7搜索管理
7搜索管理
7.1 准备环境
7.1.1 创建映射
创建xc_course索引库。
创建如下映射
post:http://localhost:9200/xc_course/doc/_mapping
参考 “资料”–》搜索测试-初始化数据.txt
{ "properties": { "description": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart" },"name": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" },"pic":{ "type":"text", "index":false }, "price": { "type": "float" },"studymodel": { "type": "keyword" },"timestamp": { "type": "date", "format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd||epoch_millis" } }
}
7.1.2 插入原始数据
向xc_course/doc中插入以下数据:
参考 “资料”–》搜索测试-初始化数据.txt
http://localhost:9200/xc_course/doc/1 {"name": "Bootstrap开发", "description": "Bootstrap是由Twitter推出的一个前台页面开发框架,是一个非常流行的开发框架,此框架集成了 多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松 的实现一个不受浏览器限制的精美界面效果。", "studymodel": "201002", "price":38.6, "timestamp":"2018‐04‐25 19:11:35", "pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}http://localhost:9200/xc_course/doc/2 {"name": "java编程基础","description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。","studymodel": "201001", "price":68.6, "timestamp":"2018‐03‐25 19:11:35", "pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}http://localhost:9200/xc_course/doc/3 {"name": "spring开发基础", "description": "spring 在java领域非常流行,java程序员都在用。","studymodel": "201001","price":88.6, "timestamp":"2018‐02‐24 19:11:35", "pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
7.1.3 简单搜索
简单搜索就是通过url进行查询,以get方式请求ES。
格式:get …/_search?q=…
q:搜索字符串。
例子:
?q=name:spring 搜索name中包括spring的文档。
7.3 DSL搜索
DSL(Domain Specifific Language)是ES提出的基于json的搜索方式,在搜索时传入特定的json格式的数据来完成不同的搜索需求。
DSL比URI搜索方式功能强大,在项目中建议使用DSL方式来完成搜索。
7.3.1 查询所有文档
查询所有索引库的文档。
发送:post http://localhost:9200/_search
查询指定索引库指定类型下的文档。(通过使用此方法)
发送:post http://localhost:9200/xc_course/doc/_search
{ "query": { "match_all": {} },"_source" : ["name","studymodel"] }
_source:source源过虑设置,指定结果中所包括的字段有哪些。
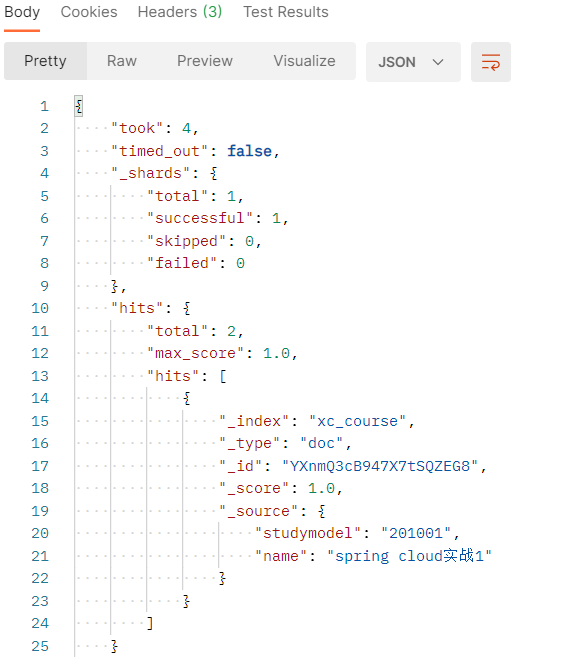
结果说明:
took:本次操作花费的时间,单位为毫秒。
timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片
hits:搜索命中的记录
hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
JavaClient:
@SpringBootTest
@RunWith(SpringRunner.class)
public class TestSearch { @Autowired RestHighLevelClient client; @Autowired RestClient restClient; //搜索type下的全部记录@Testpublic void testSearchAll() throws IOException, ParseException {//搜索请求对象SearchRequest searchRequest = new SearchRequest("xc_course");//指定类型searchRequest.types("doc");//搜索源构建对象SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//搜索方式//matchAllQuery搜索全部searchSourceBuilder.query(QueryBuilders.matchAllQuery());//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});//向搜索请求对象中设置搜索源searchRequest.source(searchSourceBuilder);//执行搜索,向ES发起http请求SearchResponse searchResponse = client.search(searchRequest);//搜索结果SearchHits hits = searchResponse.getHits();//匹配到的总记录数long totalHits = hits.getTotalHits();//得到匹配度高的文档SearchHit[] searchHits = hits.getHits();//日期格式化对象SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");for(SearchHit hit:searchHits){//文档的主键String id = hit.getId();//源文档内容Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");//由于前边设置了源文档字段过虑,这时description是取不到的String description = (String) sourceAsMap.get("description");//学习模式String studymodel = (String) sourceAsMap.get("studymodel");//价格Double price = (Double) sourceAsMap.get("price");//日期Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));System.out.println(name);System.out.println(studymodel);System.out.println(description);}}
} 7.3.2 分页查询
ES支持分页查询,传入两个参数:from和size。
form:表示起始文档的下标,从0开始。
size:查询的文档数量。
发送:post http://localhost:9200/xc_course/doc/_search
{"from" : 0, "size" : 1, "query": { "match_all": {} }, "_source" : ["name","studymodel"] }
JavaClient
SearchRequest searchRequest = new SearchRequest("xc_course");
searchRequest.types("xc_course");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//分页查询,设置起始下标,从0开始
searchSourceBuilder.from(0);
//每页显示个数
searchSourceBuilder.size(10);
//source源字段过虑
searchSourceBuilder.fetchSource(new String[]{"name","studymodel"}, new String[]{});
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest); 7.3.3 Term Query
Term Query为精确查询,在搜索时会整体匹配关键字,不再将关键字分词。
发送:post http://localhost:9200/xc_course/doc/_search
{ "query": { "term" : { "name": "spring" } },"_source" : ["name","studymodel"] }
上边的搜索会查询name包括“spring”这个词的文档。
JavaClient:
SearchRequest searchRequest = new SearchRequest("xc_course");
searchRequest.types("xc_course");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("name","spring"));
//source源字段过虑
searchSourceBuilder.fetchSource(new String[]{"name","studymodel"}, new String[]{});
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest); 7.3.4 根据id精确匹配
ES提供根据多个id值匹配的方法:
测试:
post: http://127.0.0.1:9200/xc_course/doc/_search
{ "query": { "ids" : { "type" : "doc", "values" : ["3", "4", "100"] } } }
JavaClient:
String[] split = new String[]{"1","2"};
List<String> idList = Arrays.asList(split);
searchSourceBuilder.query(QueryBuilders.termsQuery("_id", idList)); 7.3.5 match Query
1、基本使用
match Query即全文检索,它的搜索方式是先将搜索字符串分词,再使用各各词条从索引中搜索。
match query与Term query区别是match query在搜索前先将搜索关键字分词,再拿各各词语去索引中搜索。
发送:post http://localhost:9200/xc_course/doc/_search
{ "query": { "match" : { "description" : { "query" : "spring开发", "operator" : "or" } } } }
query:搜索的关键字,对于英文关键字如果有多个单词则中间要用半角逗号分隔,而对于中文关键字中间可以用
逗号分隔也可以不用。
operator:or 表示 只要有一个词在文档中出现则就符合条件,and表示每个词都在文档中出现则才符合条件。
上边的搜索的执行过程是:
1、将“spring开发”分词,分为spring、开发两个词
2、再使用spring和开发两个词去匹配索引中搜索。
3、由于设置了operator为or,只要有一个词匹配成功则就返回该文档。
JavaClient:
//MatchQuery@Testpublic void testMatchQuery() throws IOException, ParseException {//搜索请求对象SearchRequest searchRequest = new SearchRequest("xc_course");//指定类型searchRequest.types("doc");//搜索源构建对象SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//搜索方式//MatchQuerysearchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架").operator(Operator.OR));//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});//向搜索请求对象中设置搜索源searchRequest.source(searchSourceBuilder);//执行搜索,向ES发起http请求SearchResponse searchResponse = client.search(searchRequest);//搜索结果SearchHits hits = searchResponse.getHits();//匹配到的总记录数long totalHits = hits.getTotalHits();//得到匹配度高的文档SearchHit[] searchHits = hits.getHits();//日期格式化对象SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");for(SearchHit hit:searchHits){//文档的主键String id = hit.getId();//源文档内容Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");//由于前边设置了源文档字段过虑,这时description是取不到的String description = (String) sourceAsMap.get("description");//学习模式String studymodel = (String) sourceAsMap.get("studymodel");//价格Double price = (Double) sourceAsMap.get("price");//日期Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));System.out.println(name);System.out.println(studymodel);System.out.println(description);}}2、minimum_should_match
上边使用的operator = or表示只要有一个词匹配上就得分,如果实现三个词至少有两个词匹配如何实现?
使用minimum_should_match可以指定文档匹配词的占比:
比如搜索语句如下:
{ "query": { "match" : { "description" : { "query" : "spring开发框架", "minimum_should_match": "80%" } } } }
“spring开发框架”会被分为三个词:spring、开发、框架
设置"minimum_should_match": "80%"表示,三个词在文档的匹配占比为80%,即3*0.8=2.4,向上取整得2,表
示至少有两个词在文档中要匹配成功。
对应的RestClient如下:
//匹配关键字
searchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架").minimumShouldMatch("80%"));
7.3.6 multiQuery
上边学习的termQuery和matchQuery一次只能匹配一个Field,本节学习multiQuery,一次可以匹配多个字段。
1、基本使用
单项匹配是在一个field中去匹配,多项匹配是拿关键字去多个Field中匹配。
例子:
发送:post http://localhost:9200/xc_course/doc/_search
拿关键字 “spring css”去匹配name 和description字段。
{ "query": { "multi_match" : { "query" : "spring css", "minimum_should_match": "50%", "fields": [ "name", "description" ] }} }
2、提升boost
匹配多个字段时可以提升字段的boost(权重)来提高得分
例子:
提升boost之前,执行下边的查询:
{ "query": { "multi_match" : { "query" : "spring框架", "minimum_should_match": "50%", "fields": [ "name", "description" ] }} }
通过查询发现Bootstrap排在前边。
提升boost,通常关键字匹配上name的权重要比匹配上description的权重高,这里可以对name的权重提升。
{ "query": { "multi_match" : { "query" : "spring框架", "minimum_should_match": "50%", "fields": [ "name^10", "description" ] }} }
“name^10” 表示权重提升10倍,执行上边的查询,发现name中包括spring关键字的文档排在前边。
JavaClient:
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description") .minimumShouldMatch("50%");
multiMatchQueryBuilder.field("name",10);//提升boost 7.3.7 布尔查询
布尔查询对应于Lucene的BooleanQuery查询,实现将多个查询组合起来。
三个参数:
must:文档必须匹配must所包括的查询条件,相当于 “AND” should:文档应该匹配should所包括的查询条件其
中的一个或多个,相当于 “OR” must_not:文档不能匹配must_not所包括的该查询条件,相当于“NOT”
分别使用must、should、must_not测试下边的查询:
发送:POST http://localhost:9200/xc_course/doc/_search
{ "_source" : [ "name", "studymodel", "description"], "from" : 0, "size" : 1, "query": { "bool" : { "must":[{ "multi_match" : { "query" : "spring框架", "minimum_should_match": "50%", "fields": [ "name^10", "description" ] }},{ "term":{"studymodel" : "201001" } } ] } } }
must:表示必须,多个查询条件必须都满足。(通常使用must)
should:表示或者,多个查询条件只要有一个满足即可。
must_not:表示非。
JavaClient:
//BoolQuery,将搜索关键字分词,拿分词去索引库搜索
@Test
public void testBoolQuery() throws IOException { //创建搜索请求对象 SearchRequest searchRequest= new SearchRequest("xc_course"); searchRequest.types("doc"); //创建搜索源配置对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.fetchSource(new String[]{"name","pic","studymodel"},new String[]{}); //multiQuery String keyword = "spring开发框架"; MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description") .minimumShouldMatch("50%"); multiMatchQueryBuilder.field("name",10); //TermQuery TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("studymodel", "201001");//布尔查询 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(multiMatchQueryBuilder); boolQueryBuilder.must(termQueryBuilder); //设置布尔查询对象 searchSourceBuilder.query(boolQueryBuilder); searchRequest.source(searchSourceBuilder);//设置搜索源配置 SearchResponse searchResponse = client.search(searchRequest); SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); for(SearchHit hit:searchHits){ Map<String, Object> sourceAsMap = hit.getSourceAsMap(); System.out.println(sourceAsMap); }
} 7.3.8 过虑器
过虑是针对搜索的结果进行过虑,过虑器主要判断的是文档是否匹配,不去计算和判断文档的匹配度得分,所以过
虑器性能比查询要高,且方便缓存,推荐尽量使用过虑器去实现查询或者过虑器和查询共同使用。
过虑器在布尔查询中使用,下边是在搜索结果的基础上进行过虑:
{ "_source" : [ "name", "studymodel", "description","price"], "query": { "bool" : { "must":[{ "multi_match" : { "query" : "spring框架", "minimum_should_match": "50%", "fields": [ "name^10", "description" ] }} ],"filter": [ { "term": { "studymodel": "201001" }}, { "range": { "price": { "gte": 60 ,"lte" : 100}}} ] } } }
range:范围过虑,保留大于等于60 并且小于等于100的记录。
term:项匹配过虑,保留studymodel等于"201001"的记录。
注意:range和term一次只能对一个Field设置范围过虑。
client:
//布尔查询使用过虑器
@Test
public void testFilter() throws IOException { SearchRequest searchRequest = new SearchRequest("xc_course"); searchRequest.types("doc"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //source源字段过虑 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","description"}, new String[]{}); searchRequest.source(searchSourceBuilder); //匹配关键字 MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框 架", "name", "description"); //设置匹配占比 multiMatchQueryBuilder.minimumShouldMatch("50%"); //提升另个字段的Boost值 multiMatchQueryBuilder.field("name",10); searchSourceBuilder.query(multiMatchQueryBuilder); //布尔查询 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(searchSourceBuilder.query()); //过虑 boolQueryBuilder.filter(QueryBuilders.termQuery("studymodel", "201001")); boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(60).lte(100)); SearchResponse searchResponse = client.search(searchRequest); SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); String sourceAsString = hit.getSourceAsString(); Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); String studymodel = (String) sourceAsMap.get("studymodel"); String description = (String) sourceAsMap.get("description"); System.out.println(name); System.out.println(studymodel); System.out.println(description); }
}
7.3.9 排序
可以在字段上添加一个或多个排序,支持在keyword、date、flfloat等类型上添加,text类型的字段上不允许添加排 序。
发送 POST http://localhost:9200/xc_course/doc/_search
过虑0–10元价格范围的文档,并且对结果进行排序,先按studymodel降序,再按价格升序
{ "_source" : [ "name", "studymodel", "description","price"], "query": { "bool" : { "filter": [ { "range": { "price": { "gte": 0 ,"lte" : 100}}} ] } }, "sort" : [ {"studymodel" : "desc" }, { "price" : "asc" } ] }
client:
@Test
public void testSort() throws IOException { SearchRequest searchRequest = new SearchRequest("xc_course"); searchRequest.types("doc"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //source源字段过虑 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","description"}, new String[]{}); searchRequest.source(searchSourceBuilder); //布尔查询 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); //过虑 boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));//排序 searchSourceBuilder.sort(new FieldSortBuilder("studymodel").order(SortOrder.DESC)); searchSourceBuilder.sort(new FieldSortBuilder("price").order(SortOrder.ASC)); SearchResponse searchResponse = client.search(searchRequest); SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); String sourceAsString = hit.getSourceAsString(); Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); String studymodel = (String) sourceAsMap.get("studymodel"); String description = (String) sourceAsMap.get("description"); System.out.println(name); System.out.println(studymodel); System.out.println(description); }
} 7.3.10 高亮显示
高亮显示可以将搜索结果一个或多个字突出显示,以便向用户展示匹配关键字的位置。
在搜索语句中添加highlight即可实现,如下:
Post: http://127.0.0.1:9200/xc_course/doc/_search
{ "_source" : [ "name", "studymodel", "description","price"], "query": { "bool" : { "must":[{ "multi_match" : { "query" : "开发框架", "minimum_should_match": "50%", "fields": [ "name^10", "description" ], "type":"best_fields" }} ],"filter": [ { "range": { "price": { "gte": 0 ,"lte" : 100}}} ] } }, "sort" : [{ "price" : "asc" } ],"highlight": { "pre_tags": ["<tag1>"], "post_tags": ["</tag2>"], "fields": { "name": {}, "description":{} } } }
client代码如下:
@Test
public void testHighlight() throws IOException { SearchRequest searchRequest = new SearchRequest("xc_course"); searchRequest.types("doc"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //source源字段过虑 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","description"}, new String[]{}); searchRequest.source(searchSourceBuilder); //匹配关键字 MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("开发", "name", "description"); searchSourceBuilder.query(multiMatchQueryBuilder); //布尔查询 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(searchSourceBuilder.query()); //过虑 boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100)); //排序 searchSourceBuilder.sort(new FieldSortBuilder("studymodel").order(SortOrder.DESC)); searchSourceBuilder.sort(new FieldSortBuilder("price").order(SortOrder.ASC)); //高亮设置 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.preTags("<tag>");//设置前缀 highlightBuilder.postTags("</tag>");//设置后缀 // 设置高亮字段 highlightBuilder.fields().add(new HighlightBuilder.Field("name")); // highlightBuilder.fields().add(new HighlightBuilder.Field("description")); searchSourceBuilder.highlighter(highlightBuilder); SearchResponse searchResponse = client.search(searchRequest);SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //名称 String name = (String) sourceAsMap.get("name"); //取出高亮字段内容 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); if(highlightFields!=null){ HighlightField nameField = highlightFields.get("name"); if(nameField!=null){ Text[] fragments = nameField.getFragments(); StringBuffer stringBuffer = new StringBuffer(); for (Text str : fragments) { stringBuffer.append(str.string()); }name = stringBuffer.toString(); } }String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); String sourceAsString = hit.getSourceAsString(); String studymodel = (String) sourceAsMap.get("studymodel"); String description = (String) sourceAsMap.get("description"); System.out.println(name); System.out.println(studymodel); System.out.println(description); }
}相关文章:
7搜索管理
7搜索管理 7.1 准备环境 7.1.1 创建映射 创建xc_course索引库。 创建如下映射 post:http://localhost:9200/xc_course/doc/_mapping 参考 “资料”–》搜索测试-初始化数据.txt { "properties": { "description": { "type": &…...

在Pytorch中使用Tensorboard
Tensorboard是一款深度学习可视化软件,目前主要使用了它的可视化模型, 可视化模型权重和可视化损失函数功能。 x.1 tensorboard初始化 tensorboard初始化需要导入SummaryWriter包并指定存储位置和开放端口号。 from torch.utils.tensorboard import SummaryWrite…...
[笔记]深入解析Windows操作系统《四》管理机制
文章目录 前言4.1注册表查看和修改注册表注册表用法注册表数据类型注册表逻辑结构HKEY_CURRENT_USERHKEY_USERS 实验:观察轮廓加载和卸载HKEY_CLASSES_ROOTHKEY_LOCAL_MACHINE 实验:离线方式或远程编辑BCDHKEY_CURRENT_CONFIGHKEY_PERFORMANCE_DATA 前言 本章讲述了…...
【小沐学Python】Python实现在线英语翻译功能
文章目录 1、简介2、在线翻译接口2.1 Google Translate API2.2 Microsoft Translator API2.2.1 开发简介2.2.2 开发费用2.2.3 开发API 2.3 百度翻译开放平台 API2.3.1 开发简介2.3.2 开发费用2.3.3 开发API 2.4 Tencent AI 开放平台的翻译 API2.4.1 开发简介2.4.2 开发API 2.5 …...

k8s中pod使用详解
一、前言 在之前k8s组件一篇中,我们谈到了pod这个组件,了解到pod是k8s中资源管理的最小单位,可以说Pod是整个k8s对外提供服务的最基础的个体,有必要对Pod做深入的学习和探究。 二、再看k8s架构图 为了加深对k8s中pod的理解,再来回顾下k8s的完整架构 三、pod特点 结合上面这…...
案例说明:vue中Element UI下拉列表el-option中的key、value、label含义各是什么
可以简单理解为:label 是给用户展示的东西,value是前端往后端传递的真实值 <template><div><el-page-header back"goBack" content"注册"></el-page-header><el-divider></el-divider><el-…...
idea创建javaweb项目步骤超详细(2022最新版本)
目录 前言必读 一、新建文件 1.在idea里面点击文件-新建-项目 2.新建项目-更改名称为自己想要的项目名称-创建 3.右键自己建立的项目-添加框架支持(英文版是Add Framework Support...) 4.勾选Web应用程序-确定 5.建立成功界面 二、配置tomcat 6.…...

「SAP ABAP」OPEN SQL(六)【DELETE语句 | MODIFY语句】
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后端的开发语言ABAP,SQL进行任务的完成,对SAP企业管理系统,SAP ABAP开发和数据库具有较…...

SpringCloud --- Feign远程调用
一、RestTemplate问题 先来看我们以前利用RestTemplate发起远程调用的代码: 存在下面的问题: 代码可读性差,编程体验不统一参数复杂URL难以维护 Feign是一个声明式的http客户端,官方地址:GitHub - OpenFeign/feign:…...
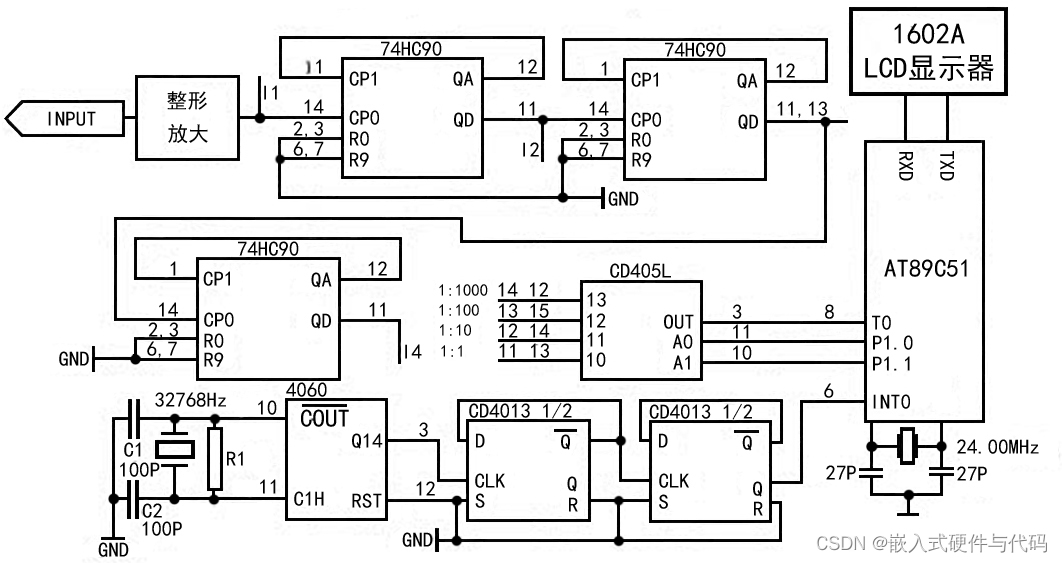
基于单片机的数字频率计设计
数字频率计概述 数字频率计是计算机、通讯设备、音频视频等科研生产领域不可缺少的测量仪器。它是一种用十进制数字显示被测信号频率的数字测量仪器。它的基本功能是测量正弦信号,方波信号及其他各种单位时间内变化的物理量。在进行模拟、数字电路的设计、安装、调试…...
我看看哪个靓仔还没把Github Copilot用起来?
本人经常分享有价值的生产力工具、技术、好物与书籍,可关注同名公众🐭并设为🌟星标,第一时间获得更新 Github Copilot 是一个AI编程助手,其使用 OpenAI CodeX 在你的编辑器中实时建议代码或给你实现整个功能。 视频版介…...

C++系列一: C++简介
C入门简介 1. C语言的特点2. C编译器3. 第一个 C 程序4. 总结(手稿版) C 是一种高级编程语言,是C语言的扩展和改进版本,由Bjarne Stroustrup于1983年在贝尔实验室为了支持C语言中的面向对象编程而创建。C 既能够进行底层的系统编程…...

信通初试第一:无科研无竞赛一战上岸上海交大819学硕感悟
笔者来自通信考研小马哥23上交819全程班学员 信通初试第一:无科研无竞赛一战上岸上海交大819学硕感悟 原创2023-04-27 11:04通信考研小马哥 笔者来自通信考研小马哥23上交819全程班学员 本人情况: 本人是19届交本,本科成绩很差,…...

Spring —— Spring Boot 配置文件
JavaEE传送门 JavaEE Spring —— Bean 作用域和生命周期 Spring —— Spring Boot 创建和使用 目录 Spring Boot 配置文件Spring Boot 配置文件格式properties配置文件properties 基本语法properties 缺点 yml 配置文件yml 基本语法yml 配置不同类型数据及 nullyml 配置对象…...
Python 网络爬虫与数据采集(一)
Python 网络爬虫与数据采集 第1章 序章 网络爬虫基础1 爬虫基本概述1.1 爬虫是什么1.2 爬虫可以做什么1.3 爬虫的分类1.4 爬虫的基本流程1.4.1 浏览网页的流程1.4.2 爬虫的基本流程 1.5 爬虫与反爬虫1.5.1 爬虫的攻与防1.5.2 常见的反爬与反反爬 1.6 爬虫的合法性与 robots 协议…...

2023年6月DAMA-CDGP数据治理专家认证请尽快报名啦!
目前6月DAMA-CDGP数据治理认证考试开放报名地区有:北京、上海、广州、深圳、长沙、呼和浩特。 目前南京、济南、西安、杭州等地区还在接近开考人数中,打算参加6月考试的朋友们可以抓紧时间报名啦!!! 5月初,…...
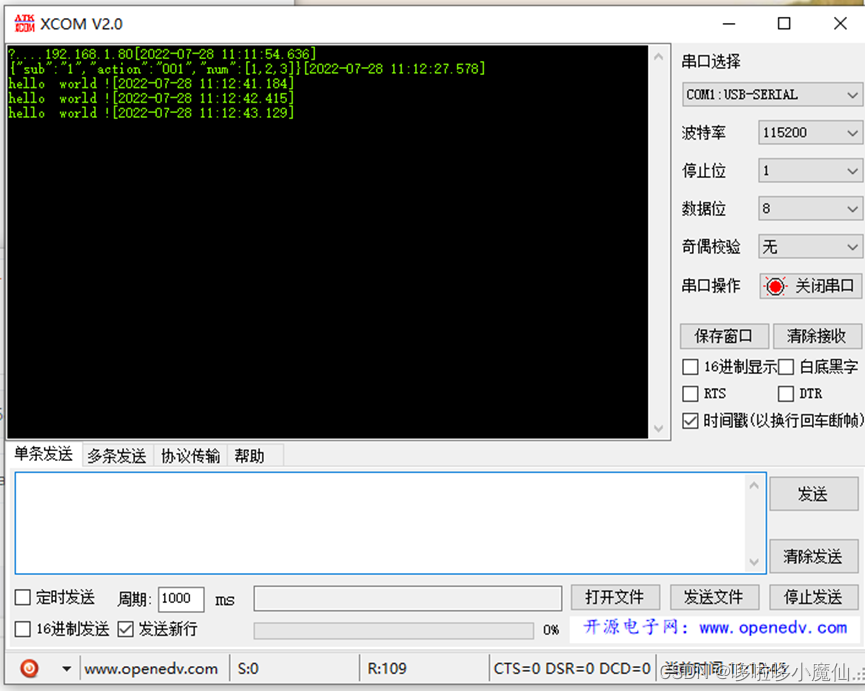
STM32+esp8266,让你的STM32开发板连接网络-----esp8266
分享一下,STM32开发板连接网络的第一种方法:连接esp8266。 esp8266与STM32利用串口通信连接,esp8266连接网络,把收到的数据通过串口的方式传输给STM32,之后STM32接收到消息做出对应的反应。 使用到的开发板如图&…...

分布式缓存的基础知识
前言 现代互联网应用中,分布式缓存成为了必不可少的一环。它通过在多台服务器之间共享数据,避免了网络通信的高延迟和低带宽的性能问题。本文将介绍分布式缓存的基础知识,包括缓存机制、常见的缓存策略以及缓存的使用场景。 缓存机制 缓存是…...

Vue3通透教程【七】生命周期函数
文章目录 🌟 写在前面🌟 生命周期钩子函数🌟 组合式API生命周期🌟 写在最后🌟 写在前面 专栏介绍: 凉哥作为 Vue 的忠实 粉丝输出过大量的 Vue 文章,应粉丝要求开始更新 Vue3 的相关技术文章,Vue 框架目前的地位大家应该都晓得,所谓三大框架使用人数最多,公司选…...

《“裸奔”时代的网络防护:如何保护你的隐私和数据安全》
一、引言 在此时此刻,你可能正在使用电子设备阅读这篇文章。你可能在一天中的大部分时间都在与网络世界互动,无论是通过电子邮件、社交媒体、在线购物,还是通过流媒体服务消费内容。然而,你有没有考虑过,当你在享受这些…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...
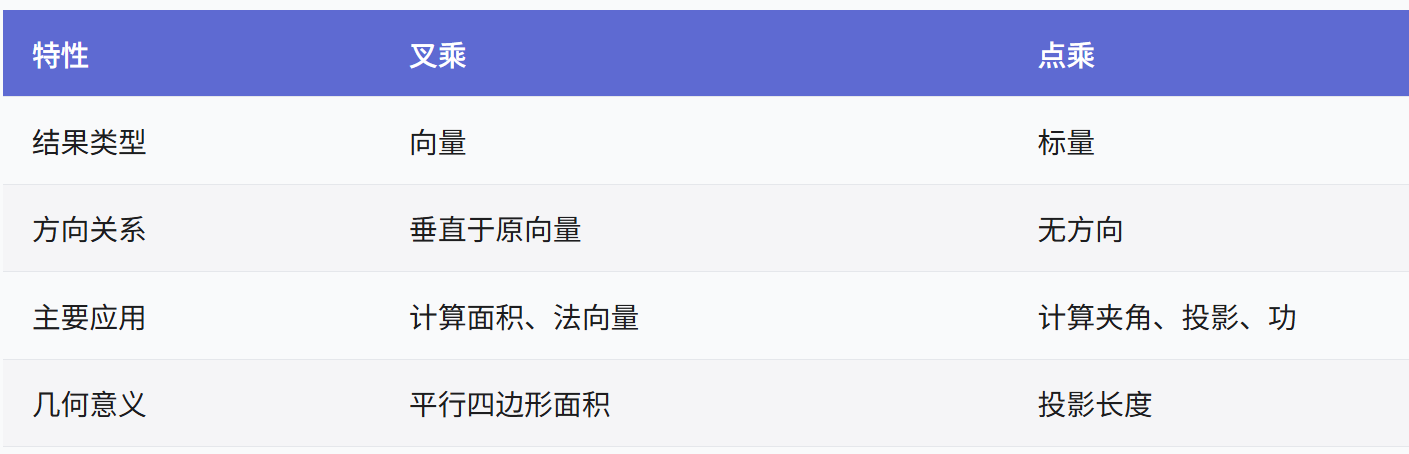
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...

手动给中文分词和 直接用神经网络RNN做有什么区别
手动分词和基于神经网络(如 RNN)的自动分词在原理、实现方式和效果上有显著差异,以下是核心对比: 1. 实现原理对比 对比维度手动分词(规则 / 词典驱动)神经网络 RNN 分词(数据驱动)…...