深入浅出Pytorch函数——torch.nn.Module
分类目录:《深入浅出Pytorch函数》总目录
Pytorch中所有网络的基类,我们的模型也应该继承这个类。Modules也可以包含其它Modules,允许使用树结构嵌入他们,我们还可以将子模块赋值给模型属性。
语法
torch.nn.Module(*args, **kwargs)
方法
torch.nn.Module.apply
实例
import torch.nn as nn
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 20, 5) # submodule: Conv2dself.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))
通过上面方式赋值的submodule会被注册,当调用.cuda() 的时候,submodule的参数也会转换为cuda Tensor。
函数实现
from collections import OrderedDict, namedtuple
import itertools
import warnings
import functools
import weakrefimport torch
from ..parameter import Parameter
import torch.utils.hooks as hooksfrom torch import Tensor, device, dtype
from typing import Union, Tuple, Any, Callable, Iterator, Set, Optional, overload, TypeVar, Mapping, Dict, List
from ...utils.hooks import RemovableHandle__all__ = ['register_module_forward_pre_hook', 'register_module_forward_hook','register_module_full_backward_pre_hook', 'register_module_backward_hook','register_module_full_backward_hook', 'register_module_buffer_registration_hook','register_module_module_registration_hook', 'register_module_parameter_registration_hook', 'Module']_grad_t = Union[Tuple[Tensor, ...], Tensor]
# See https://mypy.readthedocs.io/en/latest/generics.html#generic-methods-and-generic-self for the use
# of `T` to annotate `self`. Many methods of `Module` return `self` and we want those return values to be
# the type of the subclass, not the looser type of `Module`.
T = TypeVar('T', bound='Module')class _IncompatibleKeys(namedtuple('IncompatibleKeys', ['missing_keys', 'unexpected_keys'])):def __repr__(self):if not self.missing_keys and not self.unexpected_keys:return '<All keys matched successfully>'return super().__repr__()__str__ = __repr__def _addindent(s_, numSpaces):s = s_.split('\n')# don't do anything for single-line stuffif len(s) == 1:return s_first = s.pop(0)s = [(numSpaces * ' ') + line for line in s]s = '\n'.join(s)s = first + '\n' + sreturn sr"""This tracks hooks common to all modules that are executed immediately before
.registering the buffer/module/parameter"""
_global_buffer_registration_hooks: Dict[int, Callable] = OrderedDict()
_global_module_registration_hooks: Dict[int, Callable] = OrderedDict()
_global_parameter_registration_hooks: Dict[int, Callable] = OrderedDict()class _WrappedHook:def __init__(self, hook: Callable, module: Optional["Module"] = None):self.hook: Callable = hookfunctools.update_wrapper(self, hook)self.with_module: bool = Falseif module is not None:self.module: weakref.ReferenceType["Module"] = weakref.ref(module)self.with_module = Truedef __call__(self, *args: Any, **kwargs: Any) -> Any:if self.with_module:module = self.module()if module is None:raise RuntimeError("You are trying to call the hook of a dead Module!")return self.hook(module, *args, **kwargs)return self.hook(*args, **kwargs)def __getstate__(self) -> Dict:result = {"hook": self.hook, "with_module": self.with_module}if self.with_module:result["module"] = self.module()return resultdef __setstate__(self, state: Dict):self.hook = state["hook"]self.with_module = state["with_module"]if self.with_module:if state["module"] is None:raise RuntimeError("You are trying to revive the hook of a dead Module!")self.module = weakref.ref(state["module"])r"""This tracks hooks common to all modules that are executed before/after
calling forward and backward. This is global state used for debugging/profiling
purposes"""
_global_backward_pre_hooks: Dict[int, Callable] = OrderedDict()
_global_backward_hooks: Dict[int, Callable] = OrderedDict()
_global_is_full_backward_hook: Optional[bool] = None
_global_forward_pre_hooks: Dict[int, Callable] = OrderedDict()
_global_forward_hooks: Dict[int, Callable] = OrderedDict()_EXTRA_STATE_KEY_SUFFIX = '_extra_state'def register_module_buffer_registration_hook(hook: Callable[..., None]) -> RemovableHandle:r"""Registers a buffer registration hook common to all modules... warning ::This adds global state to the `nn.Module` moduleThe hook will be called every time :func:`register_buffer` is invoked.It should have the following signature::hook(module, name, buffer) -> None or new bufferThe hook can modify the input or return a single modified value in the hook.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(_global_buffer_registration_hooks)_global_buffer_registration_hooks[handle.id] = hookreturn handledef register_module_module_registration_hook(hook: Callable[..., None]) -> RemovableHandle:r"""Registers a module registration hook common to all modules... warning ::This adds global state to the `nn.Module` moduleThe hook will be called every time :func:`register_module` is invoked.It should have the following signature::hook(module, name, submodule) -> None or new submoduleThe hook can modify the input or return a single modified value in the hook.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(_global_module_registration_hooks)_global_module_registration_hooks[handle.id] = hookreturn handledef register_module_parameter_registration_hook(hook: Callable[..., None]) -> RemovableHandle:r"""Registers a parameter registration hook common to all modules... warning ::This adds global state to the `nn.Module` moduleThe hook will be called every time :func:`register_parameter` is invoked.It should have the following signature::hook(module, name, param) -> None or new parameterThe hook can modify the input or return a single modified value in the hook.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(_global_parameter_registration_hooks)_global_parameter_registration_hooks[handle.id] = hookreturn handledef register_module_forward_pre_hook(hook: Callable[..., None]) -> RemovableHandle:r"""Registers a forward pre-hook common to all modules... warning ::This adds global state to the `nn.module` moduleand it is only intended for debugging/profiling purposes.The hook will be called every time before :func:`forward` is invoked.It should have the following signature::hook(module, input) -> None or modified inputThe input contains only the positional arguments given to the module.Keyword arguments won't be passed to the hooks and only to the ``forward``.The hook can modify the input. User can either return a tuple or asingle modified value in the hook. We will wrap the value into a tupleif a single value is returned(unless that value is already a tuple).This hook has precedence over the specific module hooks registered with``register_forward_pre_hook``.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(_global_forward_pre_hooks)_global_forward_pre_hooks[handle.id] = hookreturn handledef register_module_forward_hook(hook: Callable[..., None]) -> RemovableHandle:r"""Registers a global forward hook for all the modules.. warning ::This adds global state to the `nn.module` moduleand it is only intended for debugging/profiling purposes.The hook will be called every time after :func:`forward` has computed an output.It should have the following signature::hook(module, input, output) -> None or modified outputThe input contains only the positional arguments given to the module.Keyword arguments won't be passed to the hooks and only to the ``forward``.The hook can modify the output. It can modify the input inplace butit will not have effect on forward since this is called after:func:`forward` is called.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``This hook will be executed before specific module hooks registered with``register_forward_hook``."""handle = hooks.RemovableHandle(_global_forward_hooks)_global_forward_hooks[handle.id] = hookreturn handledef register_module_backward_hook(hook: Callable[['Module', _grad_t, _grad_t], Union[None, _grad_t]]
) -> RemovableHandle:r"""Registers a backward hook common to all the modules.This function is deprecated in favor of:func:`torch.nn.modules.module.register_module_full_backward_hook`and the behavior of this function will change in future versions.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""global _global_is_full_backward_hookif _global_is_full_backward_hook is True:raise RuntimeError("Cannot use both regular backward hooks and full backward hooks as a ""global Module hook. Please use only one of them.")_global_is_full_backward_hook = Falsehandle = hooks.RemovableHandle(_global_backward_hooks)_global_backward_hooks[handle.id] = hookreturn handledef register_module_full_backward_pre_hook(hook: Callable[['Module', _grad_t], Union[None, _grad_t]]
) -> RemovableHandle:r"""Registers a backward pre-hook common to all the modules... warning ::This adds global state to the `nn.module` moduleand it is only intended for debugging/profiling purposes.The hook will be called every time the gradients for the module are computed.The hook should have the following signature::hook(module, grad_output) -> Tensor or NoneThe :attr:`grad_output` is a tuple. The hook shouldnot modify its arguments, but it can optionally return a new gradient withrespect to the output that will be used in place of :attr:`grad_output` insubsequent computations. Entries in :attr:`grad_output` will be ``None`` forall non-Tensor arguments.For technical reasons, when this hook is applied to a Module, its forward function willreceive a view of each Tensor passed to the Module. Similarly the caller will receive a viewof each Tensor returned by the Module's forward function.Global hooks are called before hooks registered with `register_backward_pre_hook`Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(_global_backward_pre_hooks)_global_backward_pre_hooks[handle.id] = hookreturn handledef register_module_full_backward_hook(hook: Callable[['Module', _grad_t, _grad_t], Union[None, _grad_t]]
) -> RemovableHandle:r"""Registers a backward hook common to all the modules... warning ::This adds global state to the `nn.module` moduleand it is only intended for debugging/profiling purposes.The hook will be called every time the gradients with respect to a moduleare computed, i.e. the hook will execute if and only if the gradients withrespect to module outputs are computed. The hook should have the followingsignature::hook(module, grad_input, grad_output) -> Tensor or NoneThe :attr:`grad_input` and :attr:`grad_output` are tuples. The hook shouldnot modify its arguments, but it can optionally return a new gradient withrespect to the input that will be used in place of :attr:`grad_input` insubsequent computations. :attr:`grad_input` will only correspond to the inputs givenas positional arguments and all kwarg arguments will not appear in the hook. Entriesin :attr:`grad_input` and :attr:`grad_output` will be ``None`` for all non-Tensorarguments.For technical reasons, when this hook is applied to a Module, its forward function willreceive a view of each Tensor passed to the Module. Similarly the caller will receive a viewof each Tensor returned by the Module's forward function.Global hooks are called before hooks registered with `register_backward_hook`Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""global _global_is_full_backward_hookif _global_is_full_backward_hook is False:raise RuntimeError("Cannot use both regular backward hooks and full backward hooks as a ""global Module hook. Please use only one of them.")_global_is_full_backward_hook = Truehandle = hooks.RemovableHandle(_global_backward_hooks)_global_backward_hooks[handle.id] = hookreturn handle# Trick mypy into not applying contravariance rules to inputs by defining
# forward as a value, rather than a function. See also
# https://github.com/python/mypy/issues/8795
def _forward_unimplemented(self, *input: Any) -> None:r"""Defines the computation performed at every call.Should be overridden by all subclasses... note::Although the recipe for forward pass needs to be defined withinthis function, one should call the :class:`Module` instance afterwardsinstead of this since the former takes care of running theregistered hooks while the latter silently ignores them."""raise NotImplementedError(f"Module [{type(self).__name__}] is missing the required \"forward\" function")class Module:r"""Base class for all neural network modules.Your models should also subclass this class.Modules can also contain other Modules, allowing to nest them ina tree structure. You can assign the submodules as regular attributes::import torch.nn as nnimport torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))Submodules assigned in this way will be registered, and will have theirparameters converted too when you call :meth:`to`, etc... note::As per the example above, an ``__init__()`` call to the parent classmust be made before assignment on the child.:ivar training: Boolean represents whether this module is in training orevaluation mode.:vartype training: bool"""dump_patches: bool = False_version: int = 1r"""This allows better BC support for :meth:`load_state_dict`. In:meth:`state_dict`, the version number will be saved as in the attribute`_metadata` of the returned state dict, and thus pickled. `_metadata` is adictionary with keys that follow the naming convention of state dict. See``_load_from_state_dict`` on how to use this information in loading.If new parameters/buffers are added/removed from a module, this number shallbe bumped, and the module's `_load_from_state_dict` method can compare theversion number and do appropriate changes if the state dict is from beforethe change."""training: bool_parameters: Dict[str, Optional[Parameter]]_buffers: Dict[str, Optional[Tensor]]_non_persistent_buffers_set: Set[str]_backward_pre_hooks: Dict[int, Callable]_backward_hooks: Dict[int, Callable]_is_full_backward_hook: Optional[bool]_forward_hooks: Dict[int, Callable]# Marks whether the corresponding _forward_hooks accept kwargs or not.# As JIT does not support Set[int], this dict is used as a set, where all# hooks represented in this dict accept kwargs._forward_hooks_with_kwargs: Dict[int, bool]_forward_pre_hooks: Dict[int, Callable]# Marks whether the corresponding _forward_hooks accept kwargs or not.# As JIT does not support Set[int], this dict is used as a set, where all# hooks represented in this dict accept kwargs._forward_pre_hooks_with_kwargs: Dict[int, bool]_state_dict_hooks: Dict[int, Callable]_load_state_dict_pre_hooks: Dict[int, Callable]_state_dict_pre_hooks: Dict[int, Callable]_load_state_dict_post_hooks: Dict[int, Callable]_modules: Dict[str, Optional['Module']]call_super_init: bool = Falsedef __init__(self, *args, **kwargs) -> None:"""Initializes internal Module state, shared by both nn.Module and ScriptModule."""torch._C._log_api_usage_once("python.nn_module")# Backward compatibility: no args used to be allowed when call_super_init=Falseif self.call_super_init is False and bool(kwargs):raise TypeError("{}.__init__() got an unexpected keyword argument '{}'""".format(type(self).__name__, next(iter(kwargs))))if self.call_super_init is False and bool(args):raise TypeError("{}.__init__() takes 1 positional argument but {} were"" given".format(type(self).__name__, len(args) + 1))"""Calls super().__setattr__('a', a) instead of the typical self.a = ato avoid Module.__setattr__ overhead. Module's __setattr__ has specialhandling for parameters, submodules, and buffers but simply calls intosuper().__setattr__ for all other attributes."""super().__setattr__('training', True)super().__setattr__('_parameters', OrderedDict())super().__setattr__('_buffers', OrderedDict())super().__setattr__('_non_persistent_buffers_set', set())super().__setattr__('_backward_pre_hooks', OrderedDict())super().__setattr__('_backward_hooks', OrderedDict())super().__setattr__('_is_full_backward_hook', None)super().__setattr__('_forward_hooks', OrderedDict())super().__setattr__('_forward_hooks_with_kwargs', OrderedDict())super().__setattr__('_forward_pre_hooks', OrderedDict())super().__setattr__('_forward_pre_hooks_with_kwargs', OrderedDict())super().__setattr__('_state_dict_hooks', OrderedDict())super().__setattr__('_state_dict_pre_hooks', OrderedDict())super().__setattr__('_load_state_dict_pre_hooks', OrderedDict())super().__setattr__('_load_state_dict_post_hooks', OrderedDict())super().__setattr__('_modules', OrderedDict())if self.call_super_init:super().__init__(*args, **kwargs)forward: Callable[..., Any] = _forward_unimplementeddef register_buffer(self, name: str, tensor: Optional[Tensor], persistent: bool = True) -> None:r"""Adds a buffer to the module.This is typically used to register a buffer that should not to beconsidered a model parameter. For example, BatchNorm's ``running_mean``is not a parameter, but is part of the module's state. Buffers, bydefault, are persistent and will be saved alongside parameters. Thisbehavior can be changed by setting :attr:`persistent` to ``False``. Theonly difference between a persistent buffer and a non-persistent bufferis that the latter will not be a part of this module's:attr:`state_dict`.Buffers can be accessed as attributes using given names.Args:name (str): name of the buffer. The buffer can be accessedfrom this module using the given nametensor (Tensor or None): buffer to be registered. If ``None``, then operationsthat run on buffers, such as :attr:`cuda`, are ignored. If ``None``,the buffer is **not** included in the module's :attr:`state_dict`.persistent (bool): whether the buffer is part of this module's:attr:`state_dict`.Example::>>> # xdoctest: +SKIP("undefined vars")>>> self.register_buffer('running_mean', torch.zeros(num_features))"""if persistent is False and isinstance(self, torch.jit.ScriptModule):raise RuntimeError("ScriptModule does not support non-persistent buffers")if '_buffers' not in self.__dict__:raise AttributeError("cannot assign buffer before Module.__init__() call")elif not isinstance(name, str):raise TypeError("buffer name should be a string. ""Got {}".format(torch.typename(name)))elif '.' in name:raise KeyError("buffer name can't contain \".\"")elif name == '':raise KeyError("buffer name can't be empty string \"\"")elif hasattr(self, name) and name not in self._buffers:raise KeyError("attribute '{}' already exists".format(name))elif tensor is not None and not isinstance(tensor, torch.Tensor):raise TypeError("cannot assign '{}' object to buffer '{}' ""(torch Tensor or None required)".format(torch.typename(tensor), name))else:for hook in _global_buffer_registration_hooks.values():output = hook(self, name, tensor)if output is not None:tensor = outputself._buffers[name] = tensorif persistent:self._non_persistent_buffers_set.discard(name)else:self._non_persistent_buffers_set.add(name)def register_parameter(self, name: str, param: Optional[Parameter]) -> None:r"""Adds a parameter to the module.The parameter can be accessed as an attribute using given name.Args:name (str): name of the parameter. The parameter can be accessedfrom this module using the given nameparam (Parameter or None): parameter to be added to the module. If``None``, then operations that run on parameters, such as :attr:`cuda`,are ignored. If ``None``, the parameter is **not** included in themodule's :attr:`state_dict`."""if '_parameters' not in self.__dict__:raise AttributeError("cannot assign parameter before Module.__init__() call")elif not isinstance(name, str):raise TypeError("parameter name should be a string. ""Got {}".format(torch.typename(name)))elif '.' in name:raise KeyError("parameter name can't contain \".\"")elif name == '':raise KeyError("parameter name can't be empty string \"\"")elif hasattr(self, name) and name not in self._parameters:raise KeyError("attribute '{}' already exists".format(name))if param is None:self._parameters[name] = Noneelif not isinstance(param, Parameter):raise TypeError("cannot assign '{}' object to parameter '{}' ""(torch.nn.Parameter or None required)".format(torch.typename(param), name))elif param.grad_fn:raise ValueError("Cannot assign non-leaf Tensor to parameter '{0}'. Model ""parameters must be created explicitly. To express '{0}' ""as a function of another Tensor, compute the value in ""the forward() method.".format(name))else:for hook in _global_parameter_registration_hooks.values():output = hook(self, name, param)if output is not None:param = outputself._parameters[name] = paramdef add_module(self, name: str, module: Optional['Module']) -> None:r"""Adds a child module to the current module.The module can be accessed as an attribute using the given name.Args:name (str): name of the child module. The child module can beaccessed from this module using the given namemodule (Module): child module to be added to the module."""if not isinstance(module, Module) and module is not None:raise TypeError("{} is not a Module subclass".format(torch.typename(module)))elif not isinstance(name, str):raise TypeError("module name should be a string. Got {}".format(torch.typename(name)))elif hasattr(self, name) and name not in self._modules:raise KeyError("attribute '{}' already exists".format(name))elif '.' in name:raise KeyError("module name can't contain \".\", got: {}".format(name))elif name == '':raise KeyError("module name can't be empty string \"\"")for hook in _global_module_registration_hooks.values():output = hook(self, name, module)if output is not None:module = outputself._modules[name] = moduledef register_module(self, name: str, module: Optional['Module']) -> None:r"""Alias for :func:`add_module`."""self.add_module(name, module)def get_submodule(self, target: str) -> "Module":"""Returns the submodule given by ``target`` if it exists,otherwise throws an error.For example, let's say you have an ``nn.Module`` ``A`` thatlooks like this:.. code-block:: textA((net_b): Module((net_c): Module((conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2)))(linear): Linear(in_features=100, out_features=200, bias=True)))(The diagram shows an ``nn.Module`` ``A``. ``A`` has a nestedsubmodule ``net_b``, which itself has two submodules ``net_c``and ``linear``. ``net_c`` then has a submodule ``conv``.)To check whether or not we have the ``linear`` submodule, wewould call ``get_submodule("net_b.linear")``. To check whetherwe have the ``conv`` submodule, we would call``get_submodule("net_b.net_c.conv")``.The runtime of ``get_submodule`` is bounded by the degreeof module nesting in ``target``. A query against``named_modules`` achieves the same result, but it is O(N) inthe number of transitive modules. So, for a simple check to seeif some submodule exists, ``get_submodule`` should always beused.Args:target: The fully-qualified string name of the submoduleto look for. (See above example for how to specify afully-qualified string.)Returns:torch.nn.Module: The submodule referenced by ``target``Raises:AttributeError: If the target string references an invalidpath or resolves to something that is not an``nn.Module``"""if target == "":return selfatoms: List[str] = target.split(".")mod: torch.nn.Module = selffor item in atoms:if not hasattr(mod, item):raise AttributeError(mod._get_name() + " has no ""attribute `" + item + "`")mod = getattr(mod, item)if not isinstance(mod, torch.nn.Module):raise AttributeError("`" + item + "` is not ""an nn.Module")return moddef get_parameter(self, target: str) -> "Parameter":"""Returns the parameter given by ``target`` if it exists,otherwise throws an error.See the docstring for ``get_submodule`` for a more detailedexplanation of this method's functionality as well as how tocorrectly specify ``target``.Args:target: The fully-qualified string name of the Parameterto look for. (See ``get_submodule`` for how to specify afully-qualified string.)Returns:torch.nn.Parameter: The Parameter referenced by ``target``Raises:AttributeError: If the target string references an invalidpath or resolves to something that is not an``nn.Parameter``"""module_path, _, param_name = target.rpartition(".")mod: torch.nn.Module = self.get_submodule(module_path)if not hasattr(mod, param_name):raise AttributeError(mod._get_name() + " has no attribute `"+ param_name + "`")param: torch.nn.Parameter = getattr(mod, param_name)if not isinstance(param, torch.nn.Parameter):raise AttributeError("`" + param_name + "` is not an ""nn.Parameter")return paramdef get_buffer(self, target: str) -> "Tensor":"""Returns the buffer given by ``target`` if it exists,otherwise throws an error.See the docstring for ``get_submodule`` for a more detailedexplanation of this method's functionality as well as how tocorrectly specify ``target``.Args:target: The fully-qualified string name of the bufferto look for. (See ``get_submodule`` for how to specify afully-qualified string.)Returns:torch.Tensor: The buffer referenced by ``target``Raises:AttributeError: If the target string references an invalidpath or resolves to something that is not abuffer"""module_path, _, buffer_name = target.rpartition(".")mod: torch.nn.Module = self.get_submodule(module_path)if not hasattr(mod, buffer_name):raise AttributeError(mod._get_name() + " has no attribute `"+ buffer_name + "`")buffer: torch.Tensor = getattr(mod, buffer_name)if buffer_name not in mod._buffers:raise AttributeError("`" + buffer_name + "` is not a buffer")return bufferdef get_extra_state(self) -> Any:"""Returns any extra state to include in the module's state_dict.Implement this and a corresponding :func:`set_extra_state` for your moduleif you need to store extra state. This function is called when building themodule's `state_dict()`.Note that extra state should be picklable to ensure working serializationof the state_dict. We only provide provide backwards compatibility guaranteesfor serializing Tensors; other objects may break backwards compatibility iftheir serialized pickled form changes.Returns:object: Any extra state to store in the module's state_dict"""raise RuntimeError("Reached a code path in Module.get_extra_state() that should never be called. ""Please file an issue at https://github.com/pytorch/pytorch/issues/new?template=bug-report.yml ""to report this bug.")def set_extra_state(self, state: Any):"""This function is called from :func:`load_state_dict` to handle any extra statefound within the `state_dict`. Implement this function and a corresponding:func:`get_extra_state` for your module if you need to store extra state within its`state_dict`.Args:state (dict): Extra state from the `state_dict`"""raise RuntimeError("Reached a code path in Module.set_extra_state() that should never be called. ""Please file an issue at https://github.com/pytorch/pytorch/issues/new?template=bug-report.yml ""to report this bug.")def _apply(self, fn):for module in self.children():module._apply(fn)def compute_should_use_set_data(tensor, tensor_applied):if torch._has_compatible_shallow_copy_type(tensor, tensor_applied):# If the new tensor has compatible tensor type as the existing tensor,# the current behavior is to change the tensor in-place using `.data =`,# and the future behavior is to overwrite the existing tensor. However,# changing the current behavior is a BC-breaking change, and we want it# to happen in future releases. So for now we introduce the# `torch.__future__.get_overwrite_module_params_on_conversion()`# global flag to let the user control whether they want the future# behavior of overwriting the existing tensor or not.return not torch.__future__.get_overwrite_module_params_on_conversion()else:return Falsefor key, param in self._parameters.items():if param is None:continue# Tensors stored in modules are graph leaves, and we don't want to# track autograd history of `param_applied`, so we have to use# `with torch.no_grad():`with torch.no_grad():param_applied = fn(param)should_use_set_data = compute_should_use_set_data(param, param_applied)if should_use_set_data:param.data = param_appliedout_param = paramelse:assert isinstance(param, Parameter)assert param.is_leafout_param = Parameter(param_applied, param.requires_grad)self._parameters[key] = out_paramif param.grad is not None:with torch.no_grad():grad_applied = fn(param.grad)should_use_set_data = compute_should_use_set_data(param.grad, grad_applied)if should_use_set_data:assert out_param.grad is not Noneout_param.grad.data = grad_appliedelse:assert param.grad.is_leafout_param.grad = grad_applied.requires_grad_(param.grad.requires_grad)for key, buf in self._buffers.items():if buf is not None:self._buffers[key] = fn(buf)return selfdef apply(self: T, fn: Callable[['Module'], None]) -> T:r"""Applies ``fn`` recursively to every submodule (as returned by ``.children()``)as well as self. Typical use includes initializing the parameters of a model(see also :ref:`nn-init-doc`).Args:fn (:class:`Module` -> None): function to be applied to each submoduleReturns:Module: selfExample::>>> @torch.no_grad()>>> def init_weights(m):>>> print(m)>>> if type(m) == nn.Linear:>>> m.weight.fill_(1.0)>>> print(m.weight)>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))>>> net.apply(init_weights)Linear(in_features=2, out_features=2, bias=True)Parameter containing:tensor([[1., 1.],[1., 1.]], requires_grad=True)Linear(in_features=2, out_features=2, bias=True)Parameter containing:tensor([[1., 1.],[1., 1.]], requires_grad=True)Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True))"""for module in self.children():module.apply(fn)fn(self)return selfdef cuda(self: T, device: Optional[Union[int, device]] = None) -> T:r"""Moves all model parameters and buffers to the GPU.This also makes associated parameters and buffers different objects. Soit should be called before constructing optimizer if the module willlive on GPU while being optimized... note::This method modifies the module in-place.Args:device (int, optional): if specified, all parameters will becopied to that deviceReturns:Module: self"""return self._apply(lambda t: t.cuda(device))def ipu(self: T, device: Optional[Union[int, device]] = None) -> T:r"""Moves all model parameters and buffers to the IPU.This also makes associated parameters and buffers different objects. Soit should be called before constructing optimizer if the module willlive on IPU while being optimized... note::This method modifies the module in-place.Arguments:device (int, optional): if specified, all parameters will becopied to that deviceReturns:Module: self"""return self._apply(lambda t: t.ipu(device))def xpu(self: T, device: Optional[Union[int, device]] = None) -> T:r"""Moves all model parameters and buffers to the XPU.This also makes associated parameters and buffers different objects. Soit should be called before constructing optimizer if the module willlive on XPU while being optimized... note::This method modifies the module in-place.Arguments:device (int, optional): if specified, all parameters will becopied to that deviceReturns:Module: self"""return self._apply(lambda t: t.xpu(device))def cpu(self: T) -> T:r"""Moves all model parameters and buffers to the CPU... note::This method modifies the module in-place.Returns:Module: self"""return self._apply(lambda t: t.cpu())def type(self: T, dst_type: Union[dtype, str]) -> T:r"""Casts all parameters and buffers to :attr:`dst_type`... note::This method modifies the module in-place.Args:dst_type (type or string): the desired typeReturns:Module: self"""return self._apply(lambda t: t.type(dst_type))def float(self: T) -> T:r"""Casts all floating point parameters and buffers to ``float`` datatype... note::This method modifies the module in-place.Returns:Module: self"""return self._apply(lambda t: t.float() if t.is_floating_point() else t)def double(self: T) -> T:r"""Casts all floating point parameters and buffers to ``double`` datatype... note::This method modifies the module in-place.Returns:Module: self"""return self._apply(lambda t: t.double() if t.is_floating_point() else t)def half(self: T) -> T:r"""Casts all floating point parameters and buffers to ``half`` datatype... note::This method modifies the module in-place.Returns:Module: self"""return self._apply(lambda t: t.half() if t.is_floating_point() else t)def bfloat16(self: T) -> T:r"""Casts all floating point parameters and buffers to ``bfloat16`` datatype... note::This method modifies the module in-place.Returns:Module: self"""return self._apply(lambda t: t.bfloat16() if t.is_floating_point() else t)def to_empty(self: T, *, device: Union[str, device]) -> T:r"""Moves the parameters and buffers to the specified device without copying storage.Args:device (:class:`torch.device`): The desired device of the parametersand buffers in this module.Returns:Module: self"""return self._apply(lambda t: torch.empty_like(t, device=device))@overloaddef to(self: T, device: Optional[Union[int, device]] = ..., dtype: Optional[Union[dtype, str]] = ...,non_blocking: bool = ...) -> T:...@overloaddef to(self: T, dtype: Union[dtype, str], non_blocking: bool = ...) -> T:...@overloaddef to(self: T, tensor: Tensor, non_blocking: bool = ...) -> T:...def to(self, *args, **kwargs):r"""Moves and/or casts the parameters and buffers.This can be called as.. function:: to(device=None, dtype=None, non_blocking=False):noindex:.. function:: to(dtype, non_blocking=False):noindex:.. function:: to(tensor, non_blocking=False):noindex:.. function:: to(memory_format=torch.channels_last):noindex:Its signature is similar to :meth:`torch.Tensor.to`, but only acceptsfloating point or complex :attr:`dtype`\ s. In addition, this method willonly cast the floating point or complex parameters and buffers to :attr:`dtype`(if given). The integral parameters and buffers will be moved:attr:`device`, if that is given, but with dtypes unchanged. When:attr:`non_blocking` is set, it tries to convert/move asynchronouslywith respect to the host if possible, e.g., moving CPU Tensors withpinned memory to CUDA devices.See below for examples... note::This method modifies the module in-place.Args:device (:class:`torch.device`): the desired device of the parametersand buffers in this moduledtype (:class:`torch.dtype`): the desired floating point or complex dtype ofthe parameters and buffers in this moduletensor (torch.Tensor): Tensor whose dtype and device are the desireddtype and device for all parameters and buffers in this modulememory_format (:class:`torch.memory_format`): the desired memoryformat for 4D parameters and buffers in this module (keywordonly argument)Returns:Module: selfExamples::>>> # xdoctest: +IGNORE_WANT("non-deterministic")>>> linear = nn.Linear(2, 2)>>> linear.weightParameter containing:tensor([[ 0.1913, -0.3420],[-0.5113, -0.2325]])>>> linear.to(torch.double)Linear(in_features=2, out_features=2, bias=True)>>> linear.weightParameter containing:tensor([[ 0.1913, -0.3420],[-0.5113, -0.2325]], dtype=torch.float64)>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_CUDA1)>>> gpu1 = torch.device("cuda:1")>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)Linear(in_features=2, out_features=2, bias=True)>>> linear.weightParameter containing:tensor([[ 0.1914, -0.3420],[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')>>> cpu = torch.device("cpu")>>> linear.to(cpu)Linear(in_features=2, out_features=2, bias=True)>>> linear.weightParameter containing:tensor([[ 0.1914, -0.3420],[-0.5112, -0.2324]], dtype=torch.float16)>>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)>>> linear.weightParameter containing:tensor([[ 0.3741+0.j, 0.2382+0.j],[ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)>>> linear(torch.ones(3, 2, dtype=torch.cdouble))tensor([[0.6122+0.j, 0.1150+0.j],[0.6122+0.j, 0.1150+0.j],[0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)"""device, dtype, non_blocking, convert_to_format = torch._C._nn._parse_to(*args, **kwargs)if dtype is not None:if not (dtype.is_floating_point or dtype.is_complex):raise TypeError('nn.Module.to only accepts floating point or complex ''dtypes, but got desired dtype={}'.format(dtype))if dtype.is_complex:warnings.warn("Complex modules are a new feature under active development whose design may change, ""and some modules might not work as expected when using complex tensors as parameters or buffers. ""Please file an issue at https://github.com/pytorch/pytorch/issues/new?template=bug-report.yml ""if a complex module does not work as expected.")def convert(t):if convert_to_format is not None and t.dim() in (4, 5):return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None,non_blocking, memory_format=convert_to_format)return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)return self._apply(convert)def register_full_backward_pre_hook(self,hook: Callable[["Module", _grad_t], Union[None, _grad_t]],prepend: bool = False,) -> RemovableHandle:r"""Registers a backward pre-hook on the module.The hook will be called every time the gradients for the module are computed.The hook should have the following signature::hook(module, grad_output) -> Tensor or NoneThe :attr:`grad_output` is a tuple. The hook shouldnot modify its arguments, but it can optionally return a new gradient withrespect to the output that will be used in place of :attr:`grad_output` insubsequent computations. Entries in :attr:`grad_output` will be ``None`` forall non-Tensor arguments.For technical reasons, when this hook is applied to a Module, its forward function willreceive a view of each Tensor passed to the Module. Similarly the caller will receive a viewof each Tensor returned by the Module's forward function... warning ::Modifying inputs inplace is not allowed when using backward hooks andwill raise an error.Args:hook (Callable): The user-defined hook to be registered.prepend (bool): If true, the provided ``hook`` will be fired beforeall existing ``backward_pre`` hooks on this:class:`torch.nn.modules.Module`. Otherwise, the provided``hook`` will be fired after all existing ``backward_pre`` hookson this :class:`torch.nn.modules.Module`. Note that global``backward_pre`` hooks registered with:func:`register_module_full_backward_pre_hook` will fire beforeall hooks registered by this method.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(self._backward_pre_hooks)self._backward_pre_hooks[handle.id] = hookif prepend:self._backward_pre_hooks.move_to_end(handle.id, last=False) # type: ignore[attr-defined]return handledef register_backward_hook(self, hook: Callable[['Module', _grad_t, _grad_t], Union[None, _grad_t]]) -> RemovableHandle:r"""Registers a backward hook on the module.This function is deprecated in favor of :meth:`~torch.nn.Module.register_full_backward_hook` andthe behavior of this function will change in future versions.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""if self._is_full_backward_hook is True:raise RuntimeError("Cannot use both regular backward hooks and full backward hooks on a ""single Module. Please use only one of them.")self._is_full_backward_hook = Falsehandle = hooks.RemovableHandle(self._backward_hooks)self._backward_hooks[handle.id] = hookreturn handledef register_full_backward_hook(self,hook: Callable[["Module", _grad_t, _grad_t], Union[None, _grad_t]],prepend: bool = False,) -> RemovableHandle:r"""Registers a backward hook on the module.The hook will be called every time the gradients with respect to a moduleare computed, i.e. the hook will execute if and only if the gradients withrespect to module outputs are computed. The hook should have the followingsignature::hook(module, grad_input, grad_output) -> tuple(Tensor) or NoneThe :attr:`grad_input` and :attr:`grad_output` are tuples that contain the gradientswith respect to the inputs and outputs respectively. The hook shouldnot modify its arguments, but it can optionally return a new gradient withrespect to the input that will be used in place of :attr:`grad_input` insubsequent computations. :attr:`grad_input` will only correspond to the inputs givenas positional arguments and all kwarg arguments are ignored. Entriesin :attr:`grad_input` and :attr:`grad_output` will be ``None`` for all non-Tensorarguments.For technical reasons, when this hook is applied to a Module, its forward function willreceive a view of each Tensor passed to the Module. Similarly the caller will receive a viewof each Tensor returned by the Module's forward function... warning ::Modifying inputs or outputs inplace is not allowed when using backward hooks andwill raise an error.Args:hook (Callable): The user-defined hook to be registered.prepend (bool): If true, the provided ``hook`` will be fired beforeall existing ``backward`` hooks on this:class:`torch.nn.modules.Module`. Otherwise, the provided``hook`` will be fired after all existing ``backward`` hooks onthis :class:`torch.nn.modules.Module`. Note that global``backward`` hooks registered with:func:`register_module_full_backward_hook` will fire beforeall hooks registered by this method.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""if self._is_full_backward_hook is False:raise RuntimeError("Cannot use both regular backward hooks and full backward hooks on a ""single Module. Please use only one of them.")self._is_full_backward_hook = Truehandle = hooks.RemovableHandle(self._backward_hooks)self._backward_hooks[handle.id] = hookif prepend:self._backward_hooks.move_to_end(handle.id, last=False) # type: ignore[attr-defined]return handledef _get_backward_hooks(self):r"""Returns the backward hooks for use in the call function.It returns two lists, one with the full backward hooks and one with the non-fullbackward hooks."""full_backward_hooks: List[Callable] = []if (_global_is_full_backward_hook is True):full_backward_hooks += _global_backward_hooks.values()if (self._is_full_backward_hook is True):full_backward_hooks += self._backward_hooks.values()non_full_backward_hooks: List[Callable] = []if (_global_is_full_backward_hook is False):non_full_backward_hooks += _global_backward_hooks.values()if (self._is_full_backward_hook is False):non_full_backward_hooks += self._backward_hooks.values()return full_backward_hooks, non_full_backward_hooksdef _get_backward_pre_hooks(self):backward_pre_hooks: List[Callable] = []backward_pre_hooks += _global_backward_pre_hooks.values()backward_pre_hooks += self._backward_pre_hooks.values()return backward_pre_hooksdef _maybe_warn_non_full_backward_hook(self, inputs, result, grad_fn):if not isinstance(result, torch.Tensor):if not (isinstance(result, tuple) and all(isinstance(r, torch.Tensor) for r in result)):warnings.warn("Using non-full backward hooks on a Module that does not return a ""single Tensor or a tuple of Tensors is deprecated and will be removed ""in future versions. This hook will be missing some of the grad_output. ""Please use register_full_backward_hook to get the documented behavior.")returnelse:result = (result,)if not isinstance(inputs, torch.Tensor):if not (isinstance(inputs, tuple) and all(isinstance(i, torch.Tensor) for i in inputs)):warnings.warn("Using non-full backward hooks on a Module that does not take as input a ""single Tensor or a tuple of Tensors is deprecated and will be removed ""in future versions. This hook will be missing some of the grad_input. ""Please use register_full_backward_hook to get the documented behavior.")returnelse:inputs = (inputs,)# At this point we are sure that inputs and result are tuple of Tensorsout_grad_fn = {r.grad_fn for r in result if r.grad_fn is not None}if len(out_grad_fn) == 0 or (len(out_grad_fn) == 1 and grad_fn not in out_grad_fn):warnings.warn("Using a non-full backward hook when outputs are nested in python data structure ""is deprecated and will be removed in future versions. This hook will be missing ""some grad_output.")elif len(out_grad_fn) > 1:warnings.warn("Using a non-full backward hook when outputs are generated by different autograd Nodes ""is deprecated and will be removed in future versions. This hook will be missing ""some grad_output. Please use register_full_backward_hook to get the documented behavior.")else:# At this point the grad_ouput part of the hook will most likely be correctinputs_grad_fn = {i.grad_fn for i in inputs if i.grad_fn is not None}next_functions = {n[0] for n in grad_fn.next_functions}if inputs_grad_fn != next_functions:warnings.warn("Using a non-full backward hook when the forward contains multiple autograd Nodes ""is deprecated and will be removed in future versions. This hook will be missing ""some grad_input. Please use register_full_backward_hook to get the documented ""behavior.")def register_forward_pre_hook(self,hook: Union[Callable[[T, Tuple[Any, ...]], Optional[Any]],Callable[[T, Tuple[Any, ...], Dict[str, Any]], Optional[Tuple[Any, Dict[str, Any]]]],],*,prepend: bool = False,with_kwargs: bool = False,) -> RemovableHandle:r"""Registers a forward pre-hook on the module.The hook will be called every time before :func:`forward` is invoked.If ``with_kwargs`` is false or not specified, the input contains onlythe positional arguments given to the module. Keyword arguments won't bepassed to the hooks and only to the ``forward``. The hook can modify theinput. User can either return a tuple or a single modified value in thehook. We will wrap the value into a tuple if a single value is returned(unless that value is already a tuple). The hook should have thefollowing signature::hook(module, args) -> None or modified inputIf ``with_kwargs`` is true, the forward pre-hook will be passed thekwargs given to the forward function. And if the hook modifies theinput, both the args and kwargs should be returned. The hook should havethe following signature::hook(module, args, kwargs) -> None or a tuple of modified input and kwargsArgs:hook (Callable): The user defined hook to be registered.prepend (bool): If true, the provided ``hook`` will be fired beforeall existing ``forward_pre`` hooks on this:class:`torch.nn.modules.Module`. Otherwise, the provided``hook`` will be fired after all existing ``forward_pre`` hookson this :class:`torch.nn.modules.Module`. Note that global``forward_pre`` hooks registered with:func:`register_module_forward_pre_hook` will fire before allhooks registered by this method.Default: ``False``with_kwargs (bool): If true, the ``hook`` will be passed the kwargsgiven to the forward function.Default: ``False``Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(self._forward_pre_hooks,extra_dict=self._forward_pre_hooks_with_kwargs)self._forward_pre_hooks[handle.id] = hookif with_kwargs:self._forward_pre_hooks_with_kwargs[handle.id] = Trueif prepend:self._forward_pre_hooks.move_to_end(handle.id, last=False) # type: ignore[attr-defined]return handledef register_forward_hook(self,hook: Union[Callable[[T, Tuple[Any, ...], Any], Optional[Any]],Callable[[T, Tuple[Any, ...], Dict[str, Any], Any], Optional[Any]],],*,prepend: bool = False,with_kwargs: bool = False,) -> RemovableHandle:r"""Registers a forward hook on the module.The hook will be called every time after :func:`forward` has computed an output.If ``with_kwargs`` is ``False`` or not specified, the input contains onlythe positional arguments given to the module. Keyword arguments won't bepassed to the hooks and only to the ``forward``. The hook can modify theoutput. It can modify the input inplace but it will not have effect onforward since this is called after :func:`forward` is called. The hookshould have the following signature::hook(module, args, output) -> None or modified outputIf ``with_kwargs`` is ``True``, the forward hook will be passed the``kwargs`` given to the forward function and be expected to return theoutput possibly modified. The hook should have the following signature::hook(module, args, kwargs, output) -> None or modified outputArgs:hook (Callable): The user defined hook to be registered.prepend (bool): If ``True``, the provided ``hook`` will be firedbefore all existing ``forward`` hooks on this:class:`torch.nn.modules.Module`. Otherwise, the provided``hook`` will be fired after all existing ``forward`` hooks onthis :class:`torch.nn.modules.Module`. Note that global``forward`` hooks registered with:func:`register_module_forward_hook` will fire before all hooksregistered by this method.Default: ``False``with_kwargs (bool): If ``True``, the ``hook`` will be passed thekwargs given to the forward function.Default: ``False``Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(self._forward_hooks,extra_dict=self._forward_hooks_with_kwargs)self._forward_hooks[handle.id] = hookif with_kwargs:self._forward_hooks_with_kwargs[handle.id] = Trueif prepend:self._forward_hooks.move_to_end(handle.id, last=False) # type: ignore[attr-defined]return handledef _slow_forward(self, *input, **kwargs):tracing_state = torch._C._get_tracing_state()if not tracing_state or isinstance(self.forward, torch._C.ScriptMethod):return self.forward(*input, **kwargs)recording_scopes = torch.jit._trace._trace_module_map is not Noneif recording_scopes:# type ignore was added because at this point one knows that# torch.jit._trace._trace_module_map is not Optional and has type Dict[Any, Any]name = torch.jit._trace._trace_module_map[self] if self in torch.jit._trace._trace_module_map else None # type: ignore[index, operator] # noqa: B950if name:tracing_state.push_scope(name)else:recording_scopes = Falsetry:result = self.forward(*input, **kwargs)finally:if recording_scopes:tracing_state.pop_scope()return resultdef _call_impl(self, *args, **kwargs):forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)# If we don't have any hooks, we want to skip the rest of the logic in# this function, and just call forward.if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooksor _global_backward_pre_hooks or _global_backward_hooksor _global_forward_hooks or _global_forward_pre_hooks):return forward_call(*args, **kwargs)# Do not call functions when jit is usedfull_backward_hooks, non_full_backward_hooks = [], []backward_pre_hooks = []if self._backward_pre_hooks or _global_backward_pre_hooks:backward_pre_hooks = self._get_backward_pre_hooks()if self._backward_hooks or _global_backward_hooks:full_backward_hooks, non_full_backward_hooks = self._get_backward_hooks()if _global_forward_pre_hooks or self._forward_pre_hooks:for hook_id, hook in (*_global_forward_pre_hooks.items(),*self._forward_pre_hooks.items(),):if hook_id in self._forward_pre_hooks_with_kwargs:result = hook(self, args, kwargs) # type: ignore[misc]if result is not None:if isinstance(result, tuple) and len(result) == 2:args, kwargs = resultelse:raise RuntimeError("forward pre-hook must return None or a tuple "f"of (new_args, new_kwargs), but got {result}.")else:result = hook(self, args)if result is not None:if not isinstance(result, tuple):result = (result,)args = resultbw_hook = Noneif full_backward_hooks or backward_pre_hooks:bw_hook = hooks.BackwardHook(self, full_backward_hooks, backward_pre_hooks)args = bw_hook.setup_input_hook(args)result = forward_call(*args, **kwargs)if _global_forward_hooks or self._forward_hooks:for hook_id, hook in (*_global_forward_hooks.items(),*self._forward_hooks.items(),):if hook_id in self._forward_hooks_with_kwargs:hook_result = hook(self, args, kwargs, result)else:hook_result = hook(self, args, result)if hook_result is not None:result = hook_resultif bw_hook:if not isinstance(result, (torch.Tensor, tuple)):warnings.warn("For backward hooks to be called,"" module output should be a Tensor or a tuple of Tensors"f" but received {type(result)}")result = bw_hook.setup_output_hook(result)# Handle the non-full backward hooksif non_full_backward_hooks:var = resultwhile not isinstance(var, torch.Tensor):if isinstance(var, dict):var = next((v for v in var.values() if isinstance(v, torch.Tensor)))else:var = var[0]grad_fn = var.grad_fnif grad_fn is not None:for hook in non_full_backward_hooks:grad_fn.register_hook(_WrappedHook(hook, self))self._maybe_warn_non_full_backward_hook(args, result, grad_fn)return result__call__ : Callable[..., Any] = _call_impldef __setstate__(self, state):self.__dict__.update(state)# Support loading old checkpoints that don't have the following attrs:if '_forward_pre_hooks' not in self.__dict__:self._forward_pre_hooks = OrderedDict()if '_forward_pre_hooks_with_kwargs' not in self.__dict__:self._forward_pre_hooks_with_kwargs = OrderedDict()if '_forward_hooks_with_kwargs' not in self.__dict__:self._forward_hooks_with_kwargs = OrderedDict()if '_state_dict_hooks' not in self.__dict__:self._state_dict_hooks = OrderedDict()if '_state_dict_pre_hooks' not in self.__dict__:self._state_dict_pre_hooks = OrderedDict()if '_load_state_dict_pre_hooks' not in self.__dict__:self._load_state_dict_pre_hooks = OrderedDict()if '_load_state_dict_post_hooks' not in self.__dict__:self._load_state_dict_post_hooks = OrderedDict()if '_non_persistent_buffers_set' not in self.__dict__:self._non_persistent_buffers_set = set()if '_is_full_backward_hook' not in self.__dict__:self._is_full_backward_hook = Noneif '_backward_pre_hooks' not in self.__dict__:self._backward_pre_hooks = OrderedDict()def __getattr__(self, name: str) -> Union[Tensor, 'Module']:if '_parameters' in self.__dict__:_parameters = self.__dict__['_parameters']if name in _parameters:return _parameters[name]if '_buffers' in self.__dict__:_buffers = self.__dict__['_buffers']if name in _buffers:return _buffers[name]if '_modules' in self.__dict__:modules = self.__dict__['_modules']if name in modules:return modules[name]raise AttributeError("'{}' object has no attribute '{}'".format(type(self).__name__, name))def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None:def remove_from(*dicts_or_sets):for d in dicts_or_sets:if name in d:if isinstance(d, dict):del d[name]else:d.discard(name)params = self.__dict__.get('_parameters')if isinstance(value, Parameter):if params is None:raise AttributeError("cannot assign parameters before Module.__init__() call")remove_from(self.__dict__, self._buffers, self._modules, self._non_persistent_buffers_set)self.register_parameter(name, value)elif params is not None and name in params:if value is not None:raise TypeError("cannot assign '{}' as parameter '{}' ""(torch.nn.Parameter or None expected)".format(torch.typename(value), name))self.register_parameter(name, value)else:modules = self.__dict__.get('_modules')if isinstance(value, Module):if modules is None:raise AttributeError("cannot assign module before Module.__init__() call")remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set)for hook in _global_module_registration_hooks.values():output = hook(self, name, value)if output is not None:value = outputmodules[name] = valueelif modules is not None and name in modules:if value is not None:raise TypeError("cannot assign '{}' as child module '{}' ""(torch.nn.Module or None expected)".format(torch.typename(value), name))for hook in _global_module_registration_hooks.values():output = hook(self, name, value)if output is not None:value = outputmodules[name] = valueelse:buffers = self.__dict__.get('_buffers')if buffers is not None and name in buffers:if value is not None and not isinstance(value, torch.Tensor):raise TypeError("cannot assign '{}' as buffer '{}' ""(torch.Tensor or None expected)".format(torch.typename(value), name))for hook in _global_buffer_registration_hooks.values():output = hook(self, name, value)if output is not None:value = outputbuffers[name] = valueelse:super().__setattr__(name, value)def __delattr__(self, name):if name in self._parameters:del self._parameters[name]elif name in self._buffers:del self._buffers[name]self._non_persistent_buffers_set.discard(name)elif name in self._modules:del self._modules[name]else:super().__delattr__(name)def _register_state_dict_hook(self, hook):r"""These hooks will be called with arguments: `self`, `state_dict`,`prefix`, `local_metadata`, after the `state_dict` of `self` is set.Note that only parameters and buffers of `self` or its children areguaranteed to exist in `state_dict`. The hooks may modify `state_dict`inplace or return a new one."""handle = hooks.RemovableHandle(self._state_dict_hooks)self._state_dict_hooks[handle.id] = hookreturn handledef register_state_dict_pre_hook(self, hook):r"""These hooks will be called with arguments: ``self``, ``prefix``,and ``keep_vars`` before calling ``state_dict`` on ``self``. The registeredhooks can be used to perform pre-processing before the ``state_dict``call is made."""handle = hooks.RemovableHandle(self._state_dict_pre_hooks)self._state_dict_pre_hooks[handle.id] = hookreturn handledef _save_to_state_dict(self, destination, prefix, keep_vars):r"""Saves module state to `destination` dictionary, containing a stateof the module, but not its descendants. This is called on everysubmodule in :meth:`~torch.nn.Module.state_dict`.In rare cases, subclasses can achieve class-specific behavior byoverriding this method with custom logic.Args:destination (dict): a dict where state will be storedprefix (str): the prefix for parameters and buffers used in thismodule"""for hook in self._state_dict_pre_hooks.values():hook(self, prefix, keep_vars)for name, param in self._parameters.items():if param is not None:destination[prefix + name] = param if keep_vars else param.detach()for name, buf in self._buffers.items():if buf is not None and name not in self._non_persistent_buffers_set:destination[prefix + name] = buf if keep_vars else buf.detach()extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIXif getattr(self.__class__, "get_extra_state", Module.get_extra_state) is not Module.get_extra_state:destination[extra_state_key] = self.get_extra_state()# The user can pass an optional arbitrary mappable object to `state_dict`, in which case `state_dict` returns# back that same object. But if they pass nothing, an `OrderedDict` is created and returned.T_destination = TypeVar('T_destination', bound=Dict[str, Any])@overloaddef state_dict(self, *, destination: T_destination, prefix: str = ..., keep_vars: bool = ...) -> T_destination:...@overloaddef state_dict(self, *, prefix: str = ..., keep_vars: bool = ...) -> Dict[str, Any]:...# TODO: Change `*args` to `*` and remove the copprespinding warning in docs when BC allows.# Also remove the logic for arg parsing together.def state_dict(self, *args, destination=None, prefix='', keep_vars=False):r"""Returns a dictionary containing references to the whole state of the module.Both parameters and persistent buffers (e.g. running averages) areincluded. Keys are corresponding parameter and buffer names.Parameters and buffers set to ``None`` are not included... note::The returned object is a shallow copy. It contains referencesto the module's parameters and buffers... warning::Currently ``state_dict()`` also accepts positional arguments for``destination``, ``prefix`` and ``keep_vars`` in order. However,this is being deprecated and keyword arguments will be enforced infuture releases... warning::Please avoid the use of argument ``destination`` as it is notdesigned for end-users.Args:destination (dict, optional): If provided, the state of module willbe updated into the dict and the same object is returned.Otherwise, an ``OrderedDict`` will be created and returned.Default: ``None``.prefix (str, optional): a prefix added to parameter and buffernames to compose the keys in state_dict. Default: ``''``.keep_vars (bool, optional): by default the :class:`~torch.Tensor` sreturned in the state dict are detached from autograd. If it'sset to ``True``, detaching will not be performed.Default: ``False``.Returns:dict:a dictionary containing a whole state of the moduleExample::>>> # xdoctest: +SKIP("undefined vars")>>> module.state_dict().keys()['bias', 'weight']"""# TODO: Remove `args` and the parsing logic when BC allows.if len(args) > 0:if destination is None:destination = args[0]if len(args) > 1 and prefix == '':prefix = args[1]if len(args) > 2 and keep_vars is False:keep_vars = args[2]# DeprecationWarning is ignored by defaultwarnings.warn("Positional args are being deprecated, use kwargs instead. Refer to ""https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict"" for details.")if destination is None:destination = OrderedDict()destination._metadata = OrderedDict()local_metadata = dict(version=self._version)if hasattr(destination, "_metadata"):destination._metadata[prefix[:-1]] = local_metadataself._save_to_state_dict(destination, prefix, keep_vars)for name, module in self._modules.items():if module is not None:module.state_dict(destination=destination, prefix=prefix + name + '.', keep_vars=keep_vars)for hook in self._state_dict_hooks.values():hook_result = hook(self, destination, prefix, local_metadata)if hook_result is not None:destination = hook_resultreturn destinationdef _register_load_state_dict_pre_hook(self, hook, with_module=False):r"""These hooks will be called with arguments: `state_dict`, `prefix`,`local_metadata`, `strict`, `missing_keys`, `unexpected_keys`,`error_msgs`, before loading `state_dict` into `self`. These argumentsare exactly the same as those of `_load_from_state_dict`.If ``with_module`` is ``True``, then the first argument to the hook isan instance of the module.Arguments:hook (Callable): Callable hook that will be invoked beforeloading the state dict.with_module (bool, optional): Whether or not to pass the moduleinstance to the hook as the first parameter."""handle = hooks.RemovableHandle(self._load_state_dict_pre_hooks)self._load_state_dict_pre_hooks[handle.id] = _WrappedHook(hook, self if with_module else None)return handledef register_load_state_dict_post_hook(self, hook):r"""Registers a post hook to be run after module's ``load_state_dict``is called.It should have the following signature::hook(module, incompatible_keys) -> NoneThe ``module`` argument is the current module that this hook is registeredon, and the ``incompatible_keys`` argument is a ``NamedTuple`` consistingof attributes ``missing_keys`` and ``unexpected_keys``. ``missing_keys``is a ``list`` of ``str`` containing the missing keys and``unexpected_keys`` is a ``list`` of ``str`` containing the unexpected keys.The given incompatible_keys can be modified inplace if needed.Note that the checks performed when calling :func:`load_state_dict` with``strict=True`` are affected by modifications the hook makes to``missing_keys`` or ``unexpected_keys``, as expected. Additions to eitherset of keys will result in an error being thrown when ``strict=True``, andclearing out both missing and unexpected keys will avoid an error.Returns::class:`torch.utils.hooks.RemovableHandle`:a handle that can be used to remove the added hook by calling``handle.remove()``"""handle = hooks.RemovableHandle(self._load_state_dict_post_hooks)self._load_state_dict_post_hooks[handle.id] = hookreturn handledef _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,missing_keys, unexpected_keys, error_msgs):r"""Copies parameters and buffers from :attr:`state_dict` into onlythis module, but not its descendants. This is called on every submodulein :meth:`~torch.nn.Module.load_state_dict`. Metadata saved for thismodule in input :attr:`state_dict` is provided as :attr:`local_metadata`.For state dicts without metadata, :attr:`local_metadata` is empty.Subclasses can achieve class-specific backward compatible loading usingthe version number at `local_metadata.get("version", None)`... note:::attr:`state_dict` is not the same object as the input:attr:`state_dict` to :meth:`~torch.nn.Module.load_state_dict`. Soit can be modified.Args:state_dict (dict): a dict containing parameters andpersistent buffers.prefix (str): the prefix for parameters and buffers used in thismodulelocal_metadata (dict): a dict containing the metadata for this module.Seestrict (bool): whether to strictly enforce that the keys in:attr:`state_dict` with :attr:`prefix` match the names ofparameters and buffers in this modulemissing_keys (list of str): if ``strict=True``, add missing keys tothis listunexpected_keys (list of str): if ``strict=True``, add unexpectedkeys to this listerror_msgs (list of str): error messages should be added to thislist, and will be reported together in:meth:`~torch.nn.Module.load_state_dict`"""for hook in self._load_state_dict_pre_hooks.values():hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())local_state = {k: v for k, v in local_name_params if v is not None}for name, param in local_state.items():key = prefix + nameif key in state_dict:input_param = state_dict[key]if not torch.overrides.is_tensor_like(input_param):error_msgs.append('While copying the parameter named "{}", ''expected torch.Tensor or Tensor-like object from checkpoint but ''received {}'.format(key, type(input_param)))continue# This is used to avoid copying uninitialized parameters into# non-lazy modules, since they dont have the hook to do the checks# in such case, it will error when accessing the .shape attribute.is_param_lazy = torch.nn.parameter.is_lazy(param)# Backward compatibility: loading 1-dim tensor from 0.3.* to version 0.4+if not is_param_lazy and len(param.shape) == 0 and len(input_param.shape) == 1:input_param = input_param[0]if not is_param_lazy and input_param.shape != param.shape:# local shape should match the one in checkpointerror_msgs.append('size mismatch for {}: copying a param with shape {} from checkpoint, ''the shape in current model is {}.'.format(key, input_param.shape, param.shape))continuetry:with torch.no_grad():param.copy_(input_param)except Exception as ex:error_msgs.append('While copying the parameter named "{}", ''whose dimensions in the model are {} and ''whose dimensions in the checkpoint are {}, ''an exception occurred : {}.'.format(key, param.size(), input_param.size(), ex.args))elif strict:missing_keys.append(key)extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIXif getattr(self.__class__, "set_extra_state", Module.set_extra_state) is not Module.set_extra_state:if extra_state_key in state_dict:self.set_extra_state(state_dict[extra_state_key])elif strict:missing_keys.append(extra_state_key)elif strict and (extra_state_key in state_dict):unexpected_keys.append(extra_state_key)if strict:for key in state_dict.keys():if key.startswith(prefix) and key != extra_state_key:input_name = key[len(prefix):]input_name = input_name.split('.', 1)[0] # get the name of param/buffer/childif input_name not in self._modules and input_name not in local_state:unexpected_keys.append(key)def load_state_dict(self, state_dict: Mapping[str, Any],strict: bool = True):r"""Copies parameters and buffers from :attr:`state_dict` intothis module and its descendants. If :attr:`strict` is ``True``, thenthe keys of :attr:`state_dict` must exactly match the keys returnedby this module's :meth:`~torch.nn.Module.state_dict` function.Args:state_dict (dict): a dict containing parameters andpersistent buffers.strict (bool, optional): whether to strictly enforce that the keysin :attr:`state_dict` match the keys returned by this module's:meth:`~torch.nn.Module.state_dict` function. Default: ``True``Returns:``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:* **missing_keys** is a list of str containing the missing keys* **unexpected_keys** is a list of str containing the unexpected keysNote:If a parameter or buffer is registered as ``None`` and its corresponding keyexists in :attr:`state_dict`, :meth:`load_state_dict` will raise a``RuntimeError``."""if not isinstance(state_dict, Mapping):raise TypeError("Expected state_dict to be dict-like, got {}.".format(type(state_dict)))missing_keys: List[str] = []unexpected_keys: List[str] = []error_msgs: List[str] = []# copy state_dict so _load_from_state_dict can modify itmetadata = getattr(state_dict, '_metadata', None)state_dict = OrderedDict(state_dict)if metadata is not None:# mypy isn't aware that "_metadata" exists in state_dictstate_dict._metadata = metadata # type: ignore[attr-defined]def load(module, local_state_dict, prefix=''):local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})module._load_from_state_dict(local_state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)for name, child in module._modules.items():if child is not None:child_prefix = prefix + name + '.'child_state_dict = {k: v for k, v in local_state_dict.items() if k.startswith(child_prefix)}load(child, child_state_dict, child_prefix)# Note that the hook can modify missing_keys and unexpected_keys.incompatible_keys = _IncompatibleKeys(missing_keys, unexpected_keys)for hook in module._load_state_dict_post_hooks.values():out = hook(module, incompatible_keys)assert out is None, ("Hooks registered with ``register_load_state_dict_post_hook`` are not""expected to return new values, if incompatible_keys need to be modified,""it should be done inplace.")load(self, state_dict)del loadif strict:if len(unexpected_keys) > 0:error_msgs.insert(0, 'Unexpected key(s) in state_dict: {}. '.format(', '.join('"{}"'.format(k) for k in unexpected_keys)))if len(missing_keys) > 0:error_msgs.insert(0, 'Missing key(s) in state_dict: {}. '.format(', '.join('"{}"'.format(k) for k in missing_keys)))if len(error_msgs) > 0:raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(self.__class__.__name__, "\n\t".join(error_msgs)))return _IncompatibleKeys(missing_keys, unexpected_keys)def _named_members(self, get_members_fn, prefix='', recurse=True, remove_duplicate: bool = True):r"""Helper method for yielding various names + members of modules."""memo = set()modules = self.named_modules(prefix=prefix, remove_duplicate=remove_duplicate) if recurse else [(prefix, self)]for module_prefix, module in modules:members = get_members_fn(module)for k, v in members:if v is None or v in memo:continueif remove_duplicate:memo.add(v)name = module_prefix + ('.' if module_prefix else '') + kyield name, vdef parameters(self, recurse: bool = True) -> Iterator[Parameter]:r"""Returns an iterator over module parameters.This is typically passed to an optimizer.Args:recurse (bool): if True, then yields parameters of this moduleand all submodules. Otherwise, yields only parameters thatare direct members of this module.Yields:Parameter: module parameterExample::>>> # xdoctest: +SKIP("undefined vars")>>> for param in model.parameters():>>> print(type(param), param.size())<class 'torch.Tensor'> (20L,)<class 'torch.Tensor'> (20L, 1L, 5L, 5L)"""for name, param in self.named_parameters(recurse=recurse):yield paramdef named_parameters(self,prefix: str = '',recurse: bool = True,remove_duplicate: bool = True) -> Iterator[Tuple[str, Parameter]]:r"""Returns an iterator over module parameters, yielding both thename of the parameter as well as the parameter itself.Args:prefix (str): prefix to prepend to all parameter names.recurse (bool): if True, then yields parameters of this moduleand all submodules. Otherwise, yields only parameters thatare direct members of this module.remove_duplicate (bool, optional): whether to remove the duplicatedparameters in the result. Defaults to True.Yields:(str, Parameter): Tuple containing the name and parameterExample::>>> # xdoctest: +SKIP("undefined vars")>>> for name, param in self.named_parameters():>>> if name in ['bias']:>>> print(param.size())"""gen = self._named_members(lambda module: module._parameters.items(),prefix=prefix, recurse=recurse, remove_duplicate=remove_duplicate)yield from gendef buffers(self, recurse: bool = True) -> Iterator[Tensor]:r"""Returns an iterator over module buffers.Args:recurse (bool): if True, then yields buffers of this moduleand all submodules. Otherwise, yields only buffers thatare direct members of this module.Yields:torch.Tensor: module bufferExample::>>> # xdoctest: +SKIP("undefined vars")>>> for buf in model.buffers():>>> print(type(buf), buf.size())<class 'torch.Tensor'> (20L,)<class 'torch.Tensor'> (20L, 1L, 5L, 5L)"""for _, buf in self.named_buffers(recurse=recurse):yield bufdef named_buffers(self, prefix: str = '', recurse: bool = True, remove_duplicate: bool = True) -> Iterator[Tuple[str, Tensor]]:r"""Returns an iterator over module buffers, yielding both thename of the buffer as well as the buffer itself.Args:prefix (str): prefix to prepend to all buffer names.recurse (bool, optional): if True, then yields buffers of this moduleand all submodules. Otherwise, yields only buffers thatare direct members of this module. Defaults to True.remove_duplicate (bool, optional): whether to remove the duplicated buffers in the result. Defaults to True.Yields:(str, torch.Tensor): Tuple containing the name and bufferExample::>>> # xdoctest: +SKIP("undefined vars")>>> for name, buf in self.named_buffers():>>> if name in ['running_var']:>>> print(buf.size())"""gen = self._named_members(lambda module: module._buffers.items(),prefix=prefix, recurse=recurse, remove_duplicate=remove_duplicate)yield from gendef children(self) -> Iterator['Module']:r"""Returns an iterator over immediate children modules.Yields:Module: a child module"""for name, module in self.named_children():yield moduledef named_children(self) -> Iterator[Tuple[str, 'Module']]:r"""Returns an iterator over immediate children modules, yielding boththe name of the module as well as the module itself.Yields:(str, Module): Tuple containing a name and child moduleExample::>>> # xdoctest: +SKIP("undefined vars")>>> for name, module in model.named_children():>>> if name in ['conv4', 'conv5']:>>> print(module)"""memo = set()for name, module in self._modules.items():if module is not None and module not in memo:memo.add(module)yield name, moduledef modules(self) -> Iterator['Module']:r"""Returns an iterator over all modules in the network.Yields:Module: a module in the networkNote:Duplicate modules are returned only once. In the followingexample, ``l`` will be returned only once.Example::>>> l = nn.Linear(2, 2)>>> net = nn.Sequential(l, l)>>> for idx, m in enumerate(net.modules()):... print(idx, '->', m)0 -> Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True))1 -> Linear(in_features=2, out_features=2, bias=True)"""for _, module in self.named_modules():yield moduledef named_modules(self, memo: Optional[Set['Module']] = None, prefix: str = '', remove_duplicate: bool = True):r"""Returns an iterator over all modules in the network, yieldingboth the name of the module as well as the module itself.Args:memo: a memo to store the set of modules already added to the resultprefix: a prefix that will be added to the name of the moduleremove_duplicate: whether to remove the duplicated module instances in the resultor notYields:(str, Module): Tuple of name and moduleNote:Duplicate modules are returned only once. In the followingexample, ``l`` will be returned only once.Example::>>> l = nn.Linear(2, 2)>>> net = nn.Sequential(l, l)>>> for idx, m in enumerate(net.named_modules()):... print(idx, '->', m)0 -> ('', Sequential((0): Linear(in_features=2, out_features=2, bias=True)(1): Linear(in_features=2, out_features=2, bias=True)))1 -> ('0', Linear(in_features=2, out_features=2, bias=True))"""if memo is None:memo = set()if self not in memo:if remove_duplicate:memo.add(self)yield prefix, selffor name, module in self._modules.items():if module is None:continuesubmodule_prefix = prefix + ('.' if prefix else '') + namefor m in module.named_modules(memo, submodule_prefix, remove_duplicate):yield mdef train(self: T, mode: bool = True) -> T:r"""Sets the module in training mode.This has any effect only on certain modules. See documentations ofparticular modules for details of their behaviors in training/evaluationmode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,etc.Args:mode (bool): whether to set training mode (``True``) or evaluationmode (``False``). Default: ``True``.Returns:Module: self"""if not isinstance(mode, bool):raise ValueError("training mode is expected to be boolean")self.training = modefor module in self.children():module.train(mode)return selfdef eval(self: T) -> T:r"""Sets the module in evaluation mode.This has any effect only on certain modules. See documentations ofparticular modules for details of their behaviors in training/evaluationmode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,etc.This is equivalent with :meth:`self.train(False) <torch.nn.Module.train>`.See :ref:`locally-disable-grad-doc` for a comparison between`.eval()` and several similar mechanisms that may be confused with it.Returns:Module: self"""return self.train(False)def requires_grad_(self: T, requires_grad: bool = True) -> T:r"""Change if autograd should record operations on parameters in thismodule.This method sets the parameters' :attr:`requires_grad` attributesin-place.This method is helpful for freezing part of the module for finetuningor training parts of a model individually (e.g., GAN training).See :ref:`locally-disable-grad-doc` for a comparison between`.requires_grad_()` and several similar mechanisms that may be confused with it.Args:requires_grad (bool): whether autograd should record operations onparameters in this module. Default: ``True``.Returns:Module: self"""for p in self.parameters():p.requires_grad_(requires_grad)return selfdef zero_grad(self, set_to_none: bool = True) -> None:r"""Sets gradients of all model parameters to zero. See similar functionunder :class:`torch.optim.Optimizer` for more context.Args:set_to_none (bool): instead of setting to zero, set the grads to None.See :meth:`torch.optim.Optimizer.zero_grad` for details."""if getattr(self, '_is_replica', False):warnings.warn("Calling .zero_grad() from a module created with nn.DataParallel() has no effect. ""The parameters are copied (in a differentiable manner) from the original module. ""This means they are not leaf nodes in autograd and so don't accumulate gradients. ""If you need gradients in your forward method, consider using autograd.grad instead.")for p in self.parameters():if p.grad is not None:if set_to_none:p.grad = Noneelse:if p.grad.grad_fn is not None:p.grad.detach_()else:p.grad.requires_grad_(False)p.grad.zero_()def share_memory(self: T) -> T:r"""See :meth:`torch.Tensor.share_memory_`"""return self._apply(lambda t: t.share_memory_())def _get_name(self):return self.__class__.__name__def extra_repr(self) -> str:r"""Set the extra representation of the moduleTo print customized extra information, you should re-implementthis method in your own modules. Both single-line and multi-linestrings are acceptable."""return ''def __repr__(self):# We treat the extra repr like the sub-module, one item per lineextra_lines = []extra_repr = self.extra_repr()# empty string will be split into list ['']if extra_repr:extra_lines = extra_repr.split('\n')child_lines = []for key, module in self._modules.items():mod_str = repr(module)mod_str = _addindent(mod_str, 2)child_lines.append('(' + key + '): ' + mod_str)lines = extra_lines + child_linesmain_str = self._get_name() + '('if lines:# simple one-liner info, which most builtin Modules will useif len(extra_lines) == 1 and not child_lines:main_str += extra_lines[0]else:main_str += '\n ' + '\n '.join(lines) + '\n'main_str += ')'return main_strdef __dir__(self):module_attrs = dir(self.__class__)attrs = list(self.__dict__.keys())parameters = list(self._parameters.keys())modules = list(self._modules.keys())buffers = list(self._buffers.keys())keys = module_attrs + attrs + parameters + modules + buffers# Eliminate attrs that are not legal Python variable nameskeys = [key for key in keys if not key[0].isdigit()]return sorted(keys)def _replicate_for_data_parallel(self):replica = self.__new__(type(self))replica.__dict__ = self.__dict__.copy()# replicas do not have parameters themselves, the replicas reference the original# module.replica._parameters = OrderedDict()replica._buffers = replica._buffers.copy()replica._modules = replica._modules.copy()replica._is_replica = True # type: ignore[assignment]return replica
相关文章:

深入浅出Pytorch函数——torch.nn.Module
分类目录:《深入浅出Pytorch函数》总目录 Pytorch中所有网络的基类,我们的模型也应该继承这个类。Modules也可以包含其它Modules,允许使用树结构嵌入他们,我们还可以将子模块赋值给模型属性。 语法 torch.nn.Module(*args, **kwargs)方法 …...
【100天精通python】Day38:GUI界面编程_PyQt 从入门到实战(中)_数据库操作与多线程编程
目录 专栏导读 4 数据库操作 4.1 连接数据库 4.2 执行 SQL 查询和更新: 4.3 使用模型和视图显示数据 5 多线程编程 5.1 多线程编程的概念和优势 5.2 在 PyQt 中使用多线程 5.3 处理多线程间的同步和通信问题 5.3.1 信号槽机制 5.3.2 线程安全的数据访问 Q…...
STM32--TIM定时器(3)
文章目录 输入捕获简介频率测量输入捕获通道输入捕获基本结构PWMI的基本结构输入捕获模式测量PWM频率和占空比代码 编码器接口正交编码器工作模式接口基本结构TIM编码接口器测速代码: 输入捕获简介 输入捕获IC(Input Capture),是处理器捕获外部输入信号…...
爬虫框架- feapder + 爬虫管理系统 - feaplat 的学习简记
文章目录 feapder 的使用feaplat 爬虫管理系统部署 feapder 的使用 feapder是一款上手简单,功能强大的Python爬虫框架 feapder 官方文档 文档写的很详细,可以直接上手。 基本命令: 创建爬虫项目 feapder create -p first-project创建爬虫 …...

设计模式详解-享元模式
类型:结构型模式 实现原理:尝试重用现有的同类对象,如果未找到匹配的对象,则创建新对象 目的:减少创建对象的数量以减少内存占用和提高性能。 解决的问题:大量的对象可能造成的内存溢出问题 解决方法&a…...

BDA初级分析——用SQL筛选数据
一、用SQL对数据分组 GROUP BY Group by,按...分组 作用:根据给定字段进行字段的分组,通常和聚合函数配合使用,实现分组的分析 写法:select ...from ...group by 字段名 (也可以是多个字段) GROUP BY的逻辑 SELECT gender,COUNT(user_id) …...
(成功踩坑)electron-builder打包过程中报错
目录 注意:文中的解决方法2,一定全部看完,再进行操作,有坑 背景 报错1: 报错2: 1.原因:网络连接失败 2.解决方法1: 3.解决方法2: 3.1查看缺少什么资源文件 3.2去淘…...
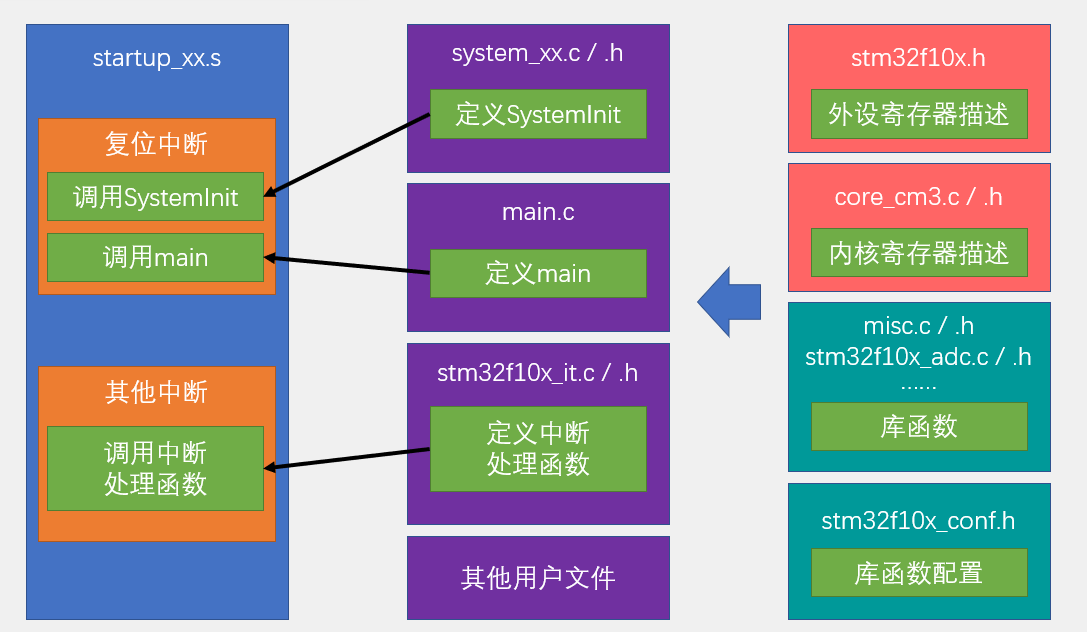
【STM32】 工程
🚩 WRITE IN FRONT 🚩 🔎 介绍:"謓泽"正在路上朝着"攻城狮"方向"前进四" 🔎🏅 荣誉:2021|2022年度博客之星物联网与嵌入式开发TOP5|TOP4、2021|2022博客之星TO…...
Git概述
目录 一、什么是Git 二、什么是版本控制系统 三、Git和SVN对比 SVN集中式 SVN优缺点 Git分布式 Git优缺点 四、Git工作流程 四个工作区域 工作流程 五、Git下载与安装 一、什么是Git 很多人都知道,林纳斯托瓦兹在1991年创建了开源的Linux,从…...
ubuntu 编译安装nginx及安装nginx_upstream_check_module模块
如果有帮助到你,麻烦点个赞呗~ 一、下载安装包 # 下载nginx_upstream_check_module模块 wget https://codeload.github.com/yaoweibin/nginx_upstream_check_module/zip/master# 解压 unzip master# 下载nginx 1.21.6 wget https://github.com/nginx/…...
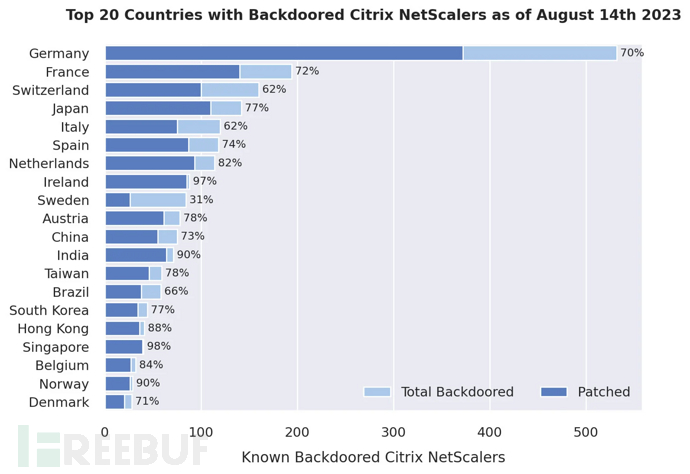
近 2000 台 Citrix NetScaler 服务器遭到破坏
Bleeping Computer 网站披露在某次大规模网络攻击活动中,一名攻击者利用被追踪为 CVE-2023-3519 的高危远程代码执行漏洞,入侵了近 2000 台 Citrix NetScaler 服务器。 研究人员表示在管理员安装漏洞补丁之前已经有 1200 多台服务器被设置了后门&#x…...
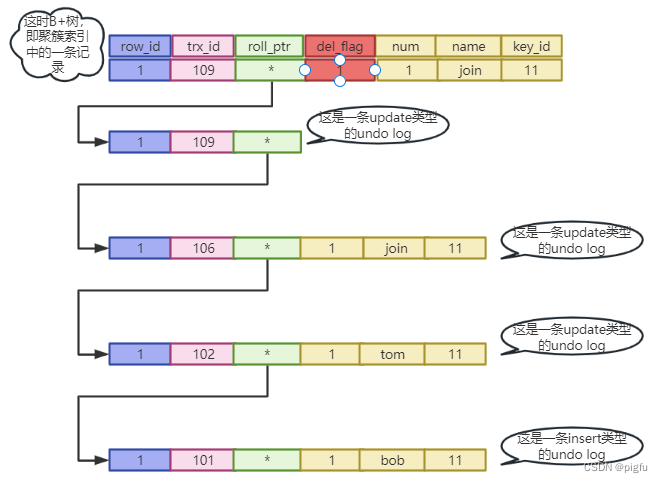
MySQL MVCC的详解之Read View
文章目录 概要一、基于UNDO LOG的版本链1.1、行记录结构1.2、了解UNDO LOG1.3、版本链 二、Read View2.1、判定机制 三、参考 概要 在上文中,我们提到了MVCC(Multi-Version Concurrency Control)多版本并发控制,是通过undo log来实现的。那具…...
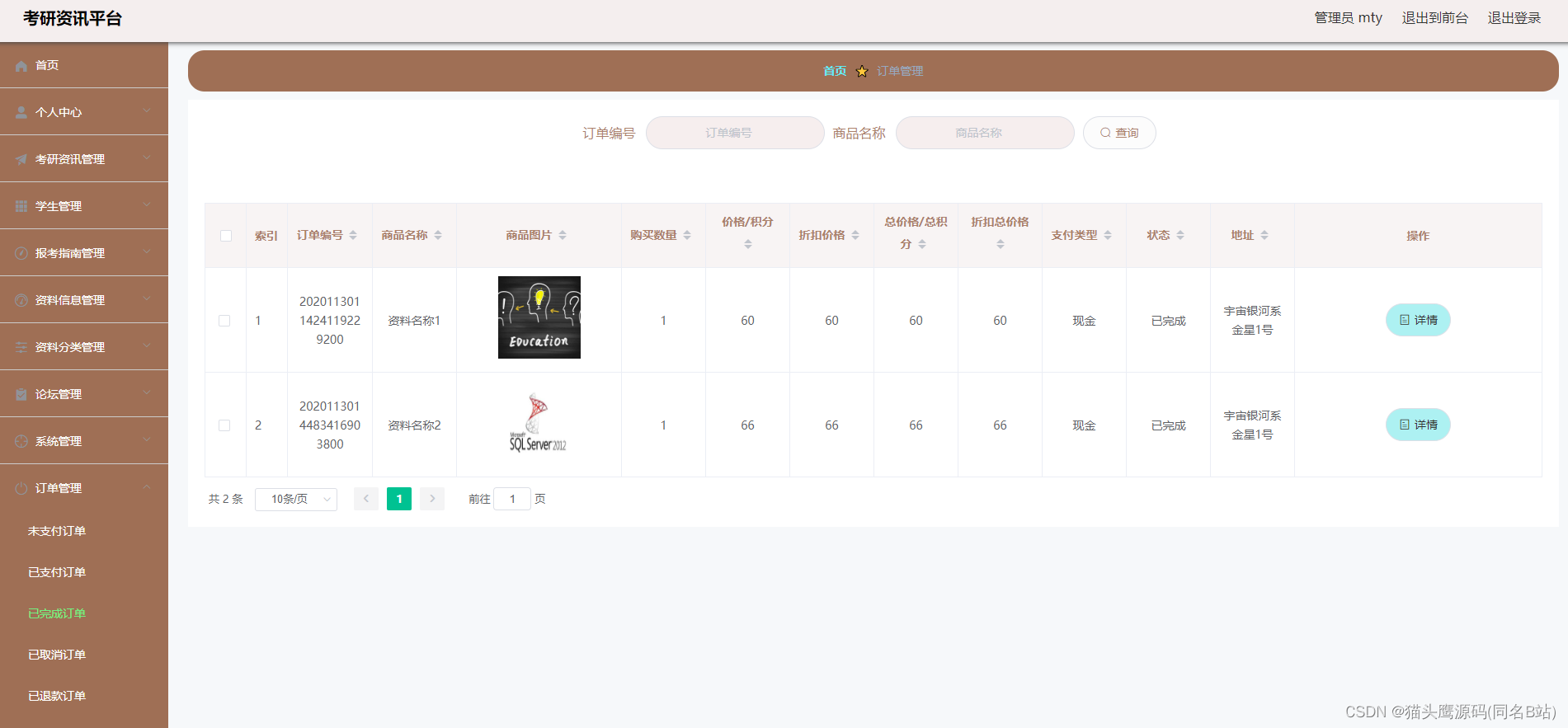
基于springboot+vue的考研资讯平台(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
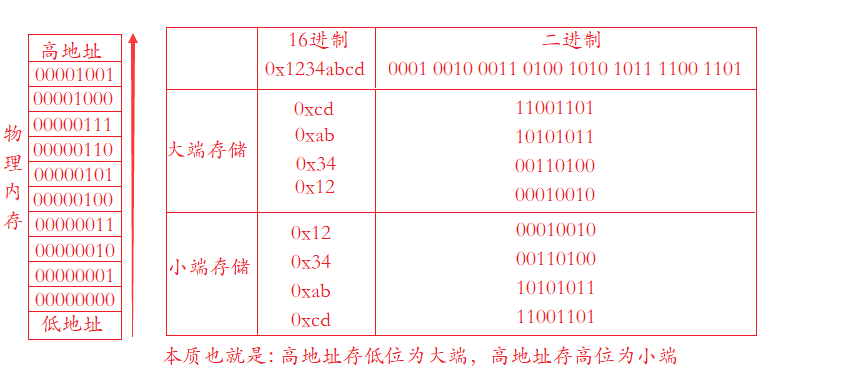
学习网络编程No.3【socket理论实战】
引言: 北京时间:2023/8/12/15:32,自前天晚上更新完文章,看了一下鹅厂新出的《扫毒3》摆烂至现在,不知道是长大了,还是近年港片就那样,给我的感觉不是很好,也可能是国内市场对港片不…...
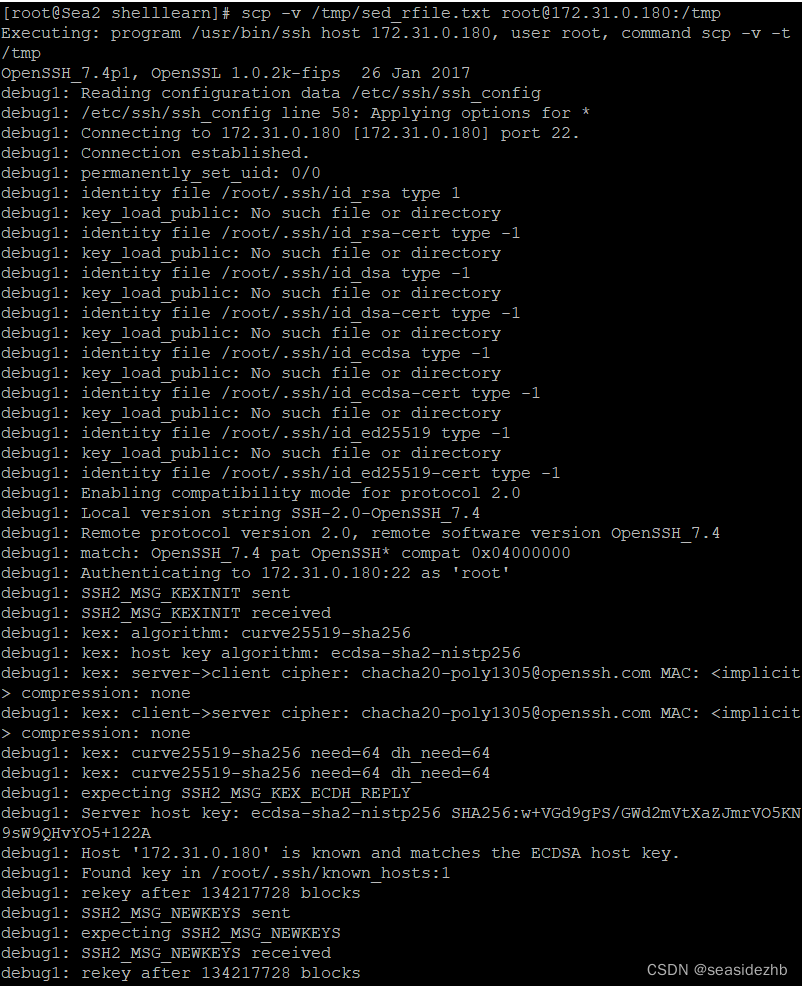
Linux学习之ssh和scp
ls /etc/ssh可以看到这个目录下有一些文件,而/etc/ssh/ssh_config是客户端配置文件,/etc/ssh/sshd_config是服务端配置文件。 cat -n /etc/ssh/sshd_config | grep "Port "可以看一下sshd监听端口的配置信息,发现这个配置端口是22…...
录制游戏视频的软件有哪些?分享3款软件!
“有录制游戏视频的软件推荐吗?最近迷上了网游,想录制点自己高端操作的游戏画面,但是不知道用什么软件录屏比较好,就想问问大家,有没有好用的录制游戏视频软件。” 在游戏领域,玩家们喜欢通过录制游戏视频…...

每日一题——螺旋矩阵
题目 给定一个m x n大小的矩阵(m行,n列),按螺旋的顺序返回矩阵中的所有元素。 数据范围:0≤n,m≤10,矩阵中任意元素都满足 ∣val∣≤100 要求:空间复杂度 O(nm) ,时间复杂度 O(nm)…...
每天10个小知识点)
前端面试的性能优化部分(12)每天10个小知识点
目录 系列文章目录前端面试的性能优化部分(1)每天10个小知识点前端面试的性能优化部分(2)每天10个小知识点前端面试的性能优化部分(3)每天10个小知识点前端面试的性能优化部分(4)每天…...
SAP BTEs 业务交易事件/增强(Business Transaction Event)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、BTEs是什么? 二、使用步骤 1.查找BTE event 2.处理FM 总结 前言 SAP BTEs是一种新型的增强方式,可以通过事务代码FIFB打开&#…...

leetcode做题笔记90. 子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。 思路一:回溯 int comp(const void* a, cons…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...