使用自己的数据集预加载 Elasticsearch
作者:David Pilato

我最近在讨论论坛上收到一个问题,关于如何修改官方 Docker 镜像以提供一个现成的 Elasticsearch 集群,其中已经包含一些数据。
说实话,我不喜欢这个想法,因为你必须通过提 entrypoint.sh 的分叉版本来破解 Elasticsearch 服务的启动方式。 这将使你的维护和升级变得更加困难。
相反,我发现使用其他解决方案来实现相同的目标会更好。
设置问题
首先,我们将考虑使用 Elasticsearch Docker 镜像并遵循文档:
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.7.0
docker network create elastic
docker run --name es01 --net elastic -p 9200:9200 -it docker.elastic.co/elasticsearch/elasticsearch:8.7.0请注意,我们没有在此处挂载 data 目录,因此该集群的数据将是短暂的,并且一旦节点关闭就会消失。 启动后,我们可以使用生成的密码检查它是否运行良好:
curl -s -k -u elastic:CHANGEME https://localhost:9200 | jq请使用在安装时候显示的 Elasticsearch 密码来替换上面的 CHANGEME。上面的命令给出:
{"name": "697bf734a5d5","cluster_name": "docker-cluster","cluster_uuid": "cMISiT__RSWkoKDYql1g4g","version": {"number": "8.7.0","build_flavor": "default","build_type": "docker","build_hash": "09520b59b6bc1057340b55750186466ea715e30e","build_date": "2023-03-27T16:31:09.816451435Z","build_snapshot": false,"lucene_version": "9.5.0","minimum_wire_compatibility_version": "7.17.0","minimum_index_compatibility_version": "7.0.0"},"tagline": "You Know, for Search"
}因此,我们希望有一个可用的数据集。 让我们采用我在演示 Elasticsearch 时经常使用的示例数据集:人员数据集。 我创建了[一个生成器](https://github.com/dadoonet/injector) 来创建一些假数据。
首先,让我们下载注入器:
wget https://repo1.maven.org/maven2/fr/pilato/elasticsearch/injector/injector/8.7/injector-8.7.jar然后我们将使用以下选项在磁盘上生成数据集:
mkdir data
java -jar injector-8.7.jar --console --silent > data/persons.json我们有 1000000 个 json 文档,数据集如下所示:
head -2 data/persons.json{"name":"Charlene Mickael","dateofbirth":"2000-11-01","gender":"female","children":3,"marketing":{"cars":1236,"shoes":null,"toys":null,"fashion":null,"music":null,"garden":null,"electronic":null,"hifi":1775,"food":null},"address":{"country":"Italy","zipcode":"80100","city":"Ischia","countrycode":"IT","location":{"lon":13.935138341699972,"lat":40.71842684204817}}}
{"name":"Kim Hania","dateofbirth":"1998-05-18","gender":"male","children":4,"marketing":{"cars":null,"shoes":null,"toys":132,"fashion":null,"music":null,"garden":null,"electronic":null,"hifi":null,"food":null},"address":{"country":"Germany","zipcode":"9998","city":"Berlin","countrycode":"DE","location":{"lon":13.164834451298645,"lat":52.604673827377155}}}使用 shell 脚本
我们这里有 100 万个文档,因此我们无法真正使用批量请求来发送它。 我们需要:
- 分成 10000 个或更少的索引操作
- 对于每个文档,添加缺少的 bulk 标题
- 使用 _bulk API 发送文档 我最终编写了这个脚本,它要求你安装了 curl 和 jq:
#!/bin/bash
ELASTIC_PASSWORD=CHANGEME
mkdir tmp
echo "Split the source in 10000 items"
split -d -l10000 ../data/persons.json tmp/part
BULK_REQUEST_FILE="tmp/bulk_request.ndjson"
FILES="tmp/part*"
for f in $FILES
dorm $BULK_REQUEST_FILEecho "Preparing $f file..."while read p; doecho -e '{"index":{}}' >> $BULK_REQUEST_FILEecho -e "$p" >> $BULK_REQUEST_FILEdone <$fecho "Calling Elasticsearch Bulk API"curl -XPOST -s -k -u elastic:$ELASTIC_PASSWORD https://localhost:9200/person/_bulk -H 'Content-Type: application/json' --data-binary "@$BULK_REQUEST_FILE" | jq '"Bulk executed in \(.took) ms with errors=\(.errors)"'
done有关脚本输入文档的方法,你也可以参考文章 “Elasticsearch:如何使用 shell 脚本来写入数据到 Elasticsearch 中”。
这基本上打印:
Preparing tmp/part00 file...
Calling Elasticsearch Bulk API
"Bulk executed in 1673 ms with errors=false"
Preparing tmp/part01 file...
Calling Elasticsearch Bulk API
"Bulk executed in 712 ms with errors=false"
...
Preparing tmp/part99 file...
Calling Elasticsearch Bulk API
"Bulk executed in 366 ms with errors=false"在我的机器上,运行它需要 8 分钟多。 大部分时间都花在编写批量请求上。 可能还有很大的改进空间,但我必须承认我不太擅长编写 shell 脚本。 哈? 你已经猜到了吗? 😅
使用logstash
Logstash 可以完成与我们手动完成的类似工作,但还提供更多功能,例如错误处理、监控,我们甚至不需要编写代码... 我们将在这里再次使用 Docker:
docker pull docker.elastic.co/logstash/logstash:8.7.0让我们为此编写一个作业:
input {file {path => "/usr/share/logstash/persons/persons.json"mode => "read"codec => json { }exit_after_read => true}
}filter {mutate {remove_field => [ "log", "@timestamp", "event", "@version" ]}
}output {elasticsearch {hosts => "${ELASTICSEARCH_URL}"index => "person"user => "elastic"password => "${ELASTIC_PASSWORD}"ssl_certificate_verification => false}
}我们现在可以运行该作业:
docker run --rm -it --name ls01 --net elastic \-v $(pwd)/../data/:/usr/share/logstash/persons/:ro \-v $(pwd)/pipeline/:/usr/share/logstash/pipeline/:ro \-e XPACK_MONITORING_ENABLED=false \-e ELASTICSEARCH_URL="https://es01:9200" \-e ELASTIC_PASSWORD="CHANGEME" \docker.elastic.co/logstash/logstash:8.7.0在我的机器上,运行它只需要不到 2 分钟。
使用 docker 撰写
你可以更轻松地使用 docker compose 命令来根据需要运行所有内容,并向用户公开一个可供使用的集群,而不是手动运行所有这些内容。 这是一个简单的 .env 文件:
ELASTIC_PASSWORD=CHANGEME
STACK_VERSION=8.7.0
ES_PORT=9200以及 docker-compose.yml:
version: "2.2"
services:es01:image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}ports:- ${ES_PORT}:9200environment:- node.name=es01- cluster.initial_master_nodes=es01- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}- bootstrap.memory_lock=trueulimits:memlock:soft: -1hard: -1healthcheck:test:["CMD-SHELL","curl -s -k https://localhost:9200 | grep -q 'missing authentication credentials'",]interval: 10stimeout: 10sretries: 120logstash:depends_on:es01:condition: service_healthyimage: docker.elastic.co/logstash/logstash:${STACK_VERSION}volumes:- type: bindsource: ../datatarget: /usr/share/logstash/personsread_only: true- type: bindsource: pipelinetarget: /usr/share/logstash/pipelineread_only: trueenvironment:- ELASTICSEARCH_URL=https://es01:9200- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}- XPACK_MONITORING_ENABLED=false我们仍然在 ../data 目录中保存有 person.json 文件。 它被安装为 /usr/share/logstash/persons/persons.json ,就像在前面的示例中一样。 因此,我们使用与之前相同的 pipeline/persons.conf 文件。 要运行它,我们现在只需输入:
docker compose up并等待 with-compose-logstash-1 容器退出:
with-compose-logstash-1 | [2023-04-21T15:17:55,335][INFO ][logstash.runner ] Logstash shut down.
with-compose-logstash-1 exited with code 0这表明我们的服务现在已准备好运行并完全加载了我们的示例数据集。
有关这个部分的内容,更多阅读请参考:数据集成的强大联盟:Elasticsearch、Kibana、Logstash、MySQL。
使用快照/恢复
你还可以使用创建快照 API 将 Elasticsearch 中的现有数据集备份到共享文件系统或 S3,然后使用 Restore Restore API 将其恢复到新集群。 假设你已经注册了一个名为 example 的存储库。 你可以使用以下命令创建快照:
# We force merge the segments first
POST /person/_forcemerge?max_num_segments=1# Snapshot the data
PUT /_snapshot/sample/persons
{"indices": "person","include_global_state": false
}因此,无论何时启动新集群,你都可以使用以下命令恢复快照:
POST /_snapshot/sample/persons/_restore你只需要小心使用此方法,当你将其升级到新的主要版本时,你拥有的快照仍然可以在集群中恢复。 例如,如果你使用版本 6.3 创建了快照,则无法在 8.2 中还原它。 有关更多详细信息,请参阅快照索引兼容性。 但好消息! 借助存档索引,Elasticsearch 现在能够访问较旧的快照存储库(返回到版本 5)... 你只需要了解一些限制即可。 为了保证你的快照始终完全兼容,你可能需要使用相同的脚本使用最新版本再次创建索引快照。 请注意,在这种情况下,Force Merger API 调用很重要,因为它将使用最新的 Elasticsearch/Lucene 版本重写所有段。
使用已挂载的目录
还记得我们启动集群时的情况吗?
docker run --name es01 --net elastic -p 9200:9200 -it docker.elastic.co/elasticsearch/elasticsearch:8.7.0我们没有绑定挂载 data 和 config 目录。 但实际上我们可以这样做:
docker run --name es01 --net elastic -p 9200:9200 -it -v persons-data:/usr/share/elasticsearch/data -v persons-config:/usr/share/elasticsearch/config docker.elastic.co/elasticsearch/elasticsearch:8.7.0我们可以检查刚刚创建的 Docker volume:
docker volume inspect persons-data persons-config
[{"CreatedAt": "2023-05-09T10:20:14Z","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/persons-data/_data","Name": "persons-data","Options": null,"Scope": "local"},{"CreatedAt": "2023-05-09T10:19:51Z","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/persons-config/_data","Name": "persons-config","Options": null,"Scope": "local"}
]如果你想使用完全相同的命令行再次启动 Elasticsearch 节点,你可以稍后再次重用此挂载点。 如果需要与其他用户共享卷,可以将 /var/lib/docker/volumes/persons-config/ 和 /var/lib/docker/volumes/persons-data/ 中的数据备份到 /tmp/volume-backup:
然后你可以与其他用户共享 /tmp/volume-backup/persons.tgz 文件并让他们恢复它。
docker volume create persons-config
docker volume create persons-data
docker run --rm -it -v /tmp/volume-backup:/backup -v /var/lib/docker:/docker alpine:edge tar xfz /backup/persons.tgz -C /并再次启动容器:
docker run --name es01 --net elastic -p 9200:9200 -it -v persons-data:/usr/share/elasticsearch/data -v persons-config:/usr/share/elasticsearch/config docker.elastic.co/elasticsearch/elasticsearch:8.7.0使用 Elastic Cloud
当然,你可以使用之前创建的快照来配置新的 Elasticsearch Cloud 实例,而不是自行启动和管理本地 Elasticsearch 实例。 以下代码假设你已经定义了 API key。
POST /api/v1/deployments?validate_only=false
{"resources": {"elasticsearch": [{"region": "gcp-europe-west1","plan": {"cluster_topology": [{"zone_count": 2,"elasticsearch": {"node_attributes": {"data": "hot"}},"instance_configuration_id": "gcp.es.datahot.n2.68x10x45","node_roles": ["master","ingest","transform","data_hot","remote_cluster_client","data_content"],"id": "hot_content","size": {"resource": "memory","value": 8192}}],"elasticsearch": {"version": "8.7.1"},"deployment_template": {"id": "gcp-storage-optimized-v5"},"transient": {"restore_snapshot": {"snapshot_name": "__latest_success__","source_cluster_id": "CLUSTER_ID"}}},"ref_id": "main-elasticsearch"}],"kibana": [{"elasticsearch_cluster_ref_id": "main-elasticsearch","region": "gcp-europe-west1","plan": {"cluster_topology": [{"instance_configuration_id": "gcp.kibana.n2.68x32x45","zone_count": 1,"size": {"resource": "memory","value": 1024}}],"kibana": {"version": "8.7.1"}},"ref_id": "main-kibana"}]},"settings": {"autoscaling_enabled": false},"name": "persons","metadata": {"system_owned": false}
}只需将 CLUSTER_ID 替换为从中获取快照的源集群即可。 集群启动后,你就拥有了一个功能齐全的实例,可以在互联网上使用你想要的默认数据集。 完成后,你可以使用以下命令轻松关闭部署:
POST /api/v1/deployments/DEPLOYMENT_ID/_shutdown同样,只需将 DEPLOYMENT_ID 替换为你在创建部署时看到的部署 ID。
结论
与往常一样,对于 Elastic,特别是 Elasticsearch,你有多种方法可以实现你的目标。 我在这里列出了其中一些,但可能还有其他一些方法:
- 使用 Shell 脚本:你实际上不需要任何第三方工具,但这需要编写一些代码。 代码看起来很简单,只要偶尔运行一下就可以了。 如果你需要它更安全,例如具有捕获和重试功能,那么这将使你创建和维护更多代码。
- 使用 Logstash:它非常灵活,因为你还可以将数据发送到 Elasticsearch 之外的其他目的地,或者使用多个过滤器来修改/丰富源数据集。 启动速度有点慢,但出于测试目的,这不应该成为真正的问题。
- 使用 docker compose:我最喜欢的方法之一。 你只需运行 docker compose up 等,几分钟后就完成了。 但这可能需要时间和硬件资源。
- 使用快照/恢复:比以前的方法更快,因为数据已经建立索引。 但灵活性较差,因为快照需要与你要恢复到的集群兼容。 一般来说,我总是更喜欢再次注入数据,因为一切都是新鲜的,并且我可以从 Elasticsearch 和 Lucene 的所有改进中受益。
- 使用挂载目录:类似于快照,但更本地化。 老实说,我更喜欢使用 Elastic API,而不是手动挂载现有目录。 让 Elasticsearch 做它知道的事情让我感觉更安全。
- 使用 Elastic Cloud:我认为这是与其他人(例如客户或内部测试人员)共享数据集的最简单方法。 一切都已准备就绪,安全,可以通过适当的 SSL 证书使用。
根据你的品味和限制,你可以选择其中一种想法并根据你的需求进行调整。 如果你有其他好主意要分享,请在 Twitter 上告诉我们或讨论区。 许多很棒的想法/功能都来自社区。 分享你的!
原文:Preload Elasticsearch with your dataset | Elastic Blog
相关文章:
使用自己的数据集预加载 Elasticsearch
作者:David Pilato 我最近在讨论论坛上收到一个问题,关于如何修改官方 Docker 镜像以提供一个现成的 Elasticsearch 集群,其中已经包含一些数据。 说实话,我不喜欢这个想法,因为你必须通过提 entrypoint.sh 的分叉版本…...

机器视觉赛道持续火热,深眸科技坚持工业AI视觉切入更多应用领域
随着深度学习等算法的突破、算力的不断提升以及海量数据的持续积累,人工智能逐渐从学术界向工业界落地。而机器视觉作为人工智能领域中一个正在快速发展的分支,广泛应用于工业制造的识别、检测、测量、定位等场景,相较于人眼,在精…...
MyBatis操作数据库常见用法总结2
文章目录 1.动态SQL使用什么是动态sql为什么用动态sql标签拼接标签拼接标签拼接标签拼接标签拼接 补充1:resultType和resultMap补充2:后端开发中单元测试工具使用(Junit框架) 1.动态SQL使用 以insert标签为例 什么是动态sql 是…...
基于SpringBoot+LayUI的宿舍管理系统 001
项目简介 源码来源于网络,项目文档仅用于参考,请自行二次完善哦。 系统以MySQL 8.0.23为数据库,在Spring Boot SpringMVC MyBatis Layui框架下基于B/S架构设计开发而成。 系统中的用户分为三类,分别为学生、宿管、后勤。这三…...
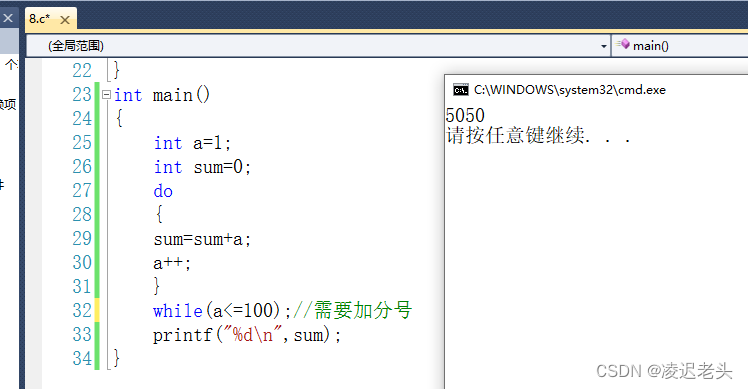
C语言笔记7
#include <stdio.h> int main(void) {int a123;int b052;//十进制42int c0xa2;//十进制162printf("a%d b%o c%x \n",a,b,c);//分别是十进制 八进制 十六进制printf("a%d b%d c%d \n",a,b,c);printf("Hello 凌迟老头\n");return …...

Centos更换网卡名称为eth0
Centos更换网卡名称为eth0 已安装好系统后需要修改网卡名称为eth0 编辑配置文件将ens33信息替换为eth0,可在vim命令模式输入%s/ens33/eth0/g替换相关内容 修改内核文件,添加内容:net.ifnames=0 biosdevname=0 [root@nova3 ~]# vim /etc/default/grub 使用命令重新生成g…...

【Express.js】软件测试
软件测试 本节介绍如何在 express.js 使用 Jest 进行单元测试 准备工作 准备一个基础的 express 项目,本文基于 evp-express-cli安装 Jest npm install jest --save-dev生成 Jest 配置 npx jest --init编写测试 创建测试文件,以 .test.js 后缀命名…...

TCP三次握手、四次握手过程,以及原因分析
TCP的三次握手和四次挥手实质就是TCP通信的连接和断开。 三次握手:为了对每次发送的数据量进行跟踪与协商,确保数据段的发送和接收同步,根据所接收到的数据量而确认数据发送、接收完毕后何时撤消联系,并建立虚连接。 四次挥手&…...

OceanBase X Flink 基于原生分布式数据库构建实时计算解决方案
摘要:本文整理自 OceanBase 架构师周跃跃,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分: 分布式数据库 OceanBase 关键技术解读 生态对接以及典型应用场景 OceanBase X Flink 在游戏行业实践 未来展望 点击…...

600V EasyPIM™ IGBT模块FB30R06W1E3、FB20R06W1E3B11、FB20R06W1E3降低了系统成本和损耗,可满足高能效要求。
EasyPIM™ IGBT模块是一种三相输入整流器PIM IGBT模块,采用TRENCHSTOP™ IGBT7、发射器控制7二极管和NTC/PressFIT技术。该模块具有增强的dv/dt可控性、改进的FWD软度、优化的开关损耗以及8μs短路稳定性。EasyPIM(功率集成模块)外形非常小巧…...
form 表单恢复初始数据
写表单的时候,想做到,某个操作时,表单恢复初始数据 this.$options.data().form form 是表单的对象 <template><div><el-dialog title"提示" :visible.sync"dialogVisible"><el-form :model"…...

MySQL—索引
这里写目录标题 索引是什么? 索引优缺点?MySQL索引类型索引底层实现? 为什么使用B树, 而不是B树, BST, AVL, 红黑树等等?什么是聚簇索引和非聚簇索引?非聚簇索引一定会回表吗?什么是联合索引?为什么需要注意联合索引中的字段顺序?什么是最左前缀原则?什么是前缀索引?…...

Android图形-合成与显示-概论
目录 引言 概念与理解 SurfaceFlinger Surface HWC Fence: Gralloc: DisplayDevice 引言 Activity是Android的主要UI相关组件。通过View的相关类和接口实现,在WMS的管理下,进行窗口和控件的测量,布局和绘制&am…...

Swift 5 数组如何获取集合的索引和对应的元素值
Swift 5 数组如何获取集合的索引和对应的元素值 在Swift 5中,你可以使用enumerated()方法来获取集合的索引和对应的元素值。这个方法会返回一个包含索引和元素的元组数组。以下是使用enumerated()方法来获取一个数组的索引和元素的示例: let array [1…...

计算 Nginx 日志的PV和UV
计算 Nginx 日志的 PV(页面浏览量)和 UV(独立访客数),你需要使用一些工具和技术。 PV(页面浏览量)是指网站的所有页面被访问的总次数,而 UV(独立访客数)则是指…...

Spring中常用的注解
1.声明Bean的注解(标注在类上) Component:表示普通的组件,也可泛指下面三种组件。Controller:控制层。Service:业务逻辑层。Repository:数据访问层。 2.Bean的生命周期的注解 Scope表示设置Spring是如何创建Bean的…...

Plugin 插件
Plugin 插件 插件是 webpack 的支柱功能。插件目的在于解决 loader 无法实现的其他事。Webpack 提供很多开箱即用的插件。 常用插件 clean-webpack-plugin 自动清理输出目录 html-webpack-plugin 自动生成使用 bundle.js 的 HTML copy-webpack-plugin 拷贝文件到输出目…...

Structure needs cleaning fsimage文件系统损坏修复
最近清除数据的时候发现有些文件无法rm [rootnode101 application_1691504014432_0002]# rm -rf ls:* [rootnode101 application_1691504014432_0002]# ls ls: 无法访问flink-dist-cache-8f72398e-9254-42d4-a14d-a0def99b493d: Structure needs cleaning以下操作可能会删除文件…...
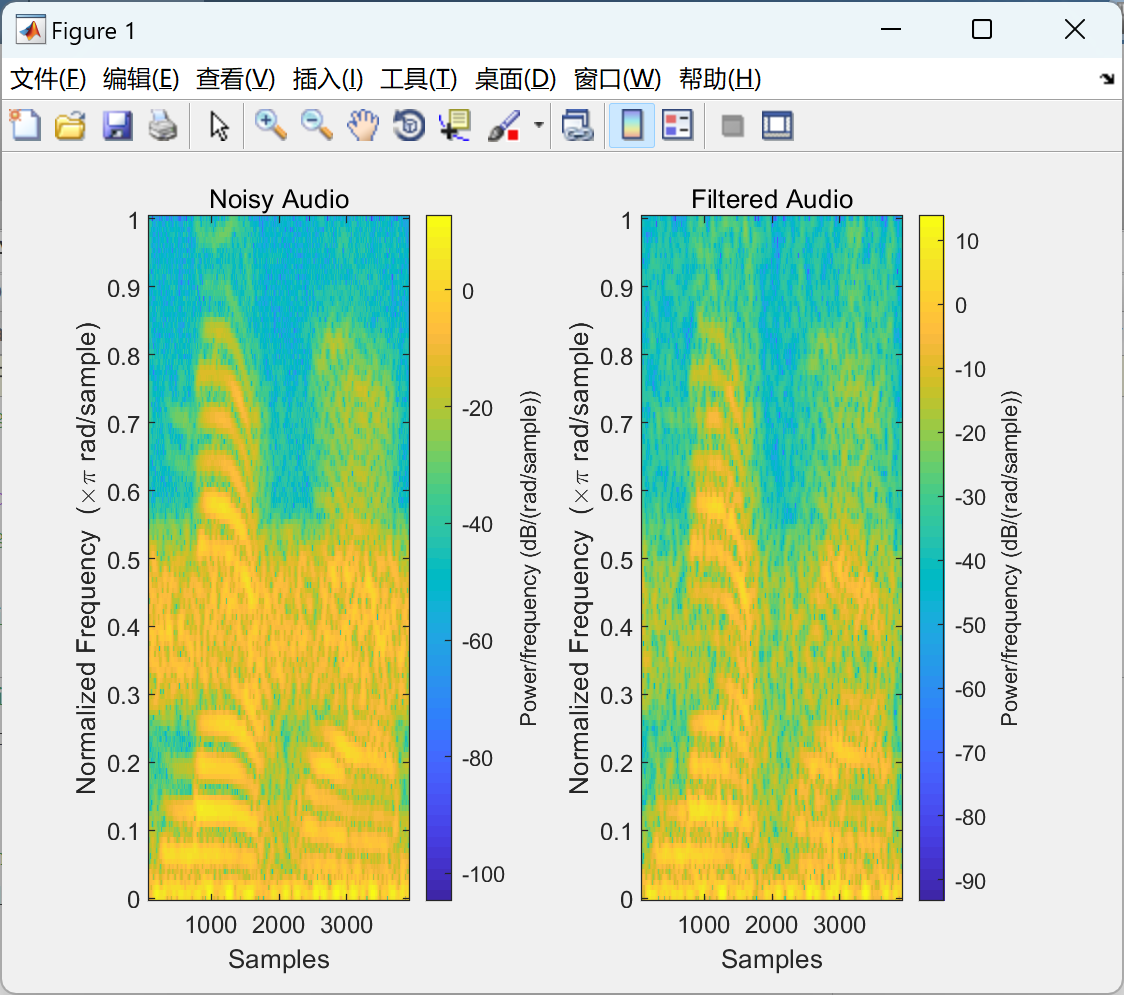
MATLAB|信号处理的Simulink搭建与研究
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
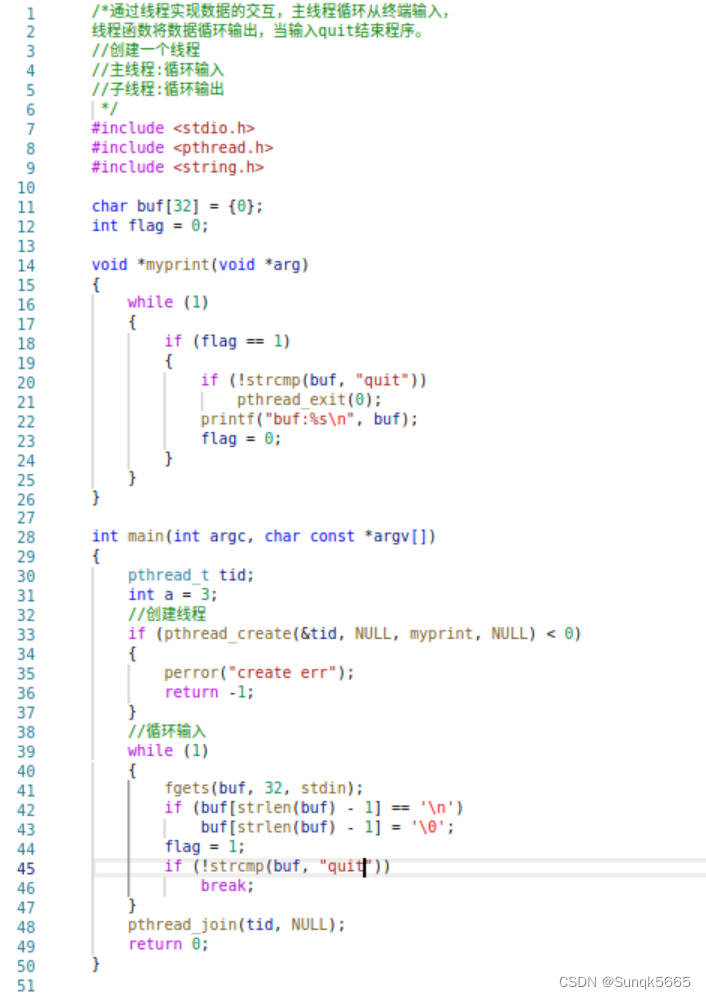
LinuxC编程——线程
目录 一、概念二、进程与线程的区别⭐⭐⭐三、线程资源四、函数接口4.1 线程创建4.2 线程退出4.3 线程回收4.3.1 阻塞回收4.3.2 非阻塞回收 4.4 pthread_create之传参4.5 练习 一、概念 是一个轻量级的进程,为了提高系统的性能引入线程。 进程与线程都参与cpu的统一…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...