【Spark分布式内存计算框架——Spark Core】4. RDD函数(下) 重分区函数、聚合函数
重分区函数
如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。
1)、增加分区函数
函数名称:repartition,此函数使用的谨慎,会产生Shuffle。

2)、减少分区函数
函数名称:coalesce,此函数不会产生Shuffle,当且仅当降低RDD分区数目。
比如RDD的分区数目为10个分区,此时调用rdd.coalesce(12),不会对RDD进行任何操作。

3)、调整分区函数
在PairRDDFunctions(此类专门针对RDD中数据类型为KeyValue对提供函数)工具类中
partitionBy函数:

范例演示代码,适当使用函数调整RDD分区数目:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD中分区函数,调整RDD分区数目,可以增加分区和减少分区
*/
object SparkPartitionTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 读取本地文件系统文本文件数据
val datasRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data", minPartitions = 2)
// TODO: 增加RDD分区数
val etlRDD: RDD[String] = datasRDD.repartition(3)
println(s"EtlRDD 分区数目 = ${etlRDD.getNumPartitions}")
// 词频统计
val resultRDD: RDD[(String, Int)] = etlRDD
// 数据分析,考虑过滤脏数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词,注意去除左右空格
.flatMap(line => line.trim.split("\\s+"))
// 转换为二元组,表示单词出现一次
.mapPartitions{iter =>
iter.map(word => (word, 1))
}
// 分组聚合,按照Key单词
.reduceByKey((tmp, item) => tmp + item)
// 输出结果RDD
resultRDD
// TODO: 对结果RDD降低分区数目
.coalesce(1)
.foreachPartition(iter => iter.foreach(println))
// 应用程序运行结束,关闭资源
sc.stop()
}
}
在实际开发中,什么时候适当调整RDD的分区数目呢?让程序性能更好好呢????
第一点:增加分区数目
- 当处理的数据很多的时候,可以考虑增加RDD的分区数目

第二点:减少分区数目
- 其一:当对RDD数据进行过滤操作(filter函数)后,考虑是否降低RDD分区数目

- 其二:当对结果RDD存储到外部系统

聚合函数
在数据分析领域中,对数据聚合操作是最为关键的,在Spark框架中各个模块使用时,主要就是其中聚合函数的使用。
集合中聚合函数
回顾列表List中reduce聚合函数核心概念:聚合的时候,往往需要聚合中间临时变量。查看列表List中聚合函数reduce和fold源码如下:

通过代码,看看列表List中聚合函数使用:

运行截图如下所示:

fold聚合函数,比reduce聚合函数,多提供一个可以初始化聚合中间临时变量的值参数:

聚合操作时,往往聚合过程中需要中间临时变量(到底时几个变量,具体业务而定),如下案例:

RDD 中聚合函数
在RDD中提供类似列表List中聚合函数reduce和fold,查看如下:

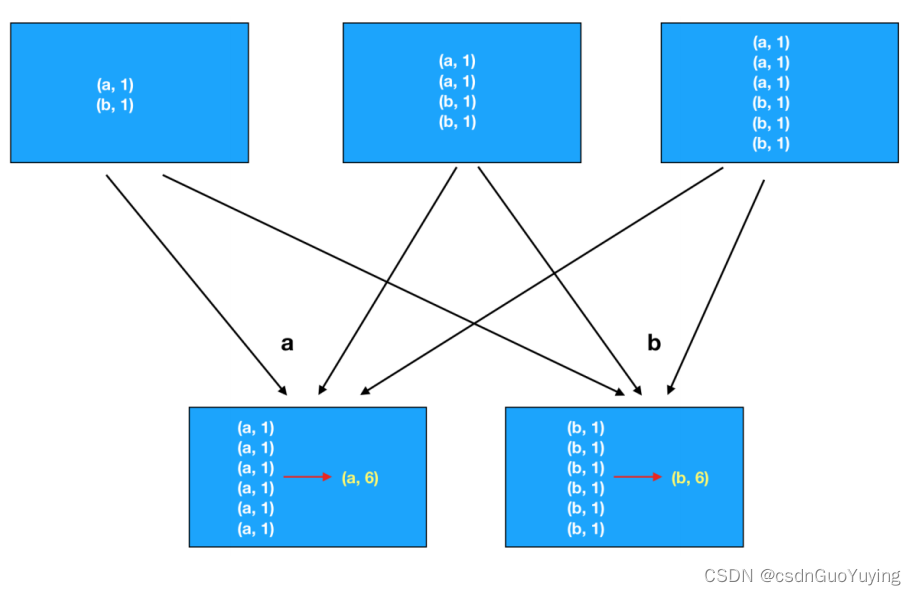
案例演示:求列表List中元素之和,RDD中分区数目为2,核心业务代码如下:

运行原理分析:

使用RDD中fold聚合函数:

查看RDD中高级聚合函数aggregate,函数声明如下:

业务需求:使用aggregate函数实现RDD中最大的两个数据,分析如下:

核心业务代码如下:

运行结果原理剖析示意图:

上述完整范例演示代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
/**
* RDD中聚合函数:reduce、aggregate函数
*/
object SparkAggTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 模拟数据,1 到 10 的列表,通过并行方式创建RDD
val datas = 1 to 10
val datasRDD: RDD[Int] = sc.parallelize(datas, numSlices = 2)
// 查看每个分区中的数据
datasRDD.foreachPartition{iter =>
println(s"p-${TaskContext.getPartitionId()}: ${iter.mkString(", ")}")
}
println("=========================================")
// 使用reduce函数聚合
val result: Int = datasRDD.reduce((tmp, item) => {
println(s"p-${TaskContext.getPartitionId()}: tmp = $tmp, item = $item")
tmp + item
})
println(result)
println("=========================================")
// 使用fold函数聚合
val result2: Int = datasRDD.fold(0)((tmp, item) => {
println(s"p-${TaskContext.getPartitionId()}: tmp = $tmp, item = $item")
tmp + item
})
println(result2)
println("=========================================")
// 使用aggregate函数获取最大的两个值
val top2: mutable.Seq[Int] = datasRDD.aggregate(new ListBuffer[Int]())(
// 分区内聚合函数,每个分区内数据如何聚合 seqOp: (U, T) => U,
(u, t) => {
println(s"p-${TaskContext.getPartitionId()}: u = $u, t = $t")
// 将元素加入到列表中
u += t //
// 降序排序
val top = u.sorted.takeRight(2)
// 返回
top
},
// 分区间聚合函数,每个分区聚合的结果如何聚合 combOp: (U, U) => U
(u1, u2) => {
println(s"p-${TaskContext.getPartitionId()}: u1 = $u1, u2 = $u2")
u1 ++= u2 // 将列表的数据合并,到u1中
//
u1.sorted.takeRight(2)
}
)
println(top2)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
PairRDDFunctions 聚合函数
在Spark中有一个object对象PairRDDFunctions,主要针对RDD的数据类型是Key/Value对的数据提供函数,方便数据分析处理。比如使用过的函数:reduceByKey、groupByKey等。*ByKey函数:将相同Key的Value进行聚合操作的,省去先分组再聚合。
第一类:分组函数groupByKey

第二类:分组聚合函数reduceByKey和foldByKey

但是reduceByKey和foldByKey聚合以后的结果数据类型与RDD中Value的数据类型是一样的。
第三类:分组聚合函数aggregateByKey

在企业中如果对数据聚合使用,不能使用reduceByKey完成时,考虑使用aggregateByKey函数,基本上都能完成任意聚合功能。
演示范例代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD中聚合函数,针对RDD中数据类型Key/Value对:
* groupByKey
* reduceByKey/foldByKey
* aggregateByKey
* combineByKey
*/
object SparkAggByKeyTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 1、并行化集合创建RDD数据集
val linesSeq: Seq[String] = Seq(
"hadoop scala hive spark scala sql sql", //
"hadoop scala spark hdfs hive spark", //
"spark hdfs spark hdfs scala hive spark" //
)
val inputRDD: RDD[String] = sc.parallelize(linesSeq, numSlices = 2)
// 2、分割单词,转换为二元组
val wordsRDD: RDD[(String, Int)] = inputRDD
.flatMap(line => line.split("\\s+"))
.map(word => word -> 1)
// TODO: 先使用groupByKey函数分组,再使用map函数聚合
val wordsGroupRDD: RDD[(String, Iterable[Int])] = wordsRDD.groupByKey()
val resultRDD: RDD[(String, Int)] = wordsGroupRDD.map{ case (word, values) =>
val count: Int = values.sum
word -> count
}
println(resultRDD.collectAsMap())
// TODO: 直接使用reduceByKey或foldByKey分组聚合
val resultRDD2: RDD[(String, Int)] = wordsRDD.reduceByKey((tmp, item) => tmp + item)
println(resultRDD2.collectAsMap())
val resultRDD3 = wordsRDD.foldByKey(0)((tmp, item) => tmp + item)
println(resultRDD3.collectAsMap())
// TODO: 使用aggregateByKey聚合
/*
def aggregateByKey[U: ClassTag]
(zeroValue: U) // 聚合中间临时变量初始值,类似fold函数zeroValue
(
seqOp: (U, V) => U, // 各个分区内数据聚合操作函数
combOp: (U, U) => U // 分区间聚合结果的聚合操作函数
): RDD[(K, U)]
*/
val resultRDD4 = wordsRDD.aggregateByKey(0)(
(tmp: Int, item: Int) => {
tmp + item
},
(tmp: Int, result: Int) => {
tmp + result
}
)
println(resultRDD4.collectAsMap())
// 应用程序运行结束,关闭资源
Thread.sleep(1000000)
sc.stop()
}
}
面试题
RDD中groupByKey和reduceByKey区别???
- reduceByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。

- groupByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的函数,将相同key的值聚合到一起,与reduceByKey的区别是只生成一个sequence。
相关文章:
【Spark分布式内存计算框架——Spark Core】4. RDD函数(下) 重分区函数、聚合函数
重分区函数 如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。 1)、增加分区函数 函数名称:repartition,此函数使用的谨慎,会产生Shuffle。 2)、…...

智能工厂自动化设备如何将数据采集到物联网云平台上
制造业工厂在进行生产管理、数字化转型升级的过程中,大量自动化设备的数据采集上云一直是困扰厂商的难题之一。因设备种类多、工艺复杂、设备老旧无多余通信接口导致数据无法集中、工艺无法实时管控,加上设备服务商的本地支持比较有限,因此设…...

SpringBoot整合Mybatis的核心原理
0. 前言:1. 自动配置类MybatisAutoConfiguration:1.1. SqlSessionFactory的生成:1.2. Mapper的扫描和代理生成:1.2.1. MapperScannerConfigurer1.2.2. MapperFactoryBean1.2.3. getMapper生成代理对象2. 小结:0. 前言&…...

滴滴一面:order by 调优10倍,思路是啥?
背景说明: Mysql调优,是大家日常常见的调优工作。 所以,Mysql调优是一个非常、非常核心的面试知识点。 在40岁老架构师 尼恩的读者交流群(50)中,其相关面试题是一个非常、非常高频的交流话题。 近段时间,有小伙伴面…...

Vue框架学习篇(五)
Vue框架学习篇(五) 1 组件 1.1 组件的基本使用 1.1.1 基本流程 a 引入外部vue组件必须要的js文件 <script src"../js/httpVueLoader.js"></script>b 创建.vue文件 <template><!--公共模板内容--></template><script><!…...
(蓝桥杯 刷题全集)【备战(蓝桥杯)算法竞赛-第1天(基础算法-上 专题)】( 从头开始重新做题,记录备战竞赛路上的每一道题 )距离蓝桥杯还有75天
🏆🏆🏆🏆🏆🏆🏆 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录&a…...
C++——继承那些事儿你真的知道吗?
目录1.继承的概念及定义1.1继承的概念1.2 继承定义1.2.1定义格式1.2.2继承关系和访问限定符1.2.3继承基类成员访问方式的变化2.父类和子类对象赋值转换3.继承中的作用域4.派生类的默认成员函数5.继承与友元6. 继承与静态成员7.复杂的菱形继承及菱形虚拟继承如何解决数据冗余和二…...
leetcode 困难 —— N 皇后(简单递归)
(不知道为啥总是给这种简单的递归设为困难题,虽然优化部分很不错,但是题目太好过了) 题目: 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个…...
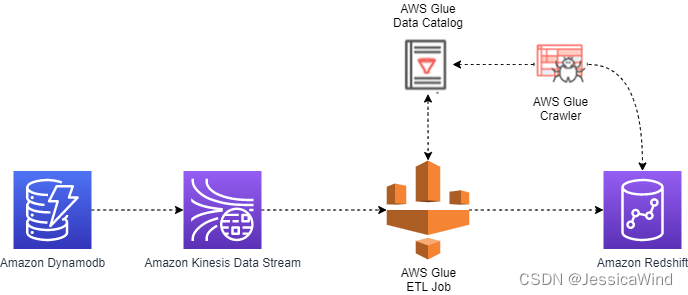
AWS实战:Dynamodb到Redshift数据同步
AWS Dynamodb简介 Amazon DynamoDB 是一种完全托管式、无服务器的 NoSQL 键值数据库,旨在运行任何规模的高性能应用程序。DynamoDB能在任何规模下实现不到10毫秒级的一致响应,并且它的存储空间无限,可在任何规模提供可靠的性能。DynamoDB 提…...
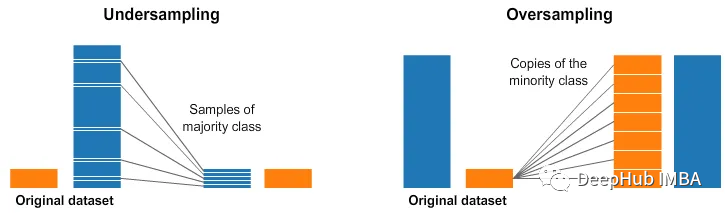
机器学习评估指标的十个常见面试问题
评估指标是用于评估机器学习模型性能的定量指标。它们提供了一种系统和客观的方法来比较不同的模型并衡量它们在解决特定问题方面的成功程度。通过比较不同模型的结果并评估其性能可以对使用哪些模型、如何改进现有模型以及如何优化给定任务的性能做出正确的决定,所…...

常见的安全问题汇总 学习记录
声明 本文是学习2017中国网站安全形势分析报告. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 2017年重大网站安全漏洞 CVE-2017-3248 :WebLogic 远程代码执行 2017年1月27日,WebLogic官方发布了一个编号为CVE-2017-3248 的…...

元宵晚会节目预告没有岳云鹏,是不敢透露还是另有隐情
在刚刚结束的元宵节晚会上,德云社的岳云鹏,再一次参加并引起轰动,并获得了观众朋友们的一致好评。 不过有细心的网友发现,早前央视元宵晚会节目预告,并没有看到小岳岳,难道是不敢提前透露,怕公布…...
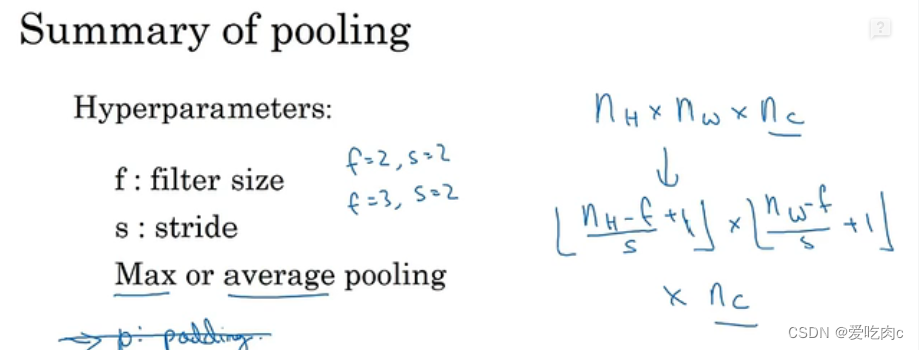
计算机视觉 吴恩达 week 10 卷积
文章目录一、边缘检测二、填充 padding1、valid convolution2、same convolution三、卷积步长 strided convolution四、三维卷积五、池化层 pooling六、 为什么要使用卷积神经网络一、边缘检测 可以通过卷积操作来进行 原图像 n✖n 卷积核 f✖f 则输出的图像为 n-f1 二、填充…...

JavaScript 函数定义
JavaScript 函数定义 函数是 JavaScript 中的基本组件之一。一个函数是 JavaScript 过程 — 一组执行任务或计算值的语句。要使用一个函数,你必须将其定义在你希望调用它的作用域内。 一个 JavaScript 函数用function关键字定义,后面跟着函数名和圆括号…...
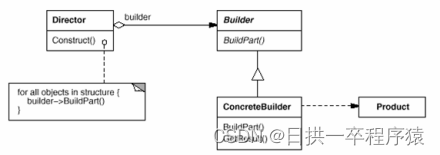
设计模式:建造者模式教你创建复杂对象
一、问题场景 当我们需要创建资源池配置对象的时候,资源池配置类里面有以下成员变量: 如果我们使用new关键字调用构造函数,构造函数参数列表就会太长。 如果我们使用set方法设置字段值,那minIdle<maxIdle<maxTotal的约束逻辑就没地方…...

在C++中将引用转换为指针表示
在C中将引用转换为指针表示 有没有办法在c 中"转换"对指针的引用?在下面的例子,func2已经定义了原型和我不能改变它,但func是我的API,我想为pass两个参数,或一(组和第二组,以NULL)或既不(均设置为NULL): void func2(some1 *p1, some2 *p2); func(some1…...

PS快速入门系列
01-界面构成 1菜单栏 2工具箱 3工县属性栏 4悬浮面板 5画布 ctr1N新建对话框(针对画布进行设置) 打开对话框:ctrl0(字母) 画布三种显示方式切换:F 隐藏工具箱,工具属性栏,悬浮面板…...

ASP.NET CORE 3.1 MVC“指定的网络名不再可用\企图在不存在的网络连接上进行操作”的问题解决过程
ASP.NET CORE 3.1 MVC“指定的网络名不再可用\企图在不存在的网络连接上进行操作”的问题解决过程 我家里的MAC没这个问题。这个是在windows上发生的。 起因很简单我用ASP.NET CORE 3.1 MVC做个项目做登录将数据从VIEW post到Controller上结果意外的报了错误。 各种百度都说…...
JVM从看懂到看开Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

服务器常用的41个状态码及其对应的含义
服务器常用的状态码及其对应的含义如下: 100——客户必须继续发出请求 101——客户要求服务器根据请求转换HTTP协议版本 200——交易成功 201——提示知道新文件的URL 202——接受和处理、但处理未完成 203——返回信息不确定或不完整 204——请求收到&#…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...
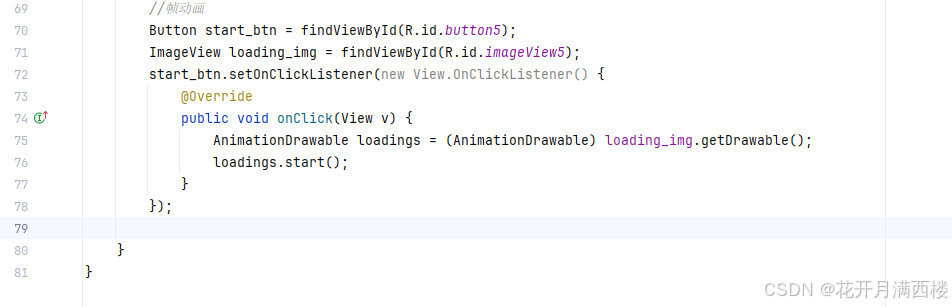
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...