YOLOX算法调试记录
YOLOX是在YOLOv3基础上改进而来,具有与YOLOv5相媲美的性能,其模型结构如下:
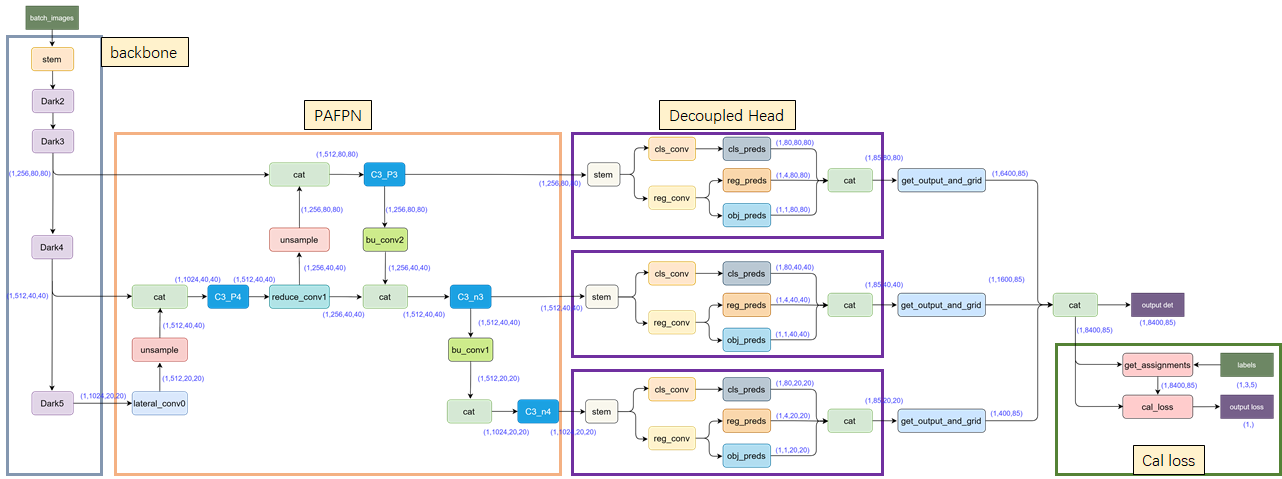
由于博主只是要用YOLOX做对比试验,因此并不需要对模型的结构太过了解。
先前博主调试过YOLOv5,YOLOv7,YOLOv8,相比而言,YOLOX的环境配置是类似的,但其参数设置太过分散,改动比较麻烦,就比如epoch这些参数竟然要放到yolox_base.py文件中去继承,而不是直接在train.py中指定。话不多说,我们开始调试过程。
环境配置
YOLOX的调试过程基本与YOLOv5类似,不同之处在于需要进行一个安装过程。
即执行:
python setup.py develop
否则在运行是会提示找不到yolox文件

运行成功后结果如下,值得注意的是,博主在本地很难成功,但在服务器上却很容易。
随后便是conda环境配置过程,基本与YOLOv5一致,可以直接使用命令配置:
conda create -n yolox python=3.8
source activate yolox
pip install -r requirements.txt
数据集配置
YOLOX使用的数据集是COCO,但不同在于其训练与测试中没有给出参数进行指定,而是直接写在了数据集读取文件中,我们只需要按照其要求修改目录即可,将数据集放到datasets/COCO文件夹下即可,当然也可以像博主这样创建软连接:
ln -s /data/datasets/coco/ /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/
但这种方法却一直报错:
File "/home/ubuntu/outputs/yolox/YOLOX-main/yolox/data/datasets/datasets_wrapper.py", line 177, in __del__
if self.cache and self.cache_type == "ram":
AttributeError: 'COCODataset' object has no attribute 'cache'
没办法,只能把数据集复制一份到这个目录了。
随后运行报错:
assert img is not None, f"file named {img_file} not found"
AssertionError: file named /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/val2017/000000567197.jpg not found
仔细一看原来是目录结构出了问题,没有images这级目录,去掉该目录即可。最终的目录结构为:

训练模型
<class 'torch.autograd.variable.Variable'>
RuntimeError: FIND was unable to find an engine to execute this computation
这是因为博主安装环境时默认安装torch为2.0,导致出错。换个torch版本即可:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.6 -c pytorch -c conda-forge
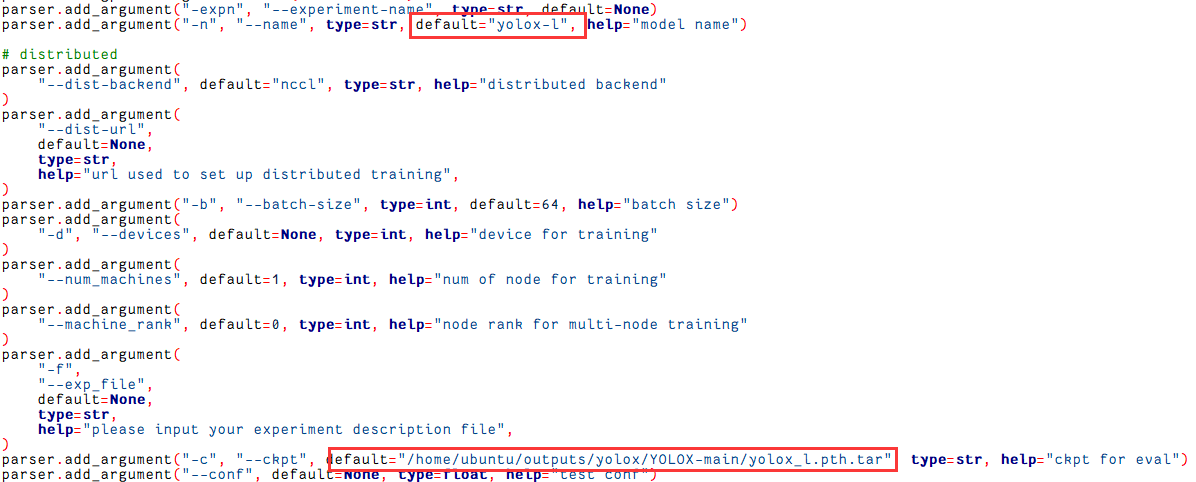
随后需要修改几个参数,首先是指定模型名称,博主使用的是yolox-l
parser.add_argument("-n", "--name", type=str, default="yolox-l", help="model name")
随后设置yolox-l的配置文件,–f代表从该文件读取,然后修改对应文件中的参数:
parser.add_argument("-f","--exp_file",default="/home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py",type=str,help="plz input your experiment description file",)
修改/home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py,num_class设置错了,博主习惯了DETR类模型,加上了背景类,实际上应该只有3类。
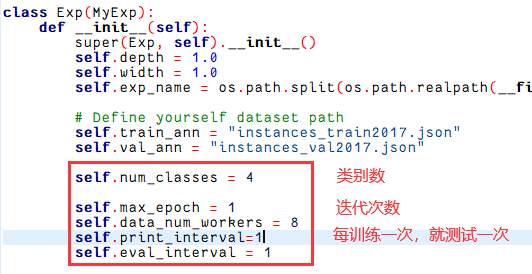
class Exp(MyExp):def __init__(self):super(Exp, self).__init__()self.depth = 1.0self.width = 1.0self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]# Define yourself dataset pathself.train_ann = "instances_train2017.json"self.val_ann = "instances_val2017.json"self.num_classes = 4self.max_epoch = 1self.data_num_workers = 8self.print_interval=1self.eval_interval = 1
随后便是batch-szie参数了,YOLOX所占用显存还是比较大的,batch-size设置为6。
训练时间还是蛮快的,1个epoch大概45分钟左右。训练1个epoch的结果,由于没有使用预训练模型,值很低。还有一个问题,便是num_class设置错了,博主习惯了DETR类模型,加上了背景类,实际上应该只有3类。
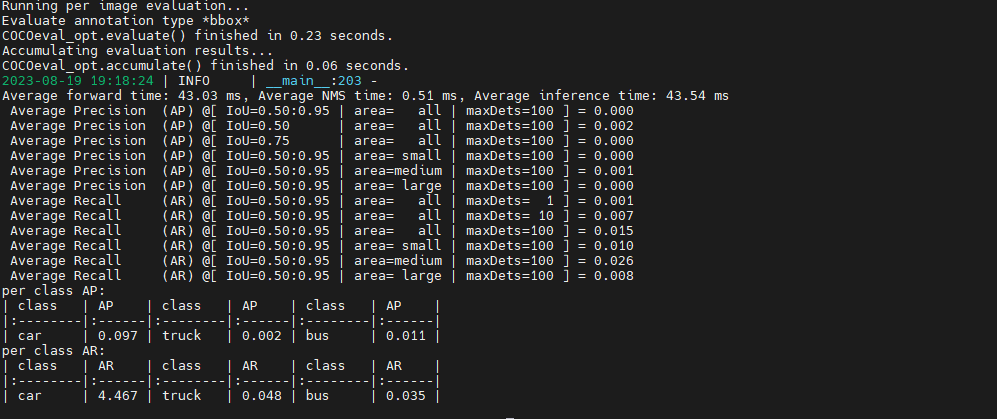
预训练模型微调
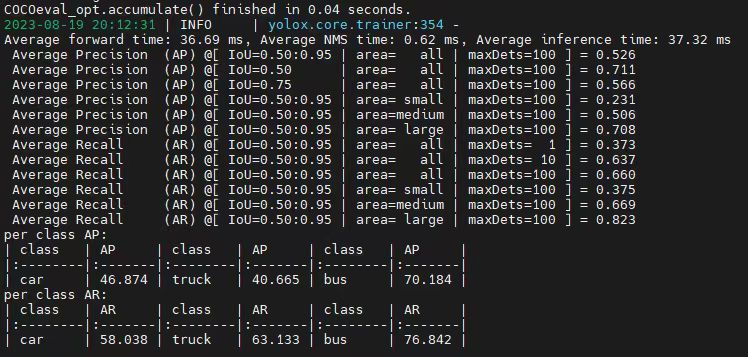
我们可以使用YOLOX-L训练好的模型当作预训练模型,在该模型上面进行微调,从而能够快速收敛,训练好的num_class=80,我们保持原样即可,即num_class=3,模型会自动处理类别不一致的问题。使用预训练模型后,迭代速度明显加快,并且精度也迅速提升。
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="checkpoint file")
使用预训练模型做微调后训练一个epoch的结果。
评估模型
完成eval.py的参数配置:
python -m yolox.tools.eval -n yolox-s -c yolox_s.pth -b 64 -d 8 --conf 0.001 [--fp16] [--fuse]
当然也可以使用参数,主要修改这两个参数即可
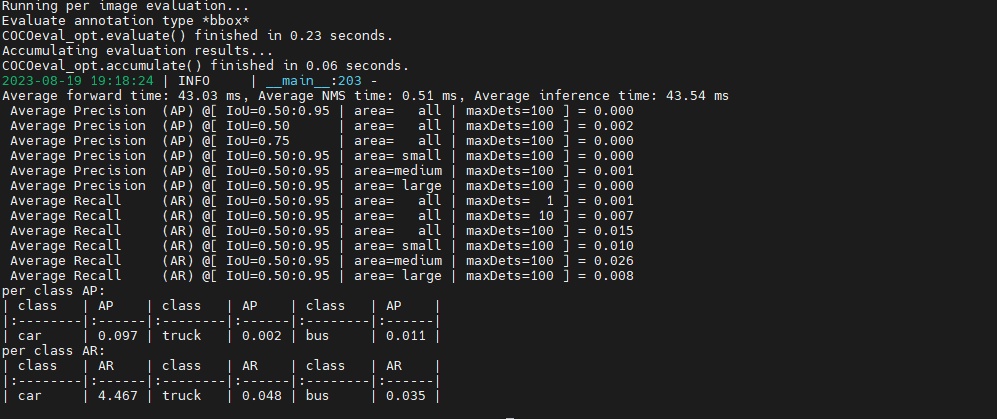
随后运行python eval.py命令即可,这里发现使用下载的权重文件会报错,于是博主自己训练了1个epoch并保存权重结果,使用这个则是没有问题的,文件保存在YOLOX_outputs中。但似乎发现了一个问题,那就是值好低呀。
模型推理
首先我们下载已经训练完成的模型,博主这里选择的是YOLOX-L,值得注意的是,下载这个文件需要翻墙。下载的权重文件为tar文件,因此需要解压:
tar -xvf yolox_l.pth.tar
但没想到却报错了:
tar: This does not look like a tar archive
tar: Skipping to next header
tar: Exiting with failure status due to previous errors
这是个BUG
解决办法:
gzip -d xxxx.tar.gz (对于.tar.gz文件的处理方式)
tar -xf xxxx.tar (对于.tar文件处理方式)
依旧不行,没办法,博主只能把其后缀名改为zip,然后使用unzip的方式解压该文件。但解压后却是一个文件夹,这与博主先前所见到的pth文件不同,果然在运行时报错:
super().init(open(name, mode)) IsADirectoryError: [Errno 21] Is a
directory: ‘/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth’
原来YOLOX的权重文件是不需要解压的,直接用即可,即在指定文件时为:
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="ckpt for eval")
,指定size=224,Demo.py中给出了其参数量与计算量,

推理结果如下:
相关文章:
YOLOX算法调试记录
YOLOX是在YOLOv3基础上改进而来,具有与YOLOv5相媲美的性能,其模型结构如下: 由于博主只是要用YOLOX做对比试验,因此并不需要对模型的结构太过了解。 先前博主调试过YOLOv5,YOLOv7,YOLOv8,相比而言,YOLOX的环…...
基于小程序的汽车俱乐部系统的设计与实现(论文+源码)_kaic
目录 前 言 1 系统概述 1.1 系统主要功能 1.2 开发及运行环境 2 系统分析和总体设计 2.1 需求分析 2.2 可行性分析 2.3 设计目标 2.4 项目规划 2.5 系统开发语言简介 2.6 系统功能模块图 3 系统数据库设计 3.1 数据库开发工具简介 3.2 数据库需求分析 3.3 数据库…...

ProgrammingArduino物联网
programming_arduino_ed2 IO 延时闪灯 void setup() {pinMode(13, OUTPUT); }void loop() {digitalWrite(13, HIGH);delay(500);digitalWrite(13, LOW);delay(500); }// sketch 03-02 加入变量 int ledPin 13; int delayPeriod 500;void setup() {pinMode(ledPin, OUTPUT)…...

SSM框架的学习与应用(Spring + Spring MVC + MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习
SSM框架的学习与应用(Spring Spring MVC MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习 一、当前的主流框架介绍(这就是后期我会发出来的框架学习) Spring框架 Spring是一个开源框架,是为了解决企业应用程序开发复杂…...

Programming abstractions in C阅读笔记: p118-p122
《Programming Abstractions In C》学习第49天,p118-p122,总结如下: 一、技术总结 1.随机数 (1)seed p119,“The initial value–the value that is used to get the entire process start–is call a seed for the random ge…...

2023国赛数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...
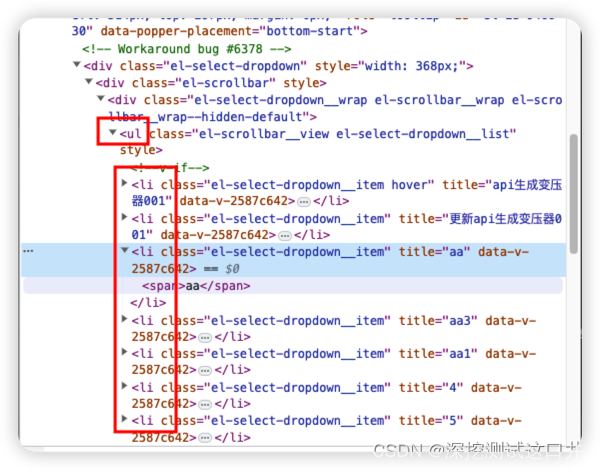
selenium 选定ul-li下拉选项中某个指定选项
场景:selenium的下拉选项是ul-li模式,选定某个指定的选项。 from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 显示等待def select_li(self, text, *ul_locator):"…...

回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍…...
使用pytorch 的Transformer进行中英文翻译训练
下面是一个使用torch.nn.Transformer进行序列到序列(Sequence-to-Sequence)的机器翻译任务的示例代码,包括数据加载、模型搭建和训练过程。 import torch import torch.nn as nn from torch.nn import Transformer from torch.utils.data im…...

解决element的select组件创建新的选项可多选且opitions数据源中有数据的情况下,回车不能自动选中创建的问题
前言 最近开发项目使用element-plus库内的select组件,其中有提供一个创建新的选项的用法,但是发现一些小问题,在此记录 版本 “element-plus”: “^2.3.9”, “vue”: “^3.3.4”, 问题 1、在options数据源中无数据的时候,在输入框…...
人工智能大模型加速数据库存储模型发展 行列混合存储下的破局
数据存储模型 专栏内容: postgresql内核源码分析手写数据库toadb并发编程toadb开源库 个人主页:我的主页 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 概述 在数据库的发展过程中,关…...
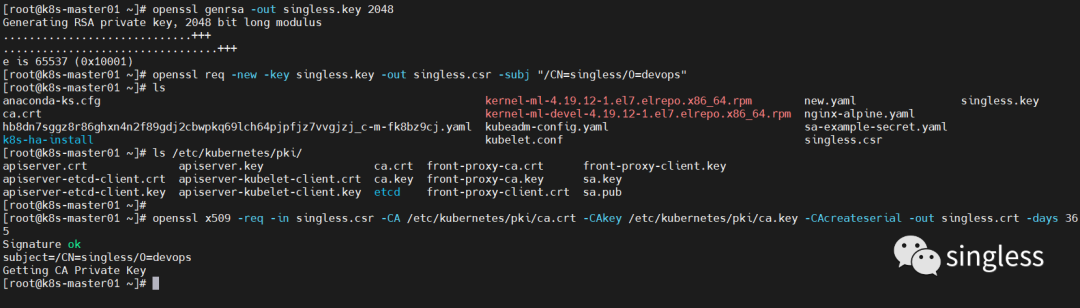
K8S用户管理体系介绍
1 K8S账户体系介绍 在k8s中,有两类用户,service account和user,我们可以通过创建role或clusterrole,再将账户和role或clusterrole进行绑定来给账号赋予权限,实现权限控制,两类账户的作用如下。 server acc…...
实现chatGPT 聊天样式
效果图 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Chat Example</title&g…...

day9 STM32 I2C总线通信
I2C总线简介 I2C总线介绍 I2C(Inter-Integrated Circuit)总线(也称IIC或I2C)是由PHILIPS公司开发的两线式串行总线,用于连接微控制器及其外围设备,是微电子通信控制领域广泛采用的一种总线标准。 它是同步通…...

终极Shell:Zsh(CentOS7 安装 zsh 及 配置 Oh my zsh)
CentOS7 安装 zsh 及 配置 Oh my zsh 我们在通过Shell操作linux终端时,配置、颜色区分、命令提示大都达不到我们预期的效果或者操作较为繁琐。 今天就来介绍一款终极一个及其好用的类Linux系统中的终端软件,江湖称之为马车中的跑车,跑车中的飞行车,史称『终极 Shell…...

Redis的数据持久化
前言 本文主要介绍Redis的三种持久化方式、AOF持久化策略等 什么是持久化 持久化是指将数据在内存中的状态保存到非易失性介质(如硬盘、固态硬盘等)上的过程。在计算机中,内存中的数据属于易失性数据,一旦断电或重启系统&#…...

CSS 选择器
前言 基础选择器 以下是几种常见的基础选择器。 标签选择器:通过HTML标签名称选择元素。 例如: p {color: red; } 上述样式规则将选择所有<p>标签 ,并将其文字颜色设置为红色。 类选择器:通过类名选择元素。使用类选择…...
)
上位机工作总结(2023.03-2023.08)
1.工作总结 不知不觉,已经从C#转为Qt开发快半年了。这半年内,也是学习了很多C相关的开发技能,同时自己的技术栈也是进一步丰富,以后跑路就更容易啦,哈哈!自己之前就有Winform和一些简单的Qt项目实践&#…...
APSIM模型参数优化 批量模拟丨气象数据准备、物候发育和光合生产、物质分配与产量模拟、土壤水分平衡算法、土壤碳氮平衡模块、农田管理模块等
随着数字农业和智慧农业的发展,基于过程的农业生产系统模型在模拟作物对气候变化的响应与适应、农田管理优化、作物品种和株型筛选、农田固碳和温室气体排放等领域扮演着越来越重要的作用。APSIM (Agricultural Production Systems sIMulator)模型是世界知名的作物生…...
Azure防火墙
文章目录 什么是Azure防火墙如何部署和配置创建虚拟网络创建虚拟机创建防火墙创建路由表,关联子网、路由配置防火墙策略配置应用程序规则配置网络规则配置 DNAT 规则 更改 Srv-Work 网络接口的主要和辅助 DNS 地址测试防火墙 什么是Azure防火墙 Azure防火墙是一种用…...

解锁 C 语言 “积木术”:大一函数总结
大一 C 语言函数核心总结 本文围绕 C 语言函数从基础认知到实战运用、从核心语法到避坑技巧展开,兼顾基础考点与编程思想,内容可直接用于复习和实操参考,每个核心模块仅保留 2 个典型示例,多余拓展示例文末有补充。 一、函数的基…...

Ubuntu 22.04 LTS 服务器 SSH 密钥配置与自动化部署实践
1. 从零开始:为什么SSH密钥是服务器管理的基石 如果你刚接触服务器运维,或者还在用密码登录你的Ubuntu 22.04服务器,那今天这篇分享可能会彻底改变你的工作流。我管理过上百台服务器,从早期的密码登录到后来的密钥认证,…...

无人机高空工程车辆识别 高清工程车辆识别 高清车辆识别 高清铲车压路机识别 无人机矿场行人识别 深度学习yolo第10558期
工程车辆识别计算机视觉数据集数据集概览 本数据集基于高空视角遥感影像构建,聚焦工程场景目标识别,为目标检测模型提供标准化标注样本,支撑工地监测与工程管理场景应用。项目内容类别数量4类类别名称汽车、人员、工程车1、工程车2图像数量50…...

MedGemma-X开箱即用体验:预装环境,零配置快速体验智能诊断
MedGemma-X开箱即用体验:预装环境,零配置快速体验智能诊断 1. 为什么选择MedGemma-X进行智能影像诊断 在医疗影像诊断领域,传统CAD系统往往存在两个痛点:一是只能提供简单的二分类结果(阳性/阴性)&#x…...

StructBERT语义匹配工具实测:本地运行+GPU加速,中文复述识别效果惊艳
StructBERT语义匹配工具实测:本地运行GPU加速,中文复述识别效果惊艳 你有没有遇到过这样的场景?需要判断两段中文文字是不是在说同一件事,或者想在海量文本里找出那些意思相近但表述不同的句子?比如,审核用…...

NOKOV度量动捕软件进阶指南:刚体与Markerset的实战配置技巧
1. 刚体与Markerset的核心概念解析 刚接触动作捕捉的朋友可能会被"刚体"和"Markerset"这两个专业术语搞得一头雾水。简单来说,刚体就像我们小时候玩的木头人玩具 - 无论你怎么移动它,它的形状都不会改变。在NOKOV动捕系统中…...

为什么NTT负包裹卷积比普通卷积更适合密码学?深入解析其数学本质与应用优势
为什么NTT负包裹卷积比普通卷积更适合密码学?深入解析其数学本质与应用优势 在密码学领域,多项式环上的快速乘法运算是构建高效加密方案的核心技术。传统卷积运算虽然直观,但在处理环Z[x]/(xⁿ1)上的乘法时,会面临系数膨胀和计算效…...

Phi-3-vision-128k-instruct惊艳案例:化学分子结构图→IUPAC命名→反应活性位点预测
Phi-3-vision-128k-instruct惊艳案例:化学分子结构图→IUPAC命名→反应活性位点预测 1. 模型能力概览 Phi-3-Vision-128K-Instruct是当前最先进的轻量级开放多模态模型,专为处理密集推理任务而设计。这个模型最令人印象深刻的特点是其128K的超长上下文…...

终极指南:如何将Nebullvm与Hadoop、Spark大数据平台无缝集成
终极指南:如何将Nebullvm与Hadoop、Spark大数据平台无缝集成 【免费下载链接】nebuly The user analytics platform for LLMs 项目地址: https://gitcode.com/gh_mirrors/ne/nebuly Nebullvm作为一款强大的LLM优化工具,能够显著提升AI模型在大数据…...

计算机毕业设计springboot中药材仓储管理系统的分析与实现 基于SpringBoot框架的中药饮片智能库存与质量追溯平台 中医药材冷链物流与数字化仓储运营管理系统
计算机毕业设计springboot中药材仓储管理系统的分析与实现0j9h07d8(配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着中医药的全球化推广和国内市场需求的增长,中药…...