【开源项目】Stream-Query的入门使用和原理分析
前言
无意间发现了一个有趣的项目,Stream-Query。了解了一下其基本的功能,可以帮助开发者省去Mapper的编写。在开发中,我们会编写entity和mapper来完成业务代码,但是Stream-Query可以省去mapper,只写entity。
快速入门
实体类
@Data
public class UserInfo{private static final long serialVersionUID = -7219188882388819210L;@TableId(value = "id", type = IdType.AUTO)private Long id;private String name;private Integer age;private String email;
}
创表语句
create table user_info
(id bigint auto_increment comment '主键'primary key,name varchar(20) null comment '姓名',age int comment '年龄',email varchar(20) comment '邮件'
)comment '用户信息';
配置扫描包
@EnableMybatisPlusPlugin(basePackages = "com.charles.entity.**")
插入Demo
@GetMapping("/t1")public void t1() {UserInfo userInfo = new UserInfo();userInfo.setAge(12);userInfo.setEmail("123@qq.com");userInfo.setName("张三");UserInfo userInfo2 = new UserInfo();userInfo2.setAge(123);userInfo2.setEmail("123@qq.com");userInfo2.setName("李四");Database.saveFewSql(Arrays.asList(userInfo, userInfo2));}
单个查询Demo
@GetMapping("t2")public void t2() {UserInfo userInfo = One.of(UserInfo::getId).eq(2L).query();System.out.println(userInfo);}
多个查询Demo
@GetMapping("t3")public void t3() {QueryCondition.query(UserInfo.class).in(UserInfo::getName, Lists.of("张三", "李四"));QueryCondition<UserInfo> wrapper =QueryCondition.query(UserInfo.class).in(UserInfo::getName, Lists.of("张三", "李四"));List<UserInfo> list = Database.list(wrapper);Map<Long, UserInfo> idUserMap = OneToOne.of(UserInfo::getId).eq(1L).query();System.out.println(list);}
Stream-Query通过Database,One,Many等静态方法完成查询和插入等操作。
核心原理分析
EnableMybatisPlusPlugin注入了StreamConfigurationSelector。
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
@Documented
@Inherited
@Import({StreamConfigurationSelector.class})
public @interface EnableMybatisPlusPlugin {/*** Alias for {@link #basePackages()}** @return base packages*/String[] value() default {};/*** Base packages** @return base packages*/String[] basePackages() default {};
}
StreamConfigurationSelector注入了StreamScannerRegistrar扫描注册器和StreamPluginAutoConfiguration配置类。
public class StreamConfigurationSelector implements DeferredImportSelector, Ordered {@Overridepublic String[] selectImports(AnnotationMetadata metadata) {return new String[] {StreamScannerRegistrar.class.getName(), StreamPluginAutoConfiguration.class.getName()};}@Overridepublic int getOrder() {return HIGHEST_PRECEDENCE;}
}StreamScannerRegistrar注入了StreamScannerConfigurer扫描类。
public class StreamScannerRegistrar implements ImportBeanDefinitionRegistrar {@Overridepublic void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {AnnotationAttributes annotationAttributes =AnnotationAttributes.fromMap(importingClassMetadata.getAnnotationAttributes(EnableMybatisPlusPlugin.class.getName()));if (Objects.isNull(annotationAttributes)) {return;}BeanDefinitionBuilder builder =BeanDefinitionBuilder.genericBeanDefinition(StreamScannerConfigurer.class);Set<String> basePackages = new HashSet<>();basePackages.addAll(Arrays.stream(annotationAttributes.getStringArray("value")).filter(StringUtils::hasText).collect(Collectors.toSet()));basePackages.addAll(Arrays.stream(annotationAttributes.getStringArray("basePackages")).filter(StringUtils::hasText).collect(Collectors.toSet()));basePackages.addAll(Arrays.stream(annotationAttributes.getClassArray("basePackageClasses")).filter(Objects::nonNull).map(ClassUtils::getPackageName).collect(Collectors.toSet()));if (basePackages.isEmpty()) {basePackages.add(ClassUtils.getPackageName(importingClassMetadata.getClassName()));builder.addPropertyValue("emptyBasePackages", true);}builder.addPropertyValue("basePackages", basePackages);Set<Class<?>> classes =Arrays.stream(annotationAttributes.getClassArray("classes")).filter(Objects::nonNull).collect(Collectors.toSet());builder.addPropertyValue("classes", classes);Class<? extends Annotation> annotation = annotationAttributes.getClass("annotation");if (!Annotation.class.equals(annotation)) {builder.addPropertyValue("annotation", annotation);}Class<?> scanInterface = annotationAttributes.getClass("interfaceClass");if (!Class.class.equals(scanInterface)) {builder.addPropertyValue("interfaceClass", scanInterface);}registry.registerBeanDefinition("streamScannerConfigurer", builder.getBeanDefinition());}
}StreamScannerConfigurer实现了BeanFactoryPostProcessor,StreamScannerConfigurer#postProcessBeanFactory可以根据注解扫描,可以根据接口扫描,可以根据扫描包扫描。详情可见 enablemybatisplusplugin。
@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)throws BeansException {defaultScanConfig();// 指定类registerEntityClasses(this.classes);StreamClassPathScanner scanner = new StreamClassPathScanner(false);scanner.setAnnotation(this.annotation);scanner.setInterfaceClass(this.interfaceClass);scanner.registerFilters();Set<Class<?>> classSet = scanner.scan(this.basePackages);registerEntityClasses(classSet);}
在StreamPluginAutoConfiguration配置类中注入了DynamicMapperHandler。
@Bean@ConditionalOnMissingBean(DynamicMapperHandler.class)public DynamicMapperHandler dynamicMapperHandler(SqlSessionFactory sqlSessionFactory, StreamScannerConfigurer streamScannerConfigurer) {return new DynamicMapperHandler(sqlSessionFactory, streamScannerConfigurer.getEntityClasses());}
DynamicMapperHandler该类的作用就是根据传入的entity的列表,构建Mapper。
public class DynamicMapperHandler {public DynamicMapperHandler(SqlSessionFactory sqlSessionFactory, Collection<Class<?>> entityClassList) {Configuration configuration = sqlSessionFactory.getConfiguration();if (configuration instanceof MybatisConfiguration) {MybatisConfiguration mybatisConfiguration = (MybatisConfiguration) configuration;entityClassList.forEach(entityClass -> Database.buildMapper(mybatisConfiguration, entityClass));}}
}
Database#buildMapper,根据ByteBuddy来生成对应的接口实现。
public static void buildMapper(Configuration configuration, Class<?> entityClass) {if (!(configuration instanceof MybatisConfiguration)) {throw new IllegalArgumentException("configuration must be MybatisConfiguration");}Maps.computeIfAbsent(ENTITY_MAPPER_CLASS_CACHE,entityClass,k -> {Class<?> dynamicMapper =new ByteBuddy().makeInterface(TypeDescription.Generic.Builder.parameterizedType(IMapper.class, entityClass).build()).name(String.format("%s.%sMapper",PluginConst.DYNAMIC_MAPPER_PREFIX, entityClass.getSimpleName())).make().load(ClassUtils.class.getClassLoader()).getLoaded();configuration.addMapper(dynamicMapper);return dynamicMapper;});}
以上就是项目初始化的流程,StreamQuery帮助我们完成了根据Entity来自动生成Mapper,接下来我们分析一下StreamQuery是如何帮助我们简化使用的。
Database#saveFewSql(java.util.Collection<T>),保存操作,获取SqlSession,获取IMapper,执行saveFewSql的方法。
public static <T> boolean saveFewSql(Collection<T> entityList) {return saveFewSql(entityList, PluginConst.DEFAULT_BATCH_SIZE);}public static <T> boolean saveFewSql(Collection<T> entityList, int batchSize) {if (CollectionUtils.isEmpty(entityList) || batchSize <= 0) {return false;}return execute(getEntityClass(entityList),(IMapper<T> baseMapper) ->entityList.size() == baseMapper.saveFewSql(entityList, batchSize));}public static <T, R, M extends BaseMapper<T>> R execute(Class<T> entityClass, SFunction<M, R> sFunction) {SqlSession sqlSession = SqlHelper.sqlSession(entityClass);try {return sFunction.apply(getMapper(entityClass, sqlSession));} finally {SqlSessionUtils.closeSqlSession(sqlSession, GlobalConfigUtils.currentSessionFactory(entityClass));}}
IMapper#saveFewSql,默认实现是批量拆分List,调用saveOneSql。
/*** 批量插入** @param list 集合* @param batchSize 分割量* @return 是否成功*/default long saveFewSql(Collection<T> list, int batchSize) {return Steam.of(list).splitList(batchSize).mapToLong(this::saveOneSql).sum();}
补充了解
One
One,返回单个实体类。通过封装Database来完成查询单个操作。
/*** query.** @return a V object*/public V query() {return Sf.of(Database.getOne(wrapper)).mayAlso(peekConsumer).mayLet(valueOrIdentity()).get();}
QueryCondition
QueryCondition查询条件类,继承了LambdaQueryWrapper。
也就是new LambdaQueryWrapper<UserInfo>().in(UserInfo::getName, Lists.of("张三", "李四"));等于QueryCondition<UserInfo> wrapper = QueryCondition.query(UserInfo.class).in(UserInfo::getName, Lists.of("张三", "李四"));
public class QueryCondition<T> extends LambdaQueryWrapper<T> {public static <T> QueryCondition<T> query(Class<T> entityClass) {QueryCondition<T> condition = new QueryCondition<>();condition.setEntityClass(entityClass);return condition;}
OneToOne
OneToOne封装了一层Stream的操作。
public Map<K, V> query() {return query(HashMap::new);}/*** query.** @param mapFactory a {@link java.util.function.IntFunction} object* @param <R> a R class* @return a R object*/public <R extends Map<K, V>> R query(IntFunction<R> mapFactory) {List<T> list = Database.list(wrapper);return Steam.of(list).parallel(isParallel).peek(peekConsumer).toMap(keyFunction,valueOrIdentity(),SerBiOp.justAfter(),() -> mapFactory.apply(list.size()));}
AsyncHelper
AsyncHelper使用
public static void main(String[] args) {List<String> result = AsyncHelper.supply(() -> {System.out.println(Thread.currentThread().getName() + "1111");return "123";}, () -> {System.out.println(Thread.currentThread().getName() + "2345");return "456";});System.out.println(result);}
原理分析,可以指定拦截器和线程池,使用CompletableFuture.supplyAsync来完成异步执行。
@SafeVarargspublic static <T> List<T> supply(AsyncConfig asyncConfig, SerSupp<T>... suppliers) {AsyncInterceptor interceptor = asyncConfig.getInterceptor();interceptor.before();CompletableFuture<T>[] futures = (CompletableFuture[])Steam.of(suppliers).map((supplier) -> {return CompletableFuture.supplyAsync(() -> {return interceptor.execute(supplier);}, asyncConfig.getExecutor());}).toArray((x$0) -> {return new CompletableFuture[x$0];});CompletableFuture var10000 = CompletableFuture.allOf(futures);interceptor.getClass();CompletableFuture<Void> exceptionally = var10000.exceptionally(interceptor::onError);(() -> {return asyncConfig.getTimeout() == -1 ? exceptionally.get() : exceptionally.get((long)asyncConfig.getTimeout(), asyncConfig.getTimeUnit());}).get();interceptor.after();return Steam.of(futures).map(CompletableFuture::get).toList();}

相关文章:
【开源项目】Stream-Query的入门使用和原理分析
前言 无意间发现了一个有趣的项目,Stream-Query。了解了一下其基本的功能,可以帮助开发者省去Mapper的编写。在开发中,我们会编写entity和mapper来完成业务代码,但是Stream-Query可以省去mapper,只写entity。 快速入…...

微信小程序picker组件的简单使用 单选
<picker mode"selector" range"{{classData}}" bindchange"bindClassChange" value"{{classIndex}}" range-key"className"><view class"picker">{{classData[classIndex].className || 请选择班级}}…...
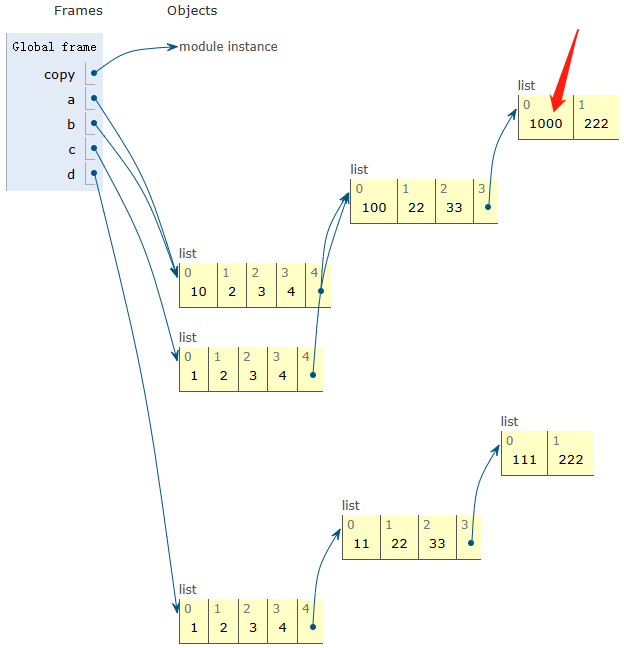
python、numpy、pytorch中的浅拷贝和深拷贝
1、Python中的浅拷贝和深拷贝 import copya [1, 2, 3, 4, [11, 22, 33, [111, 222]]] b a c a.copy() d copy.deepcopy(a)print(before modify\r\n a\r\n, a, \r\n,b a\r\n, b, \r\n,c a.copy()\r\n, c, \r\n,d copy.deepcopy(a)\r\n, d, \r\n)before modify a [1, 2…...

EasyRecovery14数据恢复软件支持各类存储设备的数据恢复
EasyRecovery14数据恢复软件专业数据恢复软件支持电脑、相机、移动硬盘、U盘、SD卡、内存卡、光盘、本地电子邮件和 RAID 磁盘阵列等各类存储设备的数据恢复。 目前市面上有许多数据恢复软件,但褒贬不一,而且数据恢复软件又不是一款会被经常使用的软件&a…...
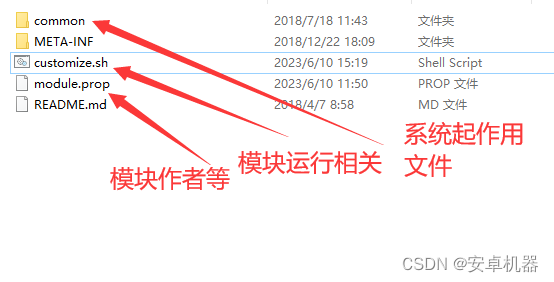
玩机搞机----面具模块的组成 制作模块
root面具相信很多玩家都不陌生。早期玩友大都使用第三方卡刷补丁来对系统进行各种修复和添加功能。目前面具补丁代替了这些操作。今天的帖子了解下面具各种模块的组成和几种普遍的代码组成。 Magisk中运行的每个单独的shell脚本都将在内部的BusyBox的shell中执行。对于与第三方…...
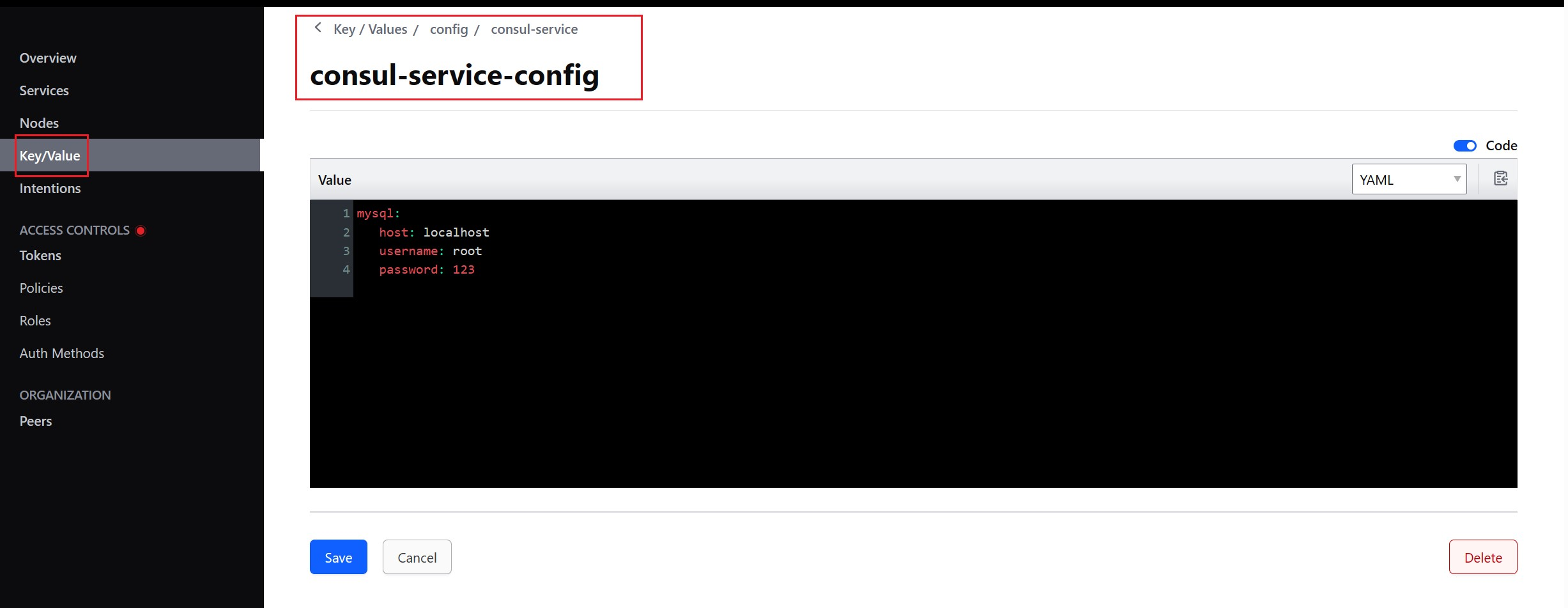
注册中心/配置管理 —— SpringCloud Consul
Consul 概述 Consul 是一个可以提供服务发现,健康检查,多数据中心,key/Value 存储的分布式服务框架,用于实现分布式系统的发现与配置。Cousul 使用 Go 语言实现,因此天然具有可移植性,安装包仅包含一个可执…...
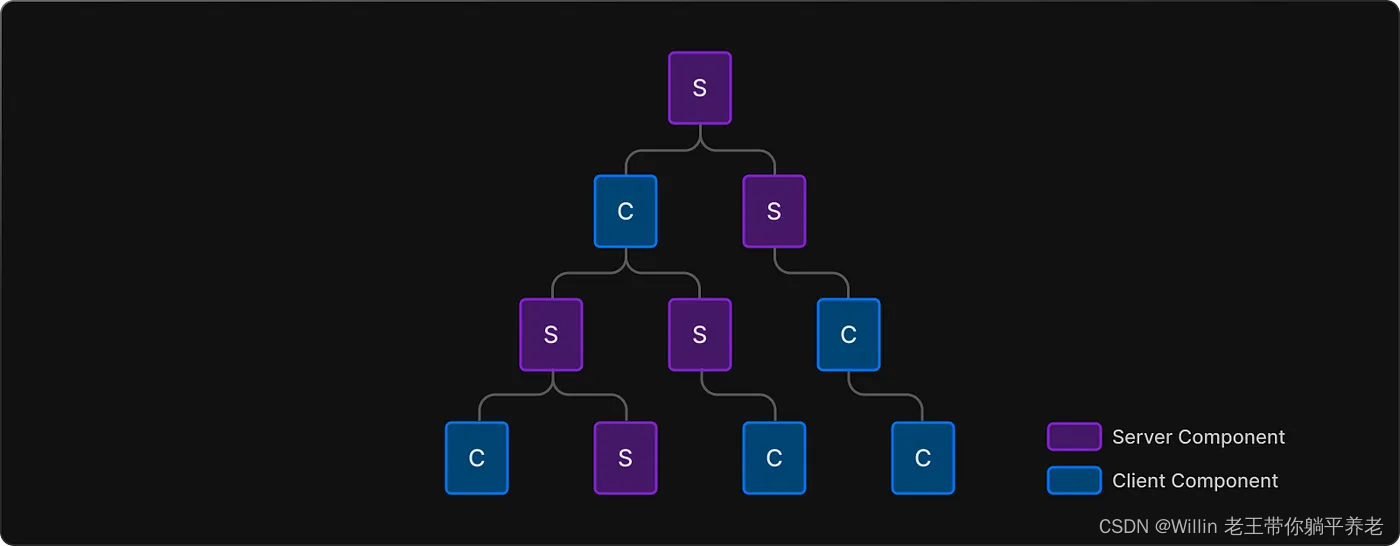
Next.js 13 你需要了解的 8 件事
目录 React 服务器组件 (RSC)服务器组件默认开启在 Next.js 中客户端组件也在服务器上呈现!组成客户端和服务器组件编译Next.js 13 渲染模式桶文件有点坏了库集成:WIP 仍在进行中Route groups 路由组总结 在本文中,我们…...
算法详解)
计数排序(Count Sort)算法详解
1. 算法简介 计数排序(Count Sort)是一种非比较排序算法,其核心思想是统计数组中每个元素出现的次数,然后根据统计结果将元素按照顺序放回原数组中。计数排序的时间复杂度为O(nk),其中n是数组的长度,k是数…...
Linux驱动开发(Day3)
驱动点灯:...
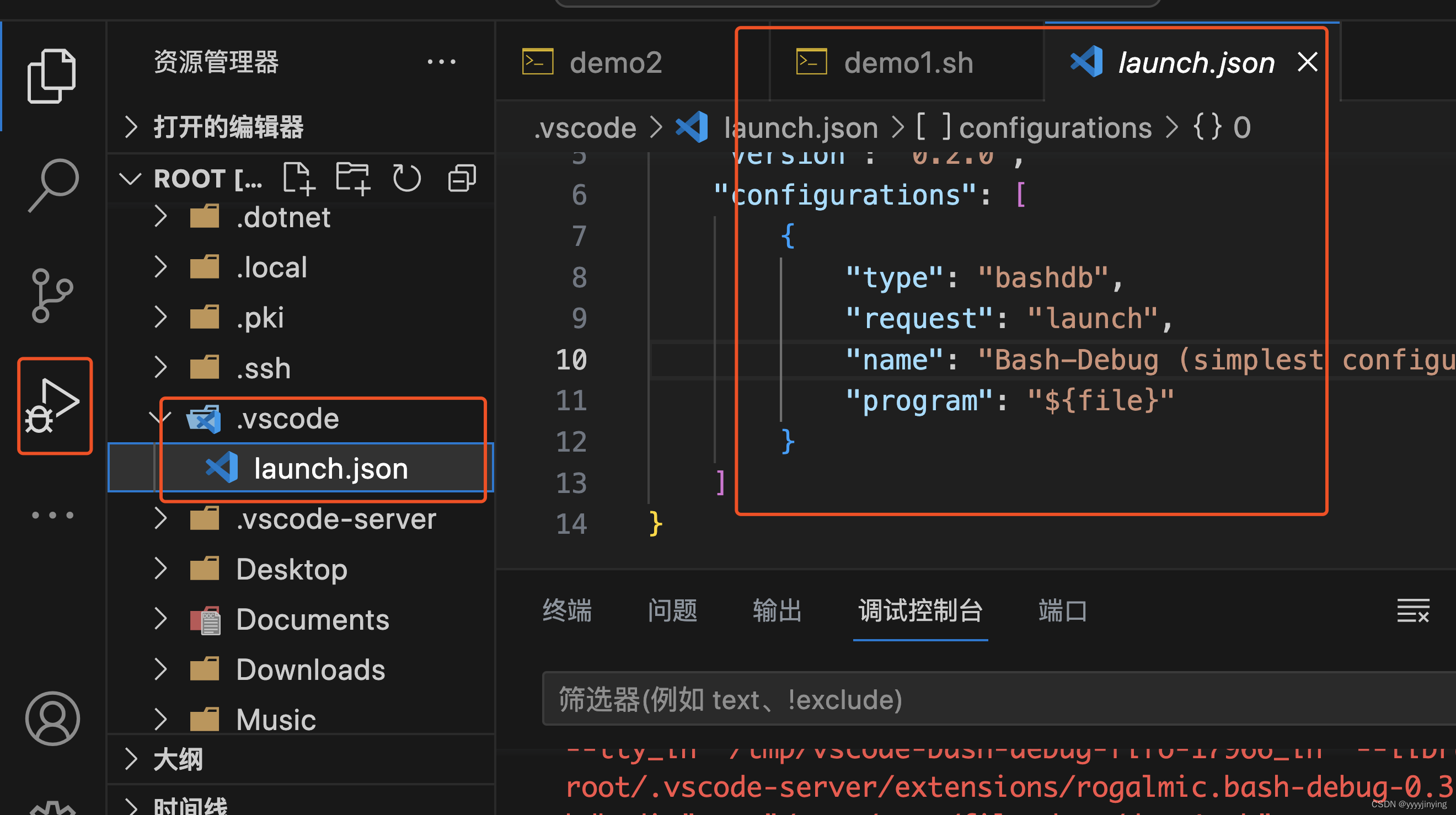
使用Vscode调试shell脚本
在vcode中安装bash dug插件 在vcode中添加launch.json配置,默认就好 参考:http://www.rply.cn/news/73966.html 推荐插件: shellman(支持shell,智能提示) shellcheck(shell语法检查) shell-format(shell格式化)...

OpenAI Function calling
开篇 原文出处 最近 OpenAI 在 6 月 13 号发布了新 feature,主要针对模型进行了优化,提供了 function calling 的功能,该 feature 对于很多集成 OpenAI 的应用来说绝对是一个“神器”。 Prompt 的演进 如果初看 OpenAI 官网对function ca…...

【C语言】字符分类函数、字符转换函数、内存函数
前言 之前我们用两篇文章介绍了strlen、strcpy、stract、strcmp、strncpy、strncat、strncmp、strstr、strtok、streeror这些函数 第一篇文章strlen、strcpy、stract 第二篇文章strcmp、strncpy、strncat、strncmp 第三篇文章strstr、strtok、streeror 今天我们就来学习字…...
Deep Learning With Pytorch - 最基本的感知机、贯序模型/分类、拟合
文章目录 如何利用pytorch创建一个简单的网络模型?Step1. 感知机,多层感知机(MLP)的基本结构Step2. 超平面 ω T ⋅ x b 0 \omega^{T}xb0 ωT⋅xb0 or ω T ⋅ x b \omega^{T}xb ωT⋅xb感知机函数 Step3. 利用感知机进行决策…...
测试工具coverage的高阶使用
在文章Python之单元测试使用的一点心得中,笔者介绍了自己在使用Python测试工具coverge的一点心得,包括: 使用coverage模块计算代码测试覆盖率使用coverage api计算代码测试覆盖率coverage配置文件的使用coverage badge的生成 本文在此基础上…...

安卓监听端口接收消息
文章目录 其他文章监听端口接收消息 建立新线程完整代码 其他文章 下面是我的另一篇文章,是在电脑上发送数据,配合本篇文章,可以实现电脑与手机的局域网通讯。直接复制粘贴就能行,非常滴好用。 点击连接 另外,如果你不…...

「Node」下载安装配置node.js
以下是Node.js的下载、安装和配置的全面教程: 下载 Node.js 打开 Node.js 官方网站:Previous Releases在主页上,您会看到两个版本可供选择:LTS(长期支持版本)和最新版(Current)。如…...
NOIP2014普及组,提高组 比例简化 飞扬的小鸟 答案
比例简化 说明 在社交媒体上,经常会看到针对某一个观点同意与否的民意调查以及结果。例如,对某一观点表示支持的有1498 人,反对的有 902人,那么赞同与反对的比例可以简单的记为1498:902。 不过,如果把调查结果就以这种…...

【Java】使用Apache POI识别PPT中的图片和文字,以及对应的大小、坐标、颜色、字体等
本文介绍如何使用Apache POI识别PPT中的图片和文字,获取图片的数据、大小、尺寸、坐标,以及获取文字的字体、大小、颜色、坐标。 官方文档:https://poi.apache.org/components/slideshow/xslf-cookbook.html 官方文档和网上的资料介绍的很少…...

根据源码,模拟实现 RabbitMQ - 实现消息持久化,统一硬盘操作(3)
目录 一、实现消息持久化 1.1、消息的存储设定 1.1.1、存储方式 1.1.2、存储格式约定 1.1.3、queue_data.txt 文件内容 1.1.4、queue_stat.txt 文件内容 1.2、实现 MessageFileManager 类 1.2.1、设计目录结构和文件格式 1.2.2、实现消息的写入 1.2.3、实现消息的删除…...
)
找到所有数组中消失的数(C语言详解)
题目:找到所有数组中消失的数 题目详情: 给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1,n] 内。请你找出所以在 [1,n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。 示例1: 输入…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...