elasticsearch 之 mapping 映射
当我们往 es 中插入数据时,若索引不存在则会自动创建,mapping 使用默认的;但是有时默认的映射关系不能满足我们的要求,我们可以自定义
mapping 映射关系。
mapping 即索引结构,可以看做是数据库中的表结构,包含字段名、字段类型、倒排序索引相关设置。
映射关系
每个索引都有一个映射类型,决定了文档将如何被索引,索引类型有:
- 元字段
meta-fields:用于自定义如何处理文档关联的元数据,如:_index、_type、_source等字段 - 字段或属性
field or properties:映射类型包含与文档相关的字段或者属性的列表
字段的数据类型
- 字符串类型:
text或者keyword - 数值类型:
integer、long、short、byte、double、float等 - 布尔类型:
boolean - 日期类型:
date - 二进制类型:
binary - 范围类型:
integer_range、double_range、date_range、float_range - 数组类型:
array - 对象类型:
object - 嵌套类型:
nested object - 地理位置数据类型:
geo_point、geo_shape - 专用类型:
ip、join、token count、percolator等
keyword 类型不会分词,text 会分词,因此 keyword 比 text 更节省空间,效率也更高。
自定义 mapping
PUT mapping_test
{"mappings": {"test1": {"properties": {"name": {"type": "text"},"age": {"type": "long"}}}}
}
参数
mapping_test:索引名mappings:关键字test1:_type名称properties:关键字name、age:字段名
以上会创建一个新的索引 mapping_test,其中 mapping 信息是我们自定义的,若返回以下信息,表示创建成功:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "mapping_test"
}
查看 mapping:
GET mapping_test/_mapping
查询结果:
{"mapping_test" : {"mappings" : {"test1" : {"properties" : {"age" : {"type" : "long"},"name" : {"type" : "text"}}}}}
}
mapping 中的参数
analyzer
字段分词器,默认为 standard,可以指定第三方的分词器:
PUT mapping_test
{"mappings": {"test1": {"properties": {"name": {"type": "text","analyzer": "ik_smart" # 使用 ik 中文分词器},}}}
}
boost
查询时提高字段的相关性算分,得分越高在查询结果集中排名越靠前,boost 可以指定其分数(权重),默认 1.0:
PUT mapping_test
{"mappings": {"test1": {"properties": {"name": {"type": "text","boost": 2},}}}
}
copy_to
该属性将多个字段的值拷贝到指定字段,然后可以将其作为单个字段查询,以下将 first_name、last_name 的值拷贝到 full_name 字段中:
# 创建索引
PUT my_index
{"mappings": {"doc": {"properties": {"first_name": {"type": "text","copy_to": "full_name"},"last_name": {"type": "text","copy_to": "full_name"},"full_name": {"type": "text"}}}}
}# 查询数据
PUT my_index/doc/1
{"first_name": "John","last_name": "Smith"
}
查询:
GET my_index/doc/_search
{"query": {"match": {"full_name": {"query": "John"}}}
}
查询结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.2876821,"hits" : [{"_index" : "my_index","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"first_name" : "John","last_name" : "Smith"}}]}
}
dynamic
创建索引时,索引中字段是固定的,该属性可以决定是否允许新增字段,有三种状态:
true:允许新增,es会自动添加映射关系false:允许新增,不会自动添加映射关系,但是不能作为主查询查询(查询不到具体的新增字段)strict:严格模式,不可以新增字段,新增就报错,需要重新设计索引
1、dynamic 为 true 时
PUT s1
{"mappings": {"doc": {"dynamic": true,"properties": {"name": {"type": "text"}}}}
}# 插入数据,新增了一个 age 字段
PUT s1/doc/1
{"name": "rose","age": 19
}# 可以使用 age 作为主查询条件查询
GET s1/doc/_search
{"query": {"match": {"age": 19}}
}
创建索引、插入数据,查询都没有问题
2、dynamic为 false 时
PUT s2
{"mappings": {"doc": {"dynamic": false,"properties": {"name": {"type": "text"}}}}
}# 插入数据,新增了一个 age 字段
PUT s2/doc/1
{"name": "rose","age": 19
}# 使用 age 字段作为主条件查询
GET s2/doc/_search
{"query": {"match": {"age": 19}}
}
查询结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 0,"max_score" : null,"hits" : [ ]}
}
创建索引、插入数据,新增字段作为主条件查询查询为空,查询不到数据。
3、dynamic 为 strict 时:
PUT s3
{"mappings": {"doc": {"dynamic": "strict","properties": {"name": {"type": "text"}}}}
}PUT s3/doc/1
{"name": "rose","age": 19
}
严格模式下,禁止插入,插入就出错:
{"error": {"root_cause": [{"type": "strict_dynamic_mapping_exception","reason": "mapping set to strict, dynamic introduction of [age] within [doc] is not allowed"}],"type": "strict_dynamic_mapping_exception","reason": "mapping set to strict, dynamic introduction of [age] within [doc] is not allowed"},"status": 400
}
index
index 属性默认为 true,若设置为 false,那么 es 不会为该属性创建索引,即不能当前主条件查询,查询会报错:
PUT s5
{"mappings": {"doc": {"properties": {"t1": {"type": "text","index": true},"t2": {"type": "text","index": false}}}}
}PUT s5/doc/1
{"t1": "论母猪的产前保养","t2": "论母猪的产后护理"
}GET s5/doc/_search
{"query": {"match": {"t1": "母猪"}}
}# t2 字段 index 设置为 false,作为主条件查询
GET s5/doc/_search
{"query": {"match": {"t2": "母猪"}}
}
t2 字段 index 设置为 false,作为主条件查询时会报错:
{"error": {"root_cause": [{"type": "query_shard_exception","reason": "failed to create query: {\n \"match\" : {\n \"t2\" : {\n \"query\" : \"母猪\",\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}","index_uuid": "jTRViM6SSRSERtEcSTSOFQ","index": "s5"}],"type": "search_phase_execution_exception","reason": "all shards failed","phase": "query","grouped": true,"failed_shards": [{"shard": 0,"index": "s5","node": "d8Q4szIXR8KlHOram-TICA","reason": {"type": "query_shard_exception","reason": "failed to create query: {\n \"match\" : {\n \"t2\" : {\n \"query\" : \"母猪\",\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}","index_uuid": "jTRViM6SSRSERtEcSTSOFQ","index": "s5","caused_by": {"type": "illegal_argument_exception","reason": "Cannot search on field [t2] since it is not indexed."}}}]},"status": 400
}
ignore_above
超过 ignore_above 设置的字符串将不会被索引或存储,对于字符串数组,ignore_above 将分别应用于每个数组元素,并且字符串元素 ignore_above 将不会被索引或存储。
PUT s6
{"mappings": {"doc": {"properties": {"t1": {"type": "keyword","ignore_above": 10}}}}
}PUT s6/doc/1
{"t1": "123456"
}# 超过 ignore_above 10
PUT s6/doc/2
{"t1": "1234567891011121314151617181920"
}# 查询时为空
GET s6/doc/_search
{"query": {"match": {"t1": "1234567891011121314151617181920"}}
}
查询结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 0,"max_score" : null,"hits" : [ ]}
}
注意:字段启用
ignore_above时,字段类型不能为text,超过ignore_above,不会被索引,即查询不到具体数据。
index_options
控制倒排序索引记录的内容,可选项:
docs:只记录文档idfreqs:记录文档id、单词频率positions:记录文档id、词频、单词位置offsets:记录文档id、词频、单词位置、偏移量
其中 text 类型字段默认的 index_options 为 positions,其余类型默认为 docs,同时记录的内容越多,占用的空间也越大。
fields
允许为字段设置子字段,可以有多个,如检索人的中文姓名和拼音姓名,把 name_pinyin 这个字段挂在 name_cn 字段下:
PUT s7
{"mappings": {"doc": {"properties": {"name_cn": {"type": "text","fields": {"name_pinyin": {"type": "keyword"}}}}}}
}PUT s7/doc/1
{"name_cn": "张三","name_pinyin": "zhangsan"
}GET s7/doc/_search
{"query": {"match": {"name_pinyin": "zhangsan"}}
}
null_value
当字段遇到 null 值时的处理策略(字段为 null 时不会被搜索的,text 类型的字段不能使用该属性),设置该值后可以用你设置的值替换null 值,这点可类比 mysql 中的 "default" 设置默认值。
PUT s8
{"mappings": {"doc": {"properties": {"name_cn": {"type": "keyword","null_value": "张三"}}}}
}
search_analyzer
指定搜索时分词器,这一要注意,在 es 之分词 中说到过,分词的两个时机是索引时分词和搜索时分词,一般情况下使用索引时分词即可,所以如果你同时设置了两个,那么这两个分词器最好保持一致,不然可能出现搜索匹配不到数据的问题。
PUT s10
{"mappings": {"doc": {"properties": {"name": {"type": "text","analyzer": "standard","search_analyzer": "standard"}}}}
}
相关文章:

elasticsearch 之 mapping 映射
当我们往 es 中插入数据时,若索引不存在则会自动创建,mapping 使用默认的;但是有时默认的映射关系不能满足我们的要求,我们可以自定义 mapping 映射关系。 mapping 即索引结构,可以看做是数据库中的表结构,…...
)
2023年rabbitMq面试题汇总2(5道)
一、如何确保消息接收⽅消费了消息?接收⽅消息确认机制:消费者接收每⼀条消息后都必须进⾏确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。这⾥并没有⽤到超时…...
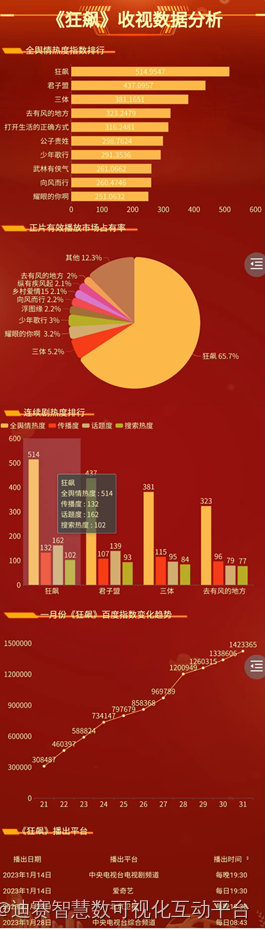
电视剧《狂飙》数据分析,正片有效播放市场占有率达65.7%
哈喽大家好,春节已经过去了,朋友们也都陆陆续续开工了,小编在这里祝大家开工大吉!春节期间,一大批电视剧和网剧上映播出,其中电视剧《狂飙》以不可阻挡之势成功成为“开年剧王”。这里小编整理了一些《狂飙…...

cas单点登录后重定向次数过多问题以及调试cas-dot-net-client
问题描述: web项目应用cas作为单点登录站点,登录后无法打开WEB项目的页面,报错,说重定向次数过多。 老实说,这种问题,以前遇到过不少,是我这种半桶水程序员的噩梦。解决这种问题,不…...
【监控】Prometheus(普罗米修斯)监控概述
文章目录一、监控系统概论二、基础资源监控2.1、网络监控2.2、存储监控2.3、服务器监控2.4、中间件监控2.5、应用程序监控(APM)三、Prometheus 简介3.1、什么是 Prometheus3.2、优点3.3、组件3.4、架构3.5、适用于什么场景3.6、不适合什么场景四、数据模…...
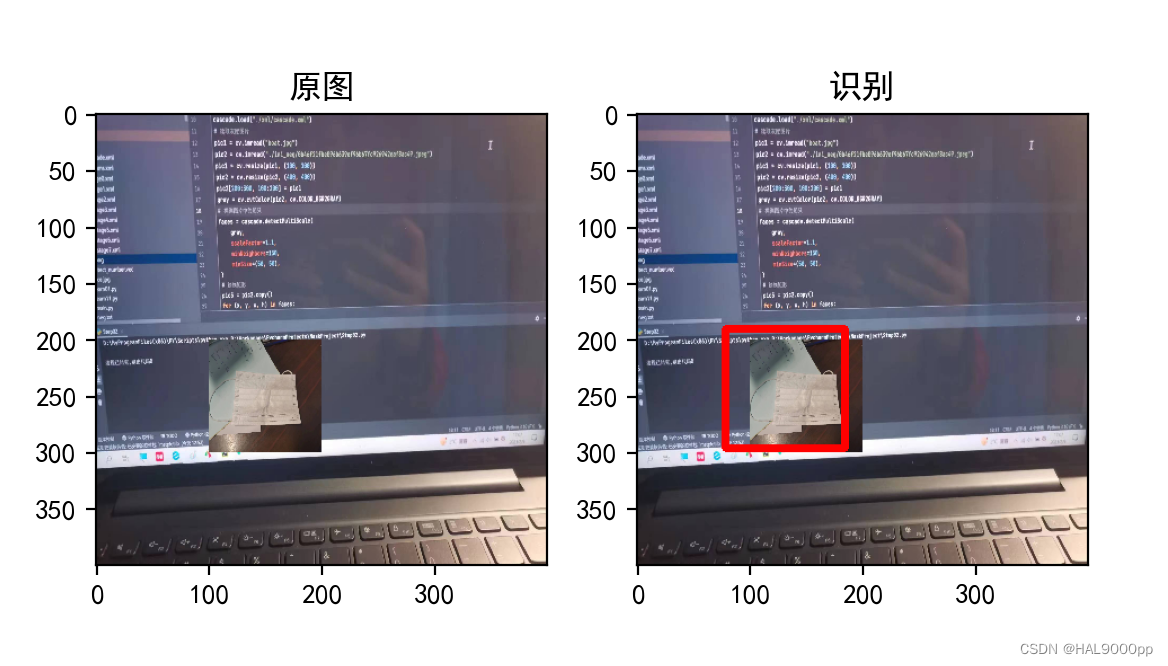
opencv+python物体检测【03-模仿学习】
仿照练习:原文链接 步骤一:准备图片 正样本集:正样本集为包含“识别物体”的灰度图,一般大于等于2000张,尺寸不能太大,尺寸太大会导致训练时间过长。 负样本集:负样本集为不含“识别物体”的…...

计算机科学基础知识第二节讲义
课程链接 运行环境:WSL Ubuntu OMZ终端 PS:看到老师终端具有高亮和自动补全功能,我连夜肝出oh-my-zsh安装教程,实现了此功能。 这节课主要讲变量的语法、控制流程、shell功能等内容。 修改终端用户名,输入密码后重启…...

openssl genrsa 命令详解
文章目录一、openssl genrsa 命令介绍二、openssl genrsa 命令的语法及选项三、实例1、生成512位的 RSA 秘钥,输出到屏幕。2、生成512位 RSA 私钥,输出到指定的文件 genrsa.txt3、生成 1024 位 RSA 秘钥,采用 des 算法加密,加密密…...
、C99、C11、C17、C2X)
C语言标准 —— C89(C90)、C99、C11、C17、C2X
C语言主要的三个标准:C89(C90)、C99、C11、K&R C 指的是 C 语言的原始版本。1978年,C 语言的发明者丹尼斯里奇(Dennis Ritchie)和布莱恩柯林(Brian Kernighan)合写了一本…...

基于Java+Dubbo设计的智能公交查询系统
一、项目背景 随着经济的飞速发展,人们的生活质量有了较大的提高,城市居民的出行变得越来越频繁,城市交通也面临越来越多的挑战。城市公共交通具有客流量大、成本低、效率高、节约资源等优势,因此,如何大力发展公交产业,鼓励人们乘坐公交出行,进而改善交通状况,是一个值得思考…...

go语言的并发编程
并发编程是 Go语言的一个重要特性,而 go语言也是基于此而设计出来的。 本文将会介绍如何使用go-gc中的“runtime”方法实现 go语言中的并发编程。 在之前的文章中,我们已经对 runtime方法进行了详细介绍,这次文章将对 runtime方法进行深入分析,并讲解如何在go-gc中使用该方…...

亚马逊要求UL94防火测试阻燃测试标准及项目
UL94认证是什么?分几个等级?是如何表示各等级?带电的产品上架亚马逊都需要相关的UL报告,需要有ISO 17025资质的实验室出具的测试报告才能正常销售和恢复链接,UL94防火测试则是其中一项。UL94试验共有五种:1.B级的水平燃烧试验2.…...

ClickHouse 合并树表引擎 MergeTree 原理分析
目录 前言 MergeTree 存储 MergeTree思想 MergeTree存储结构 MergeTree查询 索引检索 数据Sampling 数据扫描 建表 数据存储...
用YOLOv8推荐的Roboflow工具来训练自己的数据集
YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本,相较于之前的版本,YOLOv8可以更快速有效地识别和定位图像中的物体,以及更准确地分类它们。 作为一种深度学习技术,YOLOv8需要大量的训练数据来实现最佳性能。…...
三层交换机【实验】
目录 1、要求: 2、拓扑: 3、创建vlan和端口定义并划入vlan: 4、创建以太网中继Eth-Trunk使sw1和sw2的相互冗余并且不浪费链路: 5、使用mstp定义组和对应的根: 6、配置网关冗余: 7、核心层的路由的IP配…...
)
Anolis 8.6 部署 Kafka 3.3.1 安装和测试(二)
动态初始化Kafka消费者实例一.Kafka 环境搭建二.动态初始化消费者1.Topic定义2.方法处理器工厂3.参数解析器(Copy SpringBoot 源码)4.消费接口和消费实现5.动态初始化1.关键类简介2.动态初始化实现一.Kafka 环境搭建 参考:Kafka搭建和测试 …...

sed和awk
文章目录1、sed的简单介绍2、sed的使用方法2.1 命令行格式2.2 案例2.3 sed结合正则使用2.4 脚本格式3、awk的简单介绍4、awk的使用方法4.1 命令行模式4.2 脚本模式5、awk内部相关变量5.1 案例6、awk工作原理7、awk进阶使用8、awk脚本编程8.1 案例1、sed的简单介绍 sed是流编辑…...
使用STM32 CUBE IDE配置STM32F7 用DMA传输多通道ADC数据
我的使用环境: 硬件:STM32F767ZGT6、串口1、ADC1、16MHz晶振、216MHz主频 软件:STM32 CUBE IDE 优点:不用定时触发采样,ADC数据是不停的实时更新,ADC数据的更新频率根据采样时钟和采样周期决定,…...
linux 学习(持续更新)
一:初识linux 新装操作环境: mac intel电脑 CentOS系统版本:CentOS-8.1.1911 在这里解释一下[chenllocalhost /]$这句话的含义: chenl是用户名,也就是你自己起的名字。 是分割的符号 localhost是主机名,也…...

Nacos【一】Nacos集群部署配置
系列文章目录 暂无 文章目录系列文章目录前言一、Nacos集群架构1.ip直连2. SLB3. 域名-SLB二、集群部署准备2.1 机器准备2.2 Nginx安装配置1.安装2.负载均衡配置2.3 nacos安装配置1.nacos节点2. MySQL准备1.Docker安装MySQL2. nacos对应数据库初始化三、 集群启动1.失败原因汇…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...