【工程实践】使用EDA(Easy Data Augmentation)做数据增强
工程项目中,由于数据量不够,经常需要用到数据增强技术,尝试使用EDA进行数据增强。
1.EDA简介
EDA是一种简单但是非常有效的文本数据增强方法,是由美国Protago实验室发表于 EMNLP-IJCNLP 2019 会议。EDA来自论文《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》
对于提高文本分类任务性能的简单数据增强技术,文中提出了四种数据增强技术方案,具体包括同义词替换,随机插入,随机交换,随机删除。并在深度学习模型RNN和CNN上用五个数据集做了文本分类实验的对比研究,实验中,作者根据数据集大小将训练集分为3种规模,用于比较EDA技术在训练数据集规模上的影响。实验也表明了,EDA提升了文本分类的效果。
2.增强方法
2-1. 同义词替换(Synonym Replacement, SR)
1.从文本中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们。
2.不考虑 stopwords,在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。关于同义词可以使用开源同义词表+领域自定义词表来建立。
注:需要借助synonyms库完成同义词的选择
def synonym_replacement(words, n):new_words = words.copy()random_word_list = list(set([word for word in words if word not in stop_words]))random.shuffle(random_word_list)num_replaced = 0for random_word in random_word_list:synonyms = get_synonyms(random_word)if len(synonyms) >= 1:synonym = random.choice(synonyms)new_words = [synonym if word == random_word else word for word in new_words]num_replaced += 1if num_replaced >= n:breaksentence = ' '.join(new_words)new_words = sentence.split(' ')return new_wordsdef get_synonyms(word):return synonyms.nearby(word)[0]2-2.随机插入(Random Insertion, RI)
从文本中随机选择一个不在停用词表中的词,从它的同义词词集中随机选择一个词,插入到句子中的随机位置,并将该步骤重复 n 次。
def random_insertion(words, n):new_words = words.copy()for _ in range(n):add_word(new_words)return new_wordsdef add_word(new_words):synonyms = []counter = 0while len(synonyms) < 1:random_word = new_words[random.randint(0, len(new_words) - 1)]synonyms = get_synonyms(random_word)counter += 1if counter >= 10:returnrandom_synonym = random.choice(synonyms)random_idx = random.randint(0, len(new_words) - 1)new_words.insert(random_idx, random_synonym)2-3.随机交换(Random Swap, RS)
句子中,随机选择两个词,位置交换。该过程可以重复n次。 (swap_word 函数中随机产生两个序列下标,如果相同最多重新生成三次。)
def random_swap(words, n):new_words = words.copy()for _ in range(n):new_words = swap_word(new_words)return new_wordsdef swap_word(new_words):random_idx_1 = random.randint(0, len(new_words) - 1)random_idx_2 = random_idx_1counter = 0while random_idx_2 == random_idx_1:random_idx_2 = random.randint(0, len(new_words) - 1)counter += 1if counter > 3:return new_wordsnew_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]return new_words
2-4.随机删除(Random Deletion, RD)
用概率 p 随机删除文本中的单词。如果句子中只有一个单词,则直接返回。如果句子中所有单词都被删掉,则随机返回一个单词。
def random_deletion(words, p):if len(words) == 1:return wordsnew_words = []for word in words:r = random.uniform(0, 1)if r > p:new_words.append(word)if len(new_words) == 0:rand_int = random.randint(0, len(words) - 1)return [words[rand_int]]return new_words3.问题总结
3-1.若句子中有多个单词被改变了,那么句子的原始标签类别是否还会有效?
为了验证通过EDA方法产生的数据是否原数据特征一致,作者在Pro-Con数据集上进行数据的对比分析。

具体方法:首先,使用RNN在一未使用EDA过的数据集上进行训练;然后,对测试集进行EDA扩增,每个原始句子扩增出9个增强的句子,将这些句子作为测试集输入到RNN中;最后,从最后一个全连接层取出输出向量。应用t-SNE技术,将这些向量以二维的形式表示出来。如下图所示。下图中大三角和大圆圈都是原来的句子,小三角和小圆圈表示使用EDA技术进行数据增强的句子,可以看出来绝大多数原数据和EDA增强数据保持一致,即没有发生语义偏移,故而文中提出的4种数据增强技术不会影响文本的原始标签。
3-2.对于EDA中的每个方法,单独提升的效果如何?
为了确定性能的提升到底是由四种数据增强方式中哪一种,或哪几种方式起到的作用,以及哪种方式起到的作用比较大,作者做了消融研究——分别单独使用其中一种数据增强方式进行实验研究。并得到如下实验结果。

上图中,参数α表示四种数据增强方式里被改变的单词数量占原文本长度的比例,实验中取α={0.05,0.1,0.2,0.3,0.4,0.5}。
对于同义词替换(SR),当α较小时,实验性能提升明显,但是α变大时性能有所下降,可能是因为替换过多单词时改变了原文本的含义;
对于随机插入(RI),α在上述范围内的取值使得实验性能保持相对稳定,可能是因为随机插入的方法使得原文本中的单词顺序保持相对稳定;
对于随机交换(RS),当α≤0.2时实验性能提升明显,当α≥0.3时性能有所下降,因为过多的单词位置交换打乱了原文本的整体顺序,改变了文本含义;
对于随机删除(RD),当α较小时能够使得实验性能达到最高,但是α变大时能严重降低实验性能,因为删除过多单词时,句子难以理解,是的文本丢失语义信息。
消融实验得出的结论是,对于每个方法在小数据集上取得的效果更明显。 α如果太大的话,甚至会降低模型表现效果, α=0.1似乎是最佳值。
3-3.如何选取合适的增强语句个数?
在较小的数据集上,模型容易过拟合,因此生成多一点的语料能取得较好的效果。对于较大的数据集,每句话生成超过4个句子对于模型的效果提升就没有太大帮助。因此,作者推荐实际使用中的一些参数选取如下表所示。

naug :每个原始语句的增强语句个数;Ntrain :训练集大小
3-4.EDA提高文本分类的效果的原理是什么?
1.生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合;
2.使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词;
4. EDA数据增强代码实现
4-1 说明
代码实现中是需要jieba分词,停用词表(默认使用哈工大停用词表),以及一个提供同义词的包(Synonyms)。
4-2 代码实现
import pandas as pd
import json
from tqdm import tqdm# !/usr/bin/env python
# -*- coding: utf-8 -*-
import jieba
import re
import random
from random import shuffle
random.seed(2019)
import synonyms
# 停用词列表,默认使用哈工大停用词表
f = open('/home/zhenhengdong/WORk/Classfier/Dates/stopWord.json', encoding='utf-8')
stop_words = list()
for stop_word in f.readlines():stop_words.append(stop_word[:-1])
# 文本清理
import re
def get_only_chars(line):#1.清除所有的数字########################################################################
# 同义词替换
# 替换一个语句中的n个单词为其同义词
########################################################################def synonym_replacement(words, n):new_words = words.copy()random_word_list = list(set([word for word in words if word not in stop_words]))random.shuffle(random_word_list)num_replaced = 0for random_word in random_word_list:synonyms = get_synonyms(random_word)if len(synonyms) >= 1:synonym = random.choice(synonyms)new_words = [synonym if word == random_word else word for word in new_words]num_replaced += 1if num_replaced >= n:breaksentence = ' '.join(new_words)new_words = sentence.split(' ')return new_wordsdef get_synonyms(word):return synonyms.nearby(word)[0]########################################################################
# 随机插入
# 随机在语句中插入n个词
########################################################################
def random_insertion(words, n):new_words = words.copy()for _ in range(n):add_word(new_words)return new_wordsdef add_word(new_words):synonyms = []counter = 0while len(synonyms) < 1:random_word = new_words[random.randint(0, len(new_words) - 1)]synonyms = get_synonyms(random_word)counter += 1if counter >= 10:returnrandom_synonym = random.choice(synonyms)random_idx = random.randint(0, len(new_words) - 1)new_words.insert(random_idx, random_synonym)########################################################################
# Random swap
# Randomly swap two words in the sentence n times
########################################################################def random_swap(words, n):new_words = words.copy()for _ in range(n):new_words = swap_word(new_words)return new_wordsdef swap_word(new_words):random_idx_1 = random.randint(0, len(new_words) - 1)random_idx_2 = random_idx_1counter = 0while random_idx_2 == random_idx_1:random_idx_2 = random.randint(0, len(new_words) - 1)counter += 1if counter > 3:return new_wordsnew_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]return new_words########################################################################
# 随机删除
# 以概率p删除语句中的词
########################################################################
def random_deletion(words, p):if len(words) == 1:return wordsnew_words = []for word in words:r = random.uniform(0, 1)if r > p:new_words.append(word)if len(new_words) == 0:rand_int = random.randint(0, len(words) - 1)return [words[rand_int]]return new_words########################################################################
# EDA函数
def eda_func(sentence, alpha_sr = 0.35, alpha_ri = 0.35, alpha_rs = 0.35, p_rd = 0.35, num_aug = 12):seg_list = jieba.cut(sentence)seg_list = " ".join(seg_list)words = list(seg_list.split())num_words = len(words)augmented_sentences = []num_new_per_technique = int(num_aug / 4)n_sr = max(1, int(alpha_sr * num_words))n_ri = max(1, int(alpha_ri * num_words))n_rs = max(1, int(alpha_rs * num_words))# print(words, "\n")# 同义词替换srfor _ in range(num_new_per_technique):a_words = synonym_replacement(words, n_sr)augmented_sentences.append(''.join(a_words))# 随机插入rifor _ in range(num_new_per_technique):a_words = random_insertion(words, n_ri)augmented_sentences.append(''.join(a_words))## 随机交换rsfor _ in range(num_new_per_technique):a_words = random_swap(words, n_rs)augmented_sentences.append(''.join(a_words))### 随机删除rdfor _ in range(num_new_per_technique):a_words = random_deletion(words, p_rd)augmented_sentences.append(''.join(a_words))# print(augmented_sentences)shuffle(augmented_sentences)if num_aug >= 1:augmented_sentences = augmented_sentences[:num_aug]else:keep_prob = num_aug / len(augmented_sentences)augmented_sentences = [s for s in augmented_sentences if random.uniform(0, 1) < keep_prob]# augmented_sentences.append(seg_list)def Data_Augmentation(item,num):augmented_sentence_dataframe = pd.DataFrame()for join_class in tqdm(stations_dict[item]):for index in range(len(new_data)):if new_data.loc[index].联合分类 == join_class:augmented_sentences = eda_func(sentence = new_data.loc[index]['内容'])[:num]for augmented_sentence in augmented_sentences:creat_new_data = pd.DataFrame()creat_new_data['内容'] = [augmented_sentence]creat_new_data['反馈类型'] = [new_data.loc[index]['反馈类型']]creat_new_data['一级分类'] = [new_data.loc[index]['一级分类']]creat_new_data['二级分类'] = [new_data.loc[index]['二级分类']]creat_new_data['联合分类'] = [new_data.loc[index]['联合分类']]augmented_sentence_dataframe = pd.concat([augmented_sentence_dataframe, creat_new_data], ignore_index=True)print(len(augmented_sentence_dataframe)) return augmented_sentence_dataframeif __name__ == '__main__':new_data = pd.read_csv('./Temp_data.csv')stations_dict = {}for index,key_values in enumerate(new_data.联合分类.value_counts().items()):if 1500 > key_values[1] > 1000:stations_dict.setdefault('1000', []).append(key_values[0])if 1000 > key_values[1] > 800:stations_dict.setdefault('800', []).append(key_values[0])if 800 > key_values[1] > 600:stations_dict.setdefault('600', []).append(key_values[0])if 600 > key_values[1] > 500:stations_dict.setdefault('500', []).append(key_values[0])if 500 > key_values[1] > 400:stations_dict.setdefault('400', []).append(key_values[0])if 400 > key_values[1] > 300:stations_dict.setdefault('300', []).append(key_values[0])if 300 > key_values[1] > 0:stations_dict.setdefault('0', []).append(key_values[0])Temp_data = pd.DataFrame()for item in stations_dict:if item == '1000':#13642augmented_sentence_dataframe = Data_Augmentation(item,num = 2)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '800':#16503augmented_sentence_dataframe = Data_Augmentation(item,num = 3)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '600':#23684augmented_sentence_dataframe = Data_Augmentation(item,num = 4)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '500':#15186augmented_sentence_dataframe = Data_Augmentation(item,num = 6)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '400':#20400augmented_sentence_dataframe = Data_Augmentation(item,num = 8)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '300':#7137augmented_sentence_dataframe = Data_Augmentation(item,num = 9)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)if item == '0':#3897augmented_sentence_dataframe = Data_Augmentation(item,num = 9)Temp_data = pd.concat([Temp_data, augmented_sentence_dataframe], ignore_index=True)#将合并的data存储Temp_data.to_csv('./Temp_data_single_sample.csv',index = False,encoding='utf8')Reference:
1.https://www.zhihu.com/question/341361292/answer/2916784123
2.NLP中的数据增强:UDA、EDA_eda数据增强_快乐小码农的博客-CSDN博客
相关文章:
【工程实践】使用EDA(Easy Data Augmentation)做数据增强
工程项目中,由于数据量不够,经常需要用到数据增强技术,尝试使用EDA进行数据增强。 1.EDA简介 EDA是一种简单但是非常有效的文本数据增强方法,是由美国Protago实验室发表于 EMNLP-IJCNLP 2019 会议。EDA来自论文《EDA: Easy Data…...

ClickHouse(十三):Clickhouse MergeTree系列表引擎 - ReplicingMergeTree
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

机器学习笔记之优化算法(十)梯度下降法铺垫:总体介绍
机器学习笔记之优化算法——梯度下降法铺垫:总体介绍 引言回顾:线搜索方法线搜索方法的方向 P k \mathcal P_k Pk线搜索方法的步长 α k \alpha_k αk 梯度下降方法整体介绍 引言 从本节开始,将介绍梯度下降法 ( Gradient Descent,GD ) …...

Selenium 根据元素文本内容定位
使用xpath定位元素时,有时候担心元素位置会变,可以考虑使用文本内容来定位的方式。 例如图中的【股市】按钮,只有按钮文本没变,即使位置变化也可以定位到该元素。 xpath内容样例: # 文本内容完全匹配 //button[text(…...

第17章-Spring AOP经典应用场景
文章目录 一、日志处理二、事务控制三、参数校验四、自定义注解五、AOP 方法失效问题1. ApplicationContext2. AopContext3. 注入自身 六、附录1. 示例代码 AOP 提供了一种面向切面操作的扩展机制,通常这些操作是与业务无关的,在实际应用中,可…...

Leetcode周赛 | 2023-8-6
2023-8-6 题1体会我的代码 题2我的超时代码题目体会我的代码 题3体会我的代码 题1 体会 这道题完全就是唬人,只要想明白了,只要有两个连续的数的和,大于target,那么一定可以,两边一次切一个就好了。 我的代码 题2 我…...

ts中interface自定义结构约束和对类的约束
一、interface自定义结构约束对后端接口返回数据 // interface自定义结构 一般用于较复杂的结构数据类型限制 如后端返回的接口数据// 首字母大写;用分割号隔开 interface Iobj{a:number;b:string } let obj:Iobj {a:1,b:2 }// 复杂类型 模拟后端返回的接口数据 interface Il…...

Oracle单实例升级补丁
目录 1.当前DB环境2.下载补丁包和opatch的升级包3.检查OPatch的版本4.检查补丁是否冲突5.关闭数据库实例,关闭监听6.应用patch7.加载变化的SQL到数据库8.ORACLE升级补丁查询 oracle19.3升级补丁到19.18 1.当前DB环境 [oraclelocalhost ~]$ cat /etc/redhat-releas…...

力扣初级算法(二分查找)
力扣初级算法(二分法): 每日一算法:二分法查找 学习内容: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 2.二分查找流程&…...

探索未来:直播实时美颜SDK在增强现实(AR)直播中的前景
在AR直播中,观众可以与虚拟元素实时互动,为用户带来更加丰富、沉浸式的体验。那么,直播美颜SDK在AR中有哪些应用呢?下文小编将于大家一同探讨美颜SDK与AR有哪些关联。 一、AR直播与直播实时美颜SDK的结合 增强现实技术在直播中…...

SQL 单行子查询 、多行子查询、单行函数、聚合函数 IN 、ANY 、SOME 、ALL
单行子查询 子查询结果是 一个列一行记录 select a,b,c from table where a >(select avg(xx) from table ) 还支持这种写法,这种比较少见 select a,b,c from table where (a ,b)(select xx,xxx from table where col‘000’ )…...
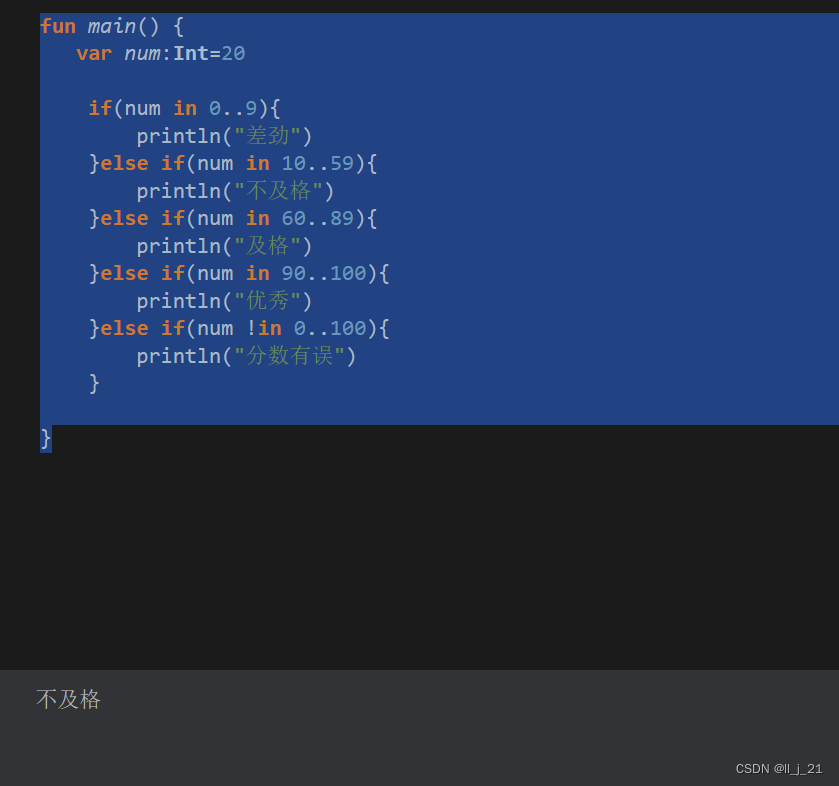
【第一阶段】kotlin的range表达式
range:范围:从哪里到哪里的意思 in:表示在 !in:表示不在 … :表示range表达式 代码示例: fun main() {var num:Int20if(num in 0..9){println("差劲")}else if(num in 10..59){println("不及格")}else if(num in 60..89…...
)
网络防御(5)
一、结合以下问题对当天内容进行总结 1. 什么是恶意软件? 2. 恶意软件有哪些特征? 3. 恶意软件的可分为那几类? 4. 恶意软件的免杀技术有哪些? 5. 反病毒技术有哪些? 6. 反病毒网关的工作原理是什么? 7. 反…...

gradle 命令行单元测试执行问题
文章目录 问题:命令行 执行失败最终解决方案(1)ADB命令(2)Java 环境配置 问题:命令行 执行失败 命令行 执行测试命令 无法使用(之前还能用的。没有任何改动,又不能用了) …...

剑指Offer12.矩阵中的路径 C++
1、题目描述 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平…...

金鸣识别将无表格线的图片转为excel的几个常用方案
我们知道,金鸣识别要将横竖线齐全的表格图片转为excel非常简单,但要是表格线不齐全甚至没有表格线的图片呢?这就没那么容易了,在识别这类图片时,我们一般会使用以下的一种或多种方法进行处理: 1. 基于布局…...

刚刚更新win11,记事本消失怎么处理?你需要注意些什么?
记录window11的bug hello,我是小索奇 昨天索奇从window10更新到了window11,由于版本不兼容卸载了虚拟机,这是第一个令脑壳大的,算了,还是更新吧,了解了解win11的生态,后期重新装虚拟机 第一个可…...

【QT】 QTabWidgetQTabBar控件样式设计(QSS)
很高兴在雪易的CSDN遇见你 ,给你糖糖 欢迎大家加入雪易社区-CSDN社区云 前言 本文分享QT控件QTabWidget&QTabBar的样式设计,介绍两者可以自定义的内容,以及如何定义,希望对各位小伙伴有所帮助! 感谢各位小伙伴…...

【个人记录】CentOS7 编译安装最新版本Git
说明 使用yum install git安装的git版本是1.8,并不是最新版本,使用gitlab-runner托管时候会拉项目失败,这里使用编译源码方式安装最新版本的git。 基础环境安装 echo "nameserver 8.8.8.8" >> /etc/resolv.conf curl -o /…...

【Linux】计算机网络的背景和协议分层
文章目录 网络发展协议何为协议网络协议协议分层OSI七层模型TCP/IP五层模型(四层) 基本通信流程mac地址和ip地址网络通信本质 网络发展 从一开始计算机作为一台台单机使用,到现在网络飞速发展,从局域网Lan建立起局域网࿰…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...