【Java集合类】ArrayList
内部结构
- ArrayList内部核心是一个Object数组elementData
- Object数组的长度(length)视为ArrayList当前的容量(capacity)
- size对象表示ArrayList当前的元素个数
类上的重要注释
内部是Object数组
允许put null值,会自动扩容
size、isEmpty、get、set、add 等方法时间复杂度都是 O (1);
多个线程操作一个ArrayList实例,如果有改变结构的操作,就一定要在外部进行线程同步,推荐的做法:List list = Collections.synchronizedList(new ArrayList(...))
增强for循环,或者使用迭代器迭代过程中,如果数组大小被改变,会快速失败,抛出异常。
如何初始化一个有元素的ArrayList
- 普通方式:
ArrayList<String> list = new ArrayList<>();
list.add("1");
list.add("2");
- 内部类方式:
ArrayList<String> list = new ArrayList<>(){add("aaa");add("bbb");
}
- Arrays.asList
ArrayList<String> list = new ArrayList<>(Arrays.asList("aaa", "bbb");
- Collections.ncopies
例子:初始化一个由10个0组成的集合
ArrayList<Integer> list = new ArrayList<>(Collections.nCopies(10, 0));
重要源码
构造
ArrayList有三种构造方法
public ArrayList();//elementData初始化一个空数组
public ArrayList(int initialCapacity) //this.elementData = new Object[initialCapacity]
public ArrayList(Collection<? extends E> c)
这里主要关注new ArrayList()和new ArrayList(0)的区别,两者都是初始化一个空数组,但是:
无参构造得到的ArrayList,容量一开始是0,初次add时会直接扩容到10(重新申请一个length为10的数组,并且拷贝过来)
但new ArrayList(0)得到ArrayList,按照扩容核心方法grow()中的写法,从0开始增长容量,前期容量增长的会很慢(0->1->2->3->4->6->9->13)
一般情况下为了避免扩容造成的造成的损耗,new ArrayList(0)不推荐使用
add 尾部添加
//要点:添加前会确认容量,防止数组越界public boolean add(E e) {ensureCapacityInternal(size + 1);elementData[size++] = e;return true;
}//扩容
//1.先确认是否需要扩容,当期望容量(size(元素数)+1)超过当前容量了,就需要扩容
//2.一般期望容量都是size+1,除了无参构造的空数组第一次扩容时,期望容量是10
private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious codeif (minCapacity - elementData.length > 0) //所需的最小容量超过当前容量了,就需要扩容grow(minCapacity);
}private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //无参构造,默认初始化容量为10return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;
}//扩容本质是按照新容量创建一个新数组,然后把老数组数据用Arrays.copyOf复制过去
//新容量的计算规则//1.一般是原容量的3/2,用old+old>>1实现//2.3/2可能都不够(比如0*3/2),直接扩容成期望容量(其实就是+1)//3.3/2超过最大容量了 Integer.MAX_VALUE - 8,看看期望容量和Integer.MAX_VALUE - 8哪个更适合
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1); //3/2if (newCapacity - minCapacity < 0) //比如0的3/2倍还是0,直接扩容到1就好了newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0) //newCapacity超大了,就不能用3/2规则了,看看minCapacitynewCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity); //浅拷贝
}private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;
}
指定位置插入
从逻辑上看指定位置插入是四步:
- 查看index是否越界
- 容量检查,不够扩容
- 数据迁移:将插入位置之后的所有元素拷贝到+1的位置
- element插入到指定位置
注意这个方法上面的注释
- rangeCheck,越界的标准是看size而不是capacity:
- 对于ArrayList来说,内部数组的长度就是capacity也就是容量,当前数组的元素个数是size,这两个数据并不见得相等(比如无参构造生成的ArrayList,size可能为1,capacity为10)
- 但从使用者的角度来看,ArrayList就是个动态增长的list,使用者感知不到容量、扩容,使用者看起来这个ArrayList的末尾就是size
- 调用add只能在数据中间插入或者在数据末尾(下标为size的位置)插入,否则即使插入的下标没有超过capacity,但是超过了size,也算越界。
- 删除,同理,也会有rangeCheck
- 固定位置的插入删除,每次都会涉及大量的数据迁移,在拥有大量数据的ArrayList中不建议这么做
public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index + 1,size - index);elementData[index] = element;size++;
}
指定位置删除
可类比上个方法
public E remove(int index) {
//溢出校验rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)
//被删除元素后边元素前移System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null;// clear to let GC do its work//返回被删除元素return oldValue;}
按元素删除
方法注释:
- 新增的时候是没有对 null 进行校验的,所以删除的时候也是允许删除 null 值的;
- 找到值在数组中的索引位置,是通过 equals 来判断的,如果数组元素不是基本类型,需要我们关注 equals 的具体实现。
public boolean remove(Object o) {if (o == null) {for (int index = 0; index < size; index++)if (elementData[index] == null) {fastRemove(index);return true;}} else {for (int index = 0; index < size; index++)
//注意判断相同的方式if (o.equals(elementData[index])) {fastRemove(index);return true;}}return false;}private void fastRemove(int index) {modCount++;int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null;// clear to let GC do its work}
重点:迭代器
迭代器模式简介
我们遍历一个一维的集合时,经常会使用for循环或者foreach循环
for (String item : list) {System.out.println(item);
}
如果我们要遍历一个二维的图,简单的for循环就做不到了,这时我们可能会采用DFS或者BFS之类的办法,相信大家刷算法的时候都写过。
这时就会存在以下问题,同时也引出迭代器模式:
- 我肯定不想每次遍历时都把DFS的代码重新在客户端代码里写一遍,这意味着客户端代码需要关心数据结构的具体实现,一旦数据结构的具体实现变了(比如邻接矩阵变成邻接表了),或者遍历方法变了(DFS变成BFS了),就需要把客户端代码的遍历代码全都修改一遍
- 如果将这部分遍历的逻辑封装到到容器类中,也会导致容器类代码的复杂性。
因此,我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历,容器类和迭代器之间用组合方式关联。
并且,容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器类,也更符合开闭原则。
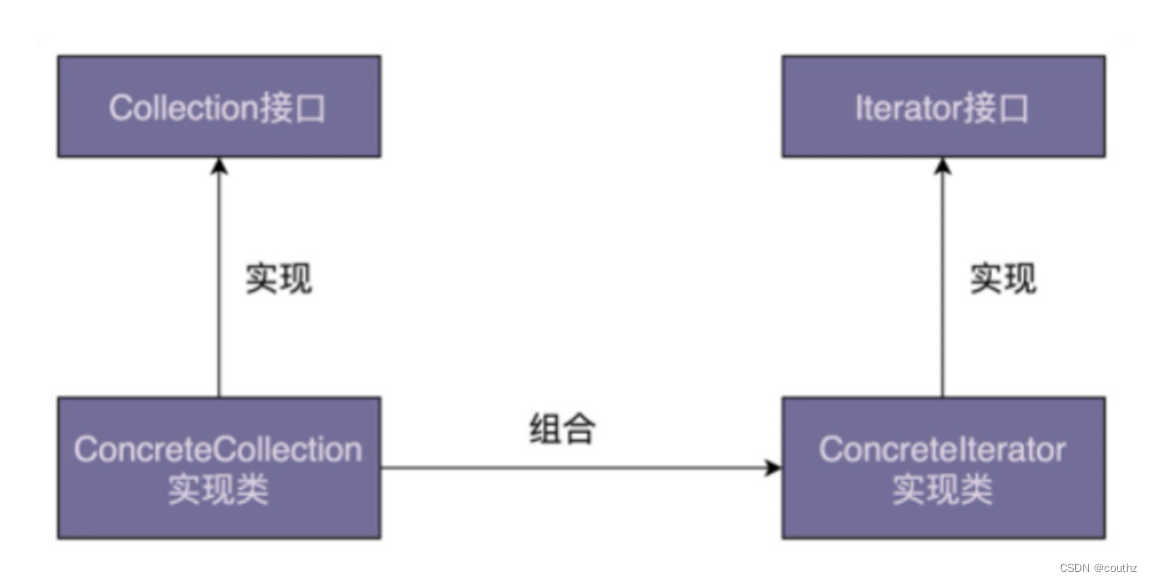
总结起来,迭代器模式有以下的好处
- 封装复杂数据结构的遍历代码:简单的数据结构我可以直接用for循环遍历,但是复杂数据结构的遍历代码,没必要在自己的客户端代码里再实现一遍,于是拆分出迭代器接口,容器类和迭代器之间用组合方式关联。
- 扩展性:我们也不想把遍历方法写在容器类中(容器类更加复杂,变化原因增加,不符合单一职责)我需要更改或添加迭代方式时,只需要扩展新的迭代器类,而不需要去更改其他地方的代码,更符合开闭原则
- 基于接口编程:容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改
ArrayList的迭代器
Java中如果要自己实现迭代器,实现java.util.Iterator类就好了,ArrayList就是这样做的
ArrayList实现了两个迭代器类Itr和ListItr,后者继承了前者,先看看第一个
这里先省略方法的具体实现,看看一个迭代器的主要参数和方法
private class Itr implements Iterator<E> {int cursor; // 迭代过程中下一个元素的位置,默认从0开始int lastRet = -1; // 一般情况下表示上一次迭代过程中索引的位置;删除一次后:为-1int expectedModCount = modCount; //expectedModCount表示迭代过程中期望的版本号Itr() {}public boolean hasNext() { //查看还有没有值可以迭代}public E next() { //如果有值可以迭代,迭代值是多少}public void remove() { //删除当前迭代的值}public void forEachRemaining(Consumer<? super E> consumer) {}final void checkForComodification() {}
}
常规情况下,遍历一个list的代码,以及删除元素的代码如下
// 获取迭代器并遍历 ArrayList
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {String item = iter.next(); //next的关键无非是cursor如何移动if (item.equals("banana")) {// 使用迭代器删除元素iter.remove(); //cursor指向的是下一个元素的位置,lastRet是cursor的前一个位置,所以remove操作实际上删除的是lastRet指向的元素}
}
需要注意删除操作:
- cursor指向的是下一个元素的位置,lastRet是cursor的前一个位置,所以remove操作实际上删除的是lastRet指向的元素
- 执行remove之后,cursor=lastRet,退回到前一个位置,防止遍历时丢失元素,lastRet=-1
- 这也就导致了remove操作不能连续执行,必须是先执行next操作(会将lastRet重新变为cursor-1),才能执行一次remove
modCount有什么作用?与一个Fail-Fast 机制有关:
首先ArrayList中有一个modCount属性,所有更改数据结构的操作,add,remove都会将modCount++,可以被视作更改了ArrayList的版本号
另外,迭代器Itr中有属性expectedModCount,初始化为modCount。每次next()都会先检查expectedModCount有没有发生改变,如果改变就抛异常。
也就是说从Itr创建开始,就不允许当前ArrayList有结构上的改变,避免可能存在的错误
private class Itr implements Iterator<E> {int expectedModCount = modCount; //expectedModCount表示迭代过程中期望的版本号public E next() { //如果有值可以迭代,迭代值是多少checkForComodification();}final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
}
那可能会出什么错呢?
一句话总结就是:遍历过程中在当前游标之前(包括当前游标)的位置插入或删除元素,会导致某个元素重复遍历或者丢失遍历
因此,在ArrayList实现的Iterator逻辑中,每次cursor指向的都是下次元素的位置,而lastRet指向最后一次遍历元素的位置
每次remove操作,因为调用了arraylist的remove方法,modCount会自增,这时会将expectedModCount重置为modCount(防止fail-fast),并且将cursor回退为lastRet,避免丢失元素
Fail-Fast 机制通常设计用于停止正常操作,而不是试图继续可能出错的过程。(注意这个并不能防止多线程操作出现异常,只是防止单线程操作,迭代器遍历过程中被其他方式改变了集合结构,那么继续使用迭代器是有可能报异常的,因为从使用者的角度看这不属于使用者的逻辑错误,但是可能会出错,所以在设计上应当主动报异常)
ArrayList还实现了一个迭代器ListIterator
private class ListItr extends Itr implements ListIterator<E> {ListItr(int index) {super();cursor = index;}public boolean hasPrevious() {return cursor != 0;}public int nextIndex() {return cursor;}public int previousIndex() {return cursor - 1;}@SuppressWarnings("unchecked")public E previous() {checkForComodification();int i = cursor - 1;if (i < 0)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i;return (E) elementData[lastRet = i];}public void set(E e) {if (lastRet < 0)throw new IllegalStateException();checkForComodification();try {ArrayList.this.set(lastRet, e);} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}}public void add(E e) {checkForComodification();try {int i = cursor;ArrayList.this.add(i, e);cursor = i + 1;lastRet = -1;expectedModCount = modCount;} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}}
}
区别:
1.使用范围不同,Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型。而ListIterator只能用于List及其子类型。
2.ListIterator有add方法,可以向List中添加对象,而Iterator不能。
3.ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator不可以。
4.ListIterator可以定位当前索引的位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
5.都可实现删除操作,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
参考资料
王争. 设计模式之美
相关文章:
【Java集合类】ArrayList
内部结构 ArrayList内部核心是一个Object数组elementDataObject数组的长度(length)视为ArrayList当前的容量(capacity)size对象表示ArrayList当前的元素个数 类上的重要注释 内部是Object数组 允许put null值,会自动扩容 size、…...

页面置换算法
页面置换算法 在进程运行过程中,若需要访问的物理块不在内存中,就需要通过一定的方式来将页面载入内存,而此时内存很可能已无空闲空间,因此就需要一定的算法来选择内存中要被置换的页面,这种算法就被称为页面置换算法…...

算法导论【在线算法】—The Ski-Rental Problem、The Lost Cow Problem、The Secretary Problem
算法导论【在线算法】The Ski-Rental Problem问题描述在线算法证明The Lost Cow Problem问题描述在线算法类似问题—寻宝藏The Secretary Problem问题描述在线算法The Best Possible kThe Ski-Rental Problem 问题描述 假设你正在上滑雪课。每节课结束后,你决定&a…...

linux 下怎样给pdf 文件加书签
linux 下怎样给pdf 文件加书签 对于没有书签的pdf文件,怎样给pdf加标签呢? 以方便阅读. 以前总是要借助windows下pdf 工具, 叫什么来者? 忘了 记得是编辑一个用tab表示目录级别的文本文件, 有一种直观的感觉,大目录下嵌套着小目录 ..., 然后导入到文件中 linux 下有没有这种…...
[软件工程导论(第六版)]第2章 可行性研究(课后习题详解)
文章目录1. 在软件开发的早期阶段为什么要进行可行性研究?应该从哪些方面研究目标系统的可行性?2. 为方便储户,某银行拟开发计算机储蓄系统。储户填写的存款单或取款单由业务员输入系统,如果是存款,系统记录存款人姓名…...
[软件工程导论(第六版)]第3章 需求分析(课后习题详解)
文章目录1. 为什么要进行需求分析?通常对软件系统有哪些需求?2. 怎样与用户有效地沟通以获取用户的真实需求?3. 银行计算机储蓄系统的工作过程大致如下:储户填写的存款单或取款单由业务员输入系统,如果是存款则系统记录…...

基于分布鲁棒联合机会约束的能源和储备调度(Matlab代码实现)
👨🎓个人主页:研学社的博客 💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜…...

ETL和数据建模
一、什么是ETL ETL是数据抽取(Extract)、转换(Transform)、加载(Load )的简写,它是将OLTP系统中的数据经过抽取,并将不同数据源的数据进行转换、整合,得出一致性的数据&…...

ccc-pytorch-回归问题(1)
文章目录1.简单回归实战:2.手写数据识别1.简单回归实战: 用 线性回归拟合二维平面中的100个点 公式:ywxbywxbywxb 损失函数:∑(yreally−y)2\sum(y_{really}-y)^2∑(yreally−y)2 迭代方法:梯度下降法,…...

【JAVA八股文】框架相关
框架相关1. Spring refresh 流程2. Spring bean 生命周期3. Spring bean 循环依赖解决 set 循环依赖的原理4. Spring 事务失效5. Spring MVC 执行流程6. Spring 注解7. SpringBoot 自动配置原理8. Spring 中的设计模式1. Spring refresh 流程 Spring refresh 概述 refresh 是…...
二叉树的相关列题!!
对于二叉树,很难,很难!笔者也是感觉很难!虽然能听懂课程,但是,对于大部分的练习题并不能做出来!所以感觉很尴尬!!因此,笔者经过先前的那篇博客,已…...

Java设计模式 - 原型模式
简介 原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直…...

深度学习中的 “Hello World“
Here’s an interesting fact—Each month, there are 186.000 Google searches for the keyword “deep learning.” 大家好✨,这里是bio🦖。每月有超18万的人使用谷歌搜索深度学习这一关键词,是什么让人们对深度学习如此感兴趣?接下来请跟随我来揭开深度学习的神秘面纱。…...

购买WMS系统前,有搞清楚与ERP仓库模块的区别吗
经常有朋友在后台询问我们关于WMS系统的问题,他们自己也有ERP系统,但是总觉得好像还差了点什么,不知道是什么。今天,我想通过本文,来向您简要地阐述ERP与WMS系统在仓储管理上的不同之处。 ERP仓库是以财务为导向的&…...

一文吃透 Spring 中的IOC和DI
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
分布式任务处理:XXL-JOB分布式任务调度框架
文章目录1.业务场景与任务调度2.任务调度的基本实现2.1 多线程方式实现2.2 Timer方式实现2.3 ScheduledExecutor方式实现2.4 第三方Quartz方式实现3.分布式任务调度4.XXL-JOB介绍5.搭建XXL-JOB —— 调度中心5.1 下载与查看XXL-JOB5.2 创建数据库表5.3 修改默认的配置信息5.4 启…...

【源码解析】Ribbon和Feign实现不同服务不同的配置
Ribbon服务实现不同服务,不同配置是通过RibbonClient和RibbonClients两个注解来实现的。RibbonClient注册的某个Client配置类。RibbonClients注册的全局默认配置类。 Feign实现不同服务,不同配置,是根据FeignClient来获取自定义的配置。 示…...
【webpack5】一些常见优化配置及原理介绍(二)
这里写目录标题介绍sourcemap定位报错热模块替换(或热替换,HMR)oneOf精准解析指定或排除编译开启缓存多进程打包移除未引用代码配置babel,减小代码体积代码分割(Code Split)介绍预获取/预加载(prefetch/pre…...

力扣sql简单篇练习(十九)
力扣sql简单篇练习(十九) 1 查询结果的质量和占比 1.1 题目内容 1.1.1 基本题目信息 1.1.2 示例输入输出 1.2 示例sql语句 # 用count是不会统计为null的数据的 SELECT query_name,ROUND(AVG(rating/position),2) quality,ROUND(count(IF(rating<3,rating,null))/count(r…...

线段树c++
前言 在谈论到种种算法知识与数据结构的时候,线段树无疑总是与“简单”和“平常”联系起来的。而这些特征意味着,线段树作为一种常用的数据结构,有常用性,基础性和易用性等诸多特点。因此,今天我来讲一讲关于线段树的话题。 定义 首先,线段树是一棵“树”,而且是一棵…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...