATCH):### 重开一把游戏state = env.reset()[0]total_reward, total_step = 0, 0seq_rewards = []for i in range(1000): ###游戏未结束action = agent.act(state) ### 按照策略网络输出的概率随机采样一个动作next_state, reward, done, _, _ = env.step(action) ### 与环境state进行交互,输出reward 和 环境next_statestate = next_statetotal_reward += rewardtotal_step += 1 rewards.append(reward) ### 记录每一个动作的rewardagent.step(reward, done) if done: ###游戏结束final_rewards.append(reward)total_rewards.append(total_reward)breakprint(f"rewards looks like ", np.shape(rewards)) if len(final_rewards)> 0 and len(total_rewards) > 0:avg_total_reward = sum(total_rewards) / len(total_rewards)avg_final_reward = sum(final_rewards) / len(final_rewards)avg_total_rewards.append(avg_total_reward)avg_final_rewards.append(avg_final_reward)
PPO agent在玩5把游戏
fix(env, seed)
agent.policy.eval() # set the network into evaluation mode
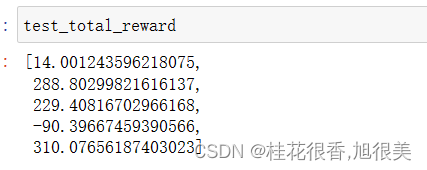
test_total_reward = []
for i in range(5):actions = []state = env.reset()[0]img = plt.imshow(env.render())total_reward = 0done = Falsewhile not done :action= agent.act(state)actions.append(action)state, reward, done, _, _ = env.step(action)total_reward += rewardimg.set_data(env.render())display.display(plt.gcf())display.clear_output(wait=True)test_total_reward.append(total_reward)
从下图可以看到,玩得比随机的时候要好很多,有三把都平安着地,小艇最终完全静止。

其中有3把得分超过200,证明ppo在300轮已经学到了如何玩这个游戏,比之前的随机agent要强了不少。
github 源码
参考
ChatGPT的强化学习部分介绍
基于人类反馈的强化学习(RLHF) 理论
Anaconda安装GYM &关于Box2D安装的相关问题
conda-forge / packages / box2d-py
jupyter Notebook 内核似乎挂掉了,它很快将自动重启
相关文章:
ChatGPT的强化学习部分介绍——PPO算法实战LunarLander-v2
PPO算法 近线策略优化算法(Proximal Policy Optimization Algorithms) 即属于AC框架下的算法,在采样策略梯度算法训练方法的同时,重复利用历史采样的数据进行网络参数更新,提升了策略梯度方法的学习效率。 PPO重要的突…...

JavaWeb ( 八 ) 过滤器与监听器
2.6.过滤器 Filter Filter过滤器能够对匹配的请求到达目标之前或返回响应之后增加一些处理代码 常用来做 全局转码 ,session有效性判断 2.6.1.过滤器声明 在 web.xml 中声明Filter的匹配过滤特征及对应的类路径 , 3.0版本后可以在类上使用 WebFilter 注解来声明 filter-cla…...
Notion Ai中文指令使用技巧
Notion AI 是一种智能技术,可以自动处理大量数据,并从中提取有用的信息。它能够 智能搜索:通过搜索文本和查询结果进行快速访问 自动归档:可以根据关键字和日期自动将内容归档 内容分类:可以根据内容的标签和内容的…...
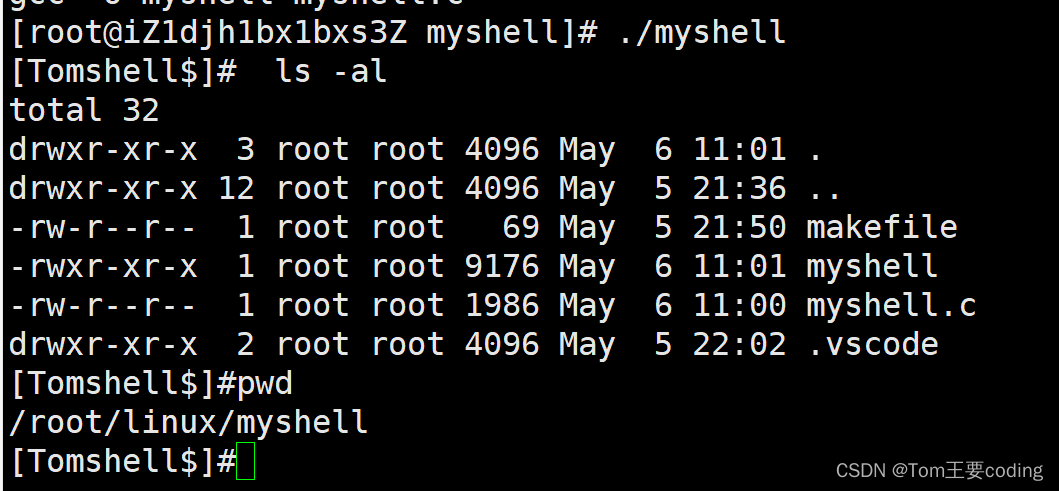
Linux一学就会——编写自己的shell
编写自己的shell 进程程序替换 替换原理 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数 以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动 例程开始执行…...

编程练习【有效的括号】
给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个右括号都有一个对应的相同类型的左…...
)
Android 音频开发——桌面小部件(七)
对于收音机的车机 APP 开发,一般都有配套的桌面小部件(Widget)开发,这里对小部件的具体实现就不介绍了,这里主要介绍一些桌面(Launcher)中的小部件(Widget)弹出窗口功能实现。 一、功能描述 在小部件上点击按钮,弹出一个有音源选择列表的弹窗,点击其他位置…...

常见的C++包管理
C包管理工具 Conan 是一款免费开源的 C/C语言的依赖项和包管理器 类似于python的anaconda Introduction — conan 2.0.4 documentationconan-io/conan: Conan - The open-source C and C package manager (github.com) CPM cmake集成的 mirrors / cpm-cmake / CPM.cmake GitC…...
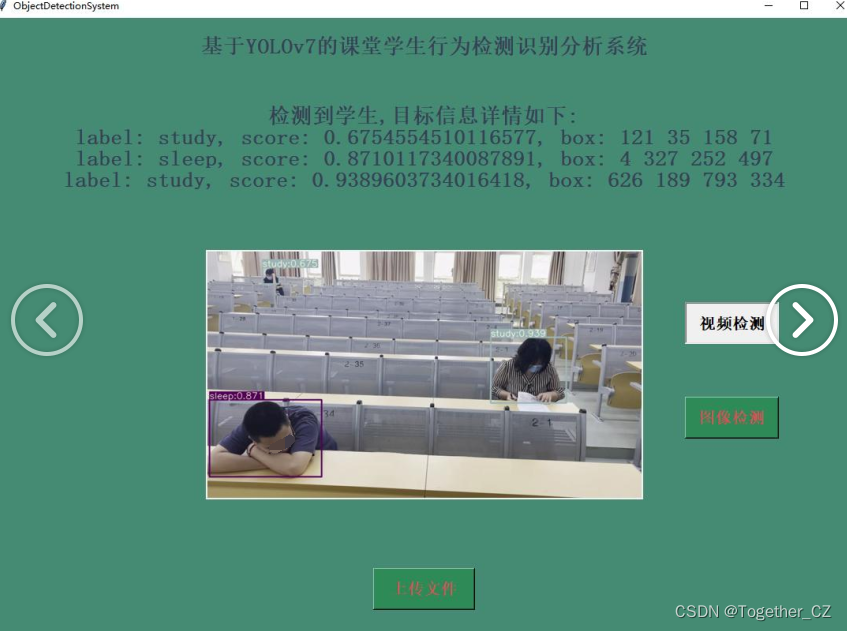
基于yolov7开发构建学生课堂行为检测识别系统
yolov7也是一款非常出众的目标检测模型,在我之前的文章中也有非常详细的教程系列的文章,感兴趣的话可以自行移步阅读即可。 《基于YOLOV7的桥梁基建裂缝检测》 《YOLOv7基于自己的数据集从零构建模型完整训练、推理计算超详细教程》 《基于YOLOv7融合…...

GPT-4 开始内测32k输入长度的版本了!你收到邀请了吗?
要说现在 GPT-4 最大的问题是什么?可能除了一时拿他没有办法的机器幻觉,就是卡死的输入长度了吧。尽管在一般的对话、搜索的场景里目前普通版本 GPT-4 的 8000 左右的上下文长度或许绰绰有余,但是在诸如内容生成、智能阅读等方面当下基础版的…...

如何用ChatGPT做新品上市推广方案策划?
该场景对应的关键词库(28个): 品牌、产品信息、新品、成分、属性、功效、人群特征、客户分析、产品定位、核心卖点、推广策略、广告、公关、线上推广、线下活动、合作伙伴、资源整合、预算、执行计划、监测、评估、微调方案、价值主张、营销策略、热点话…...

Qt之QGraphicsEffect的简单使用(含源码+注释)
文章目录 一、效果示例图1.效果演示图片3.弹窗演示图片 二.问题描述三、源码CFrame.hCFrame.cppCMainWindow.hCMainWindow.cpp 总结 一、效果示例图 1.效果演示图片 3.弹窗演示图片 二.问题描述 (因为全是简单使用,毫无技巧,直接描述问题&a…...

前端优化-css
1.css盒子模型 标准盒子模型,IE盒子模型 标准盒子模型:margin-border-padding-content IE盒子模型:margin-content(border-padding-content) 如何转换: box - sizing: border - box; // IE盒子模型 box - sizing: content - …...

第三方ipad笔哪个牌子好用?ipad触控笔推荐平价
至于选择苹果原装的电容笔,还是平替的电容笔,要看个人的需求而定,比如画图用的,可以用Apple Pencil;比如学习记笔记用的,可以用平替电容笔,目前的平替电容笔无论是品质还是性能,都非…...

windows10+detectron2完美安装教程
文章目录 前言下载detectron2安装Visual Studio 2019修改代码 前言 需要下载detectron2的github项目,安装vs2019 (强烈建议这个版本,其他的版本需要做更多地操作才能成功安装),默认其他环境没问题。 下载detectron2 链接:https…...

串口与wifi模块
经过以下学习,我们掌握: AT指令与wifi模块的测试方法:通过CH340直接测试,研究各种AT指令下wifi模块的响应信息形式。编程,使用串口中断接收wifi模块对AT指令的响应信息以及透传数据,通过判断提高指令执行的…...

上财黄烨:金融科技人才的吸引与培养
“金融科技企业在吸引人才前,应先完善人才培养机制,建立员工画像,有针对性地培训提高成员综合素质。” ——上海金融智能工程技术研究中心上海财经大学金融科技研究院秘书长&院长助理黄烨老师 01.何为数字人才? 目前大多数研…...
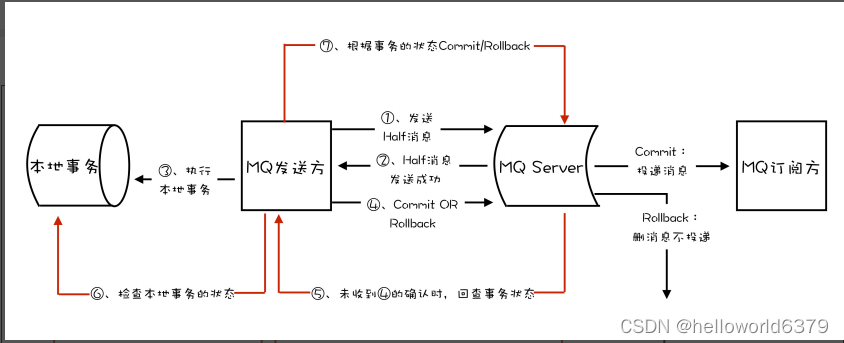
利用MQ事务消息实现分布式事务
MQ事务消息使用场景 消息队列中的“事务”,主要解决的是消息生产者和消息消费者的数据一致性问题。 拿我们熟悉的电商来举个例子。一般来说,用户在电商 APP 上购物时,先把商品加到购物车里,然后几件商品一起下单,最后…...

C++面向对象设计:深入理解多态与抽象类实现技巧
面向对象的多态 一、概念二、实现1. 静态多态1.1 函数重载1.2 运算符重载 2. 动态多态2.1 虚函数2.2 纯虚函数 三、虚函数1. 定义2. 实现3. 注意 四、纯虚函数1. 定义2. 作用 五、虚析构函数1. 定义2. 作用 六、 抽象类七、实现多态的注意事项1. 基类虚函数必须使用 virtual 关…...

长三角生物医药产业加速跑,飞桨螺旋桨为创新药企、医药技术伙伴装上AI大模型引擎...
生物医药是国家“十四五”规划中明确的战略性新兴产业之一。长三角地区是中国生物医药产业的排头兵,也是《“十四五”生物经济发展规划》的“生物经济先导区”之一。据《上海市生物医药产业投资指南》显示,2022 年上海市生物医药产业在 I 类国产创新药数…...
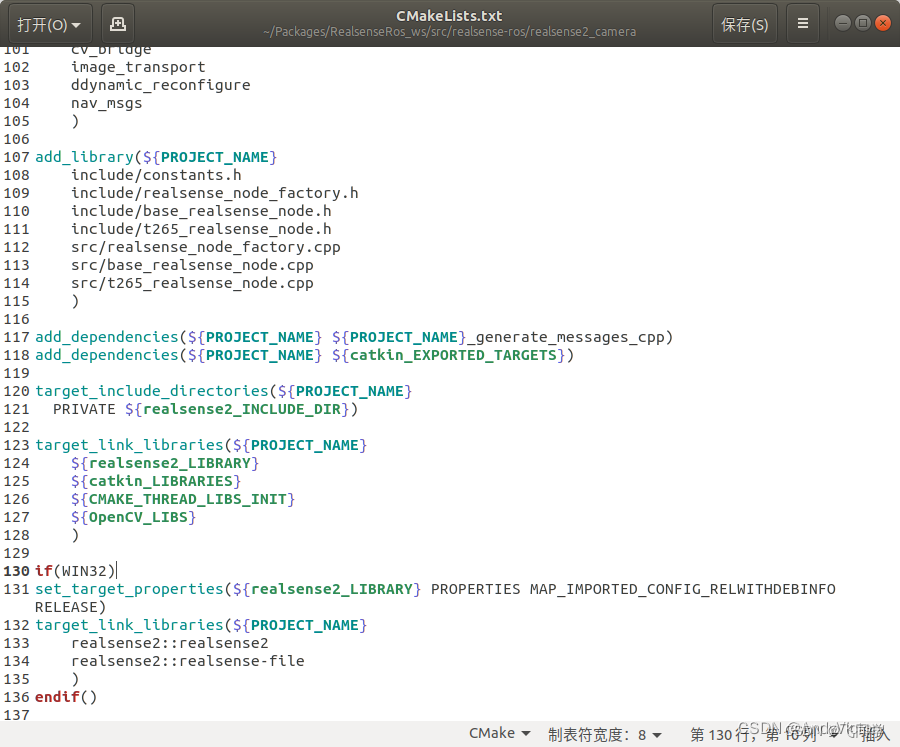
orin Ubuntu 20.04 配置 Realsense-ROS
librealsense安装 sudo apt-get install libudev-dev pkg-config libgtk-3-dev sudo apt-get install libusb-1.0-0-dev pkg-config sudo apt-get install libglfw3-dev sudo apt-get install libssl-dev sudo apt-get install ros-noetic-ddynamic-reconfigure二进制安装libr…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...