深度优先搜索算法
目录
4.1 二叉树的最大深度(简单):深度优先搜索
4.2 对称二叉树(简单):递归
4.3 岛屿数量(中等):深度优先搜索
4.4 岛屿的最大面积(中等):深度优先搜索
4.5 路径总和(简单):深度优先搜索
4.6 被围绕的区域(中等):深度优先搜索
4.7 路径总和Ⅱ(中等):深度优先搜索
4.8 树的子结构(中等):前序遍历 + 递归
4.9 合并二叉树(简单):深度优先搜索
4.10 二叉搜索树的最近公共祖先(中等):两次遍历
4.11 所有可能的路径(中等):深度优先搜索 + 递归
4.12 省份数量(中等):深度优先搜索
4.13 深度优先搜索的总结
4.1 二叉树的最大深度(简单):深度优先搜索
题目:给定一个二叉树 root ,返回其最大深度。二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
思想:对于树而言,可以使用递归的方式来计算根节点的左右子节点的最大深度,因此二叉树的最大深度应该等于:
-
左右子节点最大深度 + 1
总结:元素对应的最小路径和与其相邻元素的最小路径和有关,因此可以采用动态规划,具体是:
-
元素对应的最小路径和 = min(上方相邻元素对应的最小路径和,左方相邻元素对应的最小路径和) + 当前元素值
-
设
dp[i][j]表示从左上角出发到[i][j]的最小路径和:有:dp[i][j] = min(dp[i-1][j],dp[i][j-1]) + grid[i][j]
-
-
特殊情况:
-
只有一个点:
dp[0][0] = grid[0][0];第一个数的最小路径和为该数的值 -
只有一行:
i=0,dp[0][j] = dp[0][j-1] + grid[0][j] -
只有一列:
j=0,dp[i][0] = dp[i-1][0] + grid[i][0]
-
代码:
class Solution {public int maxDepth(TreeNode root) {//根节点为nullif(root == null){return 0;}//只有根节点if(root.left == null && root.right == null){return 1;}//根节点存在左右子树;则比较左右子树的最大深度,取其较大值 + 1int max_Depth = 0;//得到左子树的最大深度if(root.left != null){max_Depth = Math.max(maxDepth(root.left),max_Depth);}//得到右子树的最大深度if(root.right != null){max_Depth = Math.max(maxDepth(root.right),max_Depth);}
return max_Depth + 1;
}
}4.2 对称二叉树(简单):递归
题目:给你一个二叉树的根节点 root , 检查它是否轴对称
思想:可以先实现一个递归函数,使用两个指针p和q同步遍历树,两个指针开始时都指向根节点,随后p右移时,q左移;p左移时,q右移;检查当前指针值是否相等
总结:判断二叉树是否对称,只需看:
-
根节点是否一致
-
左右子树是否值相等且对称
可将一个root作两个用,然后分别比较root的左右子树值是否都相等
-
代码:
class Solution {public boolean isSymmetric(TreeNode root) {return check(root, root);}
public boolean check(TreeNode p, TreeNode q) {//先判断是否为空if (p == null && q == null) {return true;}//比较根节点是否相等if (p == null || q == null) {return false;}//比较根节点值是否都相同;然后比较p的左子树与q的右子树是否相等,并比较p的右子树与q的左子树是否相等return p.val == q.val && check(p.left, q.right) && check(p.right, q.left);}
}4.3 岛屿数量(中等):深度优先搜索
题目:给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
思想:其实这是一个寻找连通块数量的问题,岛屿只能从1开始,然后寻找与它相连接(上下左右)的1的数量,每一次找寻完毕后就说明这个连通块是一个岛屿;然后将找过的连通块中的元素由1设置为0(同一个岛屿在下一次找寻时是不会在此搜索的)
总结:深度优先搜索会从当前值开始,沿着某个节点一直走下去,直到结束,然后进行其它方向的搜索,直到搜索完相邻节点,我们只需给出搜索的起点与搜索方法即可;
-
注意边界条件:对于数组而言不能超出左右边界
[0, maxLength];
代码:
class Solution {public int numIslands(char[][] grid) {//grid为空直接返回0if(grid == null || grid.length == 0){return 0;}
//找到grid的行与列,为DFS做准备 int row = grid.length;int column = grid[0].length;
//设置常量记录连通块(岛屿)数量int num_Islands = 0;
//进行DFS查找for(int i = 0; i < row; i++){for(int j = 0; j < column; j++){//岛屿的前提条件是值为1if(grid[i][j] == '1'){++num_Islands;dfs(grid, i, j);}}}return num_Islands;}
private void dfs(char[][] grid, int i, int j){//如果i、j超过边界(两种情况,要么小于0,要么大于数组长度)、数组值为0,则直接返回if(i < 0 || j < 0 || i >= grid.length || j >= grid[0].length || grid[i][j] == '0'){return;}
//将搜索过的数组值设置为'0',下一次搜索就不会在搜索到grid[i][j] = '0';
//进行深度优先搜索: 上下左右都搜索一遍dfs(grid, i - 1, j);dfs(grid, i + 1, j);dfs(grid, i, j - 1);dfs(grid, i, j + 1);}
}4.4 岛屿的最大面积(中等):深度优先搜索
题目:给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
思想:也是一个寻找连通块数量的问题,只不过找到每个连通块还需要计算寻找连通块走过的步数,为了不重复走同一个位置,将找过的连通块中的元素由1设置为0(同一个岛屿在下一次找寻时是不会在此搜索的)
总结:深度优先搜索会从当前值开始,沿着某个节点一直走下去,直到结束,然后进行其它方向的搜索,直到搜索完相邻节点,我们只需给出搜索的起点与搜索方法即可;
-
注意边界条件:对于数组而言不能超出左右边界
[0, maxLength];
代码:
class Solution {public int maxAreaOfIsland(int[][] grid) {if(grid == null || grid.length == 0 || grid[0].length == 0){return 0;}int row = grid.length;int column = grid[0].length;int res = 0;for(int i = 0; i < row; i++){for(int j = 0; j < column; j++){res = Math.max(res, dfs(grid, i, j));}}return res;}
private int dfs(int[][] grid, int curr_i, int curr_j){if(curr_i <0 || curr_j < 0 || curr_i >= grid.length || curr_j >= grid[0].length || grid[curr_i][curr_j] == 0){return 0;}grid[curr_i][curr_j] = 0;
//为了方便求出DFS走过多少步,将上下左右操作需要+ - 的两写入矩阵int[] di = {0,0,1,-1};int[] dj = {1,-1,0,0};
int res = 1;//一样进行遍历; 分上下左右的4次遍历即可for(int i = 0; i < 4; i++){int curr_i1 = curr_i + di[i];int curr_j1 = curr_j + dj[i];res += dfs(grid, curr_i1, curr_j1);}return res;}
}4.5 路径总和(简单):深度优先搜索
题目:给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false
思想:按照深度优先搜索的思想,从根节点开始,一条路走到叶子节点,并计算路径和(可以换一种思路,一条路走下去,判断目标值 targetSum 和走过的节点之差,到达叶子节点时 targetSum == currNode.val ,sum减到最后的值等于该叶子节点的值,说明是一条符合路径)
总结:深度优先搜索,就是一条路走到黑,不行再从最近路径换一条继续走到黑
-
本题的巧妙之处在于:
targetSum - root.val;将原本的求和转换思考为求目标值与每次路径差
代码:
class Solution {public boolean hasPathSum(TreeNode root, int targetSum) {//根节点为空直接返回falseif(root == null){return false;}
//如果没有左右子树说明是根节点也是叶子节点;判断值是否相等即可if(root.left == null && root.right == null){return root.val == targetSum;}
//如果存在左右子树,进行深度优先搜索;//注意:这条可行路径可能是左子树也可能是右子树;减到叶子节点时,如果该叶子节点值等于sum就说明是符合要求的路径return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);}
}4.6 被围绕的区域(中等):深度优先搜索
题目:给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充;
注意:任何边界上的 O 都不会被填充为 X;因此:所有的不被包围的 O 都直接或间接与边界上的 O 相连。我们可以利用这个性质判断 O 是否在边界上
思想:以每一个边界上的O为起点,标记与它直接或间接相连的字母O;
-
最后我们遍历这个矩阵,对于每一个字母:
-
如果该字母被标记过,则该字母为没有被字母 X 包围的字母 O,我们将其还原为字母 O;
-
如果该字母没有被标记过,则该字母为被字母 X 包围的字母 O,我们将其修改为字母 X。
-
总结:深度优先搜索,就是一条路走到黑,不行再从最近路径换一条继续走到黑
-
本题的巧妙之处在于:
targetSum - root.val;将原本的求和转换思考为求目标值与每次路径差
代码:
class Solution {public void solve(char[][] board) {//如果数组为空、只有一个值则不进行区域填充if(board == null || board.length == 0 || board[0].length == 0){return;}
//对 m * n 的左右边界进行DFS搜索for(int i = 0; i < board.length; i++){dfs(board, i, 0);dfs(board, i, board[0].length - 1);}//对 m * n 的上下边界进行DFS搜索(排除左右搜索过的节点)for(int j = 1; j < board[0].length - 1; j++){dfs(board, 0, j);dfs(board, board.length - 1, j);}
//对所有节点判断,若被标记过'isO'的就是连着边界'O'的,无法被填充为'X';将其他节点均填充为'X'即可for(int i = 0; i < board.length; i++){for(int j = 0; j < board[0].length; j++){if(board[i][j] == 'A'){board[i][j] = 'O';}else{board[i][j] = 'X';}}}
}
private void dfs(char[][] board,int row, int column){//边界条件,且只对边界上的'O'进行DFS搜索if(row < 0 || row >= board.length || column < 0 || column >= board[0].length || board[row][column] != 'O'){return;}//对于dfs的这个'O'点做一个标记,设为'isO'board[row][column] = 'A';
//进行上下左右dfs搜索dfs(board, row, column - 1);dfs(board, row, column + 1);dfs(board, row - 1, column);dfs(board, row + 1, column);}
}4.7 路径总和Ⅱ(中等):深度优先搜索
题目:给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
思想:按照深度优先搜索的思想,从根节点开始,一条路走到叶子节点,并计算路径和(可以换一种思路,一条路走下去,判断目标值 targetSum 和走过的节点之差,到达叶子节点时 targetSum == currNode.val ,sum减到最后的值等于该叶子节点的值,说明是一条符合路径)
总结:深度优先搜索,就是一条路走到黑,不行再从最近路径换一条继续走到黑
-
本题的巧妙之处在于:
targetSum - root.val;将原本的求和转换思考为求目标值与每次路径差
代码:
class Solution {public List<List<Integer>> pathSum(TreeNode root, int targetSum) {//创建一个存储结果的数组List<List<Integer>> res = new ArrayList<>();//创建一个双端队列,存储每次符合目标的路径//注意:之所以用双端队列,是因为比如一条路径走到叶子节点了,先加左节点不等于sum,此时可以在尾部删除添加的左节点,然后再在尾部加上右节点的值Deque<Integer> deque = new LinkedList<>();dfs(root, targetSum, res, deque);return res;}
private void dfs(TreeNode root, int targetSum, List<List<Integer>> res, Deque<Integer> deque){if(root == null){return;}//将节点值加入双端队列deque.offerLast(root.val);//目标值减少targetSum -= root.val;
//如果到了叶子节点且targetSum = 0;说明是符合条件的路径,将deque加入resif(root.left == null && root.right == null && targetSum == 0){res.add(new LinkedList<>(deque));}
//搜索左子树与右子树节点dfs(root.left, targetSum, res, deque);dfs(root.right, targetSum, res, deque);
//如果最后一个节点不符合要求,将最后一个节点删除deque.pollLast();
}
}4.8 树的子结构(中等):前序遍历 + 递归
题目:输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构);B是A的子结构, 即 A中有出现和B相同的结构和节点值。
思想:一棵树B是另一棵树A的子树的前提是:
-
A不能为空 -
B为空则B一定是A的子树 -
B不为空,则存在三种可能: -
B是A从根节点下出发的子结构-
此时要判断
B和A的根节点值是否相同,不同就肯定不是 -
如果
B和A的根节点值相同,则继续判断B和A的左右子树是否相同
-
-
B是A的左子树中的子结构 -
B是A的右子树中的子结构
总结:本题的重点在于:递归判断B是否为A的根节点下出发的子结构,进而判断B 的左右子树节点是否为A的左右子树节点
代码:
class Solution {public boolean isSubStructure(TreeNode A, TreeNode B) {//B是A的子节点(在同时不为空)三种情况:B是A的根节点出发的子结构、B是A左子树子结构、B是A右子树子结构return (A != null && B != null) &&(isSubRoot(A,B) || isSubStructure(A.left,B) || isSubStructure(A.right,B));}
private boolean isSubRoot(TreeNode A, TreeNode B){//B为空,则就是子结构if(B == null){return true;}
//A为空或者A、B的根节点值不同,则返回falseif(A == null || A.val != B.val){return false;}
//到这一步说明A、B的根节点值相同,则判断A、B的左右子节点是否相同//此时需要递归,因为A、B的左右子节点判断时,一样是在证明B的左右子节点是否是A的左右子节点出发的子结构(其实就是下面的情况:B是A的根节点出发的子结构);因此调用isSubRoot()即可return isSubRoot(A.left, B.left) && isSubRoot(A.right, B.right);}
}4.9 合并二叉树(简单):深度优先搜索
题目:给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。返回合并后的二叉树。注意: 合并过程必须从两个树的根节点开始。
思想:深度优先搜索合并;合并对应节点有三种情况:
-
两个节点都为空:合并后对应节点位置为空
-
只有一个节点为空:合并后对应节点位置是不为空节点的值
-
两个节点都不为空:合并后对应节点位置为两个值相加
总结:广度优先搜索的步骤:
-
从某个节点开始搜索,将该节点存入队列
-
若队列不为空,进行循环,该节点出队
-
根据路径访问该节点的相邻节点,加入队列中;直到所有节点被访问
代码:
class Solution {//合并两棵树public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {//如果任意一棵树为空,直接返回另一棵树即可if(root1 == null){return root2;}if(root2 == null){return root1;}//创建一颗新树,根节点为根节点之和TreeNode newTree = new TreeNode(root1.val + root2.val);//合并两个树的左节点newTree.left = mergeTrees(root1.left,root2.left);
//合并两个树的右节点newTree.right = mergeTrees(root1.right, root2.right);
return newTree;}
}4.10 二叉搜索树的最近公共祖先(中等):两次遍历
题目:给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先(和1.11题解可以一样,但是二叉搜索树具有特定性质,可以根据其性质进行求解)
-
最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
思想:二叉搜索树的特点在于:有序;节点的左子树都比该节点小,节点的右子树都比该节点大;使用二次遍历法,对于节点p而言
-
从根节点遍历:
-
如果当前节点为
p,则找到节点 -
如果当前节点值大于
p,则p在当前节点的左子树 -
如果当前节点值小于
p,则p在当前节点的右子树 -
寻找节点的同时,记录走过的节点,当找到
p与q的路径pathP[i]和pathQ[i]后,p和q路径上的最后一个相同点就是最近公共祖先;即pathP[i] = pathQ[i]时只要i最大即可
总结:首先需要读懂题意,然后才能入手解决这种较为复杂的问题,可以设置一个专门判断是否存在节点p、q的函数,从而根据两种情况递归的使用该函数,最终得到结果
代码:
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {//拿到从根节点找到p或者q的路径List<TreeNode> pathP = getPath(root, p); List<TreeNode> pathQ = getPath(root, q);TreeNode ancestor = new TreeNode();//找到路径后,拿到两数组相等时的最大节点就是最近公共祖先for(int i = 0; i < pathP.size() && i < pathQ.size(); i++){if(pathP.get(i) == pathQ.get(i)){ancestor = pathP.get(i);}}return ancestor;}
private List<TreeNode> getPath(TreeNode root, TreeNode p){//创建接收走过路径的数组List<TreeNode> res = new ArrayList<>();TreeNode node = root;
//如果root值不等于p的值:根据p与root的左右节点的大小判断p在左子树还是右子树while(node.val != p.val){res.add(node);if(p.val < node.val){node = node.left;}else{node = node.right;}}//如果root值等于p的值,也要放进数组,表示从根节点找到了pres.add(node);return res;}
}4.11 所有可能的路径(中等):深度优先搜索 + 递归
题目:给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
思想:使用深度优先搜索求出可能路径,从0出发,使用栈记录路径上的点,每次遍历到n - 1就将栈中的记录加入答案中
-
有向无环图说明不会遍历同一个点,因此无法判断是否遍历过
总结:首先需要读懂题意,然后才能入手解决这种较为复杂的问题,可以设置一个专门判断是否存在节点p、q的函数,从而根据两种情况递归的使用该函数,最终得到结果
代码:
class Solution {//设置一个二维集合用来记录所有路径List<List<Integer>> res = new ArrayList<>();//设置一个栈用来辅助深度优先搜索:栈的实现不再用stack而是用deque代替;栈的作用就是从一个节点的路径出发,如果一条路走到黑,可以方便的回到上一个节点继续向另一条路出发(因为栈是先入后出的,可以保证前面的路径正确,只是最后一条路走到了头);最后将走到头的栈的值存入二维集合中即可Deque<Integer> stack = new LinkedList<>();
public List<List<Integer>> allPathsSourceTarget(int[][] graph) {//从节点0出发,因此栈中第一个元素是节点0stack.offerLast(0);//搜索:从节点0到节点n - 1的路径dfs(graph, 0, graph.length - 1);return res;}
private void dfs(int[][] graph, int x, int n){//如果搜索到n - 1节点,则将其加入集合中(注意此时的n就是graph.length - 1即n - 1)if(x == n){res.add(new ArrayList<Integer>(stack));return;}
//如果还没搜索到最后一个节点,则从节点0所在索引的所有值出发搜索for(int y : graph[x]){stack.offerLast(y);//从节点0索引的每一个值出发搜索路径即可dfs(graph, y, n);//每次搜索完毕后出栈stack.pollLast();}}
}4.12 省份数量(中等):深度优先搜索
题目:有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。返回矩阵中 省份 的数量。
思想:其实就是求一个矩阵中的连通块数量,使用深度优先搜索:
-
遍历所有城市,如果城市未被访问过,则从该城市开始深度优先搜索
-
通过
isConnected可以知道该城市与哪个城市相连-
相连城市就是一个连通分量,直到同一个连通分量的所有城市都被访问到,就能够得到一个省份;
-
-
最终所有连通分量的总数就是省份总数
总结:广度优先搜索的步骤:
-
从某个节点开始搜索,将该节点存入队列
-
若队列不为空,进行循环,该节点出队
-
根据路径访问该节点的相邻节点,加入队列中;直到所有节点被访问
代码:
class Solution {public int findCircleNum(int[][] isConnected) {//城市数量int city = isConnected.length;//设置省份数量int province = 0;boolean[] isVisited = new boolean[city];//遍历所有城市,如果城市未被访问过,则进行深度优先搜索 for(int i = 0; i < city; i++){if(isVisited[i] == false){dfs(isConnected, city, i, isVisited);province++;}}return province;}
//从当前节点对所有城市进行深度优先搜索,路径按照isConnected中给出,访问过后将状态修改为true(默认为false)private void dfs(int[][] isConnected, int city, int i, boolean[] isVisited){for(int j = 0; j < city; j++){if(isConnected[i][j] == 1 && isVisited[j] == false){isVisited[j] = true;//当前节点搜索后,从相邻节点继续搜索dfs(isConnected, city, j, isVisited);}}}
}4.13 深度优先搜索的总结
-
思想:深度优先搜索就是一条路走到黑,从某个节点出发,然后一直走到头,然后从上一个节点继续出发走到头,直到所有节点都搜索完毕;
-
实现:实现深度优先搜索时,应注意三点:
-
观察节点出发的路径如何实现,在数组中经常是上下左右的实现,比如
-
//进行深度优先搜索: 上下左右都搜索一遍dfs(grid, i - 1, j);dfs(grid, i + 1, j);dfs(grid, i, j - 1);dfs(grid, i, j + 1); //或者利用循环for(int j = 0; j < city; j++){if(isConnected[i][j] == 1 && isVisited[j] == false){isVisited[j] = true;//当前节点搜索后,从相邻节点继续搜索dfs(isConnected, city, j, isVisited);}} -
节点访问过后的标记,通常是使用
boolean[] flag标记即可,访问后设置为true -
访问过的节点路径的存储,特殊情况下要用到栈
-
相关文章:

深度优先搜索算法
目录 4.1 二叉树的最大深度(简单):深度优先搜索 4.2 对称二叉树(简单):递归 4.3 岛屿数量(中等):深度优先搜索 4.4 岛屿的最大面积(中等)&…...

k8s ----POD控制器详解
目录 一:pod控制器 1、Pod控制器及其功用 2、pod控制器类型 3、Pod与控制器之间的关系 二:Deployment 三:SatefulSet 1、StatefulSet组成 2、为什么要有headless? 3、为什么要有volumeClaimTemplate? 4、实现…...
ReactNative进阶(三十四):ipa Archive 阶段报错error: Multiple commands produce问题修复及思考
文章目录 一、前言二、问题描述三、问题解决四、拓展阅读五、拓展阅读 一、前言 在应用RN开发跨平台APP阶段,从git中拉取项目,应用Jenkins进行组包时,发现最终生成的ipa安装包版本号始终与项目中设置的版本号不一致。 二、问题描述 经过仔…...

MySQL索引ES索引
MySQL MySQL索引的种类 按照索引列值的唯一性:索引可分为唯一索引和非唯一索引; 唯一索引:此索引的每一个索引值只对应唯一的数据记录,对于单列唯一性索引,这保证单列不包含重复的值。对于多列唯一性索引,保证多个值的组合不重复。主键索引是唯一索引的特定类型。该索引…...
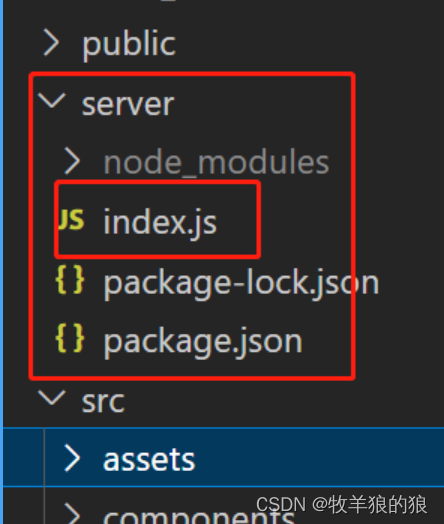
webSocket 聊天室 node.js 版
全局安装vue脚手架 npm install vue/cli -g 创建 vue3 ts 脚手架 vue create vue3-chatroom 后端代码 src 同级目录下建 server: const express require(express); const app express(); const http require(http); const server http.createServer(app);const io req…...
iptables防火墙(SNAT与DNAT)
目录 1 SNAT 1.1 SNAT原理与应用 1.2 SNAT工作原理 1.3 SNAT转换前提条件 2 SNAT示例 编辑 2.1 网关服务器配置 2.1.1 网关服务器配置网卡 2.1.2 开启SNAT命令 2.2 内网服务器端配置 2.3 外网服务器端配置 2.4 网卡服务器端添加规则 2.5 SNAT 测试 3 DNAT 3.1 网卡…...
第 359 场 LeetCode 周赛题解
A 判别首字母缩略词 签到题… class Solution { public:bool isAcronym(vector<string> &words, string s) {string pf;for (auto &s: words)pf.push_back(s[0]);return pf s;} };B k-avoiding 数组的最小总和 贪心:从 1 1 1开始升序枚举,…...

【开源项目】Stream-Query的入门使用和原理分析
前言 无意间发现了一个有趣的项目,Stream-Query。了解了一下其基本的功能,可以帮助开发者省去Mapper的编写。在开发中,我们会编写entity和mapper来完成业务代码,但是Stream-Query可以省去mapper,只写entity。 快速入…...

微信小程序picker组件的简单使用 单选
<picker mode"selector" range"{{classData}}" bindchange"bindClassChange" value"{{classIndex}}" range-key"className"><view class"picker">{{classData[classIndex].className || 请选择班级}}…...
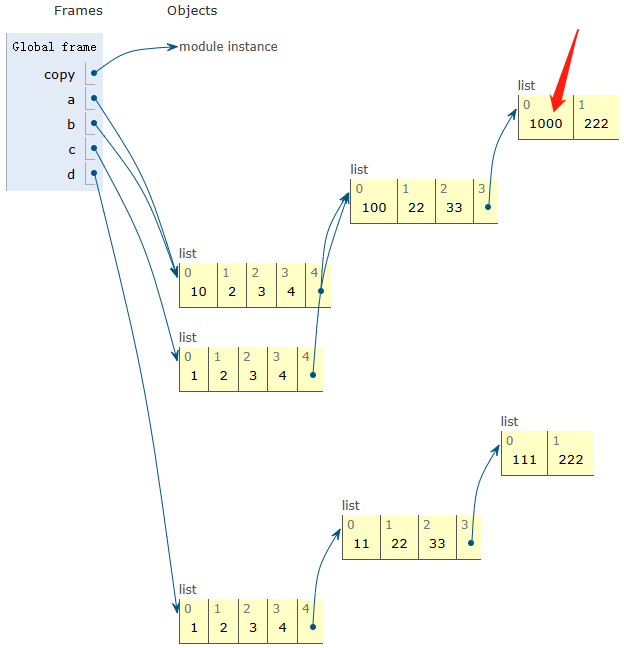
python、numpy、pytorch中的浅拷贝和深拷贝
1、Python中的浅拷贝和深拷贝 import copya [1, 2, 3, 4, [11, 22, 33, [111, 222]]] b a c a.copy() d copy.deepcopy(a)print(before modify\r\n a\r\n, a, \r\n,b a\r\n, b, \r\n,c a.copy()\r\n, c, \r\n,d copy.deepcopy(a)\r\n, d, \r\n)before modify a [1, 2…...

EasyRecovery14数据恢复软件支持各类存储设备的数据恢复
EasyRecovery14数据恢复软件专业数据恢复软件支持电脑、相机、移动硬盘、U盘、SD卡、内存卡、光盘、本地电子邮件和 RAID 磁盘阵列等各类存储设备的数据恢复。 目前市面上有许多数据恢复软件,但褒贬不一,而且数据恢复软件又不是一款会被经常使用的软件&a…...
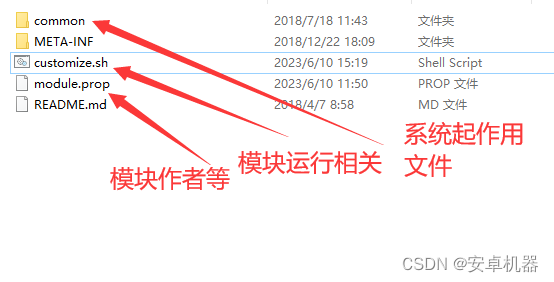
玩机搞机----面具模块的组成 制作模块
root面具相信很多玩家都不陌生。早期玩友大都使用第三方卡刷补丁来对系统进行各种修复和添加功能。目前面具补丁代替了这些操作。今天的帖子了解下面具各种模块的组成和几种普遍的代码组成。 Magisk中运行的每个单独的shell脚本都将在内部的BusyBox的shell中执行。对于与第三方…...
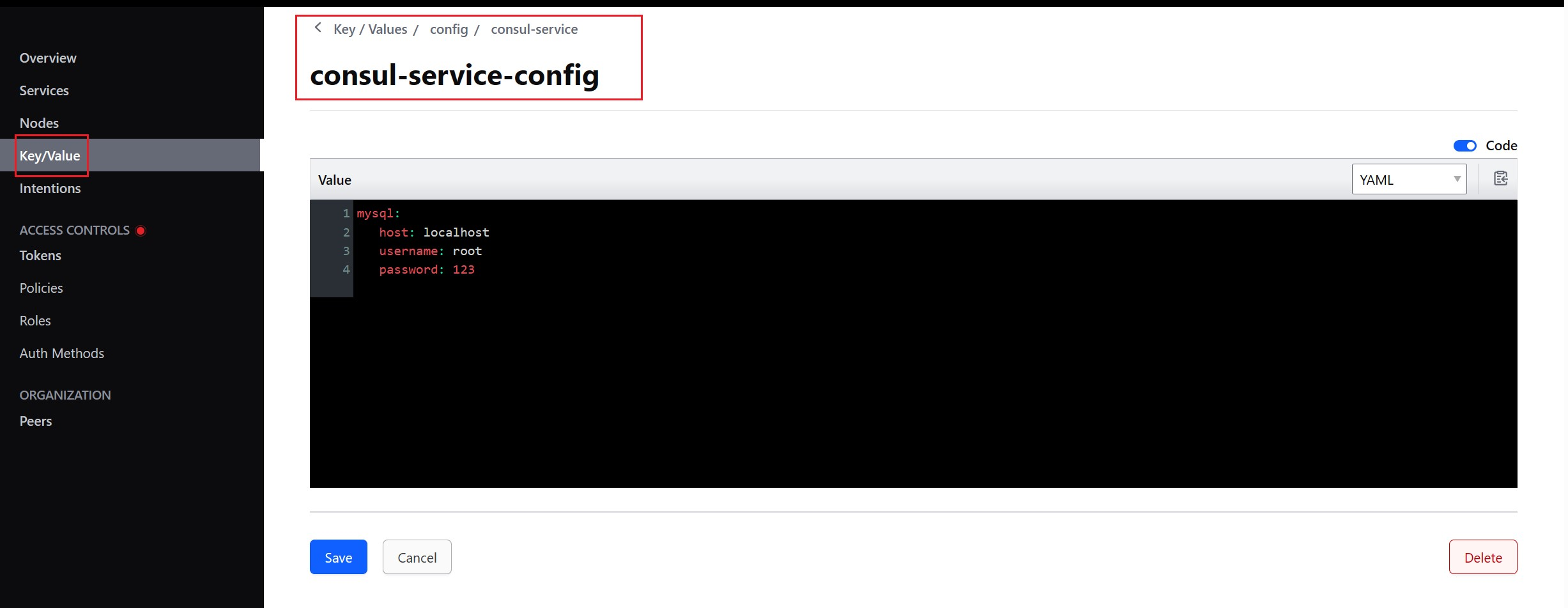
注册中心/配置管理 —— SpringCloud Consul
Consul 概述 Consul 是一个可以提供服务发现,健康检查,多数据中心,key/Value 存储的分布式服务框架,用于实现分布式系统的发现与配置。Cousul 使用 Go 语言实现,因此天然具有可移植性,安装包仅包含一个可执…...
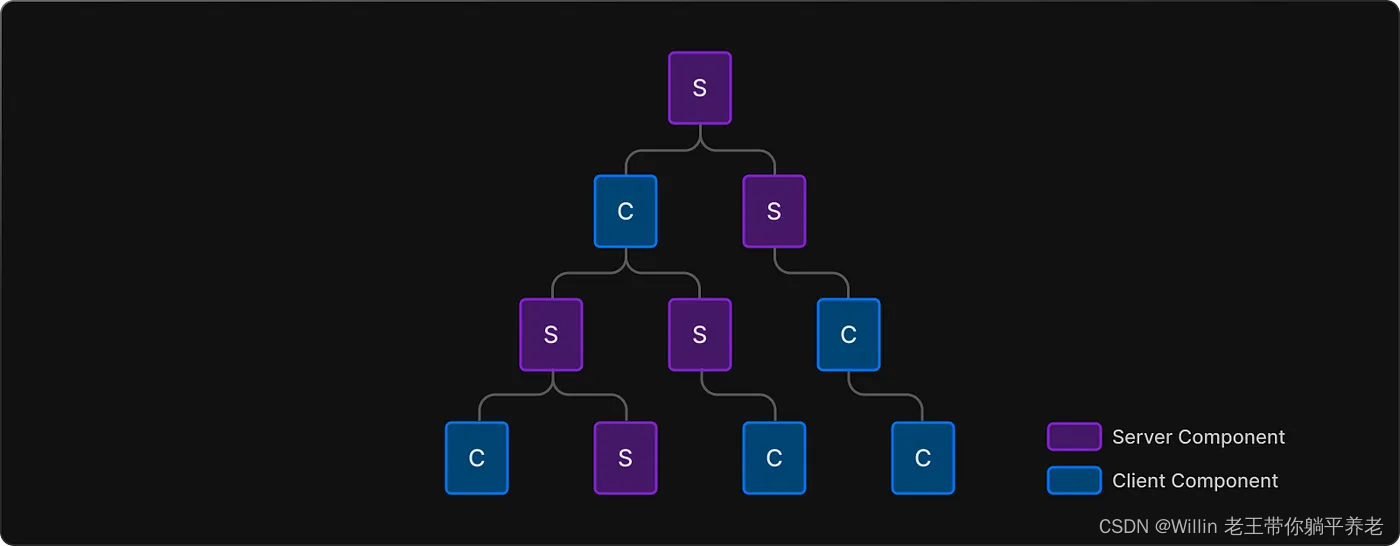
Next.js 13 你需要了解的 8 件事
目录 React 服务器组件 (RSC)服务器组件默认开启在 Next.js 中客户端组件也在服务器上呈现!组成客户端和服务器组件编译Next.js 13 渲染模式桶文件有点坏了库集成:WIP 仍在进行中Route groups 路由组总结 在本文中,我们…...
算法详解)
计数排序(Count Sort)算法详解
1. 算法简介 计数排序(Count Sort)是一种非比较排序算法,其核心思想是统计数组中每个元素出现的次数,然后根据统计结果将元素按照顺序放回原数组中。计数排序的时间复杂度为O(nk),其中n是数组的长度,k是数…...
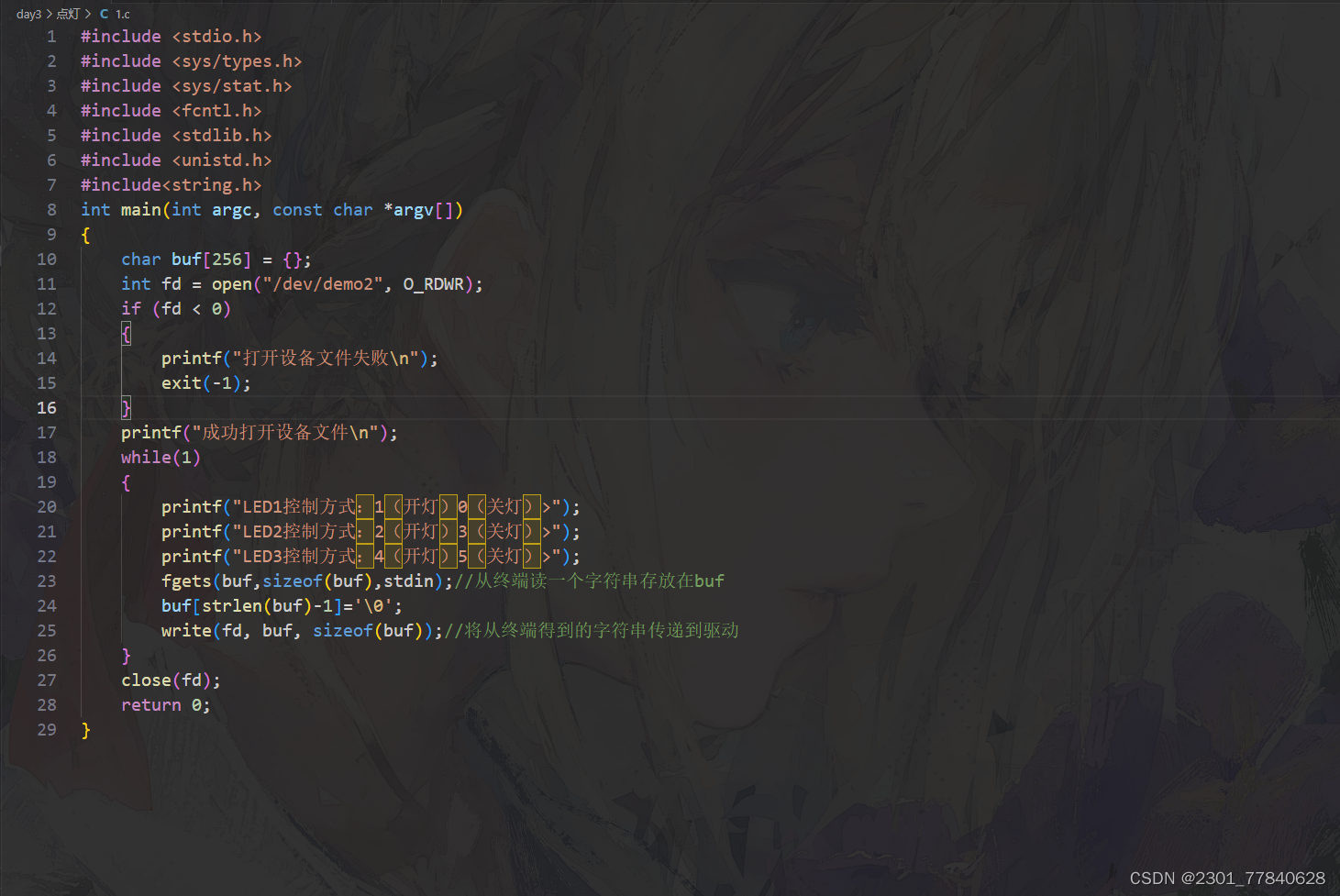
Linux驱动开发(Day3)
驱动点灯:...
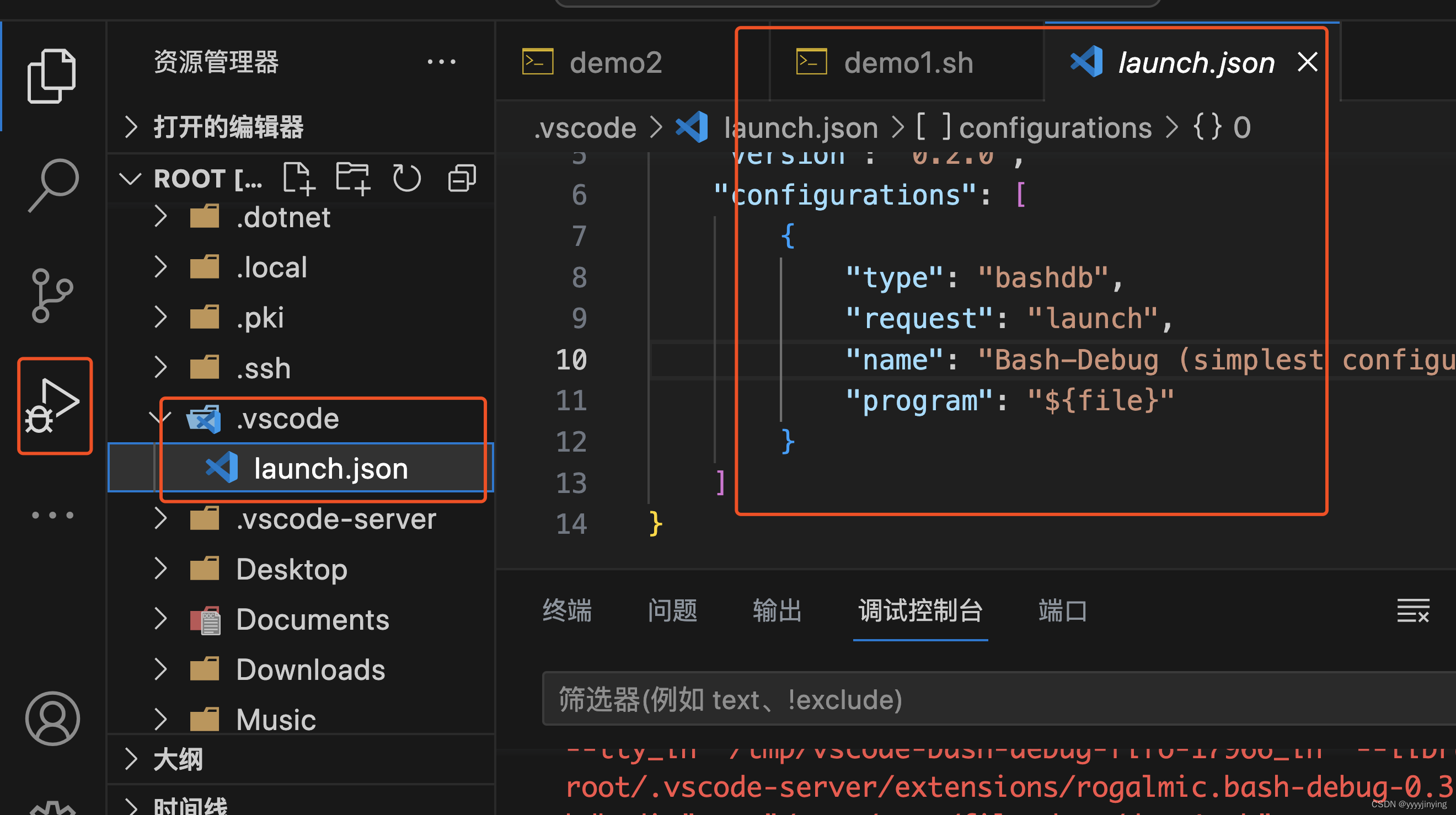
使用Vscode调试shell脚本
在vcode中安装bash dug插件 在vcode中添加launch.json配置,默认就好 参考:http://www.rply.cn/news/73966.html 推荐插件: shellman(支持shell,智能提示) shellcheck(shell语法检查) shell-format(shell格式化)...

OpenAI Function calling
开篇 原文出处 最近 OpenAI 在 6 月 13 号发布了新 feature,主要针对模型进行了优化,提供了 function calling 的功能,该 feature 对于很多集成 OpenAI 的应用来说绝对是一个“神器”。 Prompt 的演进 如果初看 OpenAI 官网对function ca…...

【C语言】字符分类函数、字符转换函数、内存函数
前言 之前我们用两篇文章介绍了strlen、strcpy、stract、strcmp、strncpy、strncat、strncmp、strstr、strtok、streeror这些函数 第一篇文章strlen、strcpy、stract 第二篇文章strcmp、strncpy、strncat、strncmp 第三篇文章strstr、strtok、streeror 今天我们就来学习字…...
Deep Learning With Pytorch - 最基本的感知机、贯序模型/分类、拟合
文章目录 如何利用pytorch创建一个简单的网络模型?Step1. 感知机,多层感知机(MLP)的基本结构Step2. 超平面 ω T ⋅ x b 0 \omega^{T}xb0 ωT⋅xb0 or ω T ⋅ x b \omega^{T}xb ωT⋅xb感知机函数 Step3. 利用感知机进行决策…...

自来水厂综合管理平台具备什么功能
随着城市化进程加速与居民用水需求提升,传统水厂面临着运行效率低下、能耗药耗偏高、水质管控难度大、设备运维依赖人工经验、应急响应滞后等一系列挑战。物联网、大数据、人工智能等信息技术的飞速发展为水厂数字化转型提供了强大支撑,智慧水务势在必行…...
)
从CRUD到业务解构:如何优雅处理多表关联的菜品管理接口(附SQL优化小技巧)
从CRUD到业务解构:如何优雅处理多表关联的菜品管理接口(附SQL优化小技巧) 在中小型外卖系统的开发过程中,菜品管理模块往往是业务逻辑最为复杂的部分之一。不同于简单的单表CRUD操作,一个完整的菜品管理接口需要处理菜…...

高效掌握百度网盘命令行工具:终端文件管理全面指南
高效掌握百度网盘命令行工具:终端文件管理全面指南 【免费下载链接】BaiduPCS BaiduPCS - 一个用 C/C 编写的百度网盘命令行工具,支持多线程下载、断点续传、快速上传等功能。 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduPCS 百度网盘命令…...

避坑指南:当Harbor遇到Nginx代理时,为什么你的Docker Push总失败?
深度解析:Harbor与Nginx代理集成中的HTTPS推送故障排查实战 当你兴冲冲地准备将精心构建的Docker镜像推送到企业私有仓库时,终端却无情地抛出一串红色错误——这种挫败感,相信不少开发者都深有体会。特别是在Harbor前面加了Nginx代理层后&…...

Web 表白页面性能优化指南:Awesome-Love-Code 最佳实践
Web 表白页面性能优化指南:Awesome-Love-Code 最佳实践 【免费下载链接】Awesome-Love-Code 表白代码收藏馆~谁说程序猿不懂浪漫❤️ 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-Love-Code 在数字化时代,表白页面已成为程序员表达爱意…...
)
解决Thingsboard数据下发难题:自定义RPC请求格式的3种方法(含源码修改指南)
ThingsBoard数据下发实战:3种自定义RPC请求格式的工程化解决方案 在物联网平台的实际部署中,数据格式的兼容性问题就像一把双刃剑——既考验着系统的灵活性,又决定着集成的成败。最近在为一个智能农业项目部署ThingsBoard平台时,我…...

GPT-SoVITS技术优化实战指南:从环境配置到性能调优全解析
GPT-SoVITS技术优化实战指南:从环境配置到性能调优全解析 【免费下载链接】GPT-SoVITS 项目地址: https://gitcode.com/GitHub_Trending/gp/GPT-SoVITS 引言 在AI语音合成领域,GPT-SoVITS作为一款开源项目,为开发者提供了强大的语音…...

DeOldify图像上色服务开箱即用:无需代码,网页上传即可体验
DeOldify图像上色服务开箱即用:无需代码,网页上传即可体验 1. 引言:让黑白记忆重焕光彩 你是否翻看过家里的老相册,那些泛黄的黑白照片承载着珍贵的记忆,却总感觉少了些色彩的温度?或者,你是否…...
—— 基于高阶扩展状态观测器HESO的MPFCC)
模型预测控制专题(十二)—— 基于高阶扩展状态观测器HESO的MPFCC
0 前言在上一节中我们复现了一篇基于内模的改进型ESO无模型预测控制的论文。在进行探究的过程中,我们可以发现一个很有意思的点,就是整个模型将高频扰动模型引入了观测器模型,形成了一个单位增益无相位延迟的高频扰动抑制方法,我个…...

云容笔谈多风格作品对比展示:从写实到水墨的东方美学演绎
云容笔谈多风格作品对比展示:从写实到水墨的东方美学演绎 最近在尝试用AI生成一些东方主题的图片,发现了一个挺有意思的现象:同一个主题,换一个风格词,出来的效果天差地别。这让我想起了“云容笔谈”这个系统…...