《TCP IP网络编程》第十八章
第 18 章 多线程服务器端的实现
18.1 理解线程的概念
线程背景:
第 10 章介绍了多进程服务端的实现方法。多进程模型与 select 和 epoll 相比的确有自身的优点,但同时也有问题。如前所述,创建(复制)进程的工作本身会给操作系统带来相当沉重的负担。而且,每个进程都具有独立的内存空间,所以进程间通信的实现难度也会随之提高。换言之,多进程的缺点可概括为:
- 创建进程的过程会带来一定的开销
- 为了完成进程间数据交换,需要特殊的 IPC 技术。
但是更大的缺点是下面的:
- 每秒少则 10 次,多则千次的「上下文切换」是创建进程的最大开销
只有一个 CPU 的系统是将时间分成多个微小的块后分配给了多个进程。为了分时使用 CPU ,需要「上下文切换」的过程。「上下文切换」是指运行程序前需要将相应进程信息读入内存,如果运行进程 A 后紧接着需要运行进程 B ,就应该将进程 A 相关信息移出内存,并读入进程 B 相关信息。这就是上下文切换。但是此时进程 A 的数据将被移动到硬盘,所以上下文切换要很长时间,即使通过优化加快速度,也会存在一定的局限。
为了保持多进程的优点,同时在一定程度上克服其缺点,人们引入的线程(Thread)的概念。这是为了将进程的各种劣势降至最低程度(不是直接消除)而设立的一种「轻量级进程」。线程比进程具有如下优点:
- 线程的创建和上下文切换比进程的创建和上下文切换更快
- 线程间交换数据无需特殊技术
线程和进程的差异:
线程是为了解决该问题:为了得到多条代码执行流而复制整个内存区域的负担太重。
每个进程的内存空间都由保存全局变量的「数据区」、向 malloc 等函数动态分配提供空间的堆(Heap)、函数运行时使用的栈(Stack)构成。每个进程都有独立的这种空间,多个进程的内存结构如图所示:

如果以获得多个代码执行流为目的,则不应该像上图那样完全分离内存结构,而只需分离栈区域。通过这种方式可以获得如下优势:
- 上下文切换时不需要切换数据区和堆
- 可以利用数据区和堆交换数据
实际上这就是线程。线程为了保持多条代码执行流而隔开了栈区域,因此具有如下图所示的内存结构:

如图所示,多个线程共享数据区和堆。为了保持这种结构,线程将在进程内创建并运行。也就是说,进程和线程可以定义为如下形式:
- 进程:在操作系统构成单独执行流的单位
- 线程:在进程构成单独执行流的单位
如果说进程在操作系统内部生成多个执行流,那么线程就在同一进程内部创建多条执行流。因此,操作系统、进程、线程之间的关系可以表示为下图:

18.2 线程创建及运行
线程的创建和执行流程:
线程具有单独的执行流,因此需要单独定义线程的 main 函数,还需要请求操作系统在单独的执行流中执行该函数,完成函数功能的函数如下:
#include <pthread.h>int pthread_create(pthread_t *restrict thread,const pthread_attr_t *restrict attr,void *(*start_routine)(void *),void *restrict arg);
/*
成功时返回 0 ,失败时返回 -1
thread : 保存新创建线程 ID 的变量地址值。线程与进程相同,也需要用于区分不同线程的 ID
attr : 用于传递线程属性的参数,传递 NULL 时,创建默认属性的线程
start_routine : 相当于线程 main 函数的、在单独执行流中执行的函数地址值(函数指针)
arg : 通过第三个参数传递的调用函数时包含传递参数信息的变量地址值
*/下面通过简单示例了解该函数功能:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void *thread_main(void *arg);int main(int argc, char *argv[])
{pthread_t t_id;int thread_param = 5;// 请求创建一个线程,从 thread_main 调用开始,在单独的执行流中运行。同时传递参数if (pthread_create(&t_id, NULL, thread_main, (void *)&thread_param) != 0){puts("pthread_create() error");return -1;}sleep(10); //延迟进程终止时间puts("end of main");return 0;
}
void *thread_main(void *arg) //传入的参数是 pthread_create 的第四个
{int i;int cnt = *((int *)arg);for (int i = 0; i < cnt; i++){sleep(1);puts("running thread");}return NULL;
}ps:线程相关代码编译时需要添加 -lpthread 选项声明需要连接到线程库:
gcc thread1.c -o tr1 -lpthread运行结果:

上述程序的执行如图所示:
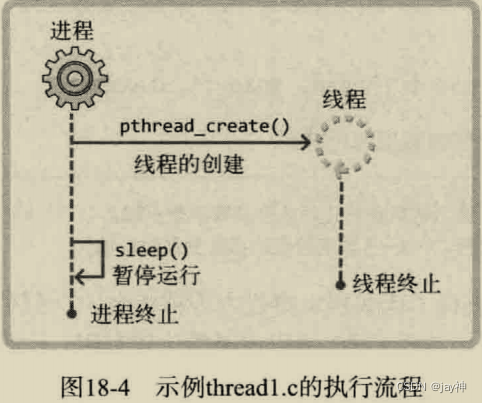
可以看出,程序在主进程没有结束时,生成的线程每隔一秒输出一次 running thread ,但是如果主进程没有等待十秒,而是直接结束,这样也会强制结束线程,不论线程有没有运行完毕。
那是否意味着主进程必须每次都 sleep 来等待线程执行完毕?并不需要,可以通过以下函数解决。
#include <pthread.h>
int pthread_join(pthread_t thread, void **status);
/*
成功时返回 0 ,失败时返回 -1
thread : 该参数值 ID 的线程终止后才会从该函数返回
status : 保存线程的 main 函数返回值的指针的变量地址值
*/作用就是调用该函数的进程(或线程)将进入等待状态,知道第一个参数为 ID 的线程终止为止。而且可以得到线程的 main 函数的返回值。下面是该函数的用法示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
void *thread_main(void *arg);int main(int argc, char *argv[])
{pthread_t t_id;int thread_param = 5;void *thr_ret;// 请求创建一个线程,从 thread_main 调用开始,在单独的执行流中运行。同时传递参数if (pthread_create(&t_id, NULL, thread_main, (void *)&thread_param) != 0){puts("pthread_create() error");return -1;}//main函数将等待 ID 保存在 t_id 变量中的线程终止if (pthread_join(t_id, &thr_ret) != 0){puts("pthread_join() error");return -1;}printf("Thread return message : %s \n", (char *)thr_ret);free(thr_ret);return 0;
}
void *thread_main(void *arg) //传入的参数是 pthread_create 的第四个
{int i;int cnt = *((int *)arg);char *msg = (char *)malloc(sizeof(char) * 50);strcpy(msg, "Hello,I'am thread~ \n");for (int i = 0; i < cnt; i++){sleep(1);puts("running thread");}return (void *)msg; //返回值是 thread_main 函数中内部动态分配的内存空间地址值
}运行结果:

可以看出,线程输出了5次字符串,并且把返回值给了主进程 。
下面是该函数的执行流程图:
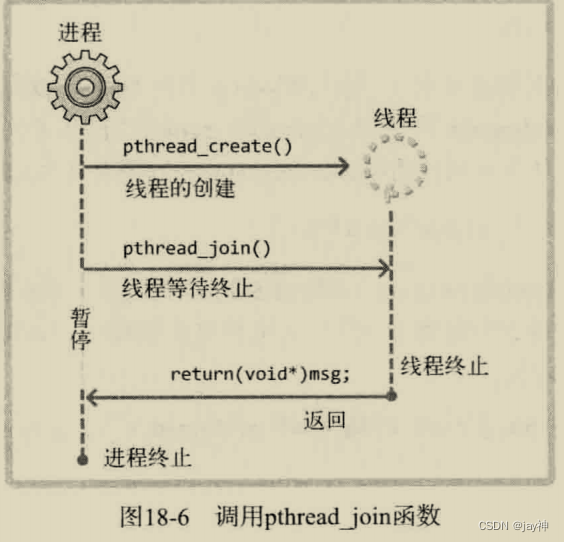
可在临界区内调用的函数 :
在同步的程序设计中,临界区块(Critical section)指的是一个访问共享资源(例如:共享设备或是共享存储器)的程序片段,而这些共享资源有无法同时被多个线程访问的特性。
当有线程进入临界区块时,其他线程或是进程必须等待(例如:bounded waiting 等待法),有一些同步的机制必须在临界区块的进入点与离开点实现,以确保这些共享资源是被异或的使用。
只能被单一线程访问的设备,例如:打印机。
一个最简单的实现方法就是当线程(Thread)进入临界区块时,禁止改变处理器;在uni-processor系统上,可以用“禁止中断(CLI)”来完成,避免发生系统调用(System Call)导致的上下文交换(Context switching);当离开临界区块时,处理器恢复原先的状态。
根据临界区是否引起问题,函数可以分为以下 2 类:
- 线程安全函数(Thread-safe function)
- 非线程安全函数(Thread-unsafe function)
线程安全函数被多个线程同时调用也不会发生问题。反之,非线程安全函数被同时调用时会引发问题。但这并非有关于临界区的讨论,线程安全的函数中同样可能存在临界区。只是在线程安全的函数中,同时被多个线程调用时可通过一些措施避免问题。
幸运的是,大多数标准函数都是线程安全函数。操作系统在定义非线程安全函数的同时,提供了具有相同功能的线程安全的函数。比如,第 8 章的:
struct hostent *gethostbyname(const char *hostname);同时,也提供了同一功能的安全函数:
struct hostent *gethostbyname_r(const char *name,struct hostent *result,char *buffer,int intbuflen,int *h_errnop); 线程安全函数结尾通常是 _r 。但是使用线程安全函数会给程序员带来额外的负担,可以通过以下方法自动将 gethostbyname 函数调用改为 gethostbyname_r 函数调用。
声明头文件前定义 _REENTRANT 宏。
无需特意更改源代码加,可以在编译的时候指定编译参数定义宏:
gcc -D_REENTRANT mythread.c -o mthread -lpthread工作(Worker)线程模型:
下面的示例是计算从 1 到 10 的和,但并不是通过 main 函数进行运算,而是创建两个线程,其中一个线程计算 1 到 5 的和,另一个线程计算 6 到 10 的和,main 函数只负责输出运算结果。这种方式的线程模型称为「工作线程」。显示该程序的执行流程图:
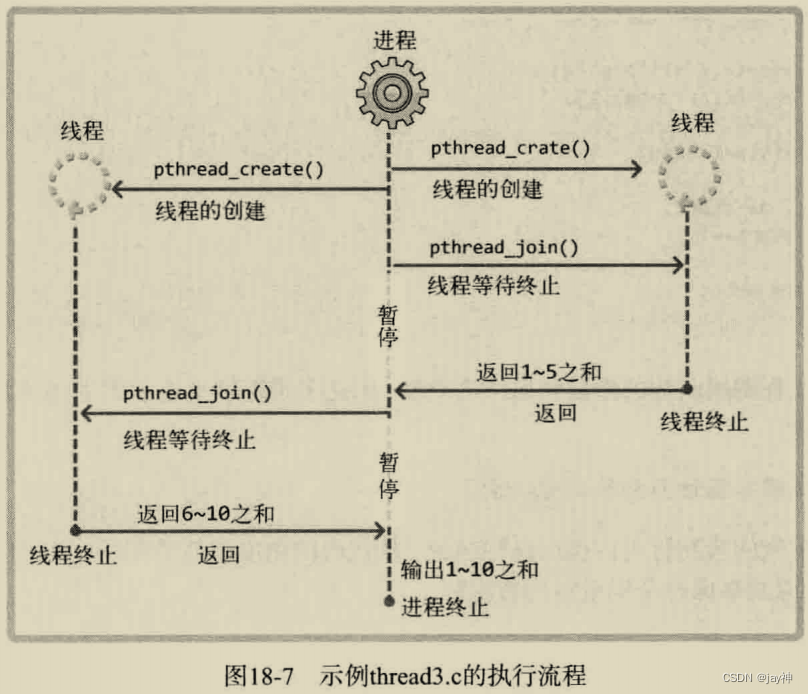
下面是代码:
#include <stdio.h>
#include <pthread.h>
void *thread_summation(void *arg);
int sum = 0;int main(int argc, char *argv[])
{pthread_t id_t1, id_t2;int range1[] = {1, 5};int range2[] = {6, 10};pthread_create(&id_t1, NULL, thread_summation, (void *)range1);pthread_create(&id_t2, NULL, thread_summation, (void *)range2);pthread_join(id_t1, NULL);pthread_join(id_t2, NULL);printf("result: %d \n", sum);return 0;
}
void *thread_summation(void *arg)
{int start = ((int *)arg)[0];int end = ((int *)arg)[1];while (start <= end){sum += start;start++;}return NULL;
}运行结果:

可以看出计算结果正确,两个线程都用了全局变量 sum ,证明了 2 个线程共享保存全局变量的数据区。
但是本例子本身存在问题。存在临界区相关问题,可以从下面的代码看出,下面的代码和上面的代码相似,只是增加了发生临界区错误的可能性,即使在高配置系统环境下也容易产生的错误:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREAD 100void *thread_inc(void *arg);
void *thread_des(void *arg);
long long num = 0;int main(int argc, char *argv[])
{pthread_t thread_id[NUM_THREAD];int i;printf("sizeof long long: %d \n", sizeof(long long));for (i = 0; i < NUM_THREAD; i++){if (i % 2)pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);elsepthread_create(&(thread_id[i]), NULL, thread_des, NULL);}for (i = 0; i < NUM_THREAD; i++)pthread_join(thread_id[i], NULL);printf("result: %lld \n", num);return 0;
}void *thread_inc(void *arg)
{int i;for (i = 0; i < 50000000; i++)num += 1;return NULL;
}
void *thread_des(void *arg)
{int i;for (i = 0; i < 50000000; i++)num -= 1;return NULL;
}运行结果:

从图上可以看出,每次运行的结果竟然不一样。理论上来说,上面代码的最后结果应该是 0 。原因暂时不得而知,但是可以肯定的是,这对于线程的应用是个大问题。
18.3 线程存在的问题和临界区
下面分析上述代码中产生问题的原因,并给出解决方案。
多个线程访问同一变量是问题:
上述代码问题如下:
2 个线程正在同时访问全局变量 num。
任何内存空间,只要被同时访问,都有可能发生问题。 因此,线程访问变量 num 时应该阻止其他线程访问,直到线程 1 运算完成。这就是同步。
临界区位置:
在刚才代码中的临界区位置是:函数内同时运行多个线程时引发问题的多条语句构成的代码块。
全局变量 num 不能视为临界区,因为他不是引起问题的语句,只是一个内存区域的声明。下面是刚才代码的两个 main 函数:
void *thread_inc(void *arg)
{int i;for (i = 0; i < 50000000; i++)num += 1;//临界区return NULL;
}
void *thread_des(void *arg)
{int i;for (i = 0; i < 50000000; i++)num -= 1;//临界区return NULL;
}由上述代码可知,临界区并非 num 本身,而是访问 num 的两条语句,这两条语句可能由多个线程同时运行,也是引起这个问题的直接原因。产生问题的原因可以分为以下三种情况:
- 2 个线程同时执行 thread_inc 函数
- 2 个线程同时执行 thread_des 函数
- 2 个线程分别执行 thread_inc 和 thread_des 函数
比如发生以下情况:
线程 1 执行 thread_inc 的 num+=1 语句的同时,线程 2 执行 thread_des 函数的 num-=1 语句。
也就是说,两条不同的语句由不同的线程执行时,也有可能构成临界区。前提是这 2 条语句访问同一内存空间。
18.4 线程同步
前面讨论了线程中存在的问题,下面就是解决方法,线程同步。
同步的两面性:
线程同步用于解决线程访问顺序引发的问题。需要同步的情况可以从如下两方面考虑。
- 同时访问同一内存空间时发生的情况
- 需要指定访问同一内存空间的线程顺序的情况
情况一之前已经解释过,下面讨论情况二。这是「控制线程执行的顺序」的相关内容。假设有 A B 两个线程,线程 A 负责向指定的内存空间内写入数据,线程 B 负责取走该数据。所以这是有顺序的,不按照顺序就可能发生问题。所以这种也需要进行同步。
互斥量:
互斥锁是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全域变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。
通俗的说就互斥量就是一把优秀的锁,当临界区被占据的时候就上锁,等占用完毕然后再放开。下面是互斥量的创建及销毁函数:
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex,const pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
/*
成功时返回 0,失败时返回其他值
mutex : 创建互斥量时传递保存互斥量的变量地址值,销毁时传递需要销毁的互斥量地址
attr : 传递即将创建的互斥量属性,没有特别需要指定的属性时传递 NULL
*/从上述函数声明中可以看出,为了创建相当于锁系统的互斥量,需要声明如下 pthread_mutex_t 型变量:
pthread_mutex_t mutex该变量的地址值传递给 pthread_mutex_init 函数,用来保存操作系统创建的互斥量(锁系统)。调用 pthread_mutex_destroy 函数时同样需要该信息。如果不需要配置特殊的互斥量属性,则向第二个参数传递 NULL 时,可以利用 PTHREAD_MUTEX_INITIALIZER 进行如下声明:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;推荐尽可能的使用 pthread_mutex_init 函数进行初始化,因为通过宏进行初始化时很难发现发生的错误。
下面是利用互斥量锁住或释放临界区时使用的函数:
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
/*
成功时返回 0 ,失败时返回其他值
*/函数本身含有 lock unlock 等词汇,很容易理解其含义。进入临界区前调用的函数就是 pthread_mutex_lock 。调用该函数时,发现有其他线程已经进入临界区,pthread_mutex_lock 函数不会返回,直到里面的线程调用 pthread_mutex_unlock 函数退出临界区位置。也就是说,其他线程让出临界区之前,当前线程一直处于阻塞状态。接下来整理一下代码的编写方式:
pthread_mutex_lock(&mutex);
//临界区开始
//...
//临界区结束
pthread_mutex_unlock(&mutex);简言之,就是利用 lock 和 unlock 函数围住临界区的两端。此时互斥量相当于一把锁,阻止多个线程同时访问,还有一点要注意,线程退出临界区时,如果忘了调用pthread_mutex_unlock 函数,那么其他为了进入临界区而调用 pthread_mutex_lock 的函数无法摆脱阻塞状态。这种情况称为「死锁」。需要格外注意,下面是利用互斥量解决上述示例中遇到的问题代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREAD 100
void *thread_inc(void *arg);
void *thread_des(void *arg);long long num = 0;
pthread_mutex_t mutex; //保存互斥量读取值的变量int main(int argc, char *argv[])
{pthread_t thread_id[NUM_THREAD];int i;pthread_mutex_init(&mutex, NULL); //创建互斥量for (i = 0; i < NUM_THREAD; i++){if (i % 2)pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);elsepthread_create(&(thread_id[i]), NULL, thread_des, NULL);}for (i = 0; i < NUM_THREAD; i++)pthread_join(thread_id[i], NULL);printf("result: %lld \n", num);pthread_mutex_destroy(&mutex); //销毁互斥量return 0;
}void *thread_inc(void *arg)
{int i;pthread_mutex_lock(&mutex); //上锁for (i = 0; i < 50000000; i++)num += 1;pthread_mutex_unlock(&mutex); //解锁return NULL;
}
void *thread_des(void *arg)
{int i;pthread_mutex_lock(&mutex);for (i = 0; i < 50000000; i++)num -= 1;pthread_mutex_unlock(&mutex);return NULL;
}运行结果:

在代码中:
void *thread_inc(void *arg)
{int i;pthread_mutex_lock(&mutex); //上锁for (i = 0; i < 50000000; i++)num += 1;pthread_mutex_unlock(&mutex); //解锁return NULL;
}以上代码的临界区划分范围较大,这样子做有如下优点:
最大限度减少互斥量 lock unlock 函数的调用次数。
信号量:
信号量(英语:Semaphore),是一个同步对象,用于保持在0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时,计数值加一。当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态.
semaphore对象适用于控制一个仅支持有限个用户的共享资源,是一种不需要使用忙碌等待(busy waiting)的方法。
信号量的概念是由荷兰计算机科学家艾兹赫尔·戴克斯特拉(Edsger W. Dijkstra)发明的,广泛的应用于不同的操作系统中。在系统中,给予每一个进程一个信号量,代表每个进程当前的状态,未得到控制权的进程会在特定地方被强迫停下来,等待可以继续进行的信号到来。如果信号量是一个任意的整数,通常被称为计数信号量(Counting semaphore),或一般信号量(general semaphore);如果信号量只有二进制的0或1,称为二进制信号量(binary semaphore)。在linux系统中,二进制信号量(binary semaphore)又称互斥锁(Mutex)。
下面介绍信号量,在互斥量的基础上,很容易理解信号量。此处只涉及利用「二进制信号量」(只用 0 和 1)完成「控制线程顺序」为中心的同步方法。下面是信号量的创建及销毁方法:
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
/*
成功时返回 0 ,失败时返回其他值
sem : 创建信号量时保存信号量的变量地址值,销毁时传递需要销毁的信号量变量地址值
pshared : 传递其他值时,创建可由多个继承共享的信号量;传递 0 时,创建只允许 1 个进程内部使用的信号量。需要完成同一进程的线程同步,故为0
value : 指定创建信号量的初始值
*/上述的 shared 参数超出了我们的关注范围,故默认向其传递为 0 。下面是信号量中相当于互斥量 lock unlock 的函数。
#include <semaphore.h>
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem);
/*
成功时返回 0 ,失败时返回其他值
sem : 传递保存信号量读取值的变量地址值,传递给 sem_post 的信号量增1,传递给 sem_wait 时信号量减一
*/调用 sem_init 函数时,操作系统将创建信号量对象,此对象中记录这「信号量值」(Semaphore Value)整数。该值在调用 sem_post 函数时增加 1 ,调用 wait_wait 函数时减一。但信号量的值不能小于 0 ,因此,在信号量为 0 的情况下调用 sem_wait 函数时,调用的线程将进入阻塞状态(因为函数未返回)。当然,此时如果有其他线程调用 sem_post 函数,信号量的值将变为 1 ,而原本阻塞的线程可以将该信号重新减为 0 并跳出阻塞状态。实际上就是通过这种特性完成临界区的同步操作,可以通过如下形式同步临界区(假设信号量的初始值为 1)
sem_wait(&sem);//信号量变为0...
// 临界区的开始
//...
//临界区的结束
sem_post(&sem);//信号量变为1...上述代码结构中,调用 sem_wait 函数进入临界区的线程在调用 sem_post 函数前不允许其他线程进入临界区。信号量的值在 0 和 1 之间跳转,因此,具有这种特性的机制称为「二进制信号量」。接下来的代码是信号量机制的代码。下面代码并非是同时访问的同步,而是关于控制访问顺序的同步,该场景为:
线程 A 从用户输入得到值后存入全局变量 num ,此时线程 B 将取走该值并累加。该过程一共进行 5 次,完成后输出总和并退出程序。
下面是代码:
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>void *read(void *arg);
void *accu(void *arg);
static sem_t sem_one;
static sem_t sem_two;
static int num;int main(int argc, char const *argv[])
{pthread_t id_t1, id_t2;sem_init(&sem_one, 0, 0);sem_init(&sem_two, 0, 1);pthread_create(&id_t1, NULL, read, NULL);pthread_create(&id_t2, NULL, accu, NULL);pthread_join(id_t1, NULL);pthread_join(id_t2, NULL);sem_destroy(&sem_one);sem_destroy(&sem_two);return 0;
}void *read(void *arg)
{int i;for (i = 0; i < 5; i++){fputs("Input num: ", stdout);sem_wait(&sem_two);scanf("%d", &num);sem_post(&sem_one);}return NULL;
}
void *accu(void *arg)
{int sum = 0, i;for (i = 0; i < 5; i++){sem_wait(&sem_one);sum += num;sem_post(&sem_two);}printf("Result: %d \n", sum);return NULL;
}运行结果:

从上述代码可以看出,设置了两个信号量 one 的初始值为 0 ,two 的初始值为 1,然后在调用函数的时候,「读」的前提是 two 可以减一,如果不能减一就会阻塞在这里,一直等到「计算」操作完毕后,给 two 加一,然后就可以继续执行下一句输入。对于「计算」函数,也一样。
18.5 线程的销毁和多线程并发服务器端的实现
先介绍线程的销毁,然后再介绍多线程服务端。
销毁线程的 3 种方法:
Linux 的线程并不是在首次调用的线程 main 函数返回时自动销毁,所以利用如下方法之一加以明确。否则由线程创建的内存空间将一直存在。
- 调用 pthread_join 函数
- 调用 pthread_detach 函数
之前调用过 pthread_join 函数。调用该函数时,不仅会等待线程终止,还会引导线程销毁。但该函数的问题是,线程终止前,调用该函数的线程将进入阻塞状态。因此,通过如下函数调用引导线程销毁:
#include <pthread.h>
int pthread_detach(pthread_t th);
/*
成功时返回 0 ,失败时返回其他值
thread : 终止的同时需要销毁的线程 ID
*/调用上述函数不会引起线程终止或进入阻塞状态,可以通过该函数引导销毁线程创建的内存空间。调用该函数后不能再针对相应线程调用 pthread_join 函数。
多线程并发服务器端的实现:
下面是多个客户端之间可以交换信息的简单聊天程序的代码及详细注释:
服务器端:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>#define BUF_SIZE 100
#define MAX_CLNT 256void *handle_clnt(void *arg);
void send_msg(char *msg, int len);
void error_handling(char *msg);int clnt_cnt = 0; // 记录连接的客户端数量
int clnt_socks[MAX_CLNT]; // 存储连接的客户端套接字
pthread_mutex_t mutx; // 互斥锁,保护共享资源int main(int argc, char *argv[])
{int serv_sock, clnt_sock;struct sockaddr_in serv_adr, clnt_adr;int clnt_adr_sz;pthread_t t_id;if (argc != 2){printf("Usage : %s <port>\n", argv[0]);exit(1);}pthread_mutex_init(&mutx, NULL); // 初始化互斥锁// ... 进行服务器套接字的创建和绑定 ...serv_sock = socket(PF_INET, SOCK_STREAM, 0);memset(&serv_adr, 0, sizeof(serv_adr));serv_adr.sin_family = AF_INET;serv_adr.sin_addr.s_addr = htonl(INADDR_ANY);serv_adr.sin_port = htons(atoi(argv[1]));if (bind(serv_sock, (struct sockaddr *)&serv_adr, sizeof(serv_adr)) == -1)error_handling("bind() error");if (listen(serv_sock, 5) == -1)error_handling("listen() error");while (1){// ... 接受客户端连接 ...clnt_adr_sz = sizeof(clnt_adr);clnt_sock = accept(serv_sock, (struct sockaddr *)&clnt_adr, &clnt_adr_sz);pthread_mutex_lock(&mutx); //上锁,保护共享资源clnt_socks[clnt_cnt++] = clnt_sock; //将新连接的客户端套接字存储起来pthread_mutex_unlock(&mutx); //解锁//创建线程为新客户端服务,并且把clnt_sock作为参数传递pthread_create(&t_id, NULL, handle_clnt, (void *)&clnt_sock); //引导线程销毁,不阻塞 pthread_detach(t_id); // 打印客户端的IP地址 printf("Connected client IP: %s \n", inet_ntoa(clnt_adr.sin_addr)); }close(serv_sock);return 0;
}void *handle_clnt(void *arg)
{int clnt_sock = *((int *)arg);int str_len = 0, i;char msg[BUF_SIZE];// 读取客户端发来的消息,并广播给所有客户端while ((str_len = read(clnt_sock, msg, sizeof(msg))) != 0)send_msg(msg, str_len);// 当收到消息长度为0时,表示客户端断开连接pthread_mutex_lock(&mutx);for (i = 0; i < clnt_cnt; i++) // 从连接列表中移除断开的客户端{if (clnt_sock == clnt_socks[i]){while (i++ < clnt_cnt - 1)clnt_socks[i] = clnt_socks[i + 1];break;}}clnt_cnt--;pthread_mutex_unlock(&mutx);close(clnt_sock);return NULL;
}
// 将消息发送给所有连接的客户端
void send_msg(char *msg, int len)
{int i;pthread_mutex_lock(&mutx);// 向每个连接的客户端发送消息for (i = 0; i < clnt_cnt; i++)write(clnt_socks[i], msg, len);pthread_mutex_unlock(&mutx);
}
void error_handling(char *msg)
{fputs(msg, stderr);fputc('\n', stderr);exit(1);
}客户端:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <pthread.h>#define BUF_SIZE 100
#define NAME_SIZE 20void *send_msg(void *arg);
void *recv_msg(void *arg);
void error_handling(char *msg);char name[NAME_SIZE] = "[DEFAULT]"; // 客户端名称
char msg[BUF_SIZE]; // 存储要发送的消息int main(int argc, char *argv[])
{int sock;struct sockaddr_in serv_addr;pthread_t snd_thread, rcv_thread;void *thread_return;
// ... 解析命令行参数,设置客户端名称、服务器IP和端口 ...if (argc != 4){printf("Usage : %s <IP> <port> <name>\n", argv[0]);exit(1);}sprintf(name, "[%s]", argv[3]);
// ... 创建客户端套接字,设置服务器地址结构体 ...sock = socket(PF_INET, SOCK_STREAM, 0);memset(&serv_addr, 0, sizeof(serv_addr));serv_addr.sin_family = AF_INET;serv_addr.sin_addr.s_addr = inet_addr(argv[1]);serv_addr.sin_port = htons(atoi(argv[2]));if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1)error_handling("connect() error");// 创建发送和接收消息的线程pthread_create(&snd_thread, NULL, send_msg, (void *)&sock); pthread_create(&rcv_thread, NULL, recv_msg, (void *)&sock); // 等待线程结束pthread_join(snd_thread, &thread_return);pthread_join(rcv_thread, &thread_return);close(sock);return 0;
}
// 发送消息的线程函数
void *send_msg(void *arg)
{int sock = *((int *)arg);char name_msg[NAME_SIZE + BUF_SIZE];while (1){fgets(msg, BUF_SIZE, stdin);if (!strcmp(msg, "q\n") || !strcmp(msg, "Q\n")) // 判断是否输入退出指令{close(sock);exit(0);}sprintf(name_msg, "%s %s", name, msg);write(sock, name_msg, strlen(name_msg)); // 发送带有客户端名称的消息}return NULL;
}
// 接收消息的线程函数
void *recv_msg(void *arg)
{int sock = *((int *)arg);char name_msg[NAME_SIZE + BUF_SIZE];int str_len;while (1){str_len = read(sock, name_msg, NAME_SIZE + BUF_SIZE - 1);if (str_len == -1)return (void *)-1;name_msg[str_len] = 0;// 打印接收到的消息fputs(name_msg, stdout); }return NULL;
}void error_handling(char *msg)
{fputs(msg, stderr);fputc('\n', stderr);exit(1);
}上面的服务端示例中,需要掌握临界区的构成,访问全局变量 clnt_cnt 和数组 clnt_socks 的代码将构成临界区,添加和删除客户端时,变量 clnt_cnt 和数组 clnt_socks 将同时发生变化。
运行结果:

习题:
1、单 CPU 系统中如何同时执行多个进程?请解释该过程中发生的上下文切换。
在单 CPU 系统中,实际上并不能真正地同时执行多个进程。然而,操作系统通过使用一种称为"时间片轮转调度"的技术,以非常快的速度在不同的进程之间进行切换,使得多个进程看起来几乎是同时运行的。
时间片轮转调度: 这是一种抢占式的调度算法,操作系统将CPU时间划分为小的时间片,每个进程被分配一个时间片来执行。当一个进程的时间片用完后,操作系统会暂停该进程的执行,保存它的状态(上下文),然后切换到下一个就绪状态的进程,并恢复其上下文,继续执行。这个过程在不同进程之间快速交替进行,给人的感觉就是多个进程在同时运行。
上下文切换: 当操作系统从一个进程切换到另一个进程时,需要保存当前进程的状态(上下文),包括寄存器值、程序计数器等信息,然后加载下一个进程的状态,使其继续执行。这个过程称为上下文切换。上下文切换会引入一些开销,因为需要保存和恢复进程的状态,但它使得多个进程能够在有限的CPU资源下共享执行时间,实现并发执行的假象。
2、为何线程的上下文切换速度相对更快?线程间数据交换为何不需要类似 IPC 特别技术。
线程的上下文切换速度相对更快,主要因为线程之间共享进程的地址空间和资源,这使得上下文切换所需的操作相对较少。
线程间数据交换不需要类似 IPC(进程间通信)的特别技术,因为线程在同一进程内部,共享同一进程的地址空间和资源,可以直接访问和操作共享的内存区域,实现数据交换和通信。这种共享性质使得线程间数据交换更加简便和高效。
3、请从执行流角度说明进程和线程的区别。
进程:在操作系统构成单独执行流的单位。线程:在进程内部构成单独执行流的单位。线程为了保持多条代码执行流而隔开了栈区域。
4、请说明完全销毁 Linux 线程的 2 种办法。
①调用 pthread_join 函数②调用 pthread_detach 函数。第一个会阻塞调用的线程,而第二个不阻塞。都可以引导线程销毁。
相关文章:
《TCP IP网络编程》第十八章
第 18 章 多线程服务器端的实现 18.1 理解线程的概念 线程背景: 第 10 章介绍了多进程服务端的实现方法。多进程模型与 select 和 epoll 相比的确有自身的优点,但同时也有问题。如前所述,创建(复制)进程的工作本身会…...

TCP编程流程
目录 1、主机字节序列和网络字节序列 2、套接字地址结构 3、IP地址转换函数 4、TCP协议编程: (1)服务器端: (2)客户端: 1、主机字节序列和网络字节序列 主机字节序列分为大端字节序和小端字节序 大端…...
)
CSDN编程题-每日一练(2023-08-19)
CSDN编程题-每日一练(2023-08-19) 一、题目名称:风险投资二、题目名称:幼稚班作业三、题目名称:韩信点兵一、题目名称:风险投资 时间限制:1000ms内存限制:256M 题目描述: 风险投资是一种感性和理性并存的投资方式,风险投资人一般会对请公允的第三方评估公司对投资对象…...
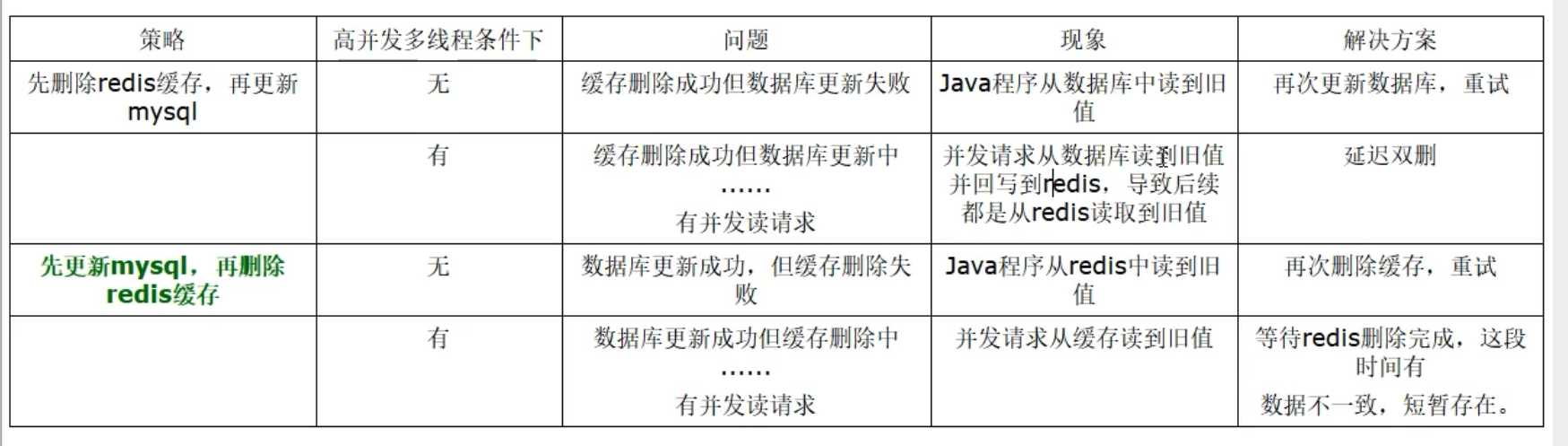
03_缓存双写一致性
03——缓存双写一致性 一、缓存双写一致性 如果redis中有数据,需要和数据库中的值相同如果redis中无数据,数据库中的值要是最新值,且准备回写redis 缓存按照操作来分,可以分为两种: 只读缓存 读写缓存 同步直写操作…...

机器学习之数据集
目录 1、简介 2、可用数据集 3、scikit-learn数据集API 3.1、小数据集 3.2、大数据集 4、数据集使用 ⭐所属专栏:人工智能 文中提到的代码如有需要可以私信我发给你😊 1、简介 当谈论数据集时,通常是指在机器学习和数据分析中使用的一组…...

PyTorch Geometric基本教程
PyG官方文档 # Install torch geometric !pip install -q torch-scatter -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-sparse -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-geometricimport t…...

MAC 命令行启动tomcat的详细介绍
MAC 命令行启动tomcat MAC 命令行启动tomcat的详细介绍 一、修改授权 进入tomcat的bin目录,修改授权 1 2 3 ➜ bin pwd /Users/yp/Documents/workspace/apache-tomcat-7.0.68/bin ➜ bin sudo chmod 755 *.sh sudo为系统超级管理员权限.chmod 改变一个或多个文件的存取模…...
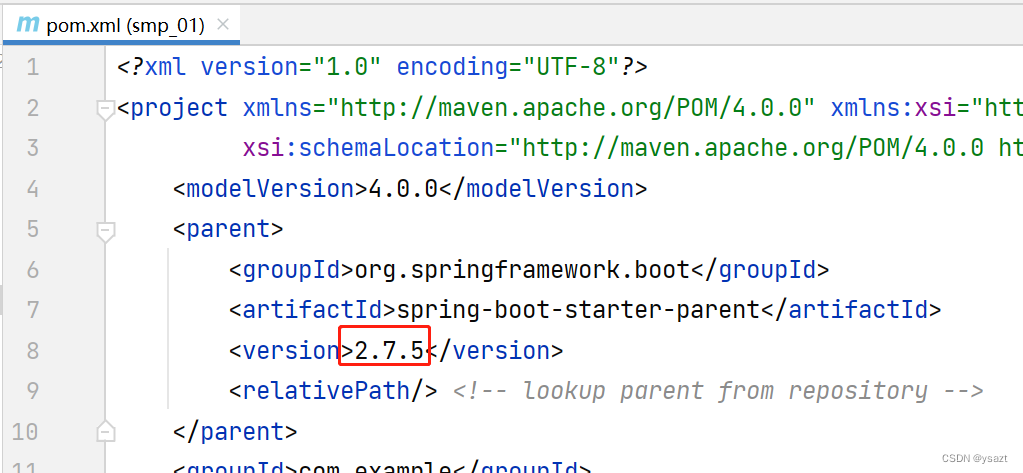
idea2023 springboot2.7.5+mybatisplus3.5.2+jsp 初学单表增删改查
创建项目 修改pom.xml 为2.7.5 引入mybatisplus 2.1 修改pom.xml <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><!--mysq…...
轻松搭建书店小程序
在现今数字化时代,拥有一个自己的小程序成为了许多企业和个人的追求。而对于书店经营者来说,拥有一个能够提供在线购书服务的小程序将有助于吸引更多的读者,并提升销售额。本文将为您介绍如何轻松搭建书店小程序,并将其成功上线。…...

Spark MLlib机器学习库(一)决策树和随机森林案例详解
Spark MLlib机器学习库(一)决策树和随机森林案例详解 1 决策树预测森林植被 1.1 Covtype数据集 数据集的下载地址: https://www.kaggle.com/datasets/uciml/forest-cover-type-dataset 该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本…...
CI/CD入门(二)
CI/CD入门(二) 目录 CI/CD入门(二) 1、代码上线方案 1.1 早期手动部署代码1.2 合理化上线方案1.3 大型企业上线制度和流程1.4 php程序代码上线的具体方案1.5 Java程序代码上线的具体方案1.6 代码上线解决方案注意事项2、理解持续集成、持续交付、持续部署 2.1 持续集成2.2 持续…...
)
【BASH】回顾与知识点梳理(三十五)
【BASH】回顾与知识点梳理 三十五 三十五. 二十七至三十四章知识点总结及练习35.1 总结35.2 练习RAIDLVMsystemd 35.3 简答题 该系列目录 --> 【BASH】回顾与知识点梳理(目录) 三十五. 二十七至三十四章知识点总结及练习 35.1 总结 Quota 可公平的分…...
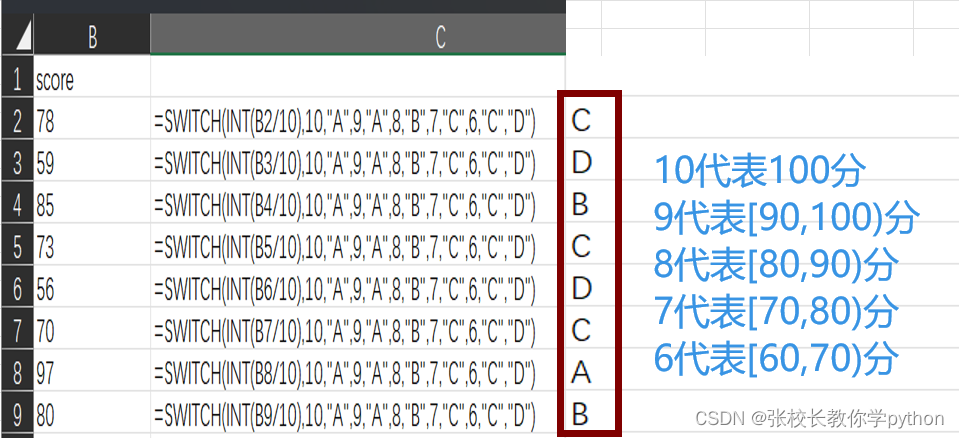
excel逻辑函数篇2
1、IF(logical_test,[value_if_true],[value_if_false]):判断是否满足某个条件,如果满足返回一个值,如果不满足则返回另一个值 if(条件,条件成立返回的值,条件不成立返回的值) 2、IFS(logical_test1,value_if_true1,…):检查是否…...

设计模式详解-解释器模式
类型:行为型模式 实现原理:实现了一个表达式接口,该接口使用标识来解释语言中的句子 作用:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器来解释。 主要解决:一些重…...

如何在React项目中动态插入HTML内容
React是一种流行的JavaScript库,用于构建用户界面。它提供了一种声明式的方法来创建可复用的组件,使得开发者能够更轻松地构建交互性的Web应用程序。在React中,我们通常使用JSX语法来描述组件的结构和行为。 在某些情况下,我们可…...
十六、Spring Cloud Sleuth 分布式请求链路追踪
目录 一、概述1、为什么出出现这个技术?需要解决哪些问题2、是什么?3、解决 二、搭建链路监控步骤1、下载运行zipkin2、服务提供者3、服务调用者4、测试 一、概述 1、为什么出出现这个技术?需要解决哪些问题 2、是什么? 官网&am…...

ElasticSearch DSL语句(bool查询、算分控制、地理查询、排序、分页、高亮等)
文章目录 DSL 查询种类DSL query 基本语法1、全文检索2、精确查询3、地理查询4、function score (算分控制)5、bool 查询 搜索结果处理1、排序2、分页3、高亮 RestClient操作 DSL 查询种类 查询所有:查询所有数据,一般在测试时使…...
)
【考研数学】概率论与数理统计 | 第一章——随机事件与概率(2,概率基本公式与事件独立)
文章目录 引言四、概率基本公式4.1 减法公式4.2 加法公式4.3 条件概率公式4.4 乘法公式 五、事件的独立性5.1 事件独立的定义5.1.1 两个事件的独立5.1.2 三个事件的独立 5.2 事件独立的性质 写在最后 引言 承接上文,继续介绍概率论与数理统计第一章的内容。 四、概…...

SpringBoot整合RabbitMQ,笔记整理
1创建生产者工程springboot-rabbitmq-produce 2.修改pom.xml文件 <!--父工程--> <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.0</version><r…...
搜狗拼音暂用了VSCode及微信小程序开发者工具快捷键Ctrl + Shit + K 搜狗拼音截图快捷键
修改搜狗拼音的快捷键 右键--更多设置--属性设置--按键--系统功能快捷键--系统功能快捷键设置--取消Ctrl Shit K的勾选--勾选截屏并设置为Ctrl Shit A 微信开发者工具设置快捷键 右键--Command Palette--删除行 微信开发者工具快捷键 删除行:Ctrl Shit K 或…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...
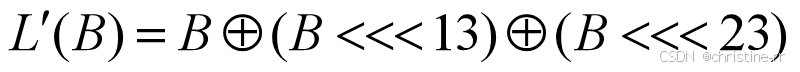
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

机器学习的数学基础:线性模型
线性模型 线性模型的基本形式为: f ( x ) ω T x b f\left(\boldsymbol{x}\right)\boldsymbol{\omega}^\text{T}\boldsymbol{x}b f(x)ωTxb 回归问题 利用最小二乘法,得到 ω \boldsymbol{\omega} ω和 b b b的参数估计$ \boldsymbol{\hat{\omega}}…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...