[机器学习]特征工程:特征降维
特征降维
1、简介
特征降维是指通过减少特征空间中的维度,将高维数据映射到一个低维子空间的过程。
在机器学习和数据分析中,特征降维可以帮助减少数据的复杂性、降低计算成本、提高模型性能和可解释性,以及解决维度灾难等问题。特征降维通常分为两种主要方法:特征选择和特征提取。
- 特征选择(Feature Selection):特征选择是指从原始特征中选择一部分最具有代表性和重要性的特征子集,而忽略其他特征。这样可以减少特征的数量,从而降低了维度。特征选择方法可以基于统计检验、信息增益、模型权重等指标来评估特征的重要性,然后选择排名靠前的特征。
- 特征提取(Feature Extraction):特征提取是通过数学变换将原始特征映射到一个新的低维子空间,从而保留数据中的关键信息。常见的特征提取方法包括主成分分析(PCA)、线性判别分析(LDA)、独立成分分析(ICA)等。这些方法通过线性或非线性的映射,将高维数据转化为低维表示,使得新特征具有更强的表达能力。
特征降维的优点包括:
- 减少维度灾难:维度灾难是指在高维空间中,数据稀疏性增加,距离度量失效等问题。特征降维可以减轻这些问题,使得数据更易处理和分析。
- 减少计算成本:高维数据的计算成本较高,特征降维可以降低计算复杂性,提高算法效率。
- 提高模型性能:在一些情况下,特征降维可以提高模型的性能,减少过拟合,提高泛化能力。
- 可视化和解释性:将数据映射到低维空间可以更容易地进行可视化和解释,帮助理解数据中的模式和关系。
特征降维的选择取决于数据的性质、问题的需求和模型的要求。不同的降维方法适用于不同的情况,需要根据具体问题来进行选择和应用。
2、降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
降低随机变量的个数:

相关特征(correlated feature):相对湿度与降雨量之间的相关
正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
降维的两种方式:特征选择和主成分分析(可以理解一种特征提取的方式)
3、特征选择
3.1、简述
定义:数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。

特征选择是指从原始数据的特征集合中选择出最具有代表性和重要性的一部分特征,以便用于构建模型、分析数据或解决问题。
特征选择的目标是减少特征的数量,同时保留数据中最具信息量的部分,从而降低计算成本、提高模型性能、加速训练过程和提高模型的可解释性。
特征选择的主要动机是:
- 降低维度:高维数据集中的特征数量可能非常庞大,导致计算和存储开销增加,降低了算法的效率。
- 减少过拟合:过多的特征可能导致模型过于复杂,容易在训练集上表现良好,但在新数据上表现较差(过拟合)。
- 提高模型性能:一些特征可能对模型性能没有贡献,甚至可能带来噪声。通过选择重要的特征,可以提高模型的性能。
- 改善解释性:使用更少的特征可以使模型更容易理解和解释。
特征选择方法可以分为三大类:
- 过滤法(Filter Methods):通过在特征选择之前对特征进行评估和排序,选择与目标变量相关性较高的特征。常用的过滤方法包括方差选择、相关系数、互信息等。
- 包装法(Wrapper Methods):将特征选择视为一个优化问题,根据模型的性能来选择特征。常见的包装方法包括递归特征消除(Recursive Feature Elimination, RFE)和前向选择(Forward Selection)等。
- 嵌入法(Embedded Methods):在模型训练过程中进行特征选择,通过优化模型的性能来选择特征。例如,决策树和正则化线性模型可以在训练过程中剪枝或约束特征的权重。
特征选择方法的选择取决于数据的性质、问题的需求和模型的要求。不同的方法适用于不同的情况,需要根据具体问题来选择和应用。特征选择是数据预处理的重要一环,能够为构建更准确、高效和可解释的机器学习模型奠定基础。
3.2、两种方法
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
方差选择法:低方差特征过滤
相关系数
Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
决策树:信息熵、信息增益
正则化:L1、L2
深度学习:卷积等
需要使用的模块:sklearn.feature_selection
3.3、过滤式
3.3.1、低方差特征过滤
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
特征方差小:某个特征大多样本的值比较相近
特征方差大:某个特征很多样本的值都有差别
API:
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
案例实践:
下面进行数据计算,我们对某些股票的指标特征之间进行一个筛选,需要的数据保存在factor_returns.csv文件。
需要除去'index,'date','return'列不考虑(这些类型不匹配,也不是所需要指标)

所以需要的特征如下:pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense
下面进行分析:
1、初始化VarianceThreshold,指定阀值方差
2、调用fit_transform
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/8/16 10:01
import pandas as pd
from sklearn.feature_selection import VarianceThreshold # 低方差特征过滤'''
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)删除所有低方差特征Variance.fit_transform(X)X:numpy array格式的数据[n_samples,n_features]返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
'''
def variance_demo():"""删除低方差特征——特征选择:return: None"""data = pd.read_csv("data/factor_returns.csv")print(data)# 1、实例化一个转换器类transfer = VarianceThreshold(threshold=1)# 2、调用fit_transformdata = transfer.fit_transform(data.iloc[:, 1:10])print("删除低方差特征的结果:\n", data)print("形状:\n", data.shape)if __name__ == '__main__':# 设置 Pandas 输出选项以展示所有行和列的内容pd.set_option('display.max_columns', None)variance_demo()结果如下:


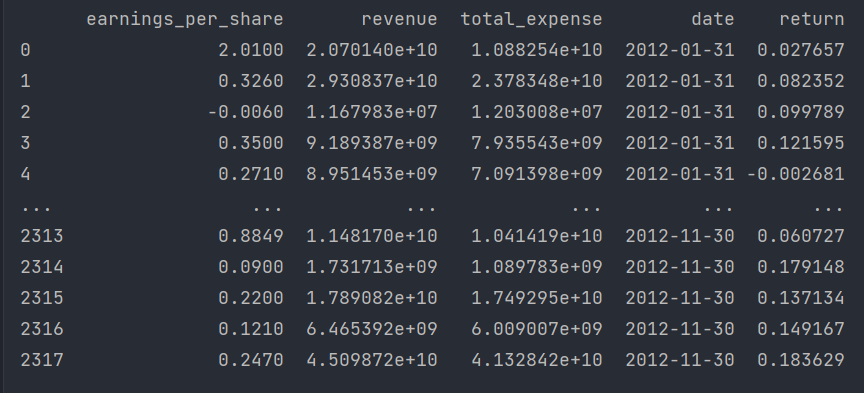

3.3.2、相关系数
皮尔逊相关系数(Pearson Correlation Coefficient):反映变量之间相关关系密切程度的统计指标
皮尔逊相关系数(Pearson Correlation Coefficient),也称为皮尔逊相关系数或皮尔逊相关系数,是一种用于衡量两个连续变量之间线性关系强度和方向的统计量。它衡量了两个变量之间的线性相关程度。
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
- 当r>0时,表示两变量正相关,r<0时,两变量为负相关
- 当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
- 当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱
- 一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
公式:

参数如下:
n:观测值的数量。
∑:求和符号,表示对所有观测值求和。
x 和 y:分别表示两个变量的观测值。
API:
from scipy.stats import pearsonr
x : (N,) array_like
y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
案例:股票的财务指标相关性计算
我们刚才的股票的这些指标进行相关性计算, 假设我们以factor = ['pe_ratio','pb_ratio','market_cap','return_on_asset_net_profit','du_return_on_equity','ev','earnings_per_share','revenue','total_expense']这些特征当中的两两进行计算,得出相关性高的一些特征。
分析:两两特征之间进行相关性计算
import pandas as pd
from scipy.stats import pearsonr # 皮尔逊相关系数'''
from scipy.stats import pearsonrx : (N,) array_likey : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
'''
def pearsonr_demo():"""相关系数计算"""data = pd.read_csv("data/factor_returns.csv")factor = ['pe_ratio', 'pb_ratio', 'market_cap', 'return_on_asset_net_profit', 'du_return_on_equity', 'ev','earnings_per_share', 'revenue', 'total_expense']for i in range(len(factor)):for j in range(i, len(factor) - 1):print("指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0]))if __name__ == '__main__':# 设置 Pandas 输出选项以展示所有行和列的内容pd.set_option('display.max_columns', None)pearsonr_demo()结果:
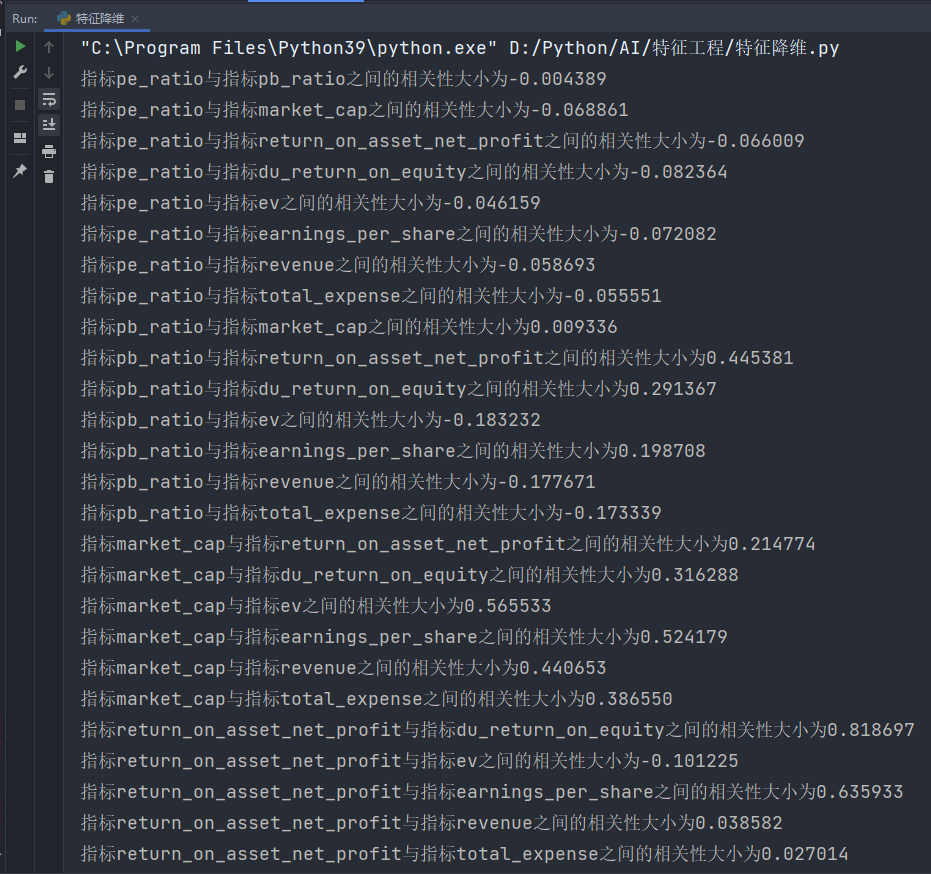
从中可以得出:

指标revenue与指标total_expense之间的相关性大小为0.995845
指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697
画图:


这两对指标之间的相关性较大,可以做之后的处理,比如合成这两个指标。
相关文章:
[机器学习]特征工程:特征降维
特征降维 1、简介 特征降维是指通过减少特征空间中的维度,将高维数据映射到一个低维子空间的过程。 在机器学习和数据分析中,特征降维可以帮助减少数据的复杂性、降低计算成本、提高模型性能和可解释性,以及解决维度灾难等问题。特征降维通…...
12. Docker可视化工具
目录 1、前言 2、Docker UI 2.1、部署Docker UI 2.2、管理容器 3、Portainer 3.1、部署Portainer 3.2、管理容器 3.3、添加远程Docker 4、Shipyard 1、前言 Docker 提供了命令行工具来管理 Docker 的镜像和运行 Docker 的容器。我们也可以使用图形工具来管理 Docker。…...

css层叠关系
文章目录 cascading声明冲突应用重置样式表a元素的类选择器顺序问题 cascading cascading – 层叠 解决声明冲突的过程,浏览器会自动处理;就是计算样式的权重,权重大的就被选择; 声明冲突 是指多个选择器选中同一个标签&#x…...

【Unity实战篇 】| 如何在小游戏中快速接入一个新手引导教程
前言 【Unity实战篇 】 | 如何在小游戏中快速接入一个新手引导教程一、简单教程描述二、接入Tutorial Master 实现游戏引导2.1 导入Tutorial Master2插件2.2 添加TutorialMasterManager脚本对象2.3 配置Tutorial,用于管理第一段引导内容2.4 配置Stage,用…...

Lookup Singularity
1. 引言 Lookup Singularity概念 由Barry WhiteHat在2022年11月在zkResearch论坛 Lookup Singularity中首次提出: 其主要目的是:让SNARK前端生成仅需做lookup的电路。Barry预测这样有很多好处,特别是对于可审计性 以及 形式化验证ÿ…...
idea 本地版本控制 local history
idea 本地版本控制 local history 如何打开 1 自定义快捷键 settings->keymap->搜索框输入 show history -》Add Keyboard Shortcut -》设置为 CtrlAltL 2 右键文件-》local history -》show history 新建文件 版本1,creating class com.geekmice…这个是初…...
【Freertos基础入门】深入浅出freertos互斥量
文章目录 前言一、互斥量是什么?二、互斥量的使用场景三、互斥量的使用1.创建 2.删除互斥量3.give和take四、示例代码总结 前言 FreeRTOS是一款开源的实时操作系统,提供了许多基本的内核对象,其中包括互斥锁(Mutex)。…...
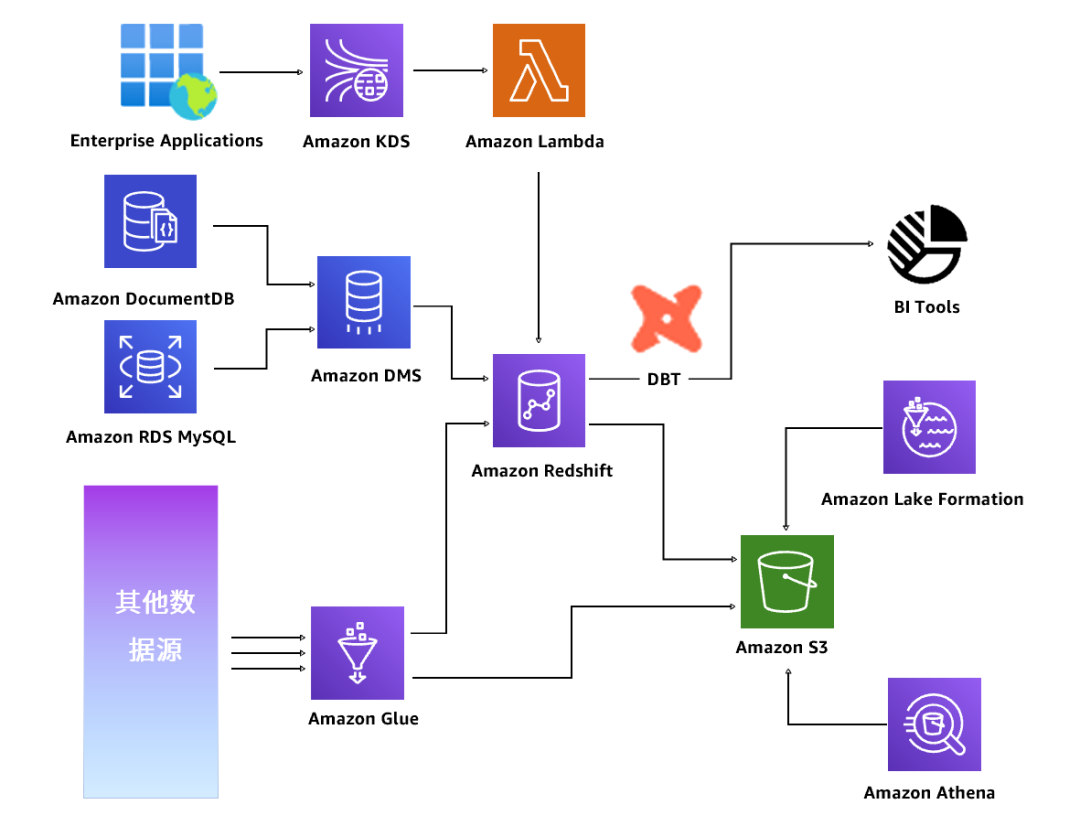
皮爷咖啡基于亚马逊云科技的数据架构,加速数据治理进程
皮爷咖啡(Peet’s Coffee)是美国精品咖啡品牌,于2017年进入中国,为中国消费者带来传统经典咖啡饮品,并特别呈现更加丰富的品质咖啡饮品体验。通过深入应用亚马逊云科技云原生数据库产品Amazon Redshift以及Amazon DMS等…...
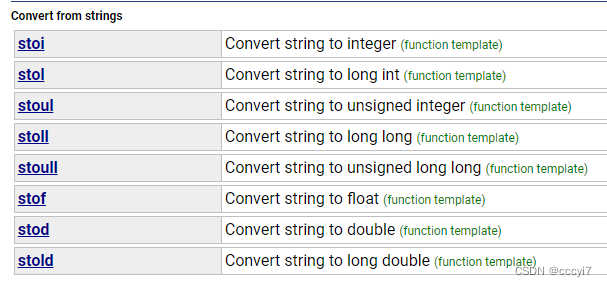
C++ string类详解
⭐️ string string 是表示字符串的字符串类,该类的接口与常规容器的接口基本一致,还有一些额外的操作 string 的常规操作,在使用 string 类时,需要使用 #include <string> 以及 using namespace std;。 ✨ 帮助文档&…...

深入浅出Pytorch函数——torch.nn.init.ones_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

一、docker及mysql基本语法
文章目录 一、docker相关命令二、mysql相关命令 一、docker相关命令 (1)拉取镜像:docker pull <镜像ID/image> (2)查看当前docker中的镜像:docker images (3)删除镜像&#x…...
【计算机网络】13、ARP 包:广播自己的 mac 地址和 ip
机器启动时,会向外广播自己的 mac 地址和 ip 地址,这个即称为 arp 协议。范围是未经过路由器的部分,如下图的蓝色部分,范围内的设备都会在本地记录 mac 和 ip 的绑定信息,若有重复则覆盖更新(例如先收到 ma…...
通过微软Azure调用GPT的接口API-兼容平替OpenAI官方的注意事项
众所周知,我们是访问不通OpenAI官方服务的,但是我们可以自己通过代理或者使用第三方代理访问接口 现在新出台的规定禁止使用境外的AI大模型接口对境内客户使用,所以我们需要使用国内的大模型接口 国内的效果真的很差,现在如果想使…...

回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍程序设计…...

GAN!生成对抗网络GAN全维度介绍与实战
目录 一、引言1.1 生成对抗网络简介1.2 应用领域概览1.3 GAN的重要性 二、理论基础2.1 生成对抗网络的工作原理2.1.1 生成器生成过程 2.1.2 判别器判别过程 2.1.3 训练过程训练代码示例 2.1.4 平衡与收敛 2.2 数学背景2.2.1 损失函数生成器损失判别器损失 2.2.2 优化方法优化代…...
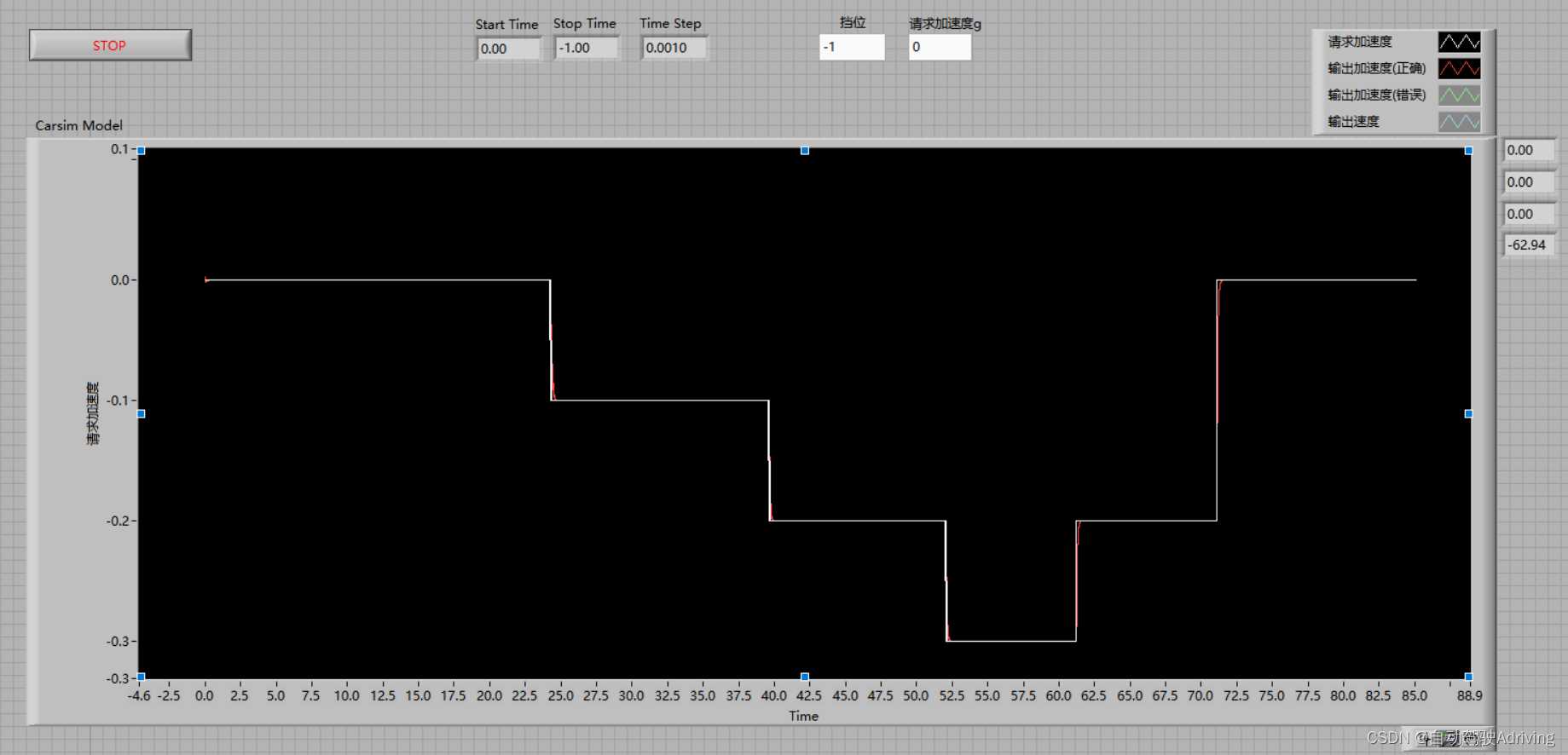
自动驾驶仿真:基于Carsim开发的加速度请求模型
文章目录 前言一、加速度输出变量问题澄清二、配置Carsim动力学模型三、配置Carsim驾驶员模型四、添加VS Command代码五、Run Control联合仿真六、加速度模型效果验证 前言 1、自动驾驶行业中,算法端对于纵向控制的功能预留接口基本都是加速度,我们需要…...
.netcore grpc客户端工厂及依赖注入使用
一、客户端工厂概述 gRPC 与 HttpClientFactory 的集成提供了一种创建 gRPC 客户端的集中方式。可以通过依赖包Grpc.Net.ClientFactory中的AddGrpcClient进行gRPC客户端依赖注入AddGrpcClient函数提供了许多配置项用于处理一些其他事项;例如AOP、重试策略等 二、案…...
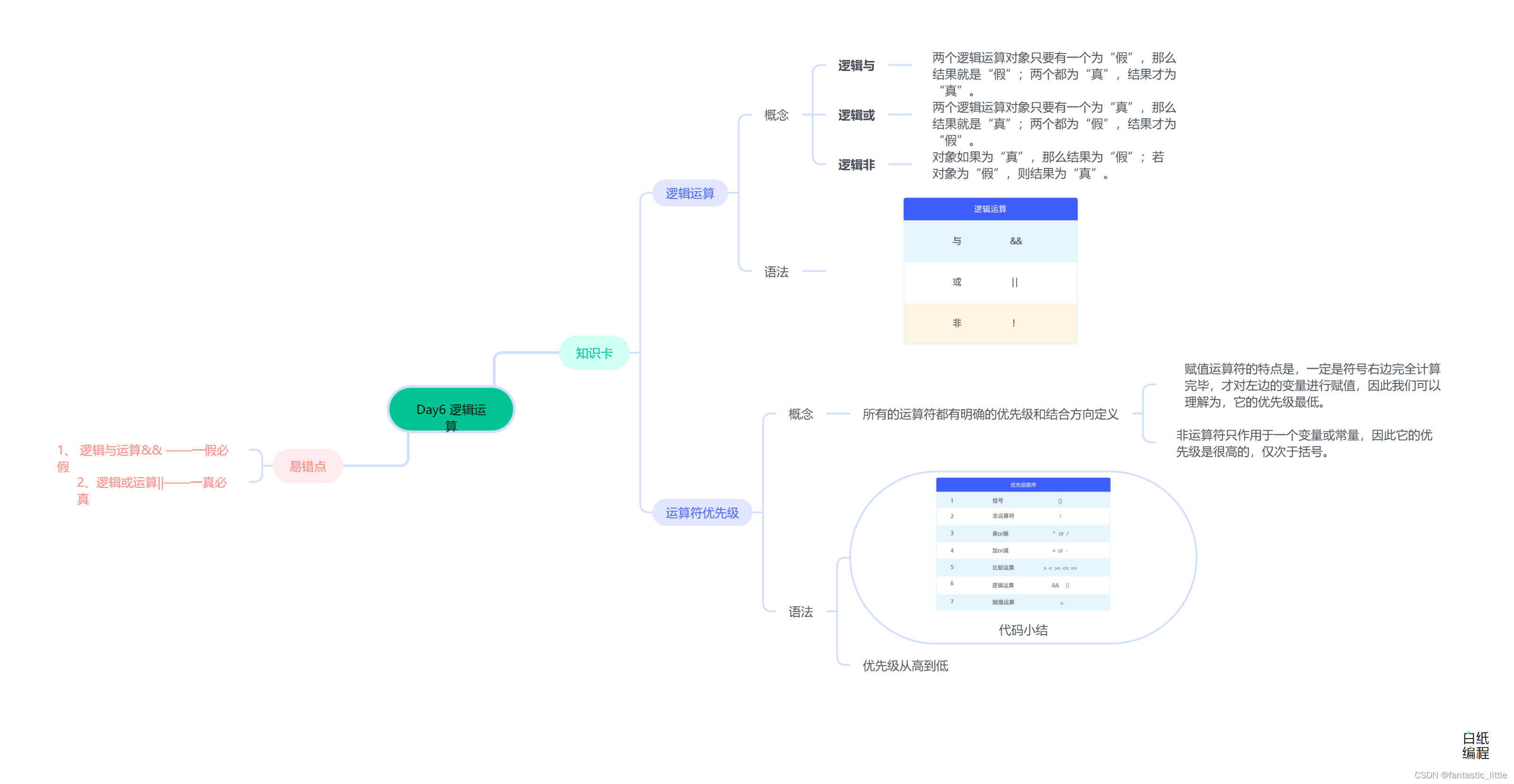
C语言入门_Day7 逻辑运算
目录: 前言 1.逻辑运算 2.优先级 3.易错点 4.思维导图 前言 算术运算用来进行数据的计算和处理;比较运算是用来比较不同的数据,进而来决定下一步怎么做;除此以外还有一种运算叫做逻辑运算,它的应用场景也是用来影…...

什么是Eureka?以及Eureka注册服务的搭建
导包 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 htt…...

Docker安装并配置镜像加速器,镜像、容器的基本操作
目录 1.安装docker服务,配置镜像加速器 (1)安装依赖的软件包 (2)设置yum源,我配置的阿里仓库 (3)选择一个版本安装 (4)启动docker服务,并设置…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...