训练自己的中文word2vec(词向量)--skip-gram方法
训练自己的中文word2vec(词向量)–skip-gram方法
什么是词向量
将单词映射/嵌入(Embedding)到一个新的空间,形成词向量,以此来表示词的语义信息,在这个新的空间中,语义相同的单词距离很近。
Skip-Gram方法(本次使用方法)
以某个词为中心,分别计算该中心词前后可能出现其他词的各个概率,即给定input word来预测上下文。

CBOW(Continous Bags Of Words,CBOW)
CBOW根据某个词前面的n个词、或者前后各n个连续的词,来计算某个词出现的概率,即给定上下文,来预测input word。相比Skip-Gram,CBOW更快一些。
本次使用 Skip-Gram方法和三国演义第一章作为数据,训练32维中文词向量。
数据代码下载链接见文末
导入库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
import re
import collections
import numpy as np
import jieba
#指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
导入数据
因为算力问题,我在此出只截取三国演义的第一章作为示例数据。
training_file = '/home/mw/input/sanguo5529/三国演义.txt'#读取text文件,并选择第一章作为输入文本
def get_ch_lable(txt_file): labels= ""with open(txt_file, 'rb') as f:for label in f:labels =labels+label.decode('utf-8')text = re.findall('第1章.*?第2章', labels,re.S)return text[0]
training_data =get_ch_lable(training_file)
# print(training_data)
print("总字数",len(training_data))
总字数 4945
分词
#jieba分词
def fenci(training_data):seg_list = jieba.cut(training_data) # 默认是精确模式 training_ci = " ".join(seg_list)training_ci = training_ci.split()#以空格将字符串分开training_ci = np.array(training_ci)training_ci = np.reshape(training_ci, [-1, ])return training_ci
training_ci =fenci(training_data)
print("总词数",len(training_ci))
总词数 3053
构建词表
def build_dataset(words, n_words):count = [['UNK', -1]]count.extend(collections.Counter(words).most_common(n_words - 1))dictionary = dict()for word, _ in count:dictionary[word] = len(dictionary)data = list()unk_count = 0for word in words:if word in dictionary:index = dictionary[word]else:index = 0 # dictionary['UNK']unk_count += 1data.append(index)count[0][1] = unk_countreversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))return data, count, dictionary, reversed_dictionarytraining_label, count, dictionary, words = build_dataset(training_ci, 3053)
#计算词频
word_count = np.array([freq for _,freq in count], dtype=np.float32)
word_freq = word_count / np.sum(word_count)#计算每个词的词频
word_freq = word_freq ** (3. / 4.)#词频变换
words_size = len(dictionary)
print("字典词数",words_size)
print('Sample data', training_label[:10], [words[i] for i in training_label[:10]])
字典词数 1456
Sample data [100, 305, 140, 306, 67, 101, 307, 308, 46, 27]
[‘第’, ‘1’, ‘章’, ‘宴’, ‘桃园’, ‘豪杰’, ‘三’, ‘结义’, ‘斩’, ‘黄巾’]
制作数据集
C = 3
num_sampled = 64 # 负采样个数
BATCH_SIZE = 32
EMBEDDING_SIZE = 32 #想要的词向量长度class SkipGramDataset(Dataset):def __init__(self, training_label, word_to_idx, idx_to_word, word_freqs):super(SkipGramDataset, self).__init__()self.text_encoded = torch.Tensor(training_label).long()self.word_to_idx = word_to_idxself.idx_to_word = idx_to_wordself.word_freqs = torch.Tensor(word_freqs)def __len__(self):return len(self.text_encoded)def __getitem__(self, idx):idx = min( max(idx,C),len(self.text_encoded)-2-C)#防止越界center_word = self.text_encoded[idx]pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+1+C))pos_words = self.text_encoded[pos_indices] #多项式分布采样,取出指定个数的高频词neg_words = torch.multinomial(self.word_freqs, num_sampled+2*C, False)#True)#去掉正向标签neg_words = torch.Tensor(np.setdiff1d(neg_words.numpy(),pos_words.numpy())[:num_sampled]).long()return center_word, pos_words, neg_wordsprint('制作数据集...')
train_dataset = SkipGramDataset(training_label, dictionary, words, word_freq)
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE,drop_last=True, shuffle=True)
制作数据集…
#将数据集转化成迭代器
sample = iter(dataloader)
#从迭代器中取出一批次样本
center_word, pos_words, neg_words = sample.next()
print(center_word[0],words[np.compat.long(center_word[0])],[words[i] for i in pos_words[0].numpy()])
模型构建
class Model(nn.Module):def __init__(self, vocab_size, embed_size):super(Model, self).__init__()self.vocab_size = vocab_sizeself.embed_size = embed_sizeinitrange = 0.5 / self.embed_sizeself.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)self.in_embed.weight.data.uniform_(-initrange, initrange)def forward(self, input_labels, pos_labels, neg_labels):input_embedding = self.in_embed(input_labels)pos_embedding = self.in_embed(pos_labels)neg_embedding = self.in_embed(neg_labels)log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze()log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze()log_pos = F.logsigmoid(log_pos).sum(1)log_neg = F.logsigmoid(log_neg).sum(1)loss = log_pos + log_negreturn -lossmodel = Model(words_size, EMBEDDING_SIZE).to(device)
model.train()valid_size = 32
valid_window = words_size/2 # 取样数据的分布范围.
valid_examples = np.random.choice(int(valid_window), valid_size, replace=False)optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
NUM_EPOCHS = 10
开始训练
for e in range(NUM_EPOCHS):for ei, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):input_labels = input_labels.to(device)pos_labels = pos_labels.to(device)neg_labels = neg_labels.to(device)optimizer.zero_grad()loss = model(input_labels, pos_labels, neg_labels).mean()loss.backward()optimizer.step()if ei % 20 == 0:print("epoch: {}, iter: {}, loss: {}".format(e, ei, loss.item()))if e %40 == 0: norm = torch.sum(model.in_embed.weight.data.pow(2),-1).sqrt().unsqueeze(1)normalized_embeddings = model.in_embed.weight.data / normvalid_embeddings = normalized_embeddings[valid_examples]similarity = torch.mm(valid_embeddings, normalized_embeddings.T)for i in range(valid_size):valid_word = words[valid_examples[i]]top_k = 8 # 取最近的排名前8的词nearest = (-similarity[i, :]).argsort()[1:top_k + 1] #argsort函数返回的是数组值从小到大的索引值log_str = 'Nearest to %s:' % valid_word for k in range(top_k):close_word = words[nearest[k].cpu().item()]log_str = '%s,%s' % (log_str, close_word)print(log_str)
epoch: 0, iter: 0, loss: 48.52019500732422
epoch: 0, iter: 20, loss: 48.51792526245117
epoch: 0, iter: 40, loss: 48.50772476196289
epoch: 0, iter: 60, loss: 48.50897979736328
epoch: 0, iter: 80, loss: 48.45783996582031
Nearest to 伏山:,王,送,话,遥望,操忽心生,江渚上,接,提刀
Nearest to 与:,”,将次,盖地,,,下文,。,妖术,玄德
Nearest to 必获:,听调,直取,各处,一端,奏帝,必出,遥望,入帐
Nearest to 郭胜十人:,南华,因为,把,贼战,告变,处,擒,玄德遂
Nearest to 官军:,秀才,统兵,说起,军齐出,四散,放荡,一彪,云长
Nearest to 碧眼:,名备,刘焉然,大汉,卷入,大胜,老人,重枣,左有
Nearest to 天书:,泛溢,约期,而进,龚景,因起,车盖,遂解,震
Nearest to 转头:,近因,直取,接,七尺,王,备下,大汉,齐声
Nearest to 张宝:,侯览,惊告嵩,誓毕,帝惊,呼风唤雨,狂风,大将军,曾
Nearest to 玄德幼:,直取,近闻,刘焉令,几度,崩,临江仙,右有翼德,左右两
Nearest to 不祥:,无数,调兵,项,刘备,玄德谢,原来,八尺,共
Nearest to 靖:,操忽心生,此病,赵忠,刘焉然,崩,庄田,剑,传至
Nearest to 五千:,岂可,丹凤眼,北行,听罢,”,性命,卓,之囚
Nearest to 日非:,赵忠,矣,闻得,蜺,破贼,早丧,书报,忽起
Nearest to 徐:,震怒,我气,卢植,”,结为,、,燕颔虎须,。
Nearest to 五百余:,帝惊,普,本部,三,神功,桓帝,滚滚,左右两
Nearest to 而:,转头,卷入,祭,近因,大商,章,人公,天子
Nearest to 去:,封谞,夏恽,周末,必,嵩信,广宗,人氏,民心
Nearest to 上:,灵,文,陷邕,四年,关羽,直赶,九尺,伏山
Nearest to ::,“,曰,飞,是,兄弟,喜,来代,我答
Nearest to 后:,必获,阁下,字,手起,祭礼,侍奉,各处,奏帝
Nearest to 因起:,帝览奏,青,!,汝可引,夺路,一把,是非成败,卷入
Nearest to 骤起:,挟恨,张宝称,明公宜,议,一统天下,又,擒,玄德请
Nearest to 汉室:,六月,临江仙,今汉运,手起,威力,抹额,讹言,提刀
Nearest to 云游四方:,背义忘恩,复,渔樵,地公,扬鞭,若,故冒姓,截住
Nearest to 桓:,崩,赵忠,刘焉然,左有,刘备,名备,二帝,游荡
Nearest to 二字于:,操故,分,白土,左右两,张角本,赏劳,当时,梁上
Nearest to 人出:,多,五十匹,肩,奏帝,梁上,九尺,六月,大汉
Nearest to 大浪:,卷入,临江仙,听调,汉武时,左有,束草,围城,及
Nearest to 青:,夺路,肩,贩马,师事,围城,卷入,大胜,客人
Nearest to 郎蔡邕:,浊酒,近闻,六月,角战于,中郎将,崩,转头,众大溃
Nearest to 二月:,马舞刀,国谯郡,只见,内外,郎蔡邕,豪,落到,汝得
epoch: 1, iter: 0, loss: 48.46757888793945
epoch: 1, iter: 20, loss: 48.42853546142578
epoch: 1, iter: 40, loss: 48.35804748535156
epoch: 1, iter: 60, loss: 48.083805084228516
epoch: 1, iter: 80, loss: 48.1635856628418
epoch: 2, iter: 0, loss: 47.89817428588867
epoch: 2, iter: 20, loss: 48.067501068115234
epoch: 2, iter: 40, loss: 48.6464729309082
epoch: 2, iter: 60, loss: 47.825260162353516
epoch: 2, iter: 80, loss: 48.07224655151367
epoch: 3, iter: 0, loss: 48.15058898925781
epoch: 3, iter: 20, loss: 47.26418685913086
epoch: 3, iter: 40, loss: 47.87504577636719
epoch: 3, iter: 60, loss: 48.74541473388672
epoch: 3, iter: 80, loss: 48.01288986206055
epoch: 4, iter: 0, loss: 47.257896423339844
epoch: 4, iter: 20, loss: 48.337745666503906
epoch: 4, iter: 40, loss: 47.70765686035156
epoch: 4, iter: 60, loss: 48.57493591308594
epoch: 4, iter: 80, loss: 48.206268310546875
epoch: 5, iter: 0, loss: 47.139137268066406
epoch: 5, iter: 20, loss: 48.70667266845703
epoch: 5, iter: 40, loss: 47.97750473022461
epoch: 5, iter: 60, loss: 48.098899841308594
epoch: 5, iter: 80, loss: 47.778892517089844
epoch: 6, iter: 0, loss: 47.86349105834961
epoch: 6, iter: 20, loss: 47.77979278564453
epoch: 6, iter: 40, loss: 48.67324447631836
epoch: 6, iter: 60, loss: 48.117042541503906
epoch: 6, iter: 80, loss: 48.69907760620117
epoch: 7, iter: 0, loss: 47.63265609741211
epoch: 7, iter: 20, loss: 47.82151794433594
epoch: 7, iter: 40, loss: 48.54405212402344
epoch: 7, iter: 60, loss: 48.06487274169922
epoch: 7, iter: 80, loss: 48.67494583129883
epoch: 8, iter: 0, loss: 48.053466796875
epoch: 8, iter: 20, loss: 47.872459411621094
epoch: 8, iter: 40, loss: 47.462432861328125
epoch: 8, iter: 60, loss: 48.10865783691406
epoch: 8, iter: 80, loss: 46.380184173583984
epoch: 9, iter: 0, loss: 47.2872314453125
epoch: 9, iter: 20, loss: 48.553428649902344
epoch: 9, iter: 40, loss: 47.00652313232422
epoch: 9, iter: 60, loss: 47.970741271972656
epoch: 9, iter: 80, loss: 48.159828186035156查看训练好的词向量
final_embeddings = normalized_embeddings
labels = words[10]
print(labels)
print(final_embeddings[10])
玄德
tensor([-0.2620, 0.0660, 0.0464, 0.2948, -0.1974, 0.2471, -0.0893, 0.1720,
-0.1488, 0.0283, -0.1165, 0.2156, -0.1642, -0.2376, -0.0356, -0.0607,
0.1985, -0.2166, 0.2222, 0.2453, -0.1414, -0.0526, 0.1153, -0.1325,
-0.2964, 0.2775, -0.0637, -0.0716, 0.2672, 0.0539, 0.1697, 0.0489])
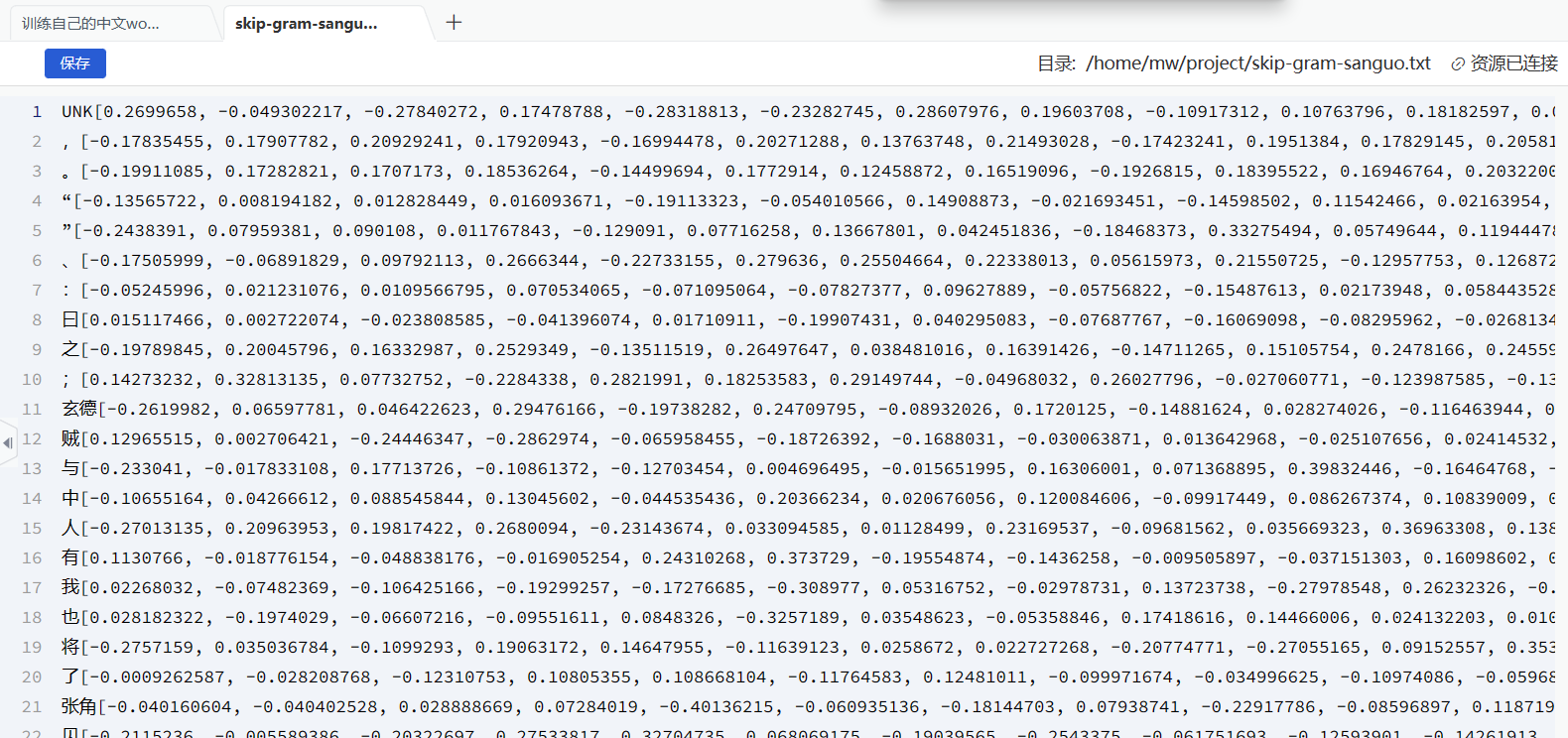
with open('skip-gram-sanguo.txt', 'a') as f: for i in range(len(words)):f.write(words[i] + str(list(final_embeddings.numpy()[i])) + '\n')
f.close()
print('word vectors have written done.')
word vectors have written done.
按照路径/home/mw/project/skip-gram-sanguo.txt查看保存的文件,不一定要保存为txt,我们平常加载的词向量更多是vec格式
数据代码下载链接
数据及代码右上角fork后可以免费获取
相关文章:
训练自己的中文word2vec(词向量)--skip-gram方法
训练自己的中文word2vec(词向量)–skip-gram方法 什么是词向量 将单词映射/嵌入(Embedding)到一个新的空间,形成词向量,以此来表示词的语义信息,在这个新的空间中,语义相同的单…...

ubuntu系统环境配置和常用软件安装
系统环境 修改文件夹名称为英文 参考链接 export LANGen_US xdg-user-dirs-gtk-update 常用软件安装 常用工具 ping 和ifconfig工具 sudo apt install -y net-tools inetutils-ping 截图软件 sudo apt install -y net-tools inetutils-ping flameshot 录屏 sudo apt-get i…...
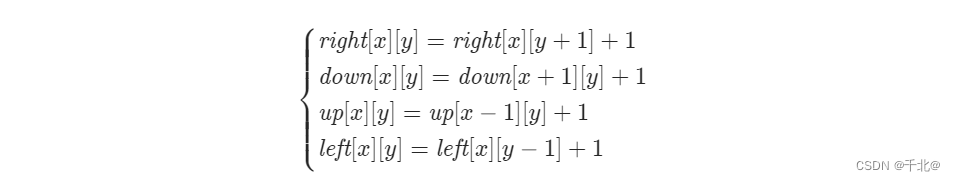
【1139. 最大的以 1 为边界的正方形】
来源:力扣(LeetCode) 描述: 给你一个由若干 0 和 1 组成的二维网格 grid,请你找出边界全部由 1 组成的最大 正方形 子网格,并返回该子网格中的元素数量。如果不存在,则返回 0。 示例 1&#…...
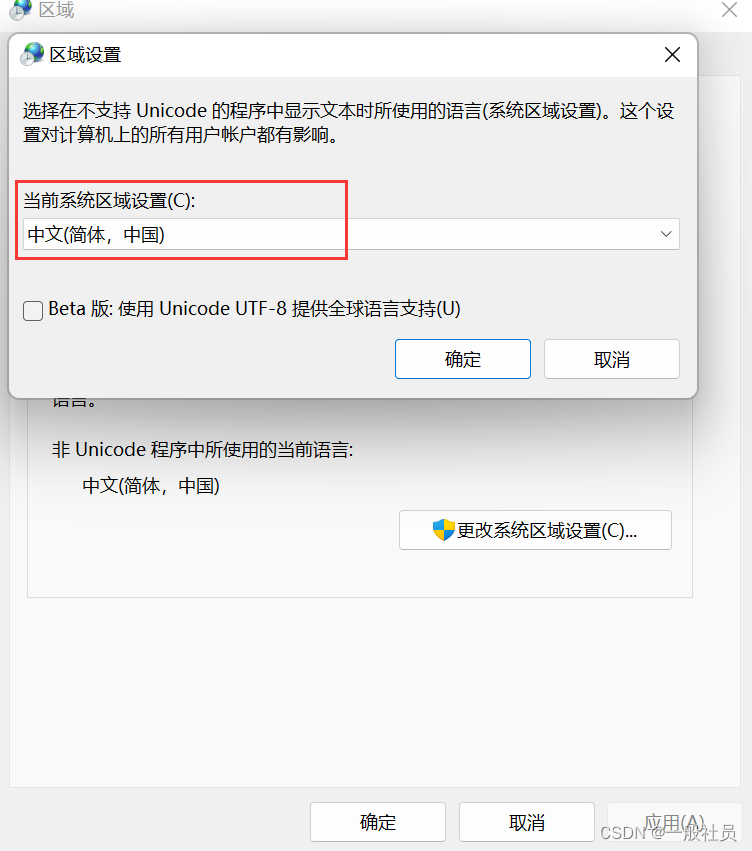
windows11安装sqlserver2022报错
window11安装SQL Server 2022 报错 糟糕… 无法安装SQL Server (setup.exe)。此 SQL Server安装程序介质不支持此OS的语言,或没有SQL Server英语版本的安装文件。请使用匹配的特定语言SQL Server介质;或安装两个特定语言MUI,然后通过控制面板的区域设置…...

Python快速上手系列--日志模块--详解篇
前言本篇主要说说日志模块,在写自动化测试框架的时候我们就需要用到这个模块了,方便我们快速的定位错误,了解软件的运行情况,更加顺畅的调试程序。为什么要用到日志模块,直接print不就好了!那得写多少print…...

【THREE.JS学习(1)】绘制一个可以旋转、放缩的立方体
学习新技能,做一下笔记。在使用ThreeJS的时候,首先创建一个场景const scene new THREE.Scene();接着,创建一个相机其中,THREE.PerspectiveCamera()四个参数分别为:1.fov 相机视锥体竖直方向视野…...
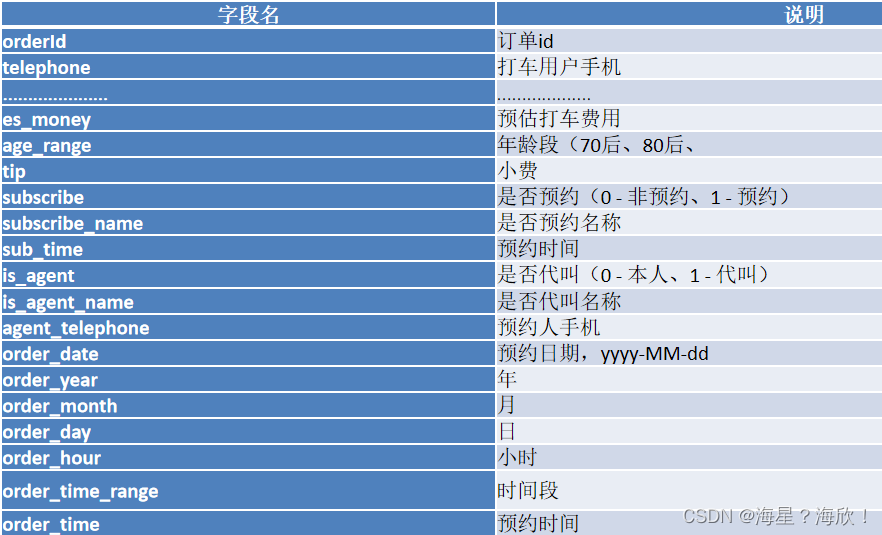
数仓实战 - 滴滴出行
项目大致流程: 1、项目业务背景 1.1 目的 本案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、预约订单与非预约订单的占比是多少、不同时段订单占比等 数据海量 – 大数据 hive比MySQL慢很多 1.2 项目架…...
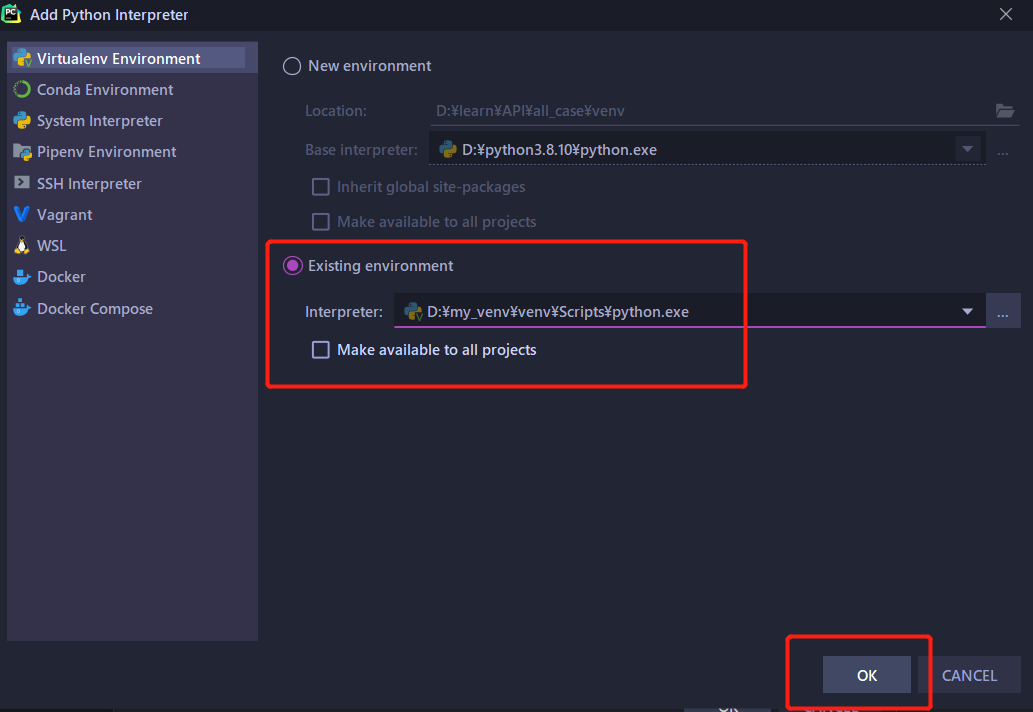
python虚拟环境与环境变量
一、环境变量 1.环境变量 在命令行下,使用可执行文件,需要来到可执行文件的路径下执行 如果在任意路径下执行可执行文件,能够有响应,就需要在环境变量配置 2.设置环境变量 用户变量:当前用户登录到系统,…...

BeautifulSoup文档4-详细方法 | 用什么方法对文档树进行搜索?
4-详细方法 | 用什么方法对文档树进行搜索?1 过滤器1.1 字符串1.2 正则表达式1.3 列表1.4 True1.5 可以自定义方法2 find_all()2.1 参数原型2.2 name参数2.3 keyword 参数2.4 string 参数2.5 limit 参数2.6 recursive 参数3 find()4 find_parents()和find_parent()5…...

初识Tkinter界面设计
目录 前言 一、初识Tkinter 二、Label控件 三、Button控件 四、Entry控件 前言 本文简单介绍如何使用Python创建一个界面。 一、初识Tk...

软件测试面试题中的sql题目你会做吗?
目录 1.学生表 2.一道SQL语句面试题,关于group by表内容: 3.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列 4. 5.姓名:name 课程:subject 分数&…...

VS实用调试技巧
一.什么是BUG🐛Bug一词的原意是虫子,而在电脑系统或程序中隐藏着的一些未被发现的缺陷或问题,人们也叫它"bug"。这是为什么呢?这就要追溯到一个程序员与飞蛾的故事了。Bug的创始人格蕾丝赫柏(Grace Murray H…...
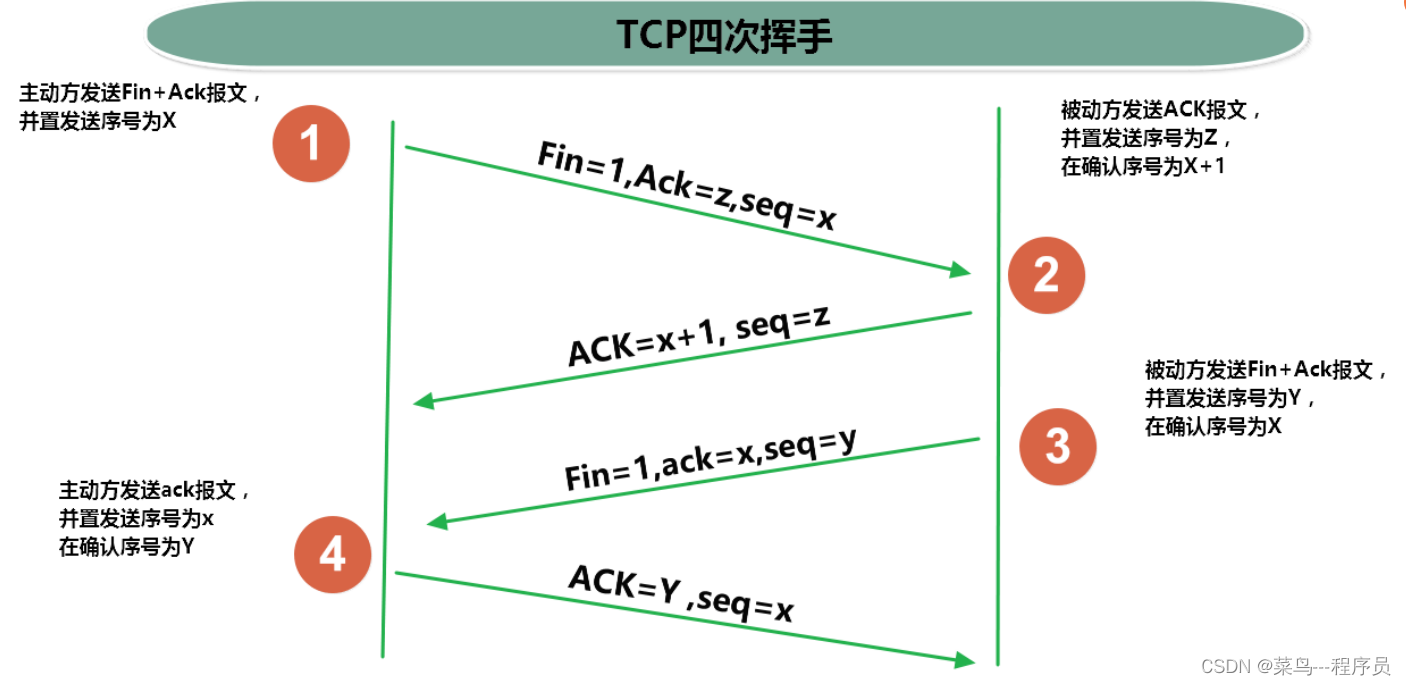
通俗易懂理解三次握手、四次挥手(TCP)
文章目录1、通俗语言理解1.1 三次握手1.2 四次挥手2、进一步理解三次握手和四次挥手2.1 三次握手2.2 四次挥手1、通俗语言理解 1.1 三次握手 C:客户端 S:服务器端 第一次握手: C:在吗?我要和你建立连接。 第二次握手ÿ…...
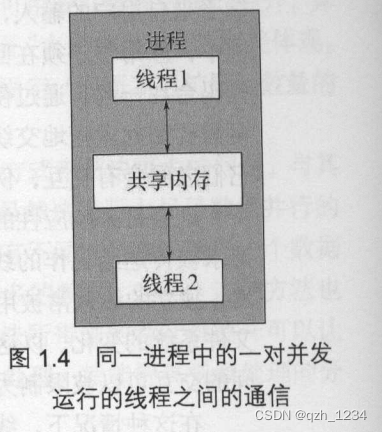
1.1 什么是并发
1.1 什么是并发 并发:指两个或更多独立的活动同时发生。并发在生活中随处可见。我们可以一边走路一边说话,也可以两只手同时做不同的动作。 1.1.1 计算机系统中的并发 当我们提到计算机术语的“并发”,指的是在单个系统里同时执行多个独立…...

万字讲解你写的代码是如何跑起来的?
今天我们来思考一个简单的问题,一个程序是如何在 Linux 上执行起来的? 我们就拿全宇宙最简单的 Hello World 程序来举例。 #include <stdio.h> int main() {printf("Hello, World!\n");return 0; } 我们在写完代码后,进行…...

034.Solidity入门——21不可变量
Solidity 中的不可变量是在编译时就被确定的常量,也称为常量变量(constant variable)或只读变量(read-only variable)。这些变量在定义时必须立即初始化,并且在整个合约中都无法被修改,可以在函…...
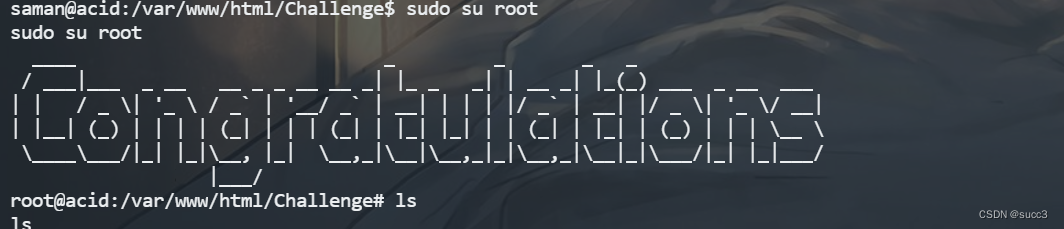
Vulnhub 渗透练习(四)—— Acid
环境搭建 环境下载 kail 和 靶机网络适配调成 Nat 模式,实在不行直接把网络适配还原默认值,再重试。 信息收集 主机扫描 没扫到,那可能端口很靠后,把所有端口全扫一遍。 发现 33447 端口。 扫描目录,没什么有用的…...

C++ 在线工具
online编译器https://godbolt.org/Online C Compiler - online editor (onlinegdb.com) https://www.onlinegdb.com/online_c_compilerC Shell (cpp.sh) https://cpp.sh/在线文档Open Standards (open-std.org)Index of /afs/cs.cmu.edu/academic/class/15211/spring.96/wwwC P…...

使用MMDetection进行目标检测、实例和全景分割
MMDetection 是一个基于 PyTorch 的目标检测开源工具箱,它是 OpenMMLab 项目的一部分。包含以下主要特性: 支持三个任务 目标检测(Object Detection)是指分类并定位图片中物体的任务实例分割(Instance Segmentation&a…...
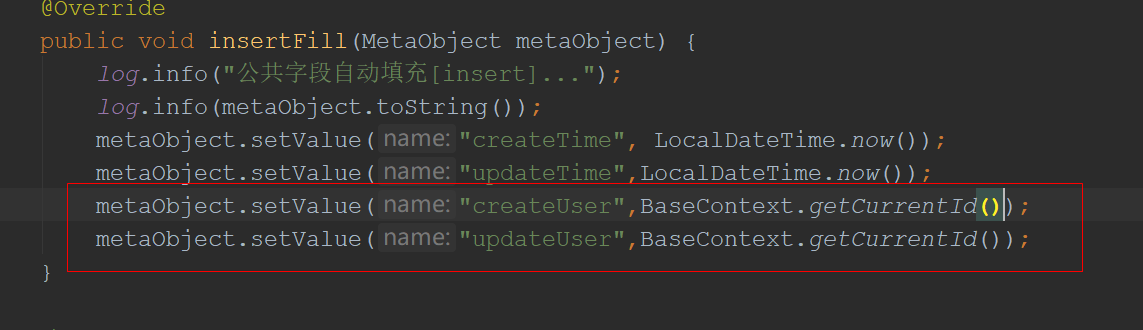
使用ThreadLocal实现当前登录信息的存取
有志者,事竟成 文章持续更新,可以关注【小奇JAVA面试】第一时间阅读,回复【资料】获取福利,回复【项目】获取项目源码,回复【简历模板】获取简历模板,回复【学习路线图】获取学习路线图。 文章目录一、使用…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...