sed和awk
文章目录
- 1、sed的简单介绍
- 2、sed的使用方法
- 2.1 命令行格式
- 2.2 案例
- 2.3 sed结合正则使用
- 2.4 脚本格式
- 3、awk的简单介绍
- 4、awk的使用方法
- 4.1 命令行模式
- 4.2 脚本模式
- 5、awk内部相关变量
- 5.1 案例
- 6、awk工作原理
- 7、awk进阶使用
- 8、awk脚本编程
- 8.1 案例
1、sed的简单介绍
sed是流编辑器,用于处理文件
sed是一行一行读取文件内容并按照要求进行处理,把处理后的结果输出到屏幕

1、首先sed读取文件中的一行内容,把其保存在一个临时缓存区中(也称为模式空间)
2、然后根据需求处理临时缓冲区中的行,完成后把该行发送到屏幕上
总结:
1.由于sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会直接修改原文件
2.Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作,对文件进行过滤和转换操作
2、sed的使用方法
sed常见的语法格式有两种,一种叫命令行模式,另一种叫脚本模式。
2.1 命令行格式
语法格式
sed [options] '处理动作' 文件名
常见选项
| 选项 | 说明 | 备注 |
|---|---|---|
| -e | 进行多项(多次)编辑 | 直接在命令列模式上进行 sed 的动作编辑 |
| -n | 取消默认输出 | 在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。 |
| -r | 使用扩展正则表达式 | sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法) |
| -i | 原地编辑(修改源文件) | 直接修改读取的文件内容,而不是输出到终端 |
| -f | 指定sed脚本的文件名 | 直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作 |
常见的处理动作
以下所有的动作都要在单引号里
| 动作 | 说明 | 备注 |
|---|---|---|
| ‘p’ | 打印 | |
| ‘i’ | 在指定行之前插入内容 | 类似vim里的大写O |
| ‘a’ | 在指定行之后插入内容 | 类似vim里的小写o |
| ‘c’ | 替换指定行所有内容 | |
| ‘d’ | 删除指定行 |
2.2 案例
文件准备
#a.txt
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4: adm:/var/adm:/sbin/nologin
lp:x:4:7:tp:/var/spool/lpd:/sbin/nologin
298374837483
172.16.0.254
10.1.1.1
打印文件内容
sed '' a.txt #对文件什么都不做,但是由于没有-n参数,因此还会将文件的内容打印到屏幕sed -n 'p' a.txt #打印每一行,并取消默认输出sed -n '1p' a.txt #打印第一行sed -n '2p' a.txt #打印第二行sed -n '1,5p' a.txt #打印1-5行sed -n '$p' a.txt #打印最后一行
增加文件内容(单独成行)
sed '$a99999' a.txt #文件最后一行后面增加内容sed 'a99999' a.txt #文件每行后面增加内容sed '5a99999' a.txt #文件第5行后面增加内容sed '$i99999' a.txt #文件最后一行的前面增加内容sed 'i99999' a.txt #文件每行的前一行增加内容sed '6i99999' a.txt #文件第6行前一行增加内容sed '/^uucp/ihello' #以uucp开头行的前一行插入内容#在第1行前连续插入3行内容(第1中写法只会将要插入的内容看成一行,应该遵循第2种写法)
sed -n '1i\hello\world\888' a.txt
结果:
helloworld888sed '1i\
> hello\
> world\
> fl' a.txt
结果:
hello
world
flsed '2,4a999' a.txt #在2-4行的每一行后面一行都增加内容
修改文件内容
sed '5chello world' a.txt #替换文件第5行的内容sed 'chello world' a.txt #替换文件所以内容sed '1,5chello world' a.txt #替换文件1到5行内容为hello world,不是1到5行每一行都替换sed '/^user01/c888888' a.txx #替换user01开头的行sed如果需要结合正则,需要将正则表达式用斜杠包裹起来,例如:
sed '/^adm/chello fl' a.txt
删除文件内容
sed '1d' a.txt #删除文件第一行sed '1,5d' a.txt #删除文件1到5行sed '$d' a.txt #删除文件最后一行sed '/[0-9]/d' a.txt #删除包含数字的行sed -r '/([0-9]\.){1,3}[0-9]{1,3}/d' a.txt #删除文件中的ip地址,-r表示支持扩展正则
对文件进行搜索替换操作
语法:sed 选项 's/搜索内容/替换内容/动作' 需要处理的文件
其中,s表示search搜索。斜杠/表示分隔符,可以自定义。动作一般是打印p和全局替换g。如果不加g,一行中有多个匹配到了,只会替换第一个,加g,则全部替换
sed -n 's/root/ROOT/gp' a.txt #全文搜索root并替换成ROOTsed -n 's/^#//gp' a.txt #删除首行以#开头的#,相当于取消注释sed -n 's@/sbin/nologin@fl@gp' a.txt #将全文中的/sbin/nologin替换为fl
或者写为:sed -n 's/\/sbin\/nologin@fl@gp' a.txtsed -n '10s@/sbin/nologin@fl@gp' a.txt #将第10行中的/sbin/nologin替换为fl,如果没有,就不处理sed -n '1,5s/^/#/gp' a.txt #注释前5行sed -n 's#\(10.1.1.\)1#\1fl#gp' a.txt #(10.1.1.)表示\1,把最后一个1替换为fl
其他命令
| 命令 | 含义 |
|---|---|
| r | 从另外文件读取内容 |
| w | 内容另存为 |
| & | 保存查找串以便在替换串中引用 |
| = | 打印行号 |
| ! | 对所选行以外的所有行应用命令,放到行数之后 |
| q | 退出 |
sed '3r /etc/hosts' a.txt #将/etc/hosts中的数据读到a.txt的第3行之后的位置
[root@fl Shell]# sed '3r /etc/hosts' a.txt
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
127.0.0.1 fl fl
adm:x:3:4: adm:/var/adm:/sbin/nologin
lp:x:4:7:tp:/var/spool/lpd:/sbin/nologin
298374837483
172.16.0.254
10.1.1.1sed '1,5w b.txt' a.txt #将a.txt中的1-5行保存到b.txt中sed -n 's/^lp/#&/gp' a.txt #在以lp开头的前面添加#号 &和\(\)的作用相同
#lp:x:4:7:tp:/var/spool/lpd:/sbin/nologinsed -n 's/^lp/&#/gp' a.txt #在以lp开头的后面添加#号
lp#:x:4:7:tp:/var/spool/lpd:/sbin/nologinsed -n '1,5!p' a.txt #打印非1到5行sed -ne '/root/p' a.txt -ne '/root/=' #打印root所在的行,并打印行号sed -e '/^#/d' -e '/^$/d' a.txt #删除以#开头行(取消注释),删除空行
sed -r '/^#|^$/d' a.txt
2.3 sed结合正则使用
sed 选项 'sed’命令或者正则表达式或者地址定位文件名
1.地址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的合。
2.如果没有指定地址. sed将外理输入文件的所有行。
| 正则 | 说明 | 案例 |
|---|---|---|
| /key/ | 查询包含关键字的行 | sed -n ‘/root/p’ a.txt |
| /key1/,/key2/ | 匹配包含两个关键字之间的行 | sed -n ‘/^adm/, /^mysql/p’ a.txt |
| /key/,X | 从匹配关键字的行开始到文件第x行之间的行(包含关键字所在行) | sed -n ‘/^ftp/,7p’ |
| x,/key/ | 从文件的第x行开始到与关键字的匹配行之间的行 | |
| x,y! | 不包含x到y行 |
sed -nr '/^lp | ^mysql/p' a.txt #找出以lp或者mysql开头的行sed -n '/sync/,8p' a.txt #打印sync所在的行到第8行之间所有的行,闭区间sed -n '3,/^halt/p' a.txt #从第3行开始,打印以halt开头的行之间的所有内容,闭区间
2.4 脚本格式
用法
#sed -f scripts.sh file //使用脚本处理文件
建议使用 ./sed.sh file脚本的第一行写上
#!/bin/sed -f
注意事项
脚本文件是一个sed的命令行清单。’ commands’
在每行的末尾不能有任何空格、制表符(tab)或其它文本。
如果在一行中有多个命令,应该用分号分隔。
不需要且不可用引号保护命令
#号开头的行为注释
3、awk的简单介绍
awk概述
awk是一种编程语言,主要用于在linux/unix下对文本和数据进行处理,是linux/unix 下的一个工具。数据可以来自标准输入、一个或多个文件,或其它命令的输出。
awk的处理文本和数据的方式:逐行扫描文件,默认从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。
awk能干啥?
1、awk用来处理文件和数据的,是类unix下的一个工具,也是一种编程语言
2、可以用来统计数据,比如网站的访问量,访问的IP量等等
3、支持条件判断,支持for和while循环
4、awk的使用方法
4.1 命令行模式
语法结构
awk 选项 '命令部分' 文件名特别说明:
引用Shell变量需要用双引号引起
常用选项介绍
- -F定义字段分隔符,默认分割符是空格
- -v定义变量并赋值
‘命名部分说明’
- 正则表达式,地址定位
'/root/{awk语句}' sed中: '/root/p'
'NR==1,NR==5{awk语句}' sed中: '1,5p'
'/^root/,/^ftp/{awk语句}' sed中: '/^root/,/^ftp/p'
- {awk语句1;awk语句2;…}
'{print $0;print $1}' sed中: 'p'
'NR==5{print $0}' sed中: '5p'
注: awk命令语句间用分号间隔
- BEGIN…END…
'BEGIN{awk语句};{处理中};END{awk语句}'
'BEGIN{awk语句};{处理中}'
'{处理中};END{awk语句}'
4.2 脚本模式
脚本编写
#!/bin/awk -f
一以下是awk引号里的命令清单,不要用引号保护命令,多个命令用分号间隔
BEGIN{FS=":"}
NR==1,NR==3{print $1"\t"$NF}
...
脚本处理
方法1:
awk 选项 -f awk的脚本文件 需要处理的文本文件
awk -f awk.sh filenamesed -f sed.sh -i filename方法2:
./awk的脚本文件(或者绝对路径) 需要处理的文本文件
./awk.sh filename./sed.sh filename
5、awk内部相关变量
| 变量 | 变量说明 | 备注 |
|---|---|---|
| $0 | 当前处理的所有记录 | |
| $1,$2,$3…$n | 文件中每行以间隔符分割的不同字段,间隔符默认是空格 | awk -F:‘{print $1,$3}’ |
| NF | 当前记录的字段数(列数) | awk -F:‘{print NF}’ |
| $NF | 最后一列 | $(NF-1)表示倒数第二列 |
| FNR/NR | 行号 | |
| FS | 定义间隔符 | ‘BEGIN{FS=“:”};{print $1,$3}’ |
| OFS | 定义输出字段分隔符,默认空格 | ‘BEGIN{OFS=“\t”};print $1,$3}’ |
| RS | 输入记录分割符,默认换行 | ‘BEGIN{RS=“\t”};{print $0}’ |
| ORS | 输出记录分割符,默认换行 | ‘BEGIN{ORS=“\n\n”};{print$1,$3}’ |
| FILENAME | 当前输入的文件名 |
5.1 案例
文本准备
head /etc/passwd > 1.txt
tail -3 /etc/passwd >> 1.txt[root@fl Shell]# cat 1.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
fl:x:1000:1000::/home/fl:/bin/bash
yunwei:x:1001:1001::/home/yunwei:/bin/bash
user1:x:1002:1002::/home/user1:/bin/bash
awk '{print $0}' 1.txt #打印每一行(因为没有分隔符,$0表示文本中的每一行)awk 'NR==1,NR==5{print $0}' 1.txt #打印1-5行,同下
awk 'NR>=1 && NR<=5{print $0}' 1.txtawk 'NR==1 || NR==5{print $0}' 1.txt #打印1和5行awk -F: '{print $1,$(NF-1),$NF}' 1.txt #打印每一行以冒号分割的第一列,倒数第二列和最后一列awk -F: '{print NF}' 1.txt #每一行以冒号分割,并打印每一行的列数awk -F: '/root/{print $1,$NF}' 1.txt #打印包含root的,以冒号分割的第一行和最后一行awk 'NR>=1 && NR<=5 && /^root/{print $0}' 1.txt #打印1-5行中以root开头的行awk 'BEGIN{FS=":";OFS="@"};{print $1,$NF}' 1.txt #打印以冒号分割的第一列和最后一列,列与列之间用@作为分隔符,同下
awk 'BEGIN{FS=":";OFS="@"};{print $1"@"$NF}' 1.txt #分隔符要用双引号引起来
6、awk工作原理
awk -F: '{print $1,$3}' /ect/passwd
- awk使用一行作为输入,并将这一 行赋给内部交量50,每行也可称为一个记录,以换行符(RS)结束
- 每行被间隔符:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中,从$1开始
- awk使用print函数打印字段,打印出来的字段会以空格分隔,因为$1,$3之间有一个逗号。逗号比较特殊,它映射为另一个内部变量,称为输出字段分隔符OFS,OFS默认为空格
- awk处理完一行后, 将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程将持续到所有行处理完毕
7、awk进阶使用
格式化的输出print和printf
print函数 类似echo
[root@fl Shell]# date | awk '{print "Month: "$2 "\nYear: "$NF}'
Month: Feb
Year: 2023printf函数 类似echo -n
[root@fl Shell]# awk -F: 'NR==1,NR==3{printf "%-15s %-10s %-15s\n",$1,$2,$3}' /etc/passwd
root x 0
bin x 1
daemon x 2 %s 字符类型 strings
%d 数值类型
- 表示左对齐,默认是右对齐
%-15s 表示向左对齐15个字符,如果不够,用空格填充
printf默认不会在行尾自动换行,需要我们手动加上\n
awk变量定义
[root@fl Shell]# awk -v NUM=3 -F: 'NR==1{print NUM}' /etc/passwd
3
[root@fl Shell]# awk -v NUM=3 -F: 'NR==1{print $NUM}' /etc/passwd
0[root@fl Shell]# awk -v num=1 'BEGIN{print num}'
1
[root@fl Shell]# awk -v num=1 'BEGIN{print $num}'注意:
awk中调用定义的变量不需要加$,因为$+数字表示特定分隔符分割后的某一列
awk中BEGIN…END使用
BEGIN:表示在程序开始之前执行
END:表示所有文件处理完后执行
用法:‘BEGIN{开始处理之前};{处理中};END{处理结束后}’
案例1:打印最后一列和倒数第二列(登录shell和家目录)
[root@fl Shell]# awk -F: 'BEGIN{printf "Login_shell\tLogin_home\n********************\n"};{printf $NF"\t"$(NF-1)"\n"};END{printf "*******************\n"}' 1.txt
Login_shell Login_home
********************
/bin/bash /root
/sbin/nologin /bin
/sbin/nologin /sbin
/sbin/nologin /var/adm
/sbin/nologin /var/spool/lpd
/bin/sync /sbin
/sbin/shutdown /sbin
/sbin/halt /sbin
/sbin/nologin /var/spool/mail
/sbin/nologin /root
/bin/bash /home/fl
/bin/bash /home/yunwei
/bin/bash /home/user1
*******************
案例2:打印/etc/passwd里的用户名、家目录以及登录shell
[root@fl Shell]# awk -F: 'BEGIN{OFS="\t\t";print "u_name\t\th_dir\t\tshell\n********************"};{printf "%-20s %-20s %-20s\n",$1,$(NF-1),$NF};END{print "********************"}' 1.txt
u_name h_dir shell
********************
root /root /bin/bash
bin /bin /sbin/nologin
daemon /sbin /sbin/nologin
adm /var/adm /sbin/nologin
lp /var/spool/lpd /sbin/nologin
sync /sbin /bin/sync
shutdown /sbin /sbin/shutdown
halt /sbin /sbin/halt
mail /var/spool/mail /sbin/nologin
operator /root /sbin/nologin
fl /home/fl /bin/bash
yunwei /home/yunwei /bin/bash
user1 /home/user1 /bin/bash
********************
awk和正则的综合运用
这里只写了之前没有出现过的正则符号
| 运算符 | 说明 |
|---|---|
| ~ | 匹配 |
| !~ | 不匹配 |
案例
awk 'NR==1,/^lp/{print $0}' 1.txt #打印从第一行开始,到以lp开头的行中间所有的行,闭区间awk '/^lp/,NR==10{print $0}' 1.txt #打印以lp开头的行,到第10行中间所有的行,闭区间awk '/^root/ || /^lp/{print $0}' 1.txt #打印以root开头或者以lp开头的行awk 'NR>=1 && NR <=5 && $0 ~ /bash$/{print $0}' 1.txt #打印1-5行中以bash结尾的行
案例3:打印IP地址
方法1:
[root@fl Shell]# ifconfig eth0 | awk 'NR==2{print $0}' | awk -F[' ']+ '{print $3}'
192.168.0.207方法2:
[root@fl Shell]# ifconfig eth0 | grep -w 'inet' | awk -F[' ']+ '{print $3}'
192.168.0.207方法3:
[root@fl Shell]# ifconfig eth0 | awk -F"[ ]+" '/inet/{print $3}' | awk 'NR==1{print $0}'
192.168.0.207
8、awk脚本编程
流程控制语句
if结构
格式:
awk 选项 '正则,地址定位{awk语句}' 文件名
{ if(表达式) {语句1;语句2;...}}awk -F: '{if($3>=500 && $3<=60000) {print $1,$3} }' /etc/passwd[root@fl Shell]# awk -F: '{if($3==0) {print $1"是管理员"} }' /etc/passwd
root是管理员[root@fl Shell]# awk -F: 'BEGIN{if($(id -u)==0) {print "当前用户是admin"}}'
当前用户是admin
if…else结构
格式:
{if(表达式) {语句1;语句2;...} else {语句1;语句2;...}}[root@fl Shell]# awk -F: 'NR==1,NR==3{if($3==0) {print $1"是管理员"} else {print $1"不是管理员"}}' /etc/passwd
root是管理员
bin不是管理员
daemon不是管理员[root@fl Shell]# awk -F: 'BEGIN{if($(id -u)!=0) {print "当前用户不是admin"} else {print "当前用户是admin"}}'
当前用户是admin
if…else if…eles结构
格式:
{if(表达式1) {语句1;语句2;...} else if(表达式2) {语句1;语句2;...} else {语句1;语句2;...}}[root@fl Shell]# awk -F: '{if($3==0) {print $1"是管理员"} else if($3>=1 && $3<=499 || $3==65534) {print $1"是系统 用户"} else {print $1"是普通用户"}}' 1.txt
root是管理员
bin是系统用户
daemon是系统用户
adm是系统用户
lp是系统用户
sync是系统用户
shutdown是系统用户
halt是系统用户
mail是系统用户
operator是系统用户
fl是普通用户
yunwei是普通用户
user1是普通用户[root@fl Shell]# awk -F: '{if($3==0) {i++} else if($3>=1 && $3<=499 || $3==65534) {j++} else {k++}};END{print "管 理员的个数为:"i"\n系统用户的个数为:"j"\n普通用户的个数为"k}' 1.txt
管理员的个数为:1
系统用户的个数为:9
普通用户的个数为3
循环语句
打印1-5
awk 'BEGIN{for(i=1;i<=5;i++) {print i}}'
awk 'BEGIN{i=1;while(i<=5) {print i; i++}}'打印1-10中的奇数
awk 'BEGIN{for(i=1;i<=10;i+=2) {print i}}'
awk 'BEGIN{i=1;while(i<=10) {print i; i+=2}}'计算1-5的和
awk 'BEGIN{for(i=1;i<=5;i++) {sum+=i};{print sum}}'
awk 'BEGIN{i=1;while(i<=5) {sum+=i;i++};{print sum}}'[root@fl Shell]# awk 'BEGIN{for(i=1;i<=5;i++) {for(j=1;j<=i;j++) {printf j};{print}}}'
1
12
123
1234
12345
8.1 案例
统计系统中各个类型的shell
[root@fl Shell]# awk -F: '{shells[$NF]++};END{for(i in shells) {print i"\t"shells[i]}}' /etc/passwd
/bin/sync 1
/bin/bash 4
/sbin/nologin 17
/sbin/halt 1
/sbin/shutdown 1
统计该服务器的所有访问状态
[root@fl Shell]# netstat -napt | grep '^tcp' | awk -F'[ ]+' '{states[$6]++};END{for(i in states) {print i":"states[i]}}'
LISTEN:5
ESTABLISHED:9
统计访问网站的每个IP的数量
ss -antp | grep 80 | awk -F: '!/LISTEN/{ip_count[$(NF-1)]++};END{for(i in ip_count) {print i":"ip_count[i]}}' | sort -k2 -rn | head
相关文章:
sed和awk
文章目录1、sed的简单介绍2、sed的使用方法2.1 命令行格式2.2 案例2.3 sed结合正则使用2.4 脚本格式3、awk的简单介绍4、awk的使用方法4.1 命令行模式4.2 脚本模式5、awk内部相关变量5.1 案例6、awk工作原理7、awk进阶使用8、awk脚本编程8.1 案例1、sed的简单介绍 sed是流编辑…...
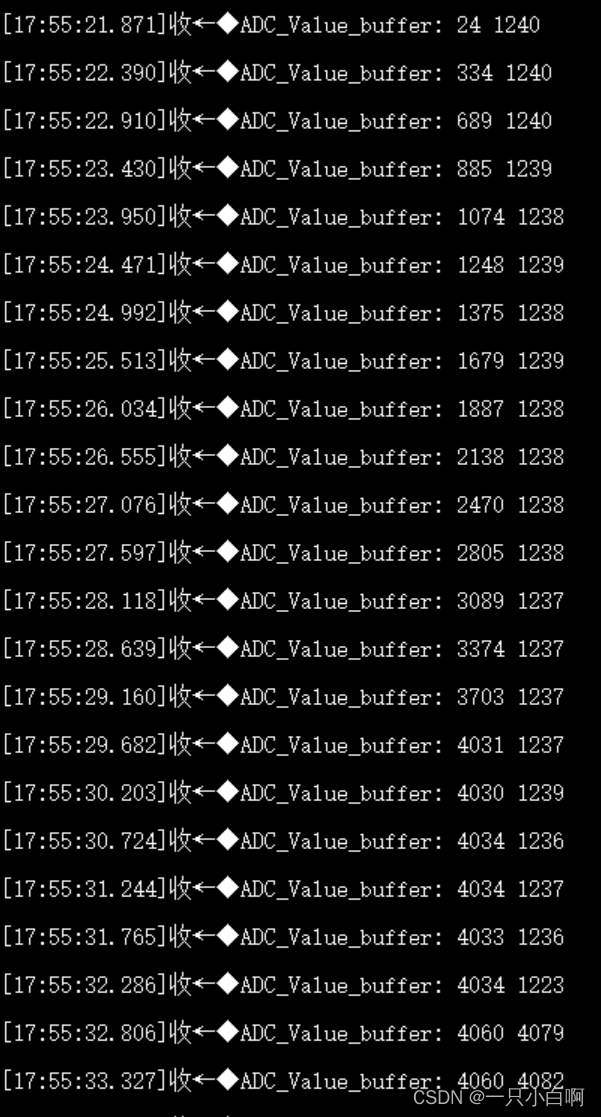
使用STM32 CUBE IDE配置STM32F7 用DMA传输多通道ADC数据
我的使用环境: 硬件:STM32F767ZGT6、串口1、ADC1、16MHz晶振、216MHz主频 软件:STM32 CUBE IDE 优点:不用定时触发采样,ADC数据是不停的实时更新,ADC数据的更新频率根据采样时钟和采样周期决定,…...
linux 学习(持续更新)
一:初识linux 新装操作环境: mac intel电脑 CentOS系统版本:CentOS-8.1.1911 在这里解释一下[chenllocalhost /]$这句话的含义: chenl是用户名,也就是你自己起的名字。 是分割的符号 localhost是主机名,也…...

Nacos【一】Nacos集群部署配置
系列文章目录 暂无 文章目录系列文章目录前言一、Nacos集群架构1.ip直连2. SLB3. 域名-SLB二、集群部署准备2.1 机器准备2.2 Nginx安装配置1.安装2.负载均衡配置2.3 nacos安装配置1.nacos节点2. MySQL准备1.Docker安装MySQL2. nacos对应数据库初始化三、 集群启动1.失败原因汇…...

“亚洲一号”也能上市?REITs背后的物流设施风起云涌
京东最近发生了两件大事,两件都与物流基础设施有关。 一件是2月8日,嘉实京东仓储物流封闭式基础设施证券投资基金(简称“京东仓储REIT”)正式登陆上交所,投资者获得了机会,去分享京东三处物流园区的收益&a…...

2023养老展,CBIAIE第十届中国北京国际老年产业博览会
8月招商季,第十届中国(北京)国际老年产业博览会再次盛大举办; CBIAIE北京国际老年产业博览会位域优势: ——北京,中国首都,世界一线城市,地处中国北部、华北平原北部,东…...
【Android -- 每日一问】现在 Android 怎么学?学什么?
不管在任何行业,任何岗位,初级技术人才总是供大于求;不管任何行业、岗位,技术过硬的也都是非常吃香的! 这几年 Android 新技术的迭代明显加速了,有来自外部跨平台新物种的冲击,有去 Java 化的商…...
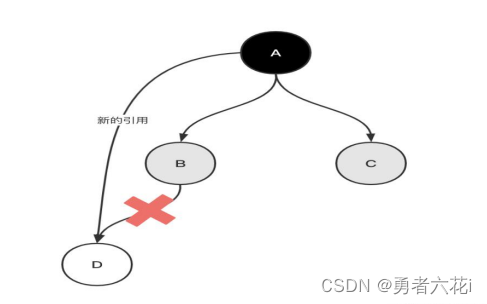
JVM垃圾回收
概述 Java是支持自动垃圾回收的,有些语言不支持自动垃圾回收(C)自动垃圾回收不是Java的首创 垃圾是什么? 在 JVM 中垃圾是指在运行程序中没有任何指针指向的对象,这个对象就是需要被回收的垃圾。 哪些区域需要回收…...

clickhouse集群安装
单机安装 yum install yum-utilsrpm --import https://repo.clickhouse.com/CLICKHOUSE-KEY.GPGyum-config-manager --add-repo https://repo.clickhouse.com/rpm/clickhouse.reposudo yum install clickhouse-server clickhouse-client 配置文件 vim /etc/clickhouse-serve…...

Zookeeper入门
Zookeeper入门概述特点结构应用场景选举机制节点信息监听原理写数据原理分布式锁概述 Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。 Zookeeper 从设计模式的角度来开:是一个基于观察者模式设计的分布式服务管理框架…...

JavaScript
BOM核心对象docunmentBOM核心对象windowBOM包含着DOMF12即可打开浏览器控制台navigator(浏览器版本)、history(浏览器历史记录),location(地址信息)、screen(屏幕相关)JS输出形式:浏览器输出:wi…...

.gitignore 常用忽略规则
.gitignore常用忽略语法 1、空格不匹配任意文件,可作为分隔符,可用反斜杠转义 2、以井号#开头的文件标识注释,可以使用反斜杠进行转义 3、以斜杠/开头表示目录 4、以星号*通配多个字符 5、以问号?通配单个字符 6、以方括号[]包含单个字符的…...

Vue路由 —— vue-router
在上一篇内容讲到关于单页面组件的内容,同时也附上补充讲了关于单页面(SPA)和多页面(MPA)之间的优缺点,在本篇目当中就要来讲这个路由(vue-router),通过路由来实现页面的…...

Java Jackson TypeReference获取泛型类型信息【泛型】
Jackson是一个比较流行的Json序列化和反序列化框架。本文以Jackson为例介绍TypeReference实现涉及泛型的反序列化,及TyperReference的实现原理。对于获取泛型类型信息的场景,TypeReference是一个可以参考的通用解决方案。 Jackson ObjectMapper的readVa…...
)
Python 核心笔记(二)
特殊规则及特殊字符:#号(#) : 注释换行(\n) : 换行反斜线(\) : 继续上一行分号(;) : 两个语句连在一行冒号(:) : 将代码块的头和体分开不同的缩进…...
Hadoop集群搭建
文章目录一、运行环境配置(所有节点)1、基础配置2、配置Host二、依赖软件安装(101节点)1、安装JDK2、安装Hadoop(root)3、Hadoop目录结构三、本地运行模式(官方WordCount)1、简介2、本地运行模式(官方WordCount)四、完全分布式运行…...

每个前端都应该掌握的7个代码优化的小技巧
本文将介绍7种JavaScript的优化技巧,这些技巧可以帮助你更好的写出简洁优雅的代码。 1. 字符串的自动匹配(Array.includes) 在写代码时我们经常会遇到这样的需求,我们需要检查某个字符串是否是符合我们的规定的字符串之一。最常…...

金三银四丨黑蛋老师带你剖析-二进制漏洞
作者:黑蛋二进制漏洞岗上篇文章我们初步了解了一下简历投递方式以及二进制方向相关逆向岗位的要求,今天我们就来看看二进制漏洞相关的岗位,当然,漏洞岗位除了分不同平台,也有漏洞挖掘岗和漏洞分析利用岗。同样…...

pgsql-用户角色组角色创建和维护
pgsql-用户&角色&组角色创建和维护 环境 win10pgsql 14.2 相关文档 PostgreSQL 14.1 手册 create 语法 grant 授权语法 revoke 撤回语法 alter 更新语法 用户、角色、组角色概念和区别 早期版本(8.1之前)中用户、组、角色是不同的概念&#…...
算法与数据结构理解
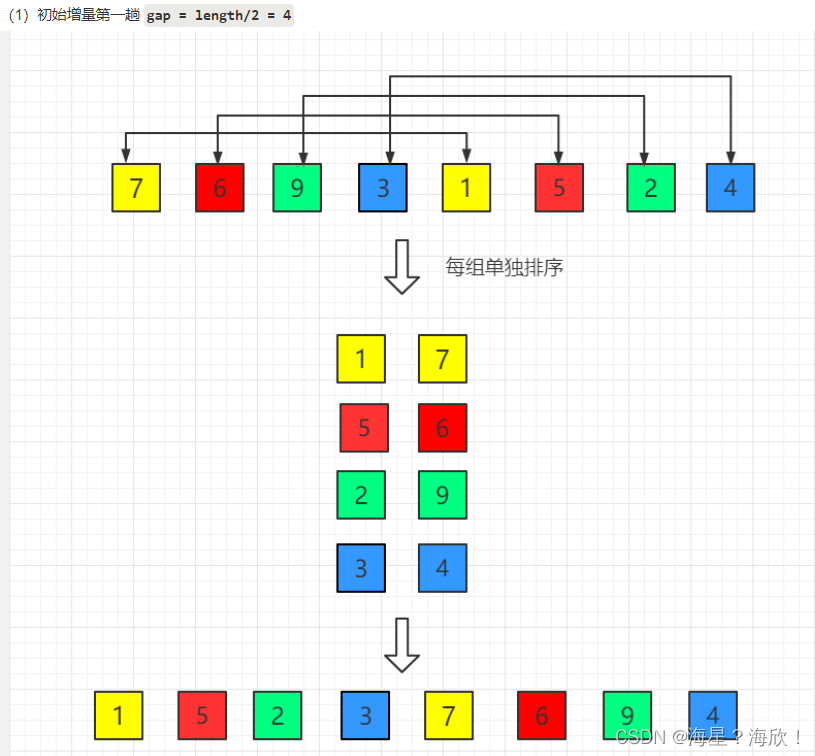
目录1、数据结构与算法1.1 定义1.2 常见数据结构1.3 常用算法2、插入排序3、希尔排序4、归并排序1、数据结构与算法 1.1 定义 数据结构:是计算机中存储、组织数据的方式。具有一定逻辑关系,应用某种存储结构,并且封装了相应操作的数据元素集…...

Phi-3-vision-128k-instruct 生成效果鉴赏:复杂信息图表的自动化摘要
Phi-3-vision-128k-instruct 生成效果鉴赏:复杂信息图表的自动化摘要 1. 当AI遇见数据图表:一场视觉理解的革命 想象一下这样的场景:你面前摊开一份50页的上市公司年报,里面充斥着各种复杂的柱状图、折线图和饼图。作为分析师&a…...

终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩
终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩 【免费下载链接】Anime4K A High-Quality Real Time Upscaler for Anime Video 项目地址: https://gitcode.com/gh_mirrors/an/Anime4K Anime4K是一款高性能实时动漫视频超分辨率工具,能…...

图图的嗨丝造相-Z-Image-Turbo作品集:多场景渔网袜AI图像生成,每一张都惊艳
图图的嗨丝造相-Z-Image-Turbo作品集:多场景渔网袜AI图像生成,每一张都惊艳 1. 模型核心能力展示 1.1 专业领域定位 图图的嗨丝造相-Z-Image-Turbo是专精于大网渔网袜图像生成的AI模型,基于Z-Image-Turbo框架开发,通过LoRA技术…...

实测Nanbeige 4.1-3B WebUI:浅灰蓝波点背景+呼吸阴影效果惊艳
实测Nanbeige 4.1-3B WebUI:浅灰蓝波点背景呼吸阴影效果惊艳 1. 极简美学与功能设计的完美融合 第一次打开这个WebUI时,最直观的感受就是它完全颠覆了我对本地大模型界面的刻板印象。传统的部署方案往往只关注功能实现,界面设计几乎都是千篇…...

掌握Blender 3MF插件:5大核心场景的全流程解决方案
掌握Blender 3MF插件:5大核心场景的全流程解决方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender 3MF插件作为连接3D建模与3D打印的关键桥梁&#x…...

Harbor容器镜像仓库详解:从入门到实践
随着容器技术的快速发展,企业对于容器镜像管理的需求日益增长。Harbor作为云原生计算基金会(CNCF)的毕业项目,为企业提供了安全可靠的容器镜像仓库解决方案。本文将全面介绍Harbor的核心功能、部署方法以及实际应用场景。 Harbor概述 Harbor是一个开源的…...

2026年大数据专业数据分析学习指南
一、核心技术与工具2026年主流大数据技术栈(如Spark、Flink、Hadoop生态) 实时数据处理与批处理技术对比 云原生数据分析平台(AWS/GCP/Azure解决方案) 机器学习与深度学习在数据分析中的融合应用二、数学与统计基础概率论与数理统…...

AITINKR_JSON_FIELDS:面向MCU的零碎片JSON字段管理库
1. AITINKR_JSON_FIELDS 库深度解析:面向资源受限 IoT 设备的动态 JSON 字段管理方案在嵌入式物联网设备开发中,JSON 已成为事实上的数据交换标准。从传感器数据上报、OTA 配置下发,到设备状态同步与远程控制指令解析,JSON 的轻量…...

XPT2046触摸驱动设计与车载嵌入式集成实践
1. XPT2046 触摸控制器驱动技术解析与嵌入式集成实践XPT2046 是一款广泛应用于嵌入式人机交互系统的 12 位逐次逼近型(SAR)模数转换器(ADC),专为四线/五线电阻式触摸屏设计。其核心功能并非独立显示驱动,而…...

深入Linux内核:RDMA Verbs API的object/method/attr三层模型设计与实现解析
深入Linux内核:RDMA Verbs API的object/method/attr三层模型设计与实现解析 在当今高性能计算和分布式存储领域,远程直接内存访问(RDMA)技术因其极低的延迟和高吞吐量而备受青睐。作为RDMA技术的核心接口,Verbs API的设计哲学直接影响着整个生…...