详解Kafka分区机制原理|Kafka 系列 二
Kafka 系列第二篇,详解分区机制原理。为了不错过更新,请大家将本号“设为星标”。
点击上方“后端开发技术”,选择“设为星标” ,优质资源及时送达
上一篇文章介绍了 Kafka 的基本概念和术语,里面有个概念是 分区(Partition)。
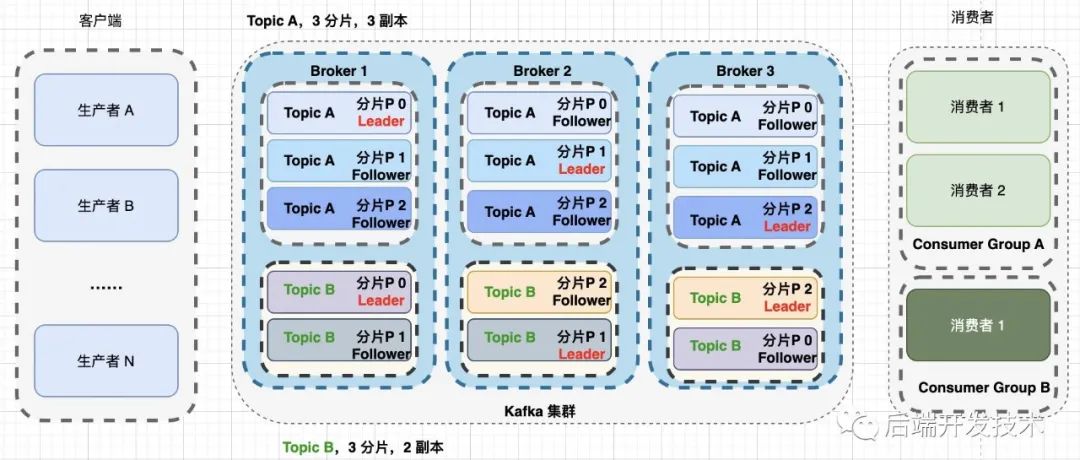
kafka 将 一个Topic 中的消息分成多份,分别存储在不同的 Broker 里,这每一段消息被 kafka 称为分区,其中每条消息只会保存在一个分区中。
如果不太理解请回顾上一篇:
开始学习 Kafka,一文掌握基本概念|Kafka 系列 一
为什么有分区?
为什么要有分区呢?
Kafka 的分区机制的本质就是将一个大的 Topic 进行拆分,将一组很大的队列拆分成了多组队列。这样做有以下几个好处:
-
因为一个 Topic 中的消息可能非常多,多到一台Broker存不下,因此需要拆分成多段存储在不同的机器里,实现负载均衡。
-
拆分成多个队列,可以在多个生产者和消费者的情况下发挥多机性能,可以分流和并行处理消息,从而提高读写性能,提升系统的吞吐力。
-
有利于系统扩缩容,提高系统的可扩展性。不同分区在不同的broker上,可以通过增加新机器提高吞吐,并且增加新机器的时候可以通过调整分区的分布来调配负载。
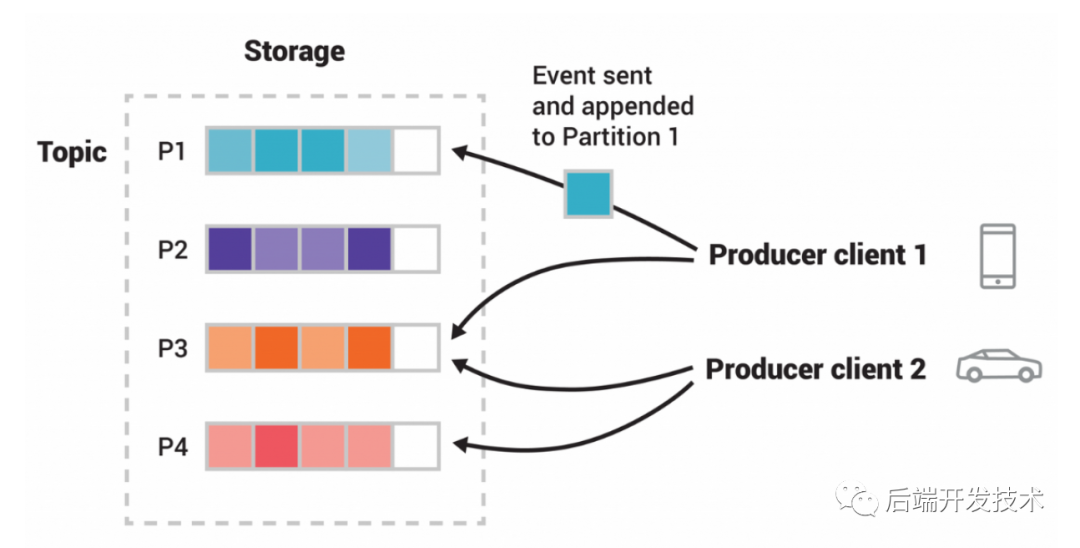
但是分区数不是越多越好,需要根据系统具体情况来设置。比如3个Broker就应该至少有3个分区,如果broker性能之间有差异,可以调大分区数进行调配。也可以通过broker的倍数来设置分区数,并且进行性能压测,测试集群的吞吐量。
分区数过多会带来资源管理上的消耗,清除日志时间变长,集群broker故障后分区leader重选时间变长,客户端消费端线程数需求增加,甚至导致连接所需的socket消耗增加。
分区策略
分区策略就是决定生产者将会把消息发送到具体哪个分区的算法,分区策略由 Partitioner 接口实现。
自定义分区策略
用于分区的 partition 方法定义如下:
/*** Compute the partition for the given record.** @param topic topic名 The topic name* @param key 用于分区的key The key to partition on (or null if no key)* @param keyBytes 用于分区的序列号key The serialized key to partition on( or null if no key)* @param value 用于分区的值 The value to partition on or null* @param valueBytes 用于分区的序列号值 The serialized value to partition on or null* @param cluster 当前集群元数据 The current cluster metadata*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);可以看出,这里提供了 Topic 和一些跟消息有关的key参数,cluster 是集群信息,包含Kafka 当前的Node 数据以及Topic、partition数据等。有了这些数据,具体拿到一条消息该发往哪个分区,我们就可以根据已有信息制定自己的分区策略。
# name of the partitioner class for partitioning events; default partition spreads data randomly
#partitioner.class=我们实现了自定义的 Partition 类之后,就可以设置 partitioner.class 为目标策略类,Producer 就会按照我们的自定义策略来对消息进行分区。
默认分区策略
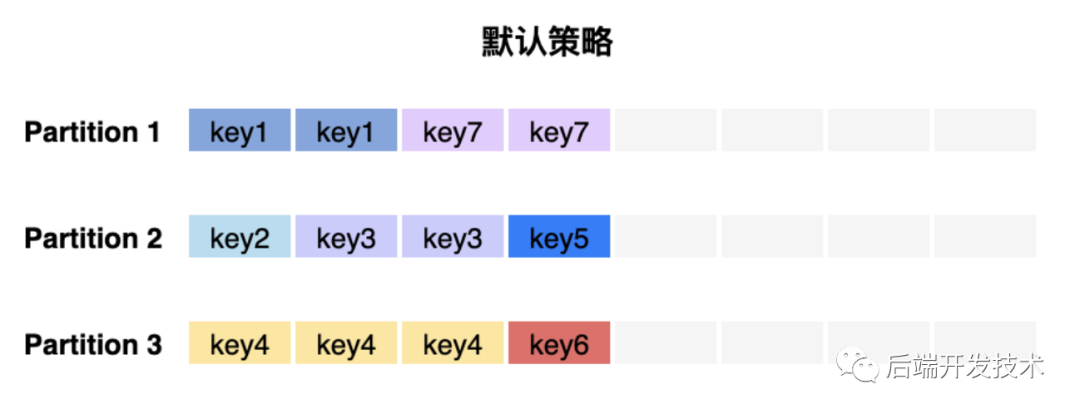
Kafka 提供了默认分区策略 DefaultPartitioner,策略内容如下:
-
如果在消息中指定了分区,优先使用指定的分区。
-
如果没有指定分区,但存在分区键,则根据序列化key使用murmur2哈希算法对分区数取模。
-
如果没有指定分区或分区键,则会使用粘性分区策略。(关于粘性分区策略后面讲解)
在实际生产中,我们一般都默认使用此策略,无需修改。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}注意,这里指的分区键是序列化后的key,也就是变量 keyBytes,其他key、value、valueBytes 并没用到。
byte[] keyBytes = keySerializer.serialize(topic, record.headers(), record.key());
default byte[] serialize(String topic, Headers headers, T data) {// data 变量return serialize(topic, data);
}看到 key 等序列化方法我们可以明白,key 的序列号值只受到 record.key() 的影响,所以同样的key会被固定分配到同样的partition中。(注意这里的key是指用于分区的key,而不是topic)
粘性分区策略
实现类为 UniformStickyPartitioner ,他与默认分区策略的区别是:
-
DefaultPartitionerd 默认分区策略:如果有分区键的话,会按照分区键来决定分区,这个时候并不会使用粘性分区策略。
-
UniformStickyPartitioner粘性分区策略:无论有没有分区键,都用粘性分区来分配。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return stickyPartitionCache.partition(topic, cluster);
}什么是粘性分区策略?
我们需要知道,在Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 然后多条消息批量发送。这样可以减少网络请求次数,提高消息的发送效率。
所以批量发送消息有两个条件:
-
一个batch满了,与
batch.size有关,一般大小是16k。 -
linger.ms时间到了。
满足任意一个条件,都会触发sender线程的发送。如果生产的消息较少,batch没有满,就必须等到等待时间到了,这就导致了较长的延迟。
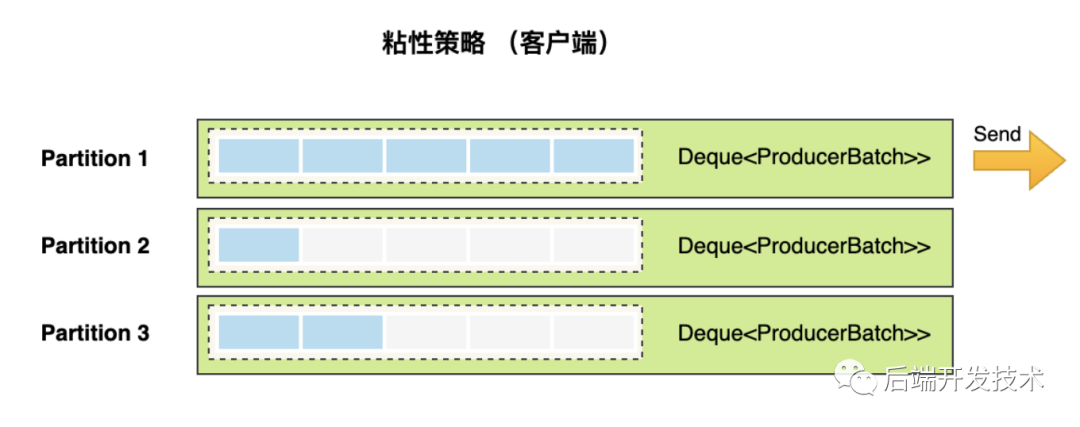
因为ProducerBatch是多个,为了让消息尽可能快的发送,就需要让其中一个ProducerBatch先变满。
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;注意:一个分区对应一个双端队列Deque<ProducerBatch>>。
粘性分区策略就是在相同的分区中,优先填满一个ProducerBatch,发送,再去填充另一个ProducerBatch。参见下图,第一个分区会被优先塞满并发送。
在一个 ProducerBatch 发送结束,选择新分区的时候,是随机选择的,之后便会继续优先填满新的分区。
-
可用分区<1 ,所有分区中随机选择。
-
可用分区=1,选择这个分区。
-
可用分区>1,所有可用分区中随机选择。
public int nextPartition(String topic, Cluster cluster, int prevPartition) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);Integer oldPart = indexCache.get(topic);Integer newPart = oldPart;// Check that the current sticky partition for the topic is either not set or that the partition that // triggered the new batch matches the sticky partition that needs to be changed.if (oldPart == null || oldPart == prevPartition) {List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() < 1) {Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = random % partitions.size();} else if (availablePartitions.size() == 1) {newPart = availablePartitions.get(0).partition();} else {while (newPart == null || newPart.equals(oldPart)) {int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = availablePartitions.get(random % availablePartitions.size()).partition();}}// Only change the sticky partition if it is null or prevPartition matches the current sticky partition.if (oldPart == null) {indexCache.putIfAbsent(topic, newPart);} else {indexCache.replace(topic, prevPartition, newPart);}return indexCache.get(topic);}return indexCache.get(topic);}轮询分区策略
Kafka 中提供了轮训策略的实现 RoundRobinPartitioner。当用户希望将写操作均匀地分发到所有分区时,可以使用此分区策略。
举例,有三个分区,针对于同一个producer,第一条消息发送到partition1,第二条消息发送到partition2,第三条发送到partition3,以此类推。
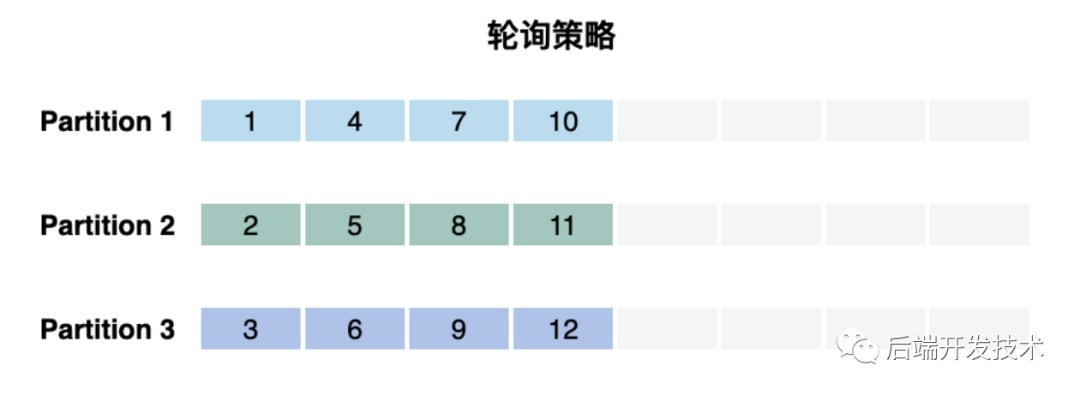
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);// 分区数int numPartitions = partitions.size();// 下一个自增值int nextValue = nextValue(topic);// 获取此主题的可用分区列表List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (!availablePartitions.isEmpty()) {// topic可用分区不为空,取余int part = Utils.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// 没有可用的分区,给出一个不可用的分区// no partitions are available, give a non-available partitionreturn Utils.toPositive(nextValue) % numPartitions;}
}hash 键的值并不会影响到数据的分布,这应该是数据均匀度最好的策略,可以保证消息最大程度的平均分配到所有分区。
除了官方提供的策略,我们还可以实现自己的分区策略,比如随机策略,实现起来也很简单;比如按照业务键去分区的策略;比如按照ip分区的策略等。
最后,欢迎大家提问和交流。
加入讨论群是升职加薪第一步!
回复:加群

点赞是一种美德,如对您有帮助,欢迎评论和分享,感谢阅读!
实战总结|记一次消息队列堆积的问题排查
2023-07-18

从二叉查找树到B*树,一文搞懂搜索树的演进!|原创
2023-05-23
CAP、BASE理论真的很重要!|分布式事务系列(一)
2023-05-06
相关文章:
详解Kafka分区机制原理|Kafka 系列 二
Kafka 系列第二篇,详解分区机制原理。为了不错过更新,请大家将本号“设为星标”。 点击上方“后端开发技术”,选择“设为星标” ,优质资源及时送达 上一篇文章介绍了 Kafka 的基本概念和术语,里面有个概念是 分区(Part…...
CSS学习记录(基础笔记)
CSS简介: CSS 指的是层叠样式表* (Cascading Style Sheets),主要用于设置HTML页面的文字内容(字体、大小、对齐方式),图片的外形(边框) CSS 描述了如何在屏幕、纸张或其他媒体上显示 HTML 元素 CSS 节省…...
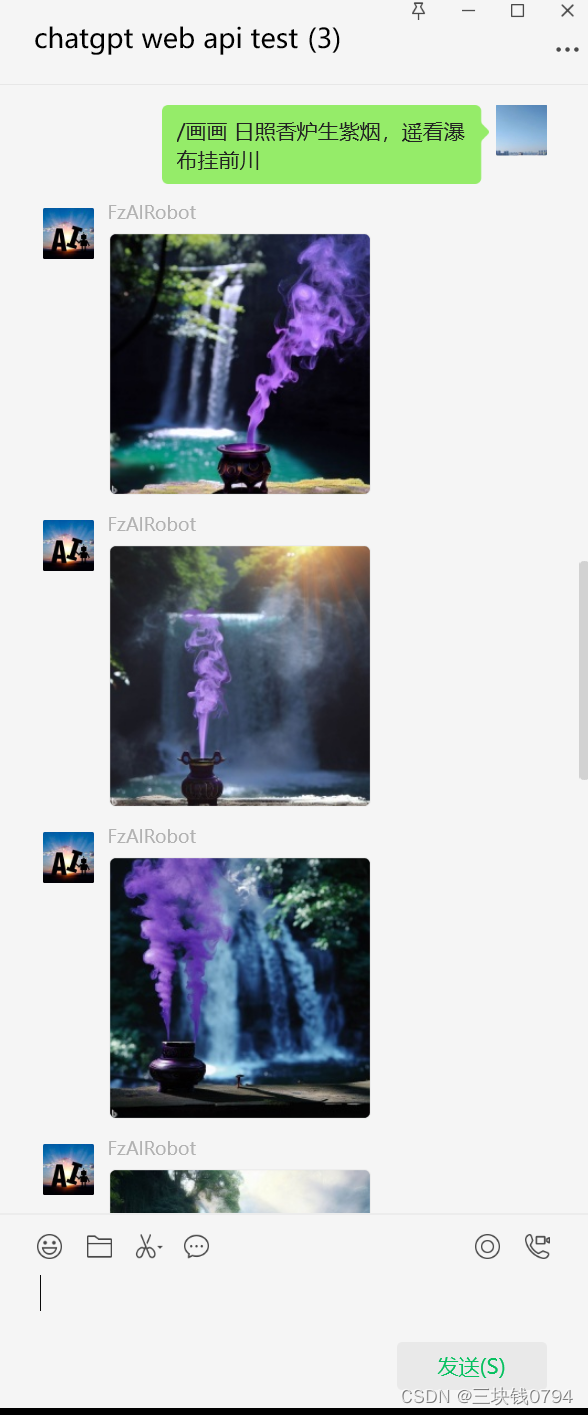
Chatgpt AI newbing作画,文字生成图 BingImageCreator 二次开发,对接wxbot
开源项目 https://github.com/acheong08/BingImageCreator 获取cookie信息 cookieStore.get("_U").then(result > console.log(result.value)) pip3 install --upgrade BingImageCreator import os import BingImageCreatoros.environ["http_proxy"]…...
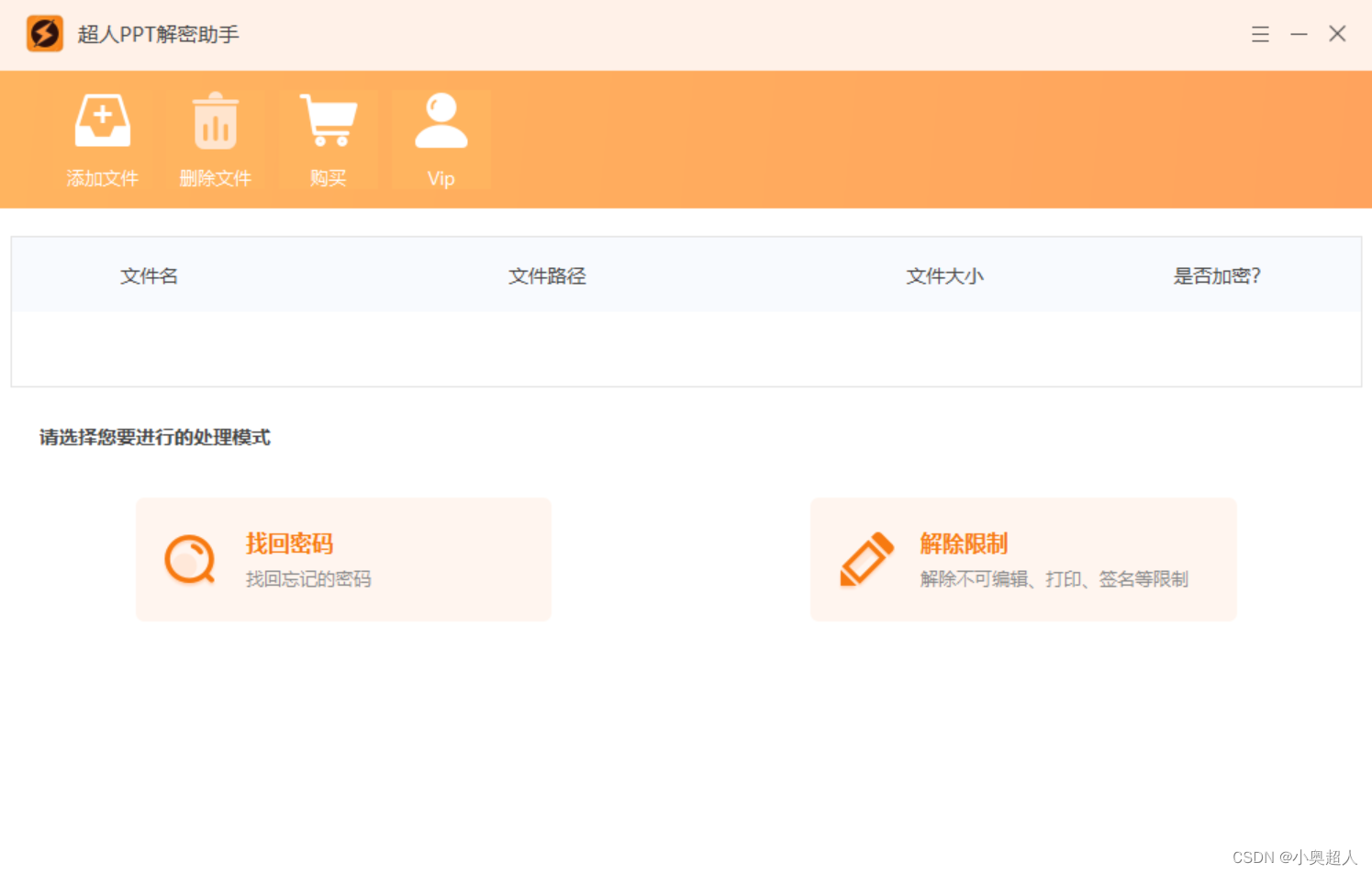
PPT忘记密码如何解除?
PPT文件所带有的两种加密方式,打开密码以及修改权限,两种密码在打开文件的时候都会有相应的提示,但不同的是两种加密忘记密码之后是不同的。 如果忘记了打开密码,我们就没办法打开PPT文件了;如果是忘记了修改密码&…...
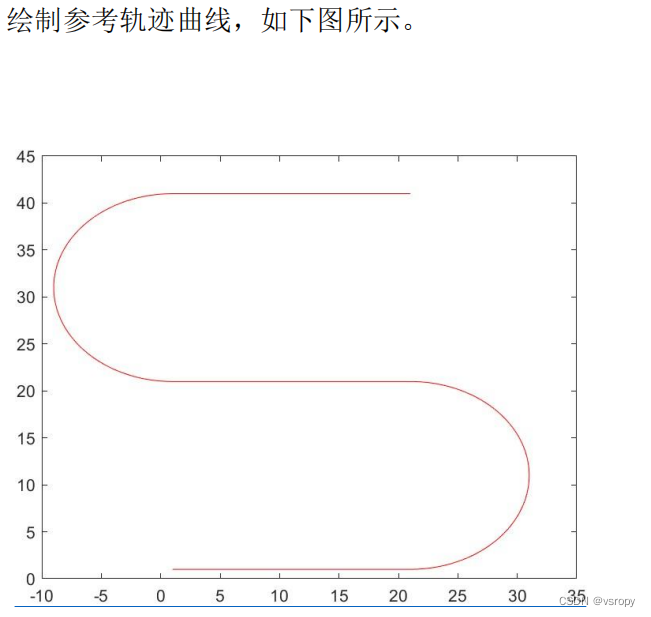
绘制曲线python
文章目录 import matplotlib.pyplot as plt# 提供的数据 x= [1,1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,2,2.1,2.2,2.3,2.4,2.5,2.6,2.7,2.8,2.9,3,3.1,3.2,3.3,3.4,3.5,3.6,3.7,3.8,3.9,4,4.1,4.2,4.3,4.4,4.5,4.6,4.7,4.8,4.9,5,5.1,5.2,5.3,5.4,5.5,5.6,5.7,5.8,5.9,6,6.1,6.2…...

CentOs 8 常见问题处理
CentOs 8 常见问题处理 vmware虚拟机新增网卡操作 vmware虚拟机新增网卡操作 [rootcentos ~]# ip add 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0…...

OpenAI将GPT-4设置为ChatGPT Plus付费用户的默认模型
OpenAI最近为ChatGPT引入了一系列新功能,这些更新旨在增强用户体验,提供更多指导和更多的功能。其中最显著的功能之一是将GPT-4设置为ChatGPT Plus付费用户的默认模型,这意味着付费订阅用户无需手动切换到其他公开可用的语言模型,…...

textarea 标签如何创建多行文本输入框?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ textarea 的写法⭐ 代码含义⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、…...

(15)Qt绘图(two)
目录 坐标变换 平移坐标轴 缩放坐标轴 旋转坐标轴 定时器加坐标轴旋转实现动画旋转 transform旋转(可设置旋转轴) 绕X轴旋转 绕Y轴旋转 绕Z轴旋转 错切 Y轴错切 X轴错切 画家的保存与坐标复原 基本图形绘制 绘制点 绘制线 绘制矩形 普…...

用队列实现栈——数据结构与算法
😶🌫️Take your time ! 😶🌫️ 💥个人主页:🔥🔥🔥大魔王🔥🔥🔥 💥代码仓库:🔥🔥魔…...

Python“牵手”1688商品详情页数据采集方法,1688API接口申请指南
1688详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用。 一、1688…...
记录第一篇被”华为开发者联盟鸿蒙专区 “收录的文章
记录第一篇被”华为开发者联盟鸿蒙专区 “社区收录的文章。 坚持写作的动力是什么? 是记录、分享,以及更好的思考 。...
jenkins的cicd操作
cicd概念 持续集成( Continuous Integration) 持续频繁的(每天多次)将本地代码“集成”到主干分支,并保证主干分支可用 持续交付(Continuous Delivery) 是持续集成的下一步,持续…...
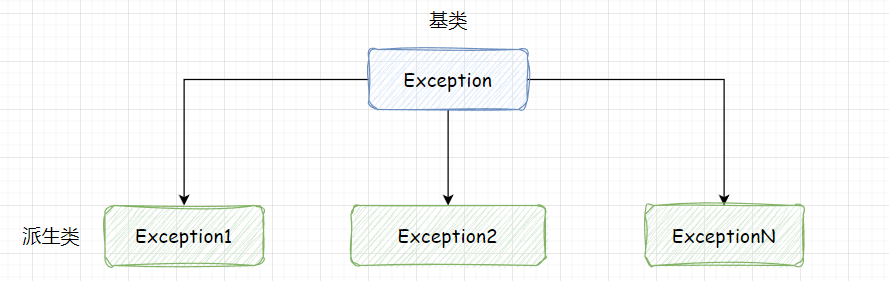
【C++】异常exception
文章目录 1. C语言中传统的处理错误方法2. C中的异常3. 异常的使用3.1 异常的抛出和捕获3.2 异常的重新抛出3.3 异常安全3.4 异常规范 4. 自定义异常体系5. 异常的优缺点 📝 个人主页 :超人不会飞)📑 本文收录专栏:《C的修行之路》…...

2023-08-06力扣今日三题
链接: 剑指 Offer 59 - I. 滑动窗口的最大值 题意: 一个lg长度的数组,一个长度k的滑动窗口,求所有滑动窗口中的最大值 解: 优先队列存储存储下标,数字大的优先,每次判断最大的值是否在范围…...

kubeasz在线安装K8S集群
一、介绍 Kubeasz 是一个基于 Ansible 自动化工具,用于快速部署和管理 Kubernetes 集群的工具。它支持快速部署高可用的 Kubernetes 集群,支持容器化部署,可以方便地扩展集群规模,支持多租户,提供了强大的监控和日志分…...

Vue中实现Web端鼠标横向滑动和触控板滑动效果
系列文章目录 文章目录 系列文章目录前言一、鼠标横向滑动效果二、触控板滑动效果总结 前言 在Web端,我们经常需要实现鼠标横向滑动和触控板滑动的效果,以便在页面中展示横向滑动的内容。本文将介绍如何使用Vue和JavaScript来实现这两种效果,…...
)
hdu5-Touhou Red Red Blue(贪心)
Problem - 7329 (hdu.edu.cn) 参考:题解 | #1006.Touhou Red Red Blue# 2023杭电暑期多校5 题解:(贪心) mp[R], mp[G], mp[P] 分别记录对应字母出现过多少次,没有AAA orABC 出现时不得分也不进行任何操作ÿ…...
【LeetCode 75】第二十三题(2352)相等行列对
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 题目很简洁,就是要我们寻找行与列相同的对数。相同行与列不仅是要元素相同,还需要顺序也一样(…...
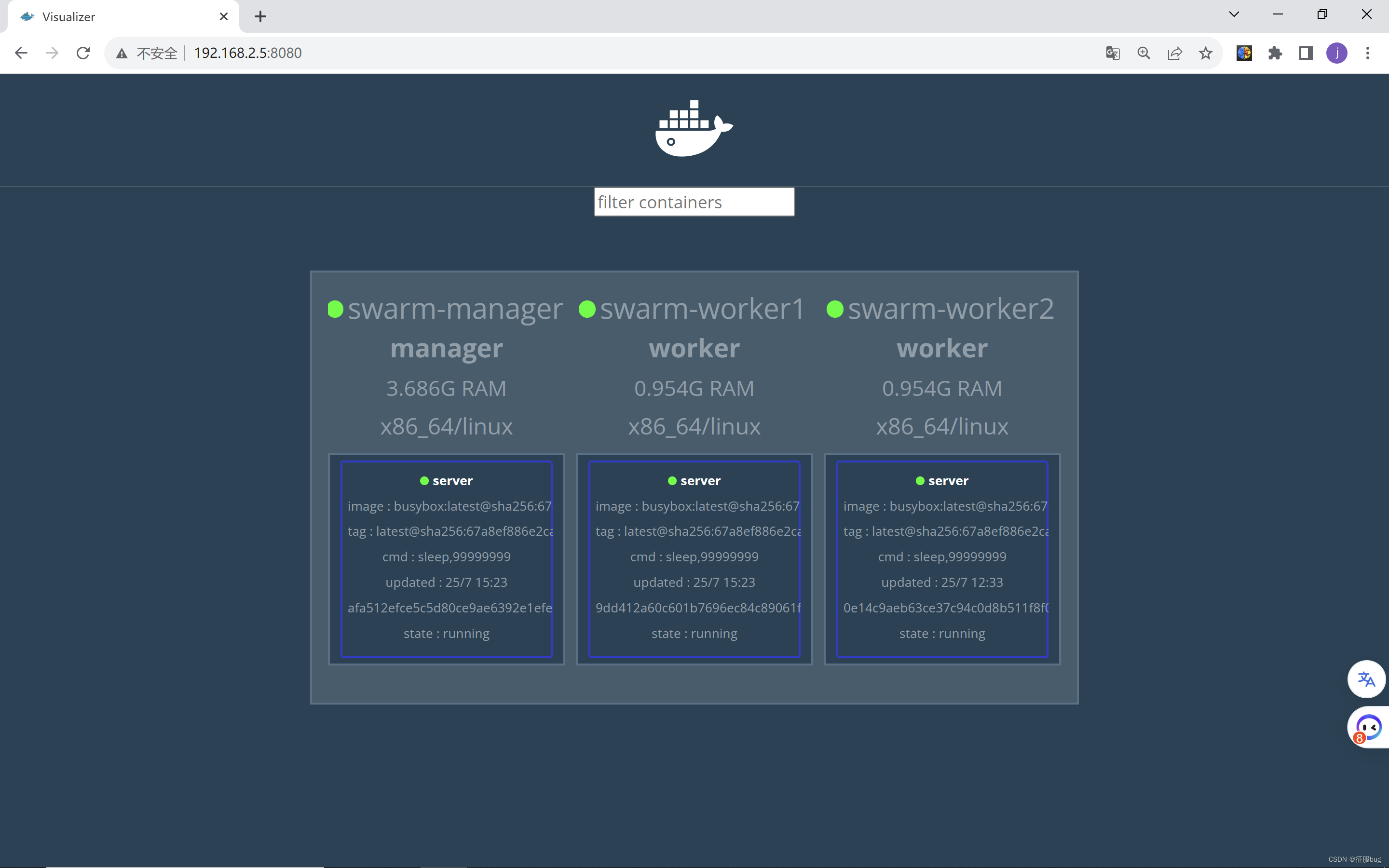
【云原生】详细学习Docker-Swarm部署搭建和基本使用
个人主页:征服bug-CSDN博客 kubernetes专栏:云原生_征服bug的博客-CSDN博客 目录 Docker-Swarm编排 1.概述 2.docker swarm优点 3.节点类型 4.服务和任务 5.路由网格 6.实践Docker swarm 1.概述 Docker Swarm 是 Docker 的集群管理工具。它将 Doc…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...