Prisma.js:JavaScript中的基于代码的ORM
Prisma是一种流行的用于服务器端JavaScript和TypeScript的数据映射层(ORM)。它的核心目的是简化和自动化数据在存储和应用程序代码之间的传输方式。Prisma支持各种数据存储,并为数据持久化提供了一个强大而灵活的抽象层。通过这个基于代码的导览,你可以对Prisma及其核心功能有一个初步了解。
JavaScript的ORM层
对象关系映射(ORM)最早由Java中的Hibernate框架引入。对象关系映射的最初目标是解决Java类和关系型数据库表之间的所谓阻抗不匹配问题。从这个想法发展出了更广泛的雄心勃勃的概念,即为应用程序提供一个通用的持久化层。Prisma是Java ORM层的现代JavaScript演进。Prisma支持多种SQL数据库,并扩展到包括NoSQL数据存储MongoDB。无论数据存储类型如何,总体目标仍然是为应用程序提供一个标准化的处理数据持久化的框架。
领域模型
我们将使用一个简单的领域模型来查看数据模型中的几种关系:多对一、一对多和多对多。(我们将跳过一对一,因为它与多对一非常相似。) Prisma使用一个模型定义(模式)作为应用程序和数据存储之间的枢纽。在构建应用程序时,我们可以采用一种方法,即从这个定义开始构建代码。Prisma会自动将模式应用到数据存储中。 Prisma模型定义格式并不难理解,你可以使用一个图形工具PrismaBuilder来创建一个。我们的模型将支持一个协作式的创意开发应用程序,所以我们将有User(用户)、Idea(创意)和Tag(标签)模型。一个User可以拥有多个Idea(一对多关系),而一个Idea只能有一个Owner(多对一关系)。User和Tag之间形成了多对多关系。列表1显示了模型定义。
列表1. Prisma中的模型定义
datasource db {provider = "sqlite"url = "file:./dev.db"
}
generator client {provider = "prisma-client-js"
}
model User {id Int @id @default(autoincrement())name Stringemail String @uniqueideas Idea[]
}
model Idea {id Int @id @default(autoincrement())name Stringdescription Stringowner User @relation(fields: [ownerId], references: [id])ownerId Inttags Tag[]
}
model Tag {id Int @id @default(autoincrement())name String @uniqueideas Idea[]
}
列表1包括一个数据源定义(一个简单的SQLite数据库,Prisma用于开发目的)和一个客户端定义,其中“generator client”设置为“prisma-client-js”。后者意味着Prisma将生成一个JavaScript客户端,应用程序可以使用该客户端与模型定义创建的映射进行交互。至于模型定义,注意每个模型都有一个id字段,并且我们使用Prisma的注解来获得自动递增的整数ID.id@default(autoincrement()) 为了在User和Idea之间创建关系,我们使用数组括号引用了Idea类型这表示:给我一个Idea的集合,属于该User。在关系的另一侧,你使用单个Idea来表示:owner User @relation(fields: [ownerId], references: [id])。User拥有一个owner字段,它引用了User的id字段。除了关系和主键ID字段之外,字段定义都很简单;例如,name是一个字符串字段,content是一个字符串字段,等等。
创造项目
我们将使用一个简单的项目来使用Prisma的功能。第一步是创建一个新的Node.js项目并添加依赖项。然后,我们可以添加列表1中的定义,并使用它来处理数据持久化,使用Prisma内置的SQLite数据库。为了启动我们的应用程序,我们将创建一个新的目录,初始化一个npm项目,并安装依赖项,如列表2所示。
列表2:创建应用程序
mkdir iw-prisma
cd iw-prisma
npm init -y
npm install express @prisma/client body-parser
mkdir prisma
touch prisma/schema.prisma
现在,在项目根目录下创建一个名为prisma的文件夹,并在其中创建一个名为schema.prisma的文件。将列表1中的模型定义复制到schema.prisma文件中。接下来,告诉Prisma使用模型定义来准备SQLite数据库的架构,如列表3所示。
列表3:设置数据库
npx prisma migrate dev --name init
npx prisma migrate deploy
列表3中的命令告诉Prisma要对数据库进行“迁移”,这意味着将Prisma定义中的模式更改应用到数据库本身。--preview-feature标志告诉Prisma使用开发配置文件,而--name标志为更改指定一个任意的名称。--apply标志告诉Prisma应用这些更改。
使用数据
现在,让我们在Express.js中创建一个RESTful端点来允许创建用户。可以在列表4中看到我们服务器的代码,它将放在server.js文件中。列表4是原始的Express代码,但是由于Prisma的存在,我们可以以最小的努力对数据库进行大量的操作。
列表4:展现代码
const express = require('express');
const bodyParser = require('body-parser');
const { PrismaClient } = require('@prisma/client');
const prisma = new PrismaClient();
const app = express();
app.use(bodyParser.json());
const port = 3000;
app.listen(port, () => {console.log(`Server is listening on port ${port}`);
});
// Fetch all users
app.get('/users', async (req, res) => {const users = await prisma.user.findMany();res.json(users);
});
// Create a new user
app.post('/users', async (req, res) => {const { name, email } = req.body;const newUser = await prisma.user.create({ data: { name, email } });res.status(201).json(newUser);
});
目前,我们只有两个端点,一个用于获取所有用户的列表,一个用于添加用户。你可以看到我们如何使用Prisma客户端来处理这些用例,分别调用prisma.user.findMany()和prisma.user.create()。prisma.user.findMany()方法没有任何参数,将返回数据库中的所有行。prisma.user.create()方法接受一个包含新行值的data字段的对象(在这种情况下,是name和email字段,记住Prisma会自动为我们创建一个唯一的ID)。现在,我们可以使用以下命令运行服务器:.node server.js
使用CURL进行测试
使用CURL命令来测试我们的端点,如列表5所示。
列表5:使用CURL尝试端点
$ curl http://localhost:3000/users
[]
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"George Harrison","email":"george.harrison@example.com"}' http://localhost:3000/users
{"id":2,"name":"John Doe","email":"john.doe@example.com"}{"id":3,"name":"John Lennon","email":"john.lennon@example.com"}{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}
$ curl http://localhost:3000/users
[{"id":2,"name":"John Doe","email":"john.doe@example.com"},{"id":3,"name":"John Lennon","email":"john.lennon@example.com"},{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}]
列表5展示了我们获取所有用户并找到一个空集合,然后添加用户,最后获取填充的集合。接下来,让我们添加一个端点,让我们能够创建想法并将其与用户关联起来,如列表6所示。
列表6:用户想法的POST端点
app.post('/users/:userId/ideas', async (req, res) => {const { userId } = req.params;const { name, description } = req.body;
try {const user = await prisma.user.findUnique({ where: { id: parseInt(userId) } });
if (!user) {return res.status(404).json({ error: 'User not found' });}
const idea = await prisma.idea.create({data: {name,description,owner: { connect: { id: user.id } },},});
res.json(idea);} catch (error) {console.error('Error adding idea:', error);res.status(500).json({ error: 'An error occurred while adding the idea' });}
});
app.get('/userideas/:id', async (req, res) => {const { id } = req.params;const user = await prisma.user.findUnique({where: { id: parseInt(id) },include: {ideas: true,},});if (!user) {return res.status(404).json({ message: 'User not found' });}res.json(user);
});
在列表6中,我们有两个端点。第一个端点允许使用POST请求在/users/:userId/ideas路径下添加一个想法。首先,它需要通过ID来获取用户,使用prisma.user.findUnique()方法。这个方法用于根据传入的条件在数据库中查找单个实体。在我们的例子中,我们想要获取具有请求中的ID的用户,所以我们使用:{ where: { id: parseInt(userId) } }。一旦我们获取到用户,我们使用prisma.idea.create()来创建一个新的想法。这个方法的使用方式与创建用户时类似,但是现在我们有了一个关联字段。Prisma允许我们使用owner: { connect: { id: user.id } }来创建新的想法与用户之间的关联。第二个端点是一个GET请求,在/users/ideas/:id路径下。这个端点的目的是根据用户ID返回包括他们的想法在内的用户信息。这里使用了prisma.user.findUnique()方法的include选项来告诉Prisma包括关联的想法。如果没有这个选项,想法将不会被包括在返回结果中,因为Prisma默认使用延迟加载的策略来获取关联数据。为了测试这些新的端点,我们可以使用列表7中显示的CURL命令。
列表7:用于测试端点的CURL
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"New Idea", "description":"Idea description"}' http://localhost:3000/users/3/ideas
$ curl http://localhost:3000/userideas/3
{"id":3,"name":"John Lennon","email":"john.lennon@example.com","ideas":[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},{"id":2,"name":"New Idea","description":"Idea description","ownerId":3}]}
我们能够添加想法并恢复带有想法的用户。
多对多关系与标签
现在让我们添加处理多对多关系中标签的端点。在列表8中,我们处理标签的创建并将其与想法关联起来。
列表8:添加和显示标签
// create a tag
app.post('/tags', async (req, res) => {const { name } = req.body;
try {const tag = await prisma.tag.create({data: {name,},});
res.json(tag);} catch (error) {console.error('Error adding tag:', error);res.status(500).json({ error: 'An error occurred while adding the tag' });}
});
// Associate a tag with an idea
app.post('/ideas/:ideaId/tags/:tagId', async (req, res) => {const { ideaId, tagId } = req.params;
try {const idea = await prisma.idea.findUnique({ where: { id: parseInt(ideaId) } });
if (!idea) {return res.status(404).json({ error: 'Idea not found' });}
const tag = await prisma.tag.findUnique({ where: { id: parseInt(tagId) } });
if (!tag) {return res.status(404).json({ error: 'Tag not found' });}
const updatedIdea = await prisma.idea.update({where: { id: parseInt(ideaId) },data: {tags: {connect: { id: tag.id },},},});
res.json(updatedIdea);} catch (error) {console.error('Error associating tag with idea:', error);res.status(500).json({ error: 'An error occurred while associating the tag with the idea' });}
});
我们已经添加了两个端点。第一个端点用于添加标签,在之前的示例中已经熟悉了。在列表8中,我们还添加了一个将想法与标签关联起来的端点。为了关联一个想法和一个标签,我们利用了模型定义中的多对多映射关系。我们通过ID获取想法和标签,并使用connect字段将它们设置在彼此之间。现在,想法的标签集合中包含了标签的ID,反之亦然。多对多关联允许最多两个一对多关系,每个实体指向另一个实体。在数据存储中,这需要创建一个“查找表”(或交叉引用表),但是Prisma会为我们处理这个过程。我们只需要与实体本身进行交互。我们多对多功能的最后一步是允许通过标签查找想法,并通过想法查找标签。你可以在列表9中看到模型的这一部分。(为了简洁起见,我删除了一些错误处理。)
列表9:通过想法找到标签,通过标签找到想法
// Display ideas with a given tag
app.get('/ideas/tag/:tagId', async (req, res) => {const { tagId } = req.params;
try {const tag = await prisma.tag.findUnique({where: {id: parseInt(tagId)}});
const ideas = await prisma.idea.findMany({where: {tags: {some: {id: tag.id}}}});
res.json(ideas);} catch (error) {console.error('Error retrieving ideas with tag:', error);res.status(500).json({error: 'An error occurred while retrieving the ideas with the tag'});}
});
// tags on an idea:
app.get('/ideatags/:ideaId', async (req, res) => {const { ideaId } = req.params;try {const idea = await prisma.idea.findUnique({where: {id: parseInt(ideaId)}});
const tags = await prisma.tag.findMany({where: {ideas: {some: {id: idea.id}}}});
res.json(tags);} catch (error) {console.error('Error retrieving tags for idea:', error);res.status(500).json({error: 'An error occurred while retrieving the tags for the idea'});}
});
在这里,我们有两个端点:一个用于查找给定标签ID的标签,另一个用于查找给定想法ID的标签。它们的工作方式与在一对多关系中非常相似,Prisma会处理查找表的关联。例如,在查找想法上的标签时,我们使用findMany方法,并使用条件来查找具有相关ID的想法,如列表10所示。
列表10:测试标签概念的多对多关系
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"Funny Stuff"}' http://localhost:3000/tags
$ curl -X POST http://localhost:3000/ideas/1/tags/2
{"idea":{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},"tag":{"id":2,"name":"Funny Stuff"}}
$ curl localhost:3000/ideas/tag/2
[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3}]
$ curl localhost:3000/ideatags/1
[{"id":1,"name":"New Tag"},{"id":2,"name":"Funny Stuff"}]
结论
虽然我们在这里介绍了一些CRUD和关系基础知识,但Prisma还具有更多的功能。它提供了级联操作,如级联删除;提供了获取策略,可以对从数据库返回的对象进行精细调整;支持事务、查询和过滤API等。Prisma还允许根据模型对数据库模式进行迁移。此外,它通过在框架中抽象出所有数据库客户端工作,使应用程序与数据库无关。Prisma提供了很多便利和强大的功能,只需定义和维护模型定义即可。很容易理解为什么这个JavaScript的ORM工具是开发者的热门选择。
作者:Matthew Tyson
更多技术干货请关注公众号“云原生数据库”
squids.cn,目前可体验全网zui低价RDS,免费的迁移工具DBMotion、SQL开发工具等。
相关文章:

Prisma.js:JavaScript中的基于代码的ORM
Prisma是一种流行的用于服务器端JavaScript和TypeScript的数据映射层(ORM)。它的核心目的是简化和自动化数据在存储和应用程序代码之间的传输方式。Prisma支持各种数据存储,并为数据持久化提供了一个强大而灵活的抽象层。通过这个基于代码的…...

解决问题:在cocos create中如何从b文件调用到a文件里用CC.resource.load动态加载的图集
目录 1.在a文件中定义一个公共的变量存储动态加载的图集 2.在a.js中添加一个静态方法,返回动态加载的图集 3.在b.js中使用a.js中定义的静态方法获取图集,并使用它 假设a文件中用CC.resource.load动态加载了一张图集,b文件需要使用这张图集&am…...

分布式 - 消息队列Kafka:Kafka 消费者消费位移的提交方式
文章目录 1. 自动提交消费位移2. 自动提交消费位移存在的问题?3. 手动提交消费位移1. 同步提交消费位移2. 异步提交消费位移3. 同步和异步组合提交消费位移4. 提交特定的消费位移5. 按分区提交消费位移 4. 消费者查找不到消费位移时怎么办?5. 如何从特定…...
如何利用 ChatGPT 进行自动数据清理和预处理
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景 ChatGPT 已经成为一把可用于多种应用的瑞士军刀,并且有大量的空间将 ChatGPT 集成到数据科学工作流程中。 如果您曾经在真实数据集上训练过机器学习模型,您就会知道数据清理和预…...
PHP“牵手”淘宝商品评论数据采集方法,淘宝API接口申请指南
淘宝天猫商品评论数据接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用…...

你更喜欢哪一个:VueJS 还是 ReactJS?
观点列表: 1、如果你想在 HTML 中使用 JS,请使用 Vue; 如果你想在 JS 中使用 HTML,请使用 React。 当然,如果您希望在 JS 中使用 HTML,请将 Vue 与 JSX 结合使用。 2、Svelte:我喜欢它&#…...
PyTorch学习笔记(十六)——利用GPU训练
一、方式一 网络模型、损失函数、数据(包括输入、标注) 找到以上三种变量,调用它们的.cuda(),再返回即可 if torch.cuda.is_available():mynn mynn.cuda() if torch.cuda.is_available():loss_function loss_function.cuda(…...
【实战】十一、看板页面及任务组页面开发(三) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(二十五)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

金额千位符自定义指令
自定义指令文件 moneyFormat.js /*** v-money 金额千分位转换*/export default {inserted: inputFormatter({// 格式化函数formatter(num, util) {if(num null || num || num undefined || typeof(num) undefined){return }if(util 万元 || util 万){return formatMone…...

请不要用 JSON 作为配置文件,使用JSON做配置文件的缺点
我最近关注到有的项目使用JSON作为配置文件。我觉得这不是个好主意。 这不是JSON的设计目的,因此也不是它擅长的。JSON旨在成为一种“轻量级数据交换格式”,并声称它“易于人类读写”和“易于机器解析和生成”。 作为一种数据交换格式,JSON是…...
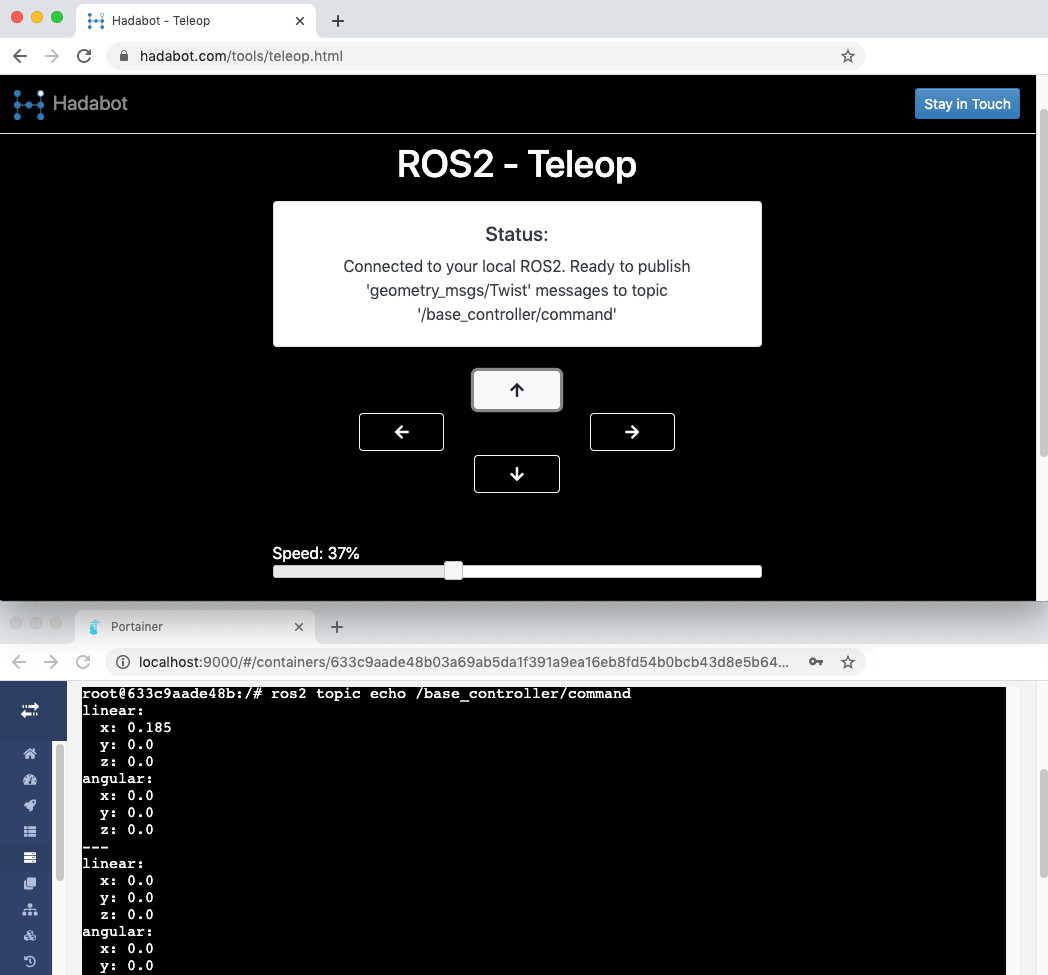
Hadabot:从网络浏览器操作 ROS2 远程控制器
一、说明 Hadabot Hadabot是一个学习ROS2和机器人技术的机器人套件。使用 Hadabot,您将能够以最小的挫败感和恐吓来构建和编程物理 ROS2 机器人。Hadabot套件目前正在开发中。它将仅针对ROS2功能,并强调基于Web的用户界面。 随着开发的进展&a…...

Kotlin 协程
Kotlin 协程(Coroutines)是一种轻量级的并发编程解决方案,旨在简化异步操作和多线程编程。它提供了一种顺序和非阻塞的方式来处理并发任务,使得代码可以更加简洁和易于理解。Kotlin 协程通过提供一套高级 API,使并发代…...
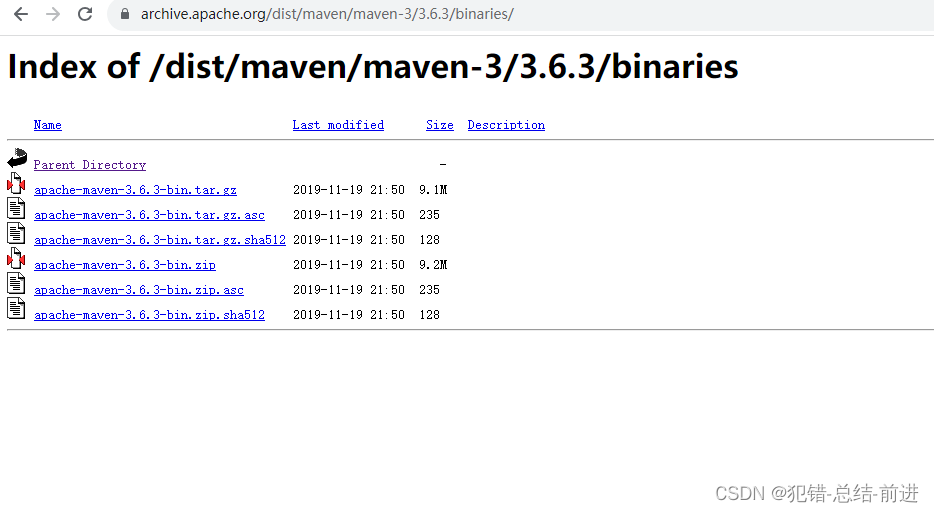
maven 从官网下载指定版本
1. 进入官网下载页面 Maven – Download Apache Maven 点击下图所示链接 2. 进入文件页,选择需要的版本 3. 选binaries 4. 选文件,下载即可...

数据结构---串(赋值,求子串,比较,定位)
目录 一.初始化 顺序表中串的存储 串的链式存储 二.赋值操作:将str赋值给S 链式表 顺序表 三.复制操作:将chars复制到str中 链式表 顺序表 四.判空操作 链式表 顺序表 五.清空操作 六.串联结 链式表 顺序表 七.求子串 链式表 顺序表…...
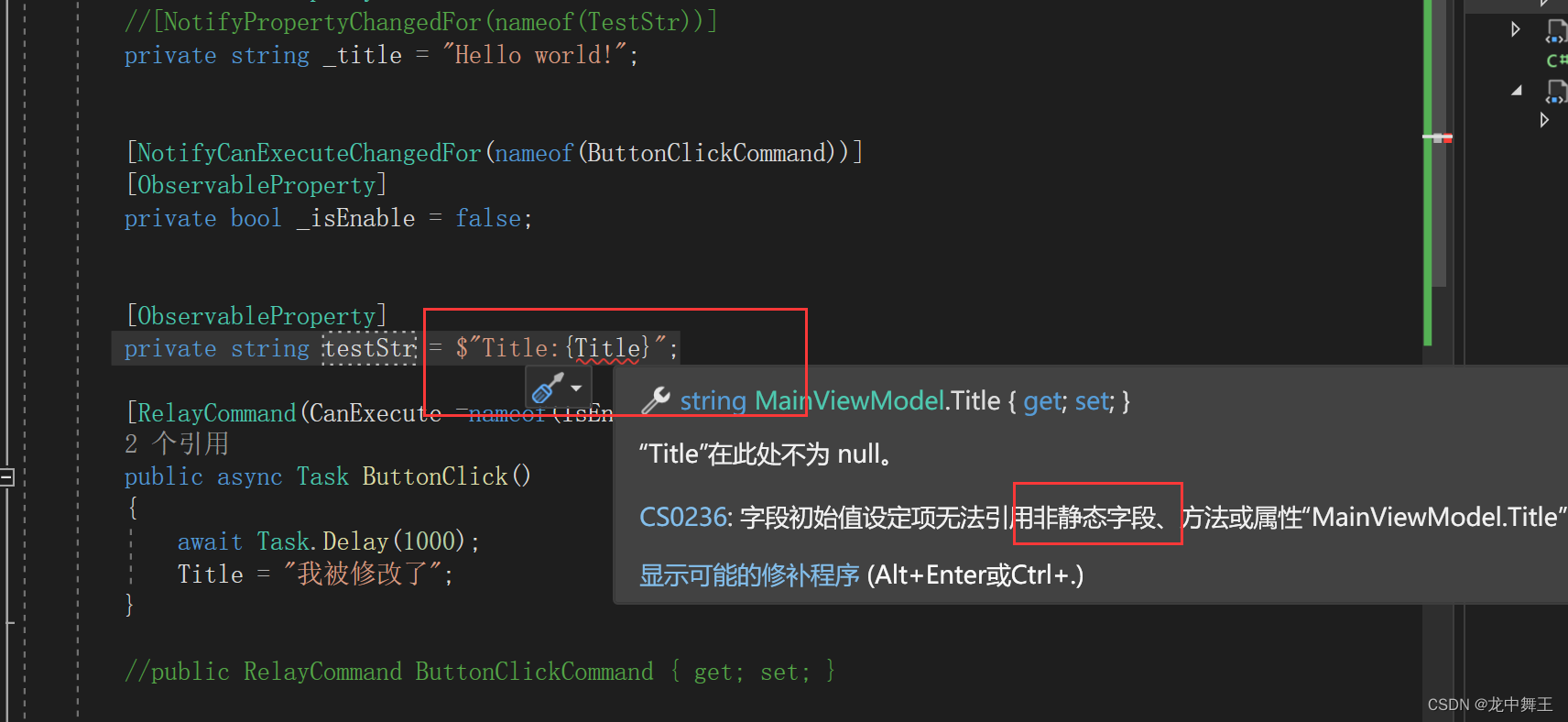
WPF CommunityToolkit.Mvvm
文章目录 前言ToolkitNuget安装简单使用SetProperty,通知更新RealyCommandCanExecute 新功能,代码生成器ObservablePropertyNotifyCanExecuteChangedForRelayCommand其他功能对应关系 NotifyPropertyChangedFor 前言 CommunityToolkit.Mvvm(…...

Vue开发中如何解决国际化语言切换问题
Vue开发中如何解决国际化语言切换问题 引言: 在如今的全球化时代,应用程序的国际化变得越来越重要。为了让不同地区的用户能够更好地使用应用程序,我们需要对内容进行本地化,以适应不同语言和文化环境。对于使用Vue进行开发的应用…...
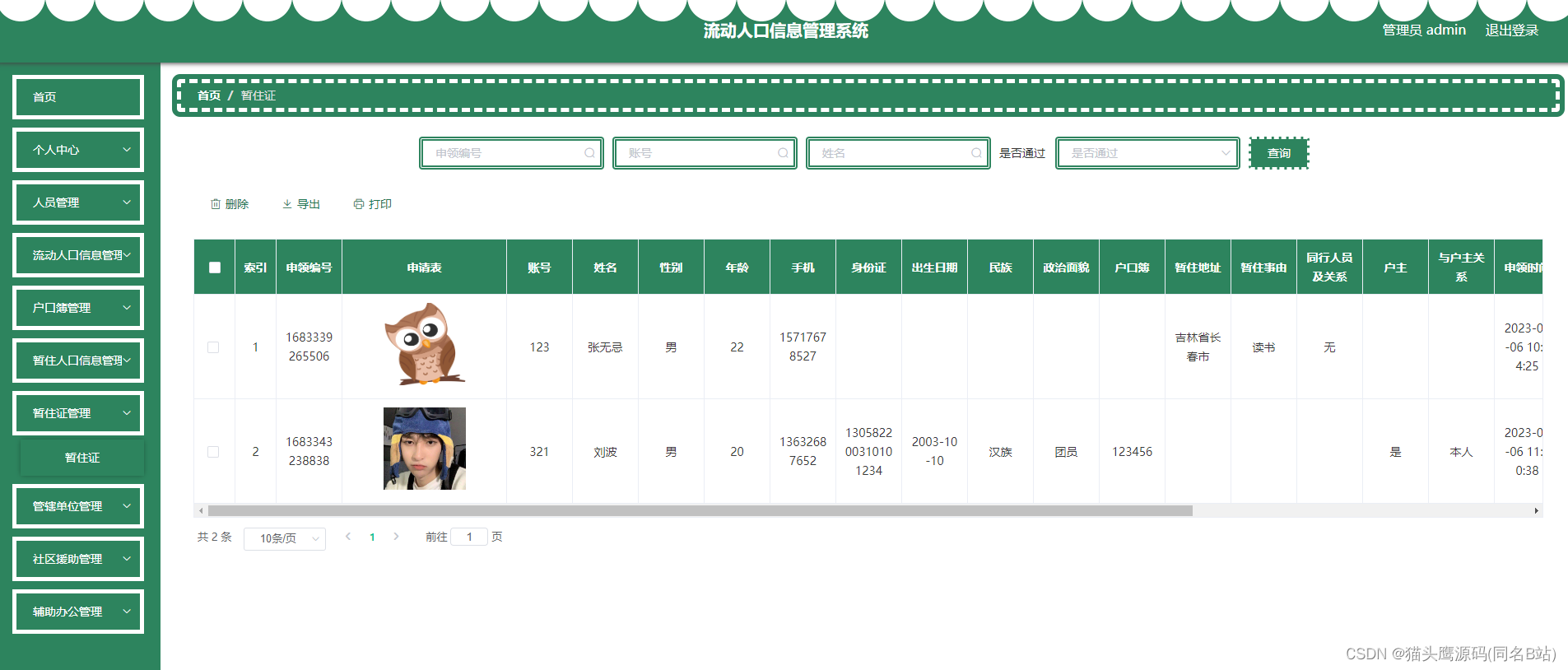
基于springboot+vue的流动人口登记系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Stable Diffusion的使用以及各种资源
Stable Diffsuion资源目录 SD简述sd安装模型下载关键词,描述语句插件管理controlNet自己训练模型 SD简述 Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如…...

Redis 分布式锁的实现方式
一般来说,在对数据进行“加锁”时,程序首先需要通过获取(acquire)锁来得到对数据排他性访问的能力,然后才能对数据执行一系列操作,最后还要将锁释放(release)给其他程序。 对于能够…...

VMware上搭建的虚拟机突然本地无法连接服务器
长时间没有使用VMware 虚拟机了,今天突然登录上去,启动虚拟服务器后发现本地等不了了, 经过排查发现是开启了:VirtualBox Host-Only Network 关闭之后就本机就可以直连服务器了...
)
MongoDB:如何构建“数据回收站“,防止人为误删数据(延迟节点)
更多内容请见: 《深入掌握MongoDB数据库》 - 专栏介绍和目录 一、引言:数据误删的现实挑战 在企业级数据库系统中,人为误删数据是导致业务中断的常见原因。根据2023年数据库安全报告,37%的数据丢失事件是由人为错误引起的,其中误删除操作占主要部分。MongoDB作为企业级No…...

浅谈MIKE URBAN转SWMM的方法
01 前言近期有群友咨询MIKE URBAN怎么转换成SWMM的INP文件格式,其实这个是很简单的,前提是你对两个软件格式足够熟悉,另一方面,很多年前SWMM就开发了inpPNS软件。可以利用这个软件便可实现转换,小编抽时间给大家分享下…...

RK3568上Qt5.12.8编译eglfs报错?手把手教你解决fbdev_window.h缺失问题
RK3568 Qt5.12.8编译eglfs报错全解析:从fbdev_window.h缺失到完整解决方案 在嵌入式开发领域,RK3568作为Rockchip推出的高性能处理器,结合Qt框架的图形界面开发能力,为工业控制、智能终端等场景提供了强大的解决方案。然而&#…...
)
S32K312实战:用AUTOSAR Icu模块测量PWM占空比与周期(基于NXP MCAL与EB Tresos)
S32K312实战:AUTOSAR Icu模块精准测量PWM信号的工程实践 在汽车电子开发中,PWM信号的精确测量是ECU功能实现的基础环节。无论是发动机控制单元中的转速信号采集,还是车身电子中的执行器状态反馈,都需要对PWM信号的周期、占空比等参…...

CST仿真EIT电磁诱导透明:石墨烯建模与案例分析
CST仿真eit电磁诱导透明(包括石墨烯的建模) EIT石墨烯电磁诱导透明案例搞EIT仿真的都知道,传统金属结构虽然经典,但石墨烯的可调性才是现在的香饽饽——靠栅压就能调费米能级,相当于给器件装了个电控遥控器,在传感器、慢光器件里简…...

大厂疯抢!AI Agent开发岗要求速览+进阶学习路线图,速收藏!
文章分析了大厂AI Agent开发岗位的核心要求,包括扎实的后端开发基础、AI知识储备、主流框架掌握等。文章强调AI应用开发与后端开发并非对立,而是相辅相成,并提供了详细的学习路线图,涵盖基础阶段、AI知识入门、实践项目、深化与拓…...

Phi-4-mini-reasoning实战案例:用supervisorctl重启服务解决502错误
Phi-4-mini-reasoning实战案例:用supervisorctl重启服务解决502错误 1. 问题场景描述 最近在部署Phi-4-mini-reasoning推理服务时,遇到了一个典型问题:Web界面突然返回502错误,导致用户无法正常使用推理功能。作为一款专注于数学…...

Streamlit像素UI深度优化教程:解决Ostrakon-VL终端文字遮挡问题
Streamlit像素UI深度优化教程:解决Ostrakon-VL终端文字遮挡问题 1. 项目背景与问题分析 在开发Ostrakon-VL零售扫描终端时,我们选择了一种独特的像素艺术风格UI设计。这种高饱和度的8-bit复古游戏美学虽然提升了用户体验的趣味性,但也带来了…...

[vxe-table] 动态列渲染中v-if与key的协同优化方案
1. 动态列渲染的常见问题与根源分析 在使用vxe-table进行动态列渲染时,很多开发者都遇到过这样的场景:当表格列通过v-if条件动态显示或隐藏时,列的位置和样式会出现莫名其妙的错乱。比如原本应该在第三列显示的数据突然跳到了第五列ÿ…...

2026年探访阎良:这三家头疗肩颈养生馆的服务为何备受好评?
在快节奏的现代生活中,头颈肩的亚健康问题几乎成了都市人的“标配”。头痛、失眠、肩颈僵硬,这些困扰背后,是人们对专业、有效且放松的养生服务的迫切需求。近期,笔者深入西安市阎良区,实地探访了三家在本地口碑颇佳的…...