awk相关知识点整理
1.awk的使用方法
1.1 语法
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file
1.2 命令常用选项
-F fs:fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value:赋值一个用户定义变量,将外部变量传递给awk
-f scripfile:从脚本文件中读取awk命令
-m[fr] val:对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用
2.awk变量
2.1内置变量
2.1.1 格式
FS :输入字段分隔符,默认为空白字符
OFS :输出字段分隔符,默认为空白字符
RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
ORS :输出记录分隔符,输出时用指定符号代替换行符
NF :字段数量,共有多少字段, NF引用最后一列,(NF-1)引用倒数第2列
NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
FILENAME :当前文件名
ARGC :命令行参数的个数
ARGV :数组,保存的是命令行所给定的各参数,查看参数
2.1.2 演示代码
[root@along ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:youou
[root@along ~]# awk -v FS=':' '{print $1,$2}' awkdemo #FS指定输入分隔符
hello world
linux redhat
along love
[root@along ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo #OFS指定输出分隔符
hello---world
linux---redhat
along---love
[root@along ~]# awk -v RS=':' '{print $1,$2}' awkdemo
hello
world linux
redhat
lalala
hahaha along
love
you
[root@along ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---
[root@along ~]# awk -F: '{print NF}' awkdemo
2
4
3
[root@along ~]# awk -F: '{print $(NF-1)}' awkdemo #显示倒数第2列
hello
lalala
love
[root@along ~]# awk '{print NR}' awkdemo awkdemo1
1
2
3
4
5
[root@along ~]# awk END'{print NR}' awkdemo awkdemo1
5
[root@along ~]# awk '{print FNR}' awkdemo awkdemo1
1
2
3
1
2
[root@along ~]# awk '{print FILENAME}' awkdemo
awkdemo
awkdemo
awkdemo
[root@along ~]# awk 'BEGIN {print ARGC}' awkdemo awkdemo1
3
[root@along ~]# awk 'BEGIN {print ARGV[0]}' awkdemo awkdemo1
awk
[root@along ~]# awk 'BEGIN {print ARGV[1]}' awkdemo awkdemo1
awkdemo
[root@along ~]# awk 'BEGIN {print ARGV[2]}' awkdemo awkdemo1
awkdemo1
2.2 自定义变量
1.先定义变量,再执行print
[root@along ~]# awk -v name="along" -F: '{print name":"$0}' awkdemo
along:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you
2.在执行动作print后定义变量
[root@along ~]# awk -F: '{print name":"$0;name="along"}' awkdemo
:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you
3.在program 中直接定义
[root@along ~]# cat awk.txt
{name="along";print name,$1}
[root@along ~]# awk -F: -f awk.txt awkdemo
along hello
along linux
along along
3.操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y
-x: 转换为负数
+x: 转换为数值
字符串操作符:没有符号的操作符,字符串连接
赋值操作符:
=, +=, -=, *=, /=, %=, ^=
++a, --a
比较操作符:
==, !=, >, >=, <, <=
模式匹配符:
~ :左边是否和右边匹配包含
!~ :是否不匹配`
逻辑操作符:
与&& ,或|| ,非!
函数调用:
function_name(argu1, argu2, ...)
条件表达式:
selector
?
if-true-expression
:
if-false-expression
4.print命令
1.格式化输出
printf` `"FORMAT"``, item1,item2, ...
① 必须指定FORMAT
② 不会自动换行,需要显式给出换行控制符,\n
③ FORMAT 中需要分别为后面每个item 指定格式符
2.格式符:与item 一一对应
%c: 显示字符的ASCII码
%d, %i: 显示十进制整数
%e, %E: 显示科学计数法数值
*%f :显示为浮点数,小数** %5.1f,带整数、小数点、整数共5位,小数1位,不够用空格补上
%g, %G :以科学计数法或浮点形式显示数值
%s :显示字符串;例:%5s最少5个字符,不够用空格补上,超过5个还继续显示
%u :无符号整数
%%: 显示% 自身
3.修饰符:放在%c[/d/e/f…]之间
\#[.#]:第一个数字控制显示的宽度;第二个# 表示小数点后精度,%5.1f
-:左对齐(默认右对齐) %-15s
+:显示数值的正负符号 %+d
5.awk控制语句
5.1 if-else判断
(1)语法
if(condition){statement;…}[else statement] 双分支
if(condition1){statement1}else if(condition2){statement2}else{statement3} 多分支
(2)使用场景:对awk 取得的整行或某个字段做条件判断
(3)演示
[root@along ~]# awk -F: '{if($3>10 && $3<1000)print $1,$3}' /etc/passwd
operator 11
games 1
[root@along ~]# awk -F: '{if($NF=="/bin/bash") print $1,$NF}' /etc/passwd
root /bin/bash
along /bin/bash
---输出总列数大于3的行
[root@along ~]# awk -F: '{if(NF>2) print $0}' awkdemo
linux:redhat:lalala:hahaha
along:love:you
---第3列>=1000为Common user,反之是root or Sysuser
[root@along ~]# awk -F: '{if($3>=1000) {printf "Common user: %s\n",$1} else{printf "root or Sysuser: %s\n",$1}}' /etc/passwd
root or Sysuser: root
root or Sysuser: bin
Common user: along
---磁盘利用率超过40的设备名和利用率
[root@along ~]# df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF > 40{print $1,$NF}'
/dev/mapper/cl-root 43
---test=100和>90为very good; 90>test>60为good; test<60为no pass
[root@along ~]# awk 'BEGIN{ test=100;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
very good
[root@along ~]# awk 'BEGIN{ test=80;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
good
[root@along ~]# awk 'BEGIN{ test=50;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
no pass
5.2循环语句
5.2.1 while循环
(1)语法
while``(condition){statement;…}
(2)使用场景
对一行内的多个字段逐一类似处理时使用
对数组中的各元素逐一处理时使用
(3)演示
---以along开头的行,以:为分隔,显示每一行的每个单词和其长度
[root@along ~]# awk -F: '/^along/{i=1;while(i<=NF){print $i,length($i); i++}}' awkdemo
along 5
love 4
you 3
---以:为分隔,显示每一行的长度大于6的单词和其长度
[root@along ~]# awk -F: '{i=1;while(i<=NF) {if(length($i)>=6){print $i,length($i)}; i++}}' awkdemo
redhat 6
lalala 6
hahaha 6
---计算1+2+3+...+100=5050
[root@along ~]# awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};print sum}'
5050
5.2.2 do-while循环
语法
do` `{statement;…}``while``(condition)
意义:无论真假,至少执行一次循环体
5.2.3 for循环
(1)语法
for``(expr1;expr2;expr3) {statement;…}
(2)特殊用法:遍历数组中的元素
for``(var ``in` `array) {``for``-body}
(3)演示
---显示每一行的每个单词和其长度
[root@along ~]# awk -F: '{for(i=1;i<=NF;i++) {print$i,length($i)}}' awkdemo
hello 5
world 5
linux 5
redhat 6
lalala 6
hahaha 6
along 5
love 4
you 3
---求男m、女f各自的平均
[root@along ~]# cat sort.txt
score
[m=>170]
xiaoming m 90
xiaohong f 93
xiaohei m 80
xiaofang f 99
[root@along ~]# awk '{m[$2]++;score[$2]+=$3}END{for(i in m){printf "%s:%6.2f\n",i,score[i]/m[i]}}' sort.txt
m: 85.00
f: 96.00
6.awk数组
6.1 关联数组
(1)可使用任意字符串;字符串要使用双引号括起来
(2)如果某数组元素事先不存在,在引用时,awk 会自动创建此元素,并将其值初始化为“空串”
(3)若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
(4)若要遍历数组中的每个元素,要使用for 循环**:for(var in array)** {for-body}
6.2 演示
[root@along ~]# cat awkdemo2
aaa
bbbb
aaa
123
123
123
---去除重复的行
[root@along ~]# awk '!arr[$0]++' awkdemo2
aaa
bbbb
123
---打印文件内容,和该行重复第几次出现 取反不会影响数组中的值 只有在++得时候,值才会改变 ?
[root@along ~]# awk '{!arr[$0]++;print $0,arr[$0]}' awkdemo2
aaa 1
bbbb 1
aaa 2
123 1
123 2
123 3awk是AWK的命令行工具,它接受一个AWK脚本作为参数,并对输入进行处理。花括号{}内是AWK脚本的主体,它定义了处理输入数据的操作。!arr[$0]++:这是一个表达式,它使用了AWK中的数组arr来记录每一行的出现次数。在AWK中,$0表示当前行的全部内容。arr[$0]表示以当前行内容为索引的数组元素。!是逻辑取反操作符,将0转换为1,非0值转换为0。arr[$0]++表示将当前行内容为索引的数组元素自增1,然后返回旧值。所以!arr[$0]++在第一次遇到某一行时为真(1),而后续再次遇到该行时为假(0)。print $0,arr[$0]:这是一个打印语句,用于输出当前行内容$0以及该行内容在数组中出现的次数arr[$0]。在AWK中,$0表示当前行的全部内容,arr[$0]表示数组中以当前行内容为索引的元素的值。所以,这段代码的作用是读取文件"awkdemo2",对每一行进行处理,并输出每行内容及其在文件中出现的次数。如果文件中有多个相同的行,则会在输出中显示它们的重复次数
6.3 遍历数组
[root@along ~]# awk 'BEGIN{abc["ceo"]="along";abc["coo"]="mayun";abc["cto"]="mahuateng";for(i in abc){print i,abc[i]}}'
coo mayun
ceo along
cto mahuateng
[root@along ~]# awk '{for(i=1;i<=NF;i++)abc[$i]++}END{for(j in abc)print j,abc[j]}' awkdemo2
aaa 2
bbbb 1
123 3
7.数值和字符串的处理
7.1 数值处理
rand():返回0和1之间一个随机数,需有个种子 srand(),没有种子,一直输出0.237788
[root@along ~]# awk 'BEGIN{print rand()}'
0.237788
[root@along ~]# awk 'BEGIN{srand(); print rand()}'
0.51692
[root@along ~]# awk 'BEGIN{srand(); print rand()}'
0.189917
---取0-50随机数
[root@along ~]# awk 'BEGIN{srand(); print int(rand()*100%50)+1}'
12
[root@along ~]# awk 'BEGIN{srand(); print int(rand()*100%50)+1}'
24
7.2 字符串处理
length([s]) :返回指定字符串的长度
sub(r,s,[t]) :对t 字符串进行搜索r 表示的模式匹配的内容,并将第一个匹配的内容替换为s
gsub(r,s,[t]) :对t 字符串进行搜索r 表示的模式匹配的内容,并全部替换为s 所表示的内容
split(s,array,[r]) :以r 为分隔符,切割字符串s ,并将切割后的结果保存至array 所表示的数组中,第一个索引值为1, 第二个索引值为2,…
演示:
[root@along ~]# echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'
2008-08:08 08:08:08
[root@along ~]# echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'
2008-08-08 08-08-08
[root@along ~]# echo "2008:08:08 08:08:08" | awk '{split($0,arr,":")}END{for(n in arr){print n,i[n]}}'
4 08
5 08
1 2008
2 08
3 08
8.awk中调用shell命令
8.1 system命令
空格是awk 中的字符串连接符,如果system中需要使用awk中的变量可以使用空格分隔,或者说除了awk 的变量外其他一律用"" 引用 起来
[root@along ~]# awk BEGIN'{system("hostname") }'
along
[root@along ~]# awk 'BEGIN{name="along";system("echo "name)}' 注:"echo " echo后有空格
along
[root@along ~]# awk 'BEGIN{score=100; system("echo your score is " score) }'
your score is 100
8.2 awk脚本
将awk 程序写成脚本,直接调用或执行
演示:
[root@along ~]# cat f1.awk
{if($3>=1000)print $1,$3}
[root@along ~]# cat f2.awk
#!/bin/awk -f
{if($3 >= 1000)print $1,$3}
[root@along ~]# chmod +x f2.awk
[root@along ~]# ./f2.awk -F: /etc/passwd
along 1000
8.3 给awk脚本传递参数
awkfile var=value var2=value2... Inputfile
注意 :在BEGIN 过程 中不可用。直到 首行输入完成以后,变量才可用 。可以通过**-v 参数**,让awk 在执行BEGIN 之前得到变量的值。命令行中每一个指定的变量都需要一个-v
相关文章:

awk相关知识点整理
1.awk的使用方法 1.1 语法 awk [options] script varvalue file(s) awk [options] -f scriptfile varvalue file1.2 命令常用选项 -F fs:fs指定输入分隔符,fs可以是字符串或正则表达式,如-F: -v varvalue:赋值一个用户定义变量…...
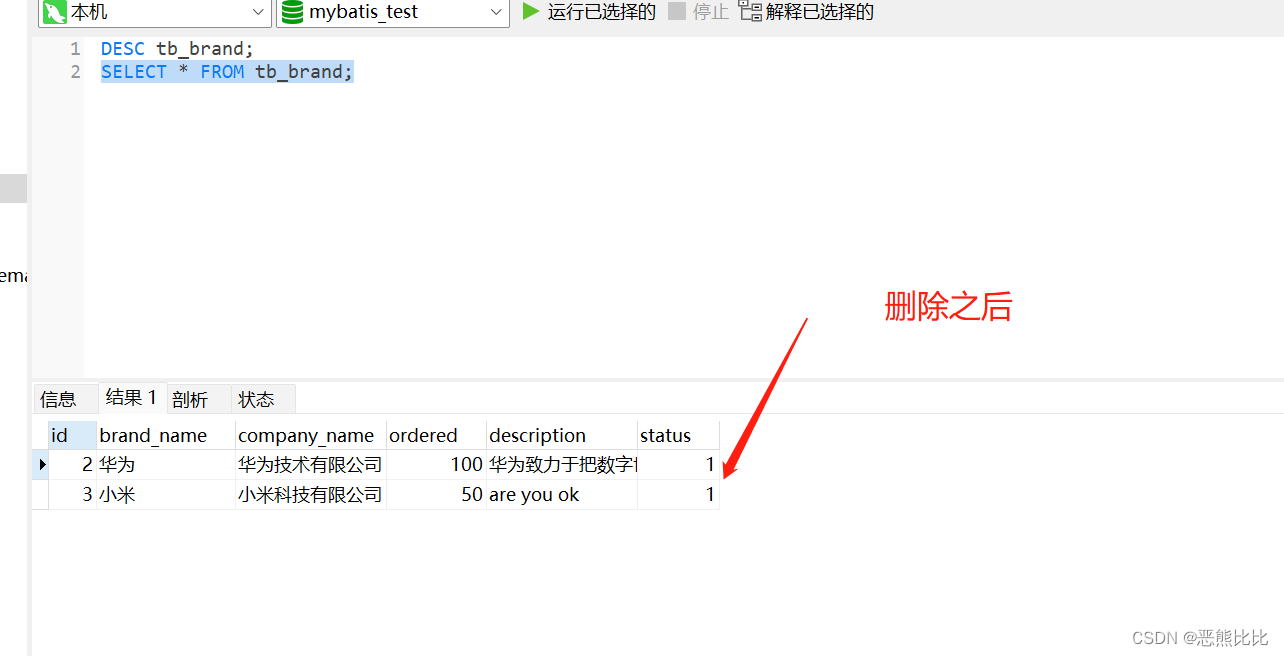
Mybatis案例-商品的增删改查
文章目录 1. aim2.环境准备3.查询3.1 查所有3.2 查看详情3.3 条件查询3.3.1 Mybatics如何接收参数?3.3.2 多条件查询3.3.3 动态条件查询3.3.4 单条件查询 4.添加主键返回 5.修改5.1 修改全部字段5.2 修改动态字段 6.删除6.1 删除1个6.2 批量删除 JDBC完成࿱…...

图像识别模型与训练策略
图像预处理 1.需要将图像Resize到相同大小输入到卷积网络中 2.翻转、裁剪、色彩偏移等操作 3.转化为Tensor数据格式 4.对RGB三种颜色通道进行标准化 data_transforms {train: transforms.Compose([transforms.Resize([96, 96]),transforms.RandomRotation(45),#随机旋转&…...
)
算法工程师-机器学习面试题总结(3)
FM模型 FM模型与逻辑回归相比有什么优缺点? FM(因子分解机)模型和逻辑回归是两种常见的预测建模方法,它们在一些方面有不同的优缺点。 FM模型的优点: 1. 能够捕获特征之间的交互作用:FM模型通过对特征向量…...
进程内topic高效通信)
ROS2学习(五)进程内topic高效通信
对ROS2有一定了解后,我们会发现ROS2中节点和ROS1中节点的概率有很大的区别。在ROS1中节点是最小的进程单元。在ROS2中节点与进程和线程的概念完全区分开了。具体区别可以参考 ROS2学习(四)进程,线程与节点的关系。 在ROS2中同一个进程中可能存在多个节点…...

算法-最大数
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。 注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。 输入:nums [10,2] 输出:"210&…...

Spark中使用RDD算子GroupBy做词频统计的方法
测试文件及环境 测试文件在本地D://tmp/spark.txt,Spark采用Local模式运行,Spark版本3.2.0,Scala版本2.12,集成idea开发环境。 hello world java world java java实验代码 import org.apache.spark.rdd.RDD import org.apache.…...
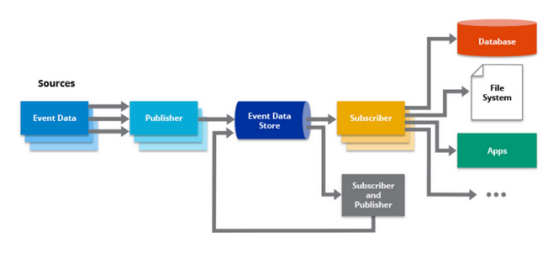
如何使用Kafka构建事件驱动的架构
事件驱动的架构(EDA)是一种软件设计模式,它关注事件的生成、检测和使用,以支持高效和可扩展的系统。在EDA中,事件是组件之间通信的主要手段,允许它们实时交互和响应更改。这种架构促进了松散耦合、可扩展性和响应性,使…...

ES6 解构赋值
解构赋值 解构赋值是一种在编程中常见且方便的语法特性,它可以让你从数组或对象中快速提取数据,并将数据赋值给变量。在许多编程语言中都有类似的特性。 在 JavaScript 中,解构赋值使得从数组或对象中提取数据变得简单。它可以用于数组和对…...

HTML5注册页面
分析 注册界面实际上是一个表格(对齐),一行有两个单元格。 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevic…...

python中的JSON模块详解
简介 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写 同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互 网址 官方文档 json — JSON encoder and dec…...
Syncfusion Essential Edit for WPF Crack
Syncfusion Essential Edit for WPF Crack 在任何WPF应用程序中启用语法高亮显示。 Syncfusion Essential Edit for WPF是一款具有所有基本功能的编辑器,如文本编辑、剪切、复制和粘贴。它允许用户从各种文件格式打开文件并将其保存为各种文件格式。Syncfusion Esse…...
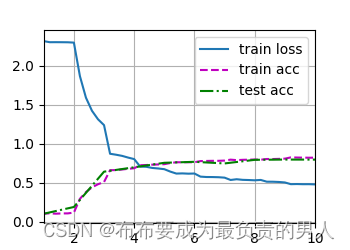
机器学习深度学习——卷积神经网络(LeNet)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——池化层 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 卷积神…...

Pytorch Tutorial【Chapter 2. Autograd】
Pytorch Tutorial 文章目录 Pytorch TutorialChapter 2. Autograd1. Review Matrix Calculus1.1 Definition向量对向量求导1.2 Definition标量对向量求导1.3 Definition标量对矩阵求导 2.关于autograd的说明3. grad的计算3.1 Manual手动计算3.2 backward()自动计算 Reference C…...

Python第三方库国内镜像下载地址
Python第三方库国内镜像下载地址 一、清华大学二、中国科技大学三、安装方法 一、清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 二、中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple 三、安装方法 例如 pyhook3 插件的安装方法,执行下面命令安装…...
服务端机器一般部署在哪里)
从浏览器输入url到页面加载(七)服务端机器一般部署在哪里
前言 上一节,我们说到了CDN和路由器的关系,说到了公有地址,说到了通信线路服务,这一节跳过那些看不懂的深层知识,直接开始说web服务器。 1. 服务端机器为什么不部署在公司内部 记得在之前的一段时间里,公…...
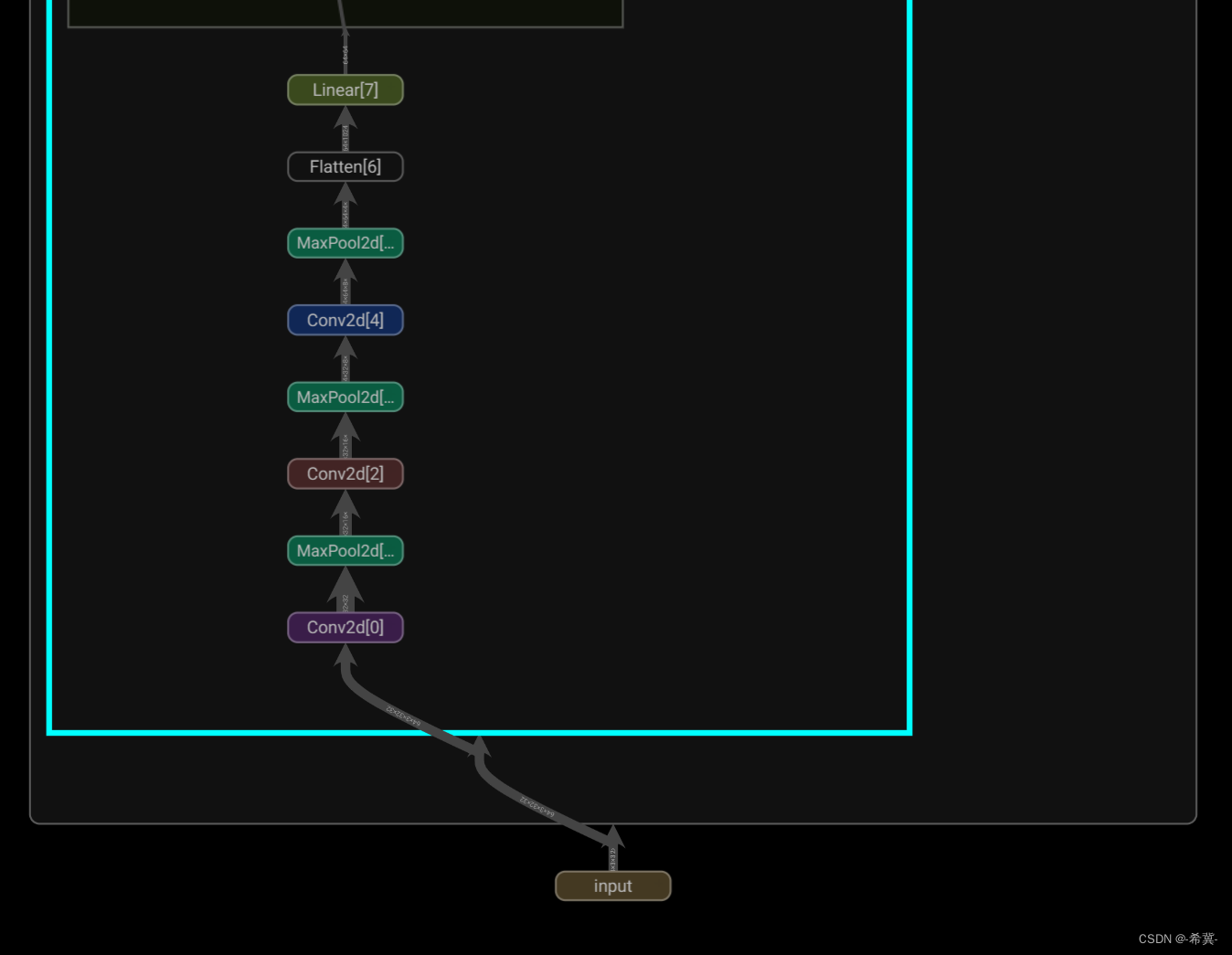
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
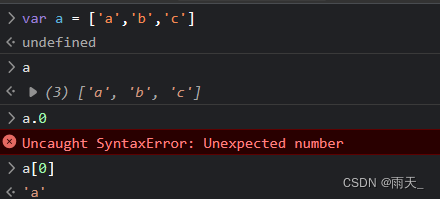
安全基础 --- https详解 + 数组(js)
CIA三属性:完整性(Confidentiality)、保密性(Integrity)、可用性(Availability),也称信息安全三要素。 https 核心技术:用非对称加密传输对称加密的密钥,然后…...

vue加载大量数据优化
在Vue中加载大量数据并形成列表时,可以通过以下方法来优化性能: 分页加载:不要一次性加载所有的数据,而是分批加载数据,每次只加载当前页需要显示的数据量。可以使用第三方库如vue-infinite-loading来实现无限滚动加载…...

WebRTC 之音视频同步
在网络视频会议中, 我们常会遇到音视频不同步的问题, 我们有一个专有名词 lip-sync 唇同步来描述这类问题,当我们看到人的嘴唇动作与听到的声音对不上的时候,不同步的问题就出现了 而在线会议中, 听见清晰的声音是优先…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...
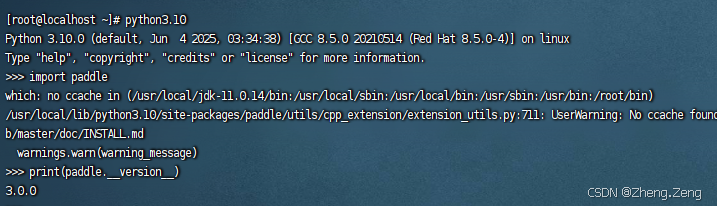
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...
恶补电源:1.电桥
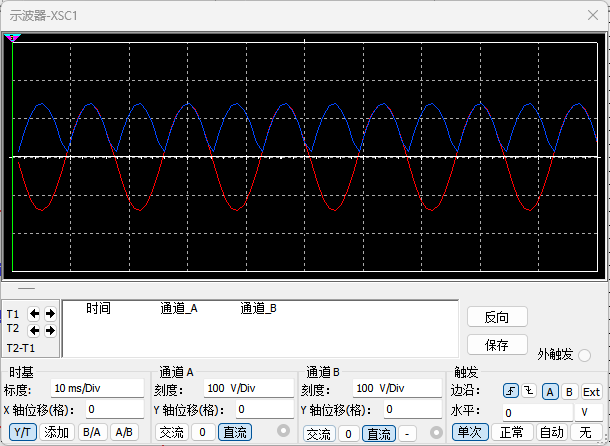
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
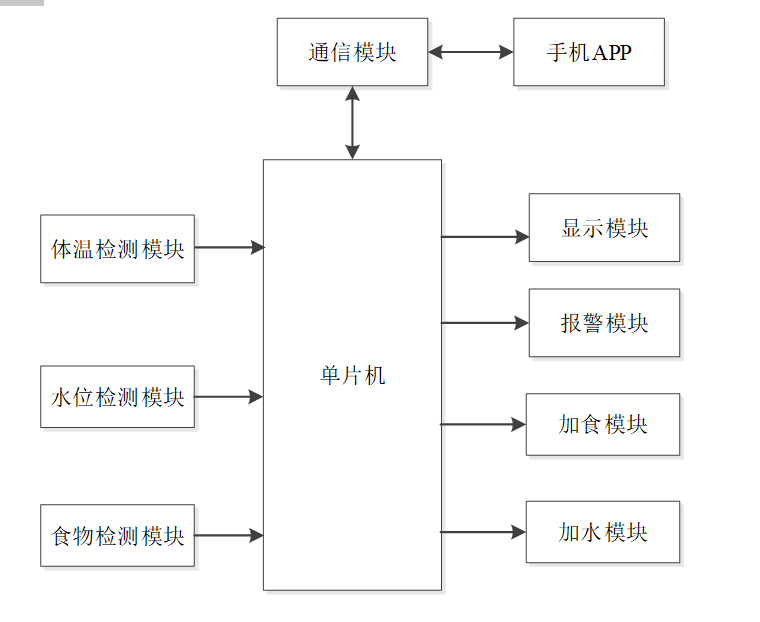
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...