Python机器学习入门笔记(2)—— 分类算法
目录
转换器(transformer)和估计器(estimator)
K-近邻(K-Nearest Neighbors,简称KNN)算法
模型选择与调优
交叉验证(Cross-validation)
GridSearchCV API
朴素贝叶斯(Naive Bayes) 算法
MultinomialNB 和 GaussianNB 区别
决策树(Decision Tree)
随机森林
转换器(transformer)和估计器(estimator)
在Scikit-learn中,转换器(transformer)和估计器(estimator)是机器学习管道(pipeline)的两个重要组成部分。
转换器是将一个数据集转换成另一个数据集的算法。例如,使用Scikit-learn的预处理模块中的StandardScaler对数据集进行标准化,或使用CountVectorizer将文本数据集转换为特征矩阵。转换器通常通过fit()方法学习数据集的某些属性,然后通过transform()方法将其转换成另一个数据集。
估计器是一种机器学习算法,它通过对已知的数据集进行学习来对新数据进行预测。例如,使用Scikit-learn的线性回归模型进行预测,或使用KMeans模型对数据进行聚类。估计器通常使用fit()方法在已知的数据集上进行训练,然后使用predict()方法对新数据进行预测。
除了fit()和transform()方法外,许多转换器和估计器还具有fit_transform()方法,该方法将学习和转换组合成单个操作,从而提高了代码的效率。
Scikit-learn提供了许多常用的转换器和估计器,它们具有统一的API接口,可以非常方便地在机器学习管道中组合使用。使用转换器和估计器,可以将数据集进行处理和预测,从而得到更好的模型性能。
K-近邻(K-Nearest Neighbors,简称KNN)算法
K-近邻(K-Nearest Neighbors,简称KNN)是一种基本的分类和回归算法。KNN的基本思想是在数据集中寻找K个距离新实例最近的训练样本,然后根据这K个样本的类别来对新实例进行分类或回归预测。KNN是一种无参数的学习算法,它没有显式地学习一个模型,而是直接根据已有的数据进行预测。
KNN算法的步骤如下:
- 计算测试数据与训练集中每个样本的距离,常用的距离度量有欧氏距离、曼哈顿距离、余弦相似度等。
- 选取与测试数据距离最近的K个训练集样本。
- 统计这K个样本中出现次数最多的类别作为测试数据的类别,即进行分类预测,或计算这K个样本的平均值作为测试数据的预测值,即进行回归预测。
KNN算法的优点在于简单易懂、无需显式地学习模型、适用于分类和回归问题,但是在处理大规模数据集时速度较慢,需要保存全部训练数据,对于高维数据效果不佳。
下面是一个使用Scikit-learn实现KNN分类算法的Python代码案例
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier# 加载iris数据集 iris = load_iris()# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)# 创建KNN分类器模型 knn = KNeighborsClassifier(n_neighbors=3)# 训练模型 knn.fit(X_train, y_train)# 预测测试集 y_pred = knn.predict(X_test)#查看预估与测试值 print("查看预估数值:\n",y_pred==y_test)# 输出模型准确率 accuracy = knn.score(X_test, y_test) print("KNN模型的准确率为:", accuracy)
以上代码中,首先使用
load_iris()函数加载iris数据集,然后使用train_test_split()函数将数据集划分为训练集和测试集。接着使用KNeighborsClassifier创建KNN分类器模型,并使用fit()方法训练模型。最后使用predict()方法对测试集进行预测,并使用score()方法计算模型准确率。

模型选择与调优
模型选择是指在给定数据集和模型族的情况下,从中选择最优模型的过程。而模型调优则是在选择好模型后,对模型参数进行优化以达到更好的模型效果。
交叉验证(Cross-validation)
交叉验证(Cross-validation)是一种常用的模型选择和调优的方法。交叉验证将原始数据集分成K个子集,然后使用其中K-1个子集作为训练集,剩余的一个子集作为测试集。这个过程会重复K次,每次用不同的子集作为测试集。最终,将这K次的测试结果平均得到模型的性能指标。
交叉验证可以有效地评估模型的性能,同时还能防止过拟合。它也可以帮助我们选择模型的超参数,即模型构建时需要手动调整的参数,比如KNN模型的k值、线性模型的正则化参数等等。为了选出最优的超参数组合,我们可以使用超参数搜索算法。
网格搜索(Grid Search)是一种常用的超参数搜索算法。它会在给定的超参数空间中进行穷举搜索,并使用交叉验证来评估每种超参数组合的性能。网格搜索通常需要指定一个参数字典,其中每个键表示一个超参数,对应的值是一个超参数的取值列表。然后网格搜索会遍历所有超参数组合,返回性能最优的超参数组合。
GridSearchCV API
GridSearchCV 是一个用于超参数优化的工具,可以通过系统地遍历不同的参数组合来找到最佳的模型参数,进而提高模型的性能。下面是几个常用的参数及其意义:
estimator: 传入一个模型对象,该模型需要实现fit()和predict()方法,这个模型会在参数网格上进行优化。param_grid: 一个字典或列表,用于指定参数的取值范围,网格搜索会遍历所有的参数组合,将最优参数组合作为模型的最终参数。cv: 交叉验证生成器或迭代器,用于确定交叉验证的折数或生成样本的分割策略。scoring: 模型评价标准,可以是字符串、自定义函数或可调用的对象,用于对每个候选参数组合进行评价。n_jobs: 并行运行的作业数。verbose: 控制详细程度的参数,可以设置为 0(不输出任何信息)到 10(输出所有信息)之间的值。
下面是一个简单的示例,演示如何使用交叉验证和网格搜索来选择最优的KNN模型超参数对上一个python示例代码进行优化
from sklearn.datasets import load_iris from sklearn.model_selection import GridSearchCV, train_test_split from sklearn.neighbors import KNeighborsClassifier# 加载数据 iris = load_iris() X, y = iris.data, iris.target# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)# 定义KNN模型 knn = KNeighborsClassifier()# 定义参数的搜索空间 param_grid = {'n_neighbors': [1, 3, 5, 7, 9]}# 使用GridSearchCV进行模型选择和调优 grid_search = GridSearchCV(knn, param_grid=param_grid, cv=5) grid_search.fit(X_train, y_train)# 输出最优参数和交叉验证的结果 print('Best parameter:', grid_search.best_params_) print('Best cross-validation score:', grid_search.best_score_) print('Test set score:', grid_search.score(X_test, y_test))
上述代码中,首先加载数据,然后划分训练集和测试集。接着,定义KNN模型,并定义参数的搜索空间。然后使用GridSearchCV进行模型选择和调优。最后输出最优参数和交叉验证的结果。

朴素贝叶斯(Naive Bayes) 算法
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类算法,它假设样本特征之间相互独立,因此被称为“朴素”。
朴素贝叶斯算法在文本分类、垃圾邮件过滤、情感分析等领域得到广泛应用,其原理是基于贝叶斯定理,通过计算样本在给定类别的条件下的概率来进行分类。
具体来说,对于一个待分类的样本,朴素贝叶斯算法会计算它属于每个类别的概率,并将概率最大的类别作为分类结果。计算样本属于某个类别的概率时,需要通过先验概率和似然概率来计算后验概率。先验概率指的是样本属于某个类别的概率,而似然概率指的是样本在给定类别下的特征出现概率。朴素贝叶斯算法假设样本特征之间相互独立,因此可以将特征的似然概率相乘来计算样本在给定类别下的概率。
MultinomialNB 和 GaussianNB 区别
MultinomialNB适用于特征是离散值的情况,例如文本分类问题,其中特征是单词或短语的出现次数或出现概率。在MultinomialNB中,每个特征的概率分布是一个多项分布。
GaussianNB适用于特征是连续值的情况,例如数据集中的各种测量结果。在GaussianNB中,每个特征的概率分布是一个高斯分布。
在使用朴素贝叶斯分类器时,应根据特征类型选择合适的模型。
下面是一个使用Scikit-learn库中的MultinomialNB和GaussianNB进行文本分类的示例:
from sklearn.naive_bayes import MultinomialNB, GaussianNB from sklearn.feature_extraction.text import CountVectorizer from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split# 加载数据集 newsgroups = fetch_20newsgroups(subset='test',data_home='./data')# 对文本进行特征提取 vectorizer = CountVectorizer() X = vectorizer.fit_transform(newsgroups.data) y = newsgroups.target# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 使用MultinomialNB进行分类 mnb = MultinomialNB() mnb.fit(X_train, y_train) print("MultinomialNB accuracy:", mnb.score(X_test, y_test))# 使用GaussianNB进行分类 gnb = GaussianNB() gnb.fit(X_train.toarray(), y_train) print("GaussianNB accuracy:", gnb.score(X_test.toarray(), y_test))
这个例子加载了Scikit-learn库中的20个新闻组数据集,使用CountVectorizer进行文本特征提取,并使用MultinomialNB和GaussianNB进行分类。其中,MultinomialNB适用于文本分类问题,而GaussianNB不太适用。

决策树(Decision Tree)
决策树(Decision Tree)是一种基于树结构的分类器,通过对一系列问题的回答,逐步向下递归,最终得到一棵决策树,每个叶节点代表一种类别。决策树算法的优点是可以处理离散型和连续型数据,且易于理解和解释,缺点是容易产生过拟合。
决策树是一种常用的分类和回归算法,在许多场景下都可以得到很好的应用。一般来说,决策树适用于以下情况:
-
数据量不大且特征比较简单:决策树在处理数据量不大且特征比较简单的数据集时,运行速度较快,同时也比较容易理解和解释生成的决策树。
-
需要理解和解释分类规则:生成的决策树可以用于直观地表示分类规则,可以帮助人们更好地理解和解释分类规则,特别是在一些需要向其他人进行解释的场景中,决策树的解释性非常有用。
-
特征具有一定的可解释性:决策树适用于特征具有一定的可解释性的情况,例如医学诊断等领域中的数据分析,特征的可解释性对于专家评估非常重要。
-
需要进行特征选择:在决策树的构建过程中,根据特征的重要性对特征进行选择,可以得到更简洁、更容易理解和解释的分类器。
class sklearn.tree.DecisionTreeClassifier API是决策树分类器的实现,主要用于分类问题。其中的参数和方法包括:
criterion: 切分质量的评价准则,可选值为"gini"或"entropy"。
splitter: 决策树分裂策略,可选值为"best"或"random"。
max_depth: 决策树最大深度,用于防止过拟合。
min_samples_split: 节点分裂所需的最小样本数。
min_samples_leaf: 叶节点所需的最小样本数。
max_features: 每个节点评估分裂时要考虑的最大特征数。
random_state: 随机数种子,用于控制每次运行时的随机性。
fit(X, y): 拟合决策树模型。
predict(X): 对X进行预测。
score(X, y): 返回模型在测试集上的精度得分。
下面是一个简单的示例,使用 sklearn.tree.DecisionTreeClassifier 对鸢尾花数据集进行分类:
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score# 加载数据 iris = load_iris() X, y = iris.data, iris.target# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型 clf = DecisionTreeClassifier(random_state=42)# 训练模型 clf.fit(X_train, y_train)# 在测试集上评估模型 y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy)
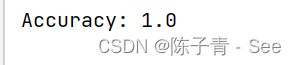
在上面的代码中,首先使用
load_iris()函数加载鸢尾花数据集,然后使用train_test_split()函数将数据集划分为训练集和测试集。接下来,使用DecisionTreeClassifier类创建决策树模型,并使用训练集对模型进行训练。最后,在测试集上评估模型的准确率。
随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
学习算法根据下列算法而建造每棵树:
- 用N来表示训练用例(样本)的个数,M表示特征数目。
- 1、一次随机选出一个样本,重复N次, (有可能出现重复的样本)
- 2、随机去选出m个特征, m <<M,建立决策树
- 采取bootstrap抽样(一种随机放回抽样的方法)
RandomForestClassifier的使用方法与其他scikit-learn的分类器类似,可以通过fit()方法拟合模型,predict()方法预测结果,score()方法评估模型性能,等等。其中,最常用的参数包括:
n_estimators:森林中决策树的数量。criterion:决策树的分裂标准,可以选择"gini"或"entropy"。max_depth:决策树的最大深度,控制决策树的复杂度。min_samples_split:决策树分裂所需的最小样本数。min_samples_leaf:叶节点所需的最小样本数。max_features:用于每个决策树的特征数量,可以选择"auto"、"sqrt"、"log2"或任意整数。bootstrap:是否使用有放回的随机抽样来训练每个决策树。
下面是一个使用RandomForestClassifier进行分类的示例代码:
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier# 生成随机数据 X, y = make_classification(n_samples=10000,n_features=100, n_informative=20,n_classes=5, random_state=1)# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state=1)# 创建随机森林分类器 clf = RandomForestClassifier(n_estimators=100, max_depth=100) tree =DecisionTreeClassifier() # 训练模型 clf.fit(X_train, y_train) tree.fit(X_train,y_train) # 预测测试集 y_pred = clf.predict(X_test) y_t_pred = tree.predict(X_test)# 评估模型性能 score = clf.score(X_test, y_test) tree_score = tree.score(X_test, y_test) print("Accuracy: {:.2f}%".format(score*100)) print("Tree Accuracy: {:.2f}%".format(tree_score*100))
相关文章:

Python机器学习入门笔记(2)—— 分类算法
目录 转换器(transformer)和估计器(estimator) K-近邻(K-Nearest Neighbors,简称KNN)算法 模型选择与调优 交叉验证(Cross-validation) GridSearchCV API 朴素贝叶…...

Docker镜像发布到阿里云和私有库
目录 一、Docker镜像 (一)概述 (二)Docker镜像加载原理 (三)镜像分层结构优势 (四)重点理解 (五)docker commit操作实例 (六)总…...
初识CSS,美化HTML
CSS称为:层叠样式表(Cascading style sheets)美化HTML即给页面种的HTML标签设置样式CSS语法规则css要写在head标签的里边,title标签的下面,用style标签框住<head> <title>...</title> <style>…...
)
华为OD机试 - 二维矩阵的最大值(Python)
题目二维矩阵的最大值 给定一个仅包含0和1的n*n二维矩阵 请计算二维矩阵的最大值 计算规则如下 每行元素按下标顺序组成一个二进制数(下标越大约排在低位), 二进制数的值就是该行的值,矩阵各行之和为矩阵的值允许通过向左或向右整体循环移动每个元素来改变元素在行中的位置 …...
)
华为OD机试 - 快递业务站(Python)
快递业务站 题目 快递业务范围有 N 个站点,A 站点与 B 站点可以中转快递,则认为 A-B 站可达, 如果 A-B 可达,B-C 可达,则 A-C 可达。 现在给 N 个站点编号 0、1、…n-1,用 s[i][j]表示 i-j 是否可达, s[i][j] = 1表示 i-j可达,s[i][j] = 0表示 i-j 不可达。 现用二维…...

百度沈抖:文心一言将通过百度智能云对外提供服务
2月17日,在2023 AI工业互联网高峰论坛上,百度智能云宣布“文心一言”将通过百度智能云对外提供服务,为产业带来AI普惠。 百度集团执行副总裁、百度智能云事业群总裁沈抖表示,“文心一言”是基于百度智能云技术打造出来的大模型&a…...

cmd 窗口、记事本打开后一片空白且几秒钟后闪退的问题解决方案汇总
前言 前段时间,电脑忽然出现了问题,首先是通过 微软应用商店 Microsoft Store 下载安装的 Snipaste 截图软件崩溃,不过将其卸载后,通过电脑管家下载后又可以正常使用了。 之后就是突然发现,记事本文本文档不能使用了…...

Linux 安装 SNMP服务
从安装盘IOS中导入安装SNMP. --挂载系统安装盘 [rootnb /]# mount -o loop -t iso9660 /software/radhat.iso /media mount: /dev/loop0 is write-protected, mounting read-only --导入安装包 [rootnb /]# rm -f /etc/yum.repos.d/*.repo [rootnbubackup /]# cat >/etc/yu…...
)
华为OD机试 - 滑动窗口最大和(Python)
滑动窗口最大和 有一个N个整数的数组,和一个长度为M的窗口。 窗口从数组内的第一个数开始滑动,直到窗口不能滑动为止。 每次滑动产生一个窗口,和窗口内所有数的和, 求窗口滑动产生的所有窗口和的最大值 输入 第一行输入一个正整数N,表示整数个数0 < N < 100000 …...
用Nacos搭建微服务操作
Nacos服务搭建 我们首先在Nacos的GitHub中下载相关的安装文件。https://github.com/alibaba/nacos/releases 但是因为服务器在国外,所以我们直接给大家提供了对应的安装文件。直接解压缩到非中文的目录下,然后启动即可 服务访问的地址是:htt…...

ChatGPT模型采样算法详解
ChatGPT模型采样算法详解 ChatGPT所使用的模型——GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果…...
【Unity3d】Unity与iOS通信
在unity开发或者sdk开发经常需要用到unity与oc之间进行交互,这里把它们之间通信代码整理出来。 Unity调用Objective-C 主要分三个步骤: (一)、在xcode中定义要被unity调用的函数 新建一个类,名字可以任意,比如UnityBridge&…...

RDD的持久化【博学谷学习记录】
RDD的缓存缓存: 一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从…...

Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。 re 模块使 Python 语言拥有全部的正则表达式功能。 compile 函数根…...

Qt-基础
Qt1. 概念其他概念对话框模态对话框与非模态对话框事件事件拦截/过滤事件例子鼠标/屏幕使用界面功能qt-designer工具debug目录结构mainwindow控件窗口QMainWindow事件2. 项目概览QOBJECT tree 对象树3. 信号和槽信号函数关联自定义信号和槽函数自定义信号和槽函数1自定义信号和…...

ABB机器人将实时坐标发送给西门子PLC的具体方法示例
ABB机器人将实时坐标发送给西门子PLC的具体方法示例 本次以PROFINET通信为例进行说明,演示ABB机器人将实时坐标发送给西门子PLC的具体方法。 首先,要保证ABB机器人和PLC的信号地址分配已经完成,具体的内容可参考以下链接: S7-1200PLC与ABB机器人进行PROFINET通信的具体方法…...

反向传播与梯度下降详解
一,前向传播与反向传播 1.1,神经网络训练过程 神经网络训练过程是: 先通过随机参数“猜“一个结果(模型前向传播过程),这里称为预测结果 a a a;然后计算 a a a 与样本标签值...
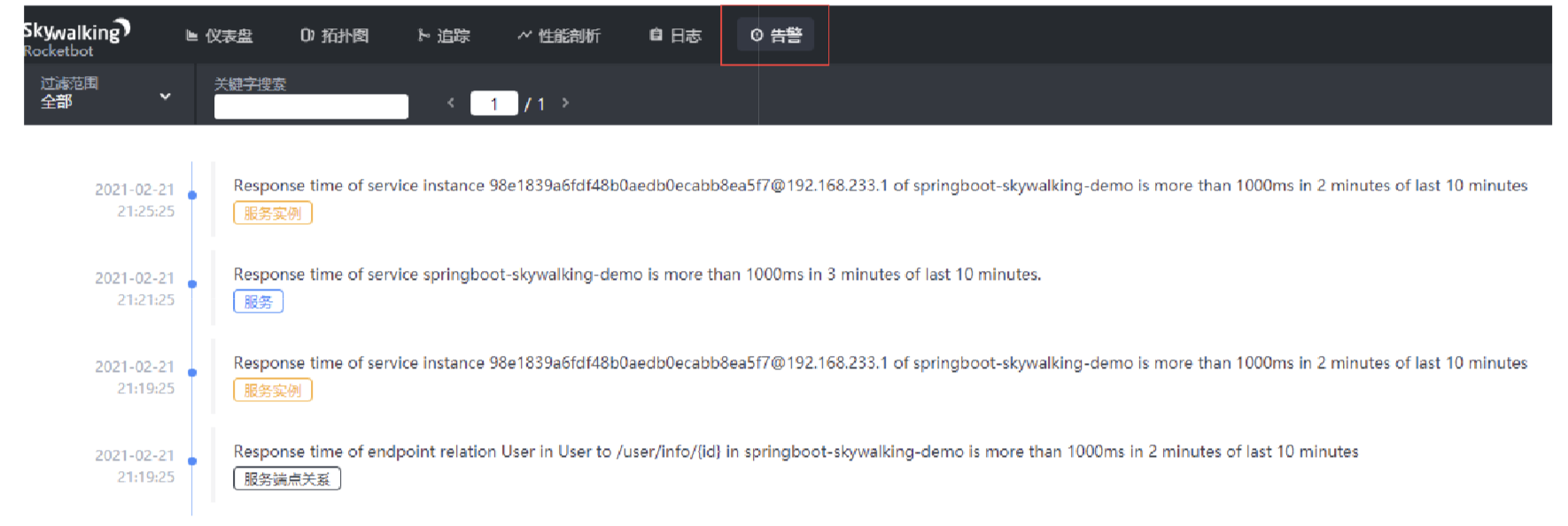
Skywalking ui页面功能介绍
菜单栏 仪表盘:查看被监控服务的运行状态; 拓扑图:以拓扑图的方式展现服务之间的关系,并以此为入口查看相关信息; 追踪:以接口列表的方式展现,追踪接口内部调用过程; 性能剖析&am…...
哪里可以找到免费的 PDF 阅读编辑器?7 个免费 PDF 阅读编辑器分享
如果您曾经需要编辑 PDF,您可能会发现很难找到免费的 PDF 编辑器。幸运的是,您可以使用在线资源来编辑该文档,而无需为软件付费。 在本文中,我将介绍七种不同的 PDF 编辑器,它们至少可以让您免费编辑几个文件。我通过…...
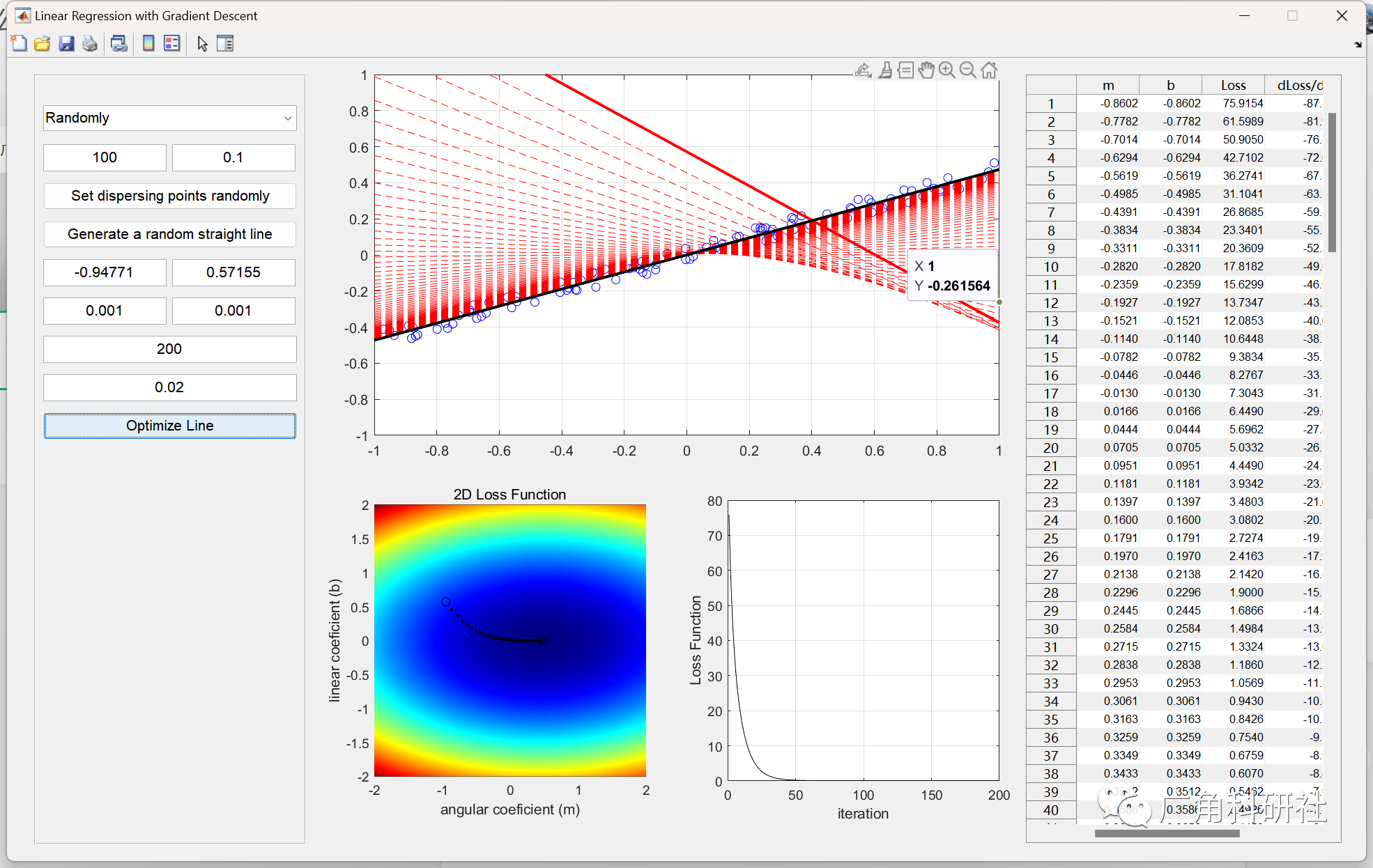
使用梯度下降的线性回归(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 梯度下降法,是一种基于搜索的最优化方法,最用是最小化一个损失函数。梯度下降是迭代法的一种,可以用于求…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...