大模型开发(十六):从0到1构建一个高度自动化的AI项目开发流程(中)
全文共1w余字,预计阅读时间约40~60分钟 | 满满干货(附代码),建议收藏!
本文目标:通过LtM提示流程实现自动构建符合要求的函数,并通过实验逐步完整测试code_generate函数功能。
代码下载点这里
一、介绍
此篇文章为从0到1构建一个高度自动化的AI项目开发流程的第二篇,在大模型开发(十五):从0到1构建一个高度自动化的AI项目开发流程(上)中已经实现了第一部分的优化:完整的执行引导Chat模型创建外部函数代码、代码管理以及测试的全部流程。此文将提出一种“全自动函数编写策略”的解决思路,进一步深化大模型在实际开发过程中的作用,即尝试梳理当前开发流程中的核心环节,并尝试借助Chat模型完成各核心环节的工作。
二、利用Chat模型自动实现需求函数的编写
2.1 借助Few-shot完成需求函数的自动编写
在之前的流程中,已经实现了围绕某个具体的需求实现了让Chat模型自己编写代码完成需求的功能,因此,现在距离让智能邮件收发系统实现功能上的自生长就还剩下最后的关键一步,那就是将用户的实时需求进行翻译和整理,并形成一整套自动代码流程和提示方法,来引导模型进行对应的外部函数创建。
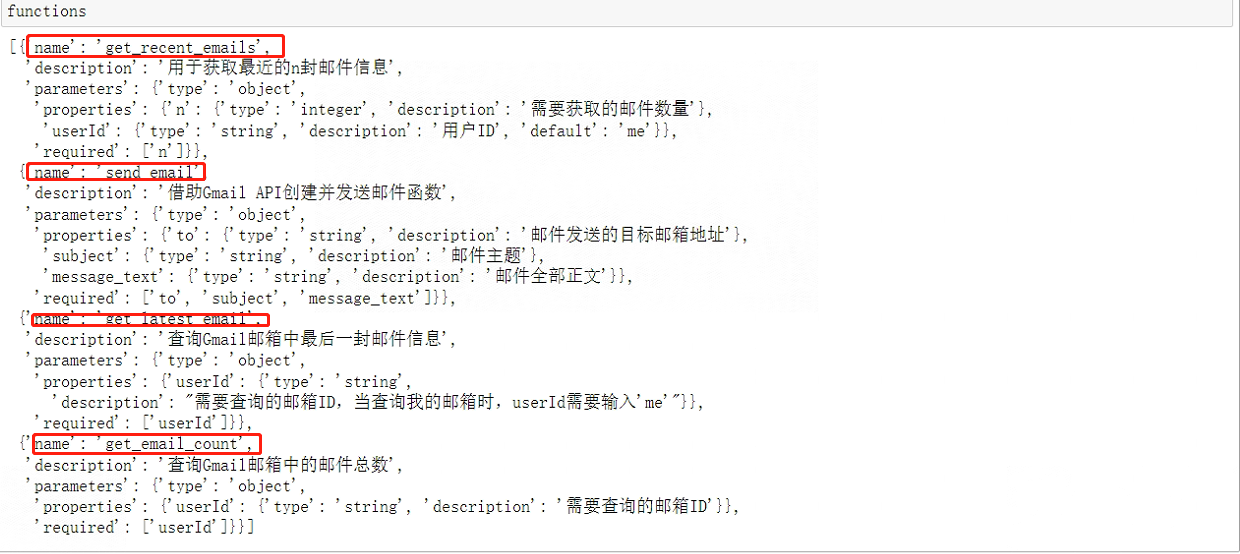
这一步是非常重要的,比如在当前对话过程中,用户提出了一个全新的需求:查看邮箱里是否有某位重要人物的未读邮件,并解读邮件里面的内容。此前定义的一系列外部函数都无法满足当前需求,回顾一下之前定义的四个函数:
functions_list = [get_recent_emails, send_email, get_latest_email, get_email_count]
functions = auto_functions(functions_list)
各外部函数JSON Schema格式的描述如下:
如果此时使用这些外部函数,来回答新需求:查看邮箱里是否有某位重要人物的未读邮件,并解读邮件里面的内容
messages = [{"role": "user", "content": '请帮我查询一下我的Gmail邮箱中是否有来自算法小陈的未读邮件,如果有的话请帮我解读下邮件内容。'}]response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages,functions=functions,function_call="auto", )
此时的输出是这样的:
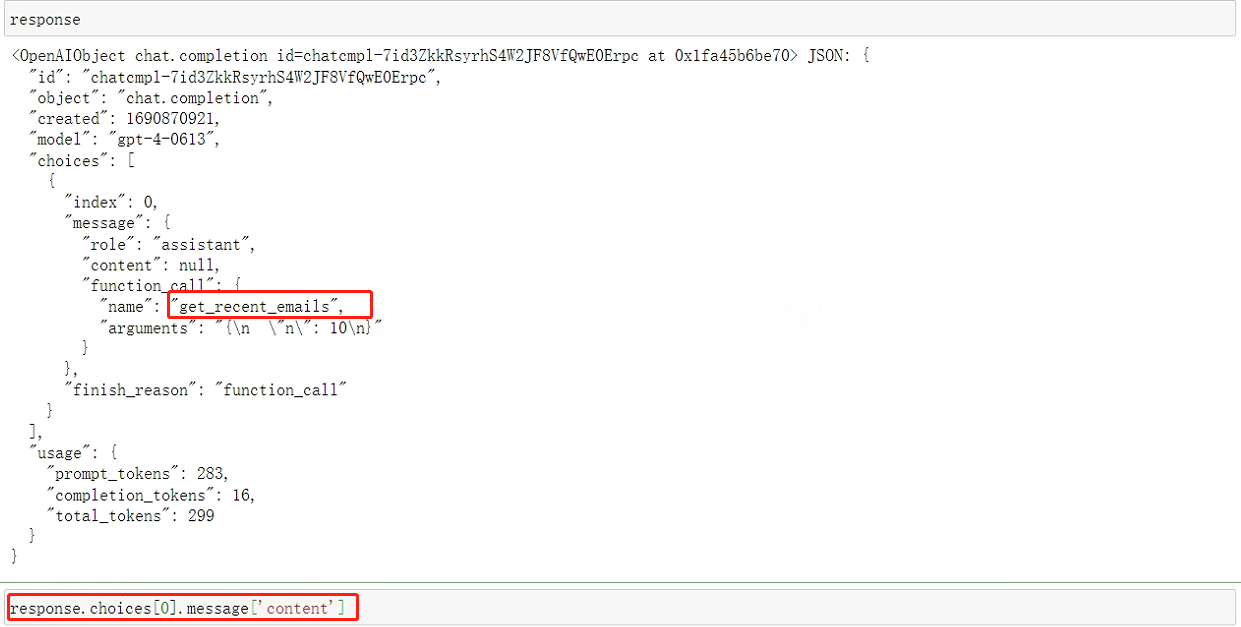
针对这个问答,模型找到了get_recent_emails函数,看起来貌似是对了,但是当使用response.choices[0].message[‘content’]查看返回内容的时候,会发现返回的内容数据是空的,很容易发现,从功能实现角度来说,这个功能和查询最近若干封邮件信息属于类似的功能,但还是存在需求上的差异,为了避免这种让大模型混淆的外部函数,是需要进一步根据新需求创建新的外部函数。
所以一个比较好的解决思路就是:通过提示工程让大模型(LLMs)自动完成新增功能。上述过程是这样的:

提示词过程其实就是一个指令翻译过程,和大模型开发(九):基于Few-Shot-LtM提示工程复现SCAN数据集下的指令翻译任务复现的任务类似,唯一不同的是,对于SCAN指令翻译,其背后是一套完全不同于自然语言的语法规则,而当前指令翻译任务相对简单,输入和输出都是可以基于自然语言的语义对其进行理解的,其背后的语法规则相对清晰。
所以从指令翻译的角度来思考,是否可以通过Few-shot提示法来给大模型赋能呢?所以做了下面一系列的测试:
- Step 1:构建提示词
直接使用这里大模型开发(十五):从0到1构建一个高度自动化的AI项目开发流程(上)中手写的两个创建外部函数的示例,如下:
get_email_input = "请帮我查下邮箱里最后一封邮件内容。"get_email_out = "请帮我编写一个python函数,用于查看我的Gmail邮箱中最后一封邮件信息,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是一个包含最后一封邮件信息的对象,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"email_counts_input = "请帮我查下邮箱里现在总共有多少封邮件。"email_counts_out = "请帮我编写一个python函数,用于查看我的Gmail邮箱中总共有多少封邮件,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是当前邮件总数,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"
- Step 2:拼接成Few-shot的输入形式
user_content = "请查下我的邮箱里是否有来自无敌小怪兽的未读邮件,并解读最近一封未读邮件的内容"messages_fewShot_stage1 = [{"role": "system", "content": "请按照格式,编写一段函数功能说明。"},{"role": "user", "name":"example1_user", "content": get_email_input},{"role": "assistant", "name":"example1_assistant", "content": get_email_out},{"role": "user", "name":"example2_user", "content": email_counts_input},{"role": "assistant", "name":"example2_assistant", "content": email_counts_out},{"role": "user", "name":"example_user", "content": user_content}]
messages_fewShot_stage1
看下输出结果:

- Step 3:调用GPT 4.0 API
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages_fewShot_stage1
)
看一下输出结果:

通过这段返回结果,其实能看出模型可以较好的学习到Few-shot提示示例的指令翻译规范,进一步测试一下。
- Step 4:功能测试
读取之前本地已经存储好的get_latest_email()外部函数:
with open('./functions/tested functions/%s_module.py' % 'get_latest_email', encoding='utf-8') as f:assistant_example_content = f.read()
描述是这样的:

在Step 3 中GPT 4.0 API给生成的函数描述是这样的:

- Step 5:构建测试的提示词
messages_fewShot_stage2 = [{"role": "system", "content": system_content},{"role": "user", "name":"example_user", "content": user_example_content},{"role": "assistant", "name":"example_assistant", "content": assistant_example_content},{"role": "user", "name":"example_user", "content": user_content}]messages_fewShot_stage2
输出是这样的:

- Step 6:再次调用GPT 4.0 API
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages_fewShot_stage2
)
结果输出是这样的:

- Step 7:提取为本地代码文件
def extract_function_code(s, detail=0, tested=False):"""函数提取函数,同时执行函数内容,可以选择打印函数信息,并选择代码保存的地址"""def extract_code(s):"""如果输入的字符串s是一个包含Python代码的Markdown格式字符串,提取出代码部分。否则,返回原字符串。参数:s: 输入的字符串。返回:提取出的代码部分,或原字符串。"""# 判断字符串是否是Markdown格式if '```python' in s or 'Python' in s or'PYTHON' in s:# 找到代码块的开始和结束位置code_start = s.find('def')code_end = s.find('```\n', code_start)# 提取代码部分code = s[code_start:code_end]else:# 如果字符串不是Markdown格式,返回原字符串code = sreturn code# 提取代码字符串code = extract_code(s)# 提取函数名称match = re.search(r'def (\w+)', code)function_name = match.group(1)# 将函数写入本地if tested == False:with open('./functions/untested functions/%s_module.py' % function_name, 'w', encoding='utf-8') as f:f.write(code)else:with open('./functions/tested functions/%s_module.py' % function_name, 'w', encoding='utf-8') as f:f.write(code)# 执行该函数try:exec(code, globals())except Exception as e:print("An error occurred while executing the code:")print(e)# 打印函数名称if detail == 0:print("The function name is:%s" % function_name)if detail == 1:with open('./functions/untested functions/%s_module.py' % function_name, encoding='utf-8') as f:content = f.read()print(content)
看一下代码描述:
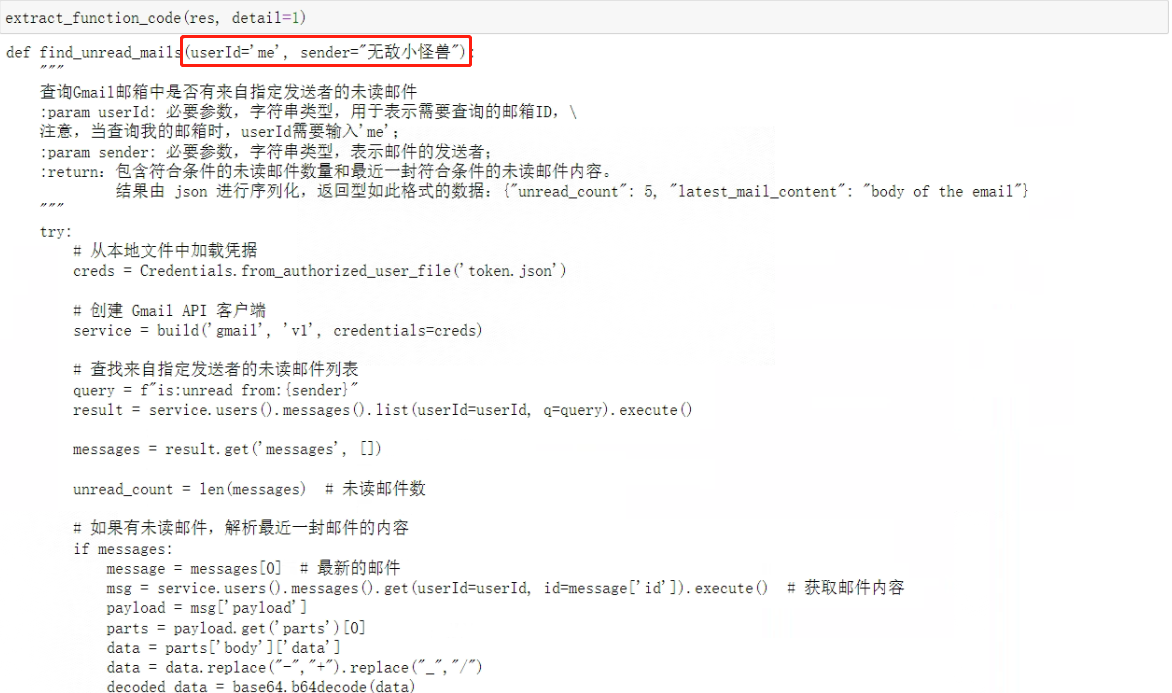
从测试结果上看,这个函数确实是没什么问题的,基本上已经能借助Few-shot来完成函数的自动创建。
2.2 借助LtM提示流程完成更稳定的函数编写
大语言模型(LLMs)生成的内容并不是固定的,虽然Few-shot在一定程度上能解决自动编写函数的需求,但在实际的测试过程中,Few-shot还不是特别的稳定,一个有效而且容易想到的解决办法就是使用更强的提示方法:如LtM提示法。
在大模型开发(八):基于思维链(CoT)的进阶提示工程这篇文章中已经用大量实验证明,LtM就是目前为止最有效的提示方法,通过多段提示策略并结合当前指令翻译任务考虑,一种更有希望能够引导模型能够顺利完成指令翻译流程的提示方法是:先引导模型拆解当前需求中的“变量”作为后续函数的参数,然后再基于已经确定的变量,引导模型完成翻译工作。
就整个指令翻译任务来说,最难的地方也就在于函数参数的理解过程,一旦模型能够准确的翻译出外部函数需要哪些参数,其他部分的翻译任务自然迎刃而解。所以优化第一阶段提示流程后,一个比较好的整体提示过程如下:
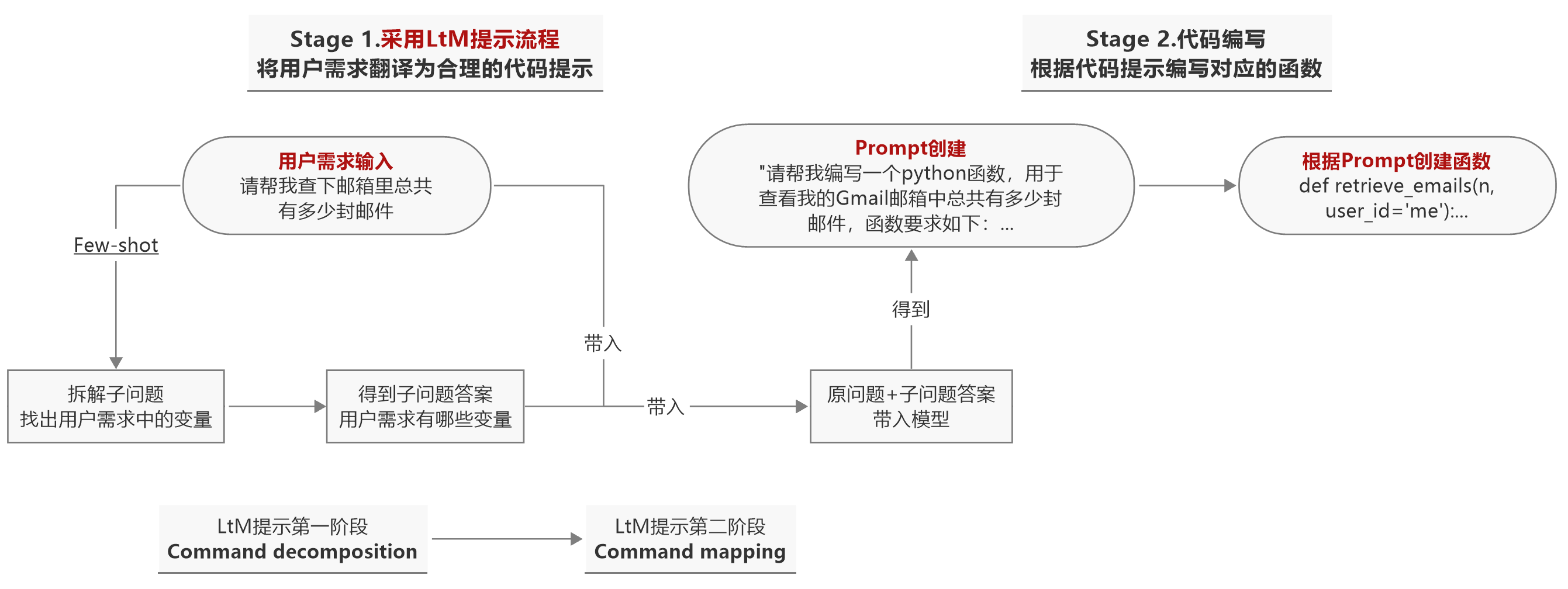
让模型合理的分析符合当前需求的参数设置,是一种提高函数复用率的措施。例如现在想查询来自无敌小怪兽的未读邮件,若模型可以将读取“谁”的未读邮件视作一个变量,即将读取邮件的对象设置为参数,则可以更好的提升后续该函数的复用率。
如果还不理解LtM提示过程的,强烈建议先看完这一篇再继续本文:大模型开发(八):基于思维链(CoT)的进阶提示工程
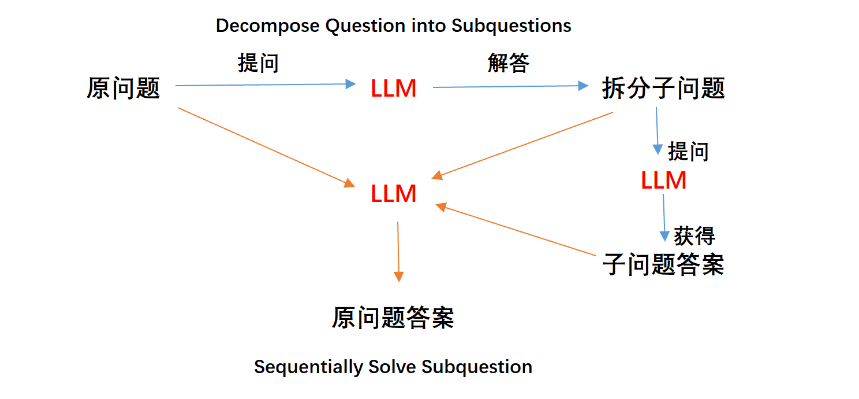
看一下LtM的流程图:

对于LtM提示有两个阶段,第一个阶段的提示命名为Command decomposition,简写为CD,第二阶段的提示命名为Command mapping,简写为CM。
- Step 1:使用Few-shot构建拆分子问题的示例
以“查看最后一封邮件内容”和“发送邮件”这两个函数作为LtM提示的两个阶段的示例,其使用Few-shot提示首先要做示例的子问题拆解,如下:
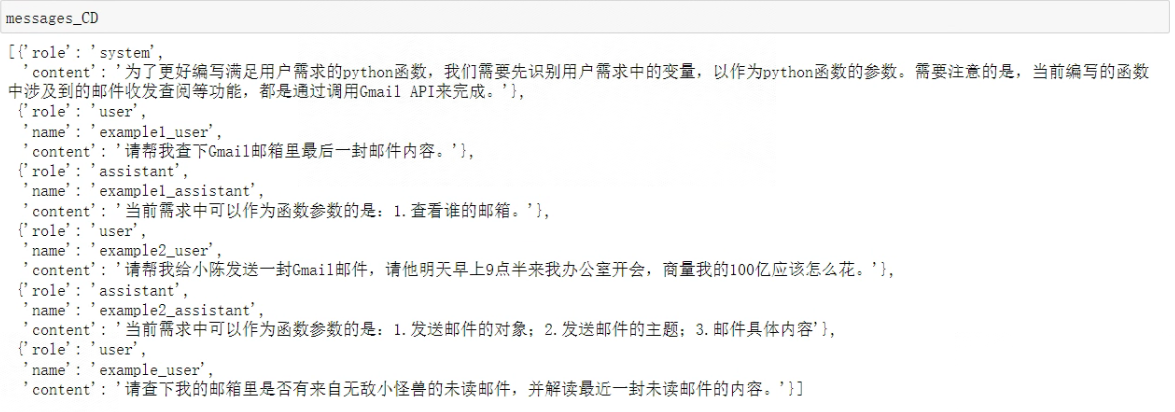
system_content1 = "为了更好编写满足用户需求的python函数,我们需要先识别用户需求中的变量,以作为python函数的参数。需要注意的是,当前编写的函数中涉及到的邮件收发查阅等功能,都是通过调用Gmail API来完成。"input1 = "请帮我查下Gmail邮箱里最后一封邮件内容。"
pi1 = "当前需求中可以作为函数参数的是:1.查看谁的邮箱。"input2 = "请帮我给小陈发送一封Gmail邮件,请他明天早上9点半来我办公室开会,商量我的100亿应该怎么花。"
pi2 = "当前需求中可以作为函数参数的是:1.发送邮件的对象;2.发送邮件的主题;3.邮件具体内容"input3 = "请查下我的邮箱里是否有来自无敌小怪兽的未读邮件,并解读最近一封未读邮件的内容。"
- Step 2:创建Prompt
messages_CD = [{"role": "system", "content": system_content1},{"role": "user", "name":"example1_user", "content": input1},{"role": "assistant", "name":"example1_assistant", "content": pi1},{"role": "user", "name":"example2_user", "content": input2},{"role": "assistant", "name":"example2_assistant", "content": pi2},{"role": "user", "name":"example_user", "content": input3}]
看下结果:
- Step 3:调用GPT 4.0 API
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages_CD
)
看一下在Few-shot下的拆解结果:

从结果上看,通过Few-shot将问题拆解并在第一个阶段给与提示,模型能够非常清楚的判断当前需求中可以作为函数的变量。
- Step 4:创建LtM Command mapping阶段提示
system_content2 = "我现在已完成Gmail API授权,授权文件为本地文件token.json。所编写的函数要求参数类型都必须是字符串类型。"get_email_input = "请帮我查下邮箱里最后一封邮件内容。" + pi1get_email_out = "请帮我编写一个python函数,用于查看我的Gmail邮箱中最后一封邮件信息,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是一个包含最后一封邮件信息的对象,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"send_email_input = "请帮我给小陈发送一封Gmail邮件,请他明天早上9点半来我办公室开会,商量我的100亿应该怎么花。" + pi2send_email_out = "请帮我编写一个python函数,用于给小陈发送邮件,请他明天早上9点半来我办公室开会,商量我的100亿应该怎么花。,函数要求如下:\1.函数参数to、subject和message_text,三个参数都是字符串类型,其中to表示发送邮件对象,subject表示邮件主题,message_text表示邮件具体内容;\2.函数返回结果是当前邮件发送状态,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"user_content = input3 + pi3
- Step 4:创建第二阶段的Prompt
messages_CM = [{"role": "system", "content": system_content2},{"role": "user", "name":"example1_user", "content": get_email_input},{"role": "assistant", "name":"example1_assistant", "content": get_email_out},{"role": "user", "name":"example2_user", "content": send_email_input},{"role": "assistant", "name":"example2_assistant", "content": send_email_out},{"role": "user", "name":"example_user", "content": user_content}]
看下输出结果:

- **Step 5:再次调用GPT 4.0 API **
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages_CM
)
看一下结果:

能够发现,在合理的函数参数设置下,这段函数描述看起来也更加合理,至此就完成了基于LtM的函数描述创建的提示过程,也就是下图:
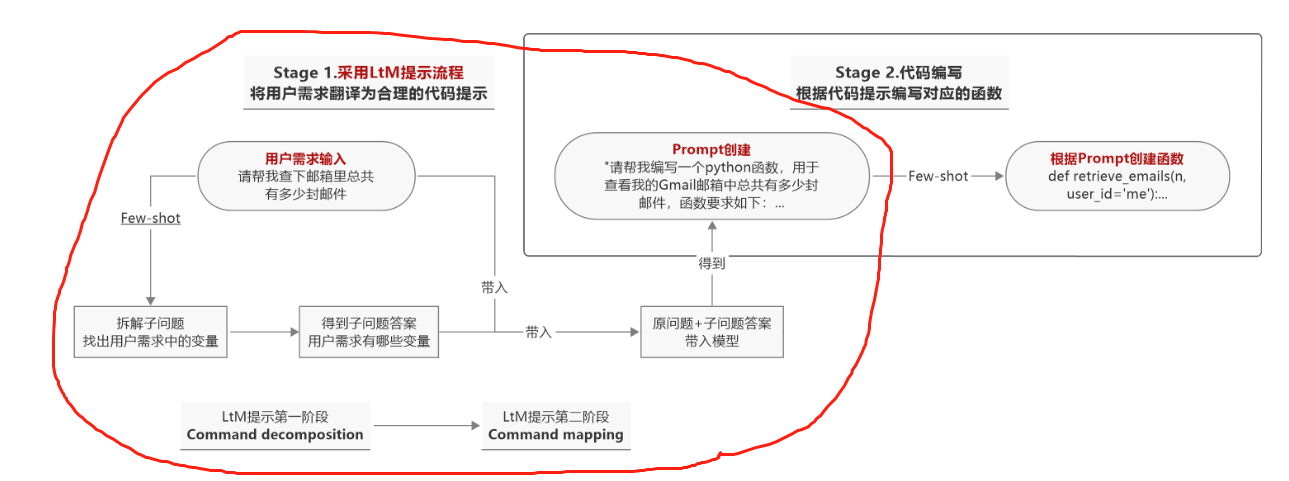
对于整体提示的第二阶段,即引导大模型基于function_description进行相应函数的创建工作。
- Step 6:根据Prompt创建函数
在函数创建阶段,同样采用Few-shot的方式进行提示,提示的示例仍然为get_email_out和send_email_out两个函数,提示流程如下:
对于get_email_out来说,它的函数描述和函数定义是这样的:

对于send_email_out来说,它的函数描述和函数定义是这样的:
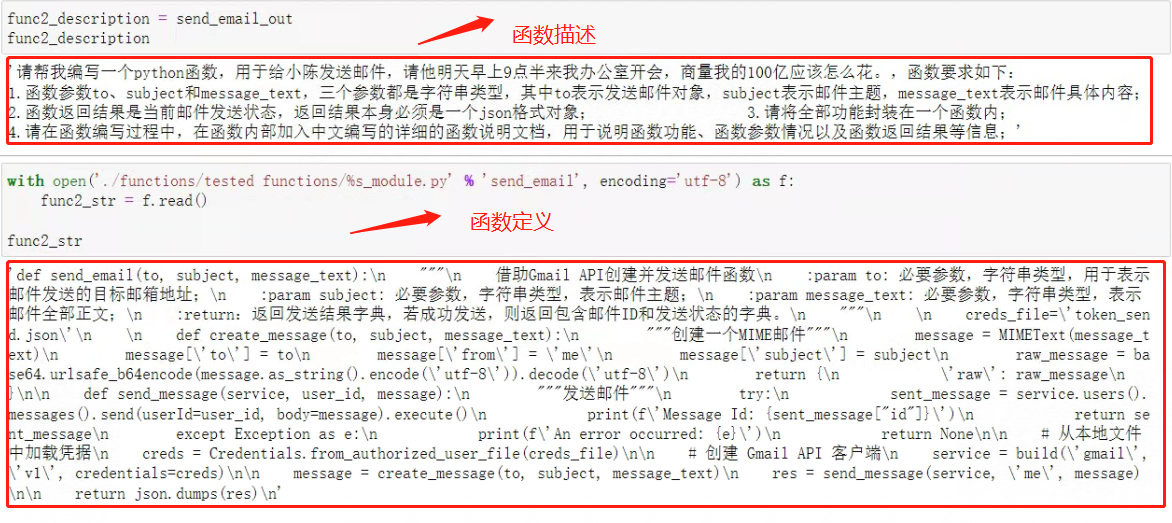
- Step 7:创建Prompt
system_content3 = "我现在已完成Gmail API授权,授权文件为本地文件token.json。函数参数必须是字符串类型对象,函数返回结果必须是json表示的字符串对象。"messages_stage2 = [{"role": "system", "content": system_content3},{"role": "user", "name":"example1_user", "content": func1_description},{"role": "assistant", "name":"example1_assistant", "content": func1_str},{"role": "user", "name":"example2_user", "content": func2_description},{"role": "assistant", "name":"example2_assistant", "content": func2_str},{"role": "user","content": function_description}]messages_stage2
生成的Prompt 是这样的:

- Step 8:调用GPT 4.0 API
response = openai.ChatCompletion.create(model="gpt-4",messages=messages_stage2
)
看一下输出结果:
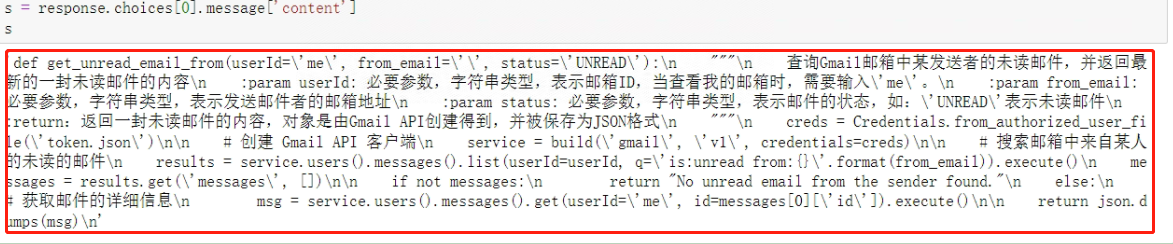
- Step 9: 将字符串解析
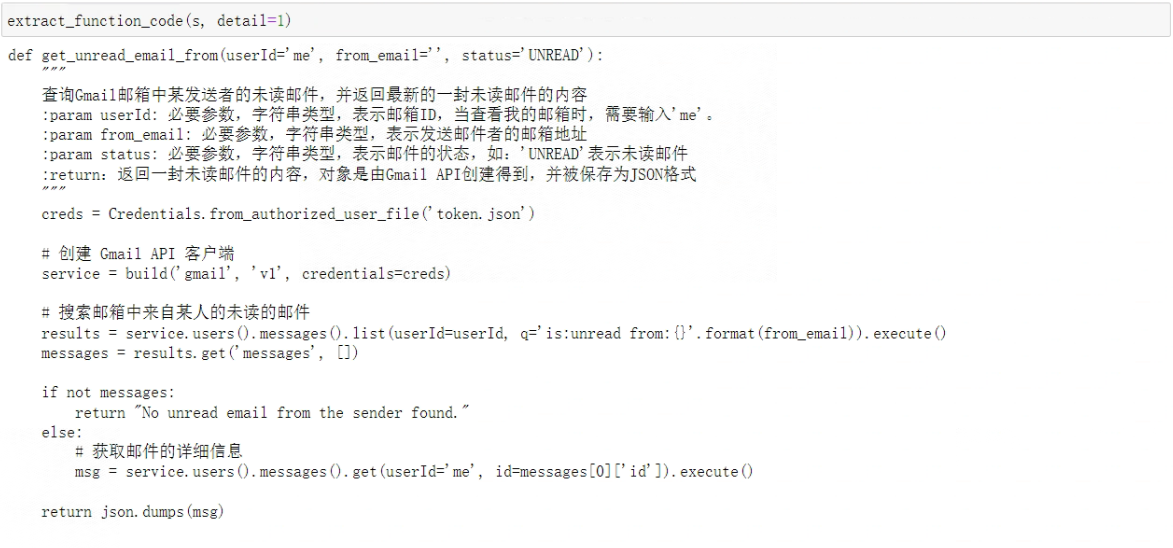
模型定义的函数为get_unread_email,该函数在经过人工审核后,是能够满足当前功能需求的。
- Step 10:带入该函数到Chat模型中进行功能验证
先看一下函数的解析情况:
functions_list = [get_unread_email_from]functions = auto_functions(functions_list)functions

先发送一篇测试邮件,如图:

然后通过LLMs + Gmail API 测试AI应用程序情况:
messages = [{"role": "user", "content": '请查询我的邮箱,看下里面是否有来自算法小陈的未读邮件。'}]response = openai.ChatCompletion.create(model="gpt-4",messages=messages,functions=functions,function_call="auto", )
看下输出:
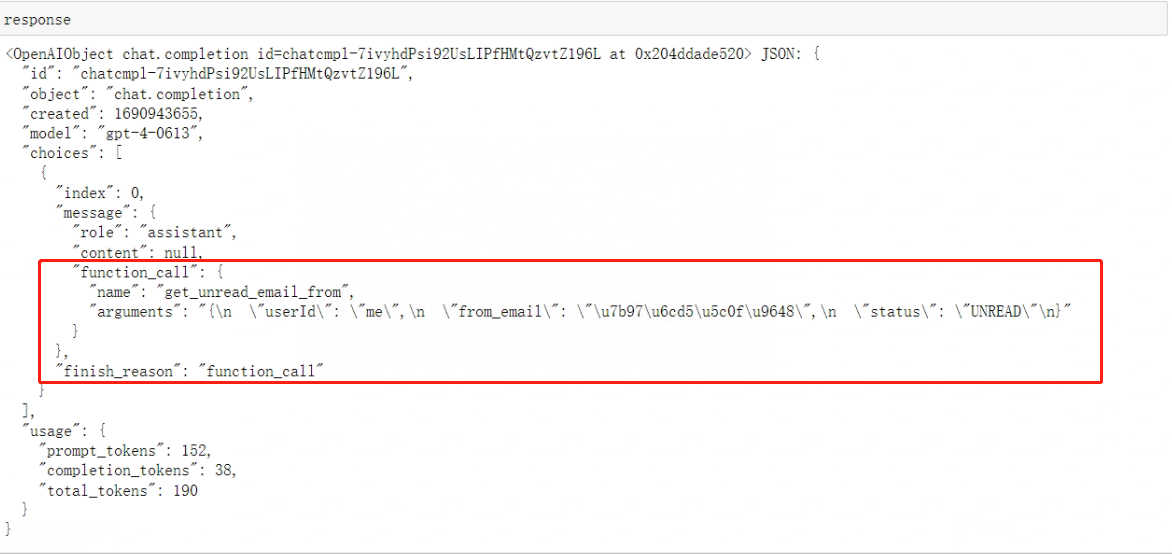
至此就能验证出:模型能够正常使用用户需求,并创建对应的符合要求的参数。
2.3 多轮对话测试
在完成上述过程后,可以将该函数直接带入到多轮对话函数中测试效果,并同时带入其他外部函数以便进行更加复杂的功能测试。
- Step 1:准备测试邮件
先提前往Gmail邮箱中发送一封邮件,邮件内容如下:

- Step 2:导入多轮对话函数:
def chat_with_model(functions_list=None, prompt="你好呀", model="gpt-4-0613", system_message=[{"role": "system", "content": "你是以为乐于助人的助手。"}]):messages = system_messagemessages.append({"role": "user", "content": prompt})while True: answer = run_conversation(messages=messages, functions_list=functions_list, model=model)print(f"模型回答: {answer}")# 询问用户是否还有其他问题user_input = input("您还有其他问题吗?(输入退出以结束对话): ")if user_input == "退出":break# 记录用户回答messages.append({"role": "user", "content": user_input})
- Step 3:更新外部函数列表
functions_list = [get_recent_emails, send_email, get_latest_email, get_email_count, get_unread_email_from]
- Step 4:功能测试
chat_with_model(functions_list=functions_list, system_message=[{"role": "system", "content": "算法小陈的邮箱地址是:snowball6@qq.com"}])
看一下对话过程:

看下邮箱情况:

至此,就完整的执行了一次新需求自动编写函数实现的完整流程。
三、实现全自动功能函数编写流程
上述基于LtM提示流程的稳定编写外部函数流程,根本目的是在探索一种适用于更多一般情况的全自动开发流程,做成目前这样还远远不够,通过更高层次的抽象实现函数封装,还有几个关键的中间环节。
3.1 提示词管理
其实不论任何领域的开发任务,**找到一种有效的对模型、流程中间环节的提示词管理方法,才能具备对掌控大语言(LLMs)输出的能力,**不同开发项目在前期需要通过人工经验的探索得到适用于当前开发流程的(能获得稳定代码结果的)提示流程,例如对于当前开发项目而言,总共是两个阶段进行提示,并且第一阶段还会采用LtM提示法,因此每个函数的背后总共都有三个提示阶段,一种有效的解决思路是:围绕每个经过测试的函数,创建一个JSON对象以保存其每个阶段的提示过程。过程如下:
- Step 1:get_latest_email完整提示示例创建过程
此前的流程中手动编写的该函数的三个阶段提示词及结果如下:
# 第一阶段LtM_CD阶段提示词及输出结果
get_latest_email_CD_input = "请帮我查下Gmail邮箱里最后一封邮件内容。"
get_latest_email_pi = "当前需求中可以作为函数参数的是:1.查看谁的邮箱。"
get_latest_email_messages_CD = [{"role": "user", "content": get_latest_email_CD_input},{"role": "assistant", "content": get_latest_email_pi}]# 第一阶段LtM_CM阶段提示词及输出结果
get_latest_email_CM_input = get_latest_email_CD_input + get_latest_email_pi
get_latest_email_description = "请帮我编写一个python函数,用于查看我的Gmail邮箱中最后一封邮件信息,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是一个包含最后一封邮件信息的对象,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"
get_latest_email_messages_CM = [{"role": "user", "content": get_latest_email_CM_input},{"role": "assistant", "content":get_latest_email_description}]# 第二阶段提示词及输出结果
with open('./functions/tested functions/%s_module.py' % 'get_latest_email', encoding='utf-8') as f:get_latest_email_function = f.read()get_latest_email_messages = [{"role": "user", "content": get_latest_email_description},{"role": "assistant", "content":get_latest_email_function}]
这个过程中需要注意两点:
- 在提示词保存过程中,不仅需要保存提示的提示词,还需要保存提示结果,以便作为其他提示过程的提示示例
- 实际开发过程多用Chat模型,因此建议以类messages参数形式进行保存
在以message形式保存完每个阶段的提示内容之后,将三个提示示例以如下格式进行保存,即将一个函数对象的三个阶段的全部提示示例保存为一个字典,并且字典中的每个键值对代表一个阶段的提示内容。同时,每个函数的完整提示示例都以function_name_prompt命名,具体get_latest_email_prompt对象创建过程如下:
# 第一阶段LtM_CD阶段提示词及输出结果
get_latest_email_CD_input = "请帮我查下Gmail邮箱里最后一封邮件内容。"
get_latest_email_pi = "当前需求中可以作为函数参数的是:1.查看谁的邮箱。"
get_latest_email_messages_CD = [{"role": "user", "content": get_latest_email_CD_input},{"role": "assistant", "content": get_latest_email_pi}]# 第一阶段LtM_CM阶段提示词及输出结果
get_latest_email_CM_input = get_latest_email_CD_input + get_latest_email_pi
get_latest_email_description = "请帮我编写一个python函数,用于查看我的Gmail邮箱中最后一封邮件信息,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是一个包含最后一封邮件信息的对象,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"
get_latest_email_messages_CM = [{"role": "user", "content": get_latest_email_CM_input},{"role": "assistant", "content":get_latest_email_description}]# 第二阶段提示词及输出结果
with open('./functions/tested functions/%s_module.py' % 'get_latest_email', encoding='utf-8') as f:get_latest_email_function = f.read()get_latest_email_messages = [{"role": "user", "content": get_latest_email_description},{"role": "assistant", "content":get_latest_email_function}] get_latest_email_prompt = {"stage1_CD": get_latest_email_messages_CD,"stage1_CM": get_latest_email_messages_CM,"stage2": get_latest_email_messages}
看一下完整的Prompt:
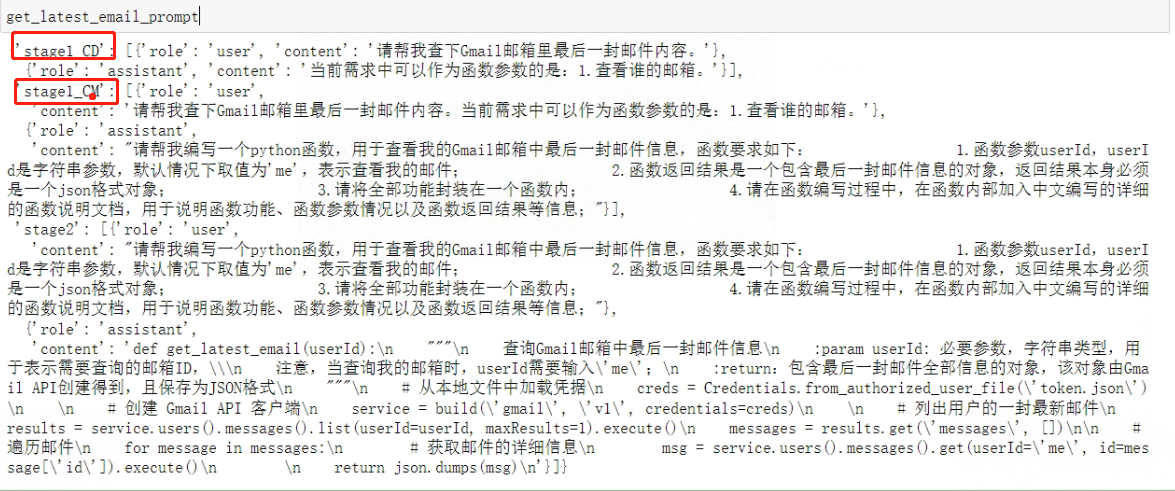
- Step 2:将其写入本地,并将其和对应函数的py文件保存为同一文件夹内
with open('./functions/tested functions/%s_prompt.json' % 'get_latest_email', 'w') as f:json.dump(get_latest_email_prompt, f)
同样的操作,可以完成get_recent_emails, send_email, get_email_count, get_unread_email_from的完整提示示例保存。
- Step 3:保存系统提示消息
system_messages = {"system_message_CD": [{"role": "system", "content": "为了更好编写满足用户需求的python函数,我们需要先识别用户需求中的变量,以作为python函数的参数。需要注意的是,当前编写的函数中涉及到的邮件收发查阅等功能,都是通过调用Gmail API来完成。"}], "system_message_CM": [{"role": "system", "content": "我现在已完成Gmail API授权,授权文件为本地文件token.json。函数参数必须是字符串类型对象,函数返回结果必须是json表示的字符串对象。"}], "system_message": [{"role": "system", "content":"我现在已完成Gmail API授权,授权文件为本地文件token.json。函数参数必须是字符串类型对象,函数返回结果必须是json表示的字符串对象。"}]}with open('./functions/tested functions/%s.json' % 'system_messages', 'w') as f:json.dump(system_messages, f)
看下最终的保存结果:
3.2 项目代码文件管理
一个完整的开发项目,必然存在着非常多的函数代码和相关提示词说明文档,为了更好的做项目管理,有必要对当前项目的代码结构和文件结构进行修改。
就以Gmail这个项目开发为例,可以尝试这种操作:
- 将原本的通用性functions文件夹更名为特定的autoGmail_project,注明是该文件夹专门用于保存autoGmail相关文件。
- 将tested和untested内的同名函数代码和提示文件保存到一个同名文件夹内,原system_messages.json文件位置不变。
修改前是这样的:
将同一个函数的module文件和prompt文件都放在一个函数同名文件夹内,修改后tested文件是这样的:
3.3 提示词管理辅助函数
- Step 1:修改remove_to_tested函数
当修改了文件路径后,需要重新定义一个remove_to_tested函数,以实现函数文件夹的untested到tested的转移过程,代码如下:
def remove_to_tested(function_name):"""将函数同名文件夹由untested文件夹转移至tested文件夹内。\完成转移则说明函数通过测试,可以使用。此时需要将该函数的源码写入gptLearning.py中方便下次调用。"""# 将函数代码写入gptLearning.py文件中with open('./functions/untested functions/%s/%s_module.py' % (function_name, function_name), encoding='utf-8') as f:function_code = f.read()with open('gptLearning.py', 'a', encoding='utf-8') as f:f.write(function_code)# 源文件夹路径src_dir = './functions/untested functions/%s' % function_name# 目标文件夹路径dst_dir = './functions/tested functions/%s' % function_name# 移动文件夹shutil.move(src_dir, dst_dir)
- Step 2:修改extract_function_code函数
extract_function_code需要添加在完成函数提取时就在untested文件夹中创建同名函数文件夹的功能,以及需要求修改读取和写入代码的文件路径,代码如下:
def extract_function_code(s, detail=0, tested=False, g=globals()):"""函数提取函数,同时执行函数内容,可以选择打印函数信息,并选择代码保存的地址"""def extract_code(s):"""如果输入的字符串s是一个包含Python代码的Markdown格式字符串,提取出代码部分。否则,返回原字符串。参数:s: 输入的字符串。返回:提取出的代码部分,或原字符串。"""# 判断字符串是否是Markdown格式if '```python' in s or 'Python' in s or'PYTHON' in s:# 找到代码块的开始和结束位置code_start = s.find('def')code_end = s.find('```\n', code_start)# 提取代码部分code = s[code_start:code_end]else:# 如果字符串不是Markdown格式,返回原字符串code = sreturn code# 提取代码字符串code = extract_code(s)# 提取函数名称match = re.search(r'def (\w+)', code)function_name = match.group(1)# 在untested文件夹内创建函数同名文件夹directory = './functions/untested functions/%s' % function_nameif not os.path.exists(directory):os.makedirs(directory)# 将函数写入本地if tested == False:with open('./functions/untested functions/%s/%s_module.py' % (function_name, function_name), 'w', encoding='utf-8') as f:f.write(code)else:# 调用remove_to_test函数将函数文件夹转移至tested文件夹内remove_to_tested(function_name)with open('./functions/tested functions/%s/%s_module.py' % (function_name, function_name), 'w', encoding='utf-8') as f:f.write(code)# 执行该函数try:exec(code, g)except Exception as e:print("An error occurred while executing the code:")print(e)# 打印函数名称if detail == 0:print("The function name is:%s" % function_name)if detail == 1:if tested == False:with open('./functions/untested functions/%s/%s_module.py' % (function_name, function_name), 'r', encoding='utf-8') as f:content = f.read()else:with open('./functions/tested functions/%s/%s_module.py' % (function_name, function_name), 'r', encoding='utf-8') as f: content = f.read()print(content)return function_name
- Step 3:修改show_functions函数
show_functions功能则需要修改为展示文件夹内内文件名称,代码如下:
def show_functions(tested=False, if_print=False):"""打印tested或untested文件夹内全部函数"""current_directory = os.getcwd()if tested == False:directory = current_directory + '\\functions\\untested functions'else:directory = current_directory + '\\functions\\tested functions'files_and_directories = os.listdir(directory)# 过滤结果,只保留.py文件和非__pycache__文件夹files_and_directories = files_and_directories = [name for name in files_and_directories if (os.path.splitext(name)[1] == '.py' or os.path.isdir(os.path.join(directory, name))) and name != "__pycache__"]if if_print != False:for name in files_and_directories:print(name)return files_and_directories
至此,就完成了经过测试的函数的提示词管理,并搭建了新的提示词管理方法,以及创建了协助完成文件管理的相关函数。
四、实现全自动编程函数创建方法
在对功能函数实现自动化编写后,还需要将从用户需求到LtM提示法创建外部函数完整流程封装到一个名为code_generate的函数内。该函数基本功能、和其他函数交互关系以及和函数库之间调用关系如下:
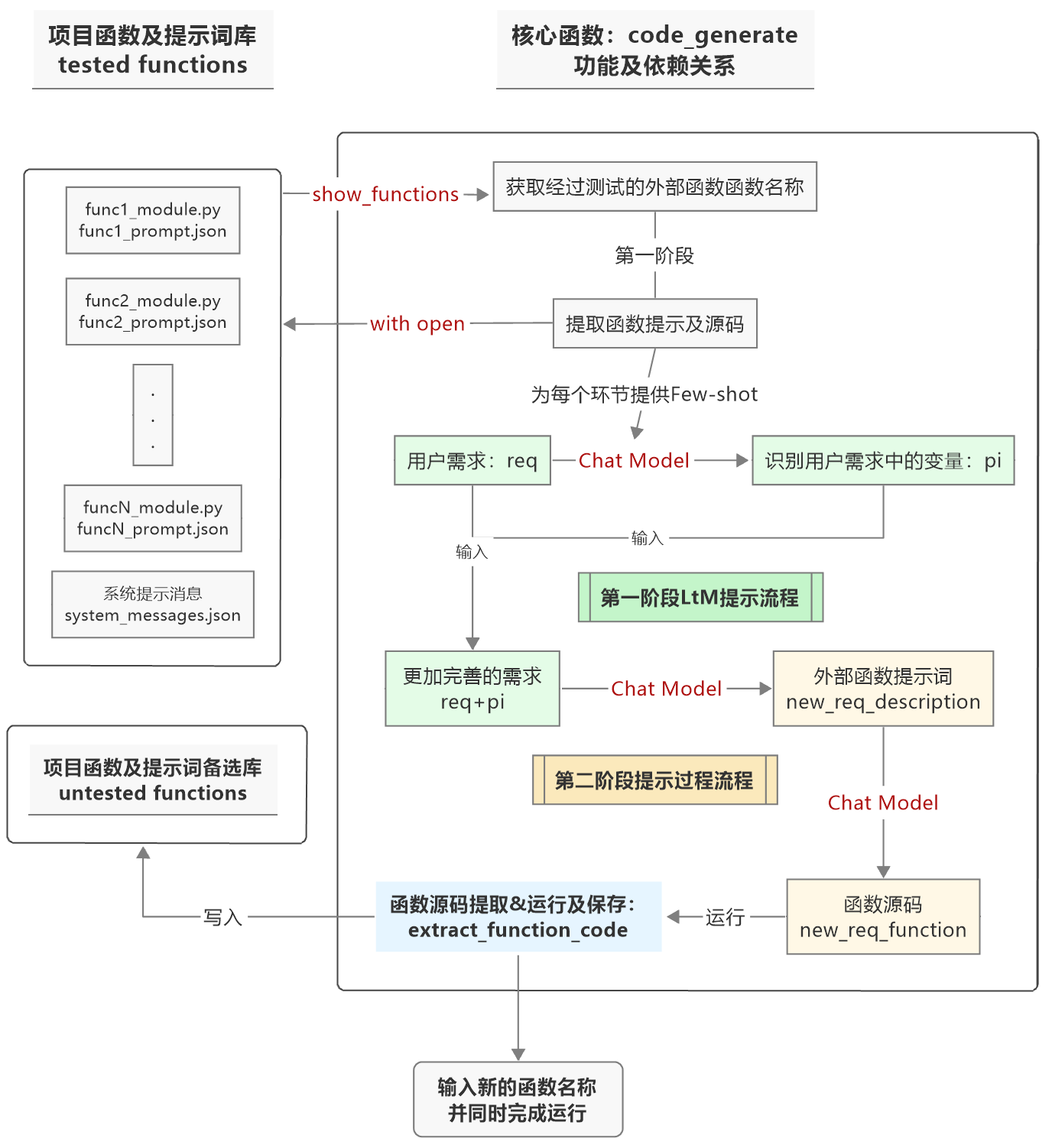
将上述过程封装成高级函数,代码是这样的:
def code_generate(req, few_shot='all', model='gpt-4-0613', g=globals(), detail=0):"""Function calling外部函数自动创建函数,可以根据用户的需求,直接将其翻译为Chat模型可以直接调用的外部函数代码。:param req: 必要参数,字符串类型,表示输入的用户需求;:param few_shot: 可选参数,默认取值为字符串all,用于描述Few-shot提示示例的选取方案,当输入字符串all时,则代表提取当前外部函数库中全部测试过的函数作为Few-shot;\而如果输入的是一个包含了多个函数名称的list,则表示使用这些函数作为Few-shot。:param model: 可选参数,表示调用的Chat模型,默认选取gpt-4-0613;:param g: 可选参数,表示extract_function_code函数作用域,默认为globals(),即在当前操作空间全域内生效;:param detail: 可选参数,默认取值为0,还可以取值为1,表示extract_function_code函数打印新创建的外部函数细节;:return:新创建的函数名称。需要注意的是,在函数创建时,该函数也会在当前操作空间被定义,后续可以直接调用;"""# 提取提示示例的函数名称if few_shot == 'all':few_shot_functions_name = show_functions(tested=True)elif type(few_shot) == list:few_shot_functions_name = few_shot# few_shot_functions = [globals()[name] for name in few_shot_functions_name]# 读取各阶段系统提示with open('./functions/tested functions/system_messages.json', 'r') as f:system_messages = json.load(f)# 各阶段提示message对象few_shot_messages_CM = []few_shot_messages_CD = []few_shot_messages = []# 先保存第一条消息,也就是system messagefew_shot_messages_CD += system_messages["system_message_CD"]few_shot_messages_CM += system_messages["system_message_CM"]few_shot_messages += system_messages["system_message"]# 创建不同阶段提示messagefor function_name in few_shot_functions_name:with open('./functions/tested functions/%s/%s_prompt.json' % (function_name, function_name), 'r') as f:msg = json.load(f)few_shot_messages_CD += msg["stage1_CD"]few_shot_messages_CM += msg["stage1_CM"]few_shot_messages += msg['stage2']# 读取用户需求,作为第一阶段CD环节User contentnew_req_CD_input = reqfew_shot_messages_CD.append({"role": "user", "content": new_req_CD_input})print('第一阶段CD环节提示创建完毕,正在进行CD提示...')# 第一阶段CD环节Chat模型调用过程response = openai.ChatCompletion.create(model=model,messages=few_shot_messages_CD)new_req_pi = response.choices[0].message['content']print('第一阶段CD环节提示完毕')# 第一阶段CM环节Messages创建new_req_CM_input = new_req_CD_input + new_req_pifew_shot_messages_CM.append({"role": "user", "content": new_req_CM_input})print('第一阶段CM环节提示创建完毕,正在进行第一阶段CM提示...')# 第一阶段CM环节Chat模型调用过程response = openai.ChatCompletion.create(model=model,messages=few_shot_messages_CM)new_req_description = response.choices[0].message['content']print('第一阶段CM环节提示完毕')# 第二阶段Messages创建过程few_shot_messages.append({"role": "user", "content": new_req_description})print('第二阶段提示创建完毕,正在进行第二阶段提示...')# 第二阶段Chat模型调用过程response = openai.ChatCompletion.create(model=model,messages=few_shot_messages)new_req_function = response.choices[0].message['content']print('第二阶段提示完毕,准备运行函数并编写提示示例')# 提取函数并运行,创建函数名称对象,统一都写入untested文件夹内function_name = extract_function_code(s=new_req_function, detail=detail, g=g)print('新函数保存在./functions/untested functions/%s/%s_module.py文件中' % (function_name, function_name))# 创建该函数提示示例new_req_messages_CD = [{"role": "user", "content": new_req_CD_input},{"role": "assistant", "content": new_req_pi}]new_req_messages_CM = [{"role": "user", "content": new_req_CM_input},{"role": "assistant", "content":new_req_description}]with open('./functions/untested functions/%s/%s_module.py' % (function_name, function_name), encoding='utf-8') as f:new_req_function = f.read()new_req_messages = [{"role": "user", "content": new_req_description},{"role": "assistant", "content":new_req_function}] new_req_prompt = {"stage1_CD": new_req_messages_CD,"stage1_CM": new_req_messages_CM,"stage2": new_req_messages} with open('./functions/untested functions/%s/%s_prompt.json' % (function_name, function_name), 'w') as f:json.dump(new_req_prompt, f)print('新函数提示示例保存在./functions/untested functions/%s/%s_prompt.json文件中' % (function_name, function_name))print('done')return function_name
对于上述过程,如果不理解的话可以手动尝试验证一下,以get_latest_email为例:
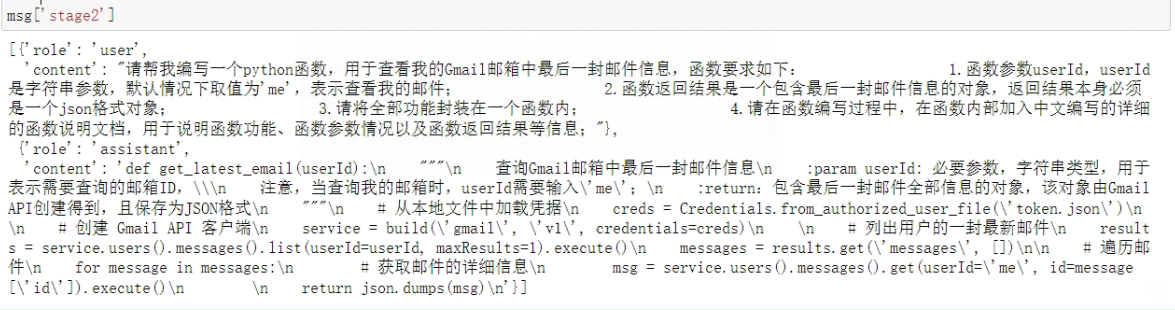
- Step 1:读取get_latest_email的函数描述
function_name = 'get_latest_email'with open('./functions/tested functions/%s/%s_prompt.json' % (function_name, function_name), 'r') as f:msg = json.load(f)msg['stage2']
看一下输出:
- Step 2:查看保存的函数文件
few_shot_functions_name = show_functions(tested=True)
看下返回结果:

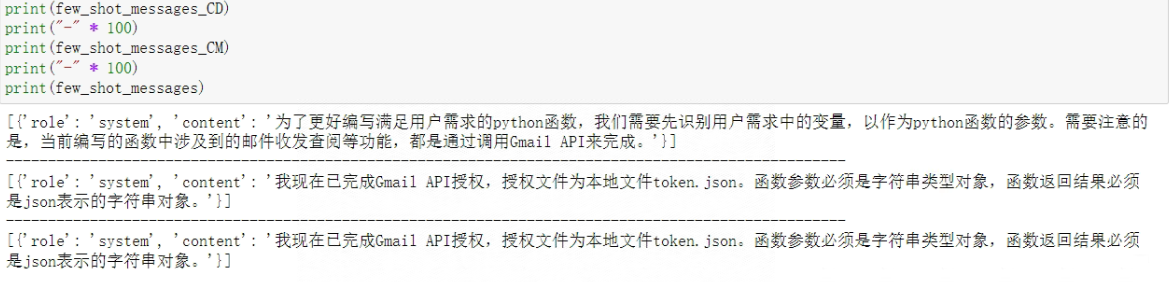
- Step 3:查看各阶段的系统Prompt
with open('./functions/tested functions/system_messages.json', 'r') as f:system_messages = json.load(f)# 各阶段提示message对象
few_shot_messages_CM = []
few_shot_messages_CD = []
few_shot_messages = []# 先保存第一条消息,也就是system message
few_shot_messages_CD += system_messages["system_message_CD"]
few_shot_messages_CM += system_messages["system_message_CM"]
few_shot_messages += system_messages["system_message"]
看下返回结果:
- Step 4:查看各函数完整的Prompt
for function_name in few_shot_functions_name:with open('./functions/tested functions/%s/%s_prompt.json' % (function_name, function_name), 'r') as f:msg = json.load(f)few_shot_messages_CD += msg["stage1_CD"]few_shot_messages_CM += msg["stage1_CM"]few_shot_messages += msg['stage2']
看下结果:
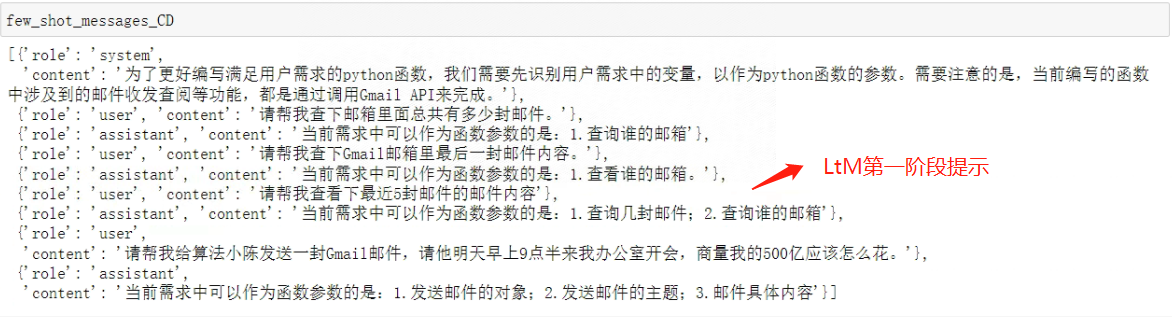

- Step 4:输入新需求
new_req_CD_input = "请查下我的邮箱里是否有来自算法小陈的未读邮件,有的话请解读下这封未读邮件的内容。"
- Step 5:拼接新需求的Prompt
few_shot_messages_CD.append({"role": "user", "content": new_req_CD_input})
输出的Prompt如下:
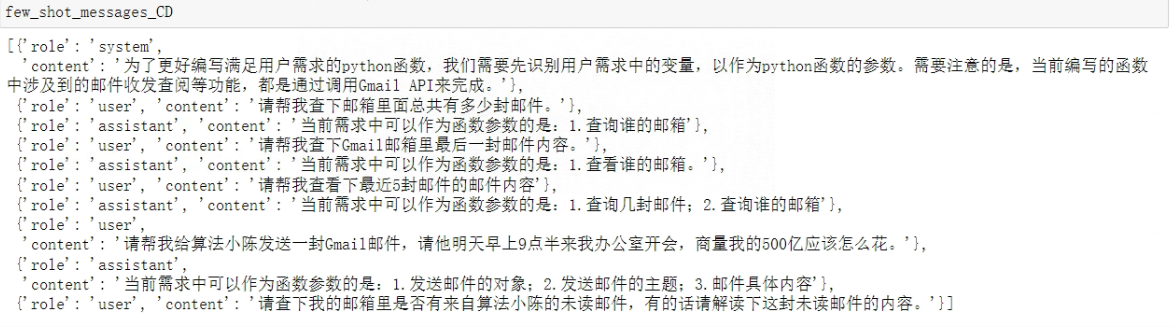
- Step 6:进行第一阶段的CD提示
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=few_shot_messages_CD
)
看下模型输出:

- Step 7:进行第一阶段的CM提示
new_req_CM_input = new_req_CD_input + new_req_pifew_shot_messages_CM.append({"role": "user", "content": new_req_CM_input})
few_shot_messages_CM
看下拼接好的Prompt:

输入模型:
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=few_shot_messages_CM
)
看一下模型返回结果:

- Step 8:进行第二阶段的提示
此阶段的提示为系统输入+ 函数描述及具体函数的Few-shot,引导大语言模型(LLMs)根据Prompt生成具体的函数,代码如下:
few_shot_messages.append({"role": "user", "content": new_req_description})response = openai.ChatCompletion.create(model="gpt-4-0613",messages=few_shot_messages
)
看下模型输出结果:

- Step 9:提取字符串,转化成函数
extract_function_code(new_req_function, detail=1, g=globals())
看下生成的函数:

- Step 10:测试code_generate一键生成函数
few_shot_functions = ['get_latest_email', 'send_email']req = "请查下我的邮箱里是否有来自算法小陈的未读邮件,有的话请解读下这封未读邮件的内容。"function_name = code_generate(req=req, few_shot=few_shot_functions)
其创建过程如下:


- Step 11:手动对生成的函数进行测试
functions_list = [check_unread_emails]messages = [{"role": "system", "content": "算法小陈的邮箱地址是:snowball6@qq.com "},{"role": "user", "content": req}]final_response = run_conversation(messages=messages, functions_list=functions_list, model="gpt-3.5-turbo-16k-0613")
基于这套流程,基本上实现了高效便捷的外部函数创建,可以基于code_generate尝试新增函数,示例如下:
few_shot_functions = ['get_latest_email', 'send_email']req = "请查下我的邮箱里第一封邮件,并告诉我第一封邮件的收件时间和邮件内容"function_name = code_generate(req=req, few_shot=few_shot_functions)functions_list = [get_first_email]messages = [{"role": "user", "content": req}]final_response = run_conversation(messages=messages, functions_list=functions_list, model="gpt-3.5-turbo-16k-0613")
final_response
五、总结
本文作为构建高度自动化AI项目开发流程的第二步优化,通过LtM提示流程,解决了根据用户需求,自动构建符合要求的函数,并通过示例一步一步的完整测试了code_generate函数功能。
总的来说,进展到这里整套流程已经基本固定并且符合高度的自动化,并且具有一定的通用性,但在实验测试中发现,gpt4.0接口相较于gpt3.5接口,其输出能力还是更为稳定,然而就算是目前最强的gpt4.0,在实际进行批量代码创建时还是会存在编写的代码不稳定的情况,这也是一个需要进一步思考如何解决的问题。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
相关文章:
大模型开发(十六):从0到1构建一个高度自动化的AI项目开发流程(中)
全文共1w余字,预计阅读时间约40~60分钟 | 满满干货(附代码),建议收藏! 本文目标:通过LtM提示流程实现自动构建符合要求的函数,并通过实验逐步完整测试code_generate函数功能。 代码下载点这里 一、介绍 此篇文章为…...
和常见的强化学习算法)
【深入了解pytorch】PyTorch强化学习:强化学习的基本概念、马尔可夫决策过程(MDP)和常见的强化学习算法
【深入了解pytorch】PyTorch强化学习:强化学习的基本概念、马尔可夫决策过程(MDP)和常见的强化学习算法 PyTorch强化学习:介绍强化学习的基本概念、马尔可夫决策过程(MDP)和常见的强化学习算法引言强化学习的基本概念状态(State)动作(Action)奖励(Reward)策略(Pol…...
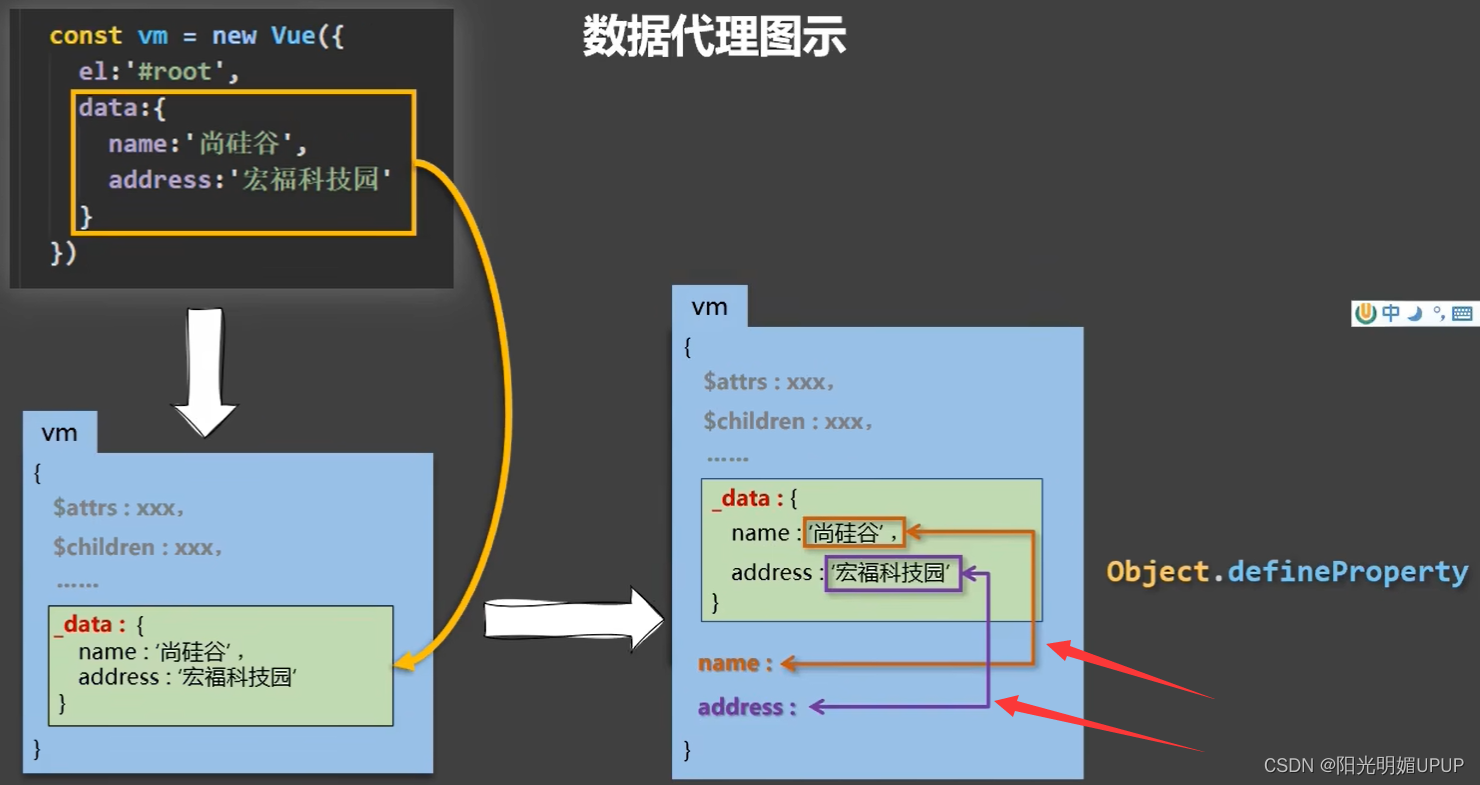
尚硅谷张天禹Vue2+Vue3笔记(待续)
简介 什么是Vue? 一套用于构建用户界面的渐进式JavaScript框架。将数据转变成用户可看到的界面。 什么是渐进式? Vue可以自底向上逐层的应用 简单应用:只需一个轻量小巧的核心库 复杂应用:可以引入各式各样的Vue插件 Vue的特点是什么? 1.采…...
深度学习(35)—— StarGAN(2)
深度学习(34)—— StarGAN(2) 完整项目在这里:欢迎造访 文章目录 深度学习(34)—— StarGAN(2)1. build model(1)generator(2&#…...

连续四年入选!三项荣耀!博云科技强势上榜Gartner ICT技术成熟度曲线
日,全球知名咨询公司Gartner发布了2023年度的《中国ICT技术成熟度曲线》(《Hype Cycle for ICT in China, 2023》,以下简称“报告”)。令人瞩目的是,博云科技在报告中荣获三项殊荣,入选云原生计算ÿ…...

Docker实战-操作Docker容器实战(一)
导语 在之前的分享中,我们介绍了关于如何去操作Docker镜像,下面我们来看看如何去操作容器。 简单来讲,容器是镜像运行的一个实例,与镜像不同的是镜像只能作为一个静态文件进行读取,而容器是可以在运行时进行写入操…...
c#设计模式-行为型模式 之 观察者模式
定义: 又被称为发布-订阅(Publish/Subscribe)模式,它定义了一种一对多的依赖关系,让多个观察者 对象同时监听某一个主题对象。这个主题对象在状态变化时,会通知所有的观察者对象,使他们能够自 …...
开窗积累之学习更新版
1. 开窗使用1之 count range between current row and current row 将相同排序字段的值进行函数计算 selectsku_id,substr(create_date,1,7) date_month,order_id,create_date,sku_num*price,sum(sku_num*price) over (partition by sku_id order by substr(create_date,1,7)…...
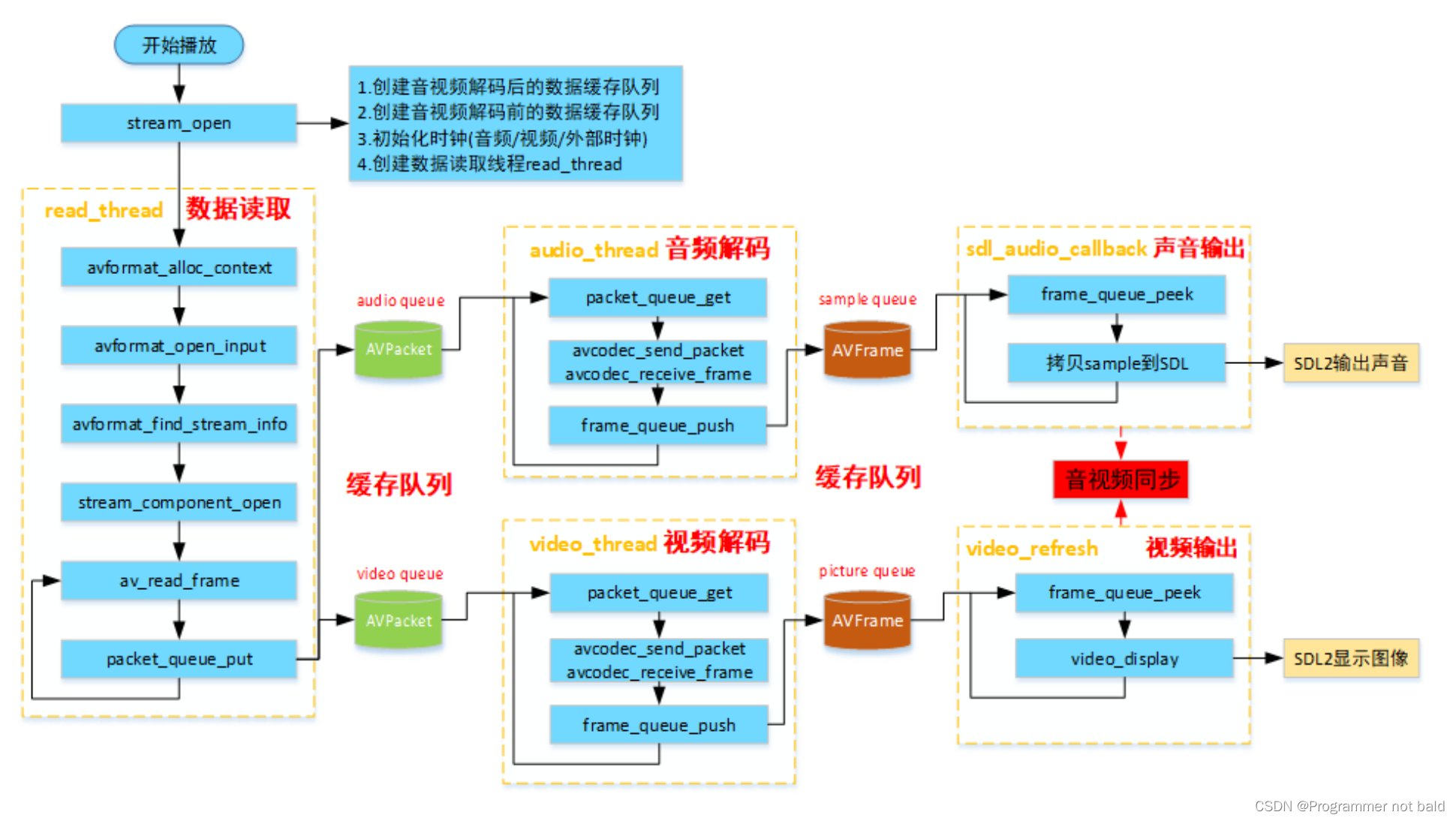
ffplay简介
本文为相关课程的学习记录,相关分析均来源于课程的讲解,主要学习音视频相关的操作,对字幕的处理不做分析 ffplay播放器的意义 ffplay.c是FFmpeg源码⾃带的播放器,调⽤FFmpeg和SDL API实现⼀个⾮常有⽤的播放器。 ffplay实现了播…...

mysql之limit语句详解
一、介绍 LIMIT是MySQL内置函数,其作用是用于限制查询结果的条数。 二、使用 1. 语法格式 LIMIT [位置偏移量,] 行数 其中,中括号里面的参数是可选参数,位置偏移量是指MySQL查询分析器要从哪一行开始显示,索引值从0开始ÿ…...

4.while循环
1、while语句的语法结构如下: while语句可以在条件表达式为真的前提下,循环执行指定的一段代码,直到表达式不为真时结束循环。 1.1while语法结构 while(条件表达式){// 循环体} 执行思路: 1、执行思路 当条件表达式结果为tru…...

【雕爷学编程】 MicroPython动手做(35)——体验小游戏2
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...

mouseover 和 mouseenter
mouseover 和 mouseenter 事件是 JavaScript 中常用的两个鼠标事件,它们有一些区别: 触发条件: mouseover 事件在鼠标指针从元素外部进入元素内部时触发,包括子元素。换句话说,只要鼠标进入元素或其子元素,就会触发 mo…...
[JavaScript游戏开发] 绘制Q版地图、键盘上下左右地图场景切换
系列文章目录 第一章 2D二维地图绘制、人物移动、障碍检测 第二章 跟随人物二维动态地图绘制、自动寻径、小地图显示(人物红点显示) 第三章 绘制冰宫宝藏地图、人物鼠标点击移动、障碍检测 第四章 绘制Q版地图、键盘上下左右地图场景切换 文章目录 系列文章目录前言一、本章节…...
CI/CD持续集成持续发布(jenkins)
1.背景 在实际开发中,我们经常要一边开发一边测试,当然这里说的测试并不是程序员对自己代码的单元测试,而是同组程序员将代码提交后,由测试人员测试; 或者前后端分离后,经常会修改接口,然后重新…...
Qt5.14.2+QtCreator+PDB 查看源码
1. 在Creator添加源码 2. 安装PDB文件 Qt下载时没有整合最新的PDB文件下载,如果没有安装PDB文件,即使安装了src也无法调试。 双击MaintenanceTool.exe->设置->资料档案库->临时资料档案库->添加按钮,添加如下下载源:…...

DOM基础获取元素+事件基础+操作元素
一.DOM简介 DOM,全称“Document Object Model(文档对象模型)”,它是由W3C定义的一个标准。 在实际开发中,我们有时候需要实现鼠标移到某个元素上面时就改变颜色,或者动态添加元素或者删除元素等。其实这些效…...

MATLAB——感知神经网络学习程序
学习目标:从学习第一个最简单的神经网络案例开启学习之路 感知器神经网络 用于点的分类 clear all; close all; P[0 0 1 1;0 1 0 1]; %输入向量 T[0 1 1 1]; %目标向量 netnewp(minmax(P),1,hardlim,lea…...
SpringBoot中事务失效的原因
SpringBoot中事务失效的原因 文章目录 SpringBoot中事务失效的原因一、事务方法非public修饰二、非事务方法调用事务方法三、事务方法的异常被捕获四、事务异常类型不对五、事务传播行为不对六、没有被Spring管理6.1、暴漏代理对象6.2、使用代理对象 常见的事务失效原因包括如下…...

Webstorm的一些常用快捷键
下面是Webstorm的一些常用快捷键: ctrl shift n: 打开工程中的文件,目的是打开当前工程下任意目录的文件。ctrl j: 输出模板ctrl b: 跳到变量申明处ctrl alt T: 围绕包裹代码(包括zencoding的Wrap with Abbreviation)ctrl []: 匹配 {}[]ctrl F1…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...