Flink_state 的优化与 remote_state 的探索
摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分:
- 相关背景
- state 压缩优化
- Remote state 探索
- 未来规划
点击查看原文视频 & 演讲PPT
一、相关背景
1.1 业务概况

- 从业务规模来讲,B 站目前大约是 4000+的 Flink 任务,其中 95%是 SQL 类型。
- 从部署模式来讲,B 站有 80%的部署是 on yarn application 部署,我们的 yarn 集群和离线的 yarn 是分开的,是实时专用的 yarn 集群。剩下的 20%作业,为了响应公司降本增效的号召,目前是在线集群混部。这个方案的采用主要是从成本考虑,目前在使用 yarn on docker。
从 state 使用情况来讲,平台默认开启的全部是 rocksdb statebackend,大概有 50%的任务都是带状态的,其中有上百个任务的状态超过了 500GB,这种任务我们称之为超大状态的 state 任务。
1.2 statebackend 痛点

主要痛点有 3 个:
-
cpu 抖动大。rocksdb 的原理决定了它一定会有一个 compaction 的操作。目前,在小状态下这种操作对任务本身没什么影响,但是在大状态下,尤其是超过 500GB 左右,compaction 会造成 cpu 抖动大,峰值资源要求高。尤其是在 5、10、15 分钟这种 checkpoint 的整数被间隔的情况下,整个 cpu 的起伏会比较高。对于一个任务来说,它的峰值资源要求会比较高。如果我们的资源满足不了峰值资源的需求,任务就会触发一阵阵的堆积和消积的情况。
-
恢复时间长。因为 rocksdb 是一个嵌入式的 DB 存储,每次重启或者任务的 rescale 状态恢复时间长。因为它要把很大的文件下载下来,然后再在本地进行一些重新的 reload,这就需要一些大量的扫描工作,所以会导致整个任务的状态恢复时间比较长。观察下来,正常来说大任务基本需要 5 分钟左右才能恢复平稳的状态。
-
rocksdb 非常依赖本地磁盘。rocksdb 是嵌入式的 DB,所以会非常依赖本地 io 的能力。由于今年公司有降本增效的策略,我们也会在线推荐一些混部,因为 Flink 的带状态任务有对本地 io 依赖的特点,对于混部来讲是没法用的,这就导致我们使用混部的资源是非常有限的。

主要通过两个方面解决这些痛点:
- 第一个是 state 压缩。出于对如何降低 compaction 开销的思考,对任务进行了一些 cpu 火焰图的分析。通过分析发现,整个 cpu 的消耗主要在 2 个方面,一个是 compaction,一个是压缩数据的换进换出,这就会带来大量的压缩和解压缩的工作。所以我们在压缩层做了一些工作。
- 第二个是基于云原生的部署。由于本地没有 io 能力,我们参考了一些云原生的方案,把整个本地的 rocksdb backend 进行了 Remote state 的升级。这相当于上面的一个存算分离,然后远程进行了服务化的操作。这样就可以实现即连即用,不需要进行 reload 的操作,整个 state 是基于远程化进行的。
二、state 压缩优化
2.1 业务场景
从业务场景角度来看,大 state 分析下来,它主要集中于模型训练和样本拼接。我们的商业化和 AI 推荐部门就是这种典型的应用场景。它的特点就是 key 数据量庞大,分布稀疏,很难命中 cache。且数据 ttl 短,基本都是小时级。
如下右图所示,整个业务的模型包含展现和点击。通过这两个动作我们进行了校验,然后完成计算,从而生成样本,再灌入模型进行训练。这个场景下它的特点是缓存失效就很快失效,它的 key 数量比较大且比较稀疏。
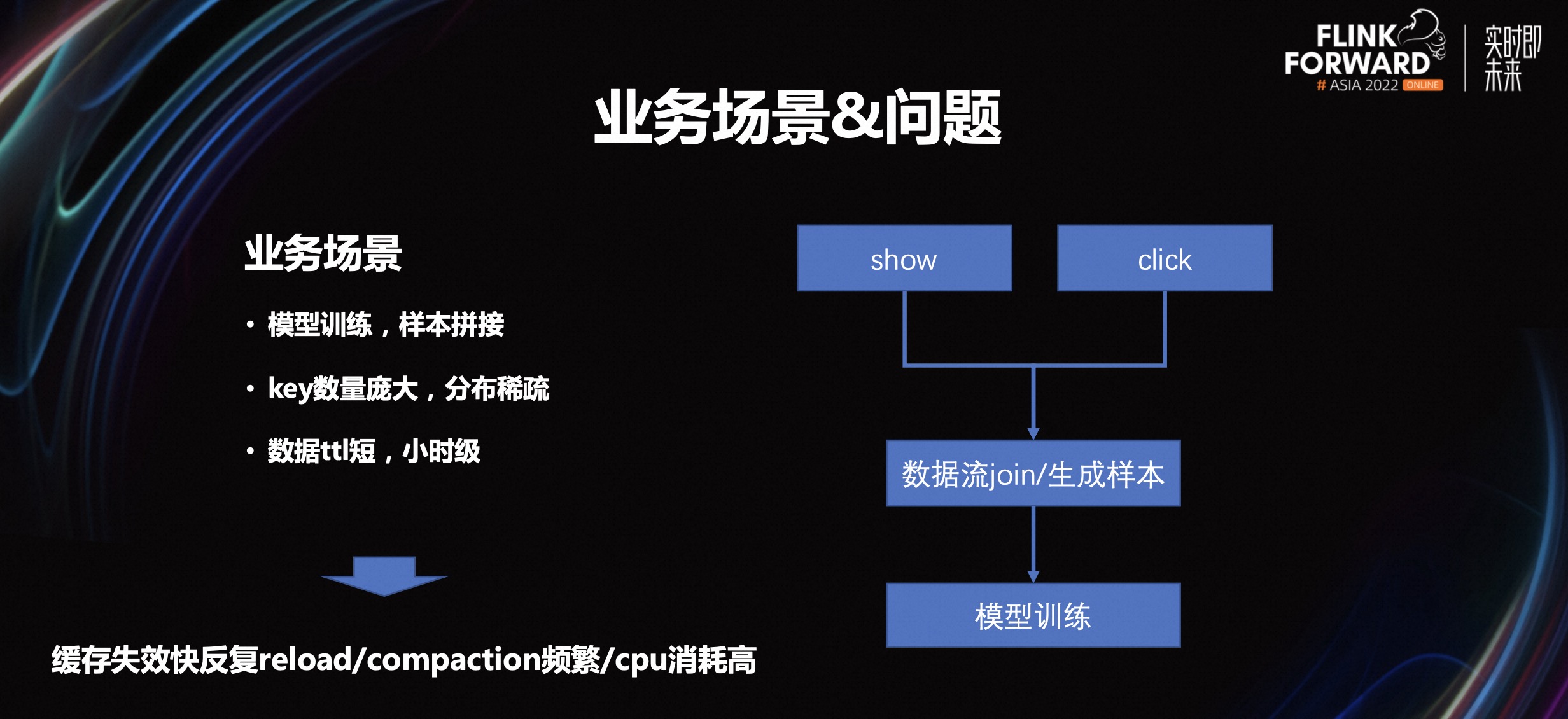
第二个点是数据的提交比较短,那么整个缓存的失效会比较快,这样就会导致 rocksdb 在使用的时候会反复从磁盘里不断地 reload 数据,然后进行压缩和解压缩,或者中间 compaction 数据不断地过期,导致 compaction 过于频繁。
2.2 优化思路

以上两个问题会导致整个 cpu 的消耗非常高,所以我们能观察到,在前面提及的整个任务的峰值 cpu 消耗会非常高。我们的优化思路是通过包括对社区的一些方案和业界其他公司分享的一些文章进行的调研,调研和优化方案主要围绕三个方面进行:
-
第一个是开启 partitoned index filter,减少缓存竞争。从火焰图中可以看到,data block 会不断地从 block cache 中被换进换出,同时产生大量的压缩和解压缩工作,大量的 cpu 其实消耗在这里。
-
第二个是关闭 rocksdb 压缩,减少缓存加载 /compaction 时候的 cpu 消耗。从火焰图中可以看到,整个 SSD 数据进行底层生成的时候,它会不断地进行整个文件的压缩和解压缩。所以我们的思路就是如何去关闭一些 rocksdb 压缩,减少整个缓存加载或者 cpu 的消耗。
-
第三个是支持接口层压缩,在数据 state 读写前后进行解压缩操作,减少 state 大小。如果关闭 rocksdb 底层的压缩,我们观察到整个磁盘的使用量非常高。这样的话,压力就是从压缩和解压缩的 cpu 消耗变成磁盘的 io 消耗,磁盘的 io 很容易就被消耗尽了。所以我们就把整个底层的压缩往上层进行了一个牵引,支持接口层的压缩。
在数据层写入读写前后进行压缩和解压缩的操作,减少底层的存储大小,我们也与内部的一些 DB 存储团队进行了一些沟通,他们一般建议在上层进行压缩,这样会比在底层做效率更高一些。因为底层整个是以 Block 维度进行压缩与解压缩的。
2.3 整体架构
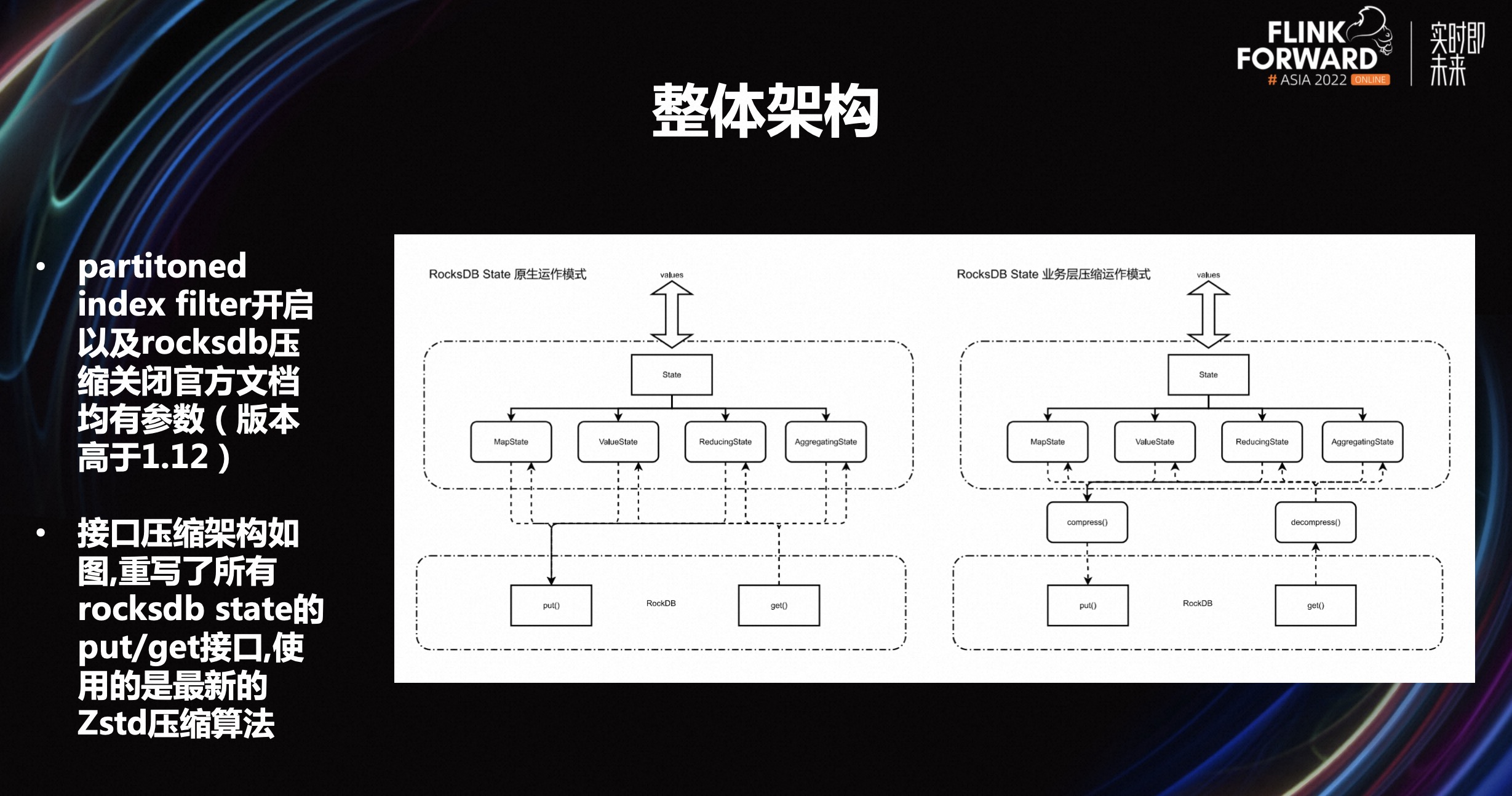
partitoned index filter 开启,B 站内部目前主要用的是 Flink 1.11 版本。当初我们大概调研到这个参数的时候,发现社区本身在 1.12 版本已经提升了这个功能,所以就直接把 1.12 版本相关的功能直接用过来了,同时 rocksdb 压缩关闭,官方文档均有参数,这个部分成本比较低。
第二个部分是支持业务的压缩。为了减少磁盘 io 的压力,在接口上做了一些压缩。接口压缩架构,如上图,重写了所有 rocksdb state 的 put/get 接口,使用的是最新的 Zstd 压缩算法。目前使用的是 LTZ 算法,比一些常用的压缩收益更高,cpu 的消耗比较小。
2.4 业务效果
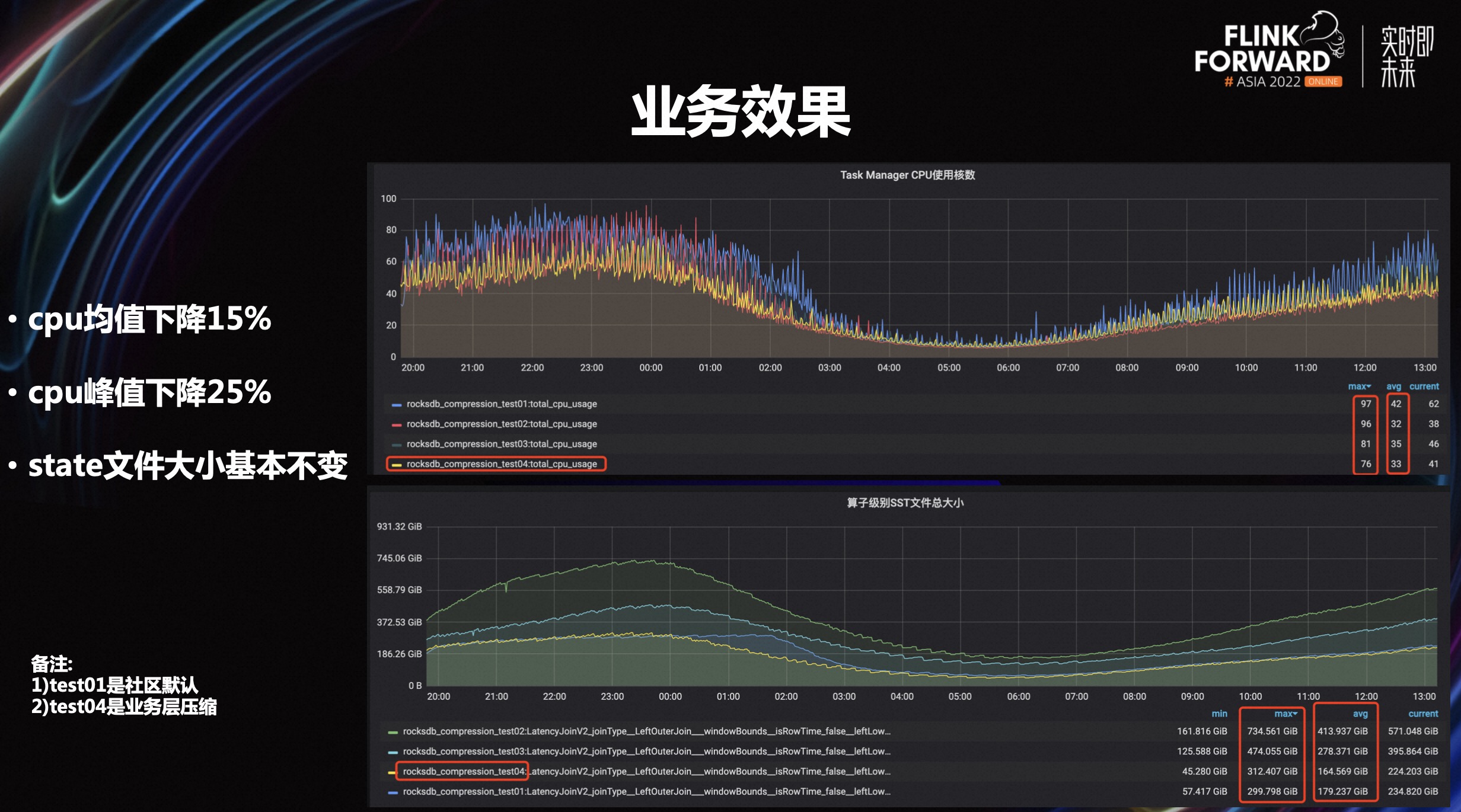
如上业务效果对比图,这里面包含 test 1、2、3、4,主要看看 test 0 和 test 4。test 0 是社区默认的方案,也就是底层用是 snappy 压缩,上层不做什么。test 4 是完全关闭了底层的压缩,无论是上层还是底层,整个压缩是全部关闭的,在业务层使用了最新的 STD 方法进行压缩。
整个观察下来,峰值和低峰期的数据都进行了查看,cpu 均值大概是下降到 15%左右,峰值大概下降到 25%,相信对毛刺的下降会更明显一些。另外,在业务层做完压缩之后,这个文件大小基本保持不变,或是只提升了一点点。这样一来,最底层的存储空间或者 io 其实完全没有增加任何压力。
目前来讲,线上所有新增的大的任务基本都已经全部开启了,老的任务也在进行一些推进。

最后补充下这个场景的适应性。因为整个方案是匹配到我们的推荐功能或是广告模型拼接场景来做的,所有的性能分析也是在这样的场景下进行的,结论是主要双流 join 的大 state 场景,小 state 场景下基本没有收益,主要原因是小 state 的模式下,cache 本身的命中率非常高,换进换出频率较低。另外,Liststate 暂时不支持业务层压缩,add 接口底层的特殊 merge 实现暂时无法做业务层压缩。
三、Remote state 探索
3.1 业务场景和问题
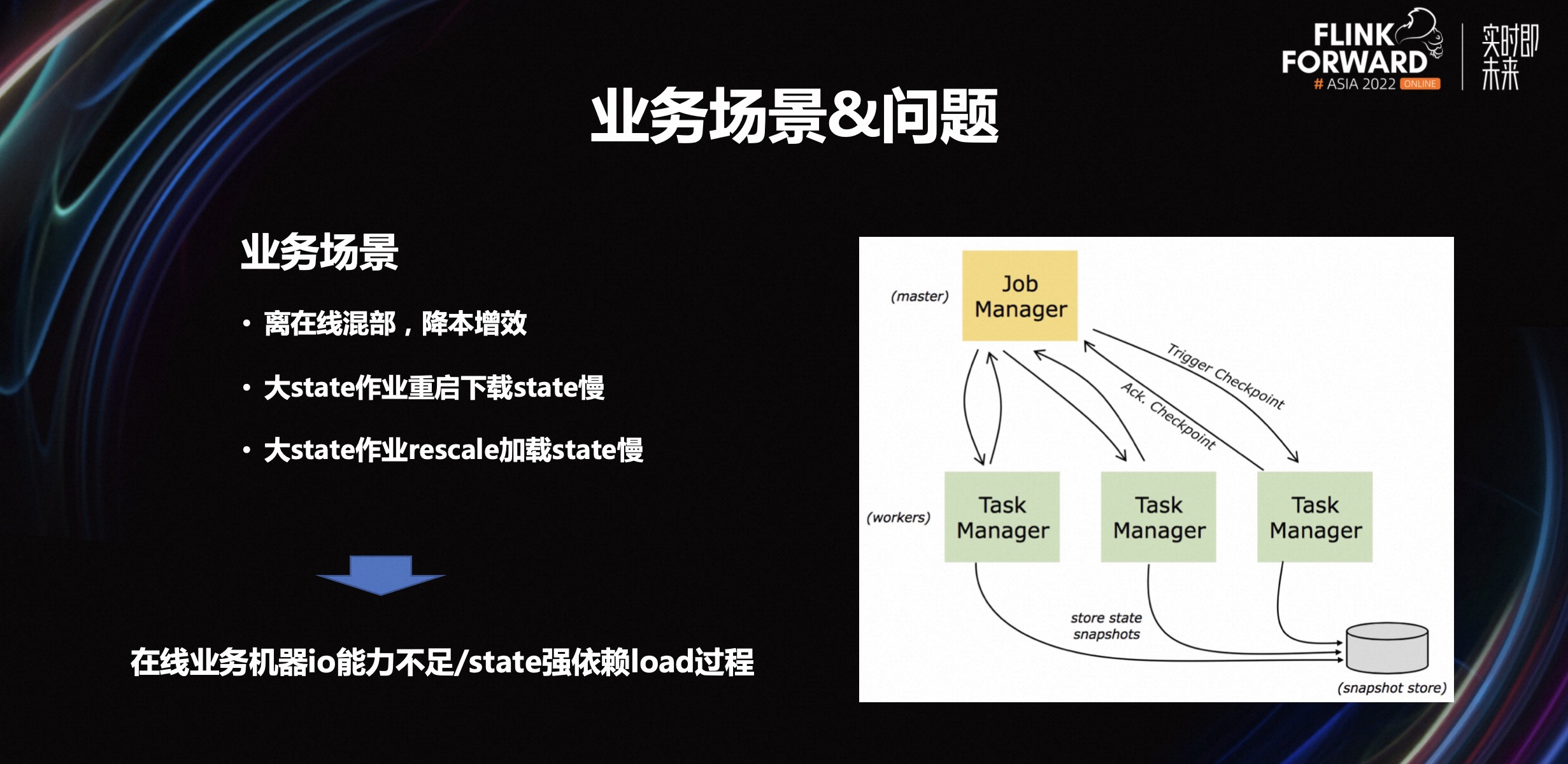
第一,降本增效。这是今年大部分互联网公司可能都在做的事情,B 站也不列外。我们在推一个离在线混部,主要是为了提升资源的使用效率。把 Flink 大数据的场景和在线服务的场景进行资源的混部。
第二,大 state 作业重启下载 state 慢。有些用户反应,对一些重启时间比较敏感的业务方,会觉得大状态下的重启对业务会有一些抖动,尤其在广告、AI 模型推荐等方面体验感不好。
第三,大 state 作业重启加载 state 慢。希望在重启或是扩容的时候,加载更快一些。这里包括两个业务场景,一个是离在线混部,第二个是用户的重启体验。这两个方面即使是用 rocksdb 来做都比较难。例如在线混部,因为在线的机器的磁盘基本是 100-200GB 的那种本地较小的磁板,同时 io 性能也不是很高,在这种情况下,将Flink大任务丢到在线混部上去,会对在线的机器负载压力比较大。这就造成在线混部上的任务是相对有限的。
其实用户很难区分到底哪些任务是可以丢到在线混部,哪些不能。这需要用户通过 state 来判断。另外, state 的慢导致用户体验比较差,主要是因为它重启的时候强依赖 load 过程,尤其是当遇到超过 500GB 的任务时候,这个体验感就会比较差。
3.2 优化思路

首先是实现 Flink state 的存算分离。如果进行混部,本地实际上没有磁盘,就很难给到在线的机器,在 Flink 上最直接的办法就是存算分离。存算分离不是陌生的概念,尤其是在云上。存储放在存储的机器上,按照存储的需求进行机型采购,计算同理。
其次是 state 远程化/服务化,重启 /rescale 直接建立连接进行读写。B 站的做法是把 Flink 的 state 进行存储的分离,这样就能解决在线的混部问题。分离之后,就可以进行远程化和服务化的部署,最终重启或是其他就能直接与远程服务进行连接。
第三是远程 state 服务需要支持 checkpoint 完整功能依赖的接口。这是正常开发流程中所依赖的,即远程服务。需要支持一个 checkpoint 的完整功能,主要对标的就是 rocksdb 的功能。
3.3 整体架构
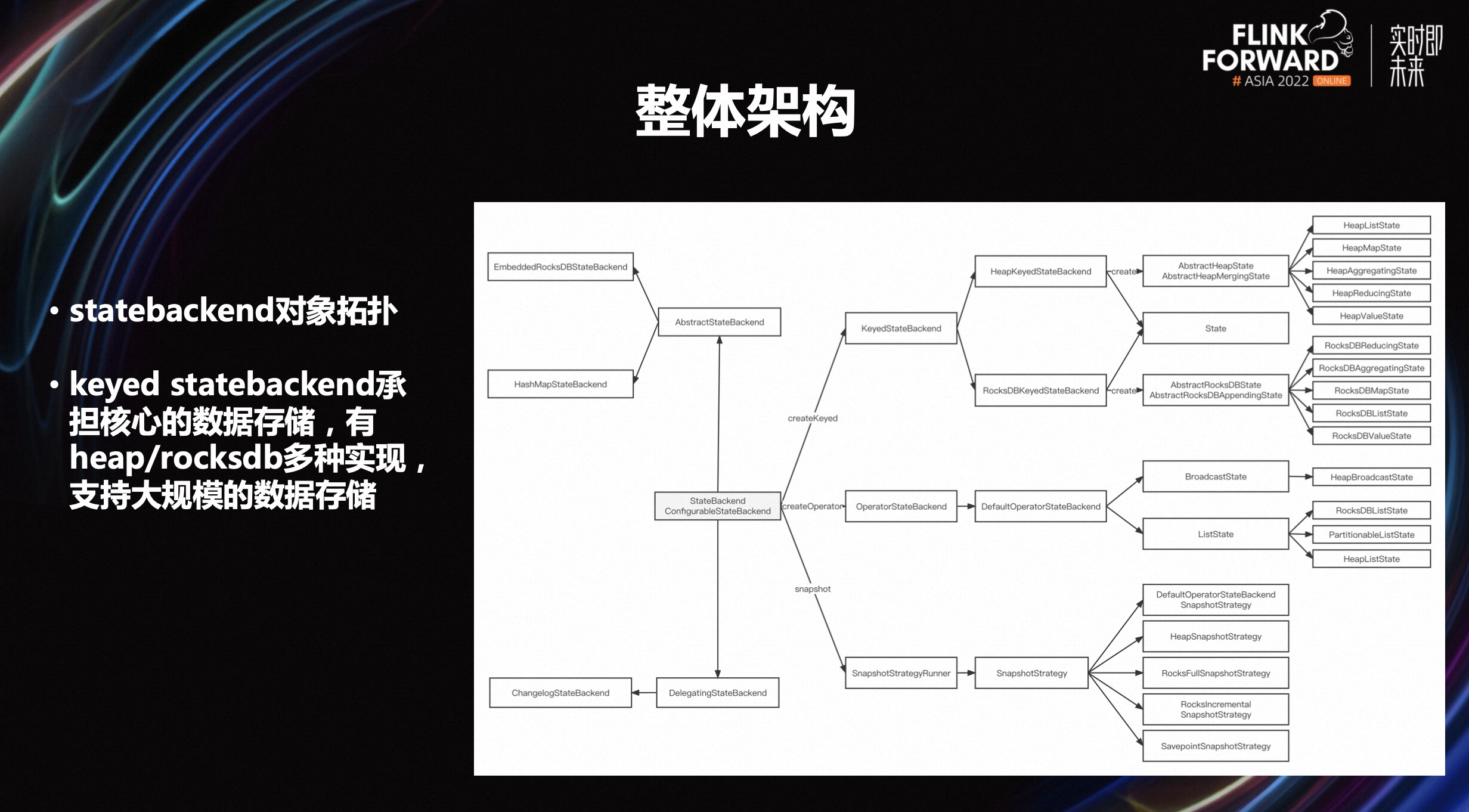
上图是 Flink state 整体的架构,也是 statebackend 对象拓扑,就是上图右侧。另外,Flink statebackend 的核心数据或是数据存储主要是由 keyed statebackend 承担,还有一部分是由 operator state 承担,这部分主要是存在内存里,并全量往远程刷,一般支持的数据不会特别大。
核心的大规模数据会存在 keyed statebackend 里。keyed statebackend 主要有 heap 和 rocksdb 两种实现,支持大规模额数据存储。
B 站主要使用的是 rocksdb 存储,主要围绕的核心是改进 keyed statebackend,因为 operator state 主要针对的是小规模数据,它不会占用本地 io,也不会在重启的时候产生大量的重复操作,速度相对来说要快很多。

上图是社区 keyed statebackend 的分配逻辑架构。如果想要把 keyed statebackend 做存算分离,需要了解:
-
Flink 的分片逻辑,它的底层有一个 keyed group 的概念。在所有状态在任务第一次启动的时候,底层分片就已经确定好了。这个分片大小就是 Flink 的最大并发度的值。这个最大并发度实际上是在任务第一次不从 checkpoint 启动时候算出来的。这中间如果一直从 checkpoint 启动,那么最大并发度永远不会变。
-
Flink checkpoint rescale 能力是有限的,本质是分片 key-group 在 subtask 之间的移动,分片无法分裂。一旦启动生成切换之后,这个分片的数量因为已经固定好了,后面不管怎么 rescale,本质是分片的移动,其实最大的变动是后面 rescale 不能超过整个分片的数量,这个数量对应的是分片最大的并发度。
-
多个 key-group 存储在相同 rocksdb 的 cf 里面,以 key-group 的 ID 作为 key 的 prefix,依赖 rocksdb 的排序特性,rescale 过程通过 prefix 进行定位遍历提取。
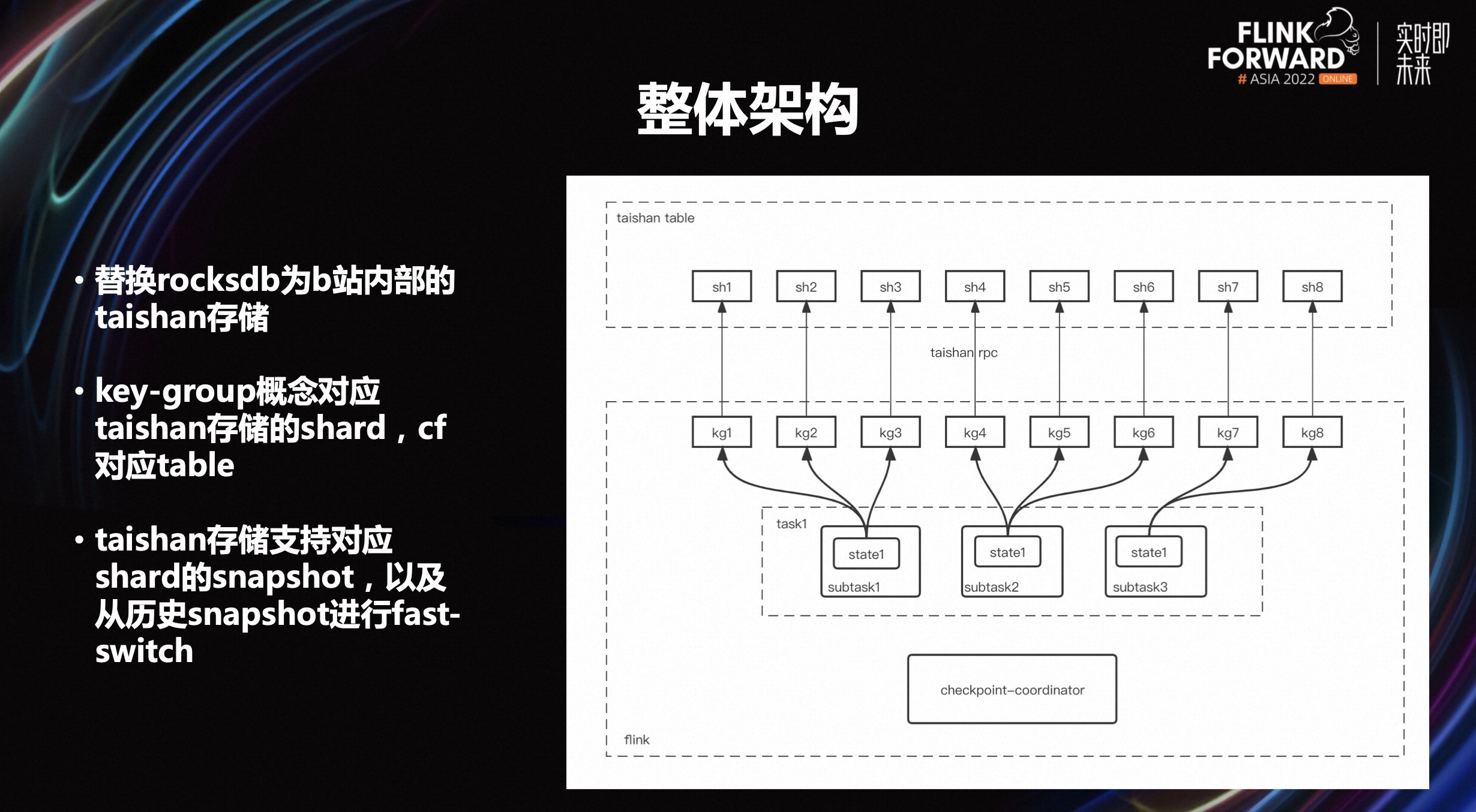
上图是 Remote state 整体架构,主要的核心工作有三点:
-
替换 rocksdb 为 B 站内部的 taishan 存储。Taishan 存储底层是分布式结构,Flink 的一些概念是可以对应到 taishan 存储上的。
-
key-group 概念对应 taishan 存储的 shard,cf 对应 table。key-group 的概念就可以对应上 taishan 存储,同时里面 cf 的概念也对应 taishan 存储中的一个 table 概念,也支持一个 table 里面可以有多个 key-group。
-
Taishan 存储支持对应 shard 的 snapshot,以及从历史的 snapshot 进行快速切换。比如重启的时候可以从老的 checkpoint 进行回复,实际上能够调用 taishan 存储这样一套接口进行快速 snapshot 切换,并可以指定对应的 snapshot 并进行加载,加载的速度非常快,基本是秒级左右。
3.4 缓存架构
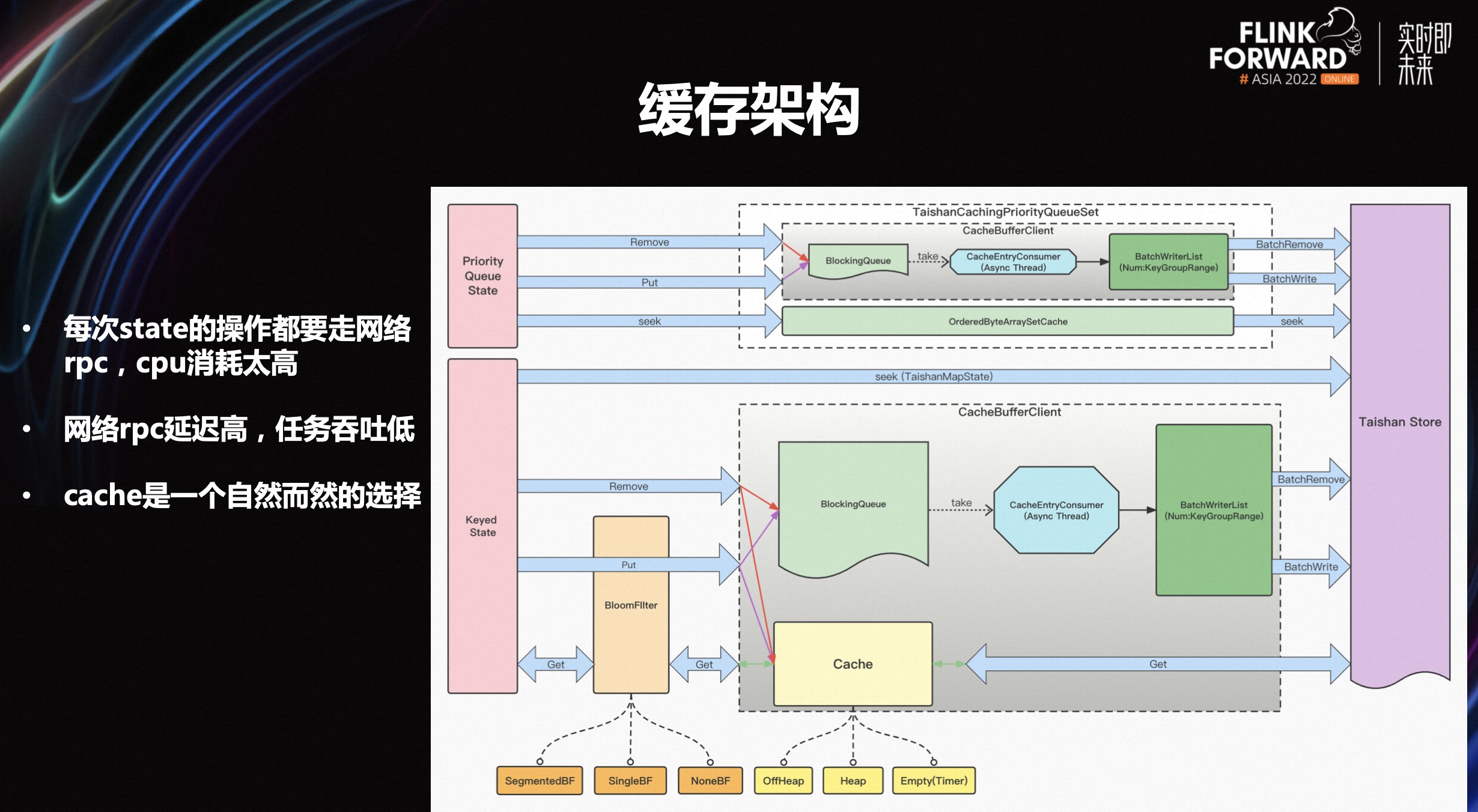
在上文介绍的基础上可以观察到,开发完之后实际上整个功能来说是完全够用的,但也发现了一些比较严重的性能问题:
-
每次 state 操作都需要走网络 rpc, cpu 的消耗太高
-
网络 rpc 的延迟高,任务吞吐低
- cache 是一个自然而然的选择
3.5 缓存难点
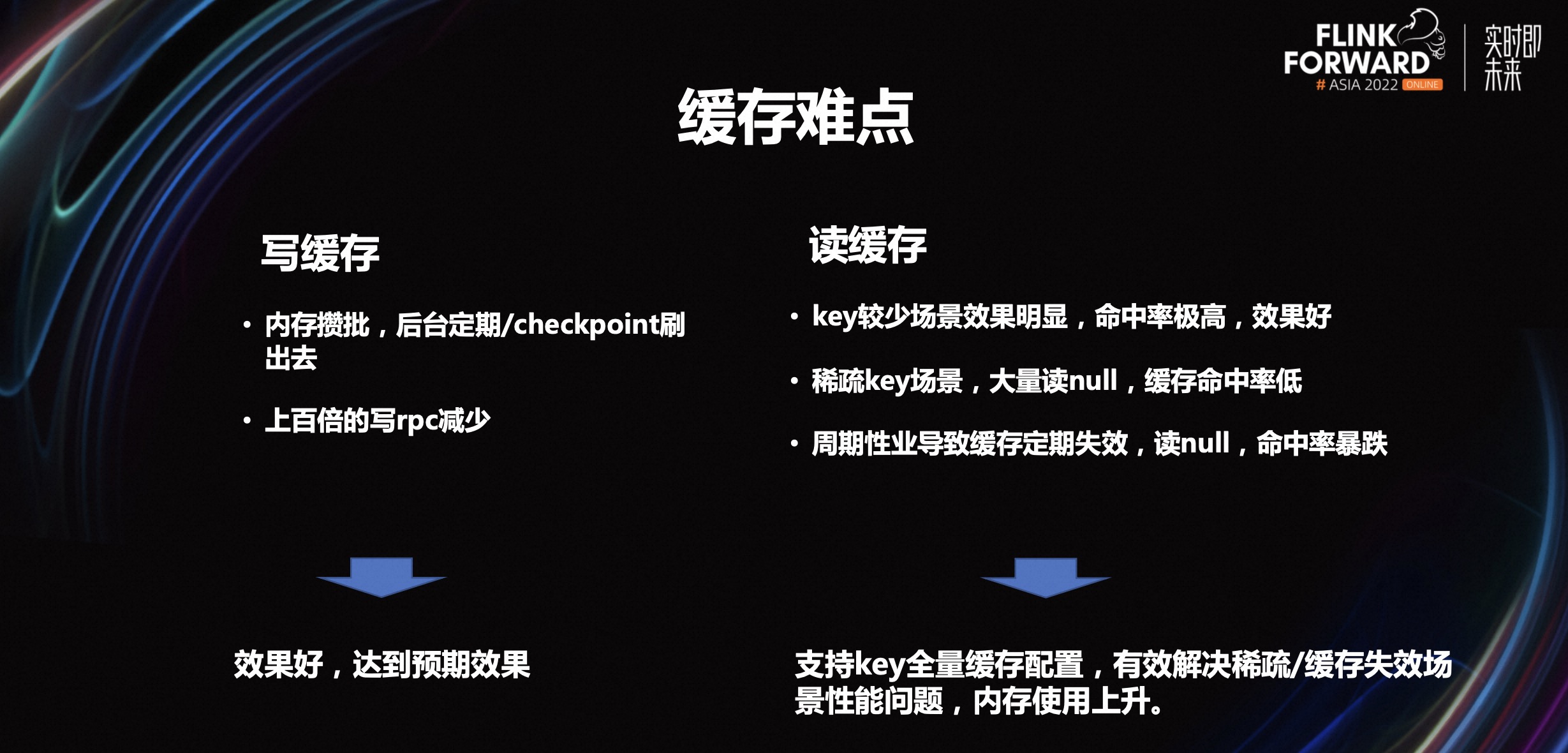
写缓存相对来讲是比较简单,内存攒批,后台定期 checkpoint 刷出去就可以上百倍的减少写的 rpc。
读缓存是比较难的。读缓存是把场景进行拆分来看:
-
key 比较少的场景效果明显,命中率极高,效果好,甚至达到几百上千倍的效果提升。
-
稀疏的 key 场景,大量读 null,缓存命中率低。这个场景是当下比较大的难点。
-
周期性业务导致缓存定期失效,读 null,命中率暴跌。周期性业务到周期末节点,就会触发一个缓存失效,一旦跨过这个节点,缓存里就会变成新的数据。如果正巧遇上读 null,命中率就会很低,甚至导致任务抖动。这也是比较大的难点。
基于以上的问题,优化方案是支持 key 全量缓存配置,有效解决稀疏/缓存失效场景性能问题,使内存使用上升。但是这个优化缺点也比较明显,即对内存的要求会高些。因为所有的 key 都要存在一个缓存里,而这个缓存就是内存。
除了以上介绍的两点难点,其实还有另外两个难点。其一是冷启动,因为缓存不会进行持久化,那么当任务重启等状态下,其实重启之后缓存内是空的,那么也就会造成重启的时候,读和写的请求量都很大,会给性能造成压力。
另外,全量 key 的缓存,启动的时候也没法立即使用,需要等一个ttl周期,这样才能可以保证后面的全量 key 缓存是真正的全量 key。
3.6 off-heap 缓存模型图
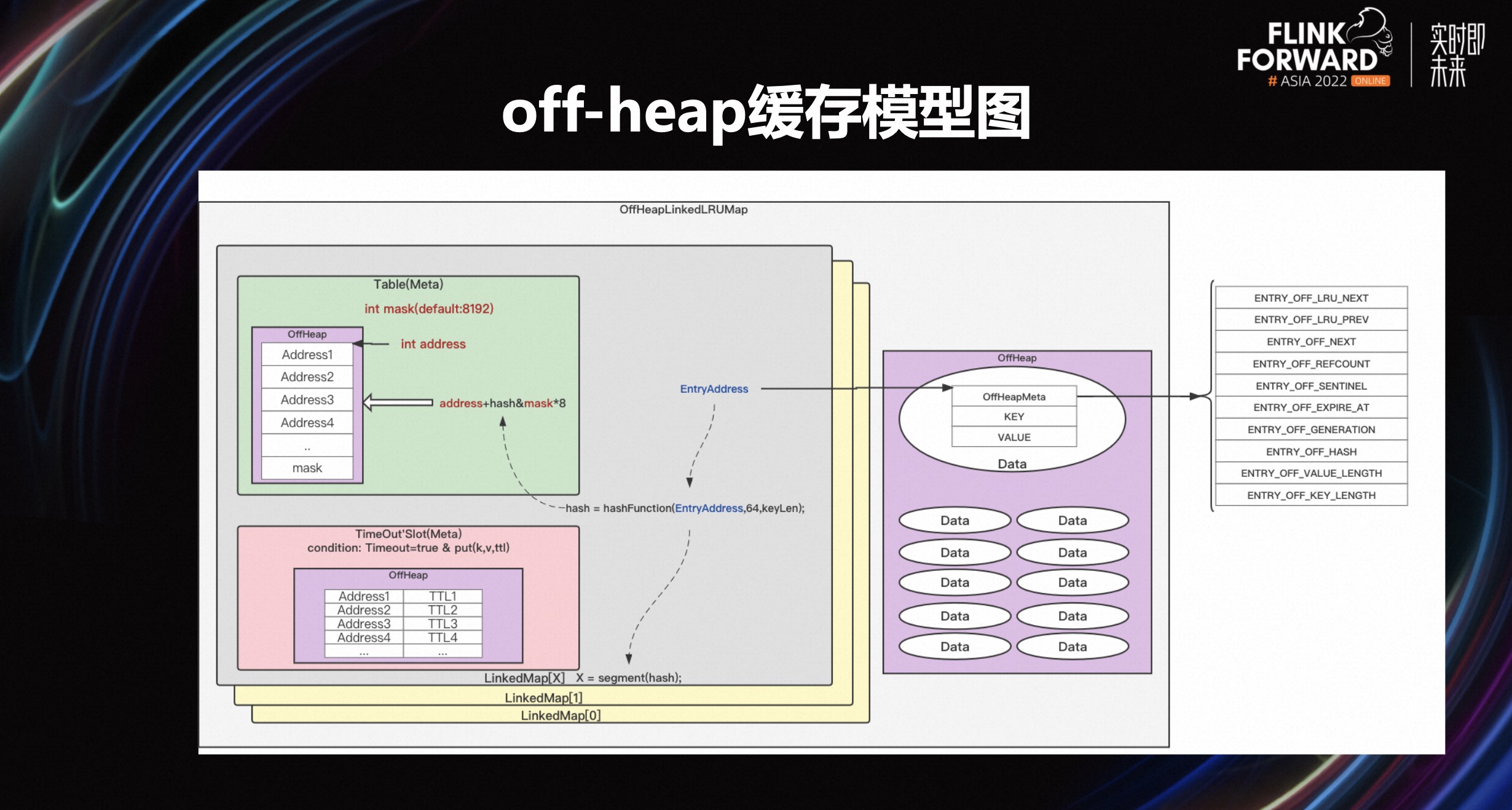
上图是 off-heap 缓存模型,我们使用的是 Facebook 的 OHC(off-heap cache)。可以观察到,基于 ttl 的主动淘汰,它带来的性能消耗相对来讲会比较大。但是如果完全关掉基于ttl的淘汰机制,在某些特殊场景,基于 io 淘汰机制,也会消耗比较大的空间。因为 io 淘汰的时候会进行判断哪个 key 可以真的被淘汰。如果完全通过 io 淘汰,在有些场景下面可能判定了很多 key,这些 key 都无法满足一个 io 的淘汰条件,那么这个淘汰流程就会很长,会导致接口卡的时间会比较久。所以在这里 B 站进行了调优,既保留了一个主动淘汰的思路,也依赖 io 这样一个淘汰机制。
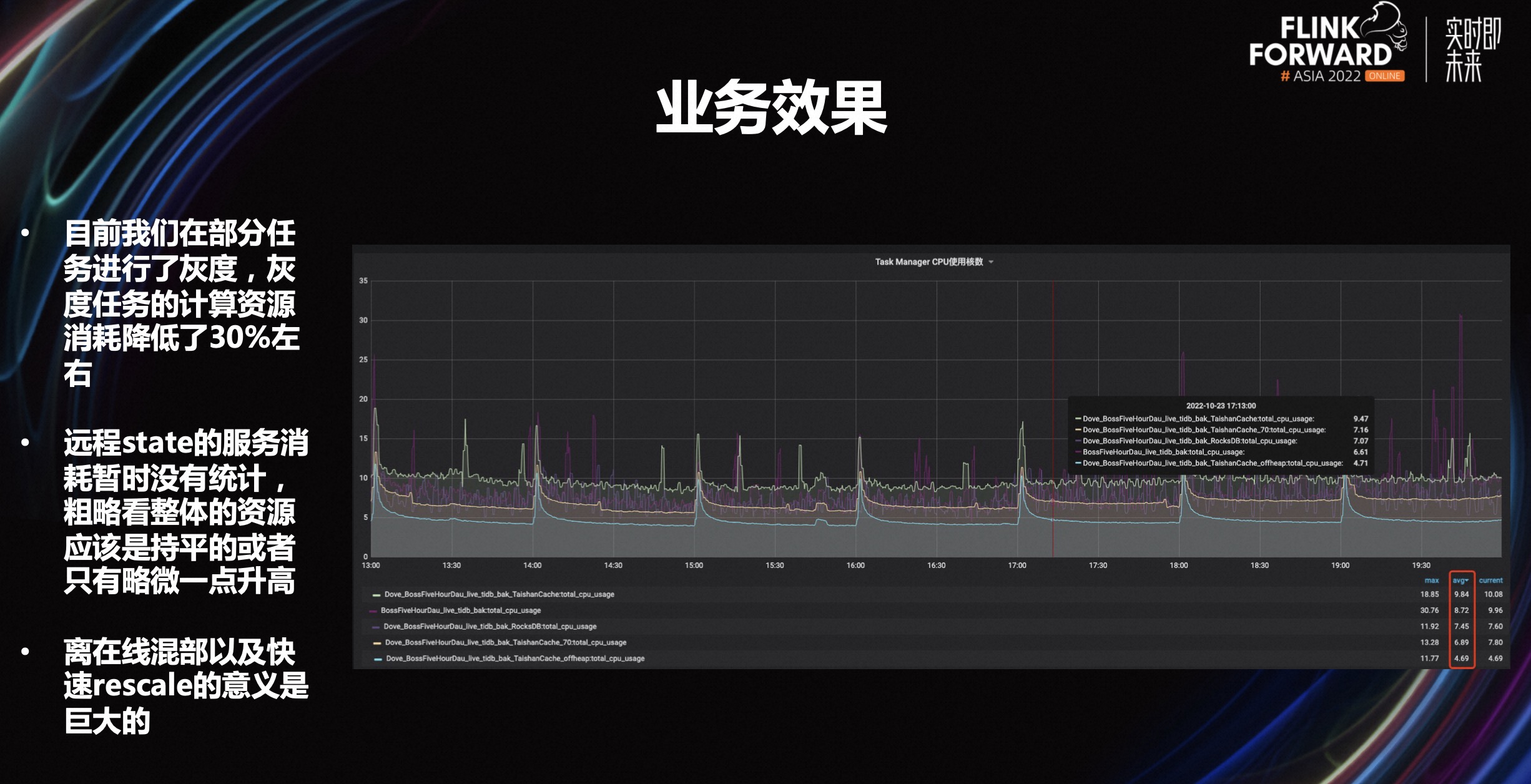
目前来讲,我们已经完成针对部分任务的灰度,灰度任务的计算资源消耗降低了 30%左右。远程 state 的服务消耗暂时没有统计,粗略看整体的资源应该是持平或是只有略微一点升高。离在线混部以及快速 rescale 的意义是巨大的。Flink 侧可以实现存算分离的效果,同时,这也能够做快速的重启而不需要进行状态的重新下载、重新加载或是 reload 的过程。
四、未来规划

点击查看原文视频 & 演讲PPT
相关文章:
Flink_state 的优化与 remote_state 的探索
摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分: 相关背景state 压缩优化Remote state 探索未来规划 点击查看原文视频 & 演讲PPT 一、相关背景 1.1 业务概况 从…...

Kdab QML (part9)自由缩放时钟
文章目录 Kdab QML (part9)自由缩放时钟代码详细解释运行截图 Kdab QML (part9)自由缩放时钟 代码 import QtQuick 2.15 import QtQuick.Window 2.15Window {id: rootwidth: 500height: 500visible: truecolor: "lightgrey"title: qsTr("Hello World")It…...
Java网络编程(二)经典案例[粘包拆包]
粘包拆包 概述 TCP是面向流的协议,TCP在网络上传输的数据就是一连串的数据,完全没有分界线。 TCP协议的底层并不了解上层业务的具体定义,它会根据TCP缓冲区的实际情况进行包的划分。 在业务层面认为一个完整的包可能会被TCP拆分成多个小包进行发送,也可能把多个小的包封装成一…...

无分布式锁的ID生成
起因 TEAM GARDEN 本来ID是自增的,后面发现自增ID比较麻烦,有问题: 不可控的间隔: 如果你在插入数据时,中途删除了一些行,导致自增的ID出现间隔,那么新插入的行会填充这些间隔,可能…...

X2000 Linux UVC
参考文档:\doc\开发使用说明\USB使用说明文档\设备\USB_UVC\xburst2\USB_UVC.pdf 一、内核添加USB UVC功能 1、确定所用dts文件 进入到/tools/iconfigtool/IConfigToolApp/路径下,执行./IConfigTool 选择config文件,查看kernel默认配置 配…...
HCIP-OpenStack组件之neutron
neutron(ovs、ovn) OVS OVS(Open vSwitch)是虚拟交换机,遵循SDN(Software Defined Network,软件定义网络)架构来管理的。 OVS介绍参考:https://mp.weixin.qq.com/s?__bizMzAwMDQyOTcwOA&mid2247485088&idx1…...
)
数学建模-常见算法(3)
KMP算法(Knuth-Morris-Pratt算法) KMP算法是一种用于字符串匹配的算法,它的时间复杂度为O(mn)。该算法的核心思想是在匹配失败时,利用已经匹配的信息,减少下一次匹配的起始位置。 def kmp(text, pattern): n len(…...
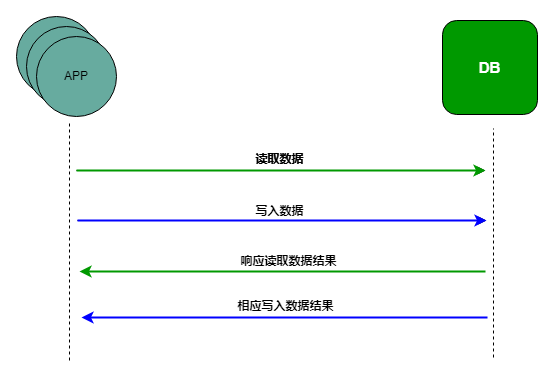
缓存的设计方式
问题情况: 当有大量的请求到内部系统时,若每一个请求都需要我们操作数据库,例如查询操作,那么对于那种数据基本不怎么变动的数据来说,每一次都去数据库里面查询,是很消耗我们的性能 尤其是对于在海量数据…...
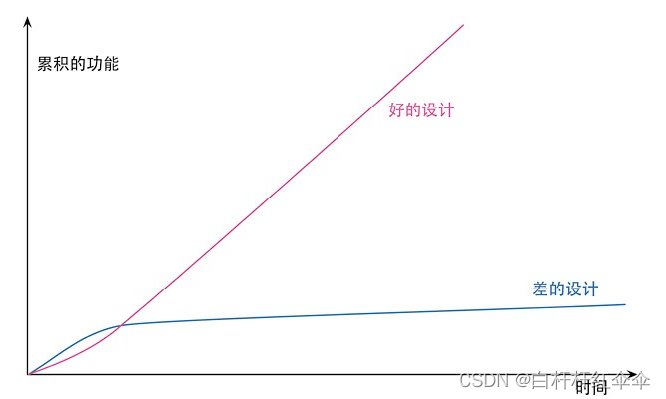
CH02_重构的原则(什么是重构、为什么重构、何时重构)
什么是重构 重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。 重构(动词):使用一系列重构手法࿰…...
)
26. 删除有序数组中的重复项(简单系列)
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素的数量为 k ,你需要做…...
【linux】基本指令(二)【man、echo、cat、cp】
目录 一、man指令二、echo指令三、cat指令二、cp指令一些常见快捷键 一、man指令 Linux的命令有很多参数,我们不可能全记住,可以通过查看联机手册获取帮助。访问Linux手册页的命令是 man 语法: man [选项] 命令 常用选项 1.-k 根据关键字搜索联机帮助 2…...

【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享...
全文下载链接:http://tecdat.cn/?p23544 在本文中,长短期记忆网络——通常称为“LSTM”——是一种特殊的RNN递归神经网络,能够学习长期依赖关系(点击文末“阅读原文”获取完整代码数据)。 本文使用降雨量数据…...
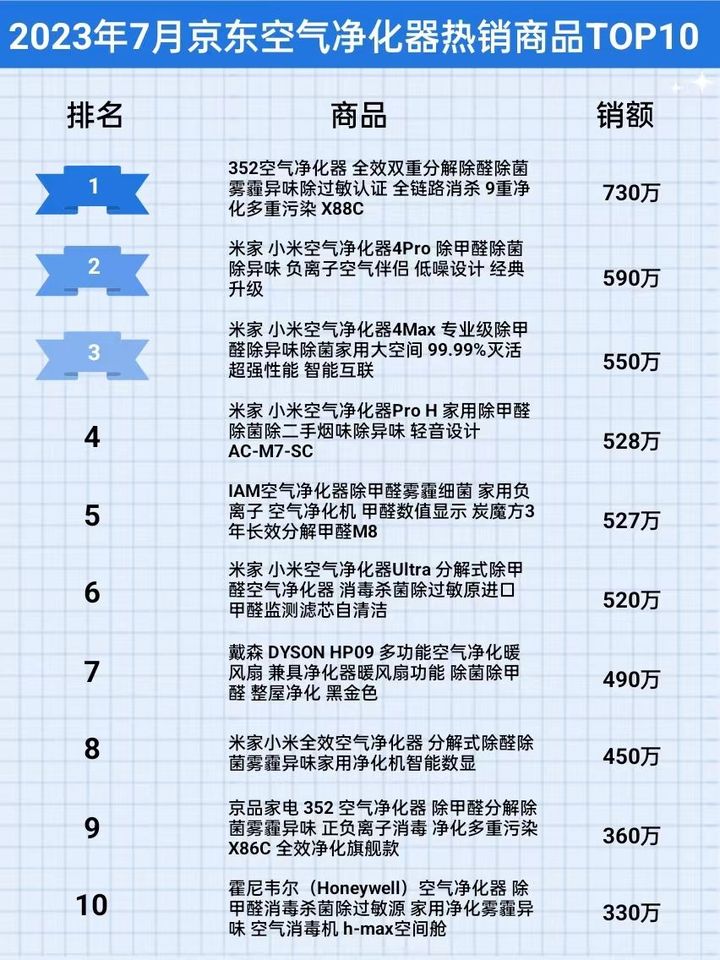
2023年7月京东空气净化器行业品牌销售排行榜(京东运营数据分析)
随着科技发展,智能家具在日常生活中出现的频率越来越高,许多曾经不被关注的家电也出现在其中,包括近年来逐渐兴起的空气净化器。伴随人们对自身健康的重视度越来越高,作为能够杀灭空气污染物、有效提高空气清洁度的产品࿰…...
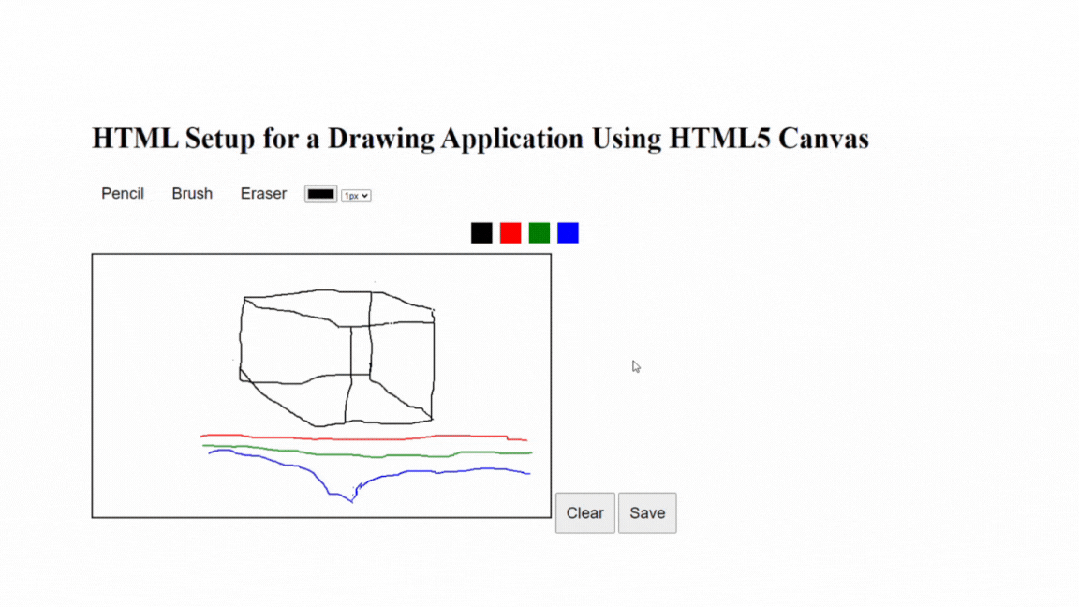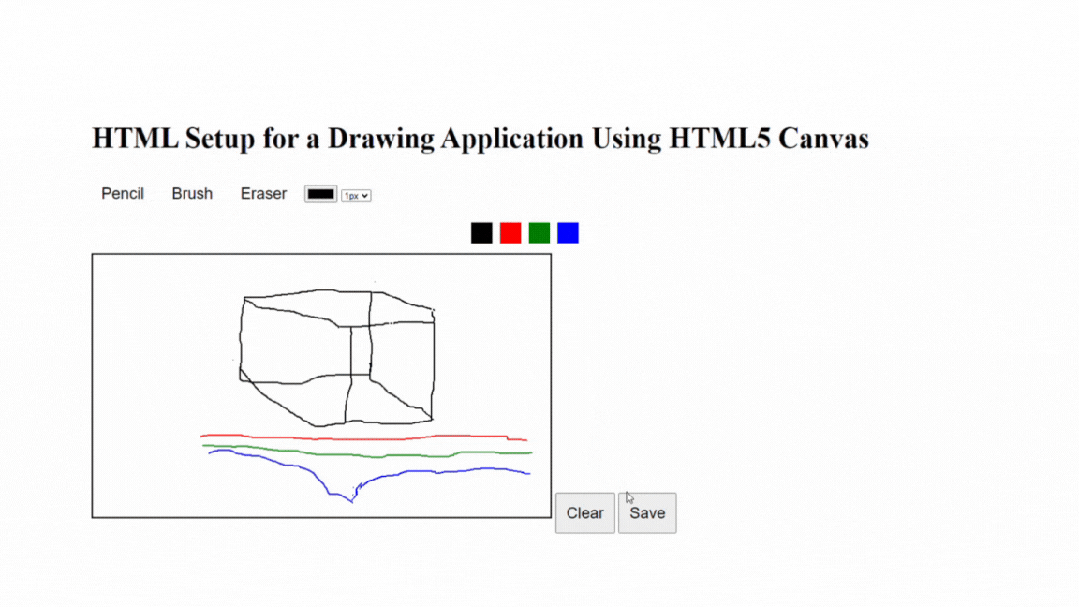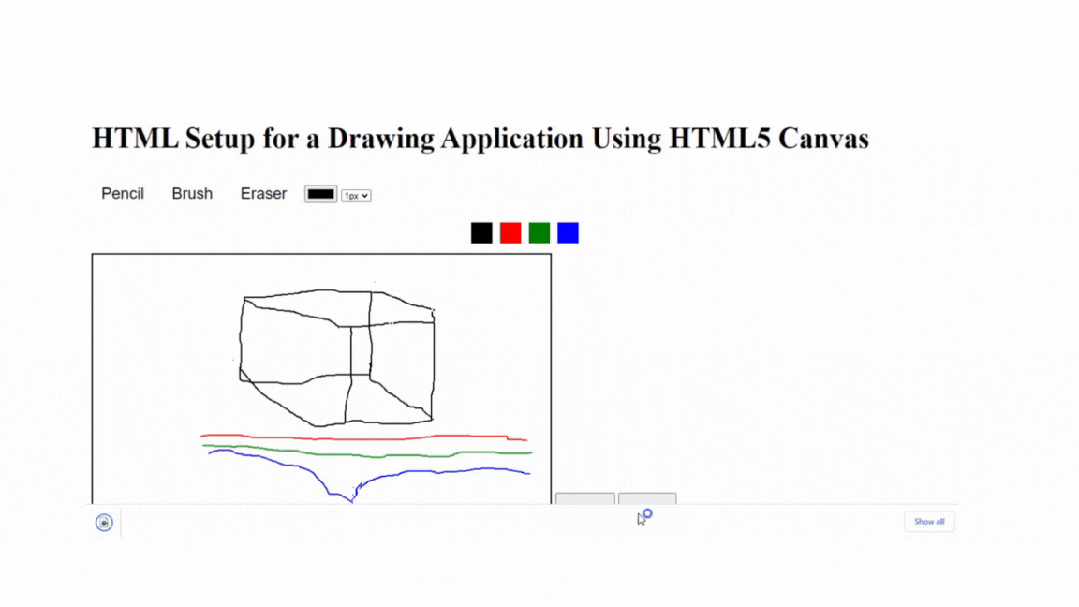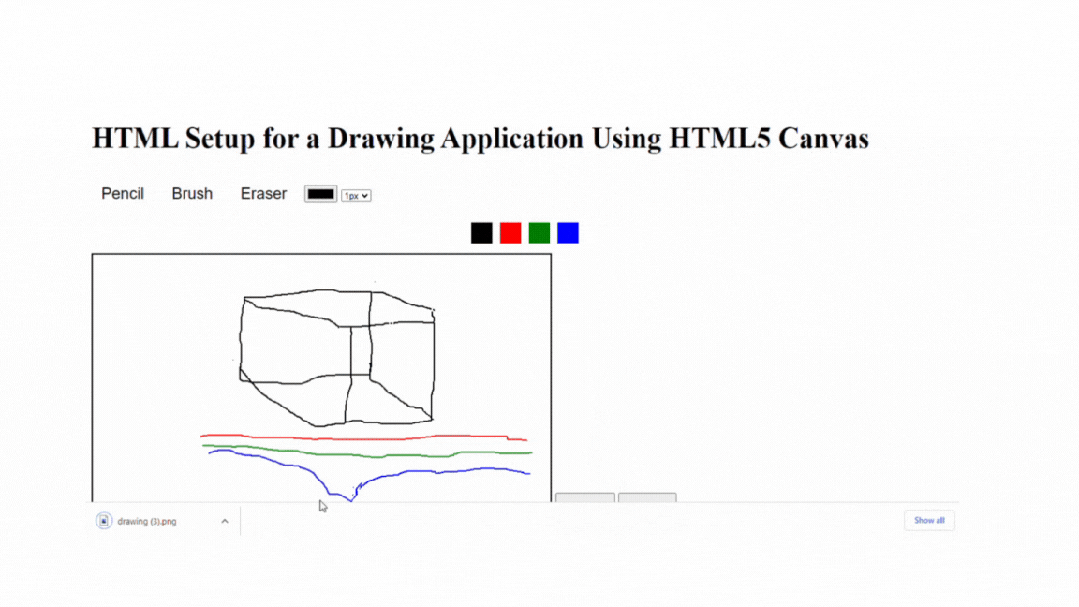
原生小案例:如何使用HTML5 Canvas构建画板应用程序
使用HTML5 Canvas构建绘图应用是在Web浏览器中创建交互式和动态绘图体验的绝佳方式。HTML5 Canvas元素提供了一个绘图表面,允许您操作像素并以编程方式创建各种形状和图形。本文将为您提供使用HTML5 Canvas创建绘图应用的概述和指导。此外,它还将通过解释…...
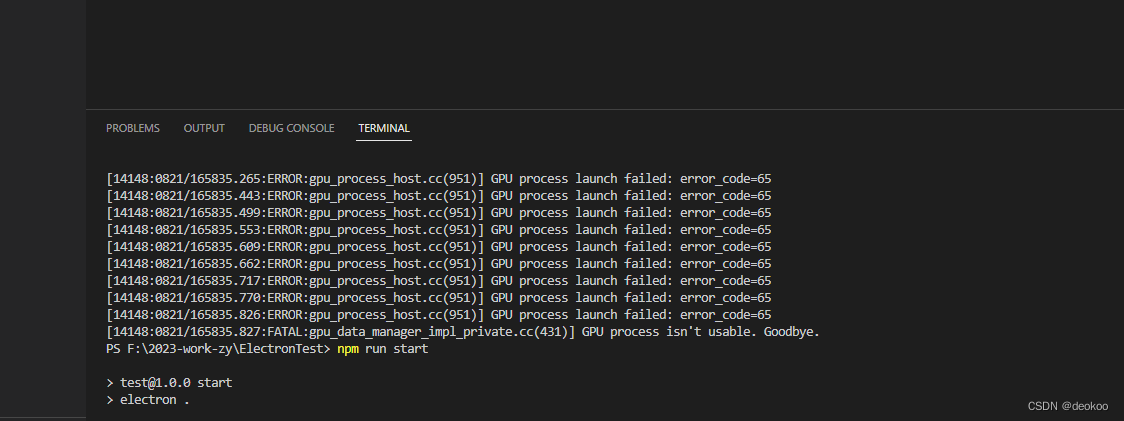
Electron 报gpu_process_host.cc(951)] GPU process launch faile错误
解决方法,在入口js文件中,添加如下代码: app.commandLine.appendSwitch(no-sandbox)...

每天一分享#读up有感#
不知道开头怎么写,想了一下,要不,就这样吧,开头也就写完 今日分享 分享一博主的分享——https://blog.csdn.net/zhangay1998/article/details/121736687 全程高能,大佬就diao,一鸣惊人、才能卓越、名扬四…...

threejs贴图系列(一)canvas贴图
threejs不仅支持各种texture的导入生成贴图,还可以利用canvas绘制图片作为贴图。这就用到了CanvasTexture,它接受一个canas对象。只要我们绘制好canvas,就可以作为贴图了。这里我们利用一张图片来实现这个效果。 基础代码: impo…...
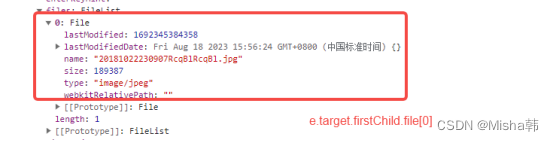
taro react/vue h5 中的上传input onchange 值得区别
<inputclassNamebase-input-file-h5typefileacceptimage/*capturecameraonChange{onChangeInput} />1、taro3react 2、taro3vue3...
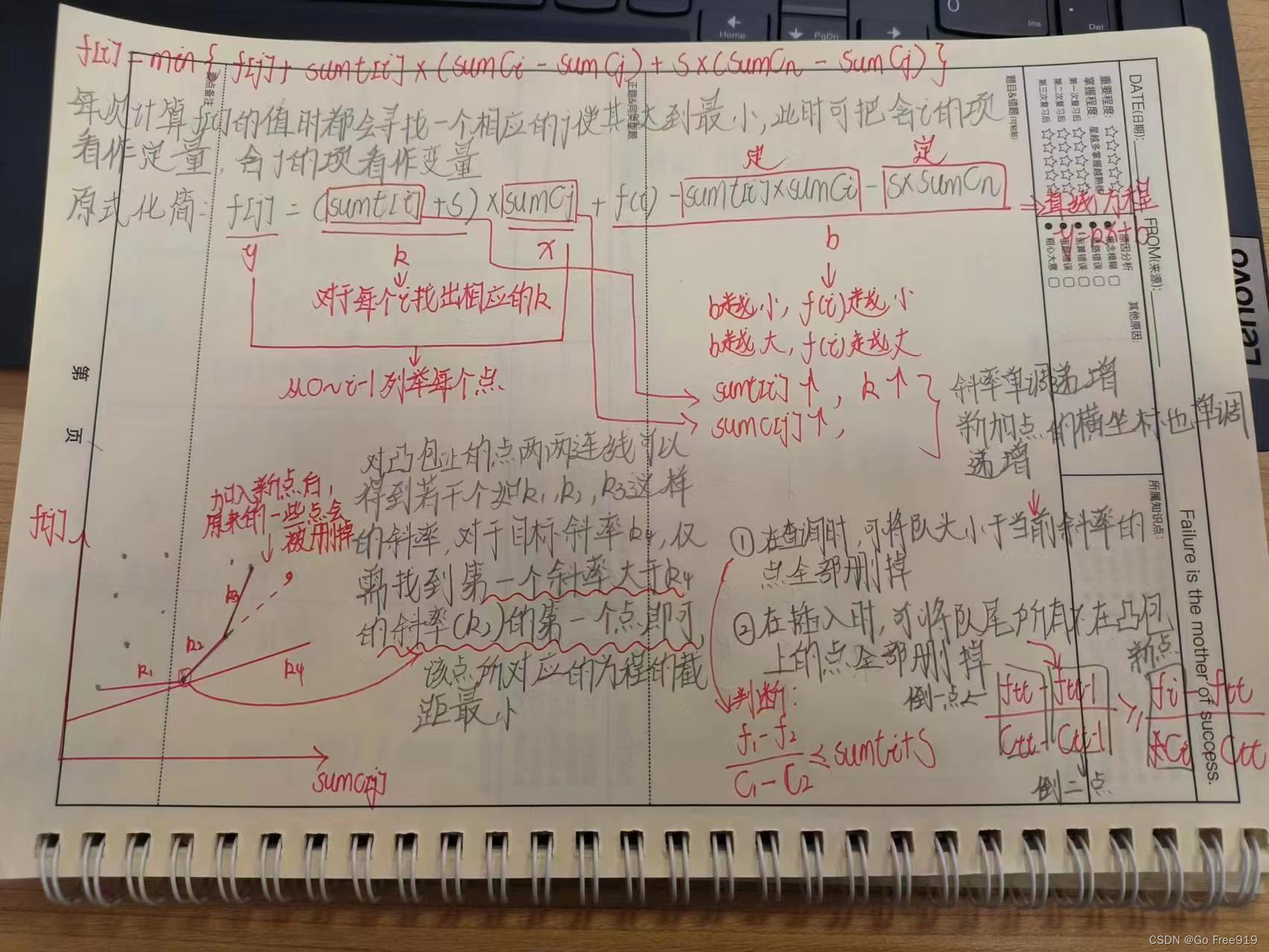
(AcWing) 任务安排(I,II,III)
任务安排I: 有 N 个任务排成一个序列在一台机器上等待执行,它们的顺序不得改变。 机器会把这 N 个任务分成若干批,每一批包含连续的若干个任务。 从时刻 0 开始,任务被分批加工,执行第 i 个任务所需的时间是 Ti。 另外&#x…...

Excel筛选后复制粘贴不连续问题的解决
一直以来都没好好正视这个问题认真寻求解决办法 终于还是被需求逼出来了,懒人拯救世界[doge] 一共找到两个方法,个人比较喜欢第二种,用起来很方便 Way1:CtrlG定位可见单元格后使用vlookup解决(感觉不定位直接公式向下…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...