分布式 - 消息队列Kafka:Kafka 消费者消费位移的提交方式
文章目录
- 1. 自动提交消费位移
- 2. 自动提交消费位移存在的问题?
- 3. 手动提交消费位移
- 1. 同步提交消费位移
- 2. 异步提交消费位移
- 3. 同步和异步组合提交消费位移
- 4. 提交特定的消费位移
- 5. 按分区提交消费位移
- 4. 消费者查找不到消费位移时怎么办?
- 5. 如何从特定分区位移处读取消息?
- 6. 如何优雅地退出轮询循环消费?
1. 自动提交消费位移
最简单的提交方式是让消费者自动提交偏移量,自动提交 offset 的相关参数:
- enable.auto.commit:是否开启自动提交 offset 功能,默认为 true;
- auto.commit.interval.ms:自动提交 offset 的时间间隔,默认为5秒;
如果 enable.auto.commit 被设置为true,那么每过5秒,消费者就会自动提交 poll() 返回的最大偏移量,即将拉取到的每个分区中最大的消息位移进行提交。提交时间间隔通过 auto.commit.interval.ms 来设定,默认是5秒。与消费者中的其他处理过程一样,自动提交也是在轮询循环中进行的。消费者会在每次轮询时检查是否该提交偏移量了,如果是,就会提交最后一次轮询返回的偏移量。
① 启动消费者消费程序,并设置为自动提交消费者位移的方式:
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-ni");// 显式配置消费者自动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);// 显式配置消费者自动提交位移的事件间隔properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,4);// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList("ni"));// 消费数据while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.printf("主题 = %s, 分区 = %d, 位移 = %d, " + "消息键 = %s, 消息值 = %s\n",record.topic(), record.partition(), record.offset(), record.key(), record.value());}}}
}
② 启动生产者程序发送3条消息,消息的内容都为 hello,kafka
③ 查看消费者消费的消息记录:
主题 = ni, 分区 = 0, 位移 = 0, 消息键 = null, 消息值 = hello,kafka
主题 = ni, 分区 = 0, 位移 = 1, 消息键 = null, 消息值 = hello,kafka
主题 = ni, 分区 = 0, 位移 = 2, 消息键 = null, 消息值 = hello,kafka
可以看到,消费者消费分区的最新消息的位移为 offset= 2,即消费者的消息位移为 offset =2;
④ 查看消费者提交的位移:
[root@master01 kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 10.65.132.2:9093 --topic __consumer_offsets --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning[group-ni,ni,0]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[0], metadata=, commitTimestamp=1692168114999, expireTimestamp=None)
可以看到,消费者的消息位移为 offset =2,但是消费者的提交位移为 offset =3;
2. 自动提交消费位移存在的问题?
假设刚刚提交完一次消费位移,然后拉取一批消息进行消费,在下一次自动提交消费位移之前,消费者崩溃了,那么又得从上一次位移提交的地方重新开始消费,这样便发生了重复消费的现象(对于再均衡的情况同样适用,再均衡完成之后,接管分区的消费者将从最后一次提交的偏移量的位置开始读取消息)。可以通过修改提交时间间隔来更频繁地提交偏移量,缩小可能导致重复消息的时间窗口,但无法完全避免。
在使用自动提交时,到了该提交偏移量的时候,轮询方法将提交上一次轮询返回的偏移量,但它并不知道具体哪些消息已经被处理过了。所以,在再次调用poll()之前,要确保上一次poll()返回的所有消息都已经处理完毕(调用close()方法也会自动提交偏移量)。通常情况下这不会有什么问题,但在处理异常或提前退出轮询循环时需要特别小心。
虽然自动提交很方便,但是没有为避免开发者重复处理消息留有余地。
3. 手动提交消费位移
在Kafka中还提供了手动位移提交的方式,这样可以使得开发人员对消费位移的管理控制更加灵活。很多时候并不是说拉取到消息就算消费完成,而是需要将消息写入数据库、写入本地缓存,或者是更加复杂的业务处理。在这些场景下,所有的业务处理完成才能认为消息被成功消费,手动的提交方式可以让开发人员根据程序的逻辑在合适的地方进行位移提交。
开启手动提交功能的前提是消费者客户端参数 enable.auto.commit 配置为 false,让应用程序自己决定何时提交偏移量。手动提交可以细分为同步提交和异步提交,对应于 KafkaConsumer 中的 commitSync() 和 commitAsync() 两种类型的方法。
① 同步提交位移是指消费者在提交位移时会阻塞,直到提交完成并收到确认。它会提交 poll() 返回的最新偏移量,提交成功后马上返回,如果由于某些原因提交失败就抛出异常。 commitAsync() 方法有四个不同的重载方法,具体定义如下:
public void commitSync()
public void commitSync(Duration timeout)
public void commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
public void commitSync(Map<TopicPartition, OffsetAndMetadata> offsets, Duration timeout)
② 异步提交位移在执行的时候消费者线程不会被阻塞,可能在提交消费位移的结果还未返回之前就开始了新一次的拉取操作。异步提交可以使消费者的性能得到一定的增强。commitAsync方法有三个不同的重载方法,具体定义如下:
public void commitAsync()
public void commitAsync(OffsetCommitCallback callback)
public void commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback)
1. 同步提交消费位移
在消费消息的循环中,处理完当前批次的消息后,在轮询更多的消息之前,调用 commitSync() 方法提交当前批次最新的偏移量,这会阻塞当前线程,直到位移提交完成并收到确认。 只要没有发生不可恢复的错误,commitSync() 方法就会一直尝试直至提交成功。如果提交失败,就把异常记录到错误日志里。
public void commitSync()
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList("topic-01"));// 消费数据while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {// 业务处理拉取的消息}try{// 消费者手动提交消费位移:同步提交方式consumer.commitSync();}catch (CommitFailedException exception){log.error("commit failed....");}}}
}
还可以将消费者程序修改为批量处理+批量提交的方式:
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList("topic-01"));// 消费数据while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));int minSize = 200;List<ConsumerRecord<String, String>> buffer = new ArrayList<>();for (ConsumerRecord<String, String> record : consumerRecords) {buffer.add(record);}try{// 消费者手动提交消费位移:同步提交方式if(buffer.size()>minSize){// 批量处理消息// ...}// 手动提交位移:同步方式consumer.commitSync();}catch (CommitFailedException exception){log.error("commit failed....");}}}
}
上面的示例中将拉取到的消息存入缓存 buffer,等到积累到足够多的时候,也就是大于等于200个的时候,再做相应的批量处理,之后再做批量提交。
commitSync() 方法会根据 poll() 方法拉取的最新位移来进行提交,只要没有发生不可恢复的错误,它就会阻塞消费者线程直至位移提交完成。对于不可恢复的错误,比如 CommitFailedException、WakeupException、InterruptException、AuthenticationException、AuthorizationException 等,我们可以将其捕获并做针对性的处理。
需要注意的是,同步提交位移时需要确保在处理完消息后再进行提交,因为 commitSync() 将会提交 poll() 返回的最新偏移量,如果你在处理完所有记录之前就调用了 commitSync(),那么一旦应用程序发生崩溃,就会有丢失消息的风险(消息已被提交但未被处理)。如果应用程序在处理记录时发生崩溃,但 commitSync() 还没有被调用,那么从最近批次的开始位置到发生再均衡时的所有消息都将被再次处理——这或许比丢失消息更好,或许更坏。
2. 异步提交消费位移
同步提交有一个缺点,在broker对请求做出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。可以通过降低提交频率来提升吞吐量,但如果发生了再均衡,则会增加潜在的消息重复。这个时候可以使用异步提交API。只管发送请求,无须等待broker做出响应。
public void commitAsync()
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList("topic-01"));// 消费数据while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {// 业务逻辑处理}// 异步提交消费位移consumer.commitAsync();}}
}
在提交成功或碰到无法恢复的错误之前,commitSync() 会一直重试,但commitAsync()不会,这是commitAsync() 的一个缺点。之所以不进行重试,是因为 commitAsync() 在收到服务器端的响应时,可能已经有一个更大的位移提交成功。假设我们发出一个提交位移2000的请求,这个时候出现了短暂的通信问题,服务器收不到请求,自然也不会做出响应。与此同时,我们处理了另外一批消息,并成功提交了位移3000。如果此时 commitAsync() 重新尝试提交位移2000,则有可能在位移3000之后提交成功。这个时候如果发生再均衡,就会导致消息重复。
之所以提到这个问题并强调提交顺序的重要性,是因为 commitAsync() 也支持回调,回调会在broker返回响应时执行。回调经常被用于记录位移提交错误或生成指标,如果要用它来重试提交位移,那么一定要注意提交顺序。
public void commitAsync(OffsetCommitCallback callback)
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList("topic-01"));// 消费数据while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {// 业务逻辑处理}// 异步提交消费位移consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsetAndMetadataMap, Exception exception) {if(exception!=null){log.info("fail to commit offsets:{}",offsetAndMetadataMap,exception);}}});}}
}
异步提交中如何实现重试:我们可以设置一个递增的序号来维护异步提交的顺序,每次位移提交之后就增加序号相对应的值。在遇到位移提交失败需要重试的时候,可以检查所提交的位移和序号的值的大小,如果前者小于后者,则说明有更大的位移已经提交了,不需要再进行本次重试;如果两者相同,则说明可以进行重试提交。
3. 同步和异步组合提交消费位移
一般情况下,偶尔提交失败但不进行重试不会有太大问题,因为如果提交失败是由于临时问题导致的,后续的提交总会成功。如果消费者异常退出,那么这个重复消费的问题就很难避免,因为这种情况下无法及时提交消费位移;但如果这是发生在消费者被关闭或再均衡前的最后一次提交,则要确保提交是成功的,可以在退出或再均衡执行之前使用同步提交的方式做最后的把关。
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll( Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 业务逻辑处理}// 异步提交位移consumer.commitAsync();}} catch (Exception e) {log.error("Unexpected error", e);} finally {try {// 同步提交位移consumer.commitSync();}finally{consumer.close();}}}
}
4. 提交特定的消费位移
对于采用 commitSync() 的无参方法而言,它提交消费位移的频率和拉取批次消息、处理批次消息的频率是一样的。但如果想要更频繁地提交位移该怎么办?如果 poll() 返回了一大批数据,那么为了避免可能因再均衡引起的消息重复,想要在批次处理过程中提交位移该怎么办?这个时候不能只是调用 commitSync() 或commitAsync(),因为它们只会提交消息批次里的最后一个位移。
幸运的是,消费者API允许在调用 commitSync() 和 commitAsync() 时传给它们想要提交的分区和位移:
public void commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
public void commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback)

如图:消费者的提交位移=当前一次poll拉取的分区消息的最大位移offset + 1,这个提交位移就是下次
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));ConcurrentHashMap<TopicPartition,OffsetAndMetadata> offsets = new ConcurrentHashMap<>();int count = 0;while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 消息所属的主题和分区TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());// 消费者提交的消费位移=当前消费消息的位移+1OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1);offsets.put(topicPartition, offsetAndMetadata);if(count % 1000 == 0){consumer.commitAsync(offsets,null);}count++;}}}
}
5. 按分区提交消费位移
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));while (true){ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 获取拉取的消息包含的所有分区列表Set<TopicPartition> partitions = consumerRecords.partitions();for (TopicPartition partition : partitions) {// 获取当前分区要消费的消息List<ConsumerRecord<String, String>> partitionRecords = consumerRecords.records(partition);// 获取当前分区消息的最大位移long lastConsumerOffset = partitionRecords.get(partitionRecords.size() - 1).offset();// 当前分区的消费位移提交 = 当前分区消息的最大位移 + 1Map<TopicPartition, OffsetAndMetadata> topicPartitionOffsetAndMetadataMap = Collections.singletonMap(partition, new OffsetAndMetadata(lastConsumerOffset + 1));consumer.commitSync(topicPartitionOffsetAndMetadataMap);}}}
}
4. 消费者查找不到消费位移时怎么办?
当一个新的消费组建立的时候,它根本没有可以查找的消费位移。或者消费组内的一个新消费者订阅了一个新的主题,它也没有可以查找的消费位移。当__consumer_offsets 主题中有关这个消费组的位移信息过期而被删除后,它也没有可以查找的消费位移。当 Kafka 中没有初始位移或服务器上不再存在当前位移时,该怎么办?
此时会根据消费者客户端参数 auto.offset.reset 的配置来决定从何处开始进行消费,auto.offset.reset 参数的取值如下:
- latest(默认值):表示从分区末尾开始消费消息。
- earliest: 表示消费者会从起始处,也就是0开始消费。
- none:查到不到消费位移的时候,既不从最新的消息位置处开始消费,也不从最早的消息位置处开始消费,此时会报出NoOffsetForPartitionException异常。如果能够找到消费位移,那么配置为“none”不会出现任何异常。
如果配置的不是“latest”、“earliest”和“none”,则会报出ConfigException异常。
auto.offset.reset 参数用于指定消费者在启动时,如果找不到消费位移应该从哪里开始消费消息。 如果能够找到消费位移,那么消费者会从该位移处开始消费消息,那么 auto.offset.reset 参数并不会奏效,只有在找不到消费位移时才会生效。如果发生位移越界,即消费位移超出了消息队列中消息的数量或位置范围,那么 auto.offset.reset 参数也会生效。
5. 如何从特定分区位移处读取消息?
如果消费者能够找到消费位移,使用 poll() 可以从各个分区的最新位移处读取消息, 而且提供的 auto.offset.reset 参数也可以在找不到消费位移或位移越界的情况下粗粒度地从开头或末尾开始消费。但是有些时候,我们需要一种更细粒度的掌控,可以让我们从特定的位移处开始拉取消息,而 KafkaConsumer 中的 seek() 方法正好提供了这个功能,让我们得以追前消费或回溯消费。
public void seek(TopicPartition partition, long offset)
public void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata)
① seek() 方法中的参数 partition 表示分区,而 offset 参数用来指定从分区的哪个位置开始消费。seek() 方法只能重置消费者分配到的分区的消费位置,而分区的分配是在 poll() 方法的调用过程中实现的。也就是说,在执行 seek() 方法之前需要先执行一次poll()方法,等到分配到分区之后才可以重置消费位置:
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));// 执行一次poll() 方法完成分区分配的逻辑// ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));Set<TopicPartition> topicPartitions = consumer.assignment();for (TopicPartition topicPartition : topicPartitions) {consumer.seek(topicPartition,10);}while (true) {ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(1000));// ...}}
}
② 如果 poll() 方法中的参数为0,此方法立刻返回,那么 poll() 方法内部进行分区分配的逻辑就会来不及实施,也就是说,消费者此时并未分配到任何分区,那么 topicPartitions 便是一个空列表。那么这里的 timeout 参数设置为多少合适呢?太短会使分配分区的动作失败,太长又有可能造成一些不必要的等待。我们可以通过 KafkaConsumer的 assignment()方法来判定是否分配到了相应的分区:
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));Set<TopicPartition> topicPartitions = consumer.assignment();// 此时说明还未完成分区分配while (topicPartitions.size()==0){consumer.poll(Duration.ofMillis(100));topicPartitions = consumer.assignment();}for (TopicPartition topicPartition : topicPartitions) {// 重置每个分区的消费位置为10consumer.seek(topicPartition,10);}while (true) {ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(1000));// 消费消息}}
}
③ 如果对未分配到的分区执行seek() 方法,那么会报出 IllegalStateException 的异常。类似在调用subscribe() 方法之后直接调用seek() 方法:
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));// 未完成分区分配,直接调用seek方法,重置分区1的消费位置为10consumer.seek(new TopicPartition("topic-01",1),10);while (true) {ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(1000));// 消费消息}}
}
报错:
Exception in thread "main" java.lang.IllegalStateException: No current assignment for partition topic-01-1
④ 如果消费组内的消费者在启动的时候能够找到消费位移,那么消费者就会从该位移处开始消费消息。除非发生位移越界,即消费位移超出了消息队列中消息的数量或位置范围,否则 auto.offset.reset 参数并不会奏效,此时如果想指定从开头或末尾开始消费,就需要seek() 方法的帮助了,指定从分区末尾开始消费:
endOffsets() 方法用来获取指定分区的末尾的消息位置, endOffsets 的具体方法定义如下:
public Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions)
public Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions, Duration timeout)
其中 partitions 参数表示分区集合,而 timeout 参数用来设置等待获取的超时时间。如果没有指定 timeout 参数的值,那么 endOffsets() 方法的等待时间由客户端参数 request.timeout.ms 来设置,默认值为 30000。与 endOffsets 对应的是 beginningOffset() 方法,一个分区的起始位置起初是0,但并不代表每时每刻都为0,因为日志清理的动作会清理旧的数据,所以分区的起始位置会自然而然地增加,beginningOffsets() 方法的具体定义如下:
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions)
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions, Duration timeout)
beginningOffsets() 方法中的参数内容和含义都与 endOffsets() 方法中的一样,配合这两个方法我们就可以从分区的开头或末尾开始消费。其实KafkaConsumer中直接提供了seekToBeginning() 方法和seekToEnd() 方法来实现这两个功能,这两个方法的具体定义如下:
public void seekToBeginning(Collection<TopicPartition> partitions)
public void seekToEnd(Collection<TopicPartition> partitions)
⑤ 有时候我们并不知道特定的消费位置,却知道一个相关的时间点,比如我们想要消费昨天8点之后的消息,这个需求更符合正常的思维逻辑。此时我们无法直接使用seek() 方法来追溯到相应的位置。KafkaConsumer同样考虑到了这种情况,它提供了一个offsetsForTimes() 方法,通过timestamp来查询与此对应的分区位置:
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch, Duration timeout)
offsetsForTimes() 方法的参数 timestampsToSearch 是一个Map类型,key为待查询的分区,而 value 为待查询的时间戳,该方法会返回时间戳大于等于待查询时间的第一条消息对应的位置和时间戳,对应于 OffsetAndTimestamp 中的 offset 和 timestamp字段。下面的示例演示了 offsetsForTimes() 和 seek() 之间的使用方法,首先通过 offsetsForTimes() 方法获取一天之前的消息位置,然后使用 seek() 方法追溯到相应位置开始消费:
@Slf4j
public class CustomConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"10.65.132.2:9093");properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group-topic-01");// 显式配置消费者手动提交位移properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList("topic-01"));Map<TopicPartition,Long> timestampToSearch = new HashMap<>();Set<TopicPartition> topicPartitionSet = consumer.assignment();// 查询的分区以及查询的时间戳for (TopicPartition topicPartition : topicPartitionSet) {timestampToSearch.put(topicPartition,System.currentTimeMillis()-1*24*3600*1000);}// 获取时间戳大于等于待查询时间的第一条消息对应的位置和时间戳Map<TopicPartition, OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = consumer.offsetsForTimes(timestampToSearch);for (TopicPartition topicPartition : topicPartitionSet) {OffsetAndTimestamp offsetAndTimestamp = topicPartitionOffsetAndTimestampMap.get(topicPartition);// seek 方法重置消费的位移if(offsetAndTimestamp != null){consumer.seek(topicPartition,offsetAndTimestamp.offset());}}}
}
⑥ 位移越界也会触发 auto.offset.reset 参数的执行,位移越界是指知道消费位置却无法在实际的分区中查找到,比如原本拉取位置为101(fetch offset 101),但已经越界了(out of range),所以此时会根据 auto.offset.reset 参数的默认值来将拉取位置重置(resetting offset)为100,我们也能知道此时分区中最大的消息 offset 为99。
6. 如何优雅地退出轮询循环消费?
如何优雅地退出轮询循环,如果你确定马上要关闭消费者(即使消费者还在等待一个poll()返回),那么可以在另一个线程中调用consumer.wakeup()。如果轮询循环运行在主线程中,那么可以在ShutdownHook里调用这个方法。需要注意的是,consumer.wakeup() 是消费者唯一一个可以在其他线程中安全调用的方法。调用 consumer.wakeup() 会导致poll()抛出WakeupException,如果调用 consumer.wakeup() 时线程没有在轮询,那么异常将在下一次调用 poll() 时抛出。不一定要处理WakeupException,但在退出线程之前必须调用consumer.close() 。消费者在被关闭时会提交还没有提交的偏移量,并向消费者协调器发送消息,告知自己正在离开群组。协调器会立即触发再均衡,被关闭的消费者所拥有的分区将被重新分配给群组里其他的消费者,不需要等待会话超时。
相关文章:
分布式 - 消息队列Kafka:Kafka 消费者消费位移的提交方式
文章目录 1. 自动提交消费位移2. 自动提交消费位移存在的问题?3. 手动提交消费位移1. 同步提交消费位移2. 异步提交消费位移3. 同步和异步组合提交消费位移4. 提交特定的消费位移5. 按分区提交消费位移 4. 消费者查找不到消费位移时怎么办?5. 如何从特定…...
如何利用 ChatGPT 进行自动数据清理和预处理
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景 ChatGPT 已经成为一把可用于多种应用的瑞士军刀,并且有大量的空间将 ChatGPT 集成到数据科学工作流程中。 如果您曾经在真实数据集上训练过机器学习模型,您就会知道数据清理和预…...
PHP“牵手”淘宝商品评论数据采集方法,淘宝API接口申请指南
淘宝天猫商品评论数据接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用…...

你更喜欢哪一个:VueJS 还是 ReactJS?
观点列表: 1、如果你想在 HTML 中使用 JS,请使用 Vue; 如果你想在 JS 中使用 HTML,请使用 React。 当然,如果您希望在 JS 中使用 HTML,请将 Vue 与 JSX 结合使用。 2、Svelte:我喜欢它&#…...
PyTorch学习笔记(十六)——利用GPU训练
一、方式一 网络模型、损失函数、数据(包括输入、标注) 找到以上三种变量,调用它们的.cuda(),再返回即可 if torch.cuda.is_available():mynn mynn.cuda() if torch.cuda.is_available():loss_function loss_function.cuda(…...
【实战】十一、看板页面及任务组页面开发(三) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(二十五)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

金额千位符自定义指令
自定义指令文件 moneyFormat.js /*** v-money 金额千分位转换*/export default {inserted: inputFormatter({// 格式化函数formatter(num, util) {if(num null || num || num undefined || typeof(num) undefined){return }if(util 万元 || util 万){return formatMone…...

请不要用 JSON 作为配置文件,使用JSON做配置文件的缺点
我最近关注到有的项目使用JSON作为配置文件。我觉得这不是个好主意。 这不是JSON的设计目的,因此也不是它擅长的。JSON旨在成为一种“轻量级数据交换格式”,并声称它“易于人类读写”和“易于机器解析和生成”。 作为一种数据交换格式,JSON是…...
Hadabot:从网络浏览器操作 ROS2 远程控制器
一、说明 Hadabot Hadabot是一个学习ROS2和机器人技术的机器人套件。使用 Hadabot,您将能够以最小的挫败感和恐吓来构建和编程物理 ROS2 机器人。Hadabot套件目前正在开发中。它将仅针对ROS2功能,并强调基于Web的用户界面。 随着开发的进展&a…...

Kotlin 协程
Kotlin 协程(Coroutines)是一种轻量级的并发编程解决方案,旨在简化异步操作和多线程编程。它提供了一种顺序和非阻塞的方式来处理并发任务,使得代码可以更加简洁和易于理解。Kotlin 协程通过提供一套高级 API,使并发代…...
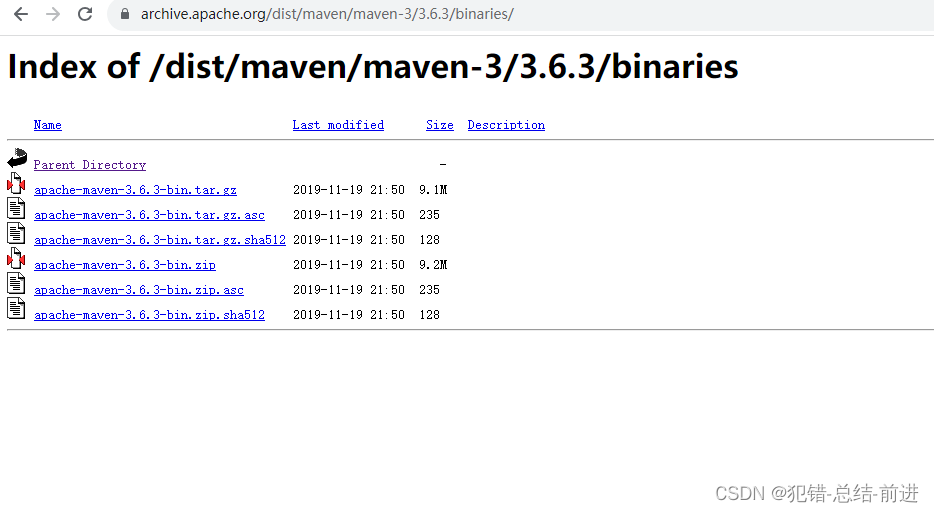
maven 从官网下载指定版本
1. 进入官网下载页面 Maven – Download Apache Maven 点击下图所示链接 2. 进入文件页,选择需要的版本 3. 选binaries 4. 选文件,下载即可...

数据结构---串(赋值,求子串,比较,定位)
目录 一.初始化 顺序表中串的存储 串的链式存储 二.赋值操作:将str赋值给S 链式表 顺序表 三.复制操作:将chars复制到str中 链式表 顺序表 四.判空操作 链式表 顺序表 五.清空操作 六.串联结 链式表 顺序表 七.求子串 链式表 顺序表…...
WPF CommunityToolkit.Mvvm
文章目录 前言ToolkitNuget安装简单使用SetProperty,通知更新RealyCommandCanExecute 新功能,代码生成器ObservablePropertyNotifyCanExecuteChangedForRelayCommand其他功能对应关系 NotifyPropertyChangedFor 前言 CommunityToolkit.Mvvm(…...

Vue开发中如何解决国际化语言切换问题
Vue开发中如何解决国际化语言切换问题 引言: 在如今的全球化时代,应用程序的国际化变得越来越重要。为了让不同地区的用户能够更好地使用应用程序,我们需要对内容进行本地化,以适应不同语言和文化环境。对于使用Vue进行开发的应用…...
基于springboot+vue的流动人口登记系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Stable Diffusion的使用以及各种资源
Stable Diffsuion资源目录 SD简述sd安装模型下载关键词,描述语句插件管理controlNet自己训练模型 SD简述 Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如…...

Redis 分布式锁的实现方式
一般来说,在对数据进行“加锁”时,程序首先需要通过获取(acquire)锁来得到对数据排他性访问的能力,然后才能对数据执行一系列操作,最后还要将锁释放(release)给其他程序。 对于能够…...

VMware上搭建的虚拟机突然本地无法连接服务器
长时间没有使用VMware 虚拟机了,今天突然登录上去,启动虚拟服务器后发现本地等不了了, 经过排查发现是开启了:VirtualBox Host-Only Network 关闭之后就本机就可以直连服务器了...

JDBC回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 JDBC回顾 前言一、JDBC1.JDBC是什么?2.如何使用?(1)注册驱动(2)获取连接(3)操作…...

mq 消息队列 mqtt emqx ActiveMQ RabbitMQ RocketMQ
省流: 十几年前,淘宝的notify,借鉴ActiveMQ。京东的ActiveMQ集群几百台,后面改成JMQ。 Linkedin的kafka,因为是scala,国内很多人不熟。淘宝的人把kafka用java写了一遍,取名metaq,后…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...