使用 Habana Gaudi2 加速视觉语言模型 BridgeTower
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
在对最先进的视觉语言模型 BridgeTower 进行微调时,使用 Optimum Habana v1.6, Habana Gaudi2 可以达到 近 3 倍于 A100 的速度。硬件加速的数据加载以及 fast DDP 这两个新特性对性能提高贡献最大。
这些技术适用于任何性能瓶颈在数据加载上的其他工作负载,很多视觉模型的性能瓶颈在数据加载。 本文将带你了解我们用于比较 Habana Gaudi2 和英伟达 A100 80GB 上的 BridgeTower 微调性能的流程及测试基准。通过我们的演示,你会发现在基于 transformers 的模型上使用 Gaudi2 以及这些新特性是多么容易!
BridgeTower
最近,视觉语言 (Vision-Language,VL) 模型 的重要性与日俱增,它们开始在各种 VL 任务中占据主导地位。在处理多模态数据时,最常见的做法是使用单模态编码器从各模态数据中提取各自的数据表征。然后,抑或是将这些表征融合在一起,抑或是将它们输入给跨模态编码器。为了有效解除传统 VL 表征学习的算法局限性及其性能限制,BridgeTower 引入了多个 桥接层 ,在单模态编码器的顶部若干层建立与跨模态编码器的逐层连接,这使得跨模态编码器中不同语义级别的视觉和文本表征之间能够实现有效的、自底而上的跨模态对齐和融合。
仅基于 400 万张图像预训练而得的 BridgeTower 模型就能在各种下游视觉语言任务上取得最先进的性能 (详见下文基准测试)。特别地,BridgeTower 在使用相同的预训练数据和几乎可以忽略不计的额外参数和计算成本的条件下,在 VQAv2 的 test-std 子集上取得了 78.73% 的准确率,比之前最先进的模型 (METER) 的准确率提高了 1.09%。值得一提的是,当进一步增加模型参数量,BridgeTower 的准确率可达 81.15%,超过了那些基于大得多的数据集预训练出来的模型。
硬件
英伟达 A100 张量核 GPU 内含第三代 张量核技术。尽管最近新一代 H100 已发布,但目前来讲 A100 仍然是大多数云服务上最快的 GPU。这里,我们使用显存为 80GB 的卡,它的显存容量和带宽都比 40GB 版本更高。
Habana Gaudi2 是 Habana Labs 设计的第二代 AI 硬件加速卡。一台服务器包含 8 个称为 HPU 的加速卡,每张加速卡有 96GB 内存。你可查阅 我们之前的博文,以了解 Gaudi2 的更多信息以及如何在 英特尔开发者云 (Intel Developer Cloud,IDC) 上获取 Gaudi2 实例。与市面上许多其他 AI 加速器不同,用户很容易通过 Optimum Habana 使用到 Gaudi2 的高级特性。有了 Optimum Habana,用户仅需更改 2 行 代码即可将基于 transformers 的模型脚本移植到 Gaudi 上。
基准测试
为了评测训练性能,我们准备微调 BridgeTower 的 large checkpoint,其参数量为 866M。该 checkpoint 在预训练时使用了掩码语言模型、图像文本匹配以及图像文本对比损失,其预训练数据集为 Conceptual Captions、SBU Captions、MSCOCO Captions 以及 Visual Genome。
我们将在 纽约客配文竞赛数据集 上进一步微调此 checkpoint,该数据集包含《纽约客》杂志上的漫画及每个漫画对应的投票最多的配文。
除了 batch size 之外,两种加速卡的其他微调超参数都是相同的: Gaudi2 单卡可放下 40 个样本,而 A100 只能放得下 32 个样本。你可以在 这儿 找到 Gaudi2 使用的训练超参,A100 使用的超参见 这儿。
在处理涉及图像的数据集时,数据加载通常是性能瓶颈之一,这是因为一般情况下很多预处理操作都是在 CPU 上完成的 (如图像解码、图像增强等),然后再将预处理后的图像发送至训练卡。这里带来一个优化点,理想情况下, 我们可以直接将原数据发送到设备,并在设备上执行解码和各种图像变换 。但在此之前,我们先看看能不能简单地通过分配更多 CPU 资源来加速数据加载。
利用 dataloader_num_workers
如果图像加载是在 CPU 上完成的,一个简单地加速方法就是分配更多的子进程来加载数据。使用 transformers 的 TrainingArguments (或 Optimum Habana 中相应的 GaudiTrainingArguments ) 可以很容易地做到这一点: 你可以用 dataloader_num_workers=N 参数来设置 CPU 上用于数据加载的子进程的数目 ( N )。
dataloader_num_workers 参数的默认值为 0,表示仅在主进程中加载数据。这个设置很多情况下并不是最佳的,因为主进程有很多事情需要做。我们可以将其设置为 1,这样就会有一个专有的子进程来加载数据。当分配多个子进程时,每个子进程将负责准备一个 batch。这意味着内存消耗将随着工作进程数的增加而增加。一个简单的方法是将其设置为 CPU 核数,但有时候有些核可能在做别的事情,因此需要尝试找到一个最佳配置。
下面,我们跑两组实验:
8 卡分布式混合精度 ( bfloat16 / float ) 训练,其中数据加载由各 rank 的主进程执行 (即
dataloader_num_workers=0)8 卡分布式混合精度 ( bfloat16 / float ) 训练,且每 rank 各有 1 个用于数据加载的专用子进程 (即
dataloader_num_workers=1)
以下是这两组实验在 Gaudi2 和 A100 上分别测得的吞吐量: dataloader_num_workers=0``dataloader_num_workers=1
| 设备 | dataloader_num_workers=0 | dataloader_num_workers=1 |
|---|---|---|
| Gaudi2 HPU | 532.4 samples/s | 639.7 samples/s |
| A100 GPU | 210.5 samples/s | 296.6 samples/s |
首先,我们看到 dataloader_num_workers=1 时 Gaudi2 的速度是 A100 的 2.16 倍,在 dataloader_num_workers=0 时是 A100 的 2.53 倍,这与我们之前 报告的数据 相当!
其次,我们还看到 为数据加载分配更多资源可以轻松实现加速: Gaudi2 上加速比为 1.20,A100 上加速比为 1.41。
我们尝试了将数据加载子进程增加到数个,但实验表明其 在 Gaudi2 和 A100 上的性能均没有比 dataloader_num_workers=1 更好。因此, 使用 dataloader_num_workers=1 通常是加速涉及到图像的工作负载时首先尝试的方法!
你可以在 这儿 找到可视化的 Gaudi2 Tensorboard 日志,A100 的在 这儿。
Optimum Habana 的 fast DDP
在深入研究硬件加速的数据加载之前,我们来看一下另一个非常简单的 Gaudi 分布式运行的加速方法。新发布的 Optimum Habana 1.6.0 版引入了一个新功能,允许用户选择分布式策略:
distribution_strategy="ddp"使用 PyTorch 的DistributedDataParallel(DDP) 实现distribution_strategy="fast_ddp"使用 Gaudi 自有的更轻量级且一般来讲更快的实现
Optimum Habana 的 fast DDP 不会像 DDP 那样将参数梯度分割到存储桶 (bucket) 中。它还会使用 HPU 图 (graph) 来收集所有进程的梯度,并以最小的主机开销来对它们进行更新 (在 all_reduce 操作之后)。你可以在 这儿 找到其实现。
只需在 Gaudi2 上使用 distribution_strategy="fast_ddp" (并保持 dataloader_num_workers=1 ) 即可将每秒吞吐提高到 705.9, 比 DDP 快 1.10 倍,比 A100 快 2.38 倍!
因此,仅添加两个训练参数 ( dataloader_num_workers=1 及 distribution_strategy="fast_ddp" ),我们即可在 Gaudi2 上实现 1.33 倍的加速,与使用 dataloader_num_workers=1 的 A100 相比,加速比达到 2.38 倍。
使用 Optimum Habana 实现硬件加速的数据加载
为了获得更多的加速,我们可以将尽可能多的数据加载操作从 CPU 上移到加速卡上 (即 Gaudi2 上的 HPU 或 A100 上的 GPU)。在 Gaudi2 上,我们可以使用 Habana 的 媒体流水线 (media pipeline) 来达到这一目的。
给定一个数据集,大多数的数据加载器会做如下操作:
获取数据 (例如,存储在磁盘上的 JPEG 文件)
CPU 读取编码图像
CPU 对图像进行解码
CPU 对图像进行变换来增强图像
最后,将图像发送至设备 (尽管这通常不是由数据加载器本身完成的)
与在 CPU 上完成整个过程后再把准备好训练的数据发送到加速卡相比,更高效的工作流程是先将编码图像发送到加速卡,然后由加速卡执行图像解码和增强:
同上
同上
将编码图像发送至加速卡
加速卡对图像进行解码
加速卡对图像进行变换来增强图像
这样我们就可以利用加速卡强大的计算能力来加速图像解码和变换。请注意,执行此操作时需要注意两个问题:
设备内存消耗将会增加,因此如果没有足够的可用内存,你需要减小 batch size。这可能会降低该方法带来的加速。
如果在使用 CPU 数据加载方案时,加速卡的利用率已经很高 (100% 或接近 100%) 了,那就不要指望把这些操作卸载到加速卡会获得加速,因为它们已经忙得不可开交了。
我们还提供了一个示例,以帮助你在 Gaudi2 上实现这一优化: Optimum Habana 中的 对比图像文本示例 提供了一个可直接使用的媒体流水线 (media pipe),你可以将其直接用于类似于 COCO 那样的包含文本和图像的数据集!只需在命令中加一个 --mediapipe_dataloader 即可使能它。
感兴趣的读者可以参阅 Gaudi 的 文档,该文档对这一机制的底层实现给出了一些概述。读者还可以参考 这个文档,它给出了目前支持的所有算子的列表。
We are now going to benchmark a run with dataloader_num_workers=1 , distribution_strategy="fast_ddp" and mediapipe_dataloader since all these optimizations are compatible with each other:
现在我们测试一下 dataloader_num_workers=1 、 distribution_strategy="fast_ddp" 和 mediapipe_dataloader 在不同组合时的性能,所有这些优化都是相互兼容的: dataloader_num_workers=0``dataloader_num_workers=1``dataloader_num_workers=1 + distribution_strategy="fast_ddp"``dataloader_num_workers=1 + distribution_strategy="fast_ddp" + mediapipe_dataloader
| 设备 | dataloader_num_workers=0 | dataloader_num_workers=1 | dataloader_num_workers=1 + distribution_strategy="fast_ddp" | dataloader_num_workers=1 + distribution_strategy="fast_ddp" + mediapipe_dataloader |
|---|---|---|---|---|
| Gaudi2 HPU | 532.4 samples/s | 639.7 samples/s | 705.9 samples/s | 802.1 samples/s |
| A100 GPU | 210.5 samples/s | 296.6 samples/s | / | / |
与之前基于 dataloader_num_workers=1 和 distribution_strategy="fast_ddp" 的性能数据相比,我们又额外获得了 1.14 倍的加速。
因此,Gaudi2 上的最终结果比最开始快了 1.51 倍,而且 仅需增加 3 个简单的训练参数。 这个结果 也比使用 dataloader_num_workers=1 的 A100 快 2.70 倍!
如何复现我们的基准测试
要复现我们的基准测试,你首先需要能够访问 英特尔开发者云 (Intel Developer Cloud,IDC) 上的 Gaudi2 实例 (更多信息,请参阅 本指南)。
然后,你需要安装最新版本的 Optimum Habana 并运行 run_bridgetower.py ,您可以在 此处 找到这个脚本。具体操作命令如下:
pip install optimum[habana]
git clone https://github.com/huggingface/optimum-habana.git
cd optimum-habana/examples/contrastive-image-text
pip install -r requirements.txt运行脚本时使用的基本命令行如下:
python ../gaudi_spawn.py --use_mpi --world_size 8 run_bridgetower.py \
--output_dir /tmp/bridgetower-test \
--model_name_or_path BridgeTower/bridgetower-large-itm-mlm-itc \
--dataset_name jmhessel/newyorker_caption_contest --dataset_config_name matching \
--image_column image --caption_column image_description \
--remove_unused_columns=False \
--do_train --do_eval --do_predict \
--per_device_train_batch_size="40" --per_device_eval_batch_size="16" \
--num_train_epochs 5 \
--learning_rate="1e-5" \
--push_to_hub --report_to tensorboard --hub_model_id bridgetower\
--overwrite_output_dir \
--use_habana --use_lazy_mode --use_hpu_graphs_for_inference --gaudi_config_name Habana/clip \
--throughput_warmup_steps 3 \
--logging_steps 10上述命令行对应于 --dataloader_num_workers 0 。如果要运行其他配置,你可以视情况添加 --dataloader_num_workers 1 、 --distribution_strategy fast_ddp 及 --mediapipe_dataloader 。
如要将模型和 Tensorboard 日志推送到 Hugging Face Hub,你必须事先登录自己的帐户:
huggingface-cli login在 A100 上运行的话,你可以使用相同的 run_bridgetower.py 脚本,但需要做一些小更改:
将
GaudiTrainer和GaudiTrainingArguments替换为transformers的Trainer和TrainingArguments删除
GaudiConfig、gaudi_config和HabanaDataloaderTrainer的相关代码直接从
transformers导入set_seed:from transformers import set_seed
本文中有关 A100 的数据是在一个含 8 张 GPU 的 Nvidia A100 80GB GCP 实例上测试而得。
请注意, --distribution_strategy fast_ddp 和 --mediapipe_dataloader 仅适用于 Gaudi2,不适用于 A100。
总结
在处理图像时,我们提出了两个用于加速训练工作流的解决方案: 1) 分配更多的 CPU 资源给数据加载器,2) 直接在加速卡上而不是 CPU 上解码和变换图像。
我们证明,在训练像 BridgeTower 这样的 SOTA 视觉语言模型时,它会带来显著的加速: 基于 Optimum Habana 的 Habana Gaudi2 几乎比基于 Transformers 的英伟达 A100 80GB 快 3 倍!。而为了获得这些加速,你只需在训练脚本中额外加几个参数即可,相当容易!
后面,我们期待能使用 HPU 图进一步加速训练,我们还想向大家展示如何在 Gaudi2 上使用 DeepSpeed ZeRO-3 来加速 LLM 的训练。敬请关注!
如果你对使用最新的 AI 硬件加速卡和软件库加速机器学习训练和推理工作流感兴趣,可以移步我们的 专家加速计划。如果你想了解有关 Habana 解决方案的更多信息,可以在 此处 了解我们相关信息并联系他们。要详细了解 Hugging Face 为让 AI 硬件加速卡更易于使用而做的努力,请查阅我们的 硬件合作伙伴计划。
相关话题
更快的训练和推理: 对比 Habana Gaudi2 和英伟达 A100 80GB
大语言模型快速推理: 在 Habana Gaudi2 上推理 BLOOMZ
英文原文: https://hf.co/blog/bridgetower
原文作者: Régis Pierrard,Anahita Bhiwandiwalla
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
相关文章:

使用 Habana Gaudi2 加速视觉语言模型 BridgeTower
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟! 在对最先进的视觉语言模型 BridgeTower 进行微调时,使用 Optimum Habana v1.6, Habana Gaudi2 可以达到 近 3 倍于 A100 的速度。硬件加速的数据加载以及 fast DDP 这两个新特…...

mysql查询语句之实践篇
基础查询语句 完整语法格式如下: select 字段列表 from 表名列表 where 条件列表 group by 分组字段 having 分组之后的条件 order by 排序 limit 分页限定 -- 创建表 create table stu(id int,name varchar(20),chinese double,english double,math double ); --…...
)
Linux 和 MacOS 中的 profile 文件详解(二)
上篇文章讲解了 profile 文件的作用、login shell 和 non-login shell 的定义、不同 profile 被 bash shell 在不同情况下的加载顺序和作用,本文讲解一下 zsh shell 相关的知识。 zsh shell MacOS 从 Catalina 版本开始将 zsh 作为默认登录 shell 和交互式 shell。…...
Python之多重继承
一、多重继承 Python支持多重继承,一个子类可以有多个“直接父类”。这样,就具备了“多个父类”的特点。但是由于,这样会被“类的整体层次”搞的异常复杂,尽量避免使用。 class A:def aa(self):print("aa") class B…...

前端CSS文字阴影text-shadow记录
前端CSS文字阴影text-shadow记录 一、文字阴影 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Doc…...
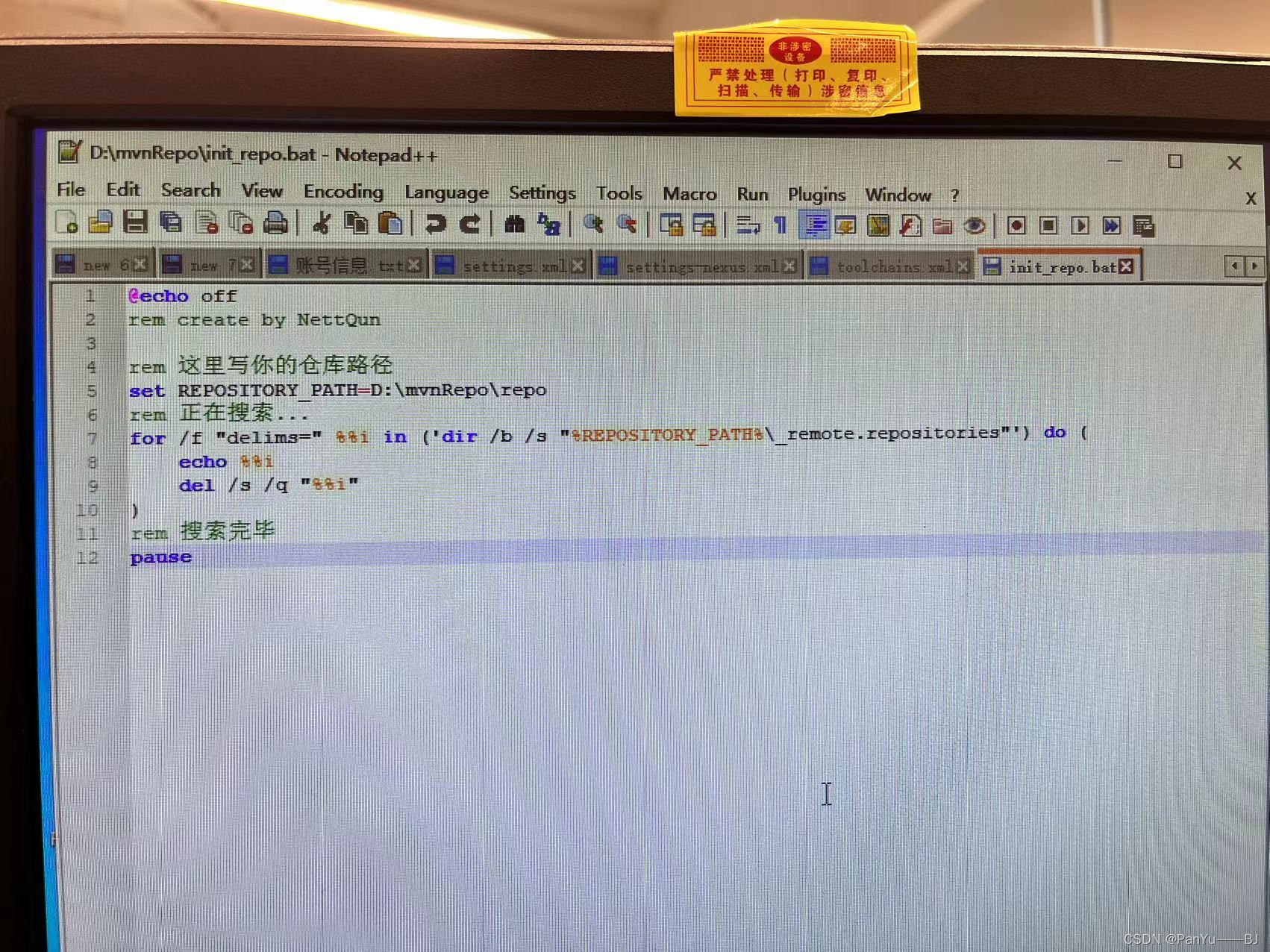
maven 删除下载失败的包
本文介绍了当Maven包报红时,使用删除相关文件的方法来解决该问题。文章详细说明了_remote.repositories、.lastUpdated和_maven.repositories文件的作用,以及如何使用命令行删除这些文件。这些方法可以帮助开发者解决Maven包报红的问题,确保项…...

《吐血整理》高级系列教程-吃透Fiddler抓包教程(37)-掌握Fiddler中Fiddler Script用法你有多牛逼-下
1.简介 Fiddler是一款强大的HTTP抓包工具,它能记录所有客户端和服务器的http和https请求,允许你监视,设置断点,甚至修改输入输出数据. 使用Fiddler无论对开发还是测试来说,都有很大的帮助。Fiddler提供的功能基本上能…...

网络安全进阶学习第十二课——SQL手工注入3(Access数据库)
文章目录 注入流程:1、判断数据库类型2、判断表名3、判断列名4、判断列数1)判断显示位 5、判断数据长度6、爆破数据内容 注入流程: 判断数据库类型 ——> 判断表名 ——> 判断列名 ——> 判断列名长度 ——> 查出数据。 asp的网…...

Zookeeper集群+Kafka集群
目录 一丶Zookkeeper概述 二、Zookeeper 特点 2.1Zookeeper 应用场景 2.2Zookeeper 选举机制 2.2.1第一次启动选举机制 2.2.2非第一次启动选举机制 三、部署 Zookeeper 集群 3.1//安装 JDK 3.2安装 Zookeeper 3.2.1修改配置文件 3.2.2拷贝配置好的 Zookeeper 配置文件…...

管理类联考——逻辑——论证逻辑——汇总篇——目录+提炼
文章目录 一、削弱方法关系的削弱必要方法的削弱因果推理的削弱果因推理的削弱概念跳跃的削弱数量比例的削弱比例因果的削弱 二、支持方法关系的支持必要方法的支持因果推理的支持果因推理的支持概念跳跃的支持数量比例的支持比例因果的支持 三、假设方法关系的假设必要方法的假…...

用excel格式书写的接口用例执行脚本
创建测试用例和测试结果集文件夹: excel编写的接口测试用例如下: 1 encoding 响应的编码格式。所测项目大部分是utf-8,有一个特殊项目是utf-8-sig 2 params 对应requests的params 3 data,对应requests的data 有些参数是动态的&a…...

【flink】Chunk splitting has encountered exception
执行任务报错: Chunk splitting has encountered exception 错误信息截图: 完整的错误信息: 16:30:43,911 ERROR org.apache.flink.runtime.source.coordinator.SourceCoordinator [SourceCoordinator-Source: CDC Sourceorg.jobslink.flink…...

单元测试用例分组 demo
文章目录 目标1、使用 Category 进行用例分组(1)设置用例组(2)编写测试类,case设置对应的用例组(3)编写执行类(4)查看运行结果(5)联系项目 2、参数…...
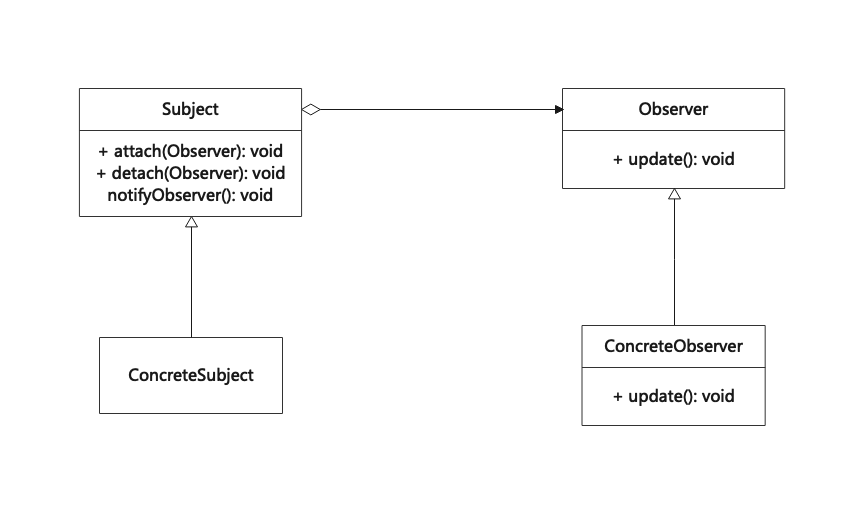
观察者模式(Observer)
观察着模式是一种行为设计模式,可以用来定义对象间的一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。 观察者模式又叫做发布-订阅(Publish/Subscribe)模式、模型-视图…...
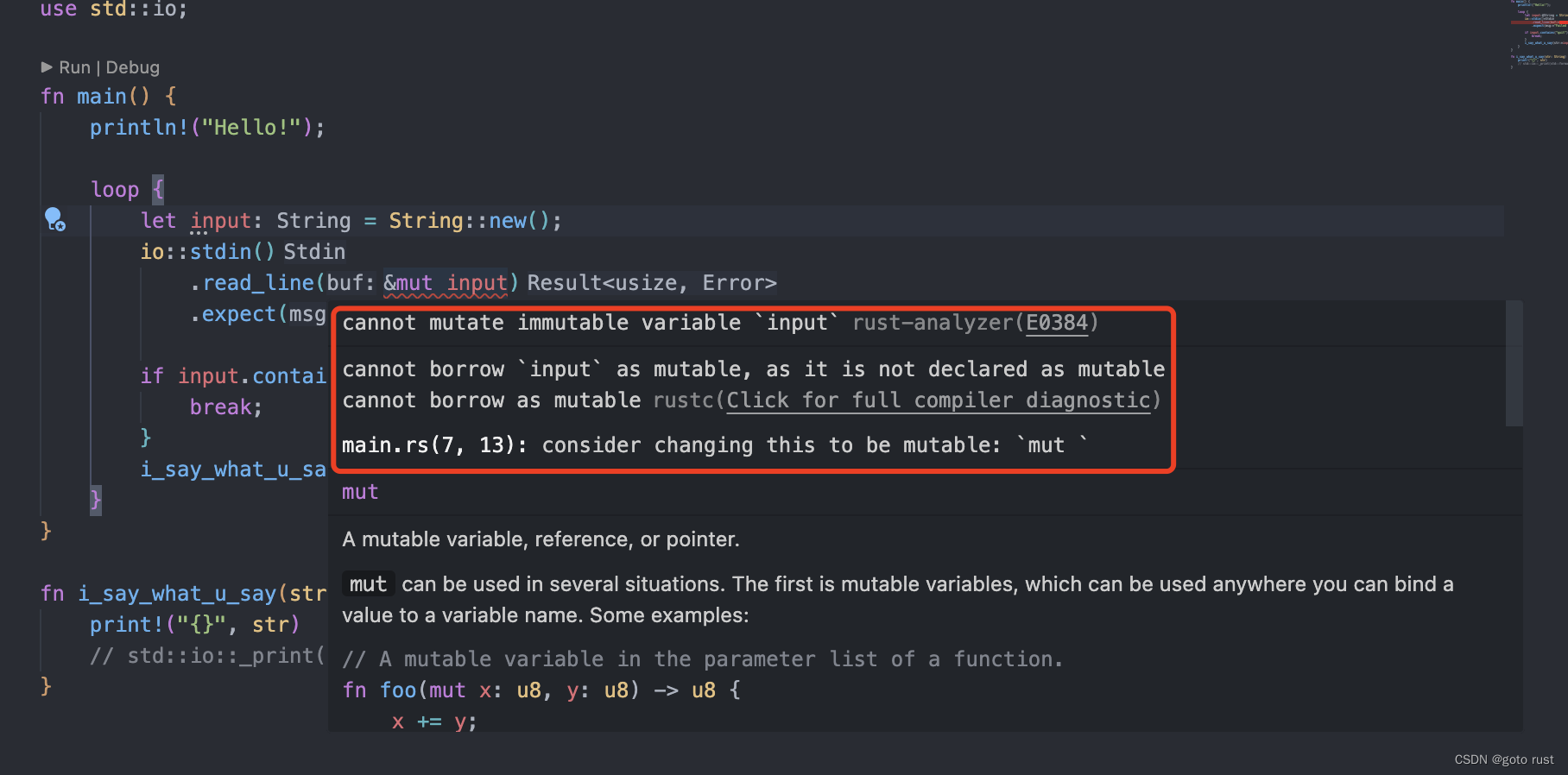
20天学会rust(二)rust的基础语法篇
在第一节(20天学rust(一)和rust say hi)我们配置好了rust的环境,并且运行了一个简单的demo——practice-01,接下来我们将从示例入手,学习rust的基础语法。 首先来看下项目结构: 项目…...

Stephen Wolfram:嵌入的概念
The Concept of Embeddings 嵌入的概念 Neural nets—at least as they’re currently set up—are fundamentally based on numbers. So if we’re going to to use them to work on something like text we’ll need a way to represent our text with numbers. And certain…...

springboot,swagger多个mapper包,多个controller加载问题
启动类添加MapperScan({"xxx.xxx.xxx.mapper","xxx.xxx.xxx.mapper"}) swagger配置类添加 Bean public Docket api01() {return new Docket(DocumentationType.SWAGGER_2)//.enable(swagger_is_enabl).apiInfo(new ApiInfoBuilder().title("你的title…...
)
湖大CG满分教程:作业训练四编程题20. 回文串(暴力×动态规划算法√)
问题描述 “回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。给你一个字符串,问最少在字符串尾添加多少字符,可以使得字符串变为回文串。 输入格式 有多组测试数据。 每组测试数据第一行是一个正整数N…...
使用toad库进行机器学习评分卡全流程
1 加载数据 导入模块 import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import numpy as np import math import xgboost as xgb …...
)
Python数据容器——列表(list)
数据容器入门 Python中的数据容器: 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素 每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。 数据容器根据特点的不同,如:是否支持重复元…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...