tidb变更大小写敏感问题的总结
作者: sustyle 原文来源: https://tidb.net/blog/2a72bc13
1 背景
近期,我们线上的tidb集群就遇到一个变更忽略大小写的需求,本来以为一个改表工单就解决了,但是业务反馈工单完成后,大小写仍旧敏感,本文就来总结一下这类需求可能遇到的问题以及如何避坑,仅供参考。
本文演示的实验环境是tidb 4.0.13版本。
tidb集群默认是大小写敏感,如果初始化集群的时候没有启用相关参数【new_collations_enabled_on_first_bootstrap】,后期想变更为忽略大小写就十分麻烦,可能还存在一定的风险。
2、问题复现
(1)准备测试环境
mysql> use tidbtest
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> create table t(id int not null primary key,name varchar(50) not null default '',age int not null default 0,unique key uk_name(name),key idx_age(age));
Query OK, 0 rows affected (0.07 sec)mysql> show create table t\G
*************************** 1. row ***************************Table: t
Create Table: CREATE TABLE `t` (`id` int(11) NOT NULL,`name` varchar(50) NOT NULL DEFAULT '',`age` int(11) NOT NULL DEFAULT '0',PRIMARY KEY (`id`),UNIQUE KEY `uk_name` (`name`),KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.01 sec)mysql> mysql> insert into t values(1,'a',10),(2,'A',11);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from t;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.00 sec)mysql> 测试表【t】id是主键字段,name是唯一索引字段,因为是大小写敏感,所以'a' 和 'A'是可以写进去的,唯一索引也是为了验证大小写敏感这一性质。
(2)修改排序集
mysql> alter table t modify `name` varchar(50) not null COLLATE utf8mb4_general_ci DEFAULT '';
Query OK, 0 rows affected (0.07 sec)mysql> show create table t\G
*************************** 1. row ***************************Table: t
Create Table: CREATE TABLE `t` (`id` int(11) NOT NULL,`name` varchar(50) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',`age` int(11) NOT NULL DEFAULT '0',PRIMARY KEY (`id`),UNIQUE KEY `uk_name` (`name`),KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
+----+------+-----+
1 row in set (0.00 sec)mysql> select * from t where name = 'A';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 2 | A | 11 |
+----+------+-----+
1 row in set (0.01 sec)mysql> 可以看到,修改排序集操作成功了,但是从实际测试看没有生效。
3、测试
经过查阅官方文档后发现是因为tidb从4.0开始支持collation规则但是默认是关闭的,对应的参数是new_collation_enabled。该参数在6.0版本开始默认开启。下面将该参数调整为True试试。
该参数对应的配置文件参数是 new_collations_enabled_on_first_bootstrap,要求是新集群才生效,即旧集群启用这个参数是无法启用collation规则,需要直接更改tidb系统的参数才生效。
(1)验证
mysql> select * from mysql.tidb where VARIABLE_NAME = 'new_collation_enabled';
+-----------------------+----------------+----------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-----------------------+----------------+----------------------------------------------------+
| new_collation_enabled | False | If the new collations are enabled. Do not edit it. |
+-----------------------+----------------+----------------------------------------------------+
1 row in set (0.00 sec)mysql> update mysql.tidb set VARIABLE_VALUE = 'True' where VARIABLE_NAME = 'new_collation_enabled' limit 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from mysql.tidb where VARIABLE_NAME = 'new_collation_enabled';
+-----------------------+----------------+----------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-----------------------+----------------+----------------------------------------------------+
| new_collation_enabled | True | If the new collations are enabled. Do not edit it. |
+-----------------------+----------------+----------------------------------------------------+
1 row in set (0.01 sec)mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
+----+------+-----+
1 row in set (0.00 sec)mysql> select * from t where name = 'A';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 2 | A | 11 |
+----+------+-----+
1 row in set (0.01 sec)mysql> 可以看到调整为True后还是不生效,原因是这个参数需要重启tidb组件才能生效。
tiup cluster reload cluster_name -R tidb
注意这里用的是reload。需要注意,这种情况下在线上一定不能reload或者重启,要不然容易引发故障,如下测试,查询会失效。
重启以后再次查看发现一个诡异的事情,之前的查询条件不管是使用小写还是大写现在都没法查询到数据,但是数据真实的存在表里,于是乎就想着走强制索引试试。
mysql> select * from mysql.tidb where VARIABLE_NAME = 'new_collation_enabled';
+-----------------------+----------------+----------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-----------------------+----------------+----------------------------------------------------+
| new_collation_enabled | True | If the new collations are enabled. Do not edit it. |
+-----------------------+----------------+----------------------------------------------------+
1 row in set (0.00 sec)mysql> use tidbtest
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> select * from t where name = 'a';
Empty set (0.00 sec)mysql> select * from t where name = 'A';
Empty set (0.00 sec)mysql> select * from t;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.00 sec)mysql>
如果name字段不带索引,这里的查询是可以查到数据的,而且是符合预期,即大小写不再敏感。
下面使用强制索引试试
mysql> select * from t where name = 'a';
Empty set (0.00 sec)mysql> select * from t force index(idx_age) where name = 'a';
Empty set (0.00 sec)mysql> desc select * from t force index(idx_age) where name = 'a';
+-------------+---------+------+------------------------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+------------------------------+---------------+
| Point_Get_1 | 1.00 | root | table:t, index:uk_name(name) | |
+-------------+---------+------+------------------------------+---------------+
1 row in set (0.00 sec)mysql> desc select * from t where name = 'a';
+-------------+---------+------+------------------------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+------------------------------+---------------+
| Point_Get_1 | 1.00 | root | table:t, index:uk_name(name) | |
+-------------+---------+------+------------------------------+---------------+
1 row in set (0.00 sec)mysql>可以看到强制索引并不能解决问题,通过执行计划发现还是走了uk_name这个索引。
起初以为跟这个表的数据量少有关系,后来追加了10000行测试数据发现结果还是一样。
后来尝试通过模糊查询发现只有将'%a'或者'%A'才能查到数据,且大小写已经不敏感。
mysql> select * from t where name like '%a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.01 sec)mysql> select * from t where name like '%a%';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.02 sec)mysql> select * from t where name like '%A';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.02 sec)mysql> select * from t where name like '%A%';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.02 sec)mysql> select id,concat('-',name,'-') name, age from t where name like '%a%';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | -a- | 10 |
| 2 | -A- | 11 |
+----+------+-----+
1 row in set (0.00 sec)mysql>
从测试结果猜测可能是uk_name这个索引的问题,忽略大小写且在唯一约束条件下,'a'和'A'能同时存在,这显然不合理,于是乎就想着重建这个索引。
mysql> alter table t drop index uk_name;
Query OK, 0 rows affected (0.26 sec)mysql> select * from t where name = 'A';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.01 sec)mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.02 sec)mysql> desc select * from t where name = 'A';
+-------------------------+---------+-----------+---------------+--------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------+---------+-----------+---------------+--------------------------------+
| TableReader_7 | 1.00 | root | | data:Selection_6 |
| └─Selection_6 | 1.00 | cop[tikv] | | eq(tidbtest.t.name, "A") |
| └─TableFullScan_5 | 2.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |
+-------------------------+---------+-----------+---------------+--------------------------------+
3 rows in set (0.00 sec)mysql> 可以看到删除uk_name这个索引后,查询就正常了。
mysql> alter table t add unique index uk_name(name);
ERROR 1062 (23000): Duplicate entry 'a' for key 'uk_name'
mysql> alter table t add index idx_name(name);
Query OK, 0 rows affected (0.26 sec)mysql> select * from t where name = 'a';
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | A |
+----+------+
2 rows in set (0.00 sec)mysql> select * from t where name = 'A';
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | A |
+----+------+
2 rows in set (0.01 sec)mysql>
因'a','A'是重复数据,所以没法加唯一索引,加一个普通二级索引。
4、解决方案
通过测试发现,这类需求比较棘手,那能不能解决呢?答案当然是肯定的,只是成本问题,下面提供两个方案,仅供参考。
(1)直接在原集群进行操作
这个方案适合小表的场景,主要考虑点是操作过程中对目标字段需要重建索引(如果有索引的话),所以要能容忍全表扫描带来的性能问题。
mysql> use tidbtest
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> select * from t where name = 'A';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 2 | A | 11 |
+----+------+-----+
1 row in set (0.00 sec)mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
+----+------+-----+
1 row in set (0.00 sec)mysql> alter table t modify `name` varchar(50) not null COLLATE utf8mb4_general_ci DEFAULT '';
ERROR 8200 (HY000): Unsupported modifying collation of column 'name' from 'utf8mb4_bin' to 'utf8mb4_general_ci' when index is defined on it.
mysql>
/*目标字段没有索引直接就能修改成功*/
如果目标字段是索引字段,则无法直接修改排序集,需要删除索引后再修改。
mysql> alter table t drop index uk_name;
Query OK, 0 rows affected (0.25 sec)mysql> alter table t modify `name` varchar(50) not null COLLATE utf8mb4_general_ci DEFAULT '';
Query OK, 0 rows affected (0.07 sec)mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.02 sec)mysql> alter table t add index idx_name(name);
Query OK, 0 rows affected (0.85 sec)
/*如果目标字段没有索引就忽略即可*/
/*如果目标字段是唯一索引则需要考虑重复值问题,有可能加不上*/mysql> select * from t where name = 'a';
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | a | 10 |
| 2 | A | 11 |
+----+------+-----+
2 rows in set (0.00 sec)mysql>
可以看到,大小写已经不敏感了。
(2)集群迁移(物理备份)
这个方案适合目标表是大表的场景。具体操作略,下面简单提供一个思路:
- 部署好一套新集群
- 利用br备份原集群
- 利用br将备份恢复到新集群
- 使用ticdc进行增量同步
- 待数据同步后,对新集群的目标表配置大小写不敏感
- 协同业务进行验证
- 切换流量,将业务流量切到新集群
另外,待数据同步后,是在新集群变更大小写敏感参数,因为新集群这时候未接受业务流量,所以重启,重建索引等可以放心操作,具体操作流程请参考第一个方案。
(3)集群迁移(逻辑备份)
这个方案适合目标表是大表的场景,这也是官方建议的方案。具体操作略,下面简单提供一个思路:
- 部署好一套新集群(初始化的时候直接启用new_collations_enabled_on_first_bootstrap参数)
- 利用逻辑备份工具备份旧集群
- 利用逻辑备份工具恢复数据到新集群
- 使用ticdc进行增量同步
- 待数据同步后,协同业务进行验证
- 切换流量,将业务流量切到新集群
这种架构可能存在一个问题,上游是大小写敏感,但是下游大小写不敏感,对于唯一索引字段可能会导致同步失败。
5、总结
官方建议有需要忽略大小写需求的话,在初始化集群的时候就启用该参数,已经初始化的集群,无法通过更改该配置项打开或关闭新的 collation 框架,但是我实际测试过程中发现直接变更【mysql.tidb】表的new_collation_enabled参数是能关闭或者开启的,而且也能符合预期。
(1)如果目标字段是非索引字段,直接变更字段排序集以及系统参数即可,待合适时间重新加载tidb组件即可生效。
(2)如果目标表是小表,全表扫描的查询成本与使用目标字段的索引的查询成本相差不大,也可直接参考第一点进行操作。
(3)如果目标表是大表,则需要慎重一些,需要考虑通过集群迁移的方式进行变更此类需求。
(4)如果集群已经启用 collation 框架,则不能对索引字段进行变更排序集操作,否则会报错。
new_collation_enabled=True
mysql> alter table t2 modify `name` varchar(50) not null COLLATE utf8mb4_general_ci DEFAULT '';
ERROR 8200 (HY000): Unsupported modifying collation of column 'name' from 'utf8mb4_bin' to 'utf8mb4_general_ci' when index is defined on it.
mysql>
综上所述,tidb集群想要变更大小写敏感问题需要考虑的风险点较多,需要用户根据自身环境进行充分评估测试,本文涉及的测试及方案仅供参考,非线上环境的操作建议。
如果存在上下游关系的架构中,一定要评估好风险,避免因调整了tidb的大小写敏感问题导致上下游同步异常。
6、写在最后
本文对tidb集群变更大小写敏感问题做了一下分析及总结,总体来说此类需求是存在一定的风险的,各公司的业务场景也不一样,需求也不同,还可能碰上其他未知的问题,本文所有内容仅供参考。
相关文章:

tidb变更大小写敏感问题的总结
作者: sustyle 原文来源: https://tidb.net/blog/2a72bc13 1 背景 近期,我们线上的tidb集群就遇到一个变更忽略大小写的需求,本来以为一个改表工单就解决了,但是业务反馈工单完成后,大小写仍旧敏感&…...

法规标准-UN R158标准解读
UN R158是做什么的? UN R158全名为针对驾驶员识别车辆后方弱势道路使用者,联合国对倒车系统和机动车的统一规定,该法规涉及批准倒车和机动车辆的装置,主要为保证倒车时避免碰撞,方便驾驶员观察了解车辆后部人员和物体…...
160个CrackMe之002
这道题就很简单 有了第一道题目的支持 我们就能做 首先 我们先要下载Msvbvm50.dll Msvbvm50.dll下载_Msvbvm50.dll最新版下载[修复系统丢失文件]-下载之家 然后我们可以运行程序了 比之前那个还简单 就是输入 然后比对 报错或者成功 开始逆向分析 先去常量中进行查找 找…...

3. 响应状态码及Response对象的status_code属性
3. 响应状态码及Response对象的status_code属性 文章目录 3. 响应状态码及Response对象的status_code属性1. 响应状态码2. 响应状态码共分为5种类型2.1 1xx(临时响应)2.2 2xx (成功)2.3 3xx (重定向)2.4 4x…...

MIME 类型列表 03
看表~按照内容类型排列的 MIME 类型列表 类型/子类型扩展名application/envoyevyapplication/fractalsfifapplication/futuresplashsplapplication/htahtaapplication/internet-property-streamacxapplication/mac-binhex40hqxapplication/msworddocapplication/msworddotappl…...

SpringBoot项目登录并接入MFA二次认证
MFA多因素认证(Multi-Factor Authentication ): 一些需要身份认证的服务(如网站),为了提升安全性,通常会在账号密码登录成功后,要求用户进行第二种身份认证,以确保是正确用户登录,避…...

算法与数据结构(三)
一、堆 1,堆结构就是用数组实现的完全二叉树结构 根节点的左孩子的下标为:2i1,右孩子为2i2。两个孩子的父节点为(i-1)/2向下取整 2,完全二叉树中如果每棵子树的最大值都在顶部就是大根堆 从下往上将孩子与父节点进行比较,如果子叶…...

亚马逊云科技出海日,让数字经济出海扩展到更多行业和领域
数字化浪潮之下,中国企业的全球化步伐明显提速。从“借帆出海”到“生而全球化”,中国企业实现了从传统制造业“中国产品”出口,向创新“中国技术”和先导“中国品牌”的逐步升级。 作为全球云计算的开创者与引领者,亚马逊云科技…...

Pb协议的接口测试
【摘要】 Protocol Buffers 是谷歌开源的序列化与反序列化框架。它与语言无关、平台无关、具有可扩展的机制。用于序列化结构化数据,此工具对标 XML ,支持自动编码,解码。比 XML 性能好,且数据易于解析。更多有关工具的介绍可参考…...
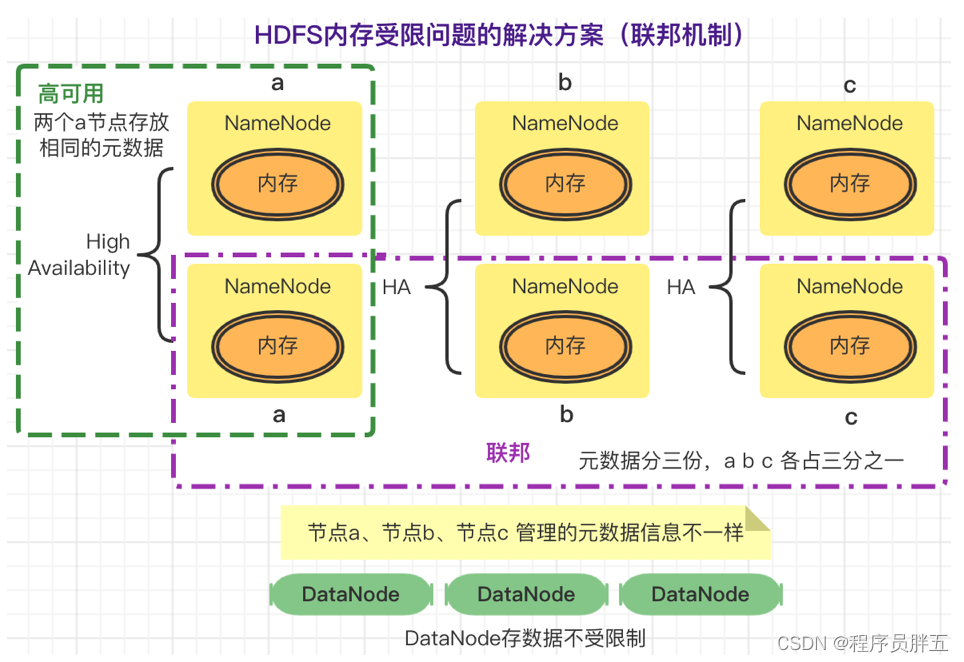
2. 分布式文件系统 HDFS
2. 分布式文件系统 HDFS 1. 引入HDFS【面试点】 问题一:如果一个文件中有 10 个数值,一行一个,并且都可以用 int 来度量。现在求 10 个数值的和 思路: 逐行读取文件的内容把读取到的内容转换成 int 类型把转换后的数据进行相加…...

借助金融科技差异化发展,不一样的“破茧”手法
撰稿 | 多客 来源 | 贝多财经 民营银行的诞生顺应了普惠金融的要求,承担着支持民营经济、服务小微的历史使命。经过近年来的发展,19家民营银行形成了特色化、差异化的发展模式,并用各自本领实践普惠金融的初心。 本文从多家民营银行在核心技…...

typescript中type、interface的区别
一、概念定义 interface:接口 在TS 中主要用于定义【对象类型】,可以对【对象】的形状进行描述。type :类型别名 为类型创建一个新名称,它并不是一个类型,只是一个别名。 二,区别 interface: …...

Ingress详解
Ingress Service对集群外暴露端口两种方式,这两种方式都有一定的缺点: NodePort :会占用集群集群端口,当集群服务变多时,缺点明显LoadBalancer:每个Service都需要一个LB,并且需要k8s之外设备支…...

【递归算法的Java实现及其应用】
文章目录 递归算法概述递归算法的实现步骤递归算法的Java实现递归算法的底层工作原理递归算法的底层代码讲解(优先级高)递归算法的实际应用场景递归算法在场景中解决的问题递归算法的优点和缺点总结 递归算法概述 递归算法是一种通过调用自身来解决问题…...
2023年度第四届全国大学生算法设计与编程挑战赛(春季赛)
目录 2023年度第四届全国大学生算法设计与编程挑战赛(春季赛)1、A2、Bx3、Cut4、Diff5、EchoN6、Farmer7、GcdGame8、HouseSub9、IMissYou!10、Jargonless 2023年度第四届全国大学生算法设计与编程挑战赛(春季赛) 1、A 题目描述…...

如何用PHP获取各大电商平台的数据
PHP获取API数据是指使用PHP语言从web服务中提取数据。API是指应用程序接口,它允许应用程序之间进行交互和通信,并且允许一个应用程序从另一个应用程序获取数据。PHP是一种网站开发语言,它可以使用多种方式来获取API数据。 在PHP中࿰…...
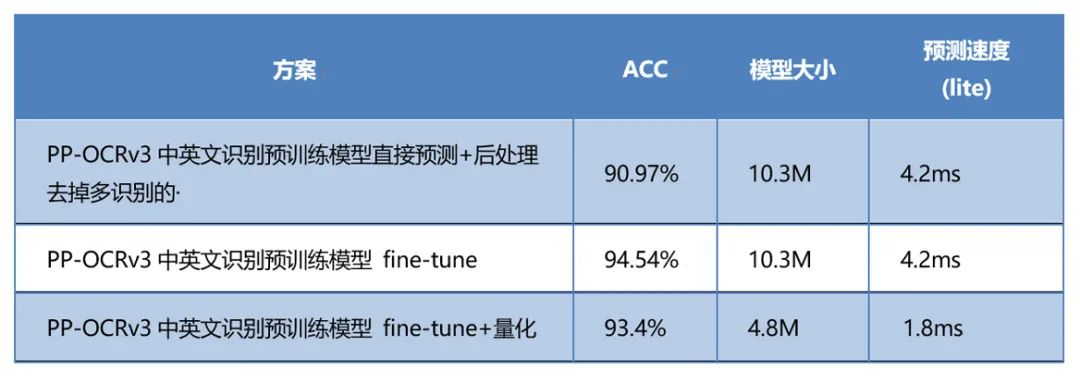
一站式完成车牌识别任务:从模型优化到端侧部署
交通领域的应用智能化不断往纵深发展,其中最为成熟的车牌识别早已融入人们的日常生活之中,在高速公路电子收费系统、停车场等场景中随处可见。一些企业在具体业务中倾向采用开源方案降低研发成本,但现有公开的方案中少有完成端到端的车牌应用…...
Linux4.8Nginx Rewrite
文章目录 计算机系统5G云计算第六章 LINUX Nginx Rewrite一、Nginx Rewrite 概述1.常用的Nginx 正则表达式2.rewrite和location3.location4.实际网站使用中,至少有三个匹配规则定义5.rewrite6.rewrite 示例 计算机系统 5G云计算 第六章 LINUX Nginx Rewrite 一、…...
DHT11温湿度传感器
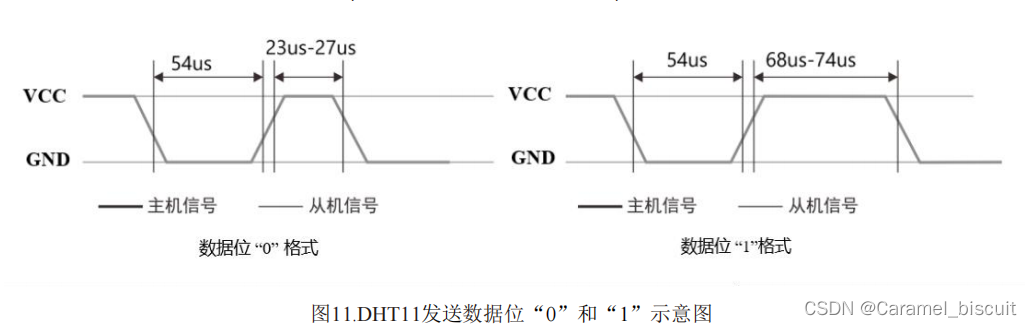
接口定义 传感器通信 DHT11采用简化的单总线通信。单总线仅有一根数据线(SDA),通信所进行的数据交换、挂在单总线上的所有设备之间进行信号交换与传递均在一条通讯线上实现。 单总线上必须有一个上拉电阻(Rp)以实现单…...

RestTemplate超简单上手
目录 1.什么是RestTemplate? 2.RestTemplate的使用 2.1spring环境下 注意1:RestTemplate中发送请求execute()和exchange()方法的区别 execute()方式 exchange()方式 二者的区别 注意2:进阶配置——底层HTTP客户端 2.2非spring环境下 1.什么是R…...

3DGS新手避坑指南:COLMAP命令行参数选错,你的Gaussian Splatting训练就白费了
3DGS新手避坑指南:COLMAP参数选择对Gaussian Splatting训练的关键影响 当你第一次接触3D Gaussian Splatting(3DGS)时,可能会被COLMAP预处理环节的各种参数搞得晕头转向。明明按照教程一步步操作,最后生成的3D模型却支…...

2023年数字图像处理实战:从噪声滤除到图像恢复的八大核心考题解析
1. 椒噪声滤除:自适应中值滤波实战 遇到图像布满黑白噪点(椒盐噪声)时,传统中值滤波直接暴力替换像素可能误伤细节。去年帮学弟调试车牌识别系统时就遇到过这种情况——滤波后车牌数字"7"直接变成了"1"。后来…...

大模型学习笔记——SAM模型:从Prompt到分割的通用视觉框架
1. SAM模型:当视觉分割遇上NLP提示工程 第一次接触SAM模型时,我正被传统图像分割项目折磨得焦头烂额。需要为每个新场景重新标注数据、调整模型参数的日子,直到遇见这个"分割一切"的视觉大模型才彻底改变。SAM(Segment …...

BiliTools终极指南:3分钟掌握跨平台B站资源管理工具
BiliTools终极指南:3分钟掌握跨平台B站资源管理工具 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 还在…...

雷石KTV惊艳7000系列专用云猫点歌系统刷机包|含刷机工具+硬盘系统文件|实测一键成功|可复刻部署
温馨提示:文末有联系方式 产品概览:专为雷石惊艳7000系列深度适配的云猫点歌系统刷机套件 本套件包含经实测验证的云猫点歌系统刷机包、配套刷机工具及完整硬盘系统文件,全面兼容雷石KTV惊艳7000系列主机。 所有组件已在多台设备上完成稳定刷…...

多语言语音识别新选择:Fun-ASR-MLT-Nano模型部署与应用
多语言语音识别新选择:Fun-ASR-MLT-Nano模型部署与应用 1. 项目概述与技术亮点 1.1 多语言语音识别新标杆 Fun-ASR-MLT-Nano-2512是阿里通义实验室推出的轻量级多语言语音识别模型,凭借800M参数的紧凑架构,实现了对31种语言的高精度识别。…...

G-Helper开源工具性能优化完全指南:从问题诊断到高级配置
G-Helper开源工具性能优化完全指南:从问题诊断到高级配置 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...

百度网盘直链解析技术:突破下载限制的Python解决方案
百度网盘直链解析技术:突破下载限制的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天,百度网盘作为国内主…...

零代码玩转Qwen3-TTS:WebUI界面操作,轻松克隆声音做配音
零代码玩转Qwen3-TTS:WebUI界面操作,轻松克隆声音做配音 1. 引言:声音克隆技术的新选择 如果你曾经想过为自己的视频配音,或者需要批量生成语音内容,但苦于没有专业录音设备和配音演员,Qwen3-TTS的WebUI界…...

硬件狗狗全方位硬件监控:实时掌握电脑运行状态
对于电脑用户来说,了解硬件的运行状态是非常重要的。 通过监控硬件的使用情况,用户可以及时发现问题,避免硬件过载,还可以优化系统的性能。 硬件狗狗在这方面提供了全面而实用的功能,帮助用户实时掌握电脑的运行状态…...