深度学习03-卷积神经网络(CNN)
简介
CNN,即卷积神经网络(Convolutional Neural Network),是一种常用于图像和视频处理的深度学习模型。与传统神经网络相比,CNN 有着更好的处理图像和序列数据的能力,因为它能够自动学习图像中的特征,并提取出最有用的信息。
CNN 的一个核心特点是卷积操作,它可以在图像上进行滑动窗口的计算,通过滤波器(又称卷积核)和池化层(Max Pooling)来提取出图像的特征。卷积操作可以有效地减少权重数量,降低计算量,同时也能够保留图像的空间结构信息。池化层则可以在不改变特征图维度的前提下,减少计算量,提高模型的鲁棒性。
CNN 的典型结构包括卷积层、池化层、全连接层等。同时,为了防止过拟合,CNN 还会加入一些正则化的技术,如 Dropout 和 L2 正则等。
CNN 在图像分类、目标检测、语音识别等领域都有着广泛的应用。在图像分类任务中,CNN 的经典模型包括 LeNet-5、AlexNet、VGG 和 GoogleNet/Inception 等,这些模型的设计思想和网络结构都有所不同,但都对卷积神经网络的发展做出了重要贡献。
发展历程
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像识别、计算机视觉等领域。在CNN的发展历程中,涌现出了许多经典的模型,下面简要介绍几个著名的模型。
- LeNet-5
LeNet-5是Yann LeCun等人于1998年提出的,是第一个被广泛应用的卷积神经网络模型。它主要用于手写数字识别,包含卷积层、池化层和全连接层。LeNet-5的设计使得它在MNIST手写数字识别任务上获得了很好的表现。它的特点是卷积核数量较少(6和16)以及参数量较少,第一层卷积层使用了6个大小为5×5的卷积核,第二层卷积层使用了16个大小为5×5的卷积核。这种设计可以有效地减少模型的参数量,但它是卷积神经网络的开山鼻祖,为后续模型奠定了基础。
- AlexNet
AlexNet由Alex Krizhevsky等人于2012年提出,是第一个在ImageNet图像分类比赛中取得优异成绩的卷积神经网络模型。它采用了多个卷积层和池化层,使用了ReLU激活函数和Dropout正则化技术。AlexNet的设计使得它在ImageNet图像分类比赛中大幅领先于其他模型,从而引领了卷积神经网络的新一轮发展。它的特点是使用了大量卷积核(近6000个)、参数量较大,但在准确率和效率上都有很好的表现。
- VGG
VGG由Karen Simonyan和Andrew Zisserman于2014年提出,其主要贡献是提出了使用更小的卷积核(3x3)来代替较大的卷积核。这种设计使得网络更深,而且参数量更少,从而提高了效率和准确率。VGG包含了16个或19个卷积层和池化层,这些层都采用了相同的卷积核大小和步长。VGG在ImageNet图像分类比赛中取得了很好的成绩,同时也为后续的ResNet等模型提供了启示。
- GoogleNet/Inception
GoogleNet由Google团队于2014年提出,其主要贡献是提出了Inception模块,可以在不增加参数量的情况下增加网络的深度和宽度。Inception模块采用了多个不同大小的卷积核和池化层来进行特征提取,然后将它们串联在一起,形成了一个模块。GoogleNet还使用了全局平均池化层来代替全连接层,从而进一步减少了参数量。GoogleNet在ImageNet图像分类比赛中取得了很好的成绩,同时也为后续的ResNet、DenseNet等模型提供了启示。
- ResNet
ResNet由Microsoft Research Asia团队于2015年提出,其主要贡献是提出了残差学习,可以解决深度卷积神经网络的退化问题。退化问题指的是随着网络深度的增加,准确率反而下降的现象。残差学习通过引入跨层连接来将输入直接传递到输出,从而避免了信息的损失。ResNet包含了较深的网络结构(152层),但却获得了更好的准确率。ResNet的设计思想被后续的DenseNet、MobileNet等模型所继承。
- DenseNet
DenseNet由Gao Huang等人于2017年提出,其主要贡献是提出了密集连接,可以增加网络的深度和宽度,从而提高了效率和准确率。密集连接指的是将每个层的输出都与后面所有层的输入相连,形成了一个密集的连接结构。这种设计使得网络更加紧凑,参数量更少,同时也可以提高特征的复用性。DenseNet在ImageNet图像分类比赛中取得了很好的成绩,同时也为后续的ShuffleNet、EfficientNet等模型提供了启示。
- MobileNet
MobileNet由Google团队于2017年提出,其主要贡献是提出了深度可分离卷积,可以在减少参数量的同时保持较好的准确率。深度可分离卷积指的是将卷积操作分为深度卷积和逐点卷积两步,从而减少了计算量和参数量。MobileNet采用了多个深度可分离卷积层和池化层,可以在移动设备等资源受限的环境下实现高效的图像分类和目标检测。MobileNet的设计思想被后续的ShuffleNet、EfficientNet等模型所继承。
- ShuffleNet
ShuffleNet由Microsoft Research Asia团队于2018年提出,其主要贡献是提出了通道重组和组卷积,可以在保持准确率的前提下大幅减少参数量和计算量。通道重组指的是将输入的通道分组并重新组合,从而让不同的组之间进行信息的交流。组卷积指的是将卷积操作分为组内卷积和组间卷积两步,从而减少了计算量和参数量。ShuffleNet采用了多个通道重组和组卷积层,可以在资源受限的环境下实现高效的图像分类和目标检测。
- EfficientNet
EfficientNet由Google团队于2019年提出,其主要贡献是提出了网络缩放和复合系数,可以在保持准确率的前提下大幅减少参数量和计算量。网络缩放指的是同时缩放网络的深度、宽度和分辨率,从而在不改变模型结构的情况下进行优化。复合系数指的是将深度、宽度和分辨率的缩放系数进行组合,从而得到一个更加高效的模型。EfficientNet在ImageNet图像分类比赛中取得了很好的成绩,同时也为后续的模型优化提供了启示。
- RegNet
RegNet由Facebook AI Research团队于2020年提出,其主要贡献是提出了网络结构的自适应规则,可以在保持准确率的前提下大幅减少参数量和计算量。自适应规则指的是通过搜索和优化来自动调整网络结构的超参数,从而得到一个更加高效的模型。RegNet在ImageNet图像分类比赛中取得了很好的成绩,同时也为后续的模型优化提供了启示。
以上是几个著名的卷积神经网络模型,它们的设计思想和网络结构都有所不同,但都对卷积神经网络的发展做出了重要贡献。
图解原理
卷积神经网络在图像识别中大放异彩,达到了前所未有的准确度,有着广泛的应用。接下来将以图像识别为例子,来介绍卷积神经网络的原理。
案例
假设给定一张图(可能是字母X或者字母O),通过CNN即可识别出是X还是O,如下图所示,那怎么做到的呢
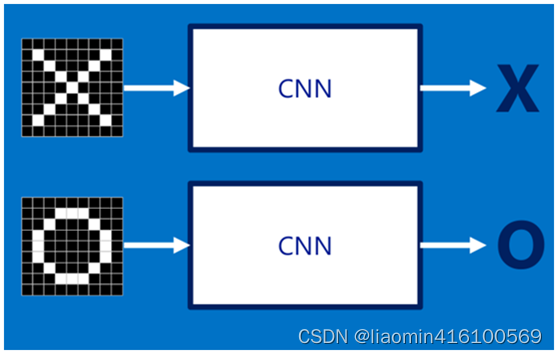
图像输入
如果采用经典的神经网络模型,则需要读取整幅图像作为神经网络模型的输入(即全连接的方式),当图像的尺寸越大时,其连接的参数将变得很多,从而导致计算量非常大。
而我们人类对外界的认知一般是从局部到全局,先对局部有感知的认识,再逐步对全体有认知,这是人类的认识模式。在图像中的空间联系也是类似,局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种模式就是卷积神经网络中降低参数数目的重要神器:局部感受野。
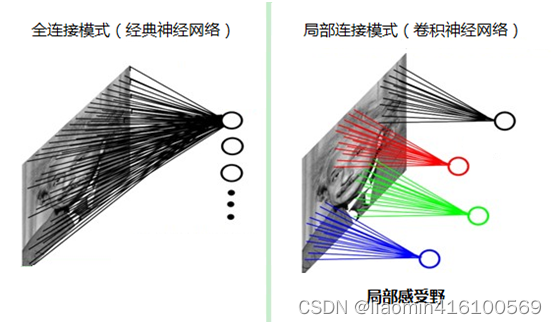
特征提取
如果字母X、字母O是固定不变的,那么最简单的方式就是图像之间的像素一一比对就行,但在现实生活中,字体都有着各个形态上的变化(例如手写文字识别),例如平移、缩放、旋转、微变形等等,如下图所示:
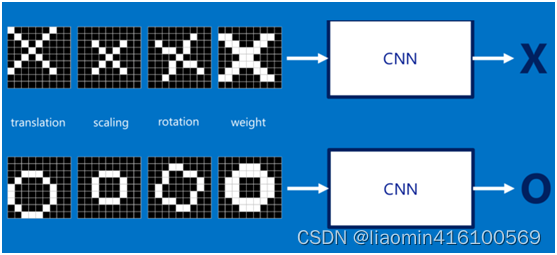
我们的目标是对于各种形态变化的X和O,都能通过CNN准确地识别出来,这就涉及到应该如何有效地提取特征,作为识别的关键因子。
回想前面讲到的“局部感受野”模式,对于CNN来说,它是一小块一小块地来进行比对,在两幅图像中大致相同的位置找到一些粗糙的特征(小块图像)进行匹配,相比起传统的整幅图逐一比对的方式,CNN的这种小块匹配方式能够更好的比较两幅图像之间的相似性。如下图:
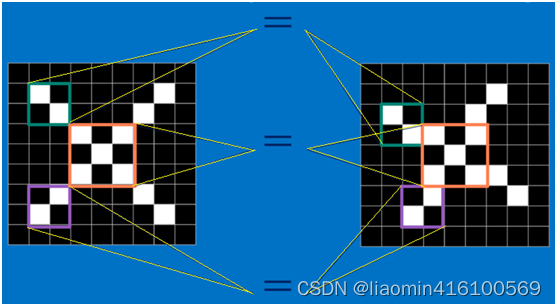
以字母X为例,可以提取出三个重要特征(两个交叉线、一个对角线),如下图所示:
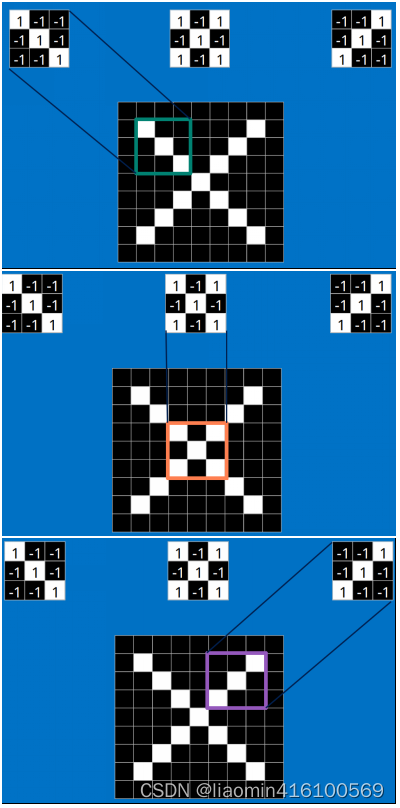
假如以像素值"1"代表白色,像素值"-1"代表黑色,则字母X的三个重要特征如下:

上面的特征提取是个假设,实际当有多张图作为输入时,卷积神经网络会对每张图进行特征提取,具体过程如下:输入图片经过第一个卷积层,卷积核会在图像上滑动,提取出一些低层次的特征,例如边缘、角点等。
在卷积神经网络中,如果使用了多个不同的卷积核,那么每个卷积核的局部感受野大小是相同的,但是不同卷积核的权重是不同的,这样可以使得每个卷积核学习到不同的特征。
举个例子,假设我们在卷积层中使用三个不同的卷积核,其中第一个卷积核的权重用于检测边缘,第二个卷积核的权重用于检测纹理特征,第三个卷积核的权重用于检测目标的形状。这三个卷积核的局部感受野大小都相同,但是由于它们的权重不同,因此每个卷积核可以学习到不同的特征。
需要注意的是,卷积核的大小和步长也会影响到每个卷积核的局部感受野大小。如果卷积核的大小较大,那么它的局部感受野也会相应地变大;如果步长较大,那么卷积核每次滑动的距离也会相应地变大,从而影响到卷积核的局部感受野大小。
边缘
边缘是图像中像素灰度值变化明显的地方,通常表示图像中物体的边缘、轮廓或者纹理等信息。在图像处理和计算机视觉中,边缘检测是一种常用的技术,可以用来分割图像、提取特征等。
比如如下图

提取边缘的效果

角点
角点是图像中局部区域的特殊点,具有明显的角度变化。角点通常是由不同方向的边缘交汇处形成的,具有高斯曲率,是图像中的重要特征之一。在图像配准、物体跟踪、图像匹配等方面,角点检测也是一种常用的技术。常用的角点检测算法包括Harris角点检测、Shi-Tomasi角点检测等。
如下图

opencv
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。它可以帮助开发人员快速构建计算机视觉应用程序,如图像处理、物体检测、人脸识别、视频分析等。
OpenCV最初是由英特尔公司发起的,现已成为一个跨平台的开源项目,支持多种编程语言,包括C++、Python、Java等,可以在Windows、Linux、macOS等操作系统上运行。
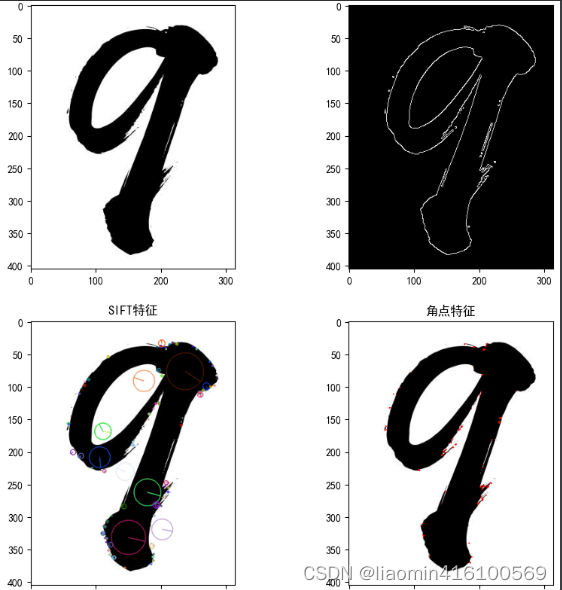
这里使用opencv来讲某张图片的边缘和角点提取出来,比如图片是

具体这里不细讲opencv,以后在开文讲解。
代码
#%%
import cv2 #注意安装open-cv conda install open-cv
import numpy as np
import matplotlib.pyplot as plt# 读入lena图像
img = cv2.imread('d:/9.png')
# 将BGR图像转换为RGB图像,便于matplotlib显示
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
gray_ori=gray
# 使用Canny边缘检测函数检测图像的边缘
edges = cv2.Canny(gray, 100, 200)# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 检测图像的特征点
keypoints = sift.detect(gray, None)
# 在图像上绘制特征点
img_sift = cv2.drawKeypoints(img, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)# 检测图像的角点
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
# 将角点标记为红色
img_corner = img.copy()
img_corner[dst > 0.01 * dst.max()] = [255, 0, 0]# 创建一个Matplotlib窗口并显示图像及其各种特征
plt.rcParams['font.family'] = 'SimHei'
fig, axs = plt.subplots(2, 2, figsize=(10, 10))
axs[0, 0].imshow(img)
axs[0, 0].set_title('原始图像')
axs[0, 1].imshow(edges, cmap='gray')
axs[0, 1].set_title('边缘')
axs[1, 0].imshow(img_sift)
#SIFT的全称是Scale Invariant Feature Transform,尺度不变特征变换。具有旋转不变性、尺度不变性、亮度变化保持不变性,是一种非常稳定的局部特征。
axs[1, 0].set_title('SIFT特征')
axs[1, 1].imshow(img_corner)
axs[1, 1].set_title('角点特征')
plt.show()
输出效果
卷积
那么这些特征又是怎么进行匹配计算呢?(不要跟我说是像素进行一一匹配的,汗!)
这时就要请出今天的重要嘉宾:卷积。那什么是卷积呢,不急,下面慢慢道来。
当给定一张新图时,CNN并不能准确地知道这些特征到底要匹配原图的哪些部分,所以它会在原图中把每一个可能的位置都进行尝试,相当于把这个feature(特征)变成了一个过滤器。这个用来匹配的过程就被称为卷积操作,这也是卷积神经网络名字的由来。
卷积的操作如下图所示:

黄色的部分就是一个卷积核,也就是上一张提取的特征
[[1,0,1]
[0,1,0]
[1,0,1]]
同图像中的每个可能的3*3图像进行计算(卷积相同位置相乘后相加/当前聚集矩阵个个数9),计算的结果得到一个数放在当前被卷积的中心位置,最终会得到一个去掉最外层的新的矩阵,具体计算逻辑参考下文。
在本案例中,要计算一个feature(特征)和其在原图上对应的某一小块的结果,只需将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可(注:也可不除以总个数的)。
如果两个像素点都是白色(值均为1),那么11 = 1,如果均为黑色,那么(-1)(-1) = 1,也就是说,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。具体过程如下(第一个、第二个……、最后一个像素的匹配结果):
先将我们之前提取的三个特征中的一个拿来进行卷积
比如拿第一个特征和绿色框框圈起来的部分比较,完全一样
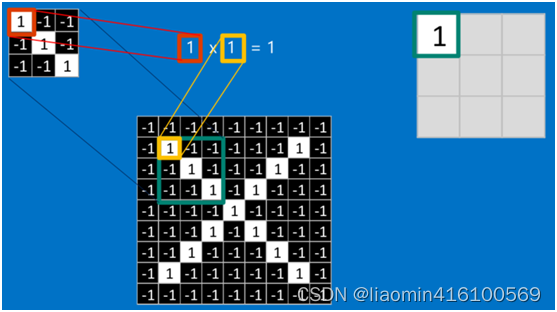
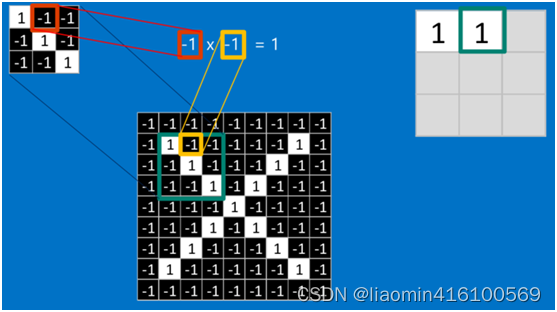
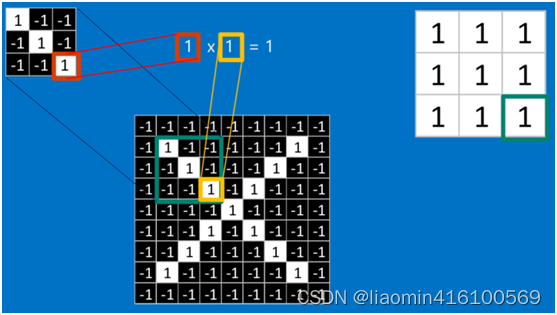
根据卷积的计算方式,第一块特征匹配后的卷积计算如下,结果为1

对于其它位置的匹配,也是类似(例如中间部分的匹配)
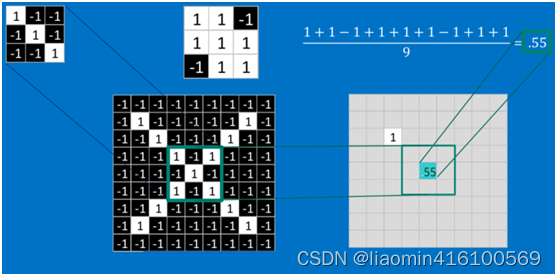
以此类推,对三个特征图像不断地重复着上述过程,通过每一个feature(特征)的卷积操作,会得到一个新的二维数组,称之为feature map(特征图)。其中的值,越接近1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。如下图所示:

可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得计算量变得相当庞大。
池化(Pooling)
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是22大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
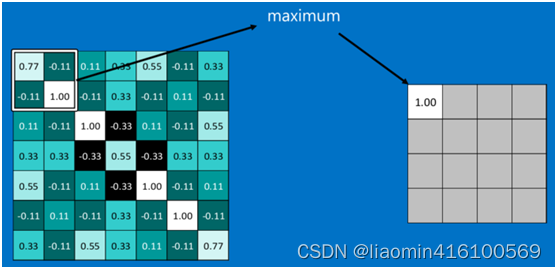
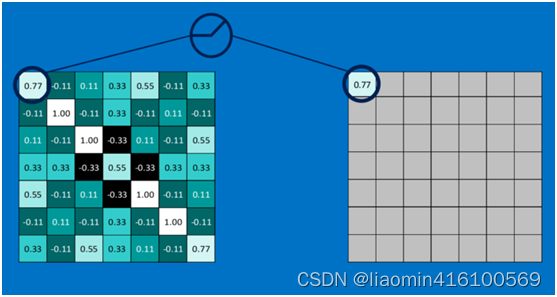
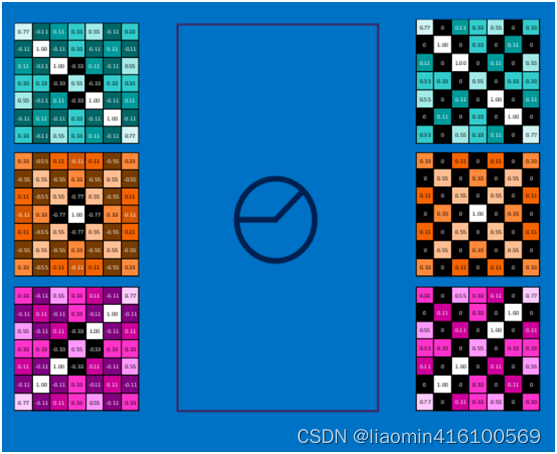
下图显示了左上角22池化区域的max-pooling结果,取该区域的最大 max(0.77,-0.11,-0.11,1.00) ,作为池化后的结果,如下图:
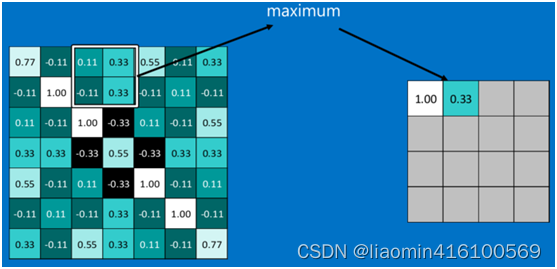
池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图:
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下:

对所有的feature map执行同样的操作,结果如下:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
激活函数ReLU (Rectified Linear Units)
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
回顾一下前面讲的感知机,感知机在接收到各个输入,然后进行求和,再经过激活函数后输出。激活函数的作用是用来加入非线性因素,把卷积层输出结果做非线性映射。
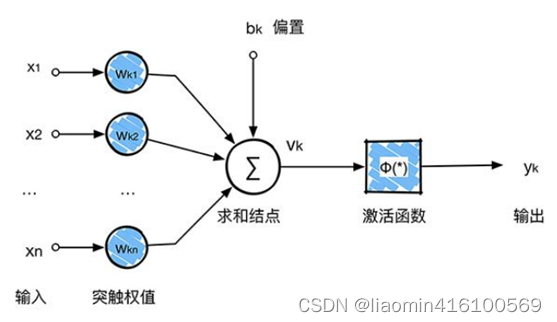
在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。
下面看一下本案例的ReLU激活函数操作过程:
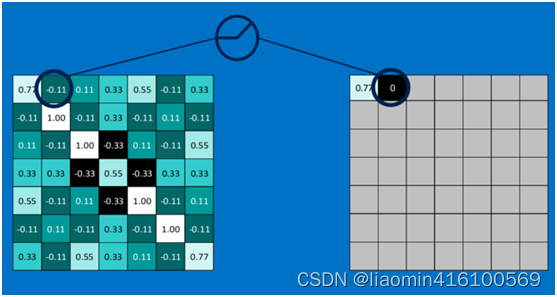
第一个值,取max(0,0.77),结果为0.77,如下图
第二个值,取max(0,-0.11),结果为0,如下图
以此类推,经过ReLU激活函数后,结果如下:
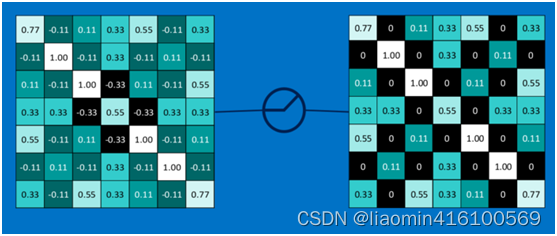
对所有的feature map执行ReLU激活函数操作,结果如下:
深度神经网络
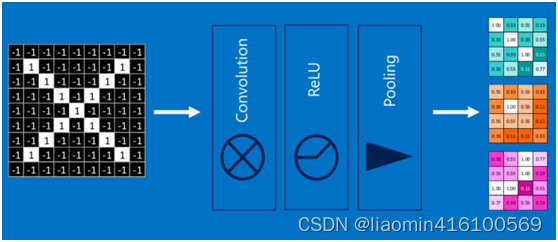
通过将上面所提到的卷积、激活函数、池化组合在一起,就变成下图:
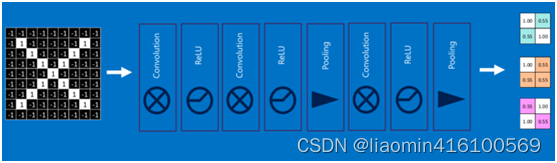
通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图:
全连接层(Fully connected layers)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
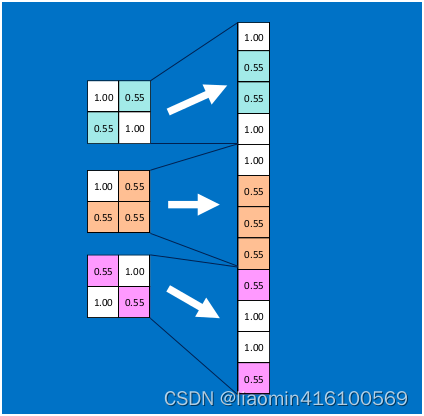
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:
由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)
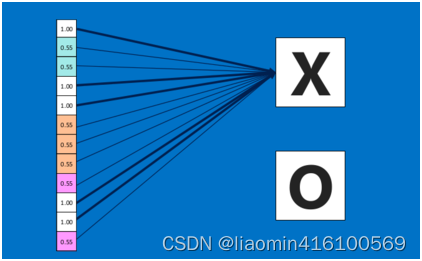
在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)
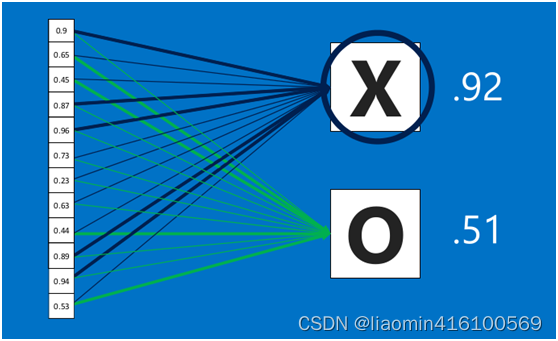
上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:

卷积神经网络(Convolutional Neural Networks)
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:
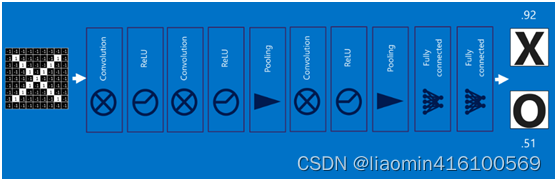
最后,再回顾总结一下,卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层),下图便是著名的手写文字识别卷积神经网络结构图:
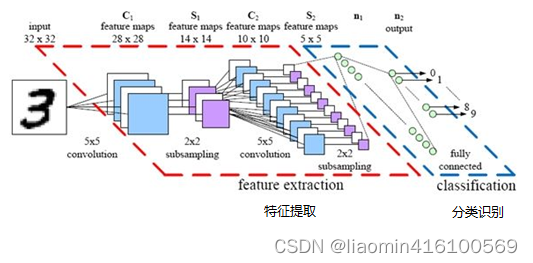
本章节内容参考:https://my.oschina.net/u/876354/blog/1620906
卷积api
Conv2D
Conv2D是卷积神经网络中最核心的层之一,它是用于图像或其他二维数据的卷积处理的层。Conv2D的作用是将输入的二维图像或数据,通过卷积核进行一系列的卷积操作,从而提取出图像或数据中的特征。
Conv2D层的输入为一个tensor,该tensor的形状通常为(batch_size, height, width, channel),其中batch_size表示输入数据的数量,height和width表示输入数据的高度和宽度,channel表示输入数据的通道数(如RGB图像的通道数为3)。
Conv2D层的输出也是一个tensor,表示经过卷积操作后得到的特征图。输出tensor的形状通常为(batch_size, conv_height, conv_width, filters),其中conv_height和conv_width表示卷积核作用后得到的特征图的高度和宽度,filters表示卷积核的数量,即输出特征图的通道数。
在卷积过程中,Conv2D层将卷积核作用于输入数据,通过逐个计算每个卷积核与输入数据的卷积操作,得到卷积后的输出特征图。在卷积过程中,卷积核的大小、步长、填充方式等参数都可以自由设置,以适应不同的应用场景。
在TensorFlow 2.0和Keras中,可以通过以下代码来创建一个Conv2D层:
from tensorflow.keras.layers import Conv2Dconv_layer = Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=(height, width, channel))
- filters:卷积核的数量,也就是输出的特征图的个数。
- kernel_size:卷积核的大小,可以是一个整数,表示正方形卷积核的边长,也可以是一个元组,表示长和宽不同的卷积核。
- strides:步长,也就是卷积核在输入特征图上移动的距离。可以是一个整数,表示在两个相邻的卷积核之间的距离,也可以是一个元组,表示在长和宽方向上的步长不同。
- padding:填充方式,可以是’same’或’valid’。'same’表示输出特征图的大小和输入特征图的大小相同,需要在输入特征图的周围填充一些值;'valid’表示不需要填充,输出特征图的大小会根据输入特征图和卷积核的大小而变化。
- activation:激活函数,用于给特征图添加非线性变换。常见的激活函数有’relu’、‘sigmoid’、'tanh’等。
- input_shape:输入特征图的形状,可以是一个三元组,表示高、宽和通道数。在第一层卷积层中需要指定该参数。
- kernel_regularizer:在深度学习中,为了防止模型过拟合,通常会使用正则化技术对模型进行约束,其中一个常用的正则化方法是L2正则化。L2正则化是指在模型的损失函数中增加一个L2范数惩罚项,以限制模型权重的大小。
在Keras中,使用regularizers.l2(0.001)可以添加L2正则化惩罚项。其中,0.001是正则化参数,控制正则化强度的大小。正则化参数越大,惩罚项对权重的影响就越大,模型的复杂度就会降低,从而有效地防止过拟合。
具体来说,regularizers.l2(0.001)可以应用于神经网络中的任何权重矩阵,例如全连接层、卷积层等。在网络的定义中,我们可以在相应的层中使用kernel_regularizer参数来添加L2正则化。例如,在Keras中添加一个带有L2正则化的全连接层的代码如下所示:
layers.Conv2D(32, (3, 3), activation='relu', kernel_regularizer=regularizers.l2(0.001), input_shape=(28, 28, 1)),
卷积实例
取minist10张图,并且使用10个卷积核进行卷积,输出特征图,并显示图像,
因为每张图会生成10个卷积核,所以总共生成100张特征图。
#%%
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np# 加载mnist数据集
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 取1张训练集图片
images = train_images[:10]# 将图片转换为float类型
images = images.astype('float32') / 255.0
# 将图片reshape成4D张量,大小为(10, 28, 28, 1),也就是第一个维度表示有10张图像,每张图像由28行、28列和1个# 通道(灰度)组成
images = np.expand_dims(images, axis=3)
# 定义卷积核数量
num_filters = 10# 定义卷积层
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(num_filters, (3, 3), activation='relu', input_shape=(28, 28, 1)),
])# 计算卷积后的特征图
features = model.predict(images)# 绘制卷积后的特征图
fig, axs = plt.subplots(nrows=num_filters, ncols=10, figsize=(10, num_filters))
for i in range(num_filters):for j in range(10):axs[i][j].imshow(features[j, :, :, i], cmap='gray')axs[i][j].axis('off')
plt.show()输出

np.expand_dims函数用于在数组的指定轴上扩展维度。在这个例子中,images是一个形状为(10, 28, 28)的数组,表示10张28x28的灰度图像。但是,机器学习模型通常需要输入4维的数组,即(样本数, 图像高度, 图像宽度, 通道数)。因此,我们需要将images数组的最后一个维度(通道数)扩展一维,变成形状为(10, 28, 28, 1)的数组。
具体来说,axis=3表示在数组的第3个轴(从0开始计数)上扩展维度,它会在每张图像的最后一个维度上增加一个维度,从而将每张图像变成形状为(28, 28, 1)的三维数组。最终,images数组的形状变成了(10, 28, 28, 1),表示有10张28x28的灰度图像,每张图像由一个通道组成。这样,images就可以作为输入传递给机器学习模型了。
从上面的输出图片可以看出,有些卷积核的输出偏向于边缘,有些角点,有些纹理。
MaxPooling2D
keras.layers.MaxPooling2D((2, 2))是Keras中的一个层,它用于进行最大池化操作。
最大池化是一种常用的卷积神经网络操作,它可以在不改变图像尺寸的前提下,减少图像中的参数数量,从而减少计算量和内存消耗。最大池化操作将输入图像划分为不重叠的块,对每个块取最大值作为输出。在卷积神经网络中,最大池化通常跟卷积层交替使用,以提取图像的空间特征。
MaxPooling2D层的参数是一个元组(2, 2),表示池化窗口的大小为2x2。这意味着,输入图像会被划分为多个大小为2x2的块,对每个块取最大值作为输出。如果将池化窗口大小设置为(3, 3),那么输入图像会被划分为多个大小为3x3的块,对每个块取最大值作为输出。
总之,MaxPooling2D层可以帮助卷积神经网络提取图像的空间特征,同时减少计算量和内存消耗。
Flatten
keras.layers.Flatten()是Keras中的一个层,它用于将输入“平铺”成一维向量。
在卷积神经网络中,通常会使用卷积层和池化层提取图像的特征,然后使用全连接层进行分类。全连接层的输入是一个一维向量,因此需要将之前的特征图“展平”为一维向量。这就是Flatten层的作用。
Flatten层没有任何参数,它只是将输入张量按照顺序展开成一维向量。例如,如果输入张量的shape为(batch_size, 7, 7, 64),则Flatten层的输出shape为(batch_size, 7764)。
在搭建卷积神经网络时,通常会在卷积层和池化层之后添加一个Flatten层,将特征图展平成一维向量,然后再连接到全连接层进行分类。
Dense|Dropout
参考多层感知器
手写数字识别
卷积mnist数据集
我们将加载MNIST数据集并进行预处理,将像素值缩放到0到1之间,并将数据集分为训练集和测试集。
这里数据处理详解参考多层感知器
import tensorflow as tf
import tensorflow.keras
from tensorflow.keras import layers
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import regularizers
(x_train, y_train), (x_test, y_test) = mnist.load_data()x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]num_classes = 10y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
接下来,我们将定义一个卷积神经网络模型。我们将使用两个卷积层和两个池化层,然后是两个全连接层和一个输出层。我们还将使用dropout和L2正则化来防止过拟合。
model = tf.keras.Sequential([layers.Conv2D(32, (3, 3), activation='relu', kernel_regularizer=regularizers.l2(0.001), input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu', kernel_regularizer=regularizers.l2(0.001)),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.001)),layers.Dropout(0.5),layers.Dense(64, activation='relu', kernel_regularizer=regularizers.l2(0.001)),layers.Dropout(0.5),layers.Dense(num_classes, activation='softmax')
])
model.summary()是Keras中模型对象的一个方法,用于打印出模型的结构信息,包括每一层的名称、输出形状、参数数量等。这对于调试、优化模型以及理解模型结构都非常有用。
model.summary()
然后,我们将对模型进行编译,并使用数据增强技术来进一步防止过拟合。数据增强技术将应用一系列随机变换,例如旋转、平移、缩放等,来生成新的训练样本。这样可以使模型更加鲁棒,并防止过拟合。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])datagen = ImageDataGenerator(rotation_range=10,width_shift_range=0.1,height_shift_range=0.1,zoom_range=0.1
)
接下来,我们将使用训练集来训练模型,并使用测试集来评估模型的性能。
datagen.fit(x_train)
batch_size = 1024
epochs = 10
checkpoint = tf.keras.callbacks.ModelCheckpoint('./model.h5', save_best_only=True, save_weights_only=False, monitor='val_loss')
history = model.fit(datagen.flow(x_train, y_train, batch_size=batch_size),epochs=epochs,validation_data=(x_test, y_test),steps_per_epoch=len(x_train) // batch_size,callbacks=[checkpoint])score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
steps_per_epoch和batch_size 两个参数区别
batch_size 是指每个训练批次(batch)中包含的样本数。在深度学习中,通常会将训练集分成多个批次,每个批次中包含若干个样本。这样做的好处是可以利用矩阵运算加速计算,同时也可以在训练过程中随机打乱样本顺序以避免过拟合。
steps_per_epoch 是指在一个 epoch 中,模型需要训练的批次数。由于每个 epoch 中包含多个批次,因此需要设置 steps_per_epoch 来指定一个 epoch 中需要经过多少个批次。通常,steps_per_epoch 的值可以通过训练集大小和 batch_size 计算得到。例如,如果训练集大小为 1000,batch_size 为 32,那么一个 epoch 中就需要训练 1000 / 32 = 31 个批次,因此 steps_per_epoch 就应该设置为 31。
需要注意的是,steps_per_epoch 不一定等于训练集大小除以 batch_size 的结果。如果训练集大小不能被 batch_size 整除,那么最后一个批次中可能会包含少于 batch_size 个样本。为了避免这种情况,可以使用向下取整操作 // 来计算 steps_per_epoch,确保每个 epoch 中都能够处理完整个训练集。
fine-tuning
Fine-tuning是指在已经训练好的模型上,针对特定任务或特定数据集进行微调,以达到更好的性能表现的方法。通常,我们会使用一个在大规模数据集上预训练好的模型,例如ImageNet等数据集,这个模型在训练过程中已经学到了很多通用的特征和模式。我们可以通过在这个模型的基础上进行微调,调整一些参数或者增加一些新的层,使得这个模型更适合新的任务或新的数据集。这种方法通常比从头开始训练一个模型更加高效,因为预训练模型已经具有很好的初始权重和特征提取能力。
mnist-c数据集
MNIST-C是MNIST数据集的一个变体,它是加入了人工噪声的MNIST数据集。MNIST数据集是一个手写数字识别数据集,包含60,000个训练样本和10,000个测试样本,每个样本都是一个28 x 28像素的灰度图像。MNIST-C数据集是通过在MNIST数据集的图像上添加随机噪声来创建的,这些噪声包括模糊、扭曲、亮度变化等,从而使模型更有鲁棒性。
MNIST-C数据集对于测试机器学习模型的稳健性非常有用,因为它可以测试模型对于不同类型的噪声的鲁棒性。MNIST-C数据集中的每个图像都包含一个标签,表示它所代表的数字。这些标签与MNIST数据集中的相应标签相同,因此您可以使用相同的训练和测试流程来训练和测试您的模型。
下载该数据集,https://github.com/google-research/mnist-c/ ,这个github地址是源码地址,实际下载地址在readme中提及:https://zenodo.org/record/3239543#.ZF2rzXZByUl,下载后解压
这些文件夹里都是npy格式的numpy数组导出。
读取每个文件夹的前10张图片显示
# 数据集的开源地址:https://github.com/google-research/mnist-c/
import os
import numpy as np
import matplotlib.pyplot as plt
#加载数据集并打印每个子文件夹前10个数据集
data_root = './mnist_c'
dirlist=os.listdir(data_root)
fig, axs = plt.subplots(len(dirlist), 10, figsize=(10, 10))for i, folder_name in enumerate(dirlist):folder_path = os.path.join(data_root, folder_name)if os.path.isdir(folder_path):file_path = os.path.join(folder_path, 'train_images.npy')data = np.load(file_path)for j in range(0,10):axs[i, j].imshow(data[j].reshape(28,28), cmap='gray')axs[i, j].axis('off')
plt.tight_layout()
plt.show()输出

fine-tuning方法训练
假设我们开始试用试用minist的训练的模型位于./model.h5,我们需要加载该模型,然后试用该模型继续训练minist-c的数据。
#%%import os
import numpy as np
import tensorflow.keras as layers
import tensorflow as tf
import datetimeTARGET_MODEL_DIR="./"
MODEL_NAME="model.h5"
epochs_count=5
"""jupyter打印的日志太大导致ipynb打开很慢,这里写个一模一样代码的py运行
"""
def againTrain(x_train, y_train, x_test, y_test):targetModel=os.path.join(TARGET_MODEL_DIR,MODEL_NAME)#记载CNN模型model=tf.keras.models.load_model(targetModel)"""在使用Fine-tuning方法微调预训练模型时,通常会冻结模型的前几层,只调整模型的后面几层,这是因为:1.预训练模型的前几层通常是针对原始数据集的通用特征提取器,这些特征对于不同的任务和数据集都是有用的,因此我们可以直接保留这些特征提取器,不需要进行微调。2.预训练模型的后几层通常是针对特定任务进行的微调,这些层的参数需要根据具体任务和数据集进行调整,以使模型更好地适应特定的任务和数据集。3.如果我们将整个模型的所有层都进行微调,会导致训练时间较长,而且可能会出现过拟合等问题。因此,冻结前几层可以有效地减少训练时间,并提高模型的泛化能力。总之,冻结模型的前几层可以节省计算资源和训练时间,同时还可以提高模型的泛化能力,使其更好地适应新的任务和数据集。"""model.layers[0].trainable = Falsemodel.layers[1].trainable = False# 对输入图像进行预处理x_train = x_train.reshape(-1, 28, 28, 1)x_train = x_train.astype('float32') / 255.0x_test = x_test.reshape(-1, 28, 28, 1)x_test = x_test.astype('float32') / 255.0y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)now = datetime.datetime.now() # 获取当前时间format_time = now.strftime("%Y-%m-%d%H-%M-%S") # 转换为指定格式checkpoint = tf.keras.callbacks.ModelCheckpoint(targetModel, save_best_only=True, save_weights_only=False, monitor='val_loss')# 继续训练模型history = model.fit(x_train, y_train, batch_size=128, epochs=epochs_count, validation_data=(x_test, y_test),callbacks=[checkpoint])test_loss, test_acc = model.evaluate(x_test, y_test)print('Test accuracy:', test_acc)
"""传入mnist-c,数据会非常大加载数据很慢,这里每加载一份子目录就训练一次,节省内存开销。
"""
def loadDataMnistC(data_root,func):dirlist=os.listdir(data_root)for i, folder_name in enumerate(dirlist):folder_path = os.path.join(data_root, folder_name)if os.path.isdir(folder_path):print("开始读取:"+folder_path)train_images = np.load(os.path.join(folder_path, 'train_images.npy'))train_labels = np.load(os.path.join(folder_path, 'train_labels.npy'))test_images = np.load(os.path.join(folder_path, 'test_images.npy'))test_labels = np.load(os.path.join(folder_path, 'test_labels.npy'))print("开始训练:"+folder_path)func(train_images,train_labels,test_images,test_labels)print("训练完成:"+folder_path)
# 加载 MNIST-C 数据集
data_root = './mnist_c'
model=None;
loadDataMnistC(data_root,againTrain)
print("全部训练完成")
这里每次读取一次某型,然后试用子文件夹训练又会写回到该模型,知道训练完成获取到最终的模型
相关文章:
深度学习03-卷积神经网络(CNN)
简介 CNN,即卷积神经网络(Convolutional Neural Network),是一种常用于图像和视频处理的深度学习模型。与传统神经网络相比,CNN 有着更好的处理图像和序列数据的能力,因为它能够自动学习图像中的特征&…...

你真正知道什么是品牌营销么?颠覆你旧有认知
什么是品牌营销,新时代也需要新时代的定义和诠释! 尤其这次疫情加剧了行业竞争,让很多企业都开始重新重视品牌建设,以此实现对产品的价格保护,脱离同质化恶性竞争;提高品牌知名度,实现更高价值…...
pytorch 测量模型运行时间,GPU时间和CPU时间,model.eval()介绍
文章目录 1. 测量时间的方式2. model.eval(), model.train(), torch.no_grad()方法介绍2.1 model.train()和model.eval()2.2 model.eval()和torch.no_grad() 3. 模型推理时间方式4. 一个完整的测试模型推理时间的代码5. 参考: 1. 测量时间的方式 time.time() time.…...
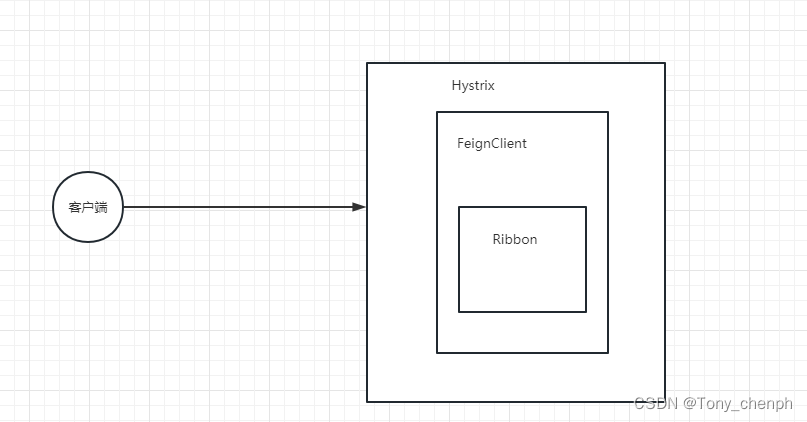
十三、超时重试机制
目录 超时配置和重试机制 FeignClient 、Ribbon 、 Hystrix三个之间配置优先级的关系 配置常用属性 Ribbon超时和重试配置: Ribbon重试次数计算公式: FeignClient 超时配置: Hystrix超时配置: Hystrix超时计算公式: 超时配…...

JAVA常用API - Runtime和System
文章目录 前言 大家好,我是最爱吃兽奶,今天给大家带来JAVA常用API中的Runtime类和System类 那么就让我们一起去看看吧! 一、Rubtime 1.Rubtime是什么? 2.Runtime常用方法 Runtime提供了很多方法,在这里演示两个 public static Runtime getRuntime(): 返回当前运行时环境的…...
ANR实战案例 - FCM拉活启动优化
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 文章目录 系列文章目录前言一、Trace日志分析二、业务分析1.Firebase源码分析2.Firebase官方查看官方文档Dem…...
Kali-linux查看打开的端口
对一个大范围的网络或活跃的主机进行渗透测试,必须要了解这些主机上所打开的端口号。在Kali Linux中默认提供了Nmap和Zenmap两个扫描端口工具。为了访问目标系统中打开的TCP和UDP端口,本节将介绍Nmap和Zenmap工具的使用。 4.4.1 TCP端口扫描工具Nmap 使…...

判断浏览器是否支持webp图片
.WebP是谷歌主导的开放免费的网络图像格式,其核心编码来自VP8也就是同时支持WebP图片和WebM视频等。 这种图像格式追求的并不是无损画质,而是在有损画质的情况下尽可能的压缩图像体积但也尽量降低清晰度下降。 谷歌资助和发展该图像格式最主要的目的就是…...
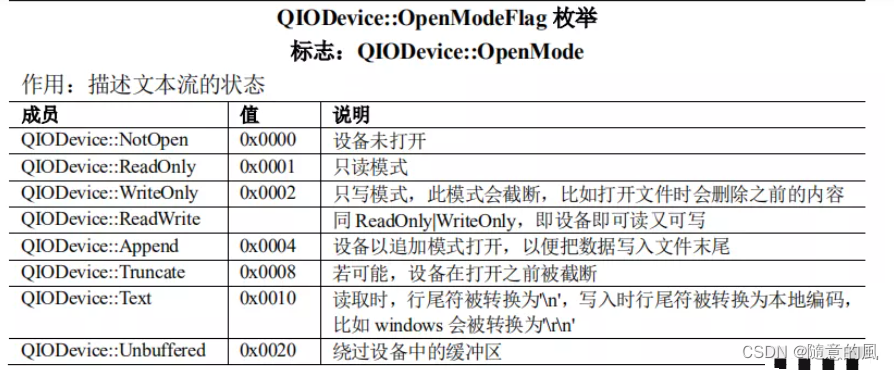
【Qt编程之Widgets模块】-007:QTextStream类及QDataStream类
1 概述 QTextStream和QDataStream都是对流进行操作 QTextStream只能普通类型的流操作像QChar、QString、int…,其实就很类似我们c或者c中读写文件的感觉, QDataStream就厉害了,无论是QTextStream的普通类型的流操作还是一些特殊类型的流操作…...

js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法
js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法 js对map排序,后端返回有序的LinkedHashMap类型时前端获取后顺序依旧从小到大的解决方法 [{"2020": [{"id": 39,"createTime": &quo…...

JMX vs JFR:谁才是最强大的JVM监控利器?
大家好,我是小米!今天我们来聊一聊JVM监控系统,特别是关于JMX和JFR的使用。你是否有过在线上应用出现性能问题时,无法准确获取关键指标的困扰呢?那么,不妨听听我给大家带来的解决方案。 什么是JMX 首先&a…...

Laravel Collection 基本使用
创建集合 为了创建一个集合,可以将一个数组传入集合的构造器中,也可以创建一个空的集合,然后把元素写到集合中。Laravel 有collect()助手,这是最简单的,新建集合的方法。 $collection collect([1, 2, 3]);默认情况下…...

JUC并发编程19 | 读写锁
有一些关于锁的面试题: 你知道 Java 里面有哪些锁?读写锁的饥饿问题是什么?有没有比读写锁更快的锁?StampedLock知道嘛?(邮戳锁/票据锁)ReentrantReadWriteLock 有锁降级机制? Ree…...

springboot_maven项目怎么引入mybatis
在pom.xml文件中添加mybatis和mybatis-spring-boot-starter的依赖 org.mybatis mybatis ${mybatis.version} org.mybatis.spring.boot mybatis-spring-boot-starter ${mybatis.spring.version} 配置mybatis 在application.properties(或application.yml࿰…...

JAVA8的新特性——lambda表达式
JAVA8的新特性——lambda表达式 此处,我们首先对于Java8的一些特性作为一个简单介绍 Java 8是Java编程语言的一个重要版本,于2014年发布。Java 8引入了许多新特性和改进,以提高开发效率和性能。以下是Java 8的一些主要新特性: Lam…...
算法修炼之练气篇——练气六层
博主:命运之光 专栏:算法修炼之练气篇 前言:每天练习五道题,炼气篇大概会练习200道题左右,题目有C语言网上的题,也有洛谷上面的题,题目简单适合新手入门。(代码都是命运之光自己写的…...
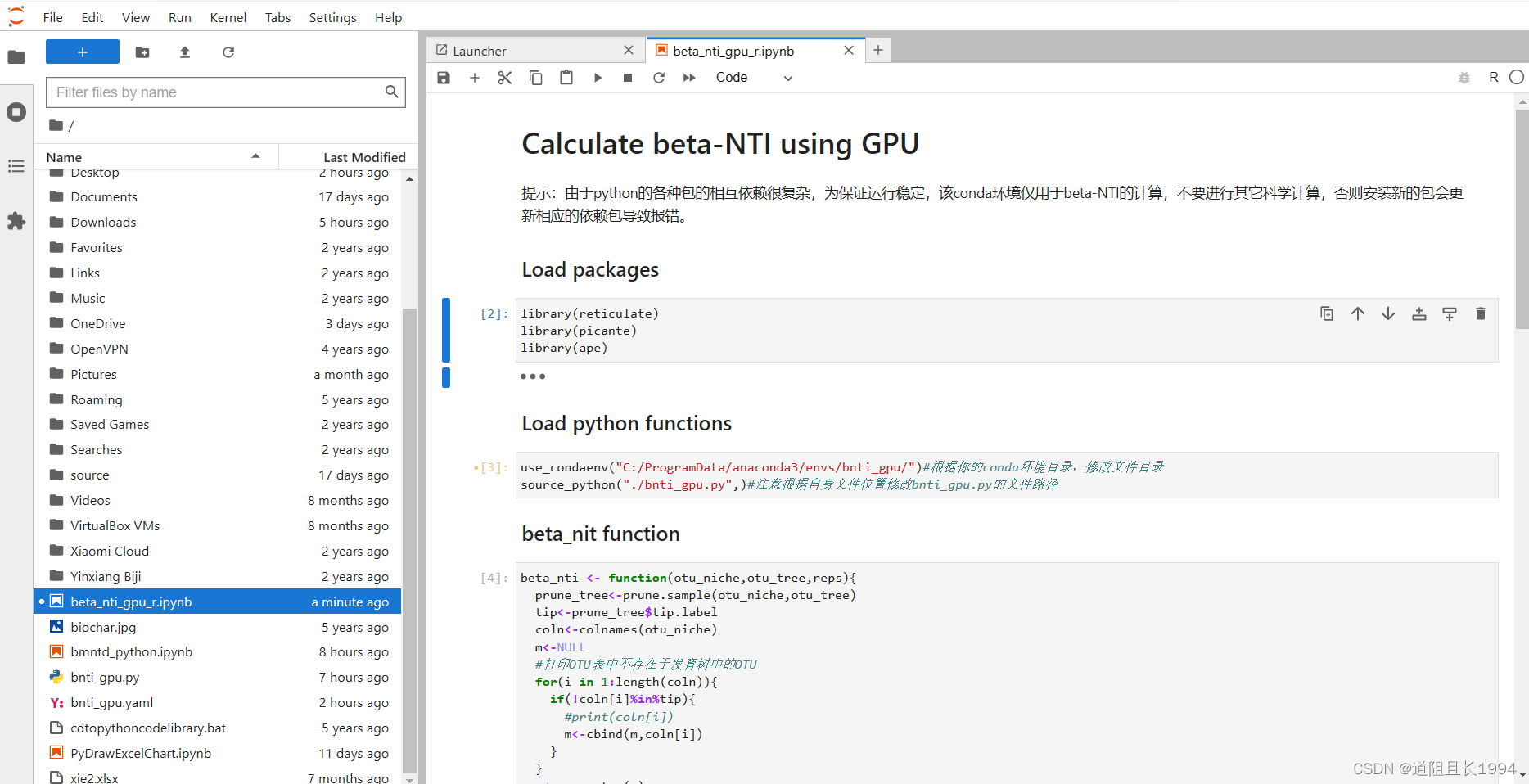
利用GPU并行计算beta-NTI,大幅减少群落构建计算时间
1 先说效果 18个样本,抽平到8500条序列,4344个OTUs,计算beta-NTI共花费时间如下。如果更好的显卡,更大的数据量,节约的时间应该更加可观。 GPU(GTX1050):1分20秒 iCAMP包 的bNTIn.p(…...
Shiro框架漏洞分析与复现
Shiro简介 Apache Shiro是一款开源安全框架,提供身份验证、授权、密码学和会话管理。Shiro框架直观、易用,同时也能提供健壮的安全性,可以快速轻松地保护任何应用程序——从最小的移动应用程序到最大的 Web 和企业应用程序。 1、Shiro反序列…...

(数字图像处理MATLAB+Python)第七章图像锐化-第一、二节:图像锐化概述和微分算子
文章目录 一:图像边缘分析二:一阶微分算子(1)梯度算子A:定义B:边缘检测C:示例D:程序 (2)Robert算子A:定义B:示例C:程序 &a…...

C# | 内存池
内存池 文章目录 内存池前言什么是内存池内存池的优点内存池的缺点 实现思路示例代码结束语 前言 在上一篇文章中,我们介绍了对象池的概念和实现方式。对象池通过重复利用对象,避免了频繁地创建和销毁对象,提高了系统的性能和稳定性。 今天我…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...