【ECCV2022】DaViT: Dual Attention Vision Transformers
DaViT: Dual Attention Vision Transformers, ECCV2022
解读:【ECCV2022】DaViT: Dual Attention Vision Transformers - 高峰OUC - 博客园 (cnblogs.com)
DaViT:双注意力Vision Transformer - 知乎 (zhihu.com)
DaViT: Dual Attention Vision Transformers - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2204.03645
代码:https://github.com/dingmyu/davit
动机
以往的工作一般是,在分辨率、全局上下文和计算复杂度之间权衡:像素级和patch级的self-attention要么是有二次计算成本,要么损失全局上下文信息。除了像素级和patch级的self-attention的变化之外,是否可以设计一个图像级的self-attention机制来捕获全局信息?
作者提出了Dual Attention Vision Transformers (DaViT),能够在保持计算效率的同时捕获全局上下文。提出的方法具有层次结构和细粒度局部注意的优点,同时采用 group channel attention,有效地建模全局环境。
创新点:
- 提出 Dual Attention Vision Transformers(DaViT),它交替地应用spatial window attention和channel group attention来捕获长短依赖关系。
- 提出 channel group attention,将特征通道划分为几个组,并在每个组内进行图像级别的交互。通过group attention,作者将空间和通道维度的复杂性降低到线性。
方法
dual attention
双attention机制是从两个正交的角度来进行self-attention:
一是对spatial tokens进行self-attention,此时空间维度(HW)定义了tokens的数量,而channel维度(C)定义了tokens的特征大小,这其实也是ViT最常采用的方式;
二是对channel tokens进行self-attention,这和前面的处理完全相反,此时channel维度(C)定义了tokens的数量,而空间维度(HW)定义了tokens的特征大小。
可以看出两种self-attention完全是相反的思路。为了减少计算量,两种self-attention均采用分组的attention:对于spatial token而言,就是在空间维度上划分成不同的windows,这就是Swin中所提出的window attention,论文称之为spatial window attention;而对于channel tokens,同样地可以在channel维度上划分成不同的groups,论文称之为channel group attention。
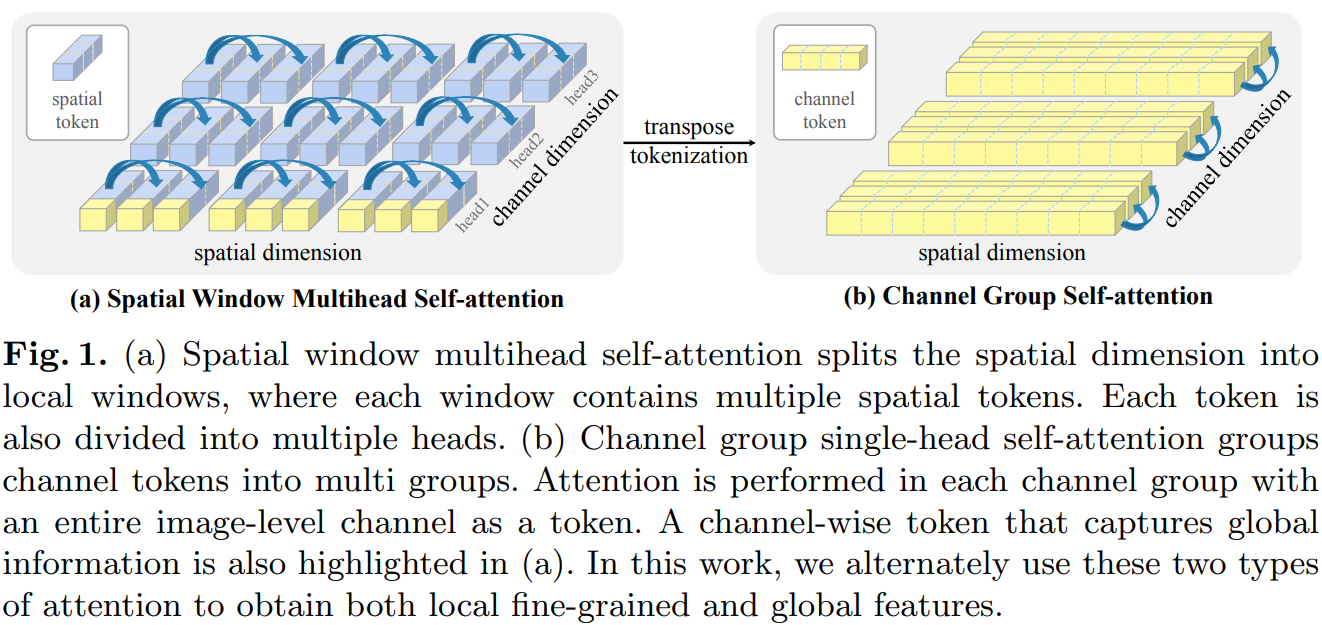
(a)空间窗口多头自注意将空间维度分割为局部窗口,其中每个窗口包含多个空间token。每个token也被分成多个头。(b)通道组单自注意组将token分成多组。在每个通道组中使用整个图像级通道作为token进行Attention。在(a)中也突出显示了捕获全局信息的通道级token。交替地使用这两种类型的注意力机制来获得局部的细粒度,以及全局特征。
两种attention能够实现互补:spatial window attention能够提取windows内的局部特征,而channel group attention能学习到全局特征,这是因为每个channel token在图像空间上都是全局的。
dual attention block
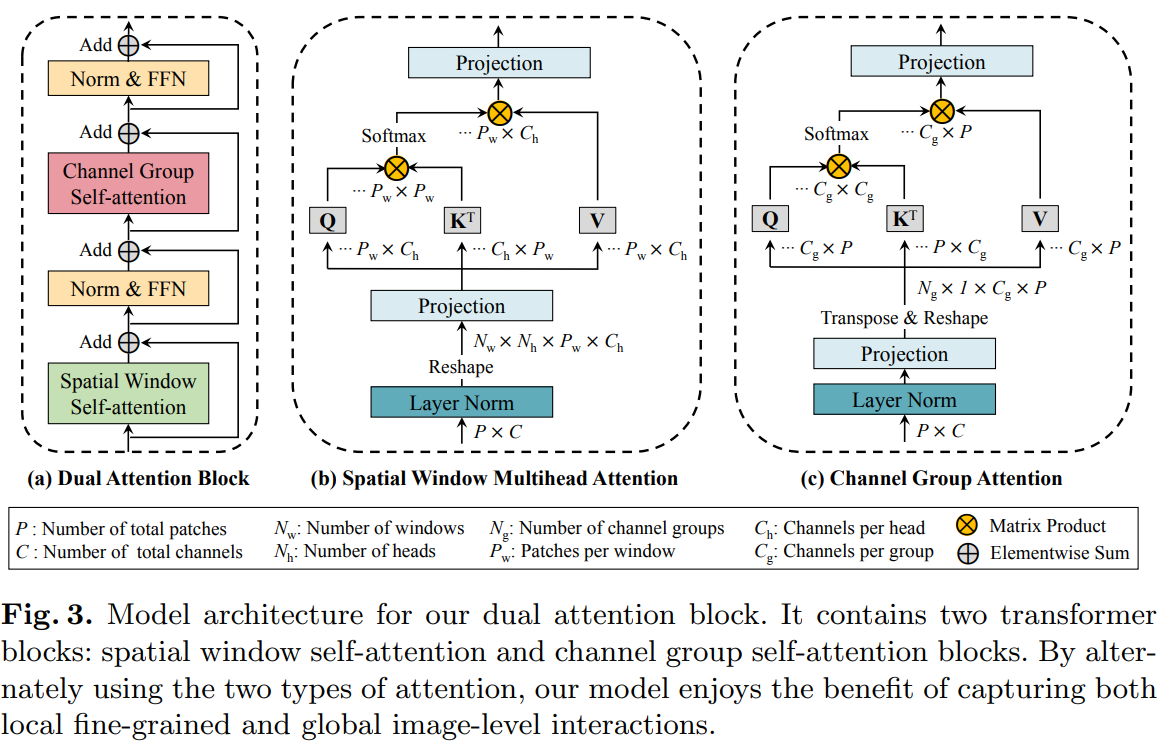
dual attention block的模型架构,它包含两个transformer block:空间window self-attention block和通道group self-attention block。通过交替使用这两种类型的attention机制,作者的模型能实现局部细粒度和全局图像级交互。图3(a)展示了作者的dual attention block的体系结构,包括一个空间window attention block和一个通道group attention block。
Spatial Window Attention
将patchs按照空间结构划分为Nw个window,每个window 里的patchs(Pw)单独计算self-attention:(P=Nw*Pw)
![]()
Channel Group Attention
将channels分为Ng个group,每个group的channel数量为Cg,有C=Ng*Cg,计算如下:
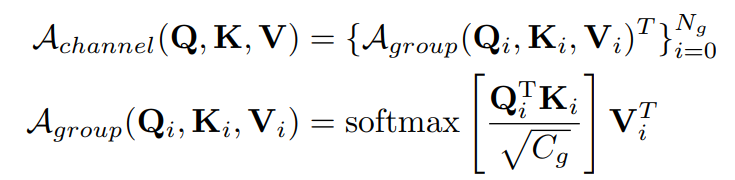
关键代码
class SpatialBlock(nn.Module):r""" Windows Block.Args:dim (int): Number of input channels.num_heads (int): Number of attention heads.window_size (int): Window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Truedrop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, num_heads, window_size=7,mlp_ratio=4., qkv_bias=True, drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,ffn=True, cpe_act=False):super().__init__()self.dim = dimself.ffn = ffnself.num_heads = num_headsself.window_size = window_sizeself.mlp_ratio = mlp_ratio# conv位置编码self.cpe = nn.ModuleList([ConvPosEnc(dim=dim, k=3, act=cpe_act),ConvPosEnc(dim=dim, k=3, act=cpe_act)])self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim,window_size=to_2tuple(self.window_size),num_heads=num_heads,qkv_bias=qkv_bias)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()if self.ffn:self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer)def forward(self, x, size):H, W = sizeB, L, C = x.shapeassert L == H * W, "input feature has wrong size"shortcut = self.cpe[0](x, size) # depth-wise convx = self.norm1(shortcut)x = x.view(B, H, W, C)pad_l = pad_t = 0pad_r = (self.window_size - W % self.window_size) % self.window_sizepad_b = (self.window_size - H % self.window_size) % self.window_sizex = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))_, Hp, Wp, _ = x.shapex_windows = window_partition(x, self.window_size)x_windows = x_windows.view(-1, self.window_size * self.window_size, C)# W-MSA/SW-MSAattn_windows = self.attn(x_windows)# merge windowsattn_windows = attn_windows.view(-1,self.window_size,self.window_size,C)x = window_reverse(attn_windows, self.window_size, Hp, Wp)if pad_r > 0 or pad_b > 0:x = x[:, :H, :W, :].contiguous()x = x.view(B, H * W, C)x = shortcut + self.drop_path(x)x = self.cpe[1](x, size) # 第2个depth-wise convif self.ffn:x = x + self.drop_path(self.mlp(self.norm2(x)))return x, sizeclass ChannelAttention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False):super().__init__()self.num_heads = num_heads # 这里的num_heads实际上是num_groupshead_dim = dim // num_headsself.scale = head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.proj = nn.Linear(dim, dim)def forward(self, x):B, N, C = x.shape# 得到query,key和value,是在channel维度上进行线性投射qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]k = k * self.scaleattention = k.transpose(-1, -2) @ v # 对维度进行反转attention = attention.softmax(dim=-1)x = (attention @ q.transpose(-1, -2)).transpose(-1, -2)x = x.transpose(1, 2).reshape(B, N, C)x = self.proj(x)return xDaViT采用金字塔结构,共包含4个stages,每个stage的开始时都插入一个 patch embedding 层。作者在每个stage叠加dual attention block,这个block就是将两种attention(还包含FFN)交替地堆叠在一起,其分辨率和特征维度保持不变。
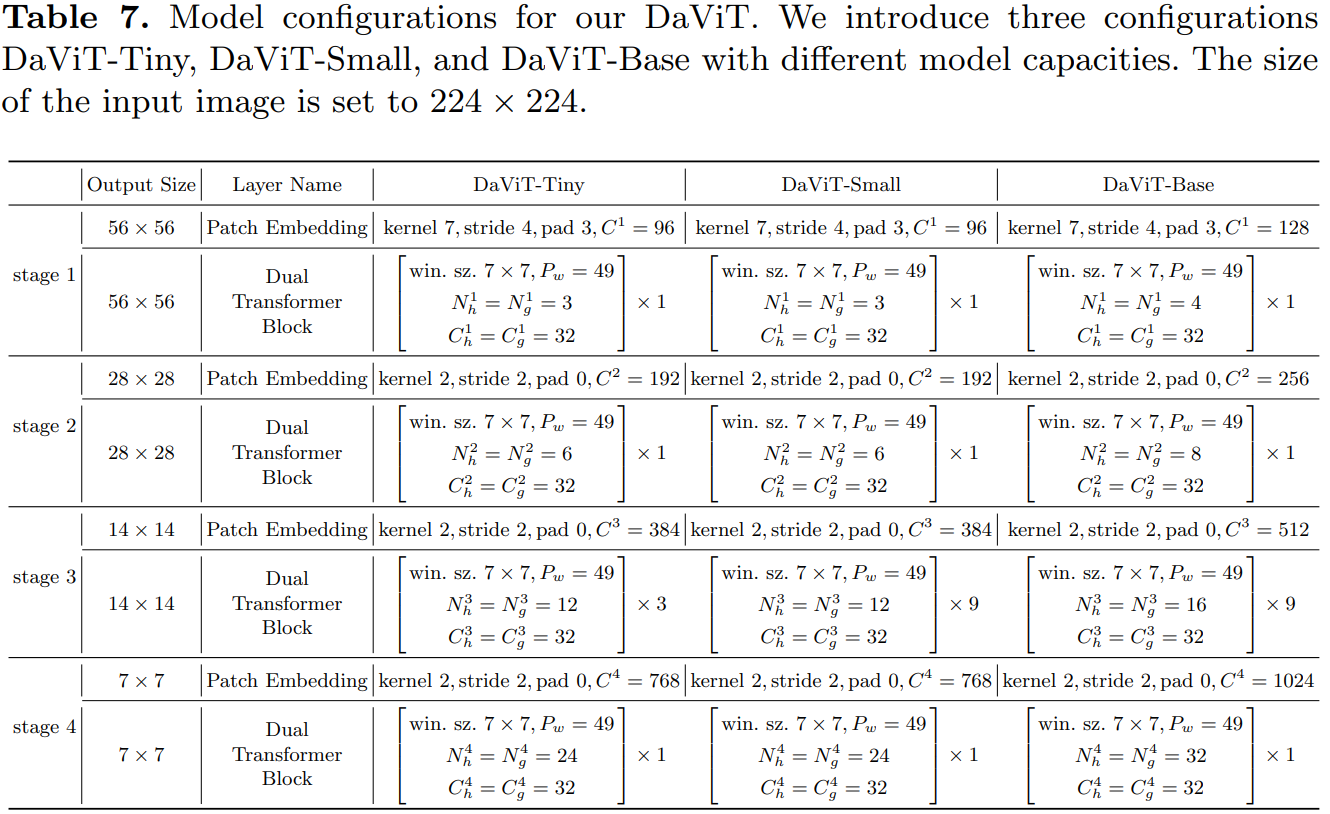
采用stride=4的7x7 conv,然后是4个stage,各stage通过stride=2的2x2 conv来进行降采样。其中DaViT-Tiny,DaViT-Small和DaViT-Base三个模型的配置如下所示:
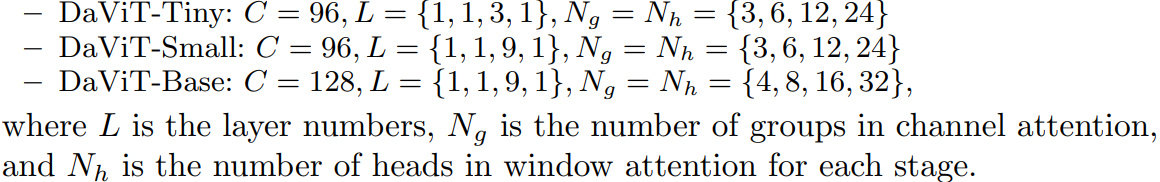
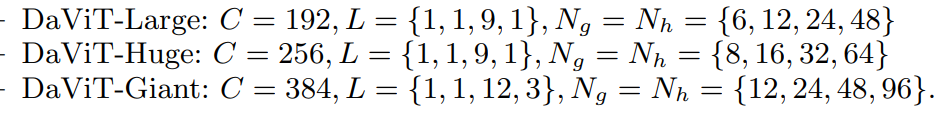
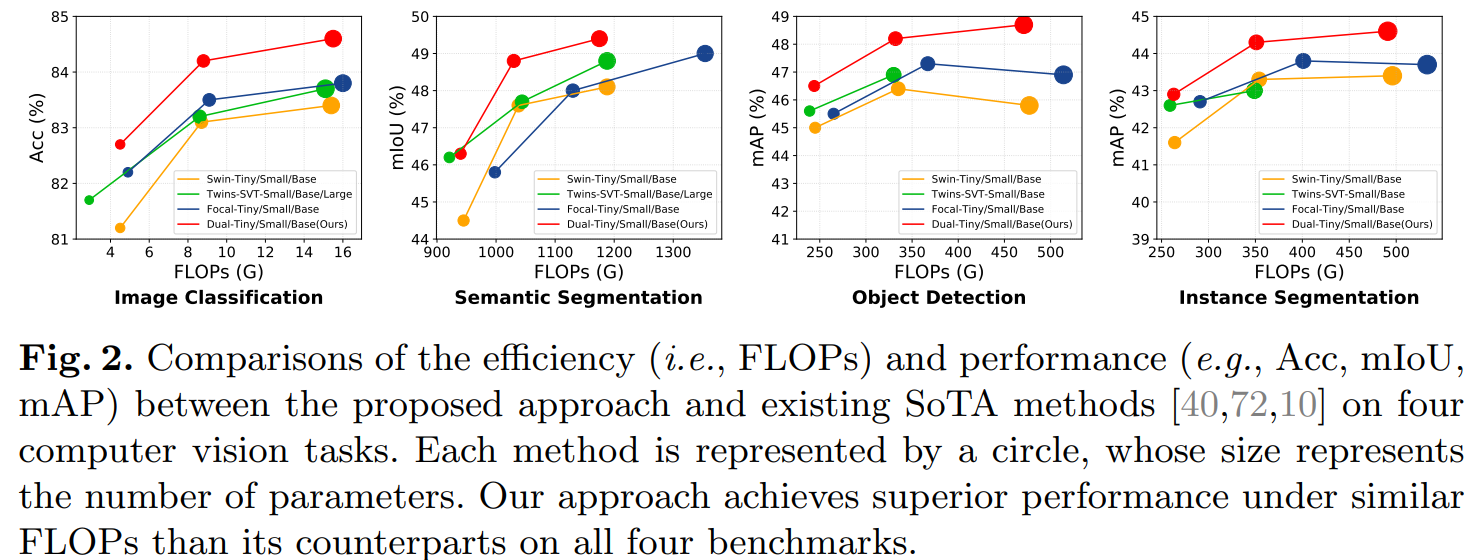
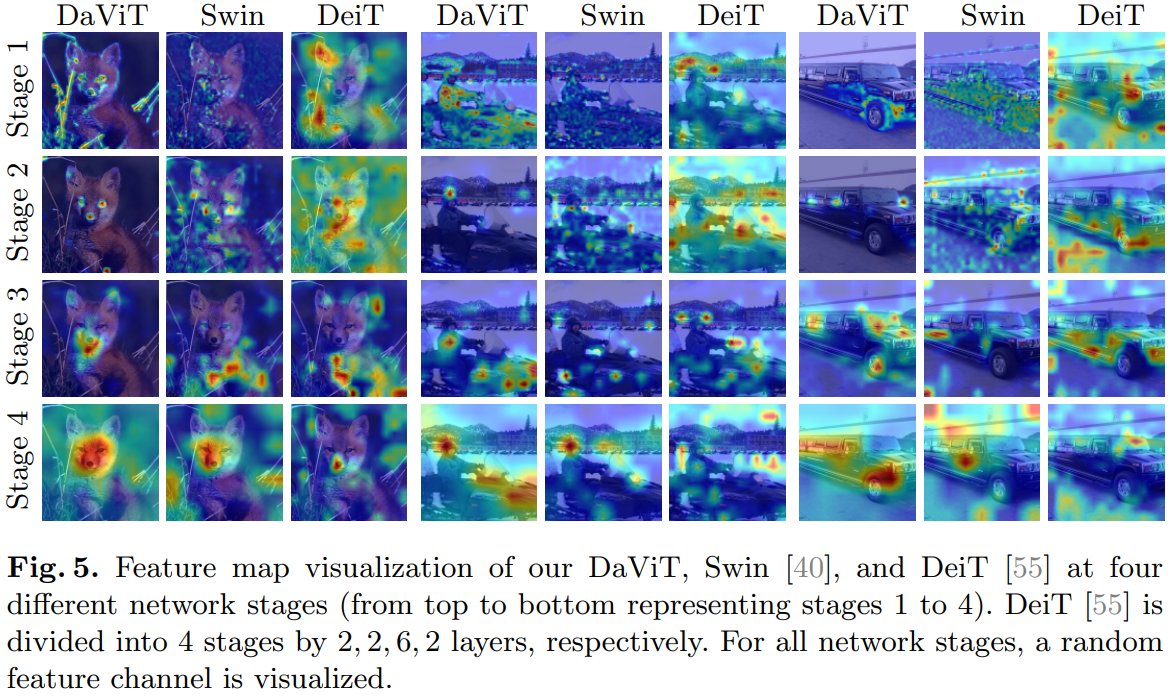
实验


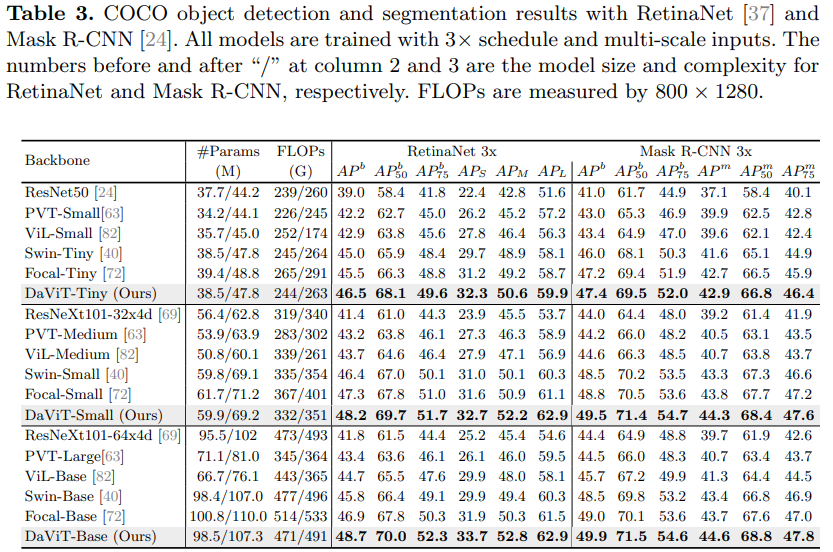
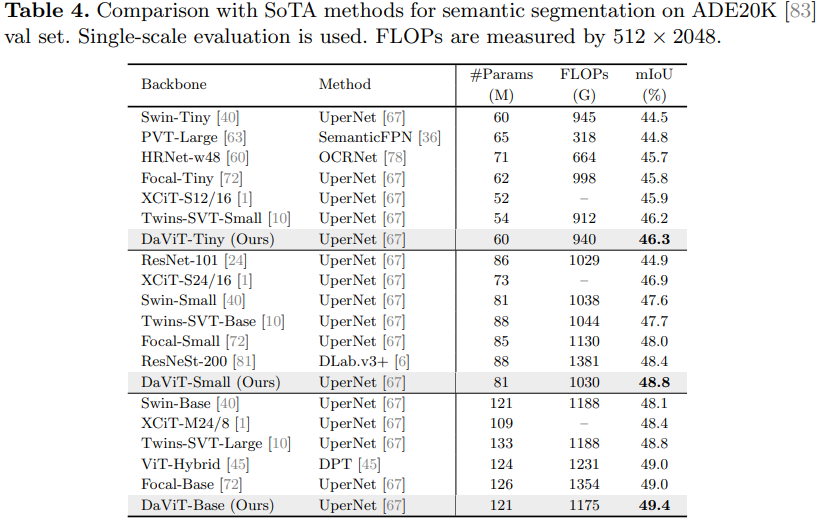
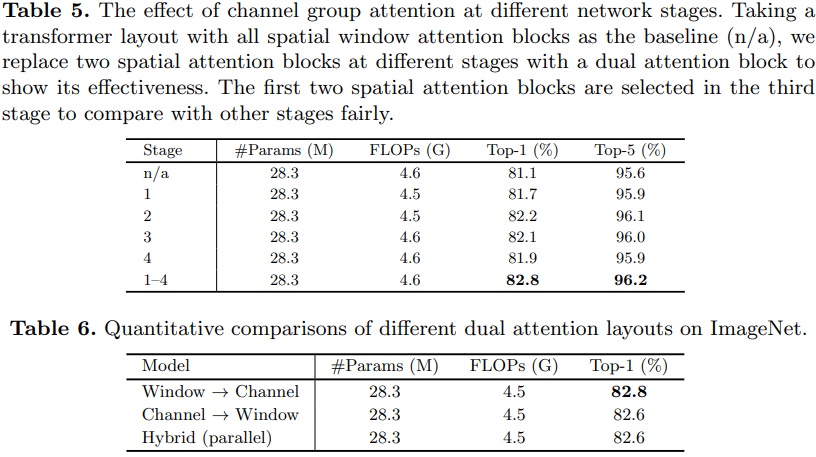
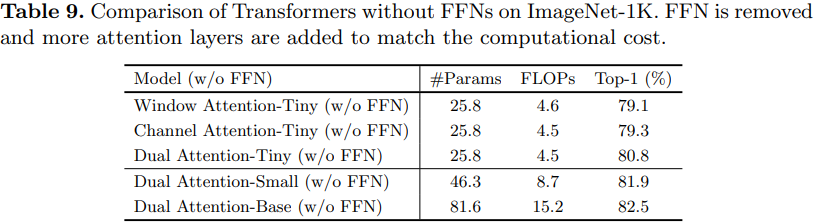
相关文章:
【ECCV2022】DaViT: Dual Attention Vision Transformers
DaViT: Dual Attention Vision Transformers, ECCV2022 解读:【ECCV2022】DaViT: Dual Attention Vision Transformers - 高峰OUC - 博客园 (cnblogs.com) DaViT:双注意力Vision Transformer - 知乎 (zhihu.com) DaViT: Dual Attention Vision Trans…...

Apache 配置与应用
Apache 配置与应用 一、构建虚拟 Web 主机httpd服务支持的虚拟主机类型包括以下三种: 二、基于域名的虚拟主机1.为虚拟主机提供域名解析方法一:部署DNS域名解析服务器 来提供域名解析方法二:在/etc/hosts 文件中临时配置域名与IP地址的映射关…...
OpenGL 纹理
1.简介 纹理是一个2D图片(甚至也有1D和3D的纹理),它可以用来添加物体的细节;你可以想象纹理是一张绘有砖块的纸,无缝折叠贴合到你的3D的房子上,这样你的房子看起来就像有砖墙外表了。 为了能够把纹理映射(M…...

Jeston Orin Nnao 安装pytorch与torchvision环境
大家好,我是虎哥,Jeston Orin nano 8G模块,提供高达 40 TOPS 的 AI 算力,安装好了Jetpack5.1之后,我们需要配置一些支持环境,来为我们后续的深度学习开发提供支持。本章内容,我将主要围绕安装对…...

ROS:常用可视化工具的使用
目录 一、日志输出工具——rqt_console二、绘制数据曲线——rqt_plot三、图像渲染工具——rqt_image_view四、图形界面总接口——rqt五、Rviz六、Gazebo 一、日志输出工具——rqt_console 启动海龟键盘控制节点,打开日志输出工具 roscorerosrun turtlesim turtles…...
智能应用搭建平台——LCHub低代码表单 vs 流程表单 vs 仪表盘
1. LCHub低代码如何选择 「流程表单」:填报数据,并带有流程审批功能,适合报销、请假申请或其他工作流; 「表单」:填报数据,并带有数据协作功能,如修改、删除、导入、导出,并可以给不同的人不同的管理权限; 「仪表盘」:数据分析处理、结果展示功能,如数据汇总、趋…...
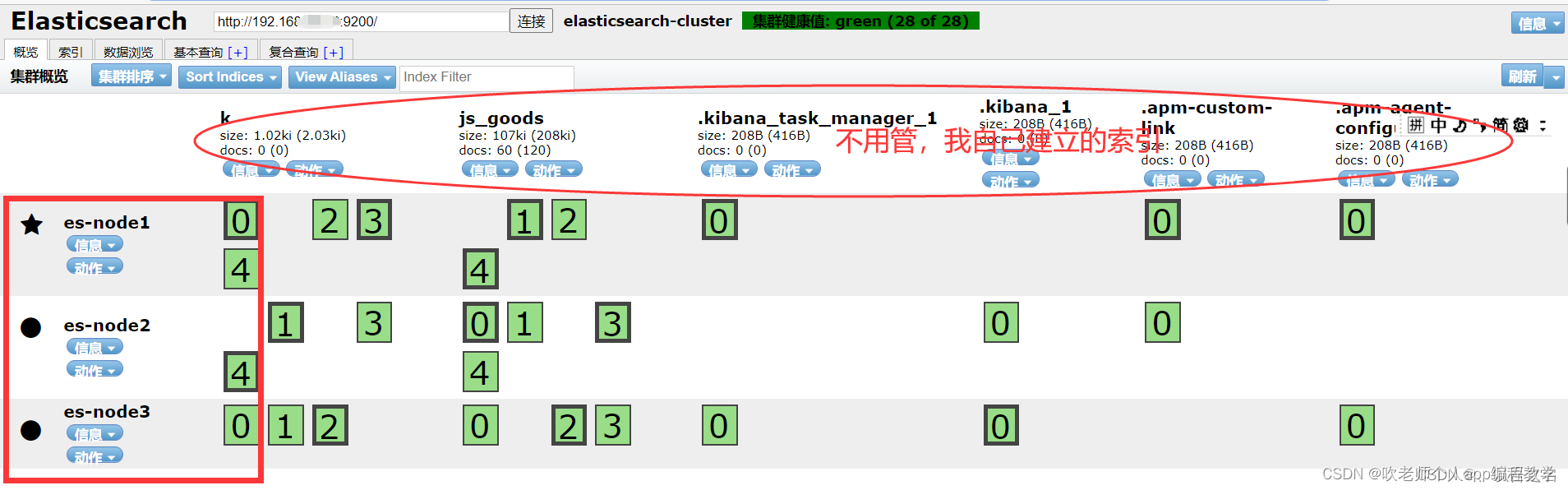
Mac下通过Docker安装ElasticSearch集群
1、安装ElasticSearch 使用docker直接获取es镜像,执行命令docker pull elasticsearch:7.7.0 执行完成后,执行docker images即可看到上一步拉取的镜像。 2、创建数据挂在目录,以及配置ElasticSearch集群配置文件 创建数据文件挂载目录 mkdir -…...

MySQL redo log、undo log、binlog
MySQL是一个广泛使用的关系型数据库管理系统,它通过一系列的日志来保证数据的一致性和持久性。在MySQL中,有三个重要的日志组件,它们分别是redo log(重做日志)、undo log(回滚日志)和binlog&…...

文件包含漏洞
一、原理解析。 开发人员通常会把可重复使用的函数写到单个文件中,在使用到某些函数时,可直接调用此文件,而无须再次编写,这种调用文件的过程被称为包含。 注意:对于开发人员来讲,文件包含很有用…...

Python 中的 F-Test
文章目录 F 统计量和 P 值方差(ANOVA) 分析中的 F 值 本篇文章介绍 F 统计、F 分布以及如何使用 Python 对数据执行 F-Test 测试。 F 统计量是在方差分析检验或回归分析后获得的数字,以确定两个总体的平均值是否存在显着差异。 它类似于 T 检验的 T 统计量…...

Docker网络模式
一、docker网络概述 1、docker网络实现的原理 Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP, 同时Docker网桥是 每个容器的…...

百度离线资源治理
作者 | 百度MEG离线优化团队 导读 近些年移动互联网的高速发展驱动了数据爆发式的增长,各大公司之间都在通过竞争获得更大的增长空间,大数据计算的效果直接影响到公司的发展,而这背后其实依赖庞大的算力及数据作为支撑,因此在满足…...
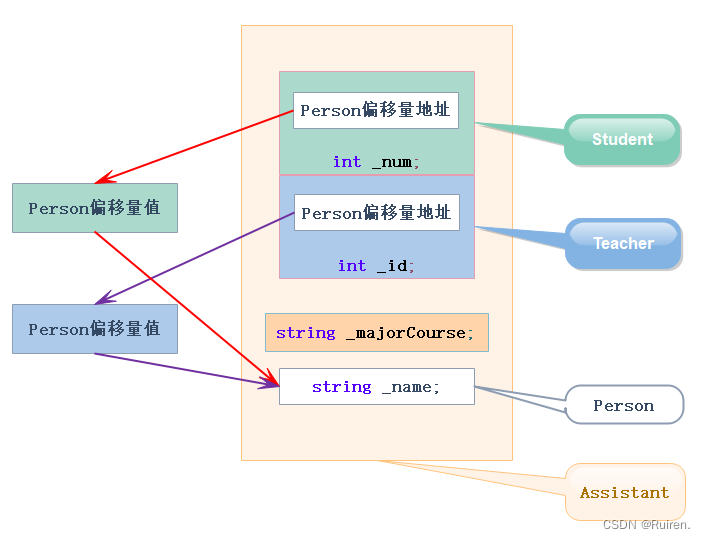
C++进阶之继承
文章目录 前言一、继承的概念及定义1.继承概念2.继承格式与访问限定符3.继承基类与派生类的访问关系变化4.总结 二、基类和派生类对象赋值转换基本概念与规则 三、继承中的作用域四、派生类的默认成员函数五、继承与友元六、继承与静态成员六、复杂的菱形继承及菱形虚拟继承七、…...
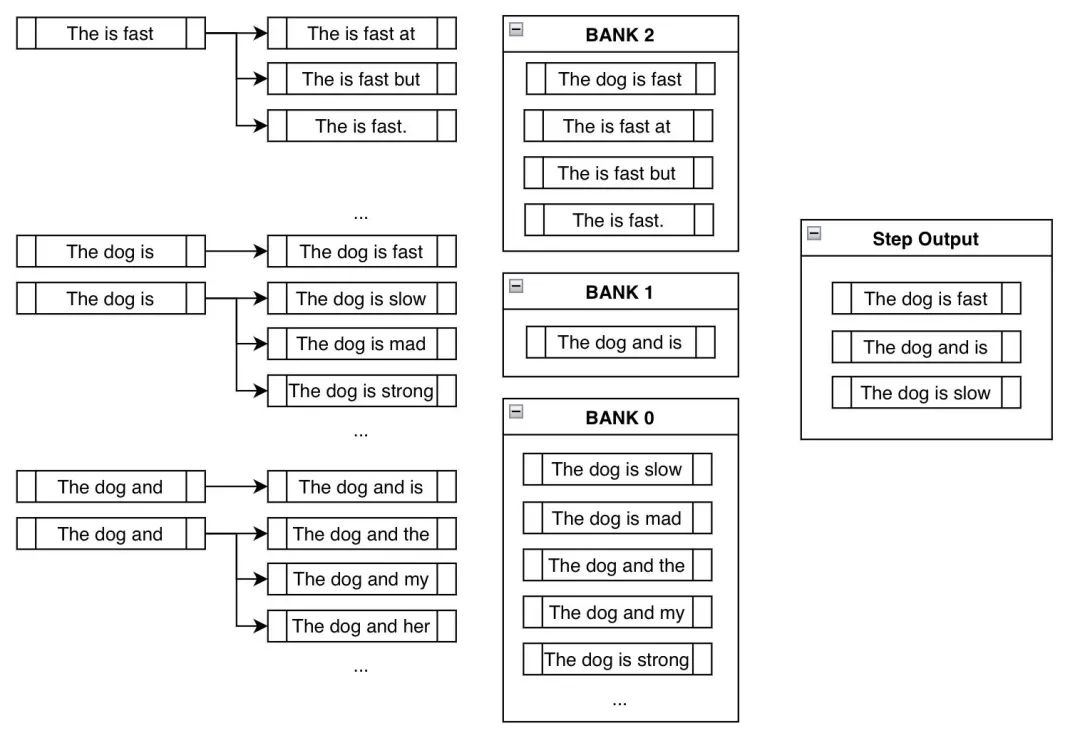
在 Transformers 中使用约束波束搜索引导文本生成
引言 本文假设读者已经熟悉文本生成领域波束搜索相关的背景知识,具体可参见博文 如何生成文本: 通过 Transformers 用不同的解码方法生成文本。 与普通的波束搜索不同,约束 波束搜索允许我们控制所生成的文本。这很有用,因为有时我们确切地知…...

Centos7更换OpenSSL版本
OpenSSL 1.1.0 用户应升级至 1.1.0aOpenSSL 1.0.2 用户应升级至 1.0.2iOpenSSL 1.0.1 用户应升级至 1.0.1u 查看openssl版本 openssl version -v选择升级版本 我的版本是OpenSSL 1.0.2系列,所以要升级1.0.2i https://www.openssl.org/source/old/1.0.2/openssl-…...
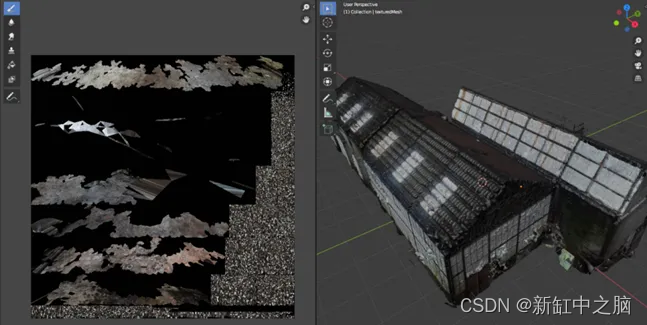
基于摄影测量的三维重建【终极指南】
我们生活的时代非常令人兴奋,如果你对 3D 东西感兴趣,更是如此。 我们有能力使用任何相机,从感兴趣的物体中捕捉一些图像数据,并在眨眼间将它们变成 3D 资产! 这种通过简单的数据采集阶段进行的 3D 重建过程是许多行业…...

配置ThreadPoolExecutor
ThreadPoolExecutor为一些Executor 提供了基本的实现,这些Executor 是由Executors中的newCachedThreadPool、newFixedThreadPool和newScheduledThreadExecutor 等工厂方法返回的。ThreadPoolExecutor是一个灵活的、稳定的线程池,允许进行各种定制。 如果默认的执行策略不能满足…...
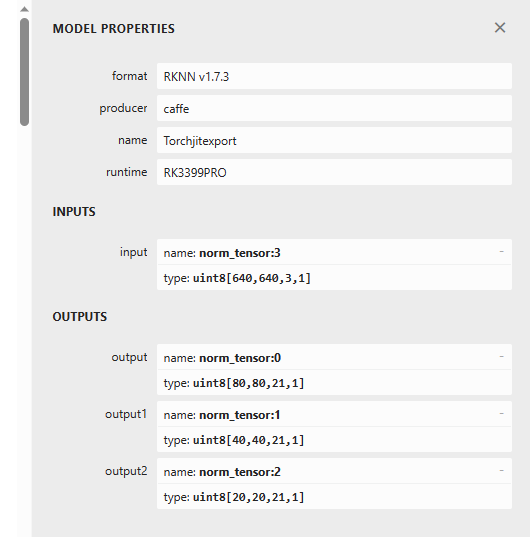
Yolov5s算法从训练到部署
文章目录 PyTorch GPU环境搭建查看显卡CUDA版本Anaconda安装PyTorch环境安装PyCharm中验证 训练算法模型克隆Yolov5代码工程制作数据集划分训练集、验证集修改工程相关文件配置预训练权重文件配置数据文件配置模型文件配置 超参数配置 测试训练出来的算法模型 量化转换算法模型…...
分布式补充技术 01.AOP技术
01.AOP技术是对于面向对象编程(OOP)的补充。是按照OCP原则进行的编写,(ocp是修改模块权限不行,扩充可以) 02.写一个例子: 创建一个新的java项目,在main主启动类中,写如下代码。 package com.co…...
)
QT 多对一服务插件 CTK开发(五)
CTK在软件的开发过程中可以很好的降低复杂性、使用 CTK Plugin Framework 提供统一的框架来进行开发增加了复用性 将同一功能打包可以提供多个应用程序使用避免重复性工作、可以进行版本控制提供了良好的版本更新迭代需求、并且支持动态热拔插 动态更新、开发更加简单快捷 方便…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...
Tauri2学习笔记
教程地址:https://www.bilibili.com/video/BV1Ca411N7mF?spm_id_from333.788.player.switch&vd_source707ec8983cc32e6e065d5496a7f79ee6 官方指引:https://tauri.app/zh-cn/start/ 目前Tauri2的教程视频不多,我按照Tauri1的教程来学习&…...
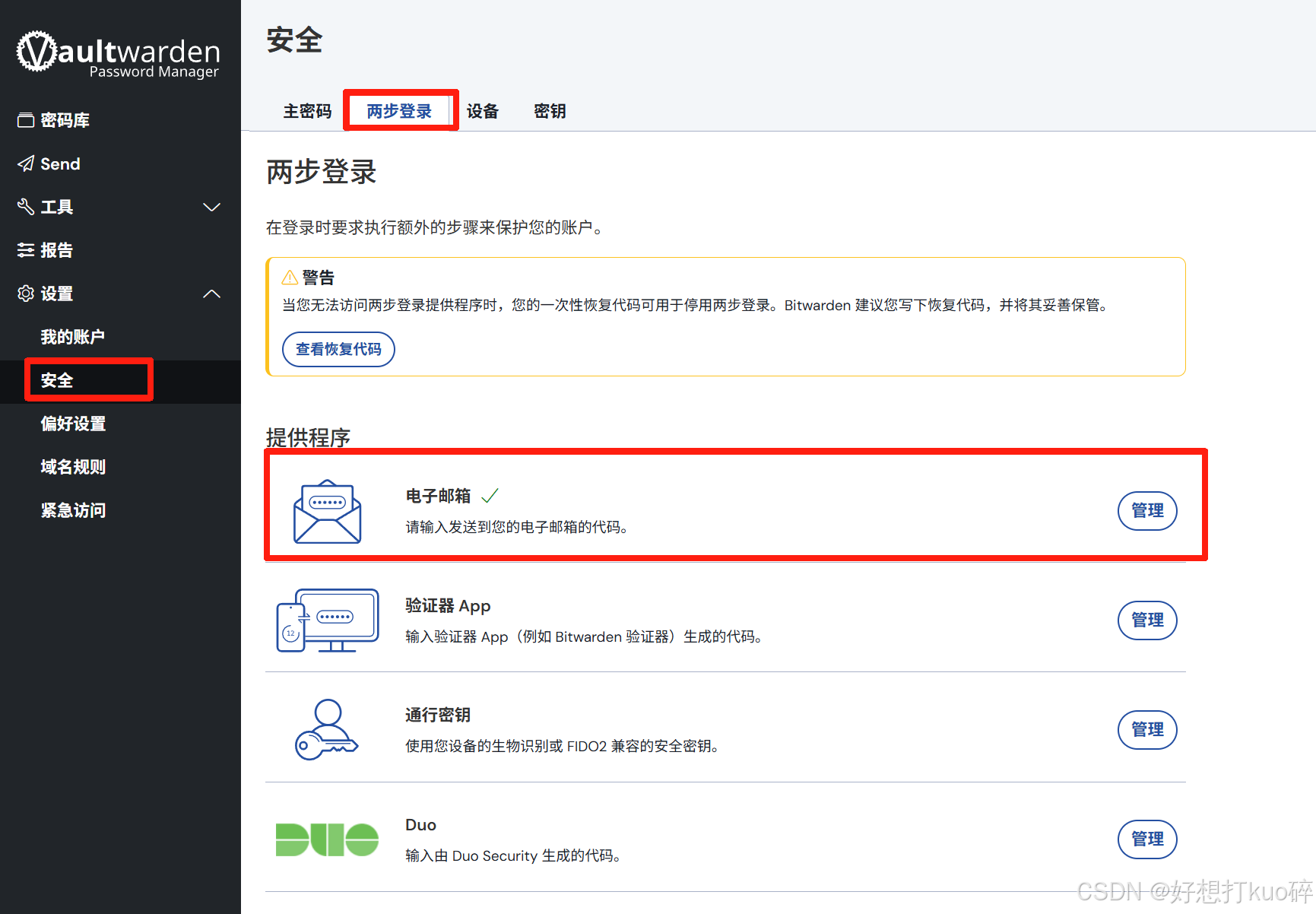
轻量安全的密码管理工具Vaultwarden
一、Vaultwarden概述 Vaultwarden主要作用是提供一个自托管的密码管理器服务。它是Bitwarden密码管理器的第三方轻量版,由国外开发者在Bitwarden的基础上,采用Rust语言重写而成。 (一)Vaultwarden镜像的作用及特点 轻量级与高性…...

Q1起重机指挥理论备考要点分析
Q1起重机指挥理论备考要点分析 一、考试重点内容概述 Q1起重机指挥理论考试主要包含三大核心模块:安全技术知识(占40%)、指挥信号规范(占30%)和法规标准(占30%)。考试采用百分制,8…...
基于微信小程序的作业管理系统源码数据库文档
作业管理系统 摘 要 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用java语言技术和微信小程序来完成对系统的…...