ThreadLocal 源码级别详解
ThreadLocal简介

稍微翻译一下:
ThreadLocal提供线程局部变量。这些变量与正常的变量不同,因为每一个线程在访问ThreadLocal实例的时候(通过其get或set方法)都有自己的、独立初始化的变量副本。ThreadLocal实例通常是类中的私有静态字段,使用它的目的是希望将状态(例如,用户ID或事务ID)与线程关联起来。
实现每一个线程都有自己专属的本地变量副本(自己用自己的变量不麻烦别人,不和其他人共享,人人有份,人各一份),
主要解决了让每个线程绑定自己的值,通过使用get()和set()方法,获取默认值或将其值更改为当前线程所存的副本的值从而避免了线程安全问题。
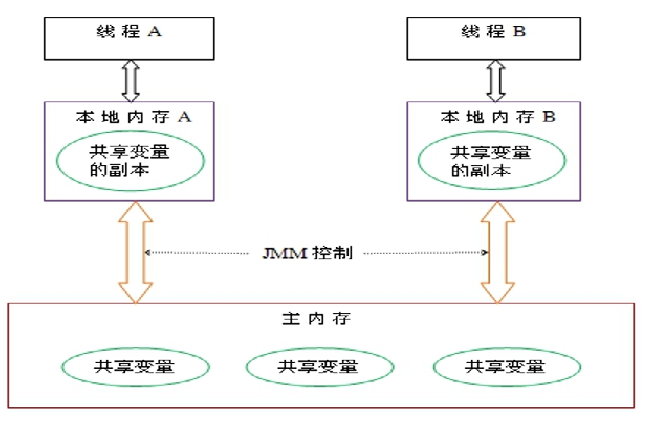
API
DOME: 比如某找房软件,每个中介销售都有自己的销售额指标,自己专属自己的,不和别人掺和
class House
{ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public void saleHouse(){Integer value = threadLocal.get();value++;threadLocal.set(value);}
}/*** 1 三个售票员卖完50张票务,总量完成即可,吃大锅饭,售票员每个月固定月薪** 2 分灶吃饭,各个销售自己动手,丰衣足食*/
public class ThreadLocalDemo
{public static void main(String[] args){House house = new House();new Thread(() -> {try {for (int i = 1; i <=3; i++) {house.saleHouse();}System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get());}finally {house.threadLocal.remove();//如果不清理自定义的 ThreadLocal 变量,可能会影响后续业务逻辑和造成内存泄露等问题}},"t1").start();new Thread(() -> {try {for (int i = 1; i <=2; i++) {house.saleHouse();}System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get());}finally {house.threadLocal.remove();}},"t2").start();new Thread(() -> {try {for (int i = 1; i <=5; i++) {house.saleHouse();}System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get());}finally {house.threadLocal.remove();}},"t3").start();System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get());}
}
ThreadLocal对象可以提供线程局部变量,每个线程Thread拥有一份自己的副本变量,多个线程互不干扰。
ThreadLocal的数据结构

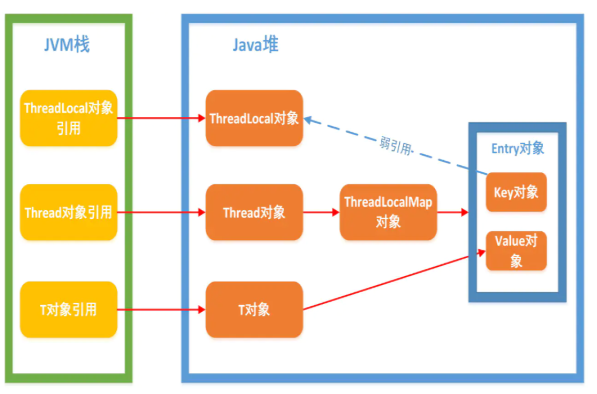
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,也就是说每个线程有一个自己的ThreadLocalMap。
ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。
每个线程在往ThreadLocal里放值的时候,都会往自己的ThreadLocalMap里存,读也是以ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
我们还要注意Entry, **它的key是ThreadLocal<?> k ,**继承自WeakReference, 也就是我们常说的弱引用类型。
Thread,ThreadLocal,ThreadLocalMap 关系
threadLocalMap实际上就是一个以threadLocal实例为key,任意对象为value的Entry对象。
当我们为threadLocal变量赋值,实际上就是以当前threadLocal实例为key,值为value的Entry往这个threadLocalMap中存放
GC 之后 key 是否为 null?回应开头的那个问题, ThreadLocal 的key是弱引用,那么在ThreadLocal.get()的时候,发生GC之后,key是否是null?
了搞清楚这个问题,我们需要搞清楚Java的四种引用类型:
强引用:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
软引用:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
弱引用:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
虚引用:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
ThreadLocal内存泄露问题

什么是内存泄漏
不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄露。
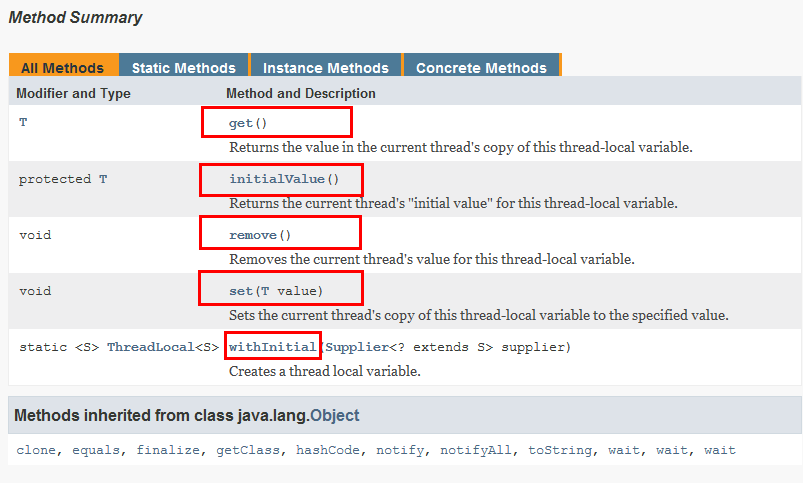
每个Thread对象维护着一个ThreadLocalMap的引用
ThreadLocalMap是ThreadLocal的内部类,用Entry来进行存储
调用ThreadLocal的set()方法时,实际上就是往ThreadLocalMap设置值,key是ThreadLocal对象,值Value是传递进来的对象
调用ThreadLocal的get()方法时,实际上就是往ThreadLocalMap获取值,key是ThreadLocal对象
ThreadLocal本身并不存储值,它只是自己作为一个key来让线程从ThreadLocalMap获取value,正因为这个原理,所以ThreadLocal能够实现“数据隔离”,获取当前线程的局部变量值,不受其他线程影响~
为什么要用弱引用?不用如何?
public void function01()
{ThreadLocal tl = new ThreadLocal<Integer>(); //line1tl.set(2021); //line2tl.get(); //line3
}
line1新建了一个ThreadLocal对象,t1 是强引用指向这个对象;
line2调用set()方法后新建一个Entry,通过源码可知Entry对象里的k是弱引用指向这个对象。
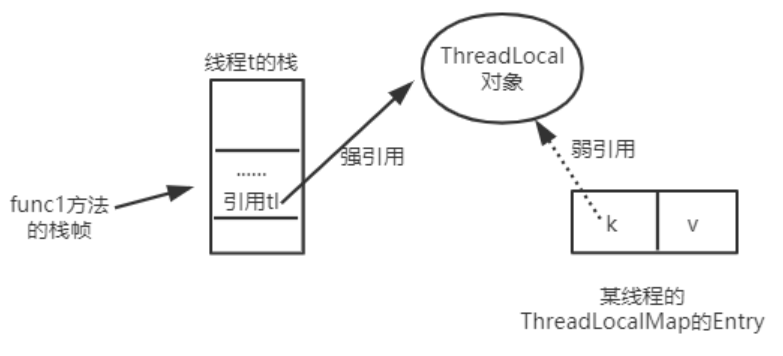
当function01方法执行完毕后,栈帧销毁强引用 tl 也就没有了。但此时线程的ThreadLocalMap里某个entry的key引用还指向这个对象
若这个key引用是强引用,就会导致key指向的ThreadLocal对象及v指向的对象不能被gc回收,造成内存泄漏;
若这个key引用是弱引用就大概率会减少内存泄漏的问题(还有一个key为null的雷)。使用弱引用,就可以使ThreadLocal对象在方法执行完毕后顺利被回收且Entry的key引用指向为null。
-
1当我们为threadLocal变量赋值,实际上就是当前的Entry(threadLocal实例为key,值为value)往这个threadLocalMap中存放。Entry中的key是弱引用,当threadLocal外部强引用被置为null(tl=null),那么系统 GC 的时候,根据可达性分析,这个threadLocal实例就没有任何一条链路能够引用到它,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
-
2当然,如果当前thread运行结束,threadLocal,threadLocalMap,Entry没有引用链可达,在垃圾回收的时候都会被系统进行回收。
-
3 但在实际使用中我们有时候会用线程池去维护我们的线程,比如在Executors.newFixedThreadPool()时创建线程的时候,为了复用线程是不会结束的,所以threadLocal内存泄漏就值得我们小心
ThreadLocal 源码剖析
ThreadLocal.set()方法源码详解

ThreadLocal中的set方法原理如上图所示,很简单,主要是判断ThreadLocalMap是否存在,然后使用ThreadLocal中的set方法进行数据处理。
代码如下:
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(this, firstValue);
}
主要的核心逻辑还是在ThreadLocalMap中的,一步步往下看,后面还有更详细的剖析
ThreadLocalMap Hash 算法
既然是Map结构,那么ThreadLocalMap当然也要实现自己的hash算法来解决散列表数组冲突问题。
int i = key.threadLocalHashCode & (len-1);
ThreadLocalMap中hash算法很简单,这里i就是当前 key 在散列表中对应的数组下标位置。
这里最关键的就是threadLocalHashCode值的计算,ThreadLocal中有一个属性为HASH_INCREMENT = 0x61c88647
public class ThreadLocal<T> {private final int threadLocalHashCode = nextHashCode();private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCREMENT = 0x61c88647;private static int nextHashCode() {return nextHashCode.getAndAdd(HASH_INCREMENT);}static class ThreadLocalMap {ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);table[i] = new Entry(firstKey, firstValue);size = 1;setThreshold(INITIAL_CAPACITY);}}
}
每当创建一个ThreadLocal对象,这个ThreadLocal.nextHashCode 这个值就会增长 0x61c88647 。
这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
我们自己可以尝试下:
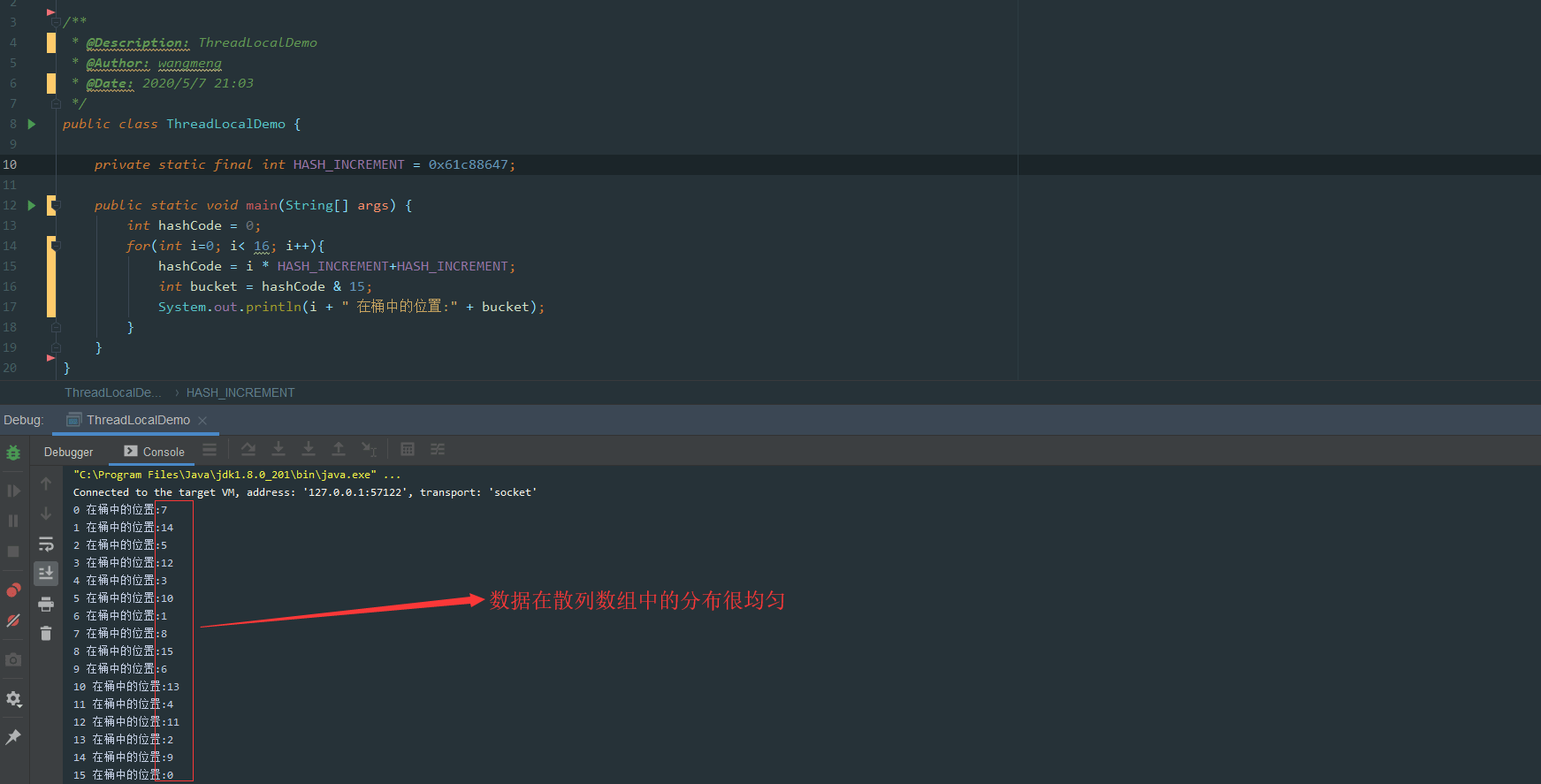
可以看到产生的哈希码分布很均匀,这里不去细纠斐波那契具体算法,感兴趣的可以自行查阅相关资料。
ThreadLocalMap Hash 冲突
注明: 下面所有示例图中,绿色块
Entry代表正常数据,灰色块代表Entry的key值为null,已被垃圾回收。白色块表示Entry为null。
虽然ThreadLocalMap中使用了黄金分割数来作为hash计算因子,大大减少了Hash冲突的概率,但是仍然会存在冲突。
HashMap中解决冲突的方法是在数组上构造一个链表结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成红黑树。
而 ThreadLocalMap 中并没有链表结构,所以这里不能使用 HashMap 解决冲突的方式了。
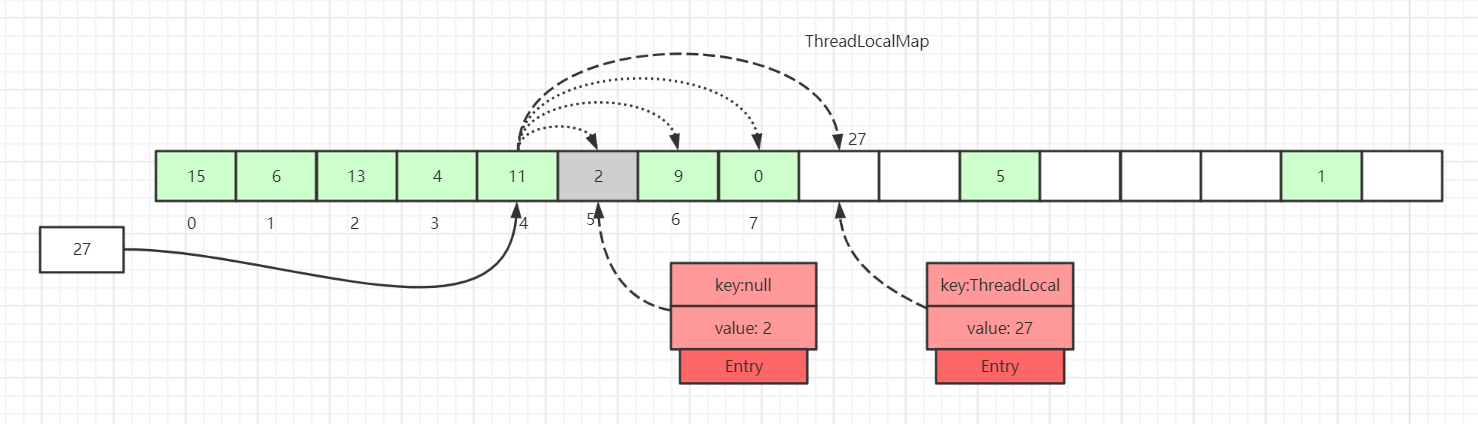
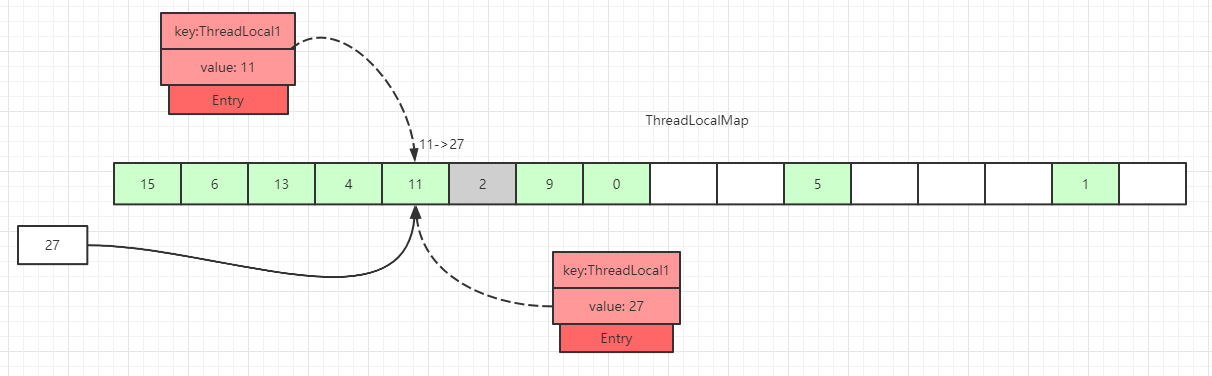
如上图所示,如果我们插入一个value=27的数据,通过 hash 计算后应该落入槽位 4 中,而槽位 4 已经有了 Entry 数据。
此时就会线性向后查找,一直找到 Entry 为 null 的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了 Entry 不为 null 且 key 值相等的情况,还有 Entry 中的 key 值为 null 的情况等等都会有不同的处理,后面会一一详细讲解。
这里还画了一个Entry中的key为null的数据(Entry=2 的灰色块数据),因为key值是弱引用类型,所以会有这种数据存在。在set过程中,如果遇到了key过期(key = null)的Entry数据,实际上是会进行一轮探测式清理操作的,具体操作方式后面会讲到。
ThreadLocalMap.set()详解
ThreadLocalMap.set()原理图解
看完了ThreadLocal hash 算法后,我们再来看set是如何实现的。
往ThreadLocalMap中set数据(新增或者更新数据)分为好几种情况,针对不同的情况我们画图来说明。
第一种情况: 通过hash计算后的槽位对应的Entry数据为空:
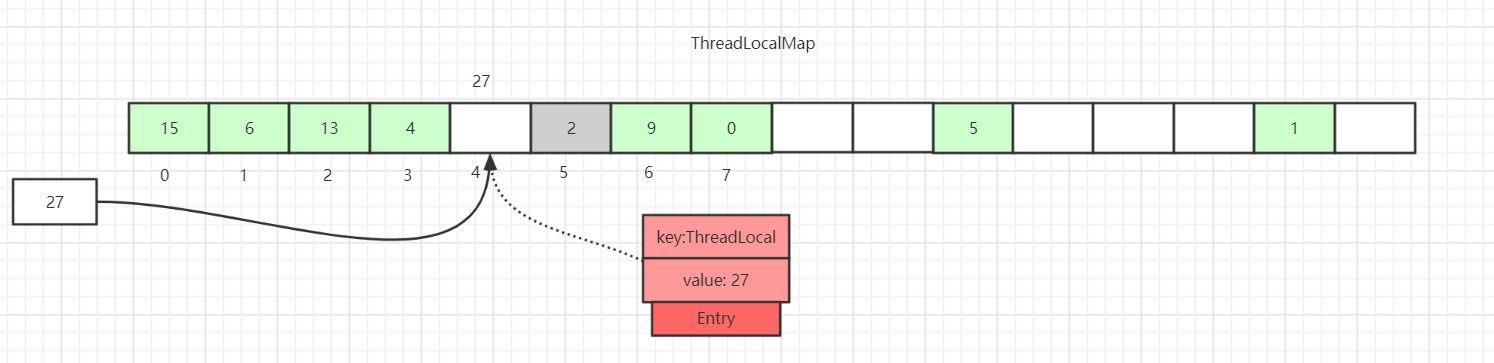
这里直接将数据放到该槽位即可。
第二种情况: 槽位数据不为空,key值与当前ThreadLocal通过hash计算获取的key值一致:
这里直接更新该槽位的数据。
第三种情况: 槽位数据不为空,往后遍历过程中,在找到Entry为null的槽位之前,没有遇到key过期的Entry:
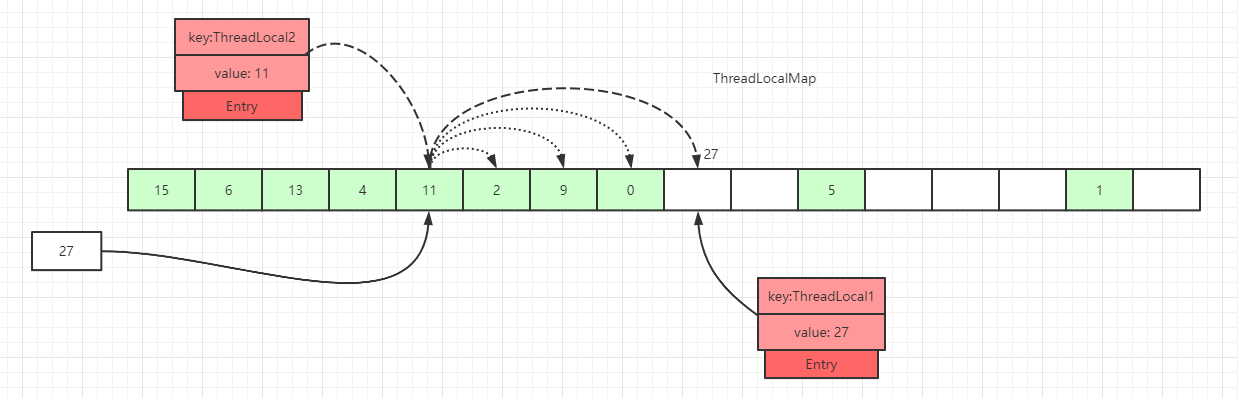
遍历散列数组,线性往后查找,如果找到Entry为null的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了key 值相等的数据,直接更新即可。
第四种情况: 槽位数据不为空,往后遍历过程中,在找到Entry为null的槽位之前,遇到key过期的Entry,如下图,往后遍历过程中,遇到了index=7的槽位数据Entry的key=null:

散列数组下标为 7 位置对应的Entry数据key为null,表明此数据key值已经被垃圾回收掉了,此时就会执行replaceStaleEntry()方法,该方法含义是替换过期数据的逻辑,以index=7位起点开始遍历,进行探测式数据清理工作。
初始化探测式清理过期数据扫描的开始位置:slotToExpunge = staleSlot = 7
以当前staleSlot开始 向前迭代查找,找其他过期的数据,然后更新过期数据起始扫描下标slotToExpunge。for循环迭代,直到碰到Entry为null结束。
如果找到了过期的数据,继续向前迭代,直到遇到Entry=null的槽位才停止迭代,如下图所示,slotToExpunge 被更新为 0:
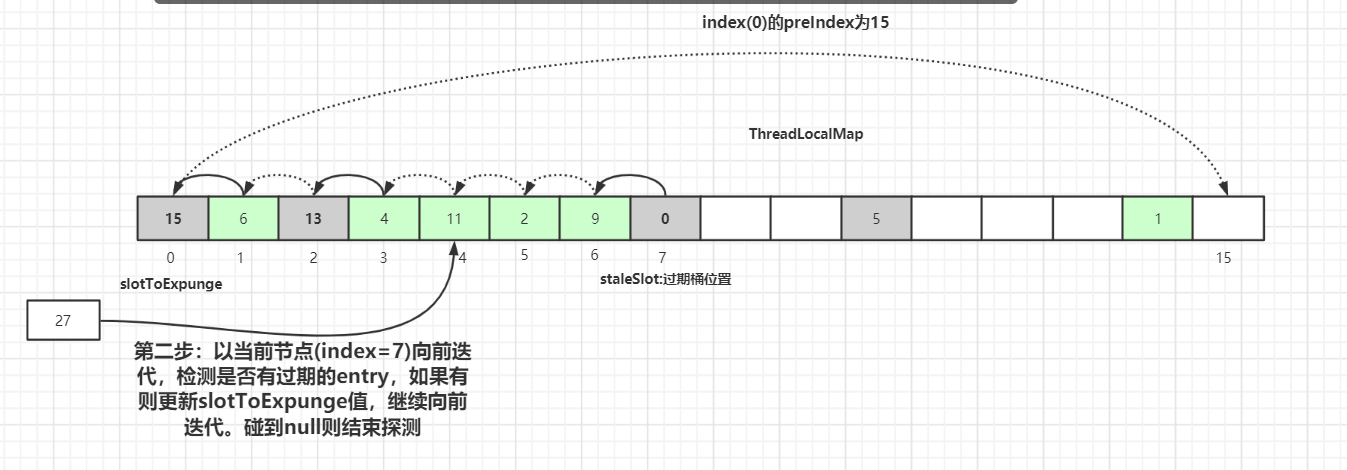
以当前节点(index=7)向前迭代,检测是否有过期的Entry数据,如果有则更新slotToExpunge值。碰到null则结束探测。以上图为例slotToExpunge被更新为 0。
上面向前迭代的操作是为了更新探测清理过期数据的起始下标slotToExpunge的值,这个值在后面会讲解,它是用来判断当前过期槽位staleSlot之前是否还有过期元素。
接着开始以staleSlot位置(index=7)向后迭代,如果找到了相同 key 值的 Entry 数据:
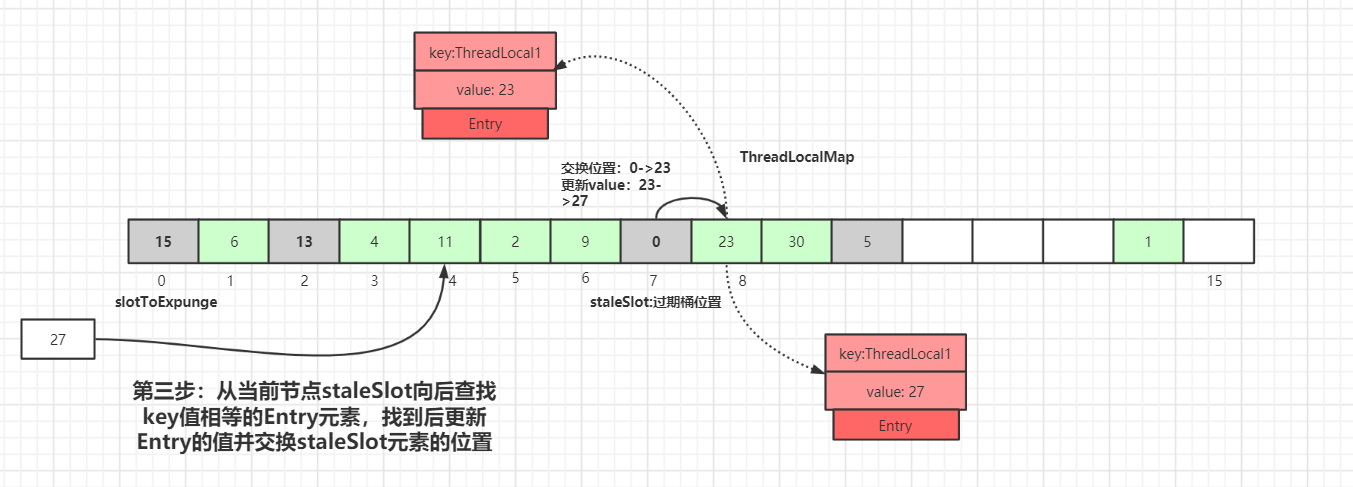
从当前节点staleSlot向后查找key值相等的Entry元素,找到后更新Entry的值并交换staleSlot元素的位置(staleSlot位置为过期元素),更新Entry数据,然后开始进行过期Entry的清理工作,如下图所示:
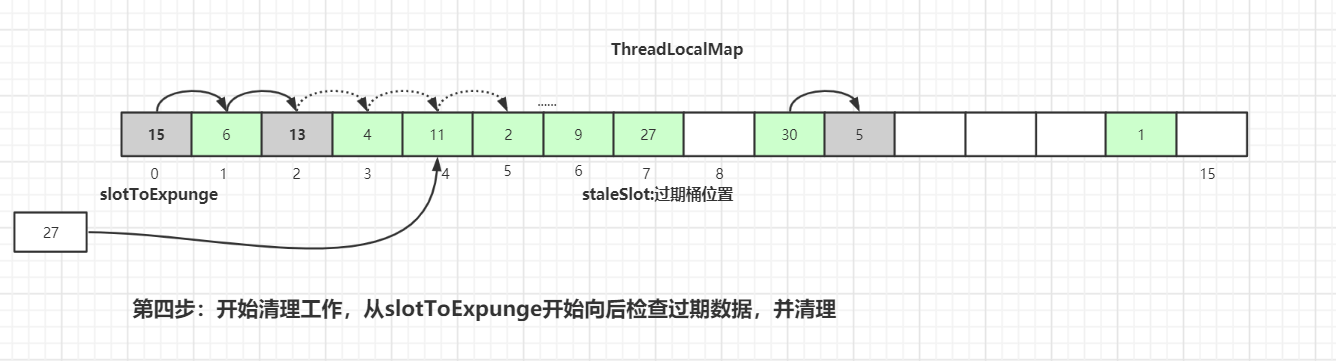 向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:
向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:
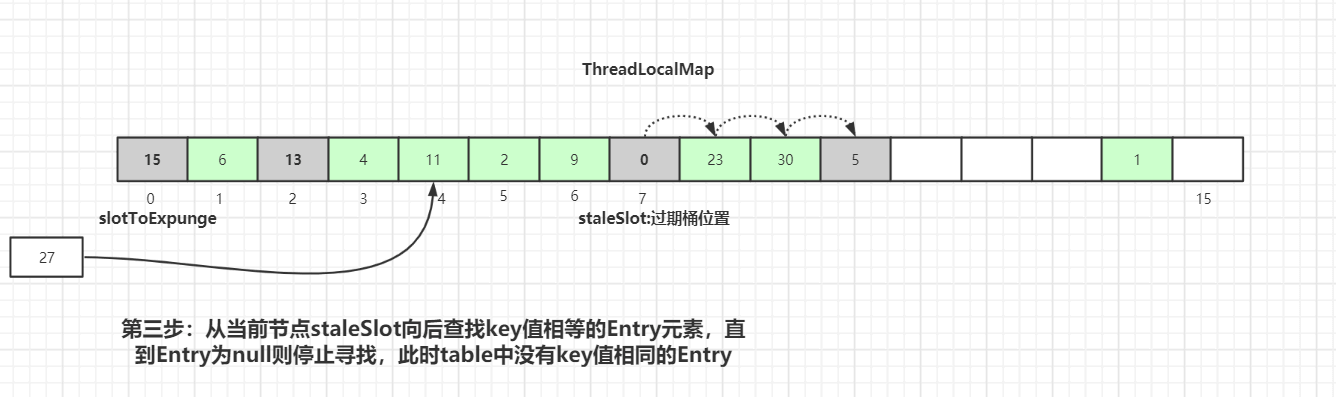
从当前节点staleSlot向后查找key值相等的Entry元素,直到Entry为null则停止寻找。通过上图可知,此时table中没有key值相同的Entry。
创建新的Entry,替换table[stableSlot]位置:
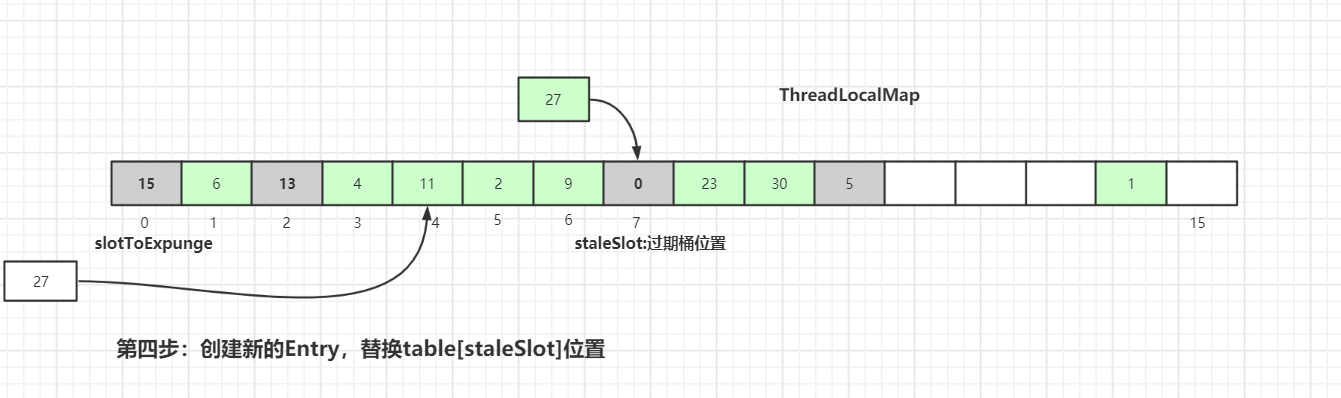
替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:expungeStaleEntry()和cleanSomeSlots(),具体细节后面会讲到,请继续往后看。
ThreadLocalMap.set()源码详解
上面已经用图的方式解析了set()实现的原理,其实已经很清晰了,我们接着再看下源码:
java.lang.ThreadLocal.ThreadLocalMap.set()
private void set(ThreadLocal<?> key, Object value) {Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal<?> k = e.get();if (k == key) {e.value = value;return;}if (k == null) {replaceStaleEntry(key, value, i);return;}}tab[i] = new Entry(key, value);int sz = ++size;if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();
}
这里会通过key来计算在散列表中的对应位置,然后以当前key对应的桶的位置向后查找,找到可以使用的桶。
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
什么情况下桶才是可以使用的呢?
k = key说明是替换操作,可以使用- 碰到一个过期的桶,执行替换逻辑,占用过期桶
- 查找过程中,碰到桶中
Entry=null的情况,直接使用
接着就是执行for循环遍历,向后查找,我们先看下nextIndex()、prevIndex()方法实现:
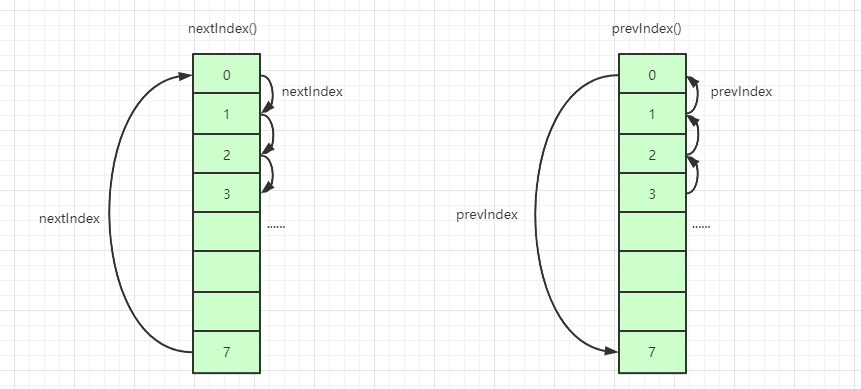
private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);
}private static int prevIndex(int i, int len) {return ((i - 1 >= 0) ? i - 1 : len - 1);
}
接着看剩下for循环中的逻辑:
- 遍历当前
key值对应的桶中Entry数据为空,这说明散列数组这里没有数据冲突,跳出for循环,直接set数据到对应的桶中 - 如果
key值对应的桶中Entry数据不为空
2.1 如果k = key,说明当前set操作是一个替换操作,做替换逻辑,直接返回
2.2 如果key = null,说明当前桶位置的Entry是过期数据,执行replaceStaleEntry()方法(核心方法),然后返回 for循环执行完毕,继续往下执行说明向后迭代的过程中遇到了entry为null的情况
3.1 在Entry为null的桶中创建一个新的Entry对象
3.2 执行++size操作- 调用
cleanSomeSlots()做一次启发式清理工作,清理散列数组中Entry的key过期的数据
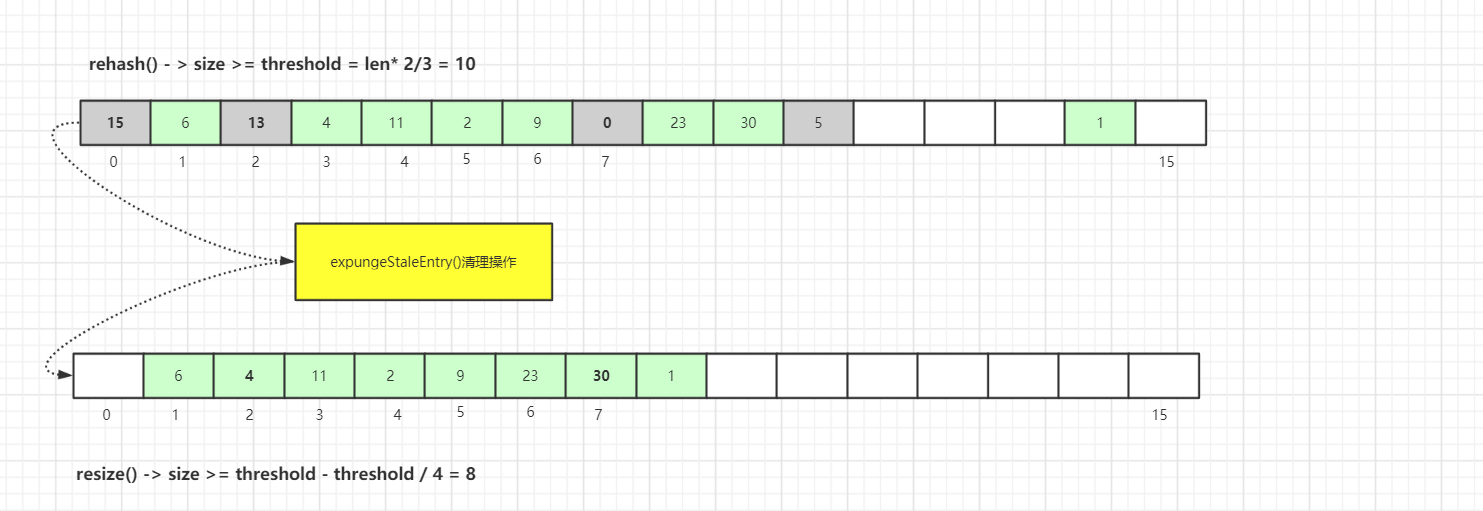
4.1 如果清理工作完成后,未清理到任何数据,且size超过了阈值(数组长度的 2/3),进行rehash()操作
4.2rehash()中会先进行一轮探测式清理,清理过期key,清理完成后如果size >= threshold - threshold / 4,就会执行真正的扩容逻辑(扩容逻辑往后看)
ThreadLocalMap扩容机制
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();
接着看下rehash()具体实现:
private void rehash() {expungeStaleEntries();if (size >= threshold - threshold / 4)resize();
}private void expungeStaleEntries() {Entry[] tab = table;int len = tab.length;for (int j = 0; j < len; j++) {Entry e = tab[j];if (e != null && e.get() == null)expungeStaleEntry(j);}
}
这里首先是会进行探测式清理工作,从table的起始位置往后清理,上面有分析清理的详细流程。清理完成之后,table中可能有一些key为null的Entry数据被清理掉,所以此时通过判断size >= threshold - threshold / 4 也就是size >= threshold * 3/4 来决定是否扩容。
我们还记得上面进行rehash()的阈值是size >= threshold,所以当面试官套路我们ThreadLocalMap扩容机制的时候 我们一定要说清楚这两个步骤:
接着看看具体的resize()方法,为了方便演示,我们以oldTab.len=8来举例:
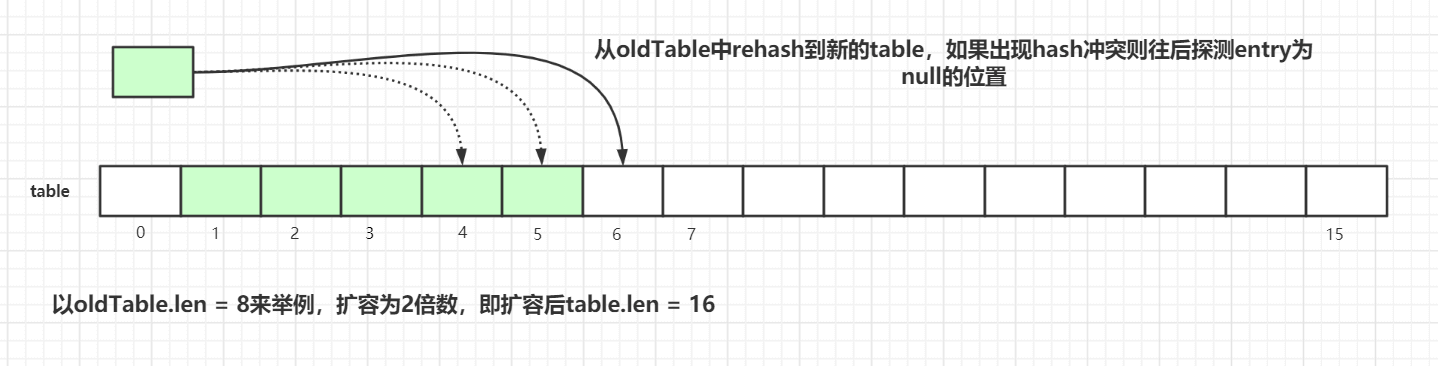
扩容后的tab的大小为oldLen * 2,然后遍历老的散列表,重新计算hash位置,然后放到新的tab数组中,如果出现hash冲突则往后寻找最近的entry为null的槽位,遍历完成之后,oldTab中所有的entry数据都已经放入到新的tab中了。重新计算tab下次扩容的阈值,具体代码如下:
private void resize() {Entry[] oldTab = table;int oldLen = oldTab.length;int newLen = oldLen * 2;Entry[] newTab = new Entry[newLen];int count = 0;for (int j = 0; j < oldLen; ++j) {Entry e = oldTab[j];if (e != null) {ThreadLocal<?> k = e.get();if (k == null) {e.value = null;} else {int h = k.threadLocalHashCode & (newLen - 1);while (newTab[h] != null)h = nextIndex(h, newLen);newTab[h] = e;count++;}}}setThreshold(newLen);size = count;table = newTab;
}
ThreadLocalMap.get()详解
上面已经看完了set()方法的源码,其中包括set数据、清理数据、优化数据桶的位置等操作,接着看看get()操作的原理。
ThreadLocalMap.get()图解
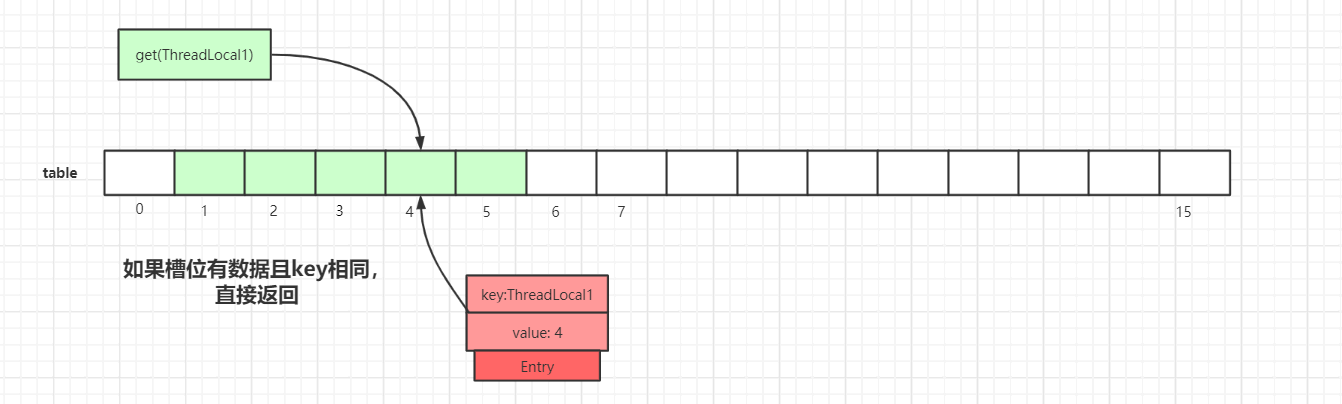
第一种情况: 通过查找key值计算出散列表中slot位置,然后该slot位置中的Entry.key和查找的key一致,则直接返回:
第二种情况: slot位置中的Entry.key和要查找的key不一致:
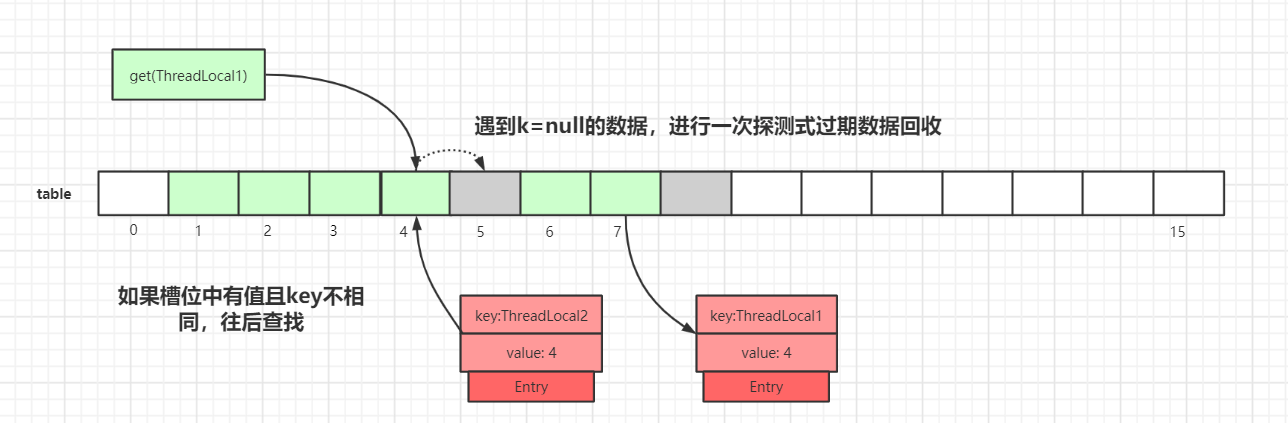
我们以get(ThreadLocal1)为例,通过hash计算后,正确的slot位置应该是 4,而index=4的槽位已经有了数据,且key值不等于ThreadLocal1,所以需要继续往后迭代查找。
迭代到index=5的数据时,此时Entry.key=null,触发一次探测式数据回收操作,执行expungeStaleEntry()方法,执行完后,index 5,8的数据都会被回收,而index 6,7的数据都会前移。index 6,7前移之后,继续从 index=5 往后迭代,于是就在 index=5 找到了key值相等的Entry数据,如下图所示:
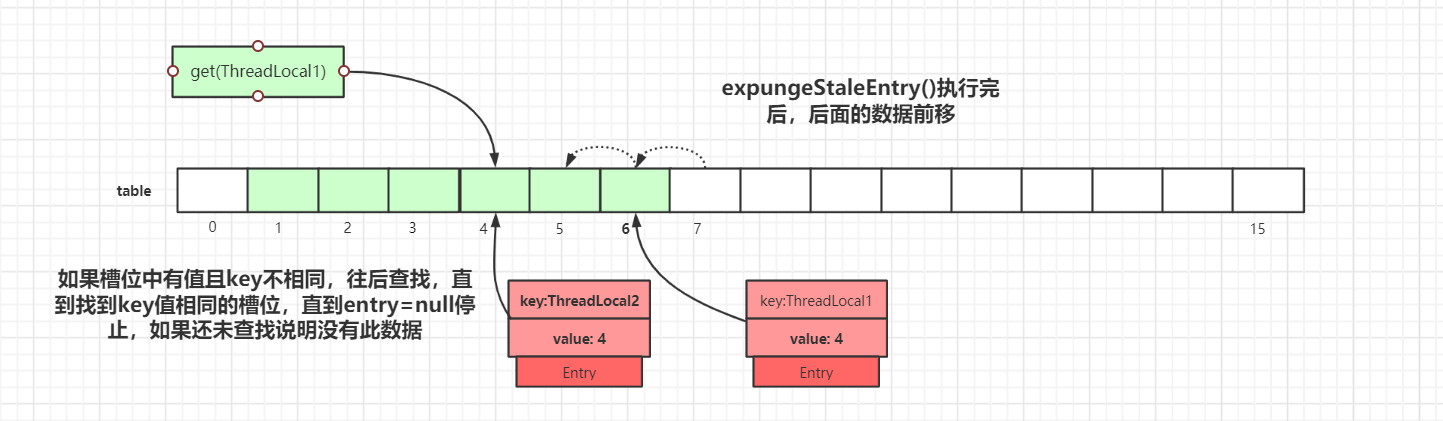
ThreadLocalMap.get()源码详解
java.lang.ThreadLocal.ThreadLocalMap.getEntry():
private Entry getEntry(ThreadLocal<?> key) {int i = key.threadLocalHashCode & (table.length - 1);Entry e = table[i];if (e != null && e.get() == key)return e;elsereturn getEntryAfterMiss(key, i, e);
}private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {Entry[] tab = table;int len = tab.length;while (e != null) {ThreadLocal<?> k = e.get();if (k == key)return e;if (k == null)expungeStaleEntry(i);elsei = nextIndex(i, len);e = tab[i];}return null;
}
InheritableThreadLocal
我们使用ThreadLocal的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
为了解决这个问题,JDK 中还有一个InheritableThreadLocal类,我们来看一个例子:
public class InheritableThreadLocalDemo {public static void main(String[] args) {ThreadLocal<String> ThreadLocal = new ThreadLocal<>();ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();ThreadLocal.set("父类数据:threadLocal");inheritableThreadLocal.set("父类数据:inheritableThreadLocal");new Thread(new Runnable() {@Overridepublic void run() {System.out.println("子线程获取父类ThreadLocal数据:" + ThreadLocal.get());System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());}}).start();}
}
打印结果:
子线程获取父类ThreadLocal数据:null
子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal
实现原理是子线程是通过在父线程中通过调用new Thread()方法来创建子线程,Thread#init方法在Thread的构造方法中被调用。在init方法中拷贝父线程数据到子线程中:
private void init(ThreadGroup g, Runnable target, String name,long stackSize, AccessControlContext acc,boolean inheritThreadLocals) {if (name == null) {throw new NullPointerException("name cannot be null");}if (inheritThreadLocals && parent.inheritableThreadLocals != null)this.inheritableThreadLocals =ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);this.stackSize = stackSize;tid = nextThreadID();
}
但InheritableThreadLocal仍然有缺陷,一般我们做异步化处理都是使用的线程池,而InheritableThreadLocal是在new Thread中的init()方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个TransmittableThreadLocal组件就可以解决这个问题,这里就不再延伸,感兴趣的可自行查阅资料。
ThreadLocal项目中使用实战
ThreadLocal使用场景
我们现在项目中日志记录用的是ELK+Logstash,最后在Kibana中进行展示和检索。
现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过 traceId 来关联,但是不同项目之间如何传递 traceId 呢?
这里我们使用 org.slf4j.MDC 来实现此功能,内部就是通过 ThreadLocal 来实现的,具体实现如下:
当前端发送请求到服务 A时,服务 A会生成一个类似UUID的traceId字符串,将此字符串放入当前线程的ThreadLocal中,在调用服务 B的时候,将traceId写入到请求的Header中,服务 B在接收请求时会先判断请求的Header中是否有traceId,如果存在则写入自己线程的ThreadLocal中。

图中的requestId即为我们各个系统链路关联的traceId,系统间互相调用,通过这个requestId即可找到对应链路,这里还有会有一些其他场景:
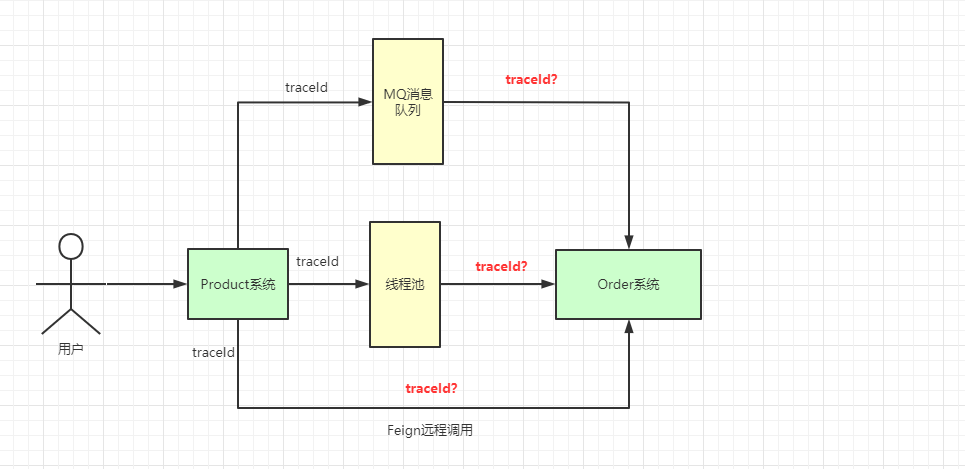
针对于这些场景,我们都可以有相应的解决方案,如下所示
Feign 远程调用解决方案
服务发送请求:
@Component
@Slf4j
public class FeignInvokeInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate template) {String requestId = MDC.get("requestId");if (StringUtils.isNotBlank(requestId)) {template.header("requestId", requestId);}}
}
服务接收请求:
@Slf4j
@Component
public class LogInterceptor extends HandlerInterceptorAdapter {@Overridepublic void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) {MDC.remove("requestId");}@Overridepublic void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) {}@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY);if (StringUtils.isBlank(requestId)) {requestId = UUID.randomUUID().toString().replace("-", "");}MDC.put("requestId", requestId);return true;}
}
线程池异步调用,requestId 传递
因为MDC是基于ThreadLocal去实现的,异步过程中,子线程并没有办法获取到父线程ThreadLocal存储的数据,所以这里可以自定义线程池执行器,修改其中的run()方法:
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {@Overridepublic void execute(Runnable runnable) {Map<String, String> context = MDC.getCopyOfContextMap();super.execute(() -> run(runnable, context));}@Overrideprivate void run(Runnable runnable, Map<String, String> context) {if (context != null) {MDC.setContextMap(context);}try {runnable.run();} finally {MDC.remove();}}
}
使用 MQ 发送消息给第三方系统
在 MQ 发送的消息体中自定义属性requestId,接收方消费消息后,自己解析requestId使用即可。
相关文章:
ThreadLocal 源码级别详解
ThreadLocal简介 稍微翻译一下: ThreadLocal提供线程局部变量。这些变量与正常的变量不同,因为每一个线程在访问ThreadLocal实例的时候(通过其get或set方法)都有自己的、独立初始化的变量副本。ThreadLocal实例通常是类中的私有静…...

训练营day17
110.平衡二叉树 力扣题目链接 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。 示例 1: 给定二叉树 [3,9,20,null,null,15,7] 返回 true 。 示…...
Nodejs原型链污染
Nodejs与JavaScript和JSON 有一些人在学习JavaScript时会分不清Nodejs和JavaScript之间的区别,如果没有node,那么我们的JavaScript代码则由浏览器中的JavaScript解析器进行解析。几乎所有的浏览器都配备了JavaScript的解析功能(最出名的就是…...

【Vue3】element-plus中el-tree的递归处理赋值回显问题
目录一:先获取所有权限tree二:在获取所有该角色能有的权限tree三:递归处理勾选tree节点由于项目是从0-1开始构建的 rbac都需要重新构建对接 所以涉及到了权限管理和菜单管理 一级菜单包含多个二级菜单 若二级不全选,则一级显示 半…...

C语言---宏
专栏:C语言 个人主页:HaiFan. 专栏简介:本专栏主要更新一些C语言的基础知识,也会实现一些小游戏和通讯录,学时管理系统之类的,有兴趣的朋友可以关注一下。 #define预处理预定义符号define#define定义标识符…...

算法导论—路径算法总结
图算法 单源最短路径 Bellman-Ford算法: 顶点为V,边为E的图 对每条边松弛|V|-1次边权可以为负值若存在一个可以从源结点到达的权值为负值的环路,算法返回False时间复杂度:O(VE) 有向无环图单源最短路径 DAG-SHORTEST-PATHS …...

程序环境--翻译+执行
ANSI C标准下,有两种程序环境。 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。 翻译环境包括:预处理(预编译)编译汇编链接。四个步骤。 第2种是执行/运行环境,它用于实际执行代码。 链接…...

微信小程序内部那些事
微信小程序没有window、document,它更像是一个类似 Node.js 的宿主环境。因此在小程序内部不能使用 document.querySelector 这样的选择器,也不支持 XMLHttpRequest、location、localStorage 等浏览器 API,只能使用小程序自己提供的 API&…...

这是从零在独自开开发,将是副业赚钱最好的平台!
文章目录最重要的事情放前面1.前言2.简单介绍一下3.【独自开】介绍3.1 分层标准化平台架构3.2 集成第三方数字接口3.3 支持各个行业的系统定制开发4.如何在【独自开】赚钱获取收益?4.1 如何称为【独自开】开发者?最重要的事情放前面 通过平台的审核也可以得到相应的奖金&…...

Spring MVC 之获取参数(对象、JSON格式数据、URL地址参数、文件、Cookie)
文章目录1. 获取单个参数2. 获取多个参数3. 获取对象4. 后端参数重命名 RequestParam5. 接收 JSON 格式的数据 RequestBody6. 从 URL 地址中获取参数 PathVariable7. 上传文件 RequestPart8. 获取Cookie (CookieValue)/Session/header8.1 获取 Request 和 Response 对象8.2 获取…...

永磁同步电机中BEMF电阻的作用
一、电路原理图 二、原理分析 如图一我们测的是相电压,从理论上我们知道我们测得相电压是一个马鞍波形,马鞍波形中并没有隐含 转子的位置和速度信息。那么为什么我们还要有这样一个电路呢? 这个问题其实困惑了我好久?直到有一天…...

JAVA练习45-二叉树的层序遍历
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 提示:这里可以添加本文要记录的大概内容: 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目二叉树的层序遍历 …...

超高精度PID调节器的特殊功能(3)——变送输出(转发)功能及其应用
摘要:变送输出是高级PID控制器的一项重要扩展功能,可用于多区控制、串级控制、比值控制和差值控制以及数据采集及记录。为展示变送输出功能的强大作用,本文主要针对超高精度VPC 2021系列PID控制器,介绍了变送输出的具体功能、参数…...
【C++】nullptr C++中的空指针(C++11)
前言 在平时我们写C/C代码时你可能会看到有人使用NULL表示空指针,也有人用nullptr表示空指针,那么你可能会很好奇它们都是空指针吗?为什么空指针有两种写法?下面就带你了解这背后的原理。 我们都知道NULL是C语言中的空指针&#x…...

笔试题-2023-大疆-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.08.07应聘岗位:数字IC设计笔试平台:赛码题目评价 难易程度:★★★★★知识覆盖:★★★☆☆超纲范围:★★★☆☆值得一刷:★★★…...
)
Python dict字典方法完全攻略(全)
我们知道,Python 字典的数据类型为 dict,我们可使用 dir(dict) 来查看该类型包含哪些方法,例如: >>> dir(dict) [clear, copy, fromkeys, get, items, keys, pop, popitem, setdefault, update, values] keys()、value…...

用“AI“挑选一件智慧礼物
在久违的烟火气回归之际,充满希望的生活可能就从精心挑选一件新年礼物开始。在罗列礼品清单时,你会想到 “数据”也是其中之一吗?事实上,几乎所有时下最受欢迎的带有“智能”一词的设备,都是由大量高质量的数据创建。我…...
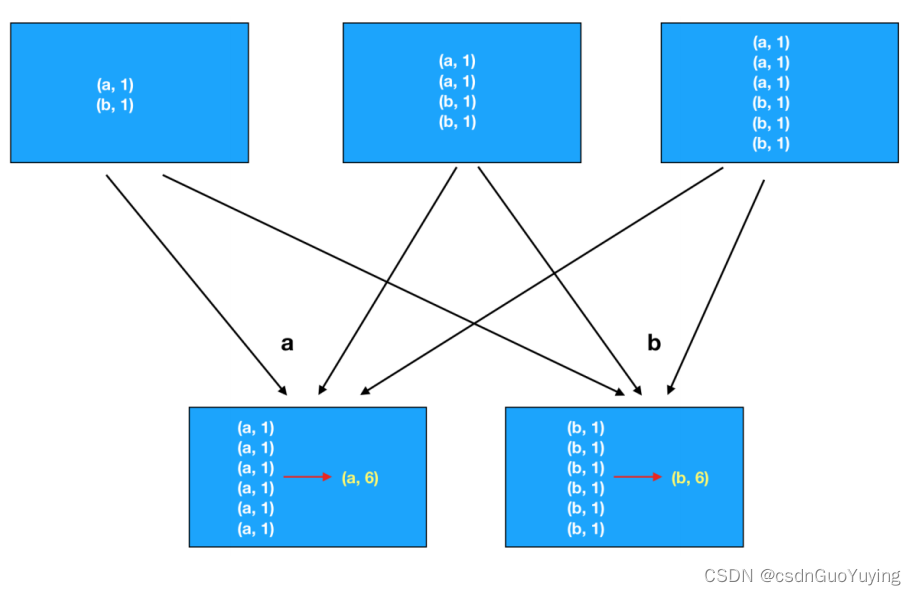
【Spark分布式内存计算框架——Spark Core】4. RDD函数(下) 重分区函数、聚合函数
重分区函数 如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。 1)、增加分区函数 函数名称:repartition,此函数使用的谨慎,会产生Shuffle。 2)、…...

智能工厂自动化设备如何将数据采集到物联网云平台上
制造业工厂在进行生产管理、数字化转型升级的过程中,大量自动化设备的数据采集上云一直是困扰厂商的难题之一。因设备种类多、工艺复杂、设备老旧无多余通信接口导致数据无法集中、工艺无法实时管控,加上设备服务商的本地支持比较有限,因此设…...

SpringBoot整合Mybatis的核心原理
0. 前言:1. 自动配置类MybatisAutoConfiguration:1.1. SqlSessionFactory的生成:1.2. Mapper的扫描和代理生成:1.2.1. MapperScannerConfigurer1.2.2. MapperFactoryBean1.2.3. getMapper生成代理对象2. 小结:0. 前言&…...

如何永久保存你的数字生活记忆:WeChatMsg数据守护终极指南
如何永久保存你的数字生活记忆:WeChatMsg数据守护终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

Flutter Riverpod:状态管理的新纪元
Flutter Riverpod:状态管理的新纪元告别 Provider 的繁琐,拥抱 Riverpod 的简洁与强大。一、为什么选择 Riverpod? 作为一名追求代码如散文般优雅的 UI 匠人,我对状态管理工具有着近乎偏执的要求。Riverpod 不仅解决了 Provider 的…...

2026届必备的十大降AI率平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 旨在降低AIGC检测率的工具,其发挥功效的途径多种多样。其一,借助对词…...

.NET AgentFramework实战:构建高可用多智能体工作流与微服务集成
1. 为什么需要多智能体工作流? 在现代化企业级应用中,业务逻辑往往涉及多个服务的协同处理。想象一下电商系统中的订单处理流程:需要同时调用库存服务、支付服务、物流服务和风控系统。传统做法是编写硬编码的调用链,但这种紧耦合…...

CNVD通用型漏洞挖掘思路,平台漏洞列表一眼定睛法!网络安全挖漏洞零基础入门到精通教程!
有一种艺术叫做,我只需看一眼就能一眼定睛其实最有效率挖cnvd的方法是在于平台本身公布出的漏洞,因为绝对不止一个漏洞这里比如我们看web应用(其他类型都可以看看)一般我们看第一页的漏洞信息就够的了,这里我们点最新的那个KingPortal开发系统存在弱口令,很好,继续挖…...

NoSleep防休眠工具:彻底解决Windows系统意外休眠的终极方案
NoSleep防休眠工具:彻底解决Windows系统意外休眠的终极方案 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 在数字化办公时代,电脑意外休眠已成为影响工…...

如何利用网站地图优化门户网站 SEO
如何利用网站地图优化门户网站 SEO 在当今互联网时代,网站地图(Sitemap)不仅是搜索引擎提高网站可访问性的重要工具,也是提升门户网站搜索引擎优化(SEO)效果的关键。本文将详细探讨如何利用网站地图来优化…...
--- CodeActAgent)
拆解 OpenHands(8)--- CodeActAgent
在 OpenHands 智能框架的生态中,CodeActAgent 占据着核心地位,它是基于 CodeAct 理念构建的核心代理模块。其设计初衷极具巧思:将各类复杂任务统一转化为 “代码执行” 的形式来完成,同时兼顾自然语言对话的交互特性。这一设计既保…...
)
绝版图书购书方案问题(折半枚举 / Meet-in-the-Middle)
绝版图书购书方案问题(折半枚举 / Meet-in-the-Middle) 📚 绝版图书购书方案问题(折半枚举 / Meet-in-the-Middle) 一、题目描述 输入 输出 样例输入 样例输出 提示 二、题目解读 2.1 什么是"购书方案"? 2.2 样例解释 三、算法选择分析 3.1 为什么不能直接用…...
)
保姆级教程:用PyTorch从零搭建联邦学习MNIST实验环境(附完整代码)
联邦学习实战:PyTorch搭建MNIST实验环境全流程解析 1. 联邦学习与MNIST实验概述 联邦学习作为一种分布式机器学习范式,正在重塑传统模型训练的方式。不同于集中式训练,联邦学习允许多个客户端在保持数据本地化的前提下协作训练模型࿰…...