Flink之SideOutput(数据分流)
Flink在早期版本有一个split算子用来做数据分流使用的,但是在flink-1.12开始这个API就已经被删除了,在1.12版本以后我们是通过process算子来做数据分流的,这里就介绍一下如何使用prodess进行数据分流.
- 代码
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;/*** @Author: J* @Version: 1.0* @CreateTime: 2023/8/7* @Description: 测流输出**/
public class FlinkSideOutput {public static void main(String[] args) throws Exception {// 构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(3);// 这里使用的是自定义数据源为了方便测试,具体数据源根据自己的实际情况进行更换DataStreamSource<CustomizeBean> customizeSourceStream = env.addSource(new CustomizeSource());/*** 需求* 1. 将性别为M且爱好为'羽毛球运动爱好者'分到一个流* 2. 将性别为W且爱好为'篮球运动爱好者'或'钓鱼爱好者'分到一个流* 3. 其他保留到主流**/SingleOutputStreamOperator<CustomizeBean> processedStream = customizeSourceStream.process(new ProcessFunction<CustomizeBean, CustomizeBean>() {@Overridepublic void processElement(CustomizeBean value, ProcessFunction<CustomizeBean, CustomizeBean>.Context ctx, Collector<CustomizeBean> out) throws Exception {String gender = value.getGender(); // 性别String hobbit = value.getHobbit(); // 爱好if (gender.equals("M") && hobbit.equals("羽毛球运动爱好者")) {// 将性别为M且爱好为'羽毛球运动爱好者'进行分流, 注意这里要声明类型,Java无法自行推断ctx.output(new OutputTag<CustomizeBean>("M-羽毛球", TypeInformation.of(CustomizeBean.class)), value);} else if (gender.equals("W") && (hobbit.equals("篮球运动爱好者") || hobbit.equals("钓鱼爱好者"))) {// 将性别为W且爱好为'篮球运动爱好者'或'钓鱼爱好者'进行分流, 注意这里要声明类型,Java无法自行推断ctx.output(new OutputTag<CustomizeBean>("W-篮球/钓鱼", TypeInformation.of(CustomizeBean.class)), value);} else {// 将剩下的数据保留在主流中out.collect(value);}}});// 获取'M-羽毛球'分流数据,这里也要加上类型声明DataStream<CustomizeBean> mSideOutput = processedStream.getSideOutput(new OutputTag<CustomizeBean>("M-羽毛球", TypeInformation.of(CustomizeBean.class)));// 打印'M-羽毛球'结果mSideOutput.print("M-羽毛球");// 获取'W-篮球/钓鱼'分流数据,这里也要加上类型声明DataStream<CustomizeBean> wSideOutput = processedStream.getSideOutput(new OutputTag<CustomizeBean>("W-篮球/钓鱼", TypeInformation.of(CustomizeBean.class)));// 打印结果wSideOutput.print("W-篮球/钓鱼");// 主流数据打印结果processedStream.print("主数据流");env.execute("Side Output");}
}
- 结果数据
主数据流:2> CustomizeBean(name=AAA-641, age=44, gender=W, hobbit=非遗文化爱好者)
主数据流:3> CustomizeBean(name=AAA-17, age=62, gender=M, hobbit=书法爱好者)
主数据流:1> CustomizeBean(name=AAA-429, age=25, gender=W, hobbit=非遗文化爱好者)
主数据流:2> CustomizeBean(name=AAA-218, age=33, gender=M, hobbit=旅游爱好者)
主数据流:3> CustomizeBean(name=AAA-826, age=39, gender=M, hobbit=篮球运动爱好者)
主数据流:1> CustomizeBean(name=AAA-190, age=31, gender=M, hobbit=旅游爱好者)
主数据流:2> CustomizeBean(name=AAA-266, age=32, gender=W, hobbit=网吧战神)
主数据流:3> CustomizeBean(name=AAA-106, age=70, gender=M, hobbit=书法爱好者)
主数据流:1> CustomizeBean(name=AAA-911, age=50, gender=M, hobbit=网吧战神)
M-羽毛球:2> CustomizeBean(name=AAA-925, age=65, gender=M, hobbit=羽毛球运动爱好者)
主数据流:3> CustomizeBean(name=AAA-20, age=59, gender=M, hobbit=书法爱好者)
主数据流:1> CustomizeBean(name=AAA-409, age=79, gender=W, hobbit=天文知识爱好者)
主数据流:2> CustomizeBean(name=AAA-865, age=58, gender=W, hobbit=天文知识爱好者)
主数据流:3> CustomizeBean(name=AAA-898, age=33, gender=M, hobbit=天文知识爱好者)
主数据流:1> CustomizeBean(name=AAA-85, age=38, gender=W, hobbit=非遗文化爱好者)
主数据流:2> CustomizeBean(name=AAA-883, age=51, gender=M, hobbit=美食爱好者)
主数据流:3> CustomizeBean(name=AAA-243, age=37, gender=M, hobbit=钓鱼爱好者)
主数据流:1> CustomizeBean(name=AAA-430, age=28, gender=W, hobbit=旅游爱好者)
主数据流:2> CustomizeBean(name=AAA-127, age=65, gender=W, hobbit=网吧战神)
W-篮球/钓鱼:3> CustomizeBean(name=AAA-986, age=52, gender=W, hobbit=钓鱼爱好者)
主数据流:1> CustomizeBean(name=AAA-840, age=50, gender=W, hobbit=旅游爱好者)
M-羽毛球:2> CustomizeBean(name=AAA-196, age=34, gender=M, hobbit=羽毛球运动爱好者)
主数据流:3> CustomizeBean(name=AAA-142, age=46, gender=W, hobbit=乒乓球运动爱好者)
主数据流:1> CustomizeBean(name=AAA-985, age=78, gender=W, hobbit=美食爱好者)
W-篮球/钓鱼:2> CustomizeBean(name=AAA-490, age=50, gender=W, hobbit=钓鱼爱好者)
主数据流:3> CustomizeBean(name=AAA-295, age=77, gender=M, hobbit=篮球运动爱好者)
主数据流:1> CustomizeBean(name=AAA-754, age=50, gender=M, hobbit=天文知识爱好者)
主数据流:2> CustomizeBean(name=AAA-249, age=35, gender=W, hobbit=羽毛球运动爱好者)
W-篮球/钓鱼:3> CustomizeBean(name=AAA-908, age=27, gender=W, hobbit=钓鱼爱好者)
主数据流:1> CustomizeBean(name=AAA-674, age=73, gender=M, hobbit=非遗文化爱好者)
通过结果内容可以看到数据完全按照我们分流的逻辑进行输出的,如果想在主数据流中讲所有数据保留下来,Collector<Object> out单独拎出来即可,也就是不加到判断逻辑中,代码如下,这里就只展示部分代码了
SingleOutputStreamOperator<CustomizeBean> processedStream = customizeSourceStream.process(new ProcessFunction<CustomizeBean, CustomizeBean>() {@Overridepublic void processElement(CustomizeBean value, ProcessFunction<CustomizeBean, CustomizeBean>.Context ctx, Collector<CustomizeBean> out) throws Exception {String gender = value.getGender(); // 性别String hobbit = value.getHobbit(); // 爱好// 将所有数据保留在主流中out.collect(value);// 开始进行分流处理if (gender.equals("M") && hobbit.equals("羽毛球运动爱好者")) {// 将性别为M且爱好为'羽毛球运动爱好者'进行分流, 注意这里要声明类型,Java无法自行推断ctx.output(new OutputTag<CustomizeBean>("M-羽毛球", TypeInformation.of(CustomizeBean.class)), value);} else if ((gender.equals("W") && (hobbit.equals("篮球运动爱好者")) || (gender.equals("W") && hobbit.equals("钓鱼爱好者")))) {// 将性别为W且爱好为'篮球运动爱好者'或'钓鱼爱好者'进行分流, 注意这里要声明类型,Java无法自行推断ctx.output(new OutputTag<CustomizeBean>("W-篮球/钓鱼", TypeInformation.of(CustomizeBean.class)), value);}}});
所有的内容到这里就结束了.
相关文章:
)
Flink之SideOutput(数据分流)
Flink在早期版本有一个split算子用来做数据分流使用的,但是在flink-1.12开始这个API就已经被删除了,在1.12版本以后我们是通过process算子来做数据分流的,这里就介绍一下如何使用prodess进行数据分流. 代码 import org.apache.flink.api.common.typeinfo.TypeInformation; im…...
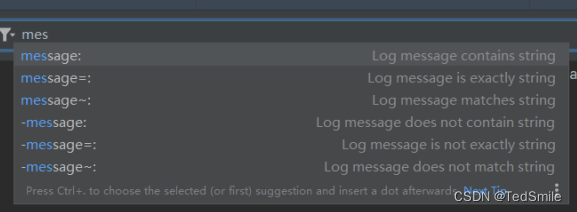
Android Studio新版本logcat过滤说明
按包名过滤 //输入package:(输入一个p就会有提示的) ,后面加上包名 比如: package:com.xal.runcontrol package:包名可以完整或者输部分包名即可 package:包名需要输完整准确 package~:正则表达式过滤 不了解正则表达式的可以参考&#…...

carsim与matlab仿真
matlab2021a安装教程,亲测。 百度网盘: matlab2021a安装包 提取码:1223 CarSim2020安装教程, 亲测。 百度网盘: CarSim2020安装包 提取码:1223 ,破解可参考 b站视频...

rust里如何快速实现一个LRU 本地缓存?
LRU是Least Recently Used(最近最少使用)的缩写,是一种常见的缓存淘汰算法。LRU算法的基本思想是,当缓存空间已满时,优先淘汰最近最少使用的数据,以保留最常用的数据。 在计算机系统中,LRU算法…...
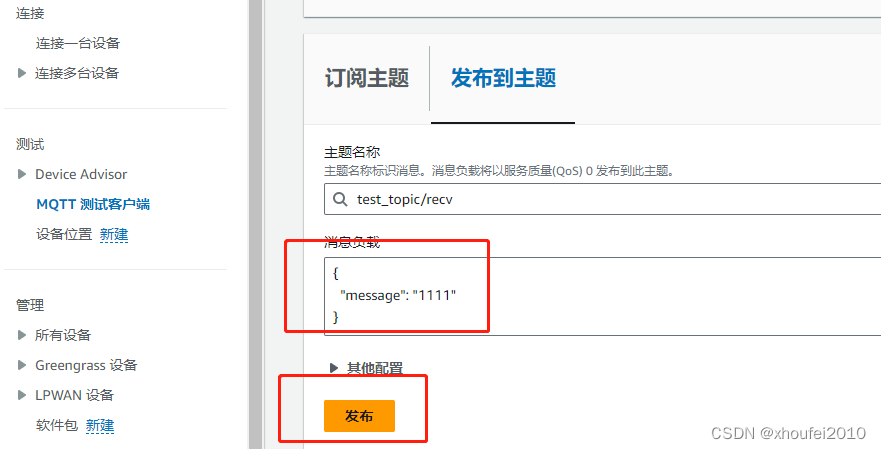
MQTT 订阅接收消息 mosquitto 方式
1 说明 采用 mosquitto 库,实现订阅主题,并接收消息。其中服务器有做限制,需要对应的 cilent id ,cafile 、certfile 、keyfile 等配置2 环境 采用ubuntu 直接编译调试 安装mosquitto 库 sudo apt install libmosquitto-dev su…...
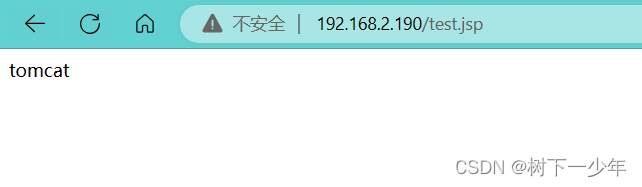
以mod_jk方式整合apache与tomcat(动静分离)
前言: 为什么要整合apache和tomcat apache对静态页面的处理能力强,而tomcat对静态页面的处理不如apache,整合后有以下好处 提升对静态文件的处理性能 利用 Web 服务器来做负载均衡以及容错 更完善地去升级应用程序 jk整合方式介绍&#…...

springboot动态数据源切换
1)、就是将多个数据源全部注入到bean中,根据需要实现多数据源之间的切换。 2)、使用baomidou的DS注解。见文章DS注解实现数据源动态切换 com.baomidou dynamic-datasource-spring-boot-starter 3.5.1 ##设置默认的数据源或者数据源组,默认值…...

代码随想录训练营day14
101. 对称二叉树 给你一个二叉树的根节点 root , 检查它是否轴对称。 func isSymmetric(root *TreeNode) bool {if root nil{ return true}return judge(root.Left,root.Right) }func judge(lf *TreeNode , ri *TreeNode)bool{if lf nil && ri nil{ retu…...

功能测试进阶自动化测试如何摸清学习方向,少走弯路呢?
目录 抛开疑问,只做学术探讨 小白在想什么? 盖楼之前先打好地基,首先需要学习一门语言 语言入门后,正式踏上开始自动化成神之路,入门篇Selenium 玩腻了Selenium 开始接触自动化框架unittest/testNG 不满足于单元…...

检测前端是否可以ping通后端返回的ip地址
检测前端是否可以ping通后端返回的ip地址 前端检测是否可ping通ip地址(PC端)前端检测是否可ping通ip地址(uniapp小程序端) 前端检测是否可ping通ip地址(PC端) // 前端检测是否可ping通ip地址 ping…...

SMART司马他法则(目标管理)
S代表具体(Specific),指绩效考核要切中特定的工作指标,不能笼统; M代表可度量(Measurable),指绩效指标是数量化或者行为化的,验证这些绩效指标的数据或者信息是可以获得的; A代表可实现(Attainable)&…...
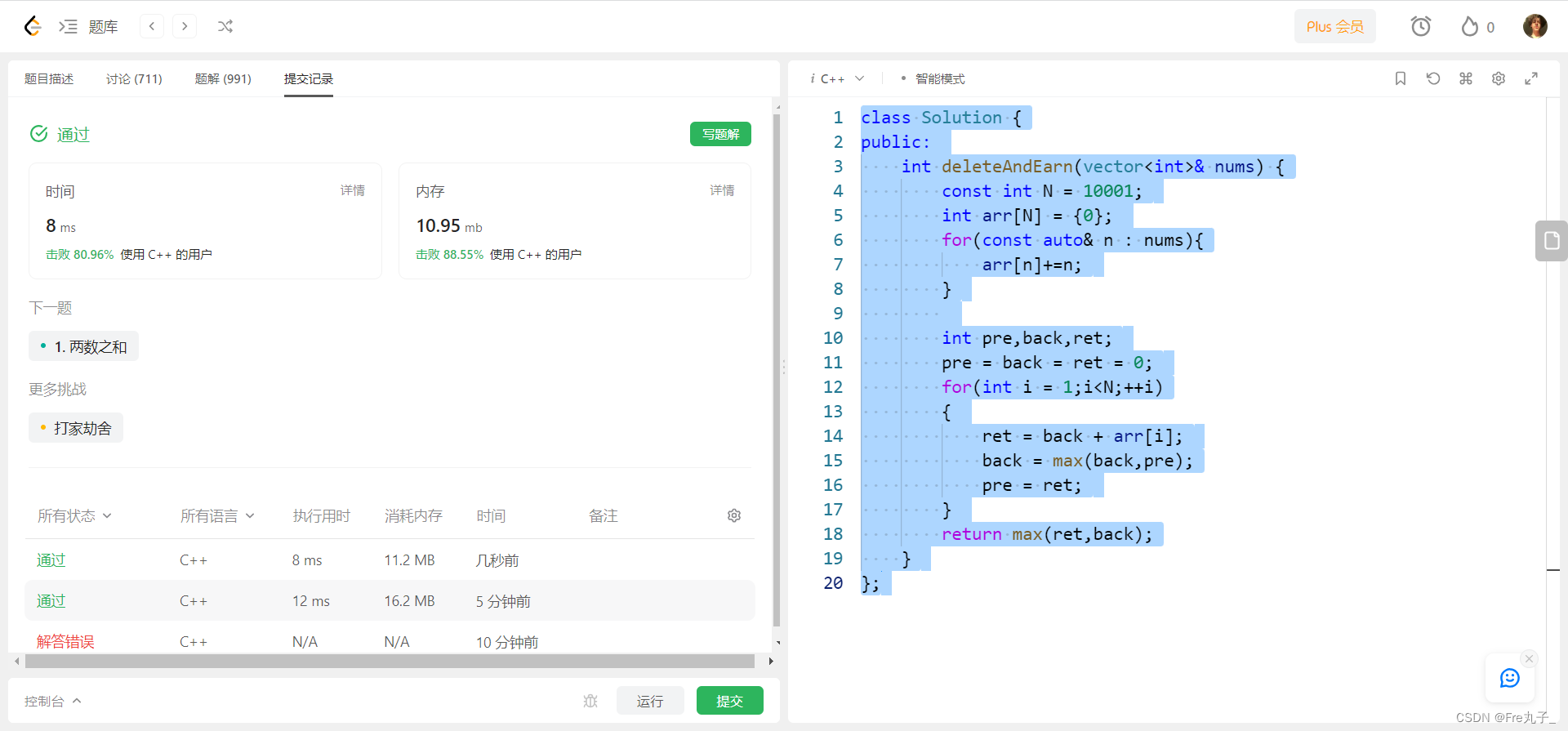
【LeetCode】删除并获得点数
删除并获得点数 题目描述算法分析编程代码空间优化 链接: 删除并获得点数 题目描述 算法分析 编程代码 class Solution { public:int deleteAndEarn(vector<int>& nums) {const int N 10001;int arr[N] {0};for(const auto& n : nums){arr[n]n;}vector<in…...

SciencePub学术 | 传感器类重点SCIE征稿中
SciencePub学术 刊源推荐: 传感器类重点SCIE征稿中!信息如下,录满为止: 一、期刊概况: 传感器类重点SCIE 【期刊简介】IF:2.0-2.5,JCR3区,中科院4区; 【版面类型】正刊࿱…...

移动端开发基础总结
移动端学习总结 (适合于复习) 移动端基础 技术选型: 单独制作移动端页面(主流) 流式布局(百分比布局)flex弹性布局(强烈推荐)lessrem媒体查询布局混合布局 响应式页面兼容移动端(…...
)
小X学游泳(深搜)
第一题 题目描述 小X想要学游泳。 这天,小X来到了游泳池,发现游泳池可以用N行M列的格子来表示,每个格子的面积都是1,且格子内水深相同。 由于小X刚刚入门,他只能在水深相同的地方游泳。为此,他把整个游泳池…...

分布式协议与算法——拜占庭将军问题
拜占庭将军问题 背景:以战国时期为背景 战国时期,齐、楚、燕、韩、赵、魏、秦七雄并立,后来秦国的势力不断强大起来,成了东方六国的共同威胁。于是,这六个国家决定联合,全力抗秦,免得被秦国各个…...

MySQL数据库管理的基本原则和技巧
MySQL数据库是一种常用的关系型数据库管理系统,用于存储和管理大量的数据。在进行MySQL数据库管理时,有一些基本原则和技巧可以帮助我们更有效地管理数据库。 数据库设计原则: 合理规划数据表结构: 根据数据之间的关系和业务需求…...
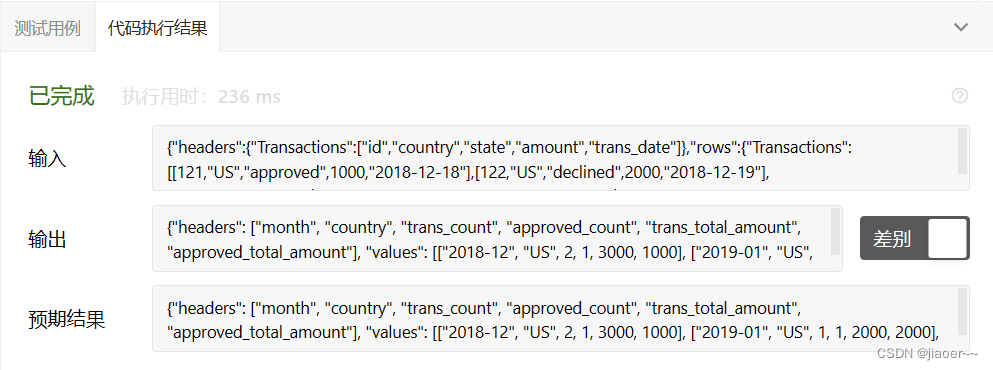
SQL-每日一题【1193. 每月交易 I】
题目 Table: Transactions 编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。 以 任意顺序 返回结果表。 查询结果格式如下所示。 示例 1: 解题思路 1.题目要求我们查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数…...

探析青少年口才训练在个人发展中的重要性与影响
论文题目:探析青少年口才训练在个人发展中的重要性与影响 摘要: 本论文旨在探讨青少年口才训练对个人发展的重要性和影响。通过对相关文献的综述和实证研究的分析,论文将阐述口才训练对青少年自信心、表达能力和思维能力的提升,以…...

HTML 元素的 class 和 id 属性有何区别?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 唯一性⭐ 选择器权重⭐ JS操作⭐ CSS和JavaScript引用⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...