如何使用Kafka构建事件驱动的架构
事件驱动的架构(EDA)是一种软件设计模式,它关注事件的生成、检测和使用,以支持高效和可扩展的系统。在EDA中,事件是组件之间通信的主要手段,允许它们实时交互和响应更改。这种架构促进了松散耦合、可扩展性和响应性,使其非常适合现代的、分布式以及高度可扩展的应用程序。EDA已成为现代系统中实现敏捷性和无缝集成的一种强大解决方案。
在事件驱动的架构中,事件表示系统中的重要事件或变化,例如用户操作、系统流程或外部服务的各种来源都可以生成这些事件。被称为事件生产者的组件将事件发布到中央事件总线或代理,后者充当事件分发的中介。其他组件称为事件消费者,它们订阅感兴趣的特定事件并做出相应的反应。
EDA的一个关键优势是它能够支持敏捷性和灵活性。事件驱动系统中的组件可以独立发展,从而允许更容易的维护、更新和可扩展性。在不影响整个系统的情况下,可以通过引入新的事件类型或订阅现有事件来添加新的功能。这种灵活性和可扩展性使得EDA特别适合于动态和不断发展的业务需求。
EDA还促进了不同系统或服务之间的无缝集成。通过使用事件作为通信机制,EDA支持互操作性,而不考虑底层技术或编程语言。事件为系统交换信息提供了一种标准化和松散耦合的方式,使企业能够更容易地集成不同的系统。这种集成方法促进了模块化和可重用性,因为组件可以在不破坏整个系统的情况下连接或断开。
EDA的关键组件:启用事件流和处理
EDA由几个关键组件组成,这些组件支持系统内的事件流和处理。这些组件一起工作以促进事件的生成、分发、使用和处理。以下是EDA的关键组件:
(1)事件生产者
事件生产者负责生成和发布事件。它们可以是系统内的各种实体,例如用户界面、应用程序、微服务或外部系统。事件生产者捕获重要的事件或更改,并向事件总线或代理发送事件。这些事件可以由用户操作、系统事件、传感器数据或任何其他相关源触发。
(2)事件总线/代理
事件总线/代理充当事件的中央通信通道。它接收事件生产者发布的事件,并将它们分发给感兴趣的事件消费者。事件总线/代理可以是消息队列、发布/订阅系统或专门的事件流平台。它确保可靠的事件交付,将事件生产者与事件消费者分离,并支持异步事件处理。
(3)事件消费者
事件消费者订阅感兴趣的特定事件或事件类型。它们从事件总线/代理接收事件并相应地处理它们。事件消费者可以是系统中的各种组件,例如微服务、工作流或数据处理器。它们通过执行业务逻辑、更新数据、触发进一步的操作或与其他系统通信来响应事件。
(4)事件处理程序
事件处理程序负责处理事件使用者接收到的事件。它们包含基于事件内容执行特定操作的业务逻辑和规则。事件处理程序可以执行数据验证、状态更改、数据库更新、触发器通知或调用其他服务。它们封装了与特定事件相关的行为,并确保系统内正确的事件处理。
(5)事件存储
事件存储是记录系统中所有已发布事件的持久数据存储组件,它提供事件及其相关数据的历史记录。事件存储支持事件重播、审计和事件溯源模式,允许系统基于过去的事件重建其状态。它在事件驱动的架构中支持可扩展性、容错和数据一致性。

通过利用这些关键组件,EDA支持系统内事件的平滑流、分布和处理。事件生产者、事件总线/代理、事件消费者、事件处理程序和事件存储一起工作,以创建松散耦合、可扩展和响应的系统,该系统可以处理实时事件驱动的交互,适应不断变化的需求,并与外部系统或服务集成。
EDA模式:为可扩展性和自主性构建系统
EDA提供了几种模式,帮助构建系统以实现可扩展性和自主性。这些模式增强了处理许多事件、解耦组件以及支持独立开发和部署的能力。下面是EDA的一些关键模式:
(1)事件溯源
事件溯源是一种模式,其中应用程序的状态派生自一系列事件。对应用程序状态的所有更改都捕获为事件存储中的一系列事件,而不是存储当前状态。应用程序可以通过重播这些事件来重建其状态。事件溯源提供了完整的事件历史记录,允许进行细粒度查询,并使事件处理器能够轻松复制和扩展,从而实现了可扩展性和可审计性。
(2)命令和查询职责分离(CQRS)
命令和查询职责分离(CQRS)是一种模式,它将读写操作分离到单独的模型中。写入模型又称为命令模型,处理改变系统状态和产生事件的命令。读取模型(称为查询模型)处理查询并更新其自身优化的数据视图。CQRS允许独立扩展读和写操作,通过针对特定查询需求优化读模型来增强性能,并提供独立发展每个模型的灵活性。
(3)发布/订阅
发布/订阅模式通过将事件生产者与事件消费者分离来实现松散耦合和可扩展性。在这一模式中,事件生产者将事件发布到中央事件总线/代理,而不知道哪些特定的消费者将接收它们。事件使用者订阅他们感兴趣的特定类型的事件,事件总线/代理将事件分发给相关的订阅者。此模式支持灵活性、可扩展性以及在不影响事件生产者或其他消费者的情况下添加或删除消费者的能力。
(4)事件驱动的消息
事件驱动的消息传递涉及基于事件的组件之间的消息交换。它支持组件之间的异步通信和松散耦合。在这一模式中,事件生产者将事件发布到消息队列、主题或事件中心,事件使用者从消息传递基础设施中使用这些事件。这一模式允许组件独立工作,提高系统可扩展性,并支持可靠的异步事件处理。
通过采用这些模式,系统的结构可以有效地处理可扩展性和自主性。事件源、CQRS、发布/订阅和事件驱动的消息传递模式促进松散耦合,支持组件的独立扩展,提供容错能力,增强性能,并支持在事件驱动的架构中无缝集成系统和服务。这些模式有助于构建有弹性、可扩展和可适应的系统,这些系统可以处理大量事件,同时保持各个组件的高度自治。
Kafka:支持实时数据流和事件驱动的应用程序
Kafka是一个分布式流平台,广泛用于构建实时数据流和事件驱动应用程序。它旨在处理大量数据,并提供低延迟、可扩展和容错的流处理。Kafka支持系统之间无缝可靠的数据流,使其成为构建事件驱动架构的强大工具。
Kafka的核心是使用发布/订阅模型,其中数据被组织到主题中。事件生产者将数据写入主题,事件消费者订阅这些主题以实时接收数据。Kafka的这种解耦特性允许异步和分布式处理事件,使应用程序能够处理大量数据并根据需要水平扩展。
Kafka的分布式架构提供了容错性和高可用性。它跨多个代理复制数据,确保即使在发生故障时数据也是持久的和可访问的。Kafka还支持数据分区,允许在多个事件消费者之间并行处理和负载平衡。这使得在处理实时数据流时实现高吞吐量和低延迟成为可能。
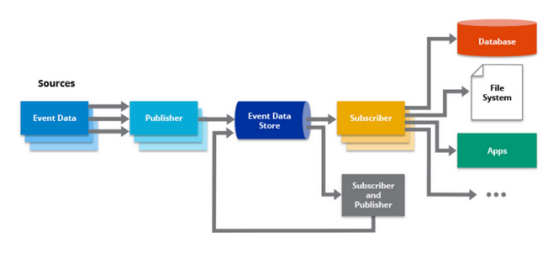
此外,Kafka与事件驱动架构生态系统的其他组件集成得很好。它可以充当中央事件总线,支持不同服务和系统之间的无缝集成和通信。Kafka Connect提供了与各种数据源和接收器集成的连接器,简化了集成过程。Kafka Streams是一个建立在Kafka之上的流处理库,允许实时处理和转换数据流,使复杂的事件驱动应用程序可以轻松构建。
构建Kafka EDA的分步指南
Kafka已经成为一个强大的流媒体平台,能够开发强大且可扩展的EDA。凭借其分布式、容错和高通量的能力,Kafka非常适合构建实时数据流和事件驱动的应用程序。以下是从设计到实现的构建Kafka EDA的步骤。
步骤1:定义系统需求
首先要清楚地定义EDA的目标和需求。确定需要捕获的事件类型、所需的可扩展性和容错性,以及任何特定的业务需求或约束。
步骤2:设计事件生成器
识别生成事件的源,并设计可以在Kafka主题上发布这些事件的事件生成器。无论是应用程序、服务还是系统,都要确保事件结构正确,并包含相关的元数据。考虑使用Kafka生产者库或框架来简化实现。
创建生产者的示例Python代码:
Python from kafka import KafkaProducer# Kafka broker configurationbootstrap_servers = 'localhost:9092'# Create Kafka producerproducer = KafkaProducer(bootstrap_servers=bootstrap_servers)# Define the topic to produce messages totopic = 'test_topic'# Produce a messagemessage = 'Hello, Kafka Broker!'producer.send(topic, value=message.encode('utf-8'))
15
16 # Wait for the message to be delivered to Kafka
17 producer.flush()
18
19 # Close the producer
20 producer.close()
21步骤3:创建Kafka主题
在Kafka中定义主题,作为事件通信的通道。根据预期的负载和数据需求仔细规划主题结构、分区策略、复制因素和保留策略。确保主题与事件粒度一致,并支持未来的可扩展性。
步骤4:设计事件消费者
确定将使用和处理Kafka事件的组件或服务。设计订阅相关主题并执行实时处理的事件消费者。考虑所需使用者的数量,并相应地设计使用者应用程序。
创建消费者的示例Python代码:
Python from kafka import KafkaConsumer# Kafka broker configurationbootstrap_servers = 'localhost:9092'# Create Kafka consumerconsumer = KafkaConsumer(bootstrap_servers=bootstrap_servers)# Define the topic to consume messages fromtopic = 'test_topic'# Subscribe to the topicconsumer.subscribe(topics=[topic])# Start consuming messagesfor message in consumer:# Process the consumed messageprint(f"Received message: {message.value.decode('utf-8')}")# Close the consumerconsumer.close()
步骤5:实现事件处理逻辑
在使用者应用程序中编写事件处理逻辑。这可能涉及数据转换、丰富、聚合或任何其他特定于业务的操作。利用Kafka的消费者组功能在多个实例之间分配处理负载,并确保可扩展性。
步骤6:确保容错
实现容错机制,处理故障,确保数据的持久性。为Kafka代理配置合适的复制因子以提供数据冗余。在使用者应用程序中实现错误处理和重试机制,以处理异常情况。
步骤7:监控和优化性能
设置监控和可观察性工具来跟踪Kafka集群和事件驱动应用程序的运行状况和性能。监控吞吐量、延迟和使用者延迟等关键指标,以识别瓶颈并优化系统。考虑利用Kafka的内置监控功能或与第三方监控解决方案集成。
步骤8:与下游系统集成
确定事件驱动的架构将如何与下游系统或服务集成。设计连接器或适配器,以实现Kafka到其他系统的无缝数据流。探索Kafka Connect,这是一个与外部数据源或接收器集成的强大工具。
步骤9:测试和迭代
彻底测试EDA,以确保其可靠性、可扩展性和性能。执行负载测试以验证系统在不同工作负载下的行为。基于测试结果和真实世界的反馈,迭代和改进设计。
步骤10:扩展和发展
随着系统的增长,监控其性能并相应地进行扩展。添加更多Kafka代理,调整分区策略,或优化消费者应用程序来处理增加的数据量。
Kafka EDA的用例
Kafka EDA由于其处理高吞吐量、容错和实时数据流的能力,已经在各个领域有了各种应用。以下是Kafka擅长的一些常见用例:
实时数据处理和分析:Kafka处理大容量、实时数据流的能力使其成为处理和分析大规模数据的理想选择。用户可以将来自多个来源的数据摄取到Kafka主题中,然后使用Apache Flink、Apache Spark或Kafka Streams等流式框架实时处理和分析数据。该用例在实时欺诈检测、监控物联网设备、点击流分析和个性化推荐等场景中很有价值。
- 事件驱动的微服务架构:Kafka在微服务架构中充当通信骨干,不同的服务通过事件进行通信。每个微服务都可以充当事件生产者或消费者,从而支持松散耦合和可扩展的架构。Kafka确保可靠和异步的事件交付,使服务能够独立运行,并以自己的速度处理事件。这个用例有助于构建可扩展和解耦的系统,在基于微服务的应用程序中实现敏捷性和自主性。
- 日志聚合和流处理:Kafka的持久性和容错特性使其成为日志聚合和数据流处理的绝佳选择。通过将日志事件发布到Kafka主题,用户可以集中来自不同系统的日志,并执行实时分析或存储它们以备将来的审计、调试或合规目的。Kafka与Elasticsearch和Apache Hadoop生态系统等工具的集成实现了高效的日志索引、搜索和分析。
- 消息和数据集成:Kafka的发布/订阅模型和分布式特性使其成为集成不同应用程序和系统的可靠消息系统。它可以作为在系统之间传输消息的数据总线,支持解耦和异步通信。Kafka的连接器允许与其他数据系统(例如关系数据库、Hadoop和云存储)无缝集成,支持数据管道和ETL进程。
- 物联网:Kafka以容错和可扩展的方式处理大量流数据的能力非常适合物联网应用。它可以实时获取和处理来自物联网设备的数据,实现实时监控、异常检测和警报。Kafka的低延迟特性使其成为物联网用例的绝佳选择,在这些用例中,快速响应时间和实时洞察至关重要。
这些只是Kafka EDA可以应用的广泛用例的几个例子。它的灵活性、可扩展性和容错性使其成为处理流数据和构建实时事件驱动应用程序的通用平台。
相关内容拓展:(技术前沿)
近10年间,甚至连传统企业都开始大面积数字化时,我们发现开发内部工具的过程中,大量的页面、场景、组件等在不断重复,这种重复造轮子的工作,浪费工程师的大量时间。
针对这类问题,低代码把某些重复出现的场景、流程,具象化成一个个组件、api、数据库接口,避免了重复造轮子。极大的提高了程序员的生产效率。
体验官网:https://www.jnpfsoft.com/?csdn,还没有了解低代码这项技术可以赶紧体验学习!
推荐一款程序员都应该知道的软件JNPF快速开发平台,采用业内领先的SpringBoot微服务架构、支持SpringCloud模式,完善了平台的扩增基础,满足了系统快速开发、灵活拓展、无缝集成和高性能应用等综合能力;采用前后端分离模式,前端和后端的开发人员可分工合作负责不同板块,省事又便捷。
结论
Kafka EDA彻底改变了用户处理数据流和构建实时应用程序的方式。凭借其处理高吞吐量、容错数据流的能力,Kafka支持可扩展和解耦的系统,从而增强灵活性、自主性和可扩展性。无论是实时数据处理、微服务通信、日志聚合、消息集成还是物联网应用,Kafka的可靠性、可扩展性和无缝集成能力使其成为构建EDA的强大工具,这些架构可以驱动实时洞察,并使用户能够利用其数据的价值。
相关文章:
如何使用Kafka构建事件驱动的架构
事件驱动的架构(EDA)是一种软件设计模式,它关注事件的生成、检测和使用,以支持高效和可扩展的系统。在EDA中,事件是组件之间通信的主要手段,允许它们实时交互和响应更改。这种架构促进了松散耦合、可扩展性和响应性,使…...

ES6 解构赋值
解构赋值 解构赋值是一种在编程中常见且方便的语法特性,它可以让你从数组或对象中快速提取数据,并将数据赋值给变量。在许多编程语言中都有类似的特性。 在 JavaScript 中,解构赋值使得从数组或对象中提取数据变得简单。它可以用于数组和对…...

HTML5注册页面
分析 注册界面实际上是一个表格(对齐),一行有两个单元格。 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevic…...

python中的JSON模块详解
简介 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写 同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互 网址 官方文档 json — JSON encoder and dec…...
Syncfusion Essential Edit for WPF Crack
Syncfusion Essential Edit for WPF Crack 在任何WPF应用程序中启用语法高亮显示。 Syncfusion Essential Edit for WPF是一款具有所有基本功能的编辑器,如文本编辑、剪切、复制和粘贴。它允许用户从各种文件格式打开文件并将其保存为各种文件格式。Syncfusion Esse…...
机器学习深度学习——卷积神经网络(LeNet)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——池化层 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 卷积神…...

Pytorch Tutorial【Chapter 2. Autograd】
Pytorch Tutorial 文章目录 Pytorch TutorialChapter 2. Autograd1. Review Matrix Calculus1.1 Definition向量对向量求导1.2 Definition标量对向量求导1.3 Definition标量对矩阵求导 2.关于autograd的说明3. grad的计算3.1 Manual手动计算3.2 backward()自动计算 Reference C…...

Python第三方库国内镜像下载地址
Python第三方库国内镜像下载地址 一、清华大学二、中国科技大学三、安装方法 一、清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 二、中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple 三、安装方法 例如 pyhook3 插件的安装方法,执行下面命令安装…...
服务端机器一般部署在哪里)
从浏览器输入url到页面加载(七)服务端机器一般部署在哪里
前言 上一节,我们说到了CDN和路由器的关系,说到了公有地址,说到了通信线路服务,这一节跳过那些看不懂的深层知识,直接开始说web服务器。 1. 服务端机器为什么不部署在公司内部 记得在之前的一段时间里,公…...
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
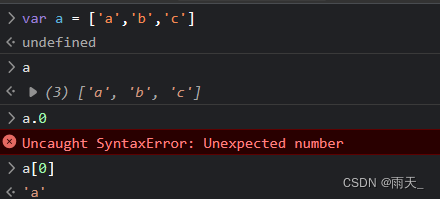
安全基础 --- https详解 + 数组(js)
CIA三属性:完整性(Confidentiality)、保密性(Integrity)、可用性(Availability),也称信息安全三要素。 https 核心技术:用非对称加密传输对称加密的密钥,然后…...

vue加载大量数据优化
在Vue中加载大量数据并形成列表时,可以通过以下方法来优化性能: 分页加载:不要一次性加载所有的数据,而是分批加载数据,每次只加载当前页需要显示的数据量。可以使用第三方库如vue-infinite-loading来实现无限滚动加载…...

WebRTC 之音视频同步
在网络视频会议中, 我们常会遇到音视频不同步的问题, 我们有一个专有名词 lip-sync 唇同步来描述这类问题,当我们看到人的嘴唇动作与听到的声音对不上的时候,不同步的问题就出现了 而在线会议中, 听见清晰的声音是优先…...
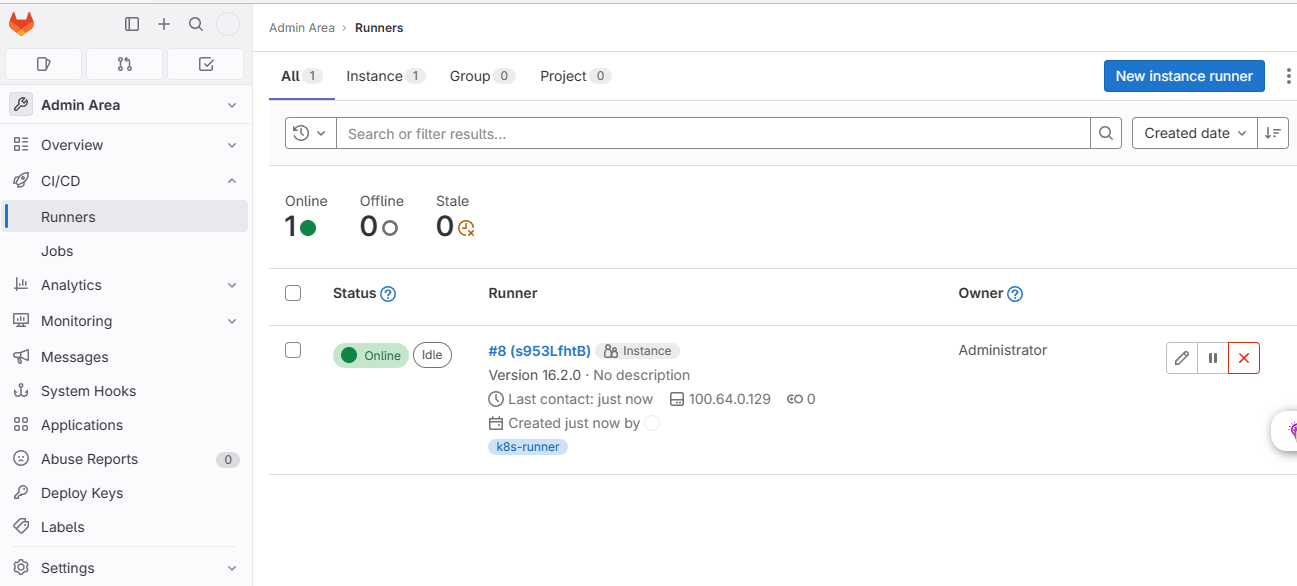
kubernetes基于helm部署gitlab-runner
kubernetes基于helm部署gitlab-runner 这篇博文介绍如何在 Kubernetes 中使用helm部署 GitLab-runner。 先决条件: 已运行的 Kubernetes 集群已运行的 gitlab 实例 项目地址:https://gitlab.com/gitlab-org/charts/gitlab-runner 官方文档ÿ…...

深度学习和OpenCV的对象检测(MobileNet SSD图像识别)
基于深度学习的对象检测时,我们主要分享以下三种主要的对象检测方法: Faster R-CNN(后期会来学习分享)你只看一次(YOLO,最新版本YOLO3,后期我们会分享)单发探测器(SSD,本节介绍,若你的电脑配置比较低,此方法比较适合R-CNN是使用深度学习进行物体检测的训练模型; 然而,…...
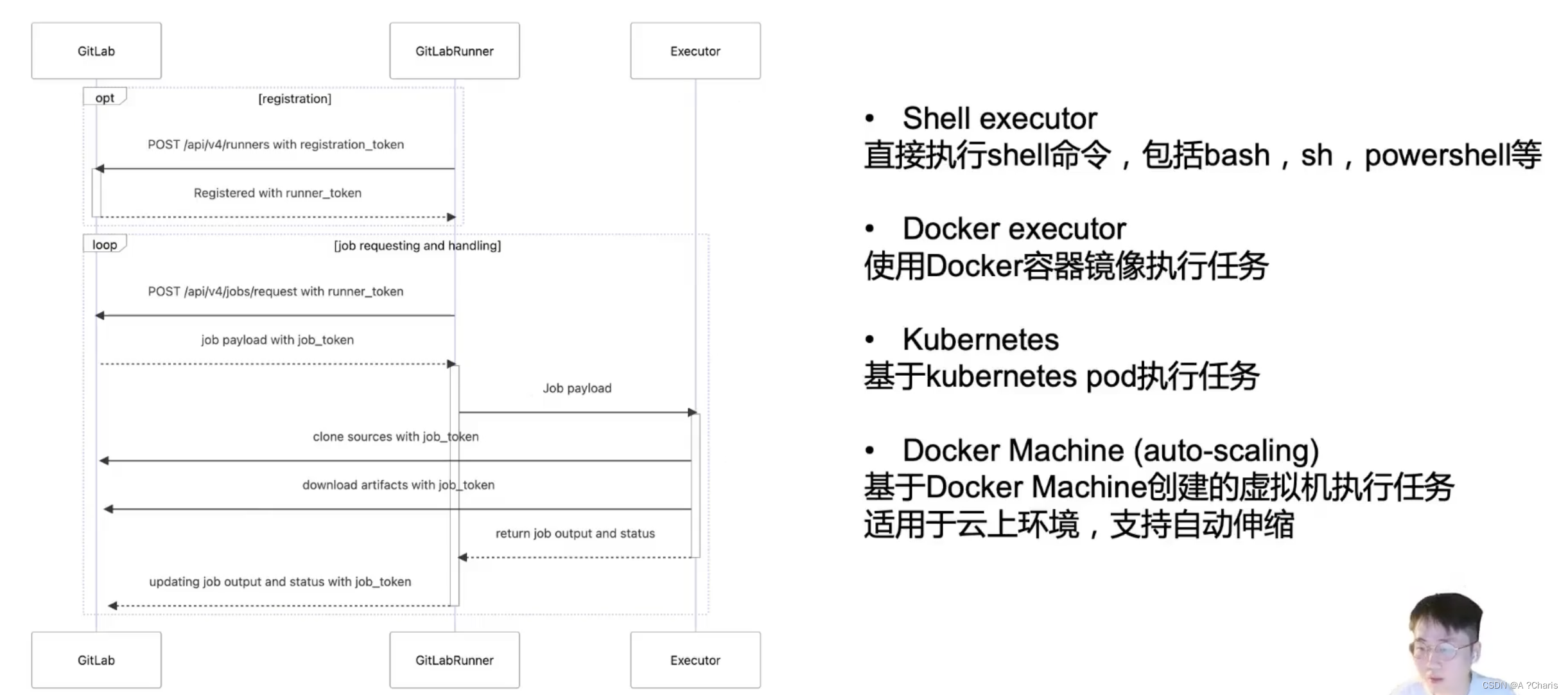
Gitlab CI/CD笔记-第一天-GitOps和以前的和jenkins的集成的区别
一、GitOps-CI/CD的流程图与Jenkins的流程图 从上图可以看到: GitOps与基于Jennkins技术栈的CI/CD流程,无法从Jenkins集成其他第三方开源的项目来实现换成了Gitlab来进行集成。 好处在于:CI 一个工具Gitlab就行了,但CD部分依旧是…...

有关OpenBSD, NetBSD, FreeBSD -- 与GPT对话
1 介绍一下 - OpenBSD, NetBSD, FreeBSD 当谈论操作系统时,OpenBSD、NetBSD和FreeBSD都是基于BSD(Berkeley Software Distribution)的操作系统,它们各自是独立开发的,并在BSD许可下发布。这些操作系统有很多共同点,但也有一些差异。以下是对它们的简要介绍: OpenBSD: O…...
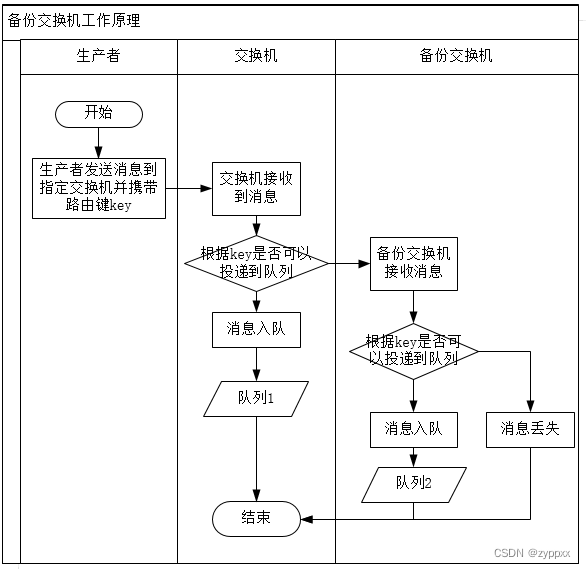
RabbitMQ 备份交换机和死信交换机
为处理生产者生产者将消息推送到交换机中,交换机按照消息中的路由键即自身策略无法将消息投递到指定队列中造成消息丢失的问题,可以使用备份交换机。 为处理在消息队列中到达TTL的过期消息,可采用死信交换机进行消息转存。 通过上述描述可知&…...

Linux 中利用设备树学习Ⅳ
系列文章目录 第一章 Linux 中内核与驱动程序 第二章 Linux 设备驱动编写 (misc) 第三章 Linux 设备驱动编写及设备节点自动生成 (cdev) 第四章 Linux 平台总线platform与设备树 第五章 Linux 设备树中pinctrl与gpio(…...
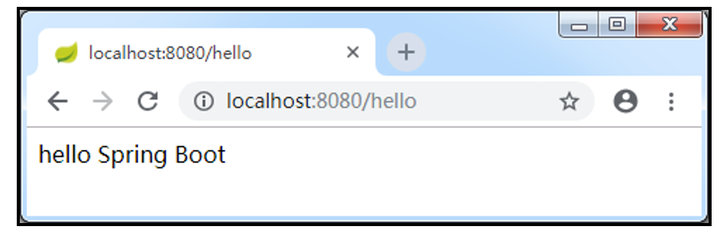
使用Spring Initializr方式构建Spring Boot项目
除了可以使用Maven方式构建Spring Boot项目外,还可以通过Spring Initializr方式快速构建Spring Boot项目。从本质上说,Spring lnitializr是一个Web应用,它提供了一个基本的项目结构,能够帮助我们快速构建一个基础的Spring Boot项目…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...
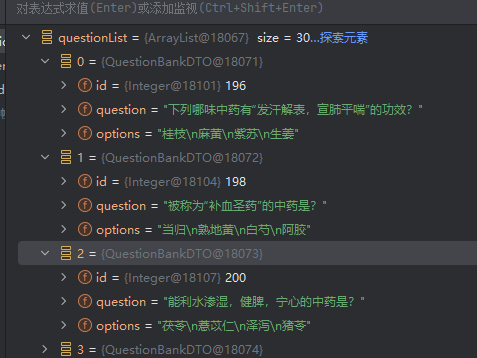
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...

多元隐函数 偏导公式
我们来推导隐函数 z z ( x , y ) z z(x, y) zz(x,y) 的偏导公式,给定一个隐函数关系: F ( x , y , z ( x , y ) ) 0 F(x, y, z(x, y)) 0 F(x,y,z(x,y))0 🧠 目标: 求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z、 …...