我用python疯狂爬取公司数据

我是半路从一个纯小白学过来的,学习途中也掉过许多坑,在这里建议新手要先把基础打扎实,然后再去学习自己需要的内容,不要想着全部学完再用,那样你是永远学不完的,用哪方面就学习哪方面的内容,不要贪多哟。
我当初想到学python是为了能在工作中提升工作效率(另一个也是兴趣),还有就是python入门快。相信大多数小伙伴也是这个原因才学python的。
python的关键词很少,入门很简单,但是想要深入还是要去用心去研究的。同时还要有耐心,因为有些资料在查询的时候,网上给的答案很杂,你需要自己去筛选有用的信息,没有耐心是不行的,有时候为了弄明白一个功能如何实现,我可能要查找几个小时的资料并自己测试可行性,这是很费时间的。当然,你学会了以后对自己的好处也是很大的,下次再有类似的应用就简单的多了,可以举一反三的去实现。
那么python入门之后呢?要用到实处才行,有的公司的工作需要到网上去查找资料做分析,有的是找别人的资料(比如百度等),有的是自己公司的内部资料(比如我😁)。因为工作需要,我需要爬取公司的案件数据,并把数据整合起来保存成表格。因为我有一点python的底子,熟悉工作流程之后就开始着手写自己需要的功能,去把一些固定的、重复的工作交给python来做。
第一步:先找到所需要的网址URL
打开网站,按F12,打开开发者模式,找到所需要的网址、请求方法和headers信息

找到网址和请求方法后,就可以知道去哪里,用什么方法去获取数据了。
网址是我公司的系统网址,没有用户和密码是登录不上去的,这里只是做个展示
有需要的酱友可以找其它的网站爬取内容。我用的requests来爬取(本来想实现模拟登录来保存cooking,目前还没有研究明白,就略过了。)。
第二步:分析网址的变化
找到这两个信息之后就可以开始了,先把网址URL和headers(headers的作用是用来模拟浏览器信息的,要不会被反爬)保存上
url = 'http://api.smart-insight-service.com:40423/case_medical?a=paginate&_=1658047475149'
headers = {'Accept':'application/json, text/javascript, */*; q=0.01','Accept-Encoding':'gzip, deflate','Accept-Language':'zh-CN,zh;q=0.9','Authorization':'','Connection':'keep-alive','Host':'api.smart-insight-service.com:40423','Origin':'http://saas.smart-insight-service.com:40423','Referer':'http://saas.smart-insight-service.com:40423/case/case_search/detail.html','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
Authorization为空是因为不能自动获取,需要手动粘贴过来,而且由于隐私原因我也不能粘贴过来。有这些信息其实就可以爬取网站的数据了,不过这个是默认的主页信息,还需要找到关键词来定位到自己需要的信息那里。比如我想找批次号为BJ-GGDE210421的批次信息,就要输入然后查询,对比一下两个URL的不同点(第一个是原网址,第二个是带有参数的网址)
url = 'http://api.smart-insight-service.com:40423/case_medical?a=paginate&_=1658047475149'
url = 'http://api.smart-insight-service.com:40423/case_medical?a=paginate&batch_no=BJ-GGDE210421&_=1658047475152'
看到区别了吗,就是a=XXX后面多了一个**&batch_no=BJ-GGDE210421**,这个是那个我要查找的批次。
第三步:开始获取数据
准备好之后就可以获取数据了,代码如下:
def 获取案件信息(url, headers):s = requests.Session()s.mount('http://', HTTPAdapter(max_retries=3))s.mount('https://', HTTPAdapter(max_retries=3))try:req = s.get(url=url, headers=headers, timeout=20)r = req.json()a = r.get('msg')if a == '请求成功':datas = r.get('data') # 案件列表要分离2次,案件详情分离1次。else:datas = aprint(a)except Exception as e:# 输出错误提示print(datetime.now())exstr = traceback.format_exc()print(f'exstr = {exstr}')print(f'e = {e}')datas = {}return datas
requests.Session() 这个功能不太清楚是做什么了🤣这就是不做注释的后果,各位新酱友要以我为戒,千万不要不写注释。(关于用中文,这是我个人的一个想法,对于英文不好的人,用中文来把一些有关联的地方替换掉,很容易就明白什么意思,有助于理解,不过不建议这么做,酱友们还是要按照大佬们的建议,规范的写代码,命名也规范命名。要是团队合作,规范是必须要遵守的。我这样只是单打独斗,自己用用还行,团队肯定不合适,我也需要去改。)
max_retries=3这个参数是重连次数,我的是重新连接3次,这个可以根据实际情况设置
timeout=20这个参数就是连接等待时长了,单位是秒,由于我们系统原因,我需要设置时间很长才行,要不会连接失败,这个也是视实际情况设置了。
获取到全部数据后,要用json() 这个函数转换成字典形式,这样利于提取数据。
第四步:定位数据字段
我现在需要这个批次下所有的案件号和案件数据,那我就要去知道在哪里去提取。同样F12打开,输入批次号查询,然后点击控制台。

左边的红框是我想要的信息内容,右边是要提取信息的地方,打开右边的红框

有以下几个字段:msg是请求状态,我上面的代码提取这个字段就是判断一下请求成功没有。status是状态码,200是请求成功。重点来了,data字段里才是我们需要的内容,打开看看

data里面有page字段,这个里面是页面信息(有需要页面信息了再从这里找),略过。
data里面还有个data字段,是个需要二次提取的地方,我上面的代码有注释,也是怕自己忘记

最后提取数据
再次点开data就出现了一个列表,里面就是我所需要的信息了,那么怎么提取出来呢?
def 获取案件信息(url, headers):s = requests.Session()s.mount('http://', HTTPAdapter(max_retries=3))s.mount('https://', HTTPAdapter(max_retries=3))try:req = s.get(url=url, headers=headers, timeout=20)r = req.json()a = r.get('msg')if a == '请求成功':datas = r.get('data') # 案件列表要分离2次,案件详情分离1次。else:datas = aprint(a)
这个函数里已经提取了一次,因为案件详情只要提取一次就行,所以这里只提取一次,如果需要提取两次的可以再提取一次,就像是获取字典的值一样方便dataset= r[‘data’][‘data’],这样就可以直接提取两次了
在这里说一下字典的 .get 这个用法,看过一些公众号,说这个好用,其实是看怎么用,我把我的字典获取值都改成 .get 了,然后就发现代码有点啰嗦了😂。如果你能确定获取的字典里必定会有这些内容的话,就直接a = dict[‘key’] 来提取值就行,除非是一些不确定的地方,用 .get 来提取会防止因为没有这个键导致程序出错而停止运行。
下面是把我需要的一些关键数据写成函数批量提取出来(提取成了字典,方便查找数据)
def 提取案件列表个案详情(x):if x:姓名 = x.get('name')批次号 = x.get('batch_no')案件号 = x.get('no')身份证号 = x.get('id_no')上传时间 = x.get('case_data').get('upload_time')回传时间 = x.get('case_data').get('send_time')案件状态 = x.get('case_status') # 案件的各种状态,可检查核查状态案件id = x.get('case_id')审核员 = x.get('user').get('nickname')理算状态 = x.get('adjuster_name')理算标识 = x.get('adjuster_status')身份证号 = x.get('id_no')核查状态 = x.get('check_name') # 和核查校验是一个核查校验 = x.get('is_check')data = {'姓名': 姓名,'批次号': 批次号,'案件号': 案件号,'身份证号': 身份证号,'上传时间': 上传时间,'回传时间': 回传时间,'案件状态': 案件状态,'案件id': 案件id,'审核员': 审核员,'核查状态': 核查状态,'理算状态': 理算状态,'理算标识': 理算标识,'身份证号': 身份证号,'核查校验': 核查校验}else:data = {}print('没有案件列表信息')return data
看看那么多 .get 有什么感想?我看着是有点别扭的,不过费了半天时间把所有函数都改了,就不动了,后面我重新写程序的时候就不这么写了
上面的代码就是把列表内所有的案件的信息都提取出来了,列表打开之后还是个字典的样式,直接找自己要的字段即可。

我框了几个字段,可以对照看看 这只是提取一条的数据,还要用for循环来获取列表里的全部内容,下面是个代码示例:
for x in datas:a = 提取案件列表个案详情(x)
这样我所需要的内容就全部提取出来存入字典里了,然后就是写入excel表格导出来了。
总结
看,其实爬虫就是这么简单,有时候直接获取后端数据即可。当然,我要学习的地方还很多。比如提取前端的数据,多协程获取数据等。
个人感悟:学习不是你学习了多少,而是你用上了多少,只有你用上的,才是有用的,所以学python不要想着我把这些都学完再写程序,那样是学习不好的,每天都会有大量的库更新,会有更好的库出现,你永远学不完,把自己能用上的学好就行,不是学的多就好。学以致用,就这样。
怎样快速掌握变现级爬虫?
很多人都表示,高阶的爬虫技术不好学,也找不到有价值的项目练手,每个人都在期待一套能快速进阶的速成方案。
想要快速学好爬虫,尤其是可以用于变现的高阶爬虫技术,在这里蛋糕特意给大家准备了一套python编程资料,能够帮你到你从零基础到python高阶爬虫的学习。

朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

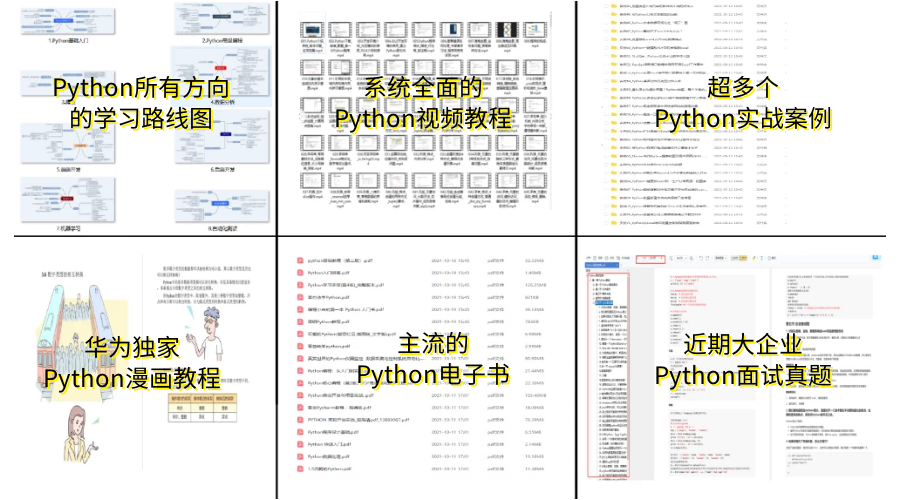
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈
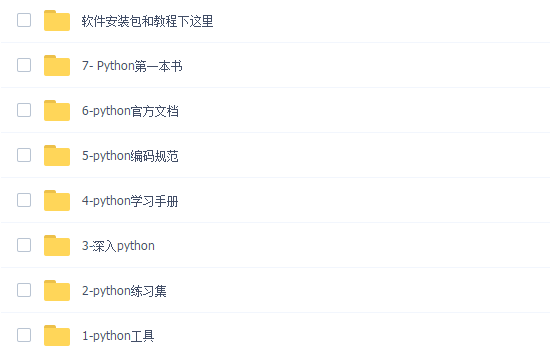
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
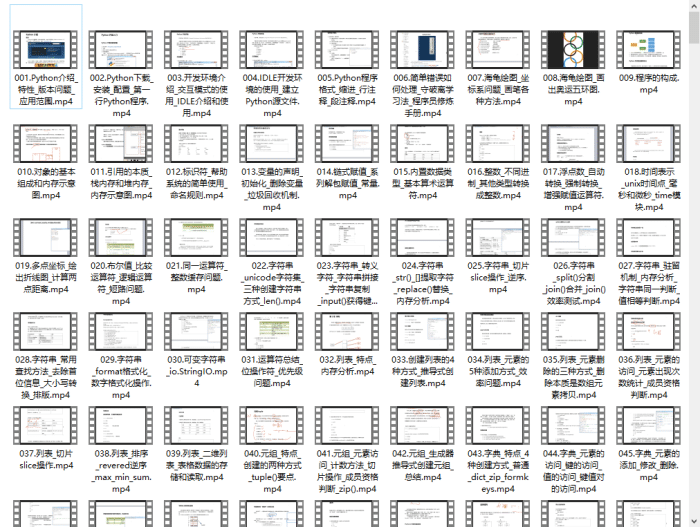
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

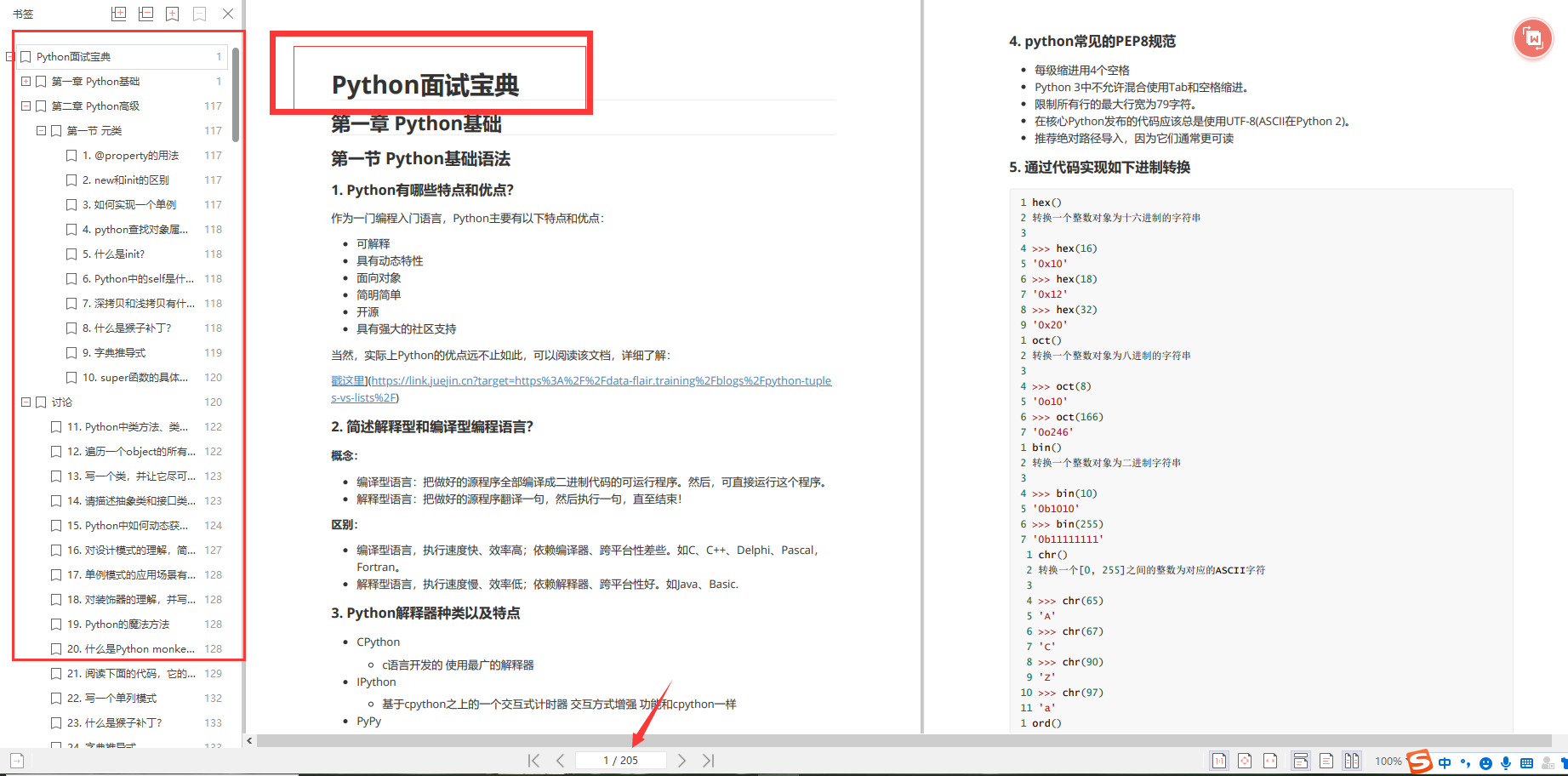
👉面试刷题👈

资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取
相关文章:
我用python疯狂爬取公司数据
我是半路从一个纯小白学过来的,学习途中也掉过许多坑,在这里建议新手要先把基础打扎实,然后再去学习自己需要的内容,不要想着全部学完再用,那样你是永远学不完的,用哪方面就学习哪方面的内容,不…...

EMR集群运行TPC-DS在云盘和OSS中的对比
1.简介 TPC-DS是大数据领域最为知名的Benchmark标准。本文介绍使用阿里云EMR集群运行TPC-DS在云盘和OSS中的表现对比。 2.环境准备 1.创建EEMR-5.10.1集群 1个master,2个core,3台机器都s是4c16g。 2.安装Git和Maven sudo yum install -y git maven3.下载TPC-DS Benchmark工…...
菜鸟在 windows 下 python 中安装 jupyter 踩坑要点 、被神化的 VsCode
我平时用不到 python ,更没用过 jupyter ,因此我的 python知识仅限于知道有 python 这么个编程语言,会写个 print("Hello World!!!") 而已,完全没听过 jupyter ,因为某些原因今天需要安装下 jupyter 看看&am…...

k8s简单搭建
前言 最近学习k8s,跟着网上各种教程搭建了简单的版本,一个master节点,两个node节点,这里记录下防止以后忘记。 具体步骤 准备环境 用Oracle VM VirtualBox虚拟机软件安装3台虚拟机,一台master节点,两台…...

计算机SCI期刊审稿人,一般关注论文的那些问题? - 易智编译EaseEditing
编辑主要关心: (1)文章内容是否具有足够的创新性? (2)文章主题是否符合期刊的受众读者? (3)文章方法学是否合理,数据处理是否充分? (…...

Docker迁移以及环境变量问题
问题一描述将docker容器通过docker export命令打包,传输到另外的服务器,再通过docker import命令导入后,发现原来docker容器中的环境变量失效了。解决方案1. 【无效方案】直接在docker容器中通过export命令设置环境变量。export LD_LIBRARY_P…...
Sphinx文档生成工具(二)
rst语法 官方的语法手册 行内的样式: #斜体 *message* #粗体 **message** #等宽 不能有换行 message标题 一级标题 ^^^^^^^^ 二级标题 --------- 三级标题 >>>>>>>>> 四级标题 ::::::::: 五级标题六级标题 """"…...

Python快速上手系列--JSON--入门篇
本章我们来看看json的一些应用。简单易懂还实用。一起来看看数据类型以及一些语法规则吧1、数字(整数或浮点数) 如:{"age":18, "score":70.5} 注意,数字直接写,不需要带任何符号2、字符串…...
axios中的GET POST PUT PATCH,发送请求时params和data的区别
axios 中 get/post请求方式 1. 前言 最近突然发现post请求可以使用params方式传值,然后想总结一下其中的用法。 2.1 分类 经过查阅资料,get请求是可以通过body传输数据的,但是许多工具类并不支持此功能。 在postman中,选择get请…...

hume项目k8s的改造
hume项目k8s的改造 一、修改构建目录结构 1、在根目录下添加build-work文件夹 目录结构如下 [rootk8s-worker-01 build-work]# tree . . ├── Dockerfile ├── hume │ └── start.sh └── Jenkinsfile2、每个文件内容如下 Dockerfile FROM ccr.ccs.tencentyun…...
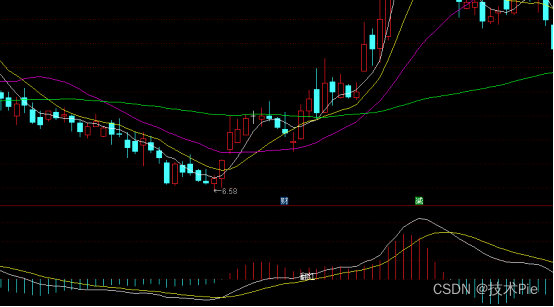
MACD红二波选股公式,选出MACD二次翻红的标的
经过一段上涨行情之后,市场出现了时间稍长或者幅度稍大的调整,MACD指标的DIF、DEA会出现死叉,柱线由红色转变为绿色。 而调整时间较短或者幅度较小,MACD红柱会缩短,但不出现绿柱,之后红柱开始变长ÿ…...
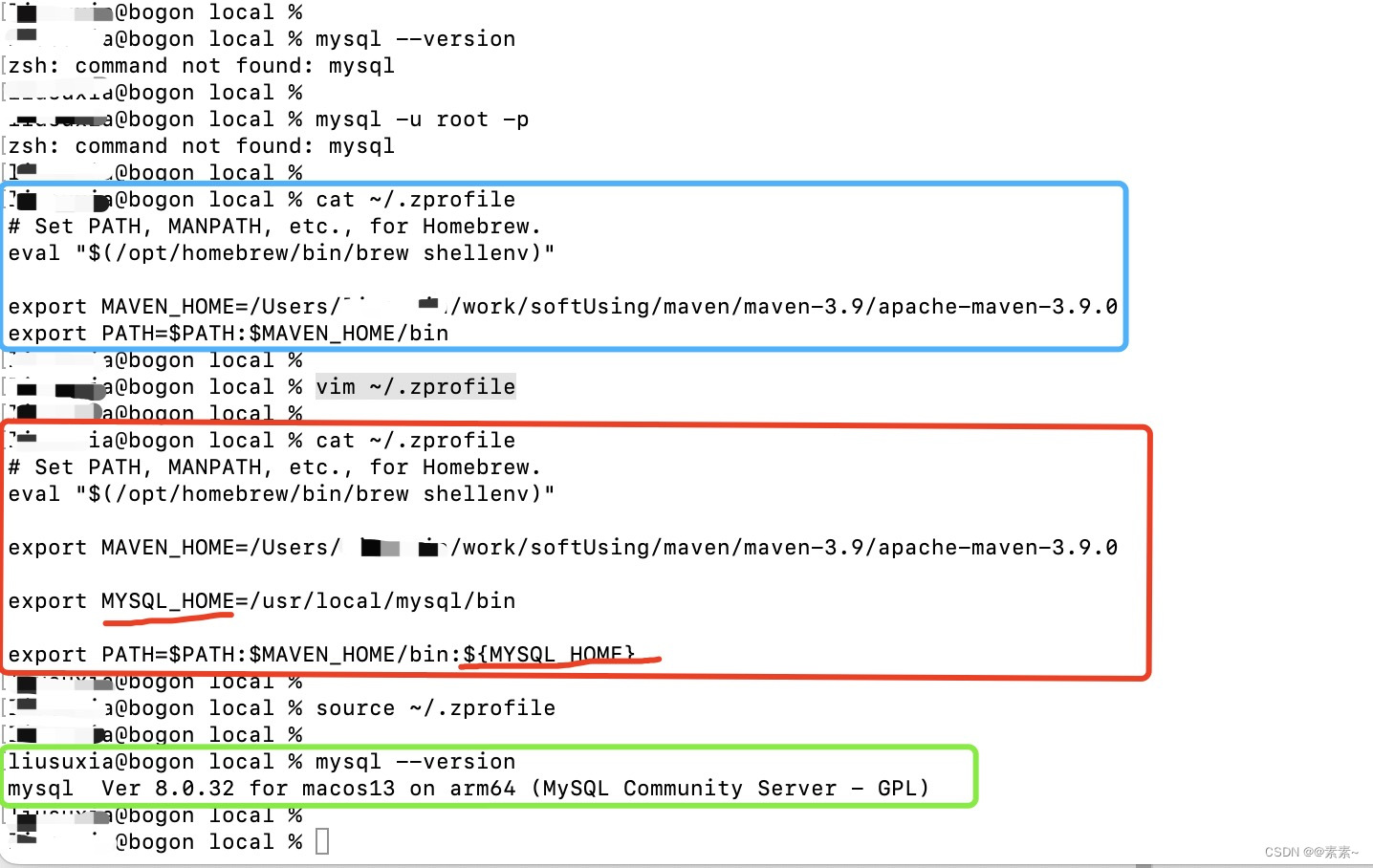
mac上安装mysql
mac上安装mysql1. 关于Linux上安装mysql2. 下载安装2.1 下载2.2 安装3. 客户端连接mysql3.1 先查看mysql服务3.2 连接mysql客户端3.2.1 终端使用命令连接3.2.2 可视化工具连接3.3 其他简单操作(启动服务等)3.3.1 可视化界面操作4. 配置环境变量4.1 配置环…...

Django 模型继承问题
文章目录Django 模型继承问题继承出现的情况Meta 和多表继承Meta 和多表继承继承与反向关系指定父类连接字段代理模型QuerySet 仍会返回请求的模型基类约束代理模型管理器代理继承和未托管的模型间的区别多重继承不能用字段名 "hiding"在一个包中管理模型Django 模型…...
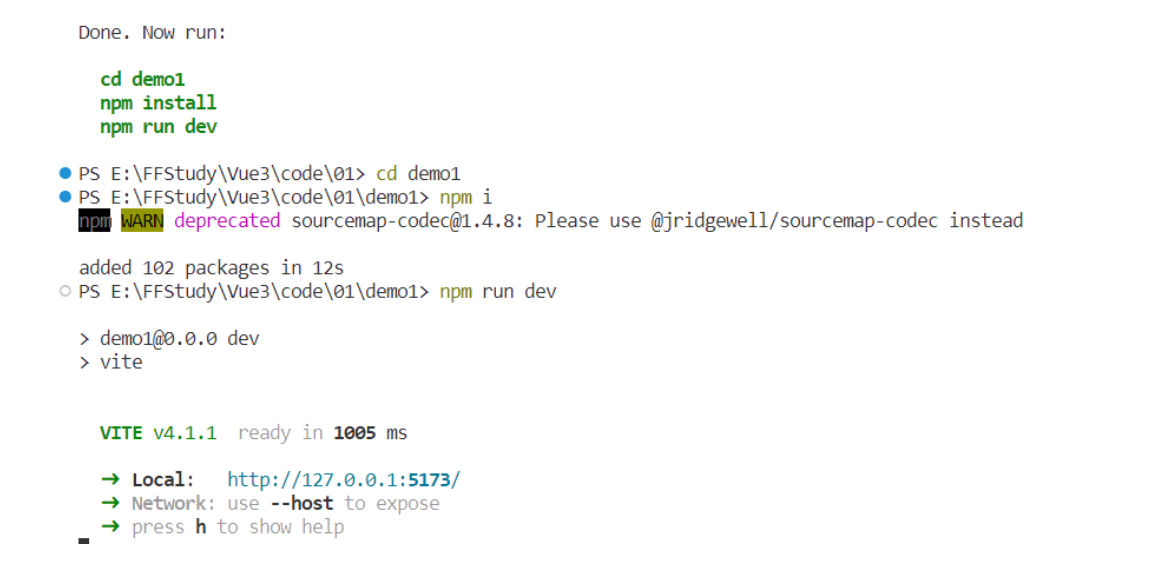
Vue3篇.01-简介及基本使用,项目创建方式, 模板语法, 事件监听, 修饰符
一.简介1.概念Vue 是一款用于构建用户界面的 JS框架, 基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型, 高效地开发用户界面。渐进式框架, 适应不同需求进行开发。两个核心功能:声明式…...

别学英语了,真的
文 / 王不留(微信公众号:王不留) 这两年,很多朋友加我微信后,第一句常是,学英语有什么用啊? 我会统一给出真诚答复:没用,真的。 看新闻,中文海量信息已经严重…...

CRM系统五大技巧集成Excel为销售流程赋能
销售过程中有很多情况会降低团队的效率。通过正确的实施CRM客户管理系统,可以帮助您的企业自动执行手动任务、减少错误并专注于完成交易。这里有5个技巧,可以帮助您的销售人员通过CRM集成Excel为销售流程赋能并提高他们的整体效率。 技巧1:将…...
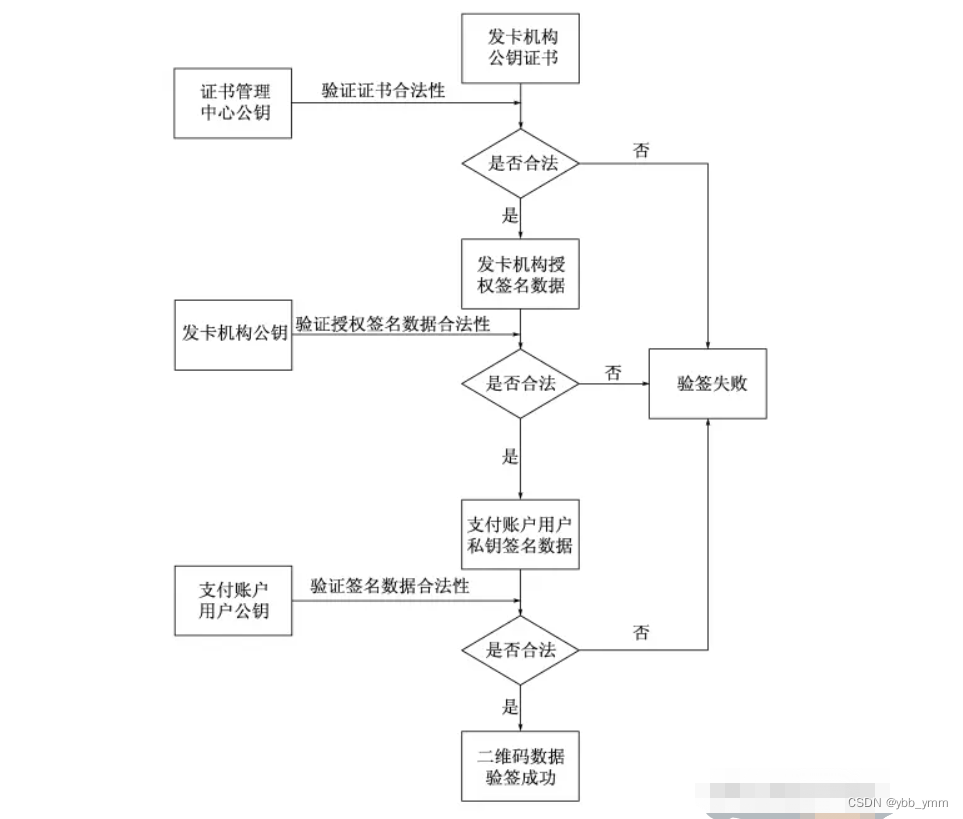
交通部互通互联码的根证书规则
引言 为了更好的服务交通互通互联码而更新这篇文章。 中金根证书其实是可以自己生成的。 代码内调整 中心公钥索引要保证自己的唯一性。 此处的唯一,是要保证在机具侧的唯一,因为他要根据这个索引去查找证书以及公钥。 提供根公钥给机具侧 生成的公钥…...
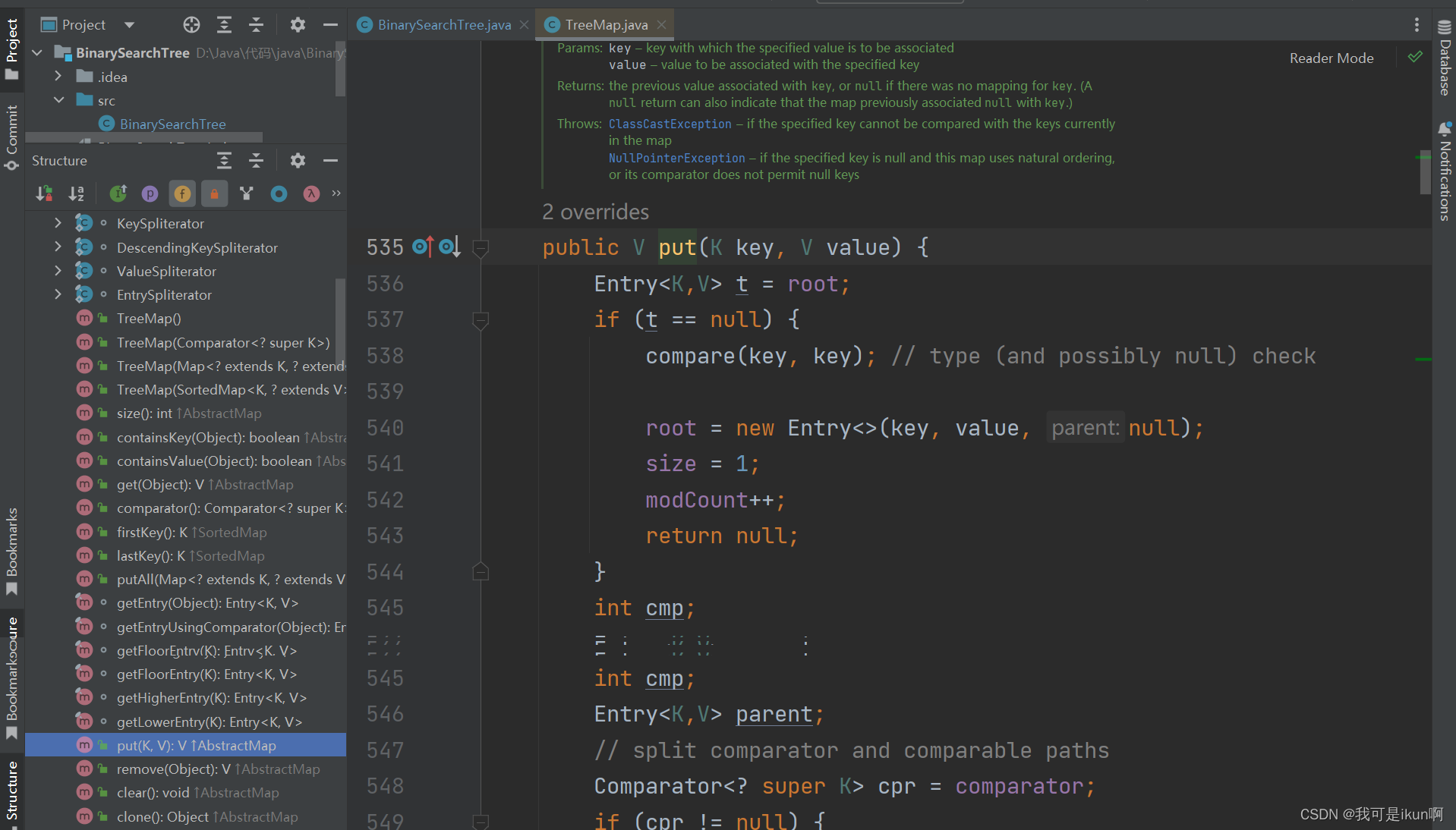
Map和Set(Java详解)
在开始详解之前,先来看看集合的框架: 可以看到Set实现了Collection接口,而Map又是一个单独存在的接口。 而最下面又分别各有两个类,分别是TreeSet(Map)和 HashSet(Map)。 TreeSet&…...

Vue 3的响应式机制
什么是响应式 Js代码是自上而下执行的,结合下面代码看,代码执行后,会打印两次double的结果,结果也都是2,即使修改了代码中count的值后,double的值也不会发生任何改变。 let count 1 let double count * …...

30岁了,说几句大实话
是的,我 30 岁了,还是周岁。 就在这上个月末,我度过了自己 30 岁的生日。 都说三十而立,要对自己有一个正确的认识,明确自己以后想做什么,能做什么。 想想时间,过得真快。 过五关斩六将&…...

终极免费虚拟光驱解决方案:WinCDEmu完整使用指南
终极免费虚拟光驱解决方案:WinCDEmu完整使用指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu 还在为找不到光驱而烦恼吗?还在为ISO文件无法直接访问而困扰吗?WinCDEmu为您提供了一站式的虚拟光…...

ESP32-C3 USB串行/JTAG控制器:从零构建高效开发与调试环境
1. ESP32-C3 USB串行/JTAG控制器:为什么它改变了游戏规则 第一次拿到ESP32-C3开发板时,我习惯性地在板子上寻找CH340这类USB转串口芯片的踪影——结果发现根本找不到。这个发现让我既困惑又兴奋,因为这意味着开发方式要彻底改变了。ESP32-C3内…...

企业级报表工具润乾报表的安全审计:从dataSphereServlet接口看文件上传风险
企业级报表工具安全审计实战:从接口风险到供应链防护 报表系统作为企业数据流转的核心枢纽,其安全性直接影响业务数据的完整性与机密性。某次内部安全评估中,我们发现部署在财务系统的报表组件存在异常文件写入行为,追踪发现是源于…...

SDMatte电商提效数据报告:某服饰品牌月省86人工小时,准确率98.7%
SDMatte电商提效数据报告:某服饰品牌月省86人工小时,准确率98.7% 1. 案例背景与痛点 在电商行业,商品图片处理是运营工作中最耗时的工作之一。某知名服饰品牌在日常运营中面临以下挑战: 人工抠图效率低:平均每张商品…...

无需代码!用圣女司幼幽-造相Z-Turbo轻松生成动漫女神图片
无需代码!用圣女司幼幽-造相Z-Turbo轻松生成动漫女神图片 1. 引言:零门槛AI绘画体验 想象一下,只需输入简单的文字描述,就能生成精美的动漫女神图片——这就是圣女司幼幽-造相Z-Turbo带来的神奇体验。这个基于Xinference部署的文…...

RePKG深度指南:如何解锁Wallpaper Engine的PKG资源与TEX纹理转换
RePKG深度指南:如何解锁Wallpaper Engine的PKG资源与TEX纹理转换 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经面对Wallpaper Engine的PKG文件束手无策&…...

Keil5编译链设置避坑指南:为什么你的AC5突然不能用了?
Keil5编译链设置避坑指南:为什么你的AC5突然不能用了? 上周三凌晨两点,李工在办公室对着屏幕上的红色报错信息揉着太阳穴——他负责维护的工业控制器项目突然无法编译了。这个基于STM32F103的老项目已经稳定运行了5年,最后一次修…...

高效解密网易云音乐NCM格式的专业解决方案
高效解密网易云音乐NCM格式的专业解决方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐版权保护的背景下,网易云音乐采用的NCM加密格式为用户带来了跨平台播放的挑战。这种专有格式虽然有效保护了音乐版权&…...

明日方舟玩家解放双手的终极方案:MAA小助手完全指南
明日方舟玩家解放双手的终极方案:MAA小助手完全指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitco…...

Lychee多模态重排序模型惊艳效果:盲文图像与语音合成文本的可访问性对齐
Lychee多模态重排序模型惊艳效果:盲文图像与语音合成文本的可访问性对齐 1. 引言 想象一下,一位视障朋友拿到一份纸质盲文文档,他需要知道里面写了什么。传统方法是找人朗读,或者用专门的盲文扫描仪。但现在,你只需要…...