kafka--技术文档--架构体系

架构体系
Kafka的架构体系包括以下几个部分:
- Producer. 消息生产者,就是向Kafka broker发送消息的客户端。
- Broker. 一台Kafka服务器就是一个Broker。一个集群由多个Broker组成。一个Broker可以容纳多个Topic。
- Topic. 可以理解为一个队列,一个Topic又分为一个或多个Partition。
- Partition. 为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,每个Partition是一个有序的队列。Partition中的每条消息都会被分配一个有序的id(offset)。
- Consumer. 消息消费者,向Kafka broker取消息的客户端。
- Zookeeper. Kafka依赖Zookeeper管理集群的配置和消费者的消费情况。
此外,Kafka还有一个非常重要的概念是“Consumer Group”,这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给任意一个Consumer)的手段。一个Topic可以有多个Consumer Group。
结构解读
Kafka的结构可以解读为以下四个主要部分:
- Producer:这是生成消息的客户端应用程序。它负责将消息发布到指定的Topic中。在发送消息时,Producer可以选择将消息发送到特定的Partition,或者让Kafka自动选择Partition。为了提高性能和吞吐量,Producer通常会缓存消息并进行批量发送。
- Broker:这是Kafka集群中的一个节点,每个节点都是一个独立的Kafka服务器。Broker负责存储和处理发布到Kafka的消息。每个Broker可以承载多个Topic的Partition,并使用日志文件(log)来持久化存储消息。
- Topic:可以理解为一个队列,是消息的分类单元。一个Topic又分为一个或多个Partition,每个Partition在不同的Broker节点上进行存储。Topic的数据以一系列有序的消息进行组织。
- Partition:为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,每个Partition是一个有序的队列。Partition中的每条消息都会被分配一个有序的id(offset)。
此外,Kafka的架构还包括Consumer和Zookeeper两个组件。Consumer可以从Kafka订阅并接收消息,而Zookeeper则用于管理和协调整个Kafka集群。Zookeeper保存了Broker的元数据、Topic的配置信息和Consumer的消费情况等信息,并用于进行Leader选举、分区分配和故障恢复等操作。
核心组件
Kafka的核心组件包括:
- Producer:负责将消息发布到Kafka的Topic中。
- Broker:Kafka集群中的一个节点,负责存储和处理发布到Kafka的消息。
- Topic:消息的分类单元,由一个或多个Partition组成。
- Partition:存储Topic中的数据,是一个有序的队列。
此外,Kafka的架构还包括Consumer和Zookeeper两个组件,但它们不是Kafka的核心组件
kafka工作原理
Kafka的工作原理如下:
- 消息发布者将消息发送到Kafka的消息中心(broker)中,然后由订阅者从中心中读取消息。
- Kafka将消息以topic的方式进行组织和管理,一个topic包含多个分区(partition),每个分区可以理解为一个独立的日志文件。
- 消息保留在分区中,分区中的消息有序排列,每个分区中的消息都有一个唯一的偏移量。
- Kafka的集群成员之间的关系是通过Zookeeper进行维护的,每个broker都有自己的唯一标识,broker启动时通过创建临时节点把自己的ID注册到Zookeeper上,然后Kafka组件订阅Zookeeper中的/brokers/ids路径,当加入或退出集群时,组件会得到通知。
- 控制器是一个broker,除了具有一般broker的功能之外,还负责分区首领的选举。集群中第一个启动的broker通过在Zookeeper中创建一个临时节点(/controller)让自己成为控制器。
Kafka的这些组件和工作原理使得它能够实现高吞吐量、可扩展、高可用性的消息流处理系统。
工作流程
kafka中消息是以topic进行分类的,producer生产消息,consumer消费消息,都是面向topic的。

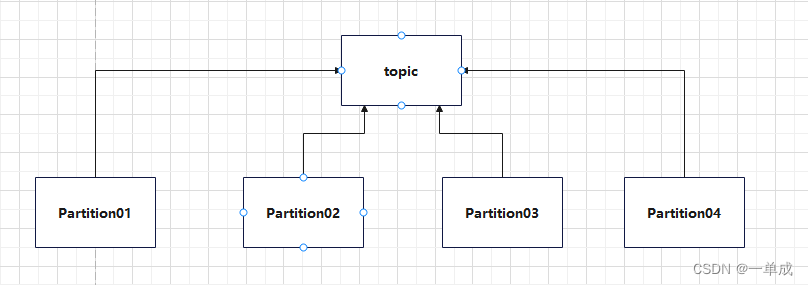
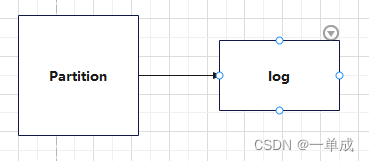
Topic是逻辑上的改变,主题分区是逻辑上的变动。partition是物理上的概念,每个partition(分区)对应着一个log文件,这个log文件中存储的就是producer生产的数据,topic=N*partition;partition=log。
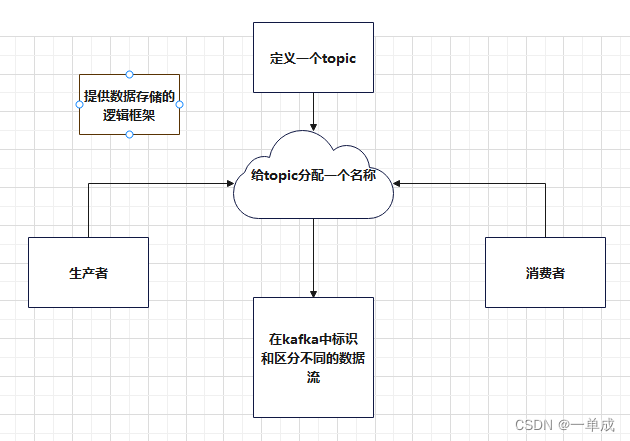
理解:topic是一个逻辑上的概念,它代表了一类数据的集合,类似于一个消息队列。每个topic都具有一个名称,用于在kafka中标识和区分不同的数据流。topic并不关系数据是如何分布式或者怎么存储的。只负责提供数据存储的逻辑框架。
这个公式解释:
topic=N*partition;partition=log
一个Topic可以由N个Partition组成,每个Partition对应一个log文件。这个公式有以下含义:
-
"topic=N":表示一个Topic可以被分为N个Partition。通过将Topic分割成多个Partition,可以实现数据的并发处理和负载均衡。不同的Partition可以在不同的节点上进行独立处理,提高系统的吞吐量和可伸缩性。
-
"partition=log":表示每个Partition对应一个log文件。这个log文件实际上是存储Producer生产的消息数据的文件。每个Partition都有自己的log文件,用于持久化存储数据。
这个公式的意义在于设计Kafka时的数据分布和存储机制。通过将一个Topic划分为多个Partition,可以实现数据的分散存储和处理,提高系统的并发性和可扩展性。而每个Partition对应一个log文件,这样可以按照顺序存储消息数据,并支持高效的读写操作。
每个Partition对应一个log文件,其中存储了Producer生产的数据。Partition的主要目的是实现数据的分布和负载均衡。通过将数据分散到多个Partition上,Kafka可以实现高吞吐量和可伸缩性,让多个消费者可以并行地处理数据。
总结起来,Topic是逻辑上的数据集合,而Partition是物理上的存储单元。Topic提供了一个逻辑框架来组织数据,而Partition在物理层面上实现了数据的分布和存储。这种逻辑和物理的分离使得Kafka可以更好地应对大规模数据流的处理需求。
Producer生产的数据会被不断的追加到该log文件的末端,且每条数据都有自己的offset,consumer组中的每个consumer,都会实时记录自己消费到了哪个offset,以便出错恢复的时候,可以从上次的位置继续消费。流程:Producer => Topic(Log with offset)=> Consumer.
offset:是指消息在一个Partition中的唯一标识符。它代表了消息在Partition中的位置或顺序。每个消息都有自己对应的offset值,通过这个值可以确定消息在Partition中的相对位置。
这个offset值是一个64位的整数,可以用来唯一标识一个消息在Partition中的位置。
总结一下流程:Producer将数据发送到对应的Topic中,其中每个Topic又被分为多个Partition。每个Partition对应一个log文件,Producer的数据会被追加到这个log文件的末端,并被分配一个唯一的offset。Consumer消费数据时,会记录自己消费到的offset,以便后续的消费过程中进行恢复和继续消费。
文件存储
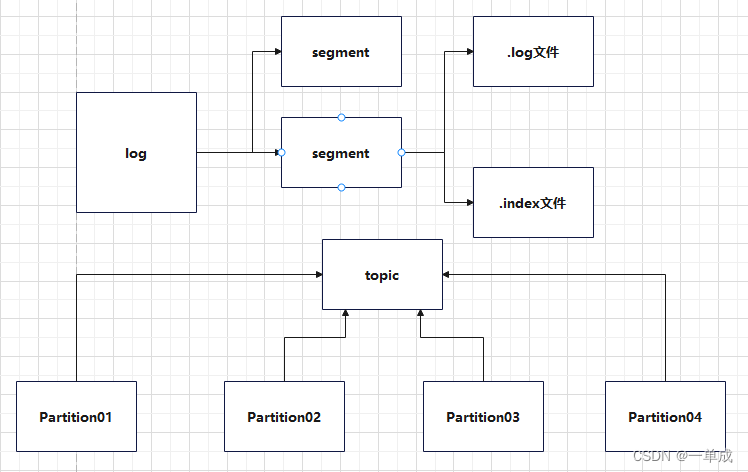
kafka通过本地落盘的方式存储,通过相应的Log与index等文件保存文件具体的消息文件。
kafka中的segment(段):
log文件的一部分。每个Partition对应的log文件由多个Segment组成,每个Segment可以理解为log文件的一个片段或区间。
Segment的引入是为了方便管理和维护log文件。当一个Segment达到一定大小或时间限制时,Kafka会关闭当前Segment,并创建一个新的Segment来接收新的消息。这样的设计有以下好处:
-
简化文件管理:通过将log文件划分为多个Segment,可以避免对一个非常大的log文件进行操作。每个Segment的大小通常是可配置的,这样可以更方便地进行日志文件的管理和维护。
-
提高性能:Segment切换时,可以并发地进行读写操作。这样在消息写入和消费的过程中,可以同时进行多个操作,提高整体的吞吐量和性能。
-
优化磁盘使用:由于Kafka采用追加写的方式,只有最新的Segment会处于活动状态,旧的Segment可以被定期压缩和删除。这样可以优化磁盘使用,减少存储空间的占用。
总的来说,Segment是Kafka中用于管理和划分log文件的一种机制。通过将log文件划分为多个Segment,可以提高性能、简化管理,并优化磁盘使用。每个Segment都有自己的大小和时间限制,Kafka会根据这些规则来管理和维护log文件。
结构图片说明:
生产者不断地向log文件追加信息文件,为了防止Log文件过大导致定位效率下降,kafka的log文件使用了1G作为分界点,当.log文件大小超过了1G之后,就会创建一个新的.log文件,同时为了快速定位大文件中消息位置,kafka采取了分片和索引的机制来加速定位。
在kafka的存储log的地方,即文件的地方,会存在消费的偏移量以及具体的分区信息,分区信息的话主要包括.index和.log文件组成。
如何快速的定位数据(在日志中):
.index文件存储的消息的offset+真实的起始偏移量。.log中存放的是真实的数据。
首先通过二分查找.index文件到查找到当前消息具体的偏移,如上图所示,查找为2,发现第二个文件为6,则定位到一个文件中。
然后通过第一个.index文件通过seek定位元素的位置3,定位到之后获取起始偏移量+当前文件大小=总的偏移量。
获取到总的偏移量之后,直接定位到.log文件即可快速获得当前消息大小。
生产者分区策略
分区原因
- 方便在集群中扩展:每个partition通过调整以适应它所在的机器,而一个Topic又可以有多个partition组成,因此整个集群可以适应适合的数据
- 可以提高并发:以Partition为单位进行读写。类似于多路。
分区的原则
指明partition(这里的指明是指第几个分区)的情况下,直接将指明的值作为partition的值
没有指明partition的情况下,但是存在值key,此时将key的hash值与topic的partition总数进行取余得到partition值
值与partition均无的情况下,第一次调用时随机生成一个整数,后面每次调用在这个整数上自增,将这个值与topic可用的partition总数取余得到partition值,即round-robin算法。
生产者ISR In-Sync Replicas(同步副本)
ISR:
SR是指In-Sync Replicas(同步副本)的缩写。ISR是每个Partition的一组副本,它们保持着与Leader副本相同的数据副本,并且与Leader副本实时保持同步。
ISR的概念是为了实现数据的可靠性和容错性。当Producer发送消息到Kafka集群时,数据首先被写入Partition的Leader副本,然后同步地复制到ISR中的其他副本。
只有ISR中的副本才被认为是“活跃”的副本,它们保持与Leader副本的数据一致性,并及时进行数据同步。这样可以确保即使在部分节点故障或网络问题的情况下,仍然可以从ISR中的副本进行消息的消费和数据的恢复。
当ISR中的副本无法及时同步时(例如副本所在的节点故障或网络异常),Kafka会将该副本移出ISR,直到副本能够追赶上Leader副本的进度。这样可以避免数据不一致问题,并保证数据的可靠性和一致性。
总的来说,ISR是Kafka中用于实现数据复制和容错的机制。它是一组与Leader副本保持实时同步的副本,用于确保数据的可靠性和高可用性。只有ISR中的副本才被认为是有效的,可以参与数据的读写操作。
为保证producer发送的数据能够可靠的发送到指定的topic中,topic的每个partition收到producer发送的数据后,都需要向producer发送ackacknowledgement,如果producer收到ack就会进行下一轮的发送,否则重新发送数据。

ExactlyOnce
在Kafka中,ExactlyOnce是一种消息处理语义,指的是同一个数据只会被处理一次,即使在传输或处理过程中出现异常也不会被重复处理。这种语义确保了消息的准确性和一致性,避免了重复或遗漏的情况。
Kafka通过幂等性和事务两种机制实现了ExactlyOnce语义。幂等性指的是同一个数据被多次处理的结果都是相同的,这样可以保证在出现故障或异常时不会重复处理数据。事务则是在Kafka中提供的一种机制,可以保证一系列操作要么全部成功,要么全部失败,这样可以避免数据的不一致性。
在Kafka中,要实现ExactlyOnce语义,需要Producer和Consumer都支持幂等性和事务机制,同时还需要在Kafka的配置中开启幂等性和事务相关的设置。
将服务器的ACK级别设置为-1(all),可以保证producer到Server之间不会丢失数据,即At Least Once至少一次语义。将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即At Most Once至多一次。
At Least Once可以保证数据不丢失,但是不能保证数据不重复,而At Most Once可以保证数据不重复,但是不能保证数据不丢失,对于重要的数据,则要求数据不重复也不丢失,即Exactly Once即精确的一次。
在0.11版本的Kafka之前,只能保证数据不丢失,在下游对数据的重复进行去重操作,多余多个下游应用的情况,则分别进行全局去重,对性能有很大影响。
0.11版本的kafka,引入了一项重大特性:幂等性,幂等性指代Producer不论向Server发送了多少次重复数据,Server端都只会持久化一条数据。幂等性结合At Least Once语义就构成了Kafka的Exactly Once语义。
启用幂等性,即在Producer的参数中设置enable.idempotence=true即可,Kafka的幂等性实现实际是将之前的去重操作放在了数据上游来做,开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一个Partition的消息会附带Sequence Number,而Broker端会对<PID,Partition,SeqNumber>做缓存,当具有相同主键的消息的时候,Broker只会持久化一条。
但PID在重启之后会发生变化,同时不同的Partition也具有不同的主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
一个任务只执行一次!!!!
消费者分区分配策略
kafka消费模式
Kafka的消费模式有两种:pull模式和push模式。
- pull模式是Kafka默认采用的消费模式。在这种模式下,Consumer可以主动从Broker中拉取数据。Consumer通过API向Broker发起请求,询问是否有新的消息,Broker收到请求后,会检查是否有消息需要发送给Consumer,如果有,就将消息发送给Consumer。这种模式的优点是Consumer可以及时获取最新的消息,但是不足之处在于如果Kafka没有数据,Consumer可能会陷入循环中,一直返回空数据。
- push模式是Kafka曾经采用的模式。在这种模式下,Broker会主动将消息推送给Consumer。然而,这种模式的缺点在于,由于Broker的推送速率取决于消息的生产速率,因此很难适应所有消费者的消费速率。例如,推送的速度是50m/s,但是Consumer1、Consumer2的处理速度可能无法跟上推送速度,导致消息积压。
consumer采用pull拉的方式来从broker中读取数据。
push推的模式很难适应消费速率不同的消费者,因为消息发送率是由broker决定的,它的目标是尽可能以最快的速度传递消息,但是这样容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull方式则可以让consumer根据自己的消费处理能力以适当的速度消费消息。
除了这两种模式,Kafka还支持发布/订阅模式和点对点模式。
- 发布/订阅模式是一种基于主题的发布/订阅模型。在这种模式下,Producer将消息发布到一个主题(topic),而多个Consumer订阅该主题,从而获取消息。这种模式的优点是多个Consumer可以同时接收来自同一主题的消息,实现负载均衡。
- 点对点模式是一种一对一的消息传递模式。在这种模式下,每个消息都被发送到一个特定的接收者进行处理。这种模式的优点是消息不会丢失,也不会被多个接收者重复处理。
无论是哪种消费模式,Kafka都能够保证消息的有序性和可靠性,以及提供高吞吐量的消息处理能力。
分区分配策略
一个消费者组中的存在多个消费者,一个主题中存在多个partition(分区),所以必然会涉及到partition的分配问题,即确定那个partition由那个consumer消费的问题。
kafka中有两种分配的策略
round-robin循环
range
round-robin
轮询,使用轮询的方式来分配所以的分区,该策略主要实现的步骤为:
按照分区的字典对分区和消费者进行排序,然后对分区进行循环遍历,遇到自己订阅的则消费,否则向下轮询下一个消费者。即按照分区轮询消费者,继而消息被消费。
轮询的方式会导致每个Consumer所承载的分区数量不一致,从而导致各个Consumer压力不均。
Range
range的重分配策略,首先计算各个消费者将会承载的分区数量,然后将制定数量的分区分配给改消费者。
本质上是以此遍历每个topic,然后将这些topic按照其订阅的consumer数进行平均分配,多出来的则按照consumer的字典序挨个分配,这种方式会导致在前面的consumer得到更多的分区,导致各个consumer的压力不均衡。
高效读写&Zookeeper作用
kafka的高效读写
顺序写入磁盘
kafka的生产者生产数据,需要写到log文件中,写的过程是追加到文件末端的,顺序写的方式,同样的磁盘顺序写能达到600m/s的速度。因为磁盘的结构关系,省去了大量磁头寻址的时间。
零拷贝
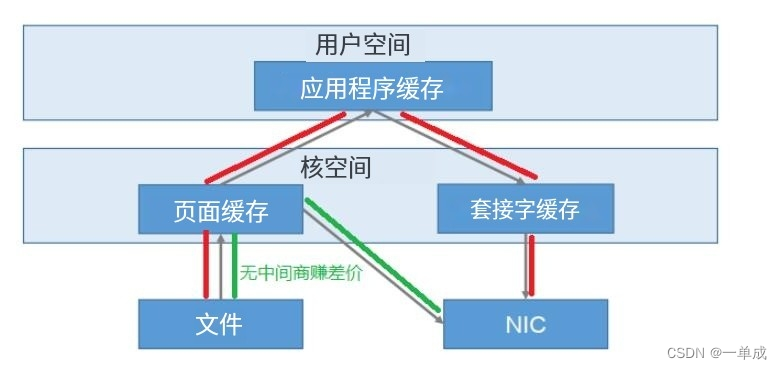
NIC:Network Interface Controller网络接口控制器
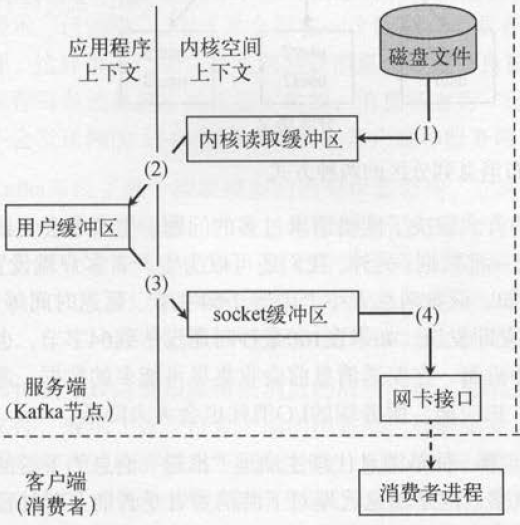
这是常规的读取操作:
- 操作系统将数据从磁盘文件中读取到内核空间的页面缓存
- 应用程序将数据从内核空间读入到用户空间缓冲区
- 应用程序将读到的数据写回内核空间并放入到socket缓冲区
- 操作系统将数据从socket缓冲区复制到网卡接口,此时数据通过网络发送给消费者
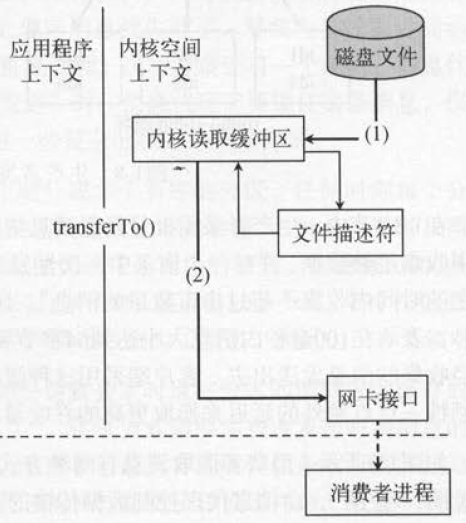
零拷贝技术是一种在不涉及内核态数据拷贝的情况下,将数据从内核空间直接传输到网络空间的技术。它通过避免数据的重复复制操作,大大提高了数据传输的效率。
在传统的文件传输过程中,数据需要经过多次复制和拷贝。首先,数据需要从磁盘文件复制到操作系统的内核缓冲区,然后从内核缓冲区复制到用户空间的应用程序缓冲区,最后再从应用程序缓冲区直接发送到网络。这种传统的传输方式需要经过多次复制和拷贝,会消耗大量的CPU资源和内存带宽。
而零拷贝技术通过将数据从磁盘文件直接复制到用户空间的页面缓存中,避免了数据的重复复制操作。然后,数据可以直接从页面缓存发送到网络,无需再次复制或拷贝。这种技术大大减少了数据的复制次数,提高了数据传输的效率。
在你提供的例子中,如果有10个消费者需要读取同一个文件,传统的方式下,数据需要复制40次。而使用零拷贝技术,数据只需要复制1次到页面缓存中,然后10个消费者各自读取一次页面缓存,总共只需要复制11次,大大减少了数据的复制次数。
需要注意的是,零拷贝技术虽然提高了数据传输的效率,但它也需要消耗一定的系统资源和内存带宽。因此,在实际应用中,需要根据具体的情况和需求来选择是否使用零拷贝技术。
相关文章:
kafka--技术文档--架构体系
架构体系 Kafka的架构体系包括以下几个部分: Producer. 消息生产者,就是向Kafka broker发送消息的客户端。Broker. 一台Kafka服务器就是一个Broker。一个集群由多个Broker组成。一个Broker可以容纳多个Topic。Topic. 可以理解为一个队列,一…...

ctfshow web入门 web103-web107
1.web103 和102一样 payload: v2115044383959474e6864434171594473&v3php://filter/writeconvert.base64-decode/resource1.php post v1hex2bin2.web104 值只要一样就可以了 payload: v21 post v113.web105 考查的是$$变量覆盖,die可以带出数据,输出一条消息…...

前端工程化之模块化
模块化的背景 前端模块化是一种标准,不是实现理解模块化是理解前端工程化的前提前端模块化是前端项目规模化的必然结果 什么是前端模块化? 前端模块化就是将复杂程序根据规范拆分成若干模块,一个模块包括输入和输出。而且模块的内部实现是私有的&…...
文件服务器实现方式汇总
hello,伙伴们,大家好,今天这一期shigen来给大家推荐几款可以一键实现文件浏览器的工具,让你轻松的实现文件服务器和内网的文件传输、预览。 基于node 本次推荐的是http-server, 它的githuab地址是:http-s…...

ChatGPT计算机科学与技术专业的本科毕业论文,2000字。论文查重率低于30%。
目录 摘要 Abstract 绪论 1.1 研究背景 1.2 研究目的和意义 2.1 ChatGPT技术概述 2.2 ChatGPT技术的优缺点分析 2.2.1 优点 2.2.2 缺点 摘要 本论文围绕ChatGPT展开,介绍了该技术的发展历程、特点及应用,分析了该技术的优缺点,提出了…...
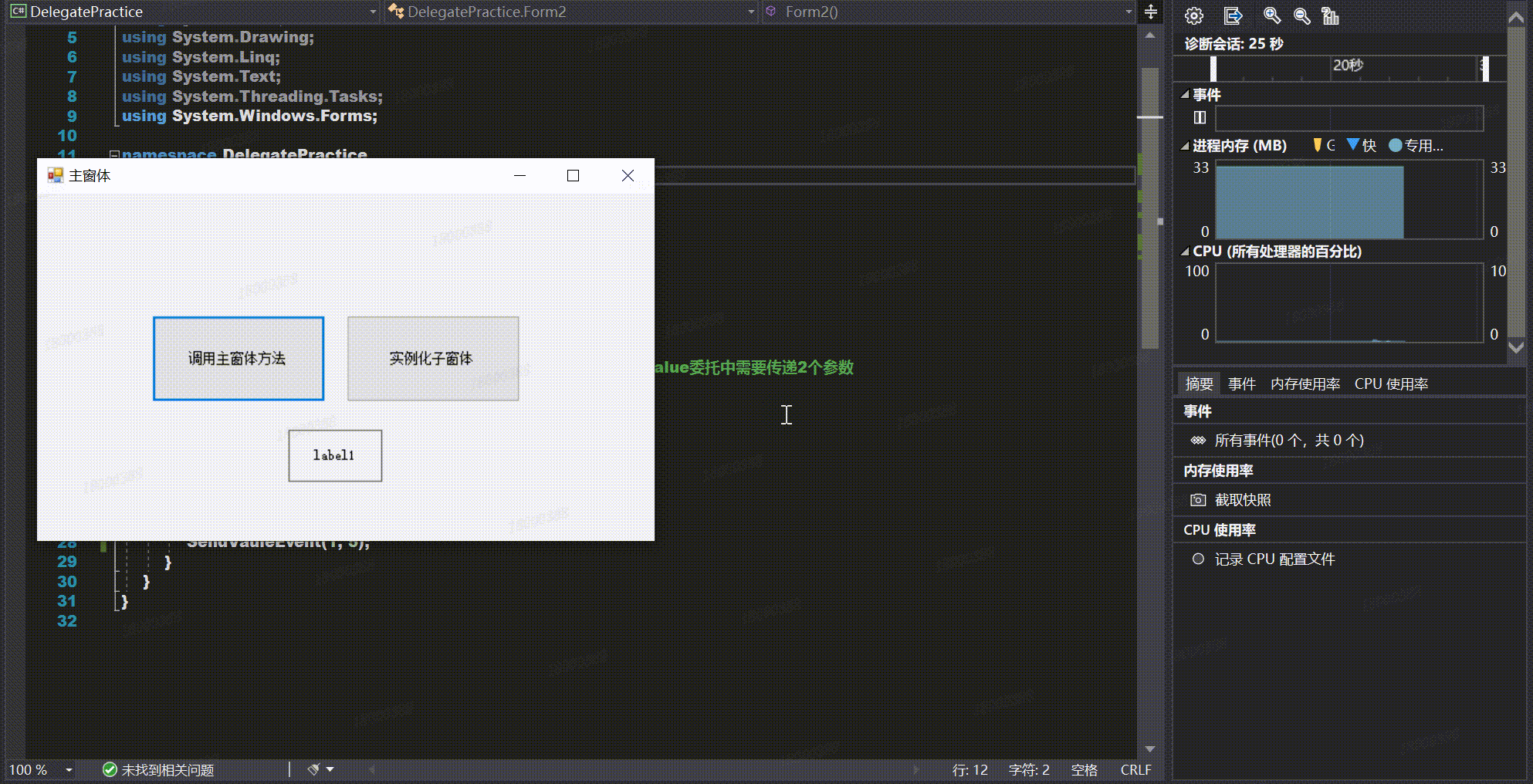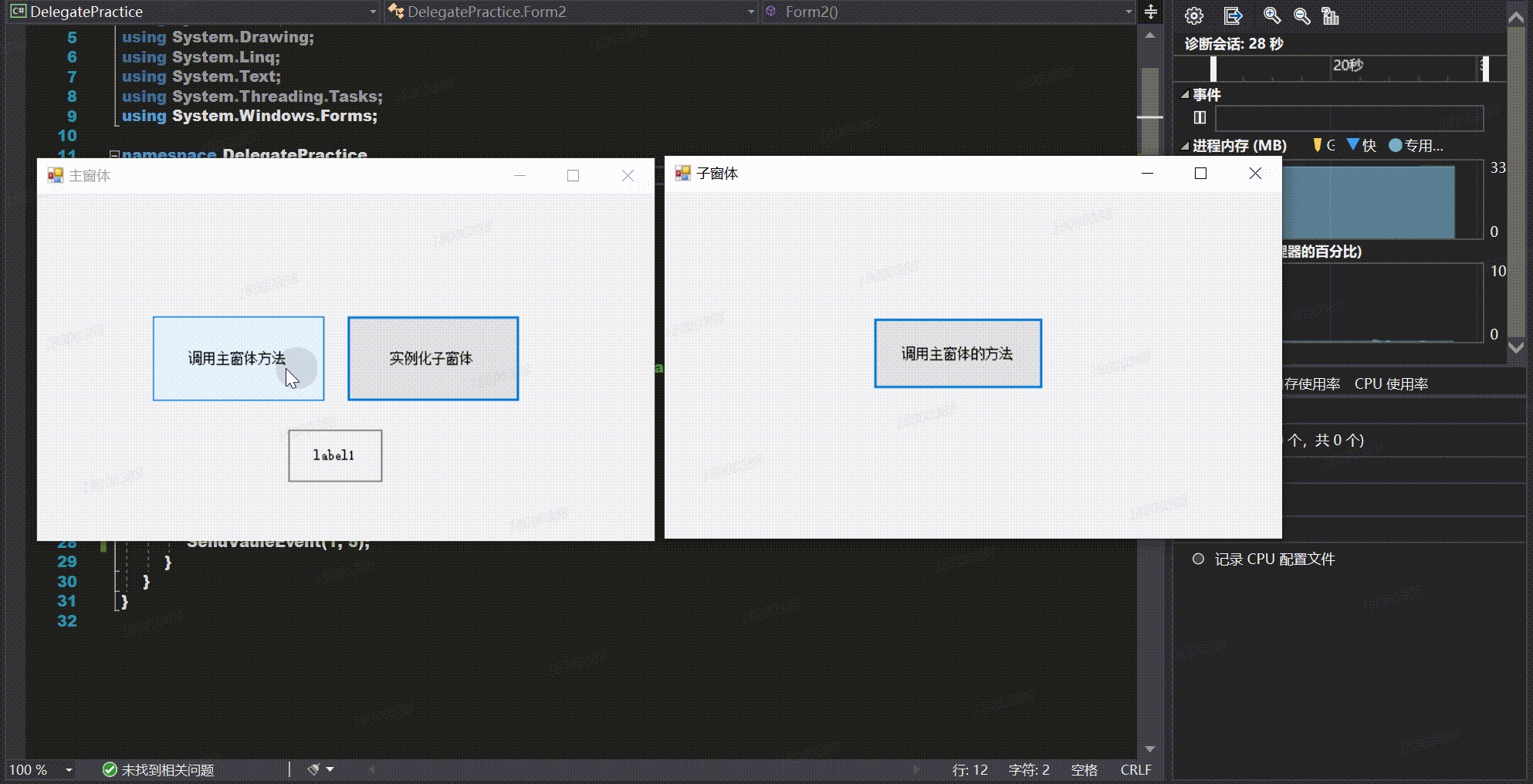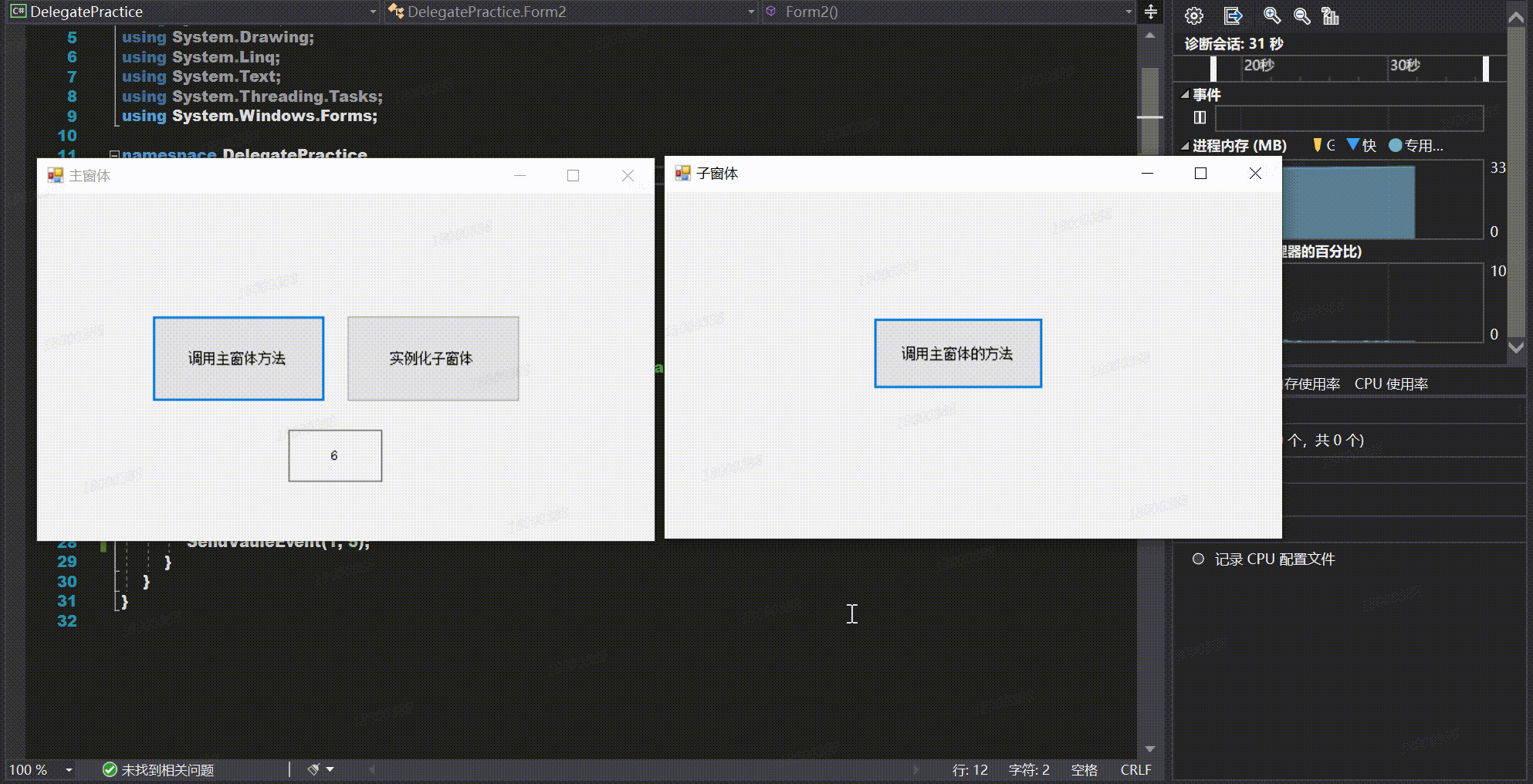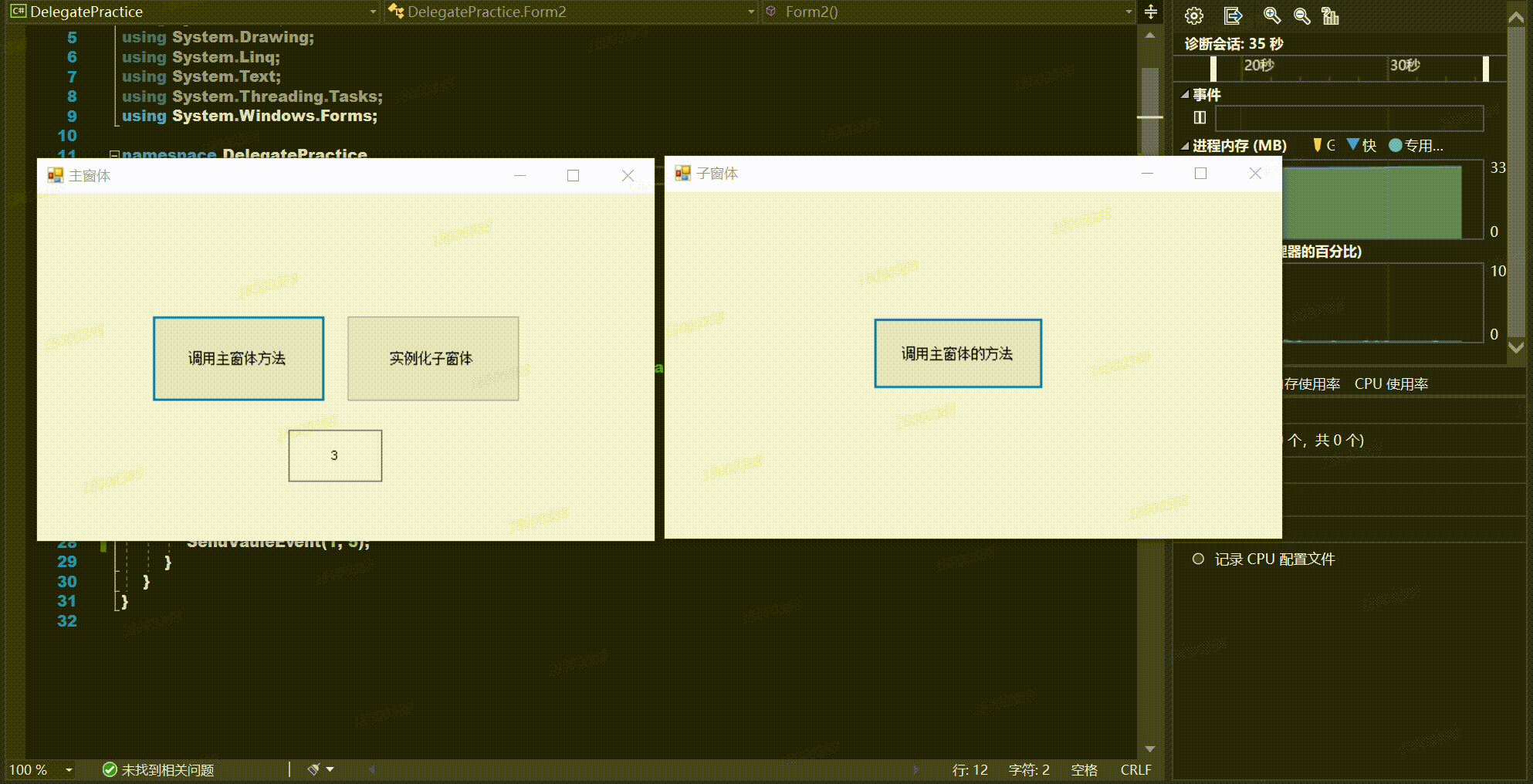
【Winform学习笔记(八)】通过委托实现跨窗体传值
通过委托实现跨窗体传值 前言正文1、委托及事件2、通过委托实现跨窗体传值的步骤1.在子窗体中定义委托2.在子窗体中声明一个委托类型的事件3.调用委托类型事件4.在实例化子窗体后,子窗体订阅事件接受方法5.实现具体的事件 3、具体示例4、完整代码5、实现效果 前言 …...

Windows用户如何安装Cpolar
目录 概述 什么是cpolar? cpolar可以用在哪些场景? 1. 注册cpolar帐号 1.1 访问官网站点 2. 下载Windows版本cpolar客户端 2.1 下载并安装 2.2 安装完验证 3. token认证 3.1 将token值保存到默认的配置文件中 3.2 创建一个随机url隧道&#x…...
梯度下降230820a)
C++最易读手撸神经网络两隐藏层(任意Nodes每层)梯度下降230820a
这是史上最简单、清晰,最易读的…… C语言编写的 带正向传播、反向传播(Forward ……和Back Propagation)……任意Nodes数的人工神经元神经网络……。 大一学生、甚至中学生可以读懂。 适合于,没学过高数的程序员……照猫画虎编写人工智能、…...

机器学习理论笔记(二):数据集划分以及模型选择
文章目录 1 前言2 经验误差与过拟合3 训练集与测试集的划分方法3.1 留出法(Hold-out)3.2 交叉验证法(Cross Validation)3.3 自助法(Bootstrap) 4 调参与最终模型5 结语 1 前言 欢迎来到蓝色是天的机器学习…...
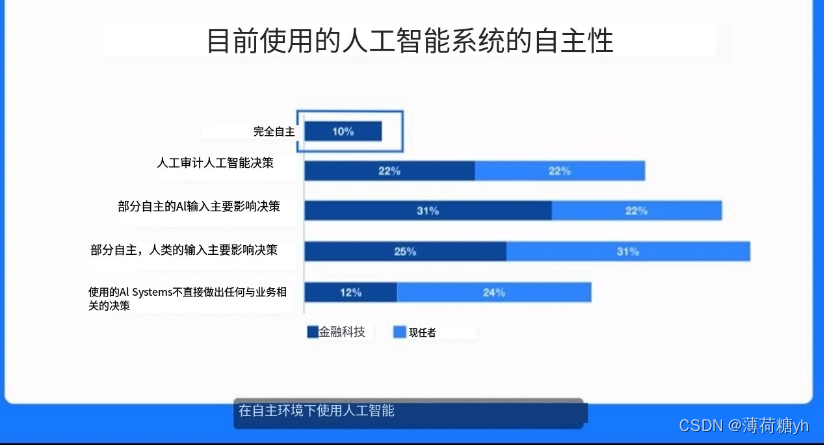
10*1000【2】
知识: -----------金融科技背后的技术---------------- -------------三个数字化趋势 1.数据爆炸:internet of everything(iot);实时贡献数据;公有云服务->提供了灵活的计算和存储。 2.由计算能力驱动的&#x…...

“探秘JS加密算法:MD5、Base64、DES/AES、RSA你都知道吗?”
目录 1、什么是JS、JS反爬是什么?JS逆向是什么? 2、JS逆向的大致流程 3、逆向的环境搭建 3.1、安装node.js 3.2、安装js代码调试工具(vscode) 3.3、安装PyExecJs模块 4、JS常见加密算法 4.1、Base64算法 4.2、MD5算法 4.3、DES/AES算法 4.2.2 AES与DES的…...
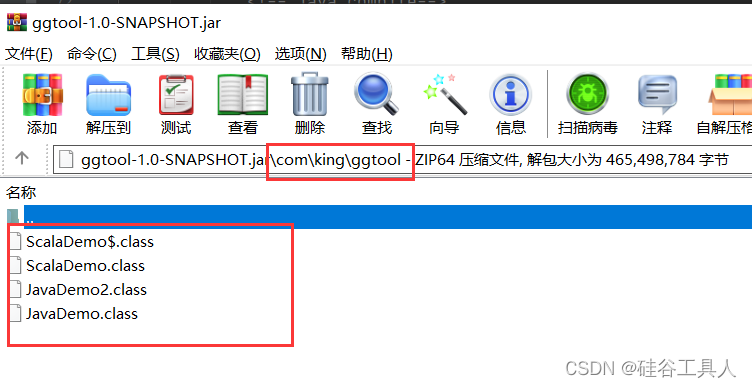
Spark项目Java和Scala混合打包编译
文章目录 项目结构Pom完整文件编译查看 实际开发用有时候引用自己写的一些java工具类,但是整个项目是scala开发的spark程序,在项目打包时需要考虑到java和scala混合在一起编译。 今天看到之前很久之前写的一些打包编译文章,发现很多地方不太对…...
深度学习处理文本(NLP)
文章目录 引言1. 反向传播1.1 实例流程实现1.2 前向传播1.3 计算损失1.4 反向传播误差1.5 更新权重1.6 迭代1.7 BackPropagation & Adam 代码实例 2. 优化器 -- Adam2.1 Adam解析2.2 代码实例 3. NLP任务4. 神经网络处理文本4.1 step1 字符数值化4.2 step 2 矩阵转化为向量…...
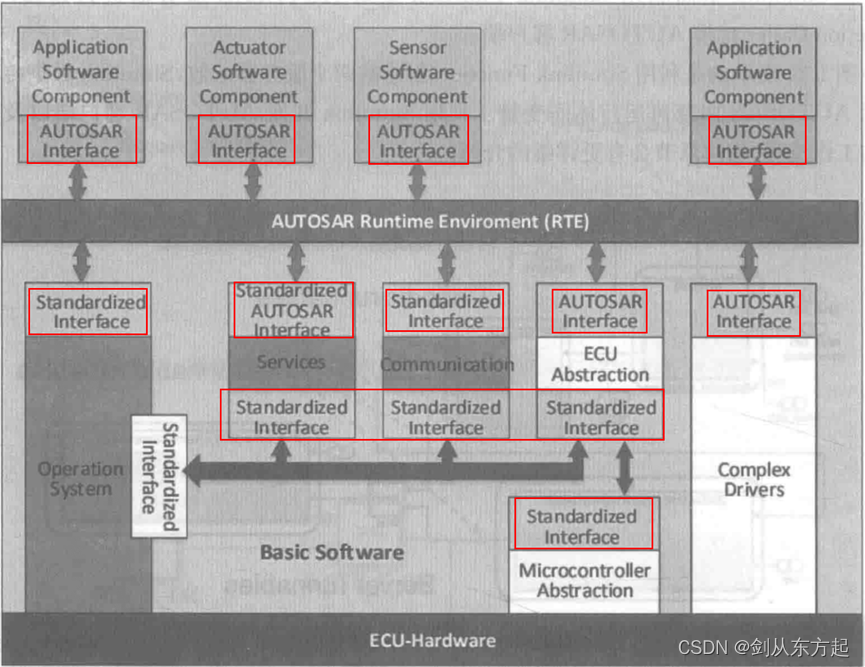
汽车电子笔记之:AUTOSAR方法论及基础概念
目录 1、AUTOSAR方法论 2、AUTOSAR的BSW 2.1、MCAL 2.2、ECU抽象层 2.3、服务层 2.4、复杂驱动 3、AUTOSAR的RTE 4、AUTOSAR的应用层 4.1、SWC 4.2、AUTOSAR的通信 4.3、AUTOSAR软件接口 1、AUTOSAR方法论 AUTOSAR为汽车电子软件系统开发过程定义了一套通用的技术方法…...

鼠标拖拽盒子移动
目录 需求思路代码页面展示【补充】纯js实现 需求 浮动的盒子添加鼠标拖拽功能 思路 给需要拖动的盒子添加鼠标按下事件鼠标按下后获取鼠标点击位置与盒子边缘的距离给 document 添加鼠标移动事件鼠标移动过程中,将盒子的位置进行重新定位侦听 document 鼠标弹起&a…...

AUTOSAR从入门到精通-【应用篇】面向车联网的车辆攻击方法及入侵检测
目录 前言 国内外研究现状 (1)车辆攻击方法的研究 (2)车辆安全防护技术的研究...
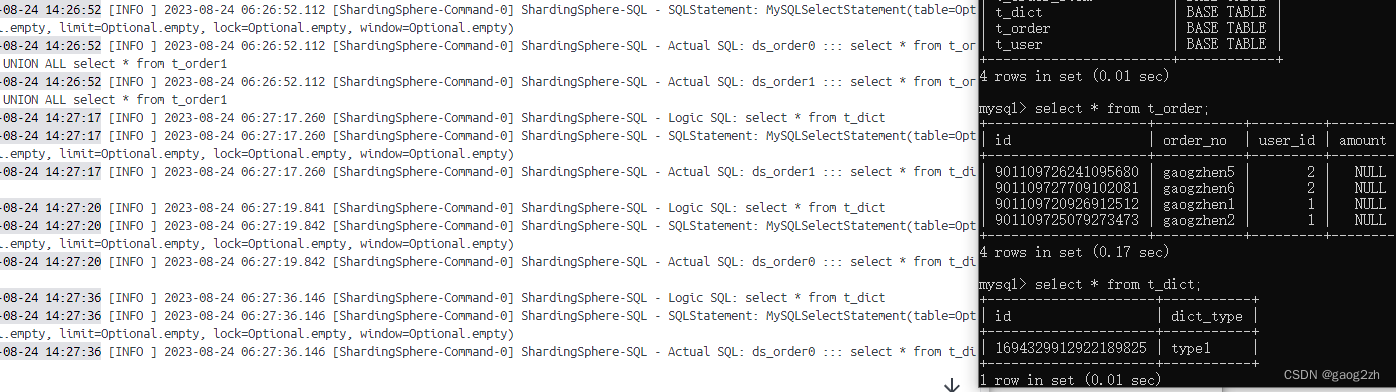
0101prox-shardingsphere-中间件
1 启动ShardingSphere-Proxy 1.1 获取 目前 ShardingSphere-Proxy 提供了 3 种获取方式: 二进制发布包DockerHelm 这里我们使用Docker安装。 1.2 使用Docker安装 step1:启动Docker容器 docker run -d \ -v /Users/gaogzhen/data/docker/shardings…...

FactoryBean和BeanFactory:Spring IOC容器的两个重要角色简介
目录 一、简介 二、BeanFactory 三、FactoryBean 四、区别 五、使用场景 总结 一、简介 在Spring框架中,IOC(Inversion of Control)容器是一个核心组件,它负责管理和配置Java对象及其依赖关系,实现了控制反转&a…...
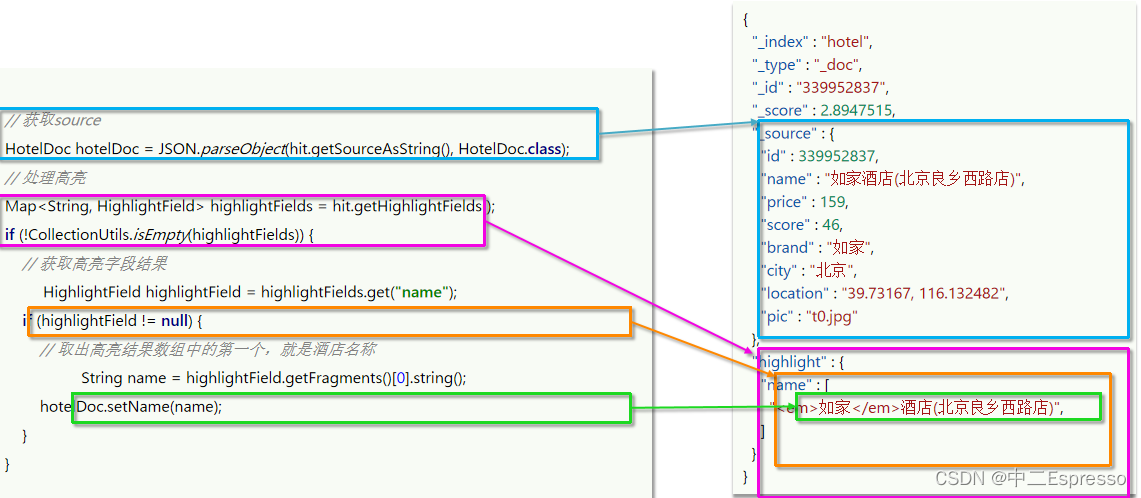
微服务中间件--分布式搜索ES
分布式搜索ES 11.分布式搜索 ESa.介绍ESb.IK分词器c.索引库操作 (类似于MYSQL的Table)d.查看、删除、修改 索引库e.文档操作 (类似MYSQL的数据)1) 添加文档2) 查看文档3) 删除文档4) 修改文档 f.RestClient操作索引库1) 创建索引库2) 删除索引库/判断索引库 g.RestClient操作文…...
触摸屏与PLC之间 EtherNet/IP无线以太网通信
在实际系统中,同一个车间里分布多台PLC,用触摸屏集中控制。通常所有设备距离在几十米到上百米不等。在有通讯需求的时候,如果布线的话,工程量较大耽误工期,这种情况下比较适合采用无线通信方式。 本方案以MCGS触摸屏和…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...
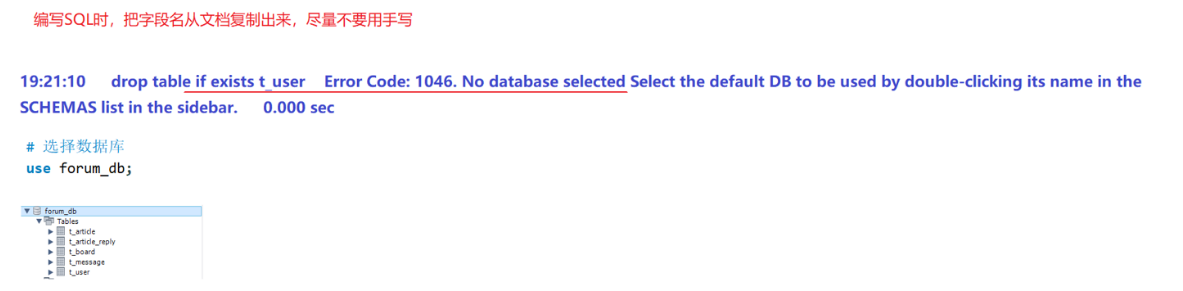
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...