【大数据clickhouse】clickhouse 常用查询优化策略详解
一、前言
在上一篇我们分享了clickhouse的常用的语法规则优化策略,这些优化规则更多属于引擎自带的优化策略,开发过程中只需尽量遵守即可,然而,在开发过程中,使用clickhouse更多将面临各种查询sql的编写甚至复杂sql的编写,这就是本篇要探讨的关于clickhouse查询相关的优化策略。
二、关于单表查询相关优化策略
2.1 使用Prewhere 替代 where
Prewhere 和 where 语句的作用相同,用来过滤数据。不同之处在于 prewhere 只支持*MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性
select u.* from user u where u.name = 'xxx'在clickhouse中,默认情况下,使用where 过程也是类似,但使用了Prewhere 时,并不需要进行全表的扫描了,这样就大大提升了查询的性能;
默认情况下,prewhere自动开启
看下面的查询sql,使用explain查看下
EXPLAIN SYNTAX
select WatchID, JavaEnable, Title, GoodEvent, EventTime, EventDate, CounterID, ClientIP, ClientIP6, RegionID, UserID, CounterClass, OS, UserAgent, URL, Referer, URLDomain, RefererDomain, Refresh, IsRobot, RefererCategories, URLCategories, URLRegions, RefererRegions, ResolutionWidth, ResolutionHeight, ResolutionDepth, FlashMajor, FlashMinor, FlashMinor2
from datasets.hits_v1 where UserID='3198390223272470366';可以看到引擎自动优化为了prewhere查询
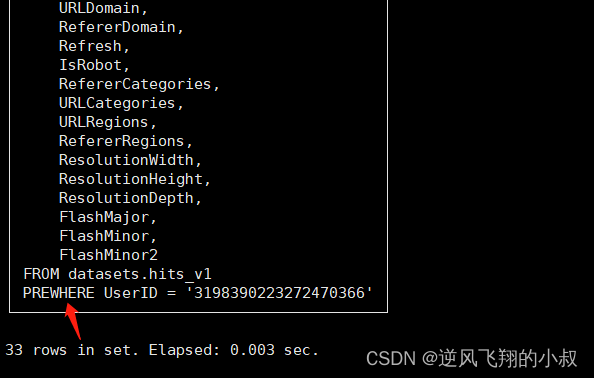
关闭 where 自动转 prewhere
开启下面的配置,可以关闭prewhere功能
set optimize_move_to_prewhere=0; 再次查询,可以发现prewhere就关闭了;

- 使用常量表达式;
- 使用默认值为 alias 类型的字段;
- 包含了 arrayJOIN,globalIn,globalNotIn 或者 indexHint 的查询;
- select 查询的列字段和 where 的谓词相同;
- 使用了主键字段;

2.2 使用数据采样替代全量查询或统计
SAMPLE 0.1 #代表采样 10%的数据,也可以是具体的条数
SELECT Title,count(*) AS PageViews
FROM hits_v1
SAMPLE 0.1
WHERE CounterID =57
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000;可以发现使用这种方式计算统计结果时性能上有明显的提升;
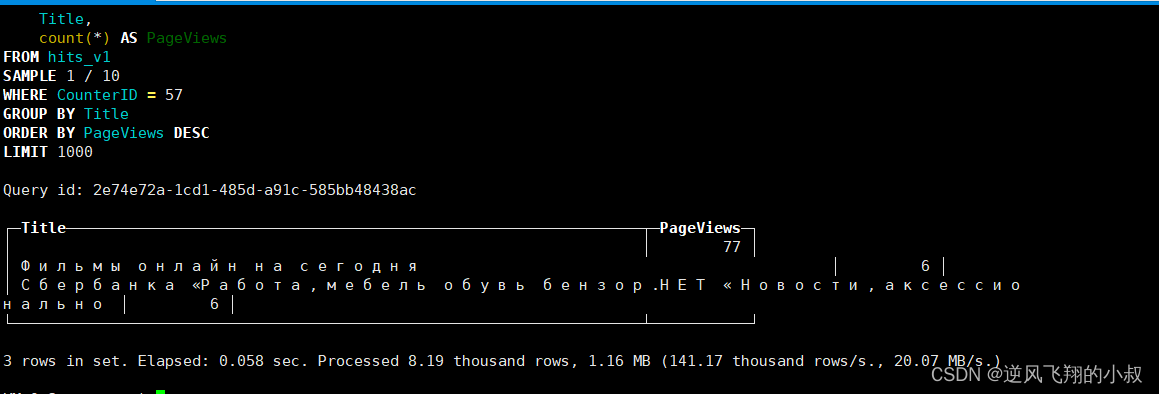
2.3 列裁剪与分区裁剪
列裁剪(减少非必要的查询字段)
select * from datasets.hits_v1;改成下面这样就会好很多;
select WatchID, JavaEnable, Title, GoodEvent, EventTime, EventDate, CounterID, ClientIP, ClientIP6, RegionID, UserID
from datasets.hits_v1;分区裁剪
select WatchID, JavaEnable, Title, GoodEvent, EventTime, EventDate, CounterID, ClientIP, ClientIP6, RegionID, UserID
from datasets.hits_v1
where EventDate='2014-03-23';2.4 orderby 结合 where、limit
千万量级以上的数据集进行 order by 查询时,最好搭配 where 条件和 limit 语句一起使用,说到底,就是对查询的结果集数量进行限制,数据量减少了怎么都好说;
SELECT UserID,Age
FROM hits_v1
WHERE CounterID=57
ORDER BY Age DESC LIMIT 1000;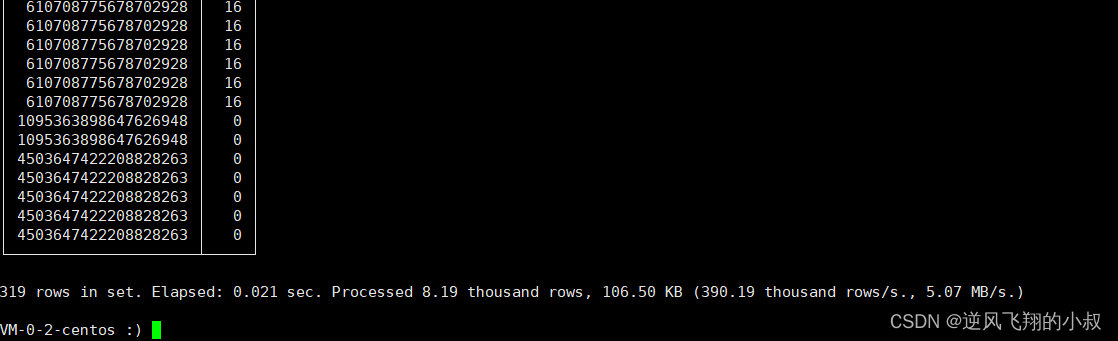
2.5 避免构建虚拟列
如非必须,不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前端进行处理,或者在表中构造实际字段进行额外存储;
比如下面的sql,Income/Age 这个就是一个虚拟列,表中并不存在这个字段,而是处于业务的需要构建出来的,不仅是clickhouse,甚至mysql中这种写法也应该是尽量要避免的;
SELECT Income,Age,Income/Age as IncRate FROM datasets.hits_v1;2.6 使用uniqCombined 替代 distinct
使用uniqCombined 替代 distinct ,性能可提升 10 倍以上,uniqCombined 底层采用类似 HyperLogLog 算法实现,能接收 2%左右的数据误差,可直接使用这种去重方式提升查询性能;
Count(distinct )会使用 uniqExact精确去重,不建议在千万级不同数据上执行 distinct 去重查询,改为近似去重 uniqCombined;
比如查询时可以使用下面这种方式
SELECT uniqCombined(rand()) from datasets.hits_v1;2.7 其他单表查询中需要注意的事项
(一)查询熔断
为了避免因个别慢查询引起服务雪崩问题,除了可以为单个查询设置超时以外,还可以配置周期熔断,在一个查询周期内,如果用户频繁进行慢查询操作超出规定阈值后将无法继续进行查询操作。
(二)关闭虚拟内存
物理内存和虚拟内存的数据交换,会导致查询变慢,资源允许的情况下建议关闭虚拟内存;
(三)配置 join_use_nulls
为每一个账户添加 join_use_nulls 配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准 SQL 中的 Null 值;
(四)批量写入时先排序
批量写数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。因为无序的数据或者涉及的分区太多,会导致 ClickHouse 无法及时对新导入的数据进行合并,从而影响查询性能。
(五)关注 CPU
cpu 一般在 50%左右会出现查询波动,达到 70%会出现大范围的查询超时,cpu 是最关
键的指标,因此运维过程中要非常关注。
三、关于多表关联查询相关优化策略
前置准备
依次执行下面的sql,从源表中复制出两个新表,并从源表中导入部分数据
#创建小表
CREATE TABLE visits_v2
ENGINE = CollapsingMergeTree(Sign)
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate, intHash32(UserID), VisitID)
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from visits_v1 limit 10000;#创建 join 结果表:避免控制台疯狂打印数据
CREATE TABLE hits_v2
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from hits_v1 where 1=0;
3.1 使用in代替join
当多表联合查询时,当最终查询的数据仅从其中一张表出来时,可考虑用 IN 操作而不是使用JOIN
这个和clickhouse的自身的关联查询数据加载机制有关,比如A join B时,需要先把B加载到内存中,然后从A中查询的结果跟内存中B的数据进行匹配,如果B表的数据量非常大,很有可能造成内存被耗尽;
正确的使用方式
insert into hits_v2
select a.* from hits_v1 a where a. CounterID in (select CounterID from
visits_v1);反例
insert into table hits_v2
select a.* from hits_v1 a left join visits_v1 b on a. CounterID=b.
CounterID;3.2 大小表 JOIN
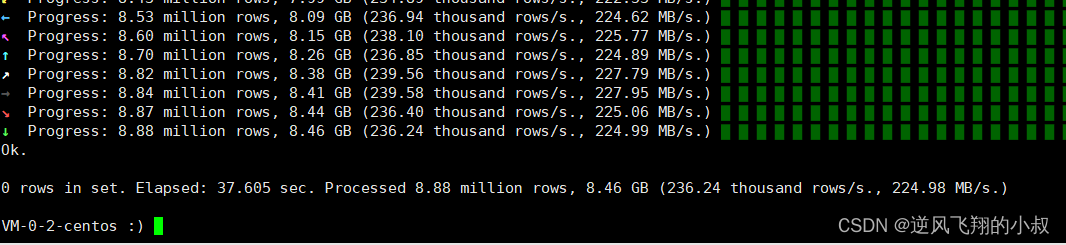
多表join时尽量要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较,ClickHouse 中无论是 Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表,这一点必须注意。
下面用两个sql分别模拟下小表在左和小表在右的情况
小表在右
insert into table hits_v2
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b.
CounterID;通过执行sql,耗时大概在37秒多
大表在右
insert into table hits_v2
select a.* from visits_v2 b left join hits_v1 a on a. CounterID=b.
CounterID;内存超过限制了,直接执行失败

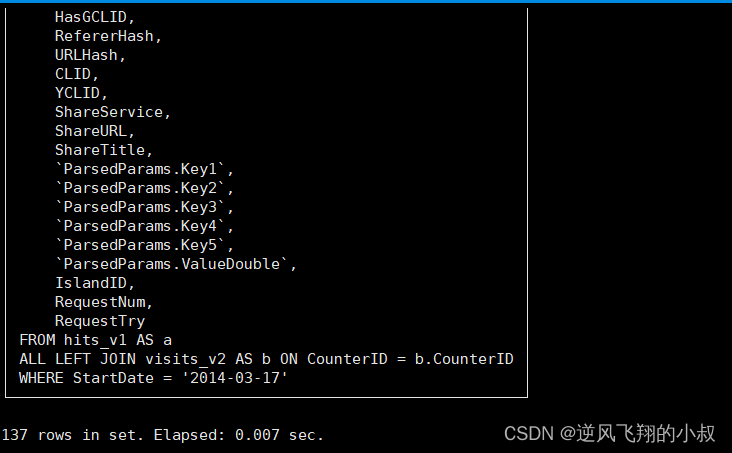
3.3 谓词下推
ClickHouse在join查询时,不会主动发起谓词下推的操作,需要每个子查询提前完成过滤操作,要注意的是,是否执行谓词下推,对性能影响差别很大(新版本中已经不存在此问题,但是需要注意谓词的位置的不同依然有性能的差异);
下面的sql会被优化为 prewhere
Explain syntax
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b.
CounterID
having a.EventDate = '2014-03-17';Explain syntax
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b.
CounterID
having b.StartDate = '2014-03-17'
3.4 分布式表使用GLOBAL
在真实的线上环境,clickhouse通常多节点部署,在这种情况下,如果两张分布式表上在使用 IN 和 JOIN 之前,必须加上 GLOBAL 关键字,右表只会在接收查询请求的那个节点查询一次,并将其分发到其他节点上。如果不加 GLOBAL 关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询 N²次(N是该分布式表的分片数量),这就是查询放大,会带来很大开销;
3.5 使用字典表
将一些需要关联分析的业务,创建成字典表进行 join 操作,前提是字典表不宜太大,因为字典表会常驻内存;
3.6 提前过滤数据
通过增加逻辑过滤以减少数据行的扫描,达到提高执行速度及降低内存消耗的目的,这个和mysql的思想是一致的;
相关文章:
【大数据clickhouse】clickhouse 常用查询优化策略详解
一、前言 在上一篇我们分享了clickhouse的常用的语法规则优化策略,这些优化规则更多属于引擎自带的优化策略,开发过程中只需尽量遵守即可,然而,在开发过程中,使用clickhouse更多将面临各种查询sql的编写甚至复杂sql的…...
【Java项目】基于Java+MySQL+Tomcat+maven+Servlet的个人博客系统的完整分析
✨哈喽,进来的小伙伴们,你们好耶!✨ 🛰️🛰️系列专栏:【Java项目】 ✈️✈️本篇内容:个人博客系统前后端分离实现! 🚀🚀个人代码托管github:博客系统源码地址ÿ…...

java 程序员怎么做找工作
java 程序员怎么做找工作 在网络招聘网站上搜索职位。在中国,像智联招聘、前程无忧、猎聘网等招聘网站上,有许多公司在招聘JAVA程序员。通过这些网站可以快速找到自己合适的工作。 关注社交媒体和专业网站。 加入一些面向JAVA程序员的社交媒体和专业网…...
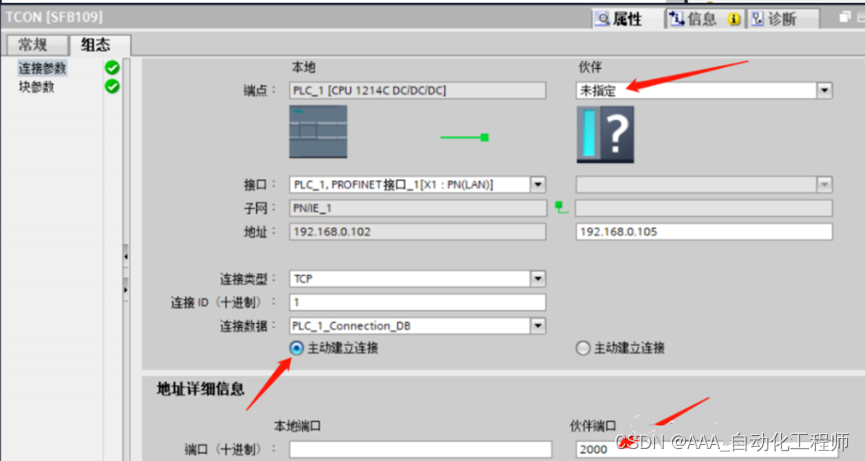
S7-1200对于不同项目下的PLC之间进行开放式以太网通信的具体方法示例
S7-1200对于不同项目下的PLC之间进行开放式以太网通信的具体方法示例 如下图所示,打开TIA博途创建一个新项目,并通过“添加新设备”组态 S7-1200 客户端 ,选择 CPU1214C DC/DC/DC (client IP:192.168.0.102),建立新子网; 首先编写客户端程序:打开OB1编程界面,选择指令…...
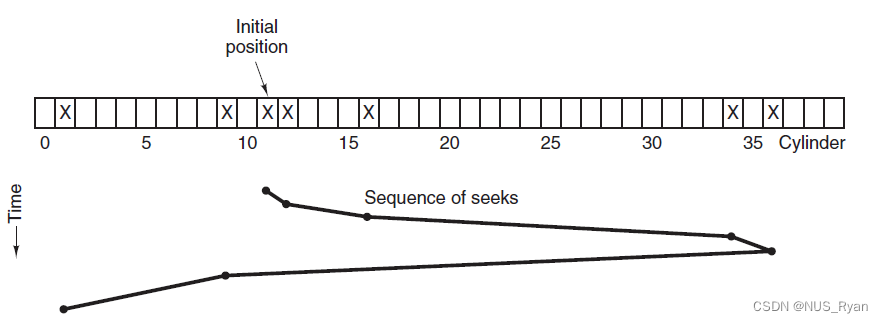
操作系统(四):磁盘调度算法,先来先服务,最短寻道时间优先,电梯算法
文章目录一、磁盘结构二、先来先服务三、最短寻道时间优先四、电梯算法 SCAN一、磁盘结构 盘面(Platter):一个磁盘有多个盘面; 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多…...

maven解决包冲突简单方式(插件maven helper | maven指令)
文章目录使用idea插件maven helper使用maven指令在Java开发中,常常会遇到不同jar包之间存在冲突的情况,这可能会导致编译错误、运行时异常等问题。 使用idea插件maven helper 在idea安装插件maven helper 安装重启完之后点击pom文件,有一个De…...

100行Pytorch代码实现三维重建技术神经辐射场 (NeRF)
提起三维重建技术,NeRF是一个绝对绕不过去的名字。这项逆天的技术,一经提出就被众多研究者所重视,对该技术进行深入研究并提出改进已经成为一个热点。不到两年的时间,NeRF及其变种已经成为重建领域的主流。本文通过100行的Pytorch…...

linux操作系统篇
目录 操作系统概述基本特征并发共享虚拟异步进程管理内存管理文件管理设备管理宏内核和微内核宏内核微内核中断分类外中断异常陷入(系统调用)进程管理进程与线程的区别进程状态切换进程调度算法**批处理系统****交互式系统**进程同步临界...

redis+token实现登录校验,前后端分离,及解跨域问题的4种方法
目录 一、使用自定义filter实现跨域 1、客户端向服务端发送请求 2、服务端做登录验证了,并生成登路用户对应的token,保存到redis 3、响应(报错)-----跨域问题 4、解决跨域问题--------服务器端添加过滤器,设置请求…...
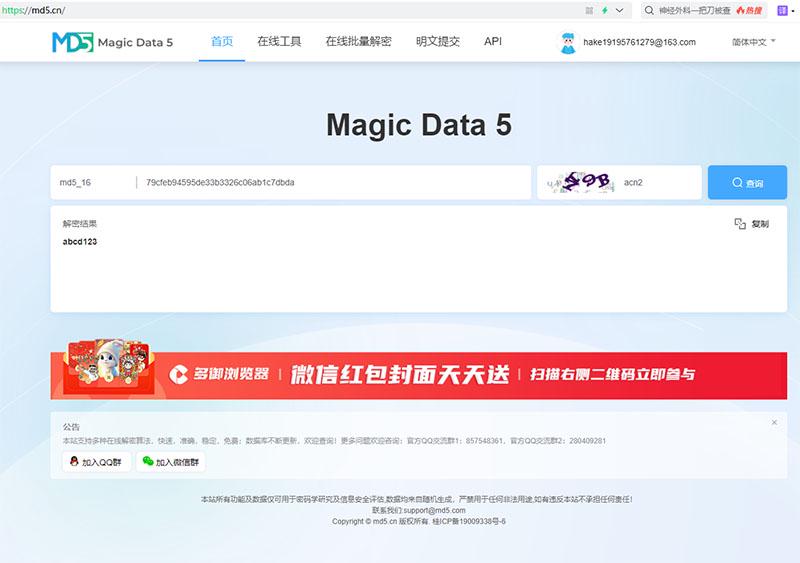
怎么解密MD5,常见的MD5解密方法,一看就会
MD5是一种被广泛使用的密码散列函数,曾在计算机安全领域使用很广泛,但是也因为它容易发生碰撞,而被人们认为不安全。那么,MD5应用场景有哪些,我们怎么解密MD5,本文将带大家了解MD5的相关知识,以…...
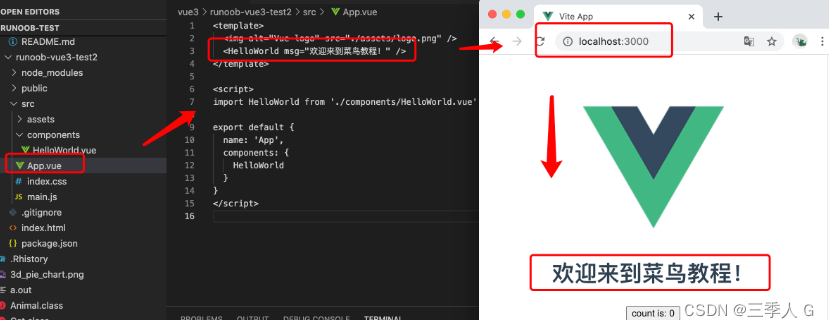
Vue3 目录结构
Vue3 目录结构 架构搭建 请确保你的电脑上成功安装 Node.js,本项目使用 Vite 构建工具,需要 Node.js 版本 > 12.0.0。 查看 Node.js 版本: node -v建议将 Node.js 升级到最新的稳定版本: 使用 nvm 安装最新稳定版 Node.js…...

Tsp_nurrec表空间满处理记录20230215
Tsp_nurrec表空间满处理记录20230215 一、问题: 问题:护理病历表空间不足。 二、解决过程:1.查询表空间使用效率 SELECT UPPER(F.TABLESPACE_NAME) “表空间名”, D.TOT_GROOTTE_MB "表空间大小(M)",D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)"…...

影像测量设备都有什么?有哪些影像仪器?
影像测量仪器是广泛应用于机械、电子、仪表的仪器。主要由机械主体、标尺系统、影像探测系统、驱动控制系统和测量软件等与高精密工作台结构组成的光电测量仪器。一般分为三大类:手动影像仪、自动影像仪和闪测影像仪。测量元素主要有:长度、宽度、高度、…...
Transformer:开启CV研究新时代
来源:投稿 作者:魔峥 编辑:学姐 起源回顾 有关Attention的论文早在上世纪九十年代就提出了。 在2012年后的深度学习时代,Attention再次被翻了出来,被用在自然语言处理任务,提高RNN模型的训练速度。但是由…...

Flink X Hologres构建企业级Streaming Warehouse
摘要:本文整理自阿里云资深技术专家,阿里云Hologres负责人姜伟华,在FFA实时湖仓专场的分享。点击查看>>本篇内容主要分为四个部分: 一、实时数仓分层的技术需求 二、阿里云一站式实时数仓Hologres介绍 三、Flink x Hologres…...
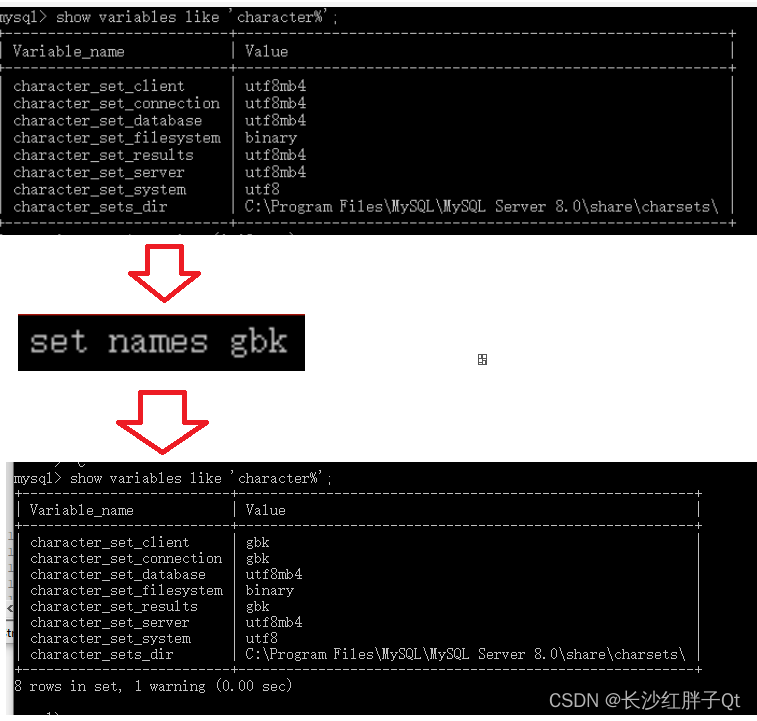
关于 mysql数据库插入中文变空白 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/129048030 红胖子网络科技的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软…...

不可错过的SQL优化干货分享-sql优化、索引使用
本文是向大家介绍在sql调优的几个操作步骤,它能够在日常遇到慢sql时有分析优化思路,能够让开发者更好的了解sql执行的顺序和原理。一、前言在日常开发中,我们经常遇到一些数据库相关的问题,比方说:SQL已经走了索引了&a…...
vue3:直接修改reative的值,页面却不响应,这是什么情况?
目录 前言 错误示范: 解决办法: 1.使用ref 2.reative多套一层 3.使用Object.assign 前言: 今天看到有人在提问,问题是这样的,我修改了reative的值,数据居然失去了响应性,页面毫无变化&…...

从Vue2 到 Vue3,这些路由差异你需要掌握!
✨ 个人主页:山山而川~xyj ⚶ 作者简介:前端领域新星创作者,专注于前端各领域技术,共同学习共同进步,一起加油! 🎆 系列专栏: vue系列 🚀 学习格言:与其临渊羡…...

Maxwell简介、部署、原理和使用介绍
Maxwell简介、部署、原理和使用介绍 1.Maxwell概述简介 1-1.Maxwell简介 Maxwell是由美国Zendesk公司开源,使用Java编写的MySQL变更数据抓取软件。他会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...