5.6 汇编语言:汇编高效数组寻址
数组和指针都是用来处理内存地址的操作,二者在C语言中可以互换使用。数组是相同数据类型的一组集合,这些数据在内存中是连续存储的,在C语言中可以定义一维、二维、甚至多维数组。多维数组在内存中也是连续存储的,只是数据的组织方式不同。在汇编语言中,实现多维数组的寻址方式相对于C语言来说稍显复杂,但仍然可行。下面介绍一些常用的汇编语言方式来实现多维数组的寻址。
6.1 数组取值操作
数组取值操作是实现数组寻址的基础,在汇编语言中取值的操作有多种实现方式,这里笔者准备了一个通用案例该案例中包含了,使用OFFSET,PTR,LENGTHOF,TYPE,SIZEOF依次取值的操作细节,读者可自行编译并观察程序的取值过程并以此熟悉这些常用汇编指令集的使用。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataWordVar1 WORD 1234hDwordVar2 DWORD 12345678hArrayBT BYTE 1,2,3,4,5,6,7,8,9,0hArrayDW DWORD 1000,2000,3000,4000,5000,6000,7000,8000,9000,0hArrayTP DWORD 30 DUP(?)
.codemain PROC; 使用 OFFSET 可返回数据标号的偏移地址,单位是字节.; 偏移地址代表标号距DS数据段基址的距离.xor eax,eaxmov eax,offset WordVar1mov eax,offset DwordVar2; 使用 PTR 可指定默认取出参数的大小(DWORD/WORD/BYTE)mov eax,dword ptr ds:[DwordVar2] ; eax = 12345678hxor eax,eaxmov ax,word ptr ds:[DwordVar2] ; ax = 5678hmov ax,word ptr ds:[DwordVar2 + 2] ; ax = 1234h; 使用 LENGTHOF 可以计算数组元素的数量xor eax,eaxmov eax,lengthof ArrayDW ; eax = 10mov eax,lengthof ArrayBT ; eax = 10; 使用 TYPE 可返回按照字节计算的单个元素的大小.xor eax,eaxmov eax,TYPE WordVar1 ; eax = 2mov eax,TYPE DwordVar2 ; eax = 4mov eax,TYPE ArrayDW ; eax = 4; 使用 SIZEOF 返回等于LENGTHOF(总元素数)和TYPE(每个元素占用字节)返回值的乘基.xor eax,eaxmov eax,sizeof ArrayBT ; eax = 10mov eax,sizeof ArrayTP ; eax = 120invoke ExitProcess,0main ENDP
END main
6.2 数组直接寻址
在声明变量名称的后面加上偏移地址即可实现直接寻址,直接寻址中可以通过立即数寻址,也可以通过寄存器相加的方式寻址,如果遇到双字等还可以使用基址变址寻址,这些寻址都属于直接寻址.
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataArrayB BYTE 10h,20h,30h,40h,50hArrayW WORD 100h,200h,300h,400hArrayDW DWORD 1h,2h,3h,4h,5h,6h,7h,8h,9h
.codemain PROC; 针对字节的寻址操作mov al,[ArrayB] ; al=10mov al,[ArrayB+1] ; al=20mov al,[ArrayB+2] ; al=30; 针对内存单元字存储操作mov bx,[ArrayW] ; bx=100mov bx,[ArrayW+2] ; bx=200mov bx,[ArrayW+4] ; bx=300; 针对内存单元双字存储操作mov eax,[ArrayDW] ; eax=00000001mov eax,[ArrayDW+4] ; eax=00000002mov eax,[ArrayDW+8] ; eax=00000003; 基址加偏移寻址: 通过循环eax的值进行寻址,每次eax递增2mov esi,offset ArrayWmov eax,0mov ecx,lengthof ArrayWs1:mov dx,word ptr ds:[esi + eax]add eax,2loop s1; 基址变址寻址: 循环取出数组中的元素mov esi,offset ArrayDW ; 数组基址mov eax,0 ; 定义为元素下标mov ecx,lengthof ArrayDW ; 循环次数s2:mov edi,dword ptr ds:[esi + eax * 4] ; 取出数值放入ediinc eax ; 数组递增loop s2invoke ExitProcess,0main ENDP
END main
6.3 数组间接寻址
数组中没有固定的编号,处理此类数组唯一可行的方法是用寄存器作为指针并操作寄存器的值,这种方法称为间接寻址,间接寻址通常可通过ESI实现内存寻址,也可通过ESP实现对堆栈的寻址操作.
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataArrayDW DWORD 1h,2h,3h,4h,5h,6h,7h,8h,9h
.codemain PROC; 第一种: 通过使用ESI寄存器实现寻址.mov esi,offset ArrayDW ; 取出数组基地址mov ecx,lengthof ArrayDW ; 取出数组元素个数s1:mov eax,dword ptr ds:[esi] ; 间接寻址add esi,4 ; 每次递增4loop s1; 第二种: 通过ESP堆栈寄存器,实现寻址.mov eax,100 ; eax=1mov ebx,200 ; ebx=2mov ecx,300 ; ecx=3push eax ; push 1push ebx ; push 2push ecx ; push 3mov edx,[esp + 8] ; EDX = [ESP+8] = 1mov edx,[esp + 4] ; EDX = [ESP+4] = 2 mov edx,[esp] ; EDX = [ESP] = 3; 第三种(高级版): 通过ESP堆栈寄存器,实现寻址.push ebpmov ebp,esp ; 保存栈地址lea eax,dword ptr ds:[ArrayDW] ; 获取到ArrayDW基地址; -> 先将数据压栈mov ecx,9 ; 循环9次s2: push dword ptr ss:[eax] ; 将数据压入堆栈add eax,4 ; 每次递增4字节loop s2; -> 在堆栈中取数据mov eax,32 ; 此处是 4*9=36 36 - 4 = 32mov ecx,9 ; 循环9次s3: mov edx,dword ptr ss:[esp + eax] ; 寻找栈中元素sub eax,4 ; 每次递减4字节loop s3add esp,36 ; 用完之后修正堆栈pop ebp ; 恢复ebpinvoke ExitProcess,0main ENDP
END main
6.4 比例因子寻址
比例因子寻址是一种常见的寻址方式,通常用于访问数组、矩阵等数据结构。通过指定不同的比例因子,可以实现对多维数组的访问。在使用比例因子寻址时,需要考虑变量的偏移地址、维度、类型以及访问方式等因素,另外比例因子寻址的效率通常比直接寻址要低,因为需要进行一些额外的乘法和加法运算。
使用比例因子寻址可以方便地访问数组或结构体中的元素。在汇编语言中,比例因子可以通过指定一个乘数来实现,这个乘数可以是1、2、4或8,它定义了一个元素相对于数组起始地址的偏移量。
以下例子每个DWORD=4字节,且总元素下标=0-3,得出比例因子3* type arrayDW,并根据比例因子实现对数组的寻址操作。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataArrayW WORD 1h,2h,3h,4h,5hArrayDW DWORD 1h,2h,3h,4h,5h,6h,7h,8h,9hTwoArray DWORD 10h,20h,30h,40h,50hRowSize = ($ - TwoArray) ; 每行所占空间 20 字节DWORD 60h,70h,80h,90h,0ahDWORD 0bh,0ch,0dh,0eh,0fh
.codemain PROC; 第一种比例因子寻址mov esi,0 ; 初始化因子mov ecx,9 ; 设置循环次数s1:mov eax,ArrayDW[esi * 4] ; 通过因子寻址,4 = DWORDadd esi,1 ; 递增因子loop s1; 第二种比例因子寻址mov esi,0lea edi,word ptr ds:[ArrayW]mov ecx,5s2:mov ax,word ptr ds:[edi + esi * type ArrayW]inc esiloop s2; 第三种二维数组寻址row_index = 1column_index = 2mov ebx,offset TwoArray ; 数组首地址add ebx,RowSize * row_index ; 控制寻址行mov esi,column_index ; 控制行中第几个mov eax, dword ptr ds:[ebx + esi * TYPE TwoArray]invoke ExitProcess,0main ENDP
END main
以二维数组为例,通过比例因子寻址可以模拟实现二维数组寻址操作。比例因子是指访问数组元素时,相邻元素之间在内存中的跨度。在访问二维数组时,需要指定两个比例因子:第一个比例因子表示行数,第二个比例因子表示列数。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataTwoArray DWORD 10h,20h,30h,40h,50hRowSize = ($ - TwoArray) ; 每行所占空间 20 字节DWORD 60h,70h,80h,90h,0ahDWORD 0bh,0ch,0dh,0eh,0fh
.codemain PROClea esi,dword ptr ds:[TwoArray] ; 取基地址mov eax,0 ; 控制外层循环变量mov ecx,3 ; 外层循环次数s1:push ecx ; 保存外循环次数push eaxmov ecx,5 ; 内层循环数s2: add eax,4 ; 每次递增4mov edx,dword ptr ds:[esi + eax] ; 定位到内层循环元素loop s2pop eaxpop ecxadd eax,20 ; 控制外层数组loop s1 invoke ExitProcess,0main ENDP
END main
通过使用比例因子的方式可以对数组进行求和。一般来说,数组求和可以使用循环语句来实现,但在某些情况下,可以通过使用比例因子的方式来提高求和的效率。
在使用比例因子求和时,需要使用汇编指令lea和add。首先,使用lea指令计算出数组元素的地址,然后使用add指令求出数组元素的和。例如,假设有一个100个元素的整型数组a,可以使用以下汇编指令来计算数组元素的和:
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataArrayA DWORD 10h,20h,30h,40h,50hArrayB DWORD 10h,20h,30h,40h,50hNewArray DWORD 5 dup(0)
.codemain PROC; 循环让数组中的每一个数加10后回写mov ebx,0mov ecx,5s1:mov eax,dword ptr ds:[ArrayA + ebx * 4]add eax,10mov dword ptr ds:[ArrayA + ebx * 4],eaxinc ebxloop s1; 循环让数组A与数组B相加后赋值到数组NewArraymov ebx,0mov ecx,5s2:mov esi,dword ptr ds:[ArrayA + ebx]add esi,dword ptr ds:[ArrayB + ebx]mov dword ptr ds:[NewArray + ebx],esiadd ebx,4loop s2invoke ExitProcess,0main ENDP
END main
6.5 数组指针寻址
指针变量是指存储另一个变量的地址的变量。指针类型是指可以存储对另一个变量的指针的数据类型。在Intel处理器中,涉及指针时有near指针和far指针两种不同类型,其中Far指针一般用于实模式下的内存管理,而在保护模式下,一般采用Near指针。
在保护模式下,Near指针指的是一个指针变量,它只存储一个内存地址。通常,Near指针的大小为4字节,因此,它可以被存储在单个双字变量中。除此之外,也可以使用void*类型的指针来代表一个指向任何类型的指针。
数组指针是指一个指向数组的指针变量。数组名是数组第一个元素的地址。因此,对数组名求地址就是数组指针。数组指针可以进行地址的加减运算,从而实现对数组中不同元素的访问。
例如,假设有一个大小为10的整型数组a,可以使用以下汇编代码来访问其中一个元素(如a[3]):
lea esi, [a] ; 将数组a的地址存储到esi中
mov eax, dword [esi+3*4] ; 将a[3]的值存储到eax中
在这个示例中,使用lea指令将数组a的地址存储到esi中。数组a元素的大小为4个字节(即eax大小),所以这里是使用3 * 4来表示a[3]的偏移地址。虽然这里的地址计算看起来比较繁琐,但是通过使用数组指针寻址,可以避免对数组进行循环访问等相对低效的操作。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataArrayA WORD 1h,2h,3h,4h,5hArrayB DWORD 1h,2h,3h,4h,5hPtrA DWORD offset ArrayA ; 指针 PtrA --> ArrayAPtrB DWORD offset ArrayB ; 指针 PTRB --> ArrayB
.codemain PROCmov ebx,0 ; 寻址因子mov ecx,5 ; 循环次数s1:mov esi,dword ptr ds:[PtrA] ; 将指针指向PtrAmov ax,word ptr ds:[esi + ebx * 2] ; 每次递增2字节mov esi,dword ptr ds:[PtrB] ; 将指针指向PtrBmov eax,dword ptr cs:[esi + ebx * 4] ; 每次递增4字节inc esi ; 基地址递增inc ebx ; 因子递增loop s1invoke ExitProcess,0main ENDP
END main
6.6 模拟二维数组寻址
在汇编语言中,内存是线性的,只有一个维度,因此,二维数组需要通过模拟方式来实现。常用的方式是使用比例因子寻址和数组指针寻址。以比例因子寻址为例,可以使用汇编指令lea和mov来模拟实现二维数组的寻址操作。例如,假设有一个二维数组a[3][4],可以使用以下汇编指令来访问数组元素:
mov eax, [a + ebx * 4 + ecx * 4 * 3] ; 访问a[ebx][ecx]元素
其中,a是数组的基地址,ebx是列号,ecx是行号。指定一个比例因子为3,可以将二维数组转换成一维数组,每行的大小为4个字节,因此在访问a[ebx][ecx]时,需要加上行号的偏移量(即ecx * 4 * 3)。
除了使用比例因子寻址,还可以使用数组指针寻址来模拟二维数组的操作。例如,假设有一个二维数组b[3][4],可以使用以下汇编指令来访问数组元素:
lea esi, [b] ; 将数组b的地址存储到esi中
mov eax, dword ptr [esi + ebx * 16 + ecx * 4] ; 访问a[ebx][ecx]元素
在这个示例中,使用lea指令将二维数组b的地址存储到esi中。首先,指针+偏移,将现在想要查的数字所在的行号+列号的位置指向到了数组中,再通过mov指令将数组元素的值存储到eax中。
由于我们的内存本身就是线性的,所以C语言中的二维数组也是线性的,二维数组仅仅只是一维数组的高阶抽象,唯一的区别仅仅只是寻址方式的不同,首先我们先来在Debug模式下编译一段代码,然后分别分析一下C编译器是如何优化的。
void function_1()
{int array[2][3] = { { 1, 2, 3 }, { 4, 5, 6 } };int x = 0, y = 1;array[x][y] = 0;
}void function_2()
{int array[2][3] = { { 1, 2, 3 }, { 4, 5, 6 } };int x = 0, y = 1;array[x][y] = 0;int a = 1, b = 2;array[a][b] = 1;
}
编译通过后,我们反汇编function_1函数,这段代码主要实现给array[0][1]赋值,核心代码如下:
0040106E 8B45 E4 mov eax, dword ptr [ebp-1C] ; eax = x 坐标
00401071 6BC0 0C imul eax, eax, 0C ; eax = x * 0c 索引数组
00401074 8D4C05 E8 lea ecx, dword ptr [ebp+eax-18] ; ecx = y 坐标
00401078 8B55 E0 mov edx, dword ptr [ebp-20] ; edx = 1 二维维度
0040107B C70491 00000000 mov dword ptr [ecx+edx*4], 0 ; 1+1*4=5 4字节中的5,指向第2个元素
接着来解释一下上方汇编代码:
- 1.第1条代码: 寄存器EAX是获取到的x的值,此处为C语言中的x=0
- 2.第2条代码: 其中0C代表一个维度的长度,每个数组有3个元素
(3x4=0C)每个元素4字节 - 3.第3条代码: 寄存器ECX代表数组的y坐标
- 4.第5条代码: 公式
ecx + edx * 4相当于数组首地址 + sizeof(int) * y
寻址公式可总结为: 数组首地址 + sizeof(type[一维数组元素]) * x + sizeof(int) * y 简化后变成数组首地址 + x坐标 + (y坐标 * 4)即可得到寻址地址.
我们来编译function_2函数,一维数组的总大小3*4=0C,并通过寻址公式计算下.
004113F8 | C745 D8 00000000 | mov dword ptr ss:[ebp-0x28],0x0 | x = 0
004113FF | C745 CC 01000000 | mov dword ptr ss:[ebp-0x34],0x1 | y = 1
00411406 | 6B45 D8 0C | imul eax,dword ptr ss:[ebp-0x28],0xC | eax = x坐标
0041140A | 8D4C05 E4 | lea ecx,dword ptr ss:[ebp+eax-0x1C] | ecx = 数组array[0]首地址
0041140E | 8B55 CC | mov edx,dword ptr ss:[ebp-0x34] | edx = y坐标
00411411 | C70491 00000000 | mov dword ptr ds:[ecx+edx*4],0x0 | ecx(数组首地址) + y坐标 * 400411418 | C745 C0 01000000 | mov dword ptr ss:[ebp-0x40],0x1 | a = 1
0041141F | C745 B4 02000000 | mov dword ptr ss:[ebp-0x4C],0x2 | b = 2
00411426 | 6B45 C0 0C | imul eax,dword ptr ss:[ebp-0x40],0xC | eax = 1 * 0c = 0c
0041142A | 8D4C05 E4 | lea ecx,dword ptr ss:[ebp+eax-0x1C] | 找到数组array[1]的首地址
0041142E | 8B55 B4 | mov edx,dword ptr ss:[ebp-0x4C] | 数组b坐标 2
00411431 | C70491 01000000 | mov dword ptr ds:[ecx+edx*4],0x1 | ecx(数组首地址) + b坐标 * 4
根据分析结论,我自己仿照编译器编译特性,仿写了一段汇编版寻址代码,代码很简单,如下:
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataMyArrayDWORD DWORD 1,2,3,4,5,6,0hMyArrayWORD DWORD 1,2,3,4,5,6,7,8,9,10,0h
.codemain PROCxor eax,eaxxor ebx,ebxxor ecx,ecxxor edx,edx; 模拟实现对二维4字节数组寻址 寻找 MyArrayDWORD[1][1]; int array[2][3] = {{1,2,3},{4,5,6}}mov eax,0ch ; 代表每个一维数组长度imul ebx,eax,1 ; 定位维度mov ecx,4 ; 每个四字节imul edx,ecx,1 ; 定位数组add ebx,edx ; 累加步长mov edx,dword ptr [MyArrayDWORD + ebx]; 模拟实现对二维数组寻址 寻找 MyArrayWORD[1][2]; word array[2][5]={{1,2,3,4,5},{6,7,8,9,10}}xor eax,eaxxor ebx,ebxxor ecx,ecxxor edx,edxmov eax,14h ; 每个一维长度 4 * 5imul ebx,eax,1 ; 定位到 {6,7,8,9,10}mov ecx,4 ; 定义步长4字节imul edx,ecx,2 ; 定位到元素 8add ebx,edx ; 累加步长mov edx,dword ptr [MyArrayWORD + ebx]main ENDP
END main
6.7 模拟三维数组寻址
相对于二维数组,三维数组的寻址更加繁琐,但仍然可以使用类似的方式进行模拟。常用的方式是使用比例因子寻址和多级指针。以比例因子寻址为例,我们可以使用数组指针来模拟多维数组的访问操作。假设有一个三维数组c[2][3][4],可以使用以下汇编指令来访问数组元素:
lea esi, [c] ; 将数组c的地址存储到esi中
mov eax, dword ptr [esi + (i*3+j)*16 + k*4] ; 访问c[i][j][k]元素
其中,i表示数组的第一维下标,j表示数组的第二维下标,k表示数组的第三维下标。指定一个比例因子为16,可以将三维数组转换成一维数组,每行的大小为4 * 4 = 16字节,因此在访问c[i][j][k]时,需要加上前两个维度的偏移量(即(i*3+j) * 16),再加上第三个维度的偏移量(即k * 4)。
除了使用比例因子寻址,还可以使用多级指针来模拟三维数组的访问操作。例如,假设有一个三维数组d[2][3][4],可以使用以下汇编指令来访问数组元素:
lea eax, [d] ; 将数组d的地址存储到eax中
mov ebx, [eax + i*4] ; 获取指向d[i]的指针
mov ecx, [ebx + j*4] ; 获取指向d[i][j]的指针
mov edx, [ecx + k*4] ; 获取d[i][j][k]的值
在这个示例中,使用lea指令将三维数组d的地址存储到eax中。然后,使用mov指令依次获取d[i]、d[i][j]以及d[i][j][k]的指针并获取其值。其中,i表示数组的第一维下标,j表示数组的第二维下标,k表示数组的第三维下标。
老样子,我们先来编写一段代码,代码中只需要声明一个三维数组即可.
int main(int argc, char* argv[])
{// int Array[M][C][H]int Array[2][3][4] = {NULL};int x = 0;int y = 1;int z = 2;Array[x][y][z] = 3;return 0;
}
首先我们反汇编这段代码,然后观察反汇编代码展示形式,并套入公式看看.针对三维数组 int Array[M][C][H]其下标操Array[x][y][z]=3
- 寻址公式为:
Array + sizeof(type[C][H]) * x + sizeof(type[H])*y + sizeof(type)*z - 寻址公式为:
Array + sizeof(Array[C][H]) * x + sizeof(Array[H]) * y + sizeof(Array[M]) * z
00401056 |. 8B45 9C mov eax, dword ptr [ebp-64] ; eax = x
00401059 |. 6BC0 30 imul eax, eax, 30 ; sizeof(type[C][H]) * x
0040105C |. 8D4C05 A0 lea ecx, dword ptr [ebp+eax-60] ; 取Array[C][H]基地址
00401060 |. 8B55 98 mov edx, dword ptr [ebp-68] ; Array[C]
00401063 |. C1E2 04 shl edx, 4 ;
00401066 |. 03CA add ecx, edx ;
00401068 |. 8B45 94 mov eax, dword ptr [ebp-6C] ; Array[Z]
0040106B |. C70481 030000 mov dword ptr [ecx+eax*4], 3
接着来解释一下上方汇编代码:
- 1.第1条指令: 得出
eax=x的值. - 2.第2条指令: 其中
eax * 30,相当于求出sizeof(type[C][H]) * x - 3.第3条指令: 求出
数组首地址+eax-60也就求出Array[H]位置,并取地址放入ECX - 4.第4条指令: 临时
[ebp-68]存放Y的值,此处就是得到y的值 - 5.第5条指令: 左移4位,相当于
2^4次方也就是16这一步相当于求sizeof(type[H])的值 - 6.最后
Array[M] + sizeof(type[H])的值求出Array[M][C]的值
接下来我们通过汇编的方式来实现这个寻址过程,为了方便理解,先来写一段C代码,代码中实现定位Array[1][2][3]的位置.
int main(int argc, char* argv[])
{// 对应关系: Array[M][C][H]int Array[2][3][4] = {{{ 1, 2, 3, 4 }, { 2, 3, 4, 5 }, { 3, 4, 5, 6 }},{{ 4, 5, 6, 7 }, { 5, 6, 7, 8 }, { 6, 7, 8, 9 }}};int x = 1;int y = 2;int z = 3;Array[x][y][z] = 999;return 0;
}
最终的汇编版如下,这段代码我一开始并没有想出来怎么写,经过不断尝试,终于算是理解了它的寻址方式,并成功实现了仿写,除去此种方式外其实可以完全将imul替换为shl这样还可以提高运算效率.
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.dataMyArray DWORD 1,2,3,4,2,3,4,5,3,4,5,6,4,5,6,7,5,6,7,8,6,7,8,9,0hCount DWORD ?x DWORD ?y DWORD ?z DWORD ?.codemain PROCxor eax,eaxxor ebx,ebxxor ecx,ecxxor edx,edx; 定位 Array[1][2][3]mov dword ptr [x],1hmov dword ptr [y],2hmov dword ptr [z],3h; 找到 Array[M]imul eax,dword ptr [x],30h ; 定位 Array[1] => ([C] * [H]) * 4lea ecx,dword ptr [MyArray + eax] ; 定位 Array[1] 基地址; 找到 Array[C]mov ebx,dword ptr [y] ; 定位 Array[2] => ([C])shl ebx,4h ; 2^4=32 计算 (EBX * 16)add ecx,ebx ; Array[M] + Array[C]; 找到 Array[H]imul edx,dword ptr[z],4h ; Array[H] * 4add ecx,edxmov dword ptr [Count],ecx ; 取出结果main ENDP
END main
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/a38e7460.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
相关文章:

5.6 汇编语言:汇编高效数组寻址
数组和指针都是用来处理内存地址的操作,二者在C语言中可以互换使用。数组是相同数据类型的一组集合,这些数据在内存中是连续存储的,在C语言中可以定义一维、二维、甚至多维数组。多维数组在内存中也是连续存储的,只是数据的组织方…...

uniapp - 实现卡片式胶囊单选后右上角出现 “√“ 对勾对号选中效果功能,适用于小程序h5网页app全平台通用(一键复制组件源码,开箱即用!)
效果图 uniapp全平台兼容(小程序/h5网页/app)实现点击选择后,右上角出现 √ 对号效果(角标形式展现),功能组件, 改个样式,直接复制使用该组件。 组件源码 在 components 组件文件夹下,随便建立一个 .vue 文件,一键复制下方源码。...

使用Jetpack Compose构建可折叠Card
使用Jetpack Compose构建可折叠Card 为何在Android应用开发中使用扩展卡片 扩展卡片在Android应用开发中广受欢迎,它们可以让开发者打造干净紧凑的用户界面,同时可以轻松展开,显示额外的内容。 通过巧妙地使用扩展卡片,开发者可…...
安卓手机跑 vins slam (1)
我是迪卡魏曼依奇,一直是用手机拍照,将图片导出到电脑,然后使用RealityCapture三维重建。 RealityCapture是靠特征点去把拍摄的多个图像进行对齐的。需要拍摄的足够多,且有特征才能对齐,要不然很多图像会找不到公共点…...
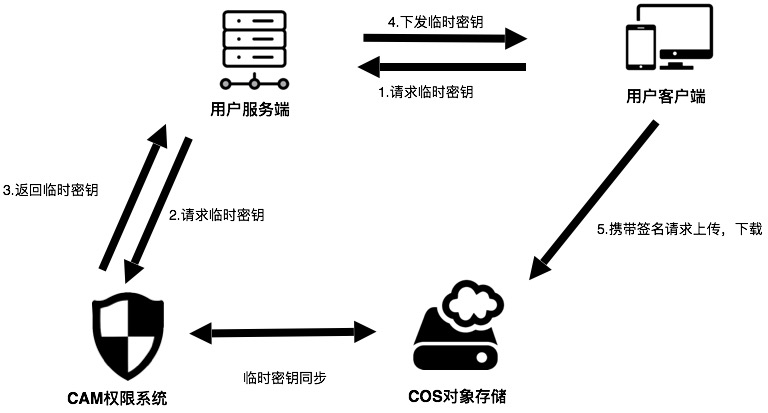
腾讯云-对象存储服务(COS)的使用总结
简介 对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,具有高扩展性、低成本、可靠安全等优点。通过控制台、API、SDK 和工具等多样化方式,用户可简单、快速地接入 COS࿰…...
自定义序列化器和反序列化器)
kafka复习:(3)自定义序列化器和反序列化器
一、实体类定义: public class Company {private String name;private String address;public String getName() {return name;}public void setName(String name) {this.name name;}public String getAddress() {return address;}public void setAddress(String a…...
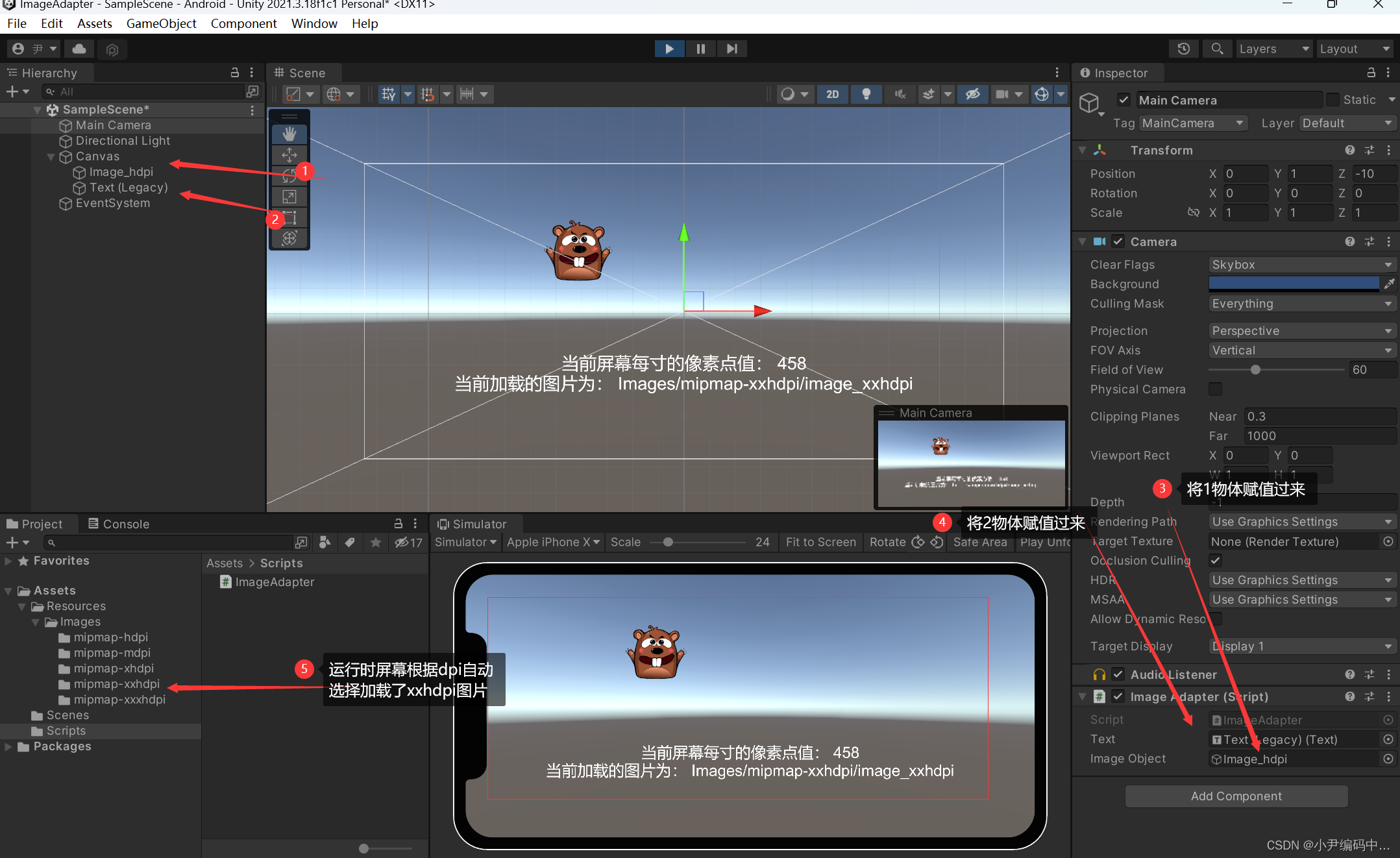
Unity 图片资源的适配
前言 最近小编做Unity项目时,发现在资源处理这方面和Android有所不同;例如:Android的资源文件夹res下会有着mipmap-mdpi,mipmap-hdpi,mipmap-xhdpi,mipmap-xxhdpi,mipmap-xxxhdpi这五个文件夹&a…...
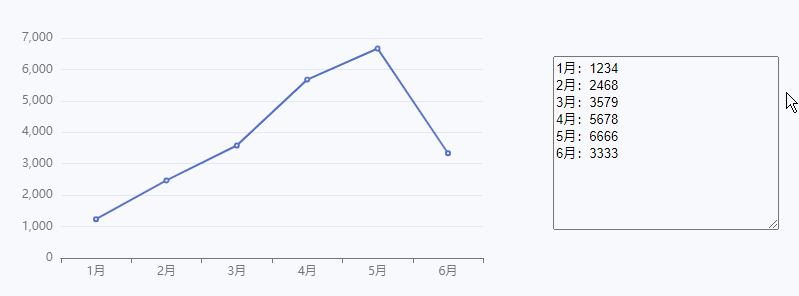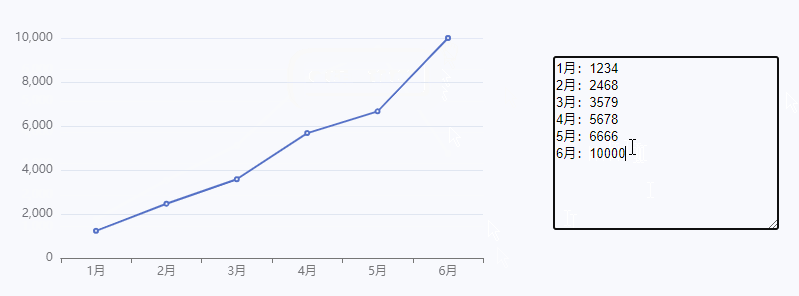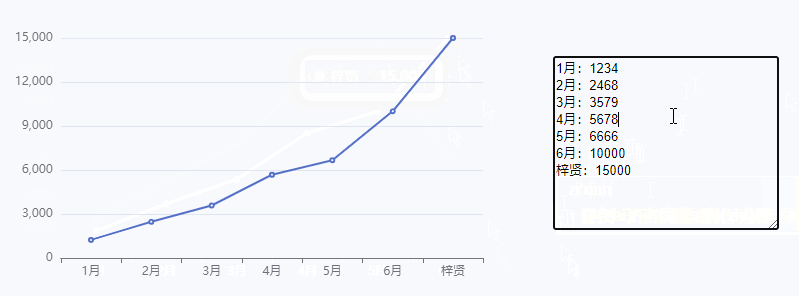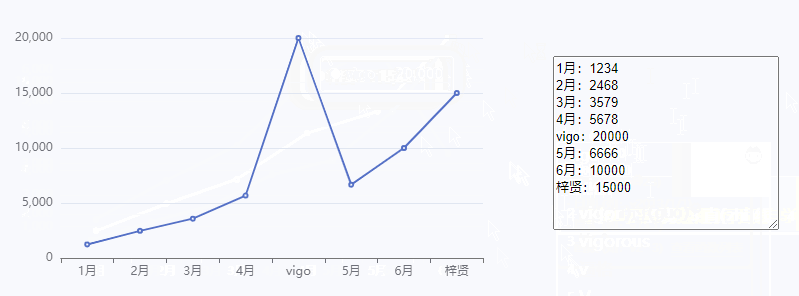
【Axure高保真原型】通过输入框动态控制折线图
今天和大家分享通过输入框动态控制折线图的原型模板,在输入框里维护项目数据,可以自动生成对应的折线图,鼠标移入对应折点,可以查看对应数据。使用也非常方便,只需要修改输入框里的数据,或者复制粘贴文本&a…...
【Java】树结构数据的搜索
这里写自定义目录标题 需要实现的效果前端需要的json格式:一定是一个完整的树结构错误错误的返回格式错误的返回格式实现的效果 正确正确的返回格式正确的展示画面 后端逻辑分析代码总览 数据库表结构 需要实现的效果 前端需要的json格式:一定是一个完整…...
ElementUI中的日历组件加载无效的问题
在ElementUI中提供了一个日历组件。在某些场景下还是比较有用的。只是在使用的时候会有些下坑,大家要注意下。 官网提供的信息比较简介。我们在引入到项目中使用的时候可以能会出现下面的错误提示。 Unknown custom element: <el-calendar> - did you …...
stash临时操作和.gitignore配置)
Git版本管理(03)stash临时操作和.gitignore配置
1 git stash操作(临时存储) 1.1 git stash常见流程 当你修改了某一个分支,但此时要切换分支时如果直接切换会因为一些修改冲突而checkout失败,那么此时就可以使用git stash命令来解决该问题。一般流程为: $git pull# 将当前未提交的修改…...
【ThingJS | 3D可视化】开发框架,一站式数字孪生
博主:_LJaXi Or 東方幻想郷 专栏: 数字孪生 | 3D可视化框架 开发工具:ThingJS在线开发工具 ThingJs 低代码开发 ThingJs 低代码开发注意点场景效果配置层级层级常用API实例化 Thing,加载场景load 加载函数ThingJs 层级关系图查找层…...
SpringBoot返回响应排除为 null 的字段
SpringBoot返回响应排除为 null 的字段 可以通过全局配置,使返回响应中为null的字段,不在出现在返回结果中。 注意:这样配置,使得返回响应包含的字段随请求结果变化,响应到底包含哪些字段不直观;除非业务…...

华为数通方向HCIP-DataCom H12-821题库(单选题:41-60)
第41题 以下关于IS-IS协议说法错误的是? A、IS-IS协议支持CLNP网络 B、IS-IS 协议支持IP 网络 C、IS-IS 协议的报文直接由数据链路层封装 D、IS-IS协议是运行在AS之间的链路状态协议 答案:D 解析: 关于IS-IS协议的说法错误是D. IS-IS协议是运行在A…...

OpenAI推出GPT-3.5Turbo微调功能并更新API;Midjourney更新局部绘制功能
🦉 AI新闻 🚀 OpenAI推出GPT-3.5Turbo微调功能并更新API,将提供GPT-4微调功能 摘要:OpenAI宣布推出GPT-3.5Turbo微调功能,并更新API,使企业和开发者能够定制ChatGPT,达到或超过GPT-4的能力。通…...
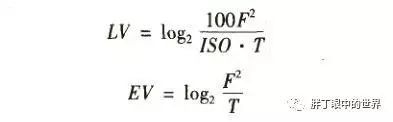
相机成像之3A算法的综述
3A算法是摄像机成像控制技术中的三大自动控制算法。随着计算机视觉的迅速发展,该算法在摄像器材领域具有广泛的应用和前景。 那么3A控制算法又是指什么呢? (1)AE (Auto Exposure)自动曝光控制 (2)AF (Auto Focus)自动聚焦控制 (3)AWB (Auto White Balance)自动白平衡控…...
最新AI系统ChatGPT程序源码/微信公众号/H5端+搭建部署教程+完整知识库
一、前言 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...
OpenCV实例(九)基于深度学习的运动目标检测(二)YOLOv2概述
基于深度学习的运动目标检测(二)YOLOv2&YOLOv3概述 1.YOLOv2概述2.YOLOv3概述2.1 新的基础网络结构:2.2 采用多尺度预测机制。2.3 使用简单的逻辑回归进行分类 1.YOLOv2概述 对YOLO存在的不足,业界又推出了YOLOv2。YOLOv2主要…...
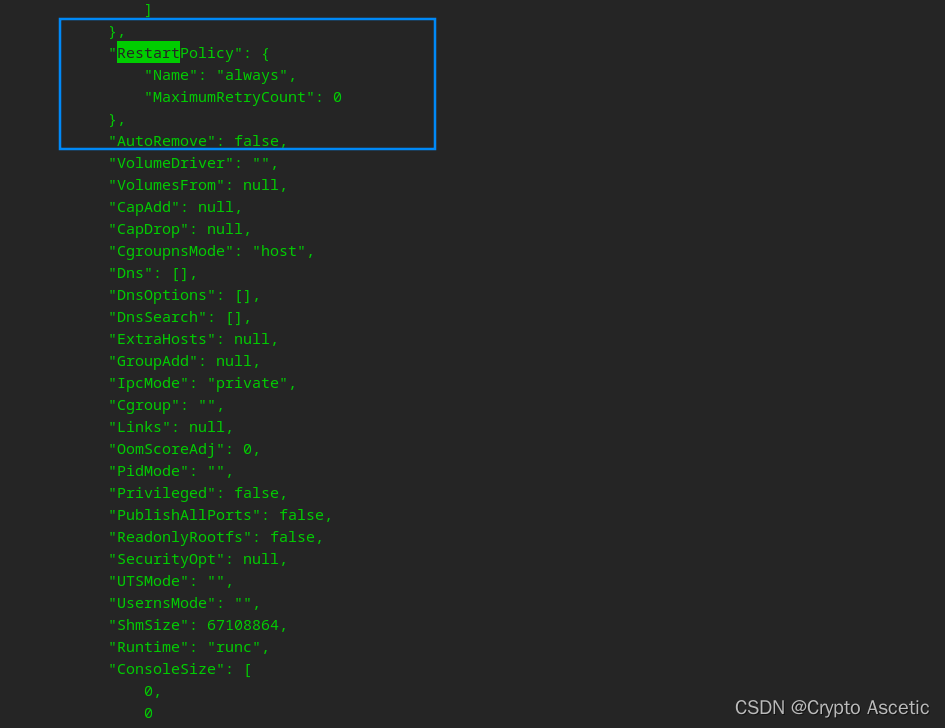
【Docker】已经创建好的Docker怎么设置开机自启
已经创建好的Docker怎么设置开机自启 1.使用命令Docker update来完成2.查看是否开启3.验证是否开启 1.使用命令Docker update来完成 操作步骤: docker update --restartalways 容器ID2.查看是否开启 docker inspect 容器Id看到这里RestartPolicy设置为如图&#…...

E - Excellent Views
Problem - E - Codeforces 问题描述:数组H大小都不相同。从i到j是可行的,当且仅当 不存在 k ,使 ∣ i − k ∣ ≤ ∣ i − j ∣ , H k > H j 不存在k,使 \\ |i - k| \leq |i - j|, \quad H_k > H_j 不存在k,使…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...