INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践
INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践
文章目录
- INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践
- 结构稀疏
- 量化
- 在 TensorRT 中部署稀疏量化模型的工作流程
- 案例研究:ResNet-34
- 要求
- 第 1 步:从密集模型中进行稀疏化和微调
- 第 2 步:量化 PyTorch 模型
- PTQ 通过 TensorRT 校准
- QAT 通过 pytorch-quantization 工具包
- 第三步:部署TensorRT引擎
- 结果
深度学习 (DL) 模型的训练阶段包括学习大量密集的浮点权重矩阵,这导致推理过程中需要进行大量的浮点计算。 研究表明,可以通过强制某些权重为零来跳过其中许多计算,而对最终精度的影响很小。
与此同时,之前的帖子表明较低的精度(例如 INT8)通常足以在推理过程中获得与 FP32 相似的精度。 稀疏性和量化是流行的优化技术,用于解决这些问题,缩短推理时间并减少内存占用。
NVIDIA TensorRT 已经提供量化支持一段时间(从 2.1 版本开始),并且最近在 NVIDIA Ampere 架构 Tensor Cores 中内置了对稀疏性的支持,并在 TensorRT 8.0 中引入。
这篇文章是关于如何使用稀疏性和量化技术使用 TensorRT 加速 DL 模型的分步指南。 尽管已经单独讨论了这些优化中的每一个,但仍然需要展示从训练到使用 TensorRT 部署的端到端工作流,同时考虑这两种优化。
在这篇文章中,我们旨在弥合这一差距并帮助您了解稀疏量化训练工作流程是什么样的,就 TensorRT 加速方面的稀疏性最佳实践提出建议,并展示 ResNet-34 的端到端案例研究.
结构稀疏
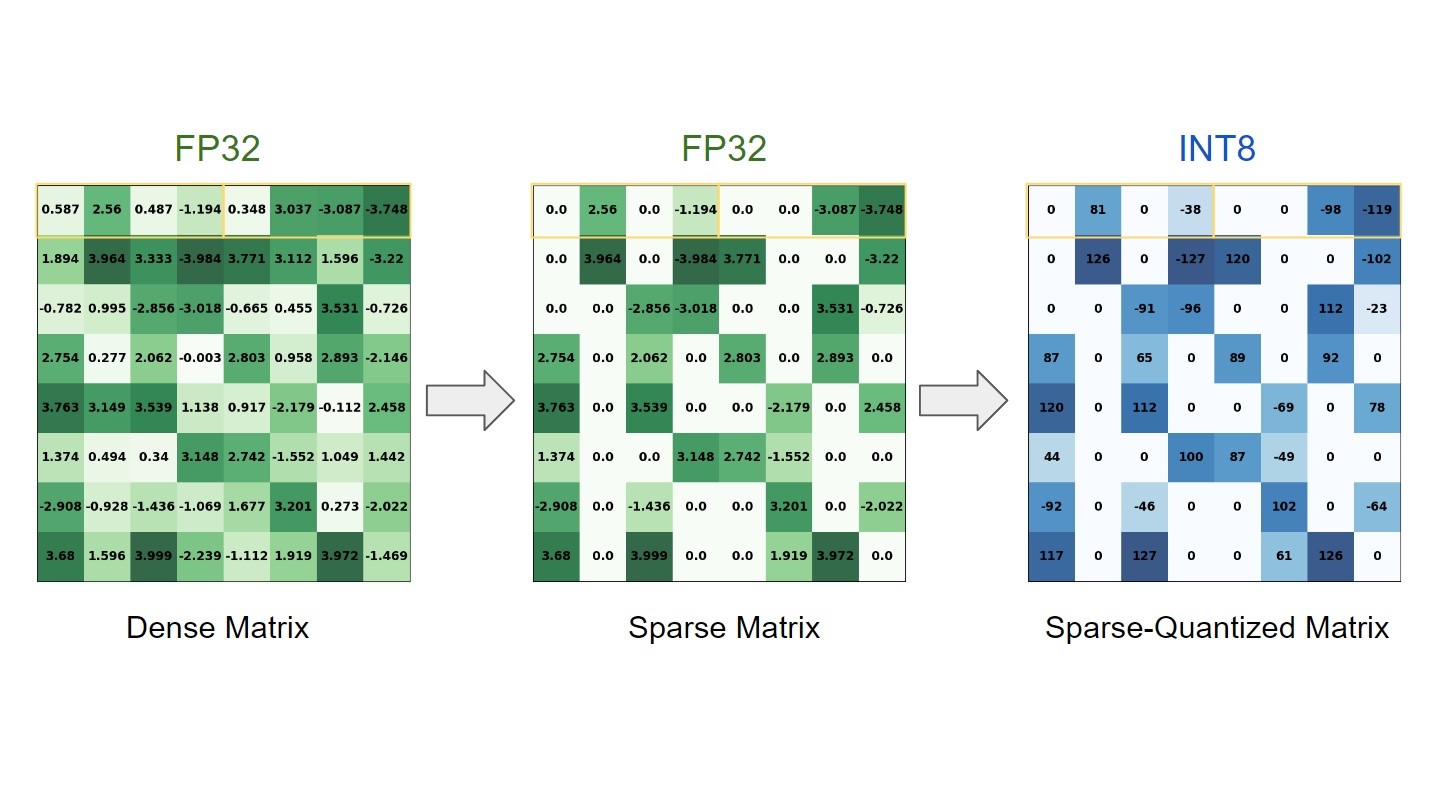
NVIDIA 稀疏张量核心使用 2:4 模式,这意味着四个值的每个连续块中的两个必须为零。 换句话说,我们遵循 50% 的细粒度结构化稀疏度配方,由于直接在 Tensor Core 上提供可用支持,因此不会对零值进行任何计算。 这导致在相同的时间内计算更多的工作量。 在这篇文章中,我们将此过程称为修剪。
有关详细信息,请参阅使用 NVIDIA Ampere 架构和 NVIDIA TensorRT 通过稀疏性加速推理。
量化
量化是指将连续的无限值映射到一组有限的离散值(例如,FP32 到 INT8)的过程。 这篇文章中讨论了两种主要的量化技术:
- 训练后量化 (PTQ):使用隐式量化工作流程。 在隐式量化网络中,每个量化张量都有一个关联的标度,用于通过校准对值进行隐式量化和反量化。 然后 TensorRT 检查该层运行速度更快的精度并相应地执行它。
- 量化感知训练 (QAT):使用显式量化工作流程。 显式量化网络利用量化和反量化 (Q/DQ) 节点来明确指示必须量化哪些层。 这意味着您可以更好地控制在 INT8 中运行哪些层。 有关详细信息,请参阅 Q/DQ 层布局建议。
有关量化基础知识、PTQ 和 QAT 量化技术之间的比较、何时选择哪种量化的见解以及 TensorRT 中的量化的更多信息,请参阅使用 NVIDIA TensorRT 的量化感知训练实现 INT8 推理的 FP32 精度。
在 TensorRT 中部署稀疏量化模型的工作流程
在 TensorRT 中部署稀疏量化模型的工作流程,以 PyTorch 作为 DL 框架,有以下步骤:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 通过 PTQ 或 QAT 工作流程量化稀疏化模型。
- 在 TensorRT 中部署获得的稀疏 INT8 引擎。
下图显示了所有三个步骤。 步骤 2 中的一个区别是 Q/DQ 节点存在于通过 QAT 生成的 ONNX 图中,但在通过 PTQ 生成的 ONNX 图中不存在。 有关详细信息,请参阅使用 INT8。
鉴于此,这是 QAT 的完整工作流程:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 在 PyTorch 中量化、校准和微调稀疏模型。
- 将 PyTorch 模型导出到 ONNX。
- 通过 ONNX 生成 TensorRT 引擎。
- 在 TensorRT 中部署获得的 Sparse INT8 引擎。
另一方面,这是 PTQ 的完整工作流程:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 将 PyTorch 模型导出到 ONNX。
- 通过 TensorRT 构建器对稀疏化的 ONNX 模型进行校准和量化,生成 TensorRT 引擎。
- 在 TensorRT 中部署获得的稀疏 INT8 引擎。

案例研究:ResNet-34
本节演示了使用 ResNet-34 的稀疏量化工作流程的案例研究。 有关详细信息,请参阅 /SparsityINT8 GitHub 存储库中的完整代码示例。
要求
以下是完成此案例研究所需的基本配置:
- Python 3.8
- PyTorch 1.11 (also tested with 2.0.0)
- PyTorch vision
- apex sparsity toolkit
- pytorch-quantization toolkit
- TensorRT 8.6
- Polygraphy
- ONNX opset>=13
- NVIDIA Ampere architecture GPU for Tensor Core support
本案例研究需要使用 ImageNet 2012 数据集进行图像分类。 有关下载数据集并将其转换为所需格式的更多信息,请参阅 GitHub 存储库上的自述文件。
稀疏训练、稀疏 QAT 模型微调和稀疏 PTQ 模型校准需要此数据集。 它还用于评估模型。
第 1 步:从密集模型中进行稀疏化和微调
加载预训练的密集模型并增强模型和优化器以进行稀疏训练。 有关详细信息,请参阅 NVIDIA/apex/tree/master/apex/contrib/sparsity 文件夹。
import copy
from torchvision import models
from apex.contrib.sparsity import ASP# Load dense model
model_dense = models.__dict__["resnet34"](pretrained=True)# Initialize sparsity mode before starting sparse training
model_sparse = copy.deepcopy(model_dense)
ASP.prune_trained_model(model_sparse, optimizer)# Re-train model
for e in range(0, epoch):for i, (image, target) in enumerate(data_loader):image, target = image.to(device), target.to(device)output = model_sparse(image)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()# Save model
torch.save(model_sparse.state_dict(), "sparse_finetuned.pth")
第 2 步:量化 PyTorch 模型
您可以为此步骤选择两种量化方法:PTQ 或 QAT。
PTQ 通过 TensorRT 校准
此选项将 PyTorch 模型导出到 ONNX 并通过 TensorRT Python API 对其进行校准。 这会生成校准缓存和准备部署的 TensorRT 引擎。
将稀疏 PyTorch 模型导出到 ONNX:
dummy_input = torch.randn(batch_size, 3, 224, 224, device="cuda")
torch.onnx.export(model_sparse, dummy_input, "sparse_finetuned.onnx", opset_version=13, do_constant_folding=True)使用校准数据集校准在上一步中导出的 ONNX 模型。 以下代码示例假定 ONNX 模型具有静态输入形状和批量大小。
from infer_engine import infer
from polygraphy.backend.trt import Calibrator, CreateConfig, EngineFromNetwork, NetworkFromOnnxPath, TrtRunner, SaveEngine
from polygraphy.logger import G_LOGGER# Data loader argument to `Calibrator`
def calib_data(val_batches, input_name):for iteration, (images, labels) in enumerate(val_batches):yield {input_name: images.numpy()}# Set path to ONNX model
onnx_path = "sparse_finetuned.onnx"# Set calibrator
calibration_cache_path = onnx_path.replace(".onnx", "_calibration.cache")
calibrator = Calibrator(data_loader=calib_data(data_loader_calib, args.onnx_input_name), cache=calibration_cache_path
)# Build engine from ONNX model by enabling INT8 and sparsity weights, and providing the calibrator
build_engine = EngineFromNetwork(NetworkFromOnnxPath(onnx_path),config=CreateConfig(int8=True,calibrator=calibrator,sparse_weights=True)
)# Trigger engine saving
engine_path = onnx_path.replace(".onnx", ".engine")
build_engine = SaveEngine(build_engine, path=engine_path)# Calibrate engine (activated by the runner)
with G_LOGGER.verbosity(G_LOGGER.VERBOSE), TrtRunner(build_engine) as runner:print("Calibrated engine!")# Infer PTQ engine and evaluate its accuracylog_file = engine_path.split("/")[-1].replace(".engine", "_accuracy.txt")infer(engine_path,data_loader_test,batch_size=args.batch_size,log_file=log_file)QAT 通过 pytorch-quantization 工具包
此选项使用 pytorch-quantization 工具包在稀疏 PyTorch 模型中添加 Q/DQ 节点,对其进行校准,并对其进行微调几个 epoch。 然后将微调后的模型导出到 ONNX 并转换为 TensorRT 引擎进行部署。
为确保已计算的稀疏浮点权重不会被覆盖,确保 QAT 权重也将结构化为稀疏,您必须再次准备模型进行剪枝。
在加载微调的稀疏权重之前初始化 QAT 模型和优化器以进行修剪。 稀疏掩码重新计算也必须禁用,因为它们已经在步骤 1 中计算过。这需要一个自定义函数,该函数是对 APEX 工具包的 prune_trained_model 函数的轻微修改。 修改在代码示例中突出显示:
from apex.contrib.sparsity import ASPdef prune_trained_model_custom(model, optimizer, compute_sparse_masks=False):asp = ASP()asp.init_model_for_pruning(model, mask_calculator="m4n2_1d", verbosity=2, whitelist=[torch.nn.Linear, torch.nn.Conv2d], allow_recompute_mask=False)asp.init_optimizer_for_pruning(optimizer)if compute_sparse_masks:asp.compute_sparse_masks()为了优化 Q/DQ 节点放置,您必须修改模型的定义以量化残差分支,如 pytorch-quantization 工具包示例所示。 例如,对于ResNet,需要在残差分支中添加Q/DQ节点的修改突出显示如下:
from pytorch_quantization import nn as quant_nnclass BasicBlock(nn.Module):def __init__(self, ..., quantize: bool = False) -> None:super().__init__()...if self._quantize:self.residual_quantizer = quant_nn.TensorQuantizer(quant_nn.QuantConv2d.default_quant_desc_input)def forward(self, x: Tensor) -> Tensor:identity = x...if self._quantize:out += self.residual_quantizer(identity)else:out += identityout = self.relu(out)return out
必须对 Bottleneck 类重复相同的修改,并且必须通过 ResNet、_resnet 和 resnet34 函数传播量化 bool 参数。 完成这些修改后,使用 quantize=True 实例化模型。 有关详细信息,请参阅 resnet.py 中的第 734 行。
通过 QAT 量化稀疏模型的第一步是在模型中启用量化和剪枝。 第二步是加载微调的稀疏检查点,对其进行校准,然后最后对该模型进行一些 epoch 的微调。 有关 collect_stats 和 compute_amax 函数的更多信息,请参阅 calibrate_quant_resnet50.ipynb。
# Add Q/DQ nodes to the dense model
from pytorch_quantization import quant_modules
quant_modules.initialize()
model_qat = models.__dict__["resnet34"](pretrained=True, quantize=True)# Initialize sparsity mode before starting Sparse-QAT fine-tuning
prune_trained_model_custom(model_qat, optimizer, compute_sparse_masks=False)# Load Sparse weights
load_dict = torch.load("sparse_finetuned.pth")
model_qat.load_state_dict(load_dict["model_state_dict"])# Calibrate model
collect_stats(model_qat, data_loader_calib, num_batches=len(data_loader_calib))
compute_amax(model_qat, method="entropy”)# Fine-tune model
for e in range(0, epoch):for i, (image, target) in enumerate(data_loader):image, target = image.to(device), target.to(device)output = model_qat(image)...# Save model
torch.save(model_qat.state_dict(), "quant_finetuned.pth")要准备部署 TensorRT 引擎,您必须将稀疏量化 PyTorch 模型导出到 ONNX。 TensorRT 期望 QAT ONNX 模型指示哪些层应该通过一组 QuantizeLinear 和 DequantizeLinear ONNX 操作进行量化。 在将量化的 PyTorch 模型导出到 ONNX 时,通过启用伪量化来满足此要求。
from pytorch_quantization import nn as quant_nn
quant_nn.TensorQuantizer.use_fb_fake_quant = True
dummy_input = torch.randn(batch_size, 3, 224, 224, device="cuda")
torch.onnx.export(model_qat, dummy_input, "quant_finetuned.onnx", opset_version=13, do_constant_folding=True)最后,构建 TensorRT 引擎:
$ trtexec --onnx=quant_finetuned.onnx --int8 --sparsity=enable --saveEngine=quant_finetuned.engine --skipInference
第三步:部署TensorRT引擎
$ trtexec --loadEngine=quant_finetuned.engine -v
结果
以下是在配备 TensorRT 8.6-GA (8.6.1.6) 的 NVIDIA A40 GPU 上针对 ResNet-34 密集量化和稀疏量化模型在分类精度和运行时方面的性能测量。 要重现这些结果,请遵循上一节中描述的工作流程。
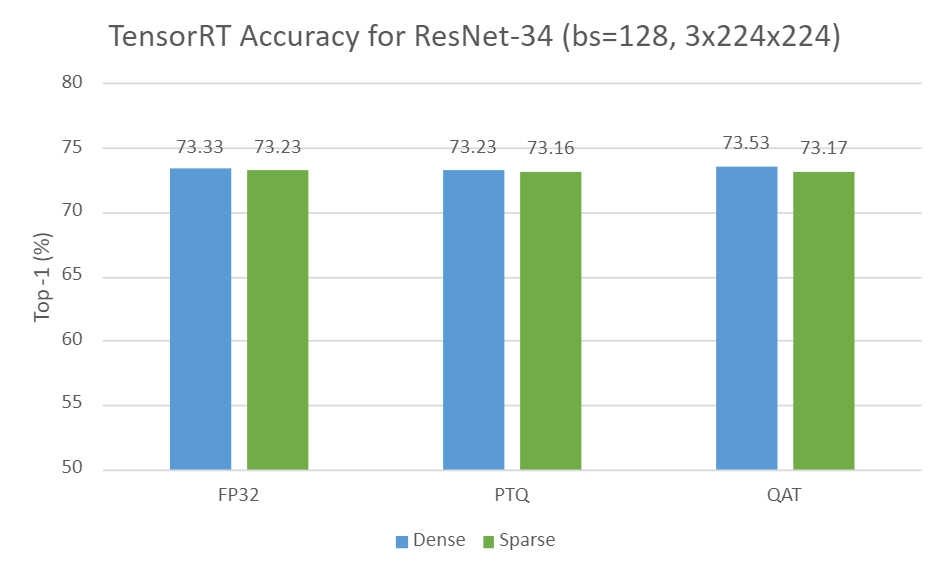
下图显示了 TensorRT 中 ResNet-34 在三种设置下的密集精度与稀疏精度的比较:
- FP32 中的密集与稀疏
- INT8 中的密集 PTQ 与稀疏 PTQ
- INT8 中的密集 QAT 与稀疏 QAT
如您所见,与所有设置的密集变体相比,稀疏变体在很大程度上可以保持准确性。
相关文章:
INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践
INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践 文章目录 INT8 中的稀疏性:加速的训练工作流程和NVIDIA TensorRT 最佳实践结构稀疏量化在 TensorRT 中部署稀疏量化模型的工作流程案例研究:ResNet-34要求第 1 步:…...

隧道模式HTTP代理使用代码示例
以下是使用Python实现隧道模式HTTP代理的代码示例: python import socket def handle_client(client_socket): # 接收客户端请求 request client_socket.recv(4096) # 解析请求头,获取目标主机和端口号 host request.split(b\r\n)[1].sp…...

翻筋斗觅食海鸥优化算法-附代码
翻筋斗觅食海鸥优化算法 文章目录 翻筋斗觅食海鸥优化算法1.海鸥优化算法2. 改进海鸥优化算法2.1 非线性参数 A 策略2.2 翻筋斗觅食策略 3.实验结果4.参考文献5.Matlab代码6.python代码 摘要:针对基本海鸥优化算法(SOA)在处理复杂优化问题中存在低精度、…...
K8S常见应用场景(六)
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。 Kubernetes 这个名字源于希腊语,意为“…...

《不抱怨的世界》随记
*不抱怨的世界 * 1.天才只有三件事:我的事,他的事,老天的事。抱怨自己的的人,应该试着学习接纳自己;抱怨他人的人,应该试着把抱怨转成请求;抱怨老天的人么,请试着用祈祷的方式来诉求…...
2.2 利用MyBatis实现CRUD操作
一、准备工作 打开MyBatisDemo项目 二、查询表记录 1、在映射器配置文件里引入结果映射元素 在UserMapper.xml文件里创建结果映射元素 将UserMapper接口里抽象方法上的注解暂时注释掉 运行TestUserMapper测试类里的testFindAll()测试方法,查看结果 2、添加…...
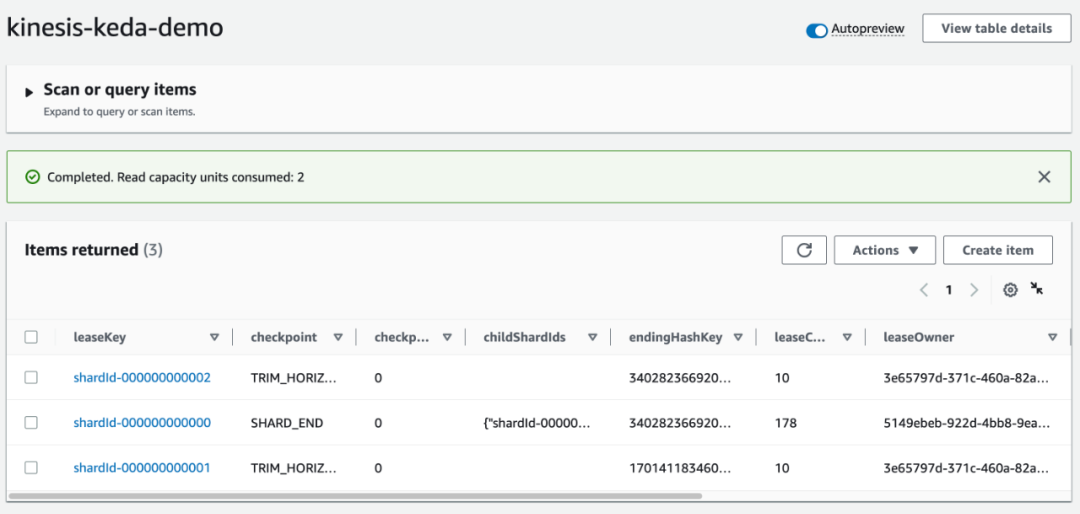
自动缩放Kubernetes上的Kinesis Data Streams应用程序
想要学习如何在Kubernetes上自动缩放您的Kinesis Data Streams消费者应用程序,以便节省成本并提高资源效率吗?本文提供了一个逐步指南,教您如何实现这一目标。 通过利用Kubernetes对Kinesis消费者应用程序进行自动缩放,您可以从其…...

介绍js各种事件
目录 一、点击事件 二、鼠标移动事件 三、键盘事件 四、滚轮事件 五、拖放事件 六、窗口大小改变事件 一、点击事件 点击事件是指当用户单击页面上的某个元素时触发的事件。这是最常见和基础的事件之一,也是Web应用程序中最常用的交互之一。 以下是如何使用…...

Python 将 CSV 分割成多个文件
文章目录 使用 Pandas 在 Python 中创建 CSV 文件在 Python 中将 CSV 文件拆分为多个文件根据行拆分 CSV 文件根据列拆分 CSV 文件 总结 在本文中,我们将学习如何在 Python 中将一个 CSV 文件拆分为多个文件。 我们将使用 Pandas 创建一个 CSV 文件并将其拆分为多个…...
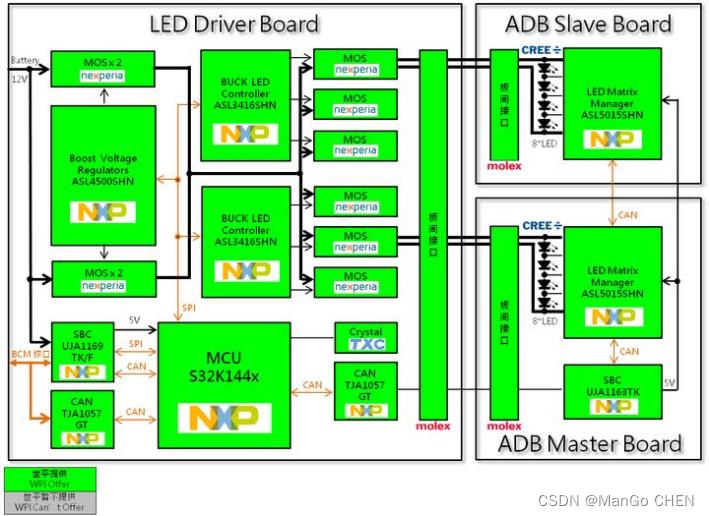
S32K144开发板
目录 一.S32K144开发板概述 二.产品技术和功能规格 三.开发环境 1.S32K144的开发环境主流是这么三种: 2.开发板Demo工程 四.S32K144开发板实物图 五、汽车大灯硬件架构 一.S32K144开发板概述 S32K14…...
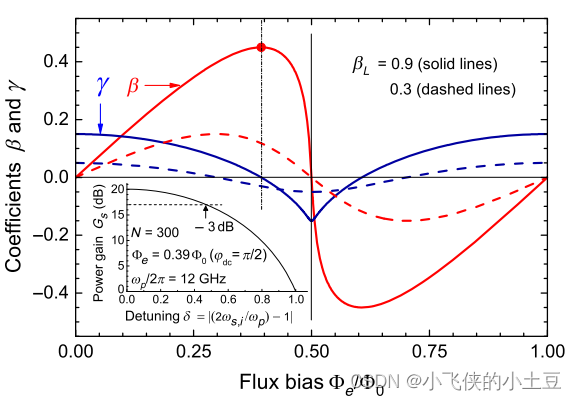
三波混频下的相位失配原理
原理推导 在四波混频情况下,实现零相位失配是一件很困难的事情。因为在四波混频中,相位调制和增益都依赖于相同的参数,即克尔非线性 γ \gamma γ。这个问题可以用嵌入在传输线上的辅助共振元件的复杂色散工程来部分解决。 但是在三波混频中…...

软考A计划-试题模拟含答案解析-卷一
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&am…...

Ubuntu下编译运行MicroPython Unix版本
文章目录 github拉取源码更新模块编译运行 github拉取源码 到Github(https://github.com/micropython/micropython)上下载源码 终端输入,如果提示识别不到gh命令,就sudo apt-get install gc安装一下。 再根据提示在终端里登录自己的github账号。 再次…...

实现用QCustomPlot封装的插件,放到绘图软件中可以点击和移动
首先,我们需要在绘图软件中创建一个插件,并将QCustomPlot控件添加到插件中。QCustomPlot是一个功能强大的绘图控件,可以轻松创建各种类型的图表,包括折线图、散点图、柱状图等等。 接下来,我们需要为QCustomPlot控件添加鼠标事件处理函数,以实现点击和移动的功能。QCust…...

【源码解析】Nacos配置热更新的实现原理
使用入门 使用RefreshScopeValue,实现动态刷新 RestController RefreshScope public class TestController {Value("${cls.name}")private String clsName;}使用ConfigurationProperties,通过Autowired注入使用 Data ConfigurationProperti…...

界面组件DevExpress ASP.NET Core v22.2 - UI组件升级
DevExpress ASP.NET Core Controls使用强大的混合方法,结合现代企业Web开发工具所期望的所有功能。该套件通过ASP.NET Razor标记和服务器端ASP.NET Core Web API的生产力和简便性,提供客户端JavaScript的性能和灵活性。ThemeBuilder工具和集成的Material…...

阿里系文生图(PAI+通义)
PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋 - 知乎作者:汪诚愚、段忠杰、朱祥茹、黄俊导读近年来,随着海量多模态数据在互联网的爆炸性增长和训练深度学习大模型的算力大幅提升,AI生成内容(AI Gen…...
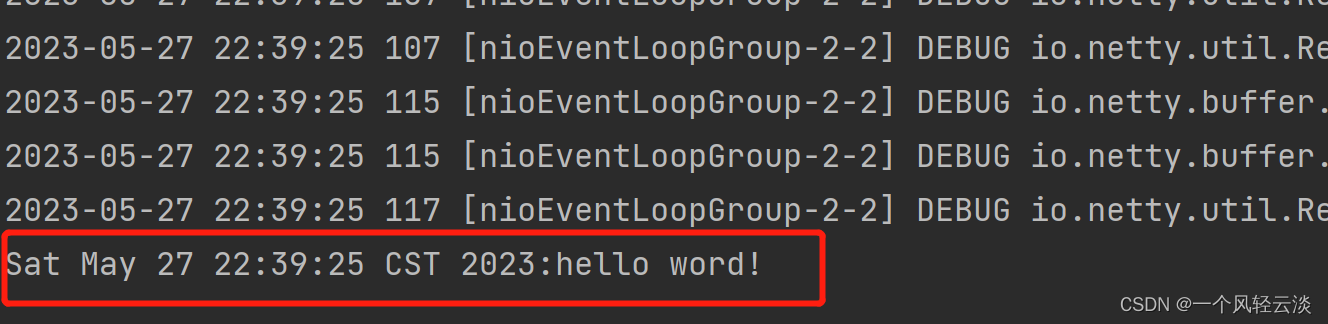
Netty概述及Hello word入门
目录 概述 Netty是什么 Netty的地位 Netty的优势 HelloWord入门程序 目标 pom依赖 服务器端 客户端 运行结果 入门把握理解 概述 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable hi…...
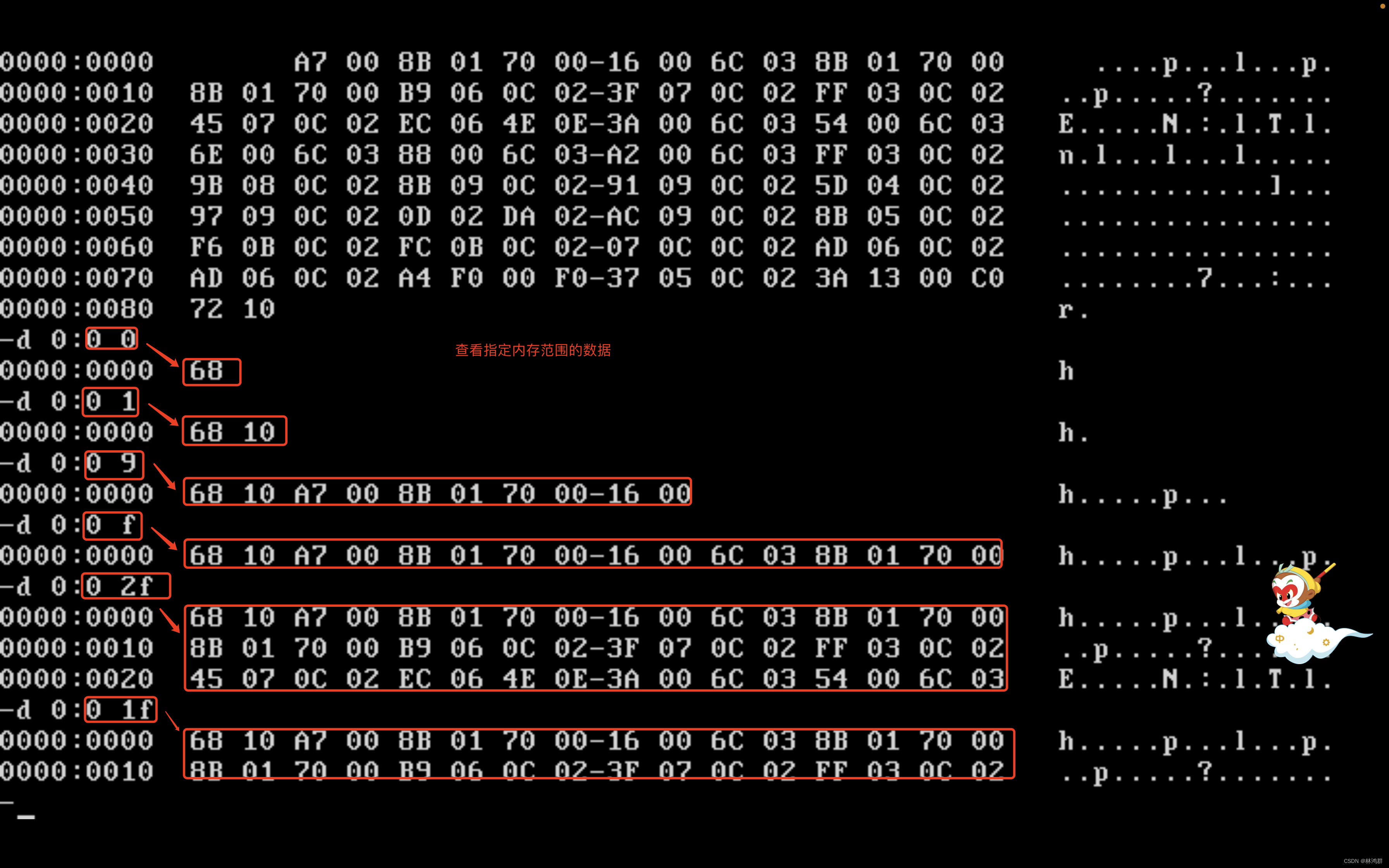
汇编寄存器之内存访问
1.内存中字的存储: 在CPU中用一个16位寄存器来存储一个字, 高8位存高字节,低8位存低字节 如AX寄存器存在一个字,那么AH存高字节,AL存低字节 在内存中存储字时是用两个连续的字节来存储字的, 这个字的低字节存在低单元,高字节存在高单元. 如下表示: 内存单元编号 单元中…...

C++进阶 —— lambda表达式(C++11新特性)
目录 一,模板函数sort 二,lambda表达式 一,模板函数sort 在C98中,如对一个数据集合中的元素进行排序,可使用模板函数sort,如元素为自定义类型,需定义排序时的比较规则;随着C的发展…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...