Scalene:Python CPU+GPU+内存分析器,具有人工智能驱动的优化建议
一、前言
Python 是一种广泛使用的编程语言,通常与其他语言编写的库一起使用。在这种情况下,如何提高性能和内存使用率可能会变得很复杂。但是,现在有一个解决方案,可以轻松地解决这些问题 - 分析器。
分析器旨在找出哪些代码段占用时间最长或使用最多内存。而 Scalene 则是一个出色的 Python 分析器,它针对 CPU、GPU 和内存进行优化。如果您想更快地重构有问题的部分,并获得高水平的性能,Scalene 可以与 AI 建议相结合,帮助您达到目标。
二、Scalene 基本介绍
Scalene 是一个适用于 Python 的高性能 CPU、GPU 和内存分析器,它可以完成许多其他 Python 分析器没有也不能做的事情。它的运行速度比许多其他分析器快几个数量级,同时提供更详细的信息。它也是第一个采用人工智能驱动的优化建议的分析器。
2.1、选择 Scalene 的优势
与 Python 捆绑的分析器相比,Scalene 分析器不仅易于使用,而且具有许多优势:
-
Scalene 速度很快。它使用采样而不是检测或依赖 Python 的跟踪工具。其开销通常不超过 10-20%(而且通常更少)。
-
Scalene 非常精确。与大多数其他 Python 分析器不同,Scalene 在行级别执行 CPU 分析,指向负责程序执行时间的特定代码行。这种级别的详细信息比大多数分析器返回的函数级配置文件有用得多。
-
Scalene 将在 Python 中运行的时间与在本机代码(包括库)中花费的时间分开。大多数 Python 程序员不会优化本机代码(通常在 Python 实现或外部库中)的性能,因此这有助于开发人员将优化工作集中在他们实际可以改进的代码上。
-
Scalene 分析内存使用情况。除了跟踪 CPU 使用情况外,Scalene 还指出负责内存增长的特定代码行。它通过包含的专用内存分配器来实现这一点。
-
Scalene 生成每行内存配置文件,从而更容易追踪泄漏。
-
Scalene 配置文件复制量,可以轻松发现无意的复制,特别是由于跨越 Python/库边界而导致的复制(例如,意外地将 numpy 数组转换为 Python 数组,反之亦然)。
三、Scalene 安装部署
对于不同平台,Scalene 提供了两种方式进行安装,在安装前请先确保在本机电脑或者服务器上成功安装了Python环境。
3.1、安装 Conda(Python)
Conda 包管理器默认内置了一个 Python 版本,你也可以根据需要选择安装任意版本的 Python。
- 如果是首次安装Conda,在终端中,使用以下命令下载Miniconda安装脚本:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 使用以下命令运行安装脚本:
bash Miniconda3-latest-Linux-x86_64.sh
-
按照安装程序的提示进行安装。您可以选择安装位置和环境变量设置等选项。
-
安装完成后,关闭终端并重新打开一个新终端,在新终端中,使用以下命令激活conda环境:
source ~/.bashrc
- 使用以下命令检查conda是否成功安装:
conda --version
如果conda成功安装,您将看到conda的版本号,我这里安装的是conda 23.5.2。
3.2、创建 Python 虚拟环境
如果需要在Miniconda中安装特定版本的Python,可以使用以下命令:
conda create -n myenv python=3.11
这将创建一个名为myenv的环境,并在其中安装 Python 3.11 版本。您可以根据需要替换版本号。
如果使用的是 Mac/Linux,您可以使用以下命令激活虚拟环境:
conda activate myenv
在命令行前面如果看到 (myenv) 则说明 Python 的虚拟环境激活成功了,后续推出会话需要安装依赖也需要先激活到虚拟环境再进行操作。
(base) root@racknerd:/scalene# conda activate myenv
(myenv) root@racknerd:/scalene# pip --version
pip 23.2.1 from /root/miniconda3/envs/myenv/lib/python3.11/site-packages/pip (python 3.11)
3.3、安装 Scalene
3.3.1、pip 安装(Mac OS X、Linux、Windows 和 WSL2)
Scalene 作为 pip 软件包分发,可在 Mac OS X、Linux(包括 Windows WSL2 中的 Ubuntu)和(有限制)Windows 平台上运行。 (注意:Windows 版本尚未完成;目前仅支持 CPU 和 GPU 分析,但不支持内存分析。)
pip install -U scalene
3.3.2、Homebrew 安装(Max OS X)
brew tap plasma-umass/scalenebrew install --head plasma-umass/scalene/scalene
四、Scalene 如何使用
要运行 Scalene,请使用命令 scalene program_name.py 。默认情况下,它会分析 CPU、GPU 和内存。如果您只需要一个或部分选项,请使用标志 --cpu 、 --gpu 和 --memory 。例如, scalene --cpu --gpu program_name.py 仅分析 CPU 和 GPU。
除了行级分析之外,Scalene 还提供功能级分析。这两种类型的分析保存在输出表的不同部分中。第一部分包括所有行的行级分析,而第二部分包括所有函数的函数级分析。要仅分析具有重要用途的行和函数,请添加标志 --reduced-profile 。

4.1、接口
运行分析命令后,它会在界面上显示结果。您有两个界面选项:命令行界面 (CLI) 和 Web 界面。为了比较它们,我们将使用以下名为 test.py 的 Python 文件。
size = 1000000# 高内存分配
x = [i for i in range(size)]
y = [i for i in range(size)]# 高计算时间
for i in range(size):y[i] = y[i] * y[i]
4.2、命令行界面
默认情况下,命令 scalene test.py 将打开 Web 界面。要获取 CLI,请添加标志 --cli 。
在表中,我们提供了三种颜色。蓝色表示 CPU 分析,绿色表示内存分析,黄色表示 GPU 分析和复制量。
CPU 分析提供了运行 Python 代码、本机代码(例如 C 或 C++)所花费的时间以及在系统上所花费的时间(例如 I/O)。在示例中,总运行时间的 45% 花费在 y[i] = y[i] * y[i] 行的 Python 代码上。因此,这是我们必须优化以提高性能的线路之一。如果将蓝色栏中的所有百分比相加,则得到 100%。
内存分析给出了 Python 代码分配的内存百分比。该表还包括一段时间内的内存使用情况及其峰值。正如预期的那样, x 和 y 向量的创建会导致最高的内存分配。为了提高性能,我们必须为它们创建更高效的分配函数。
GPU 分析和复制量分别给出 GPU 运行时间和复制量 (mb/s)。复制量包括GPU和CPU之间的复制。需要注意的是,GPU 分析仅支持 NVIDIA GPU。
4.3、Web UI 界面
Scalene Web 系统访问地址:Scalene
Scalene Web 界面可以很方便的通过统计图表可视化的方式展现代码的性能情况,同时也支持接入OpenAI GPT模型来生成更高质量更准确的代码优化建议,只需要两步操作即可使用。
- 首先,在我们本机电脑(也可以直接在PyCharm开发工具中使用终端命令的方式)或者是服务器端执行以下命令来生成一个
profile.json分析文件。
scalene test.py --json --outfile profile.json
其中的 test.py 只需要换成你需要分析的 python 代码文件名,如果只需要分析一部分代码,可以将代码分离出来分析,然后通过 --outfile 指定分析结果通过文件的形式输出,默认是 stdout 控制台的内容打印,所以这里我们需要指定 --json 来输出json文件。
-
第二步,打开我们的Scalene Web页面(http://23.95.233.243),点击【高级选项】,输入OpenAI 的API Key,这里支持 GPT-3.5 或者 GPT-4 。然后将第一步生成的 profile.json 文件上传即可出现如下图所示的分析结果,这个展示结果是只是通过可视化的方式展示 Scalene 分析的内存和CPU的结果,如果代码中有性能问题,只需要点击前面的小图标即可调用 GPT 模型来给出代码优化建议。

Web 界面与 CLI 非常相似。但是,某些列是使用颜色阴影进行压缩的。例如,我们只有一列蓝色(用于 CPU 分析),其中三种阴影分别代表 Python、本机和系统时间。
内存和 GPU 分析有额外的列。内存分析有一个额外的列,指示平均内存使用情况。内存活动显示 Python 和本机代码分配的内存,以两种绿色阴影区分。 GPU 分析有一个额外的列,指示 GPU 内存使用情况。
与 CLI 不同,会创建名为 profile.html 和 profile.json 的额外文件,其中包括显示的结果。如果您希望通过 CLI 获取这些内容,请使用标志 --json 和 --html 。
4.4、人工智能建议
到目前为止,我们已经可以使用Scalene来帮助我们分析和优化我们的Python代码了。接下来接入GPT人工智能模型来生成代码优化建议可以更快更准确的加快工作速度,并提供更多创意和灵感。
要获取OpenAI的API密钥,您需要登录您的OpenAI账户或创建一个新的账户。然后,按照以下步骤获取API密钥:
-
登录OpenAI账户并转到OpenAI网站。
-
单击屏幕右上角的"Personal",然后选择"View API keys"。
-
在API密钥页面上,您可以生成新的API密钥。请确保妥善保存您的API密钥,因为它是访问OpenAI API的凭证。
一旦您获得了API密钥,您可以将其复制到Scalene Web界面上的【高级选项】中。这样,Scalene就可以与OpenAI进行集成,并使用人工智能生成建议来加快工作速度。
请注意,保护好您的API密钥非常重要,不要将其泄露给他人。只在安全可信的环境中使用API密钥,并遵循OpenAI的使用规则和指南。

您可以选择两种类型的建议。爆炸符号💥给出了对整个代码区域的优化,而闪电⚡仅建议对一行进行优化。在下图中,您可以看到 test.py 的闪电建议,其中主要包括使用 NumPy 的替换。

根据上述代码分析优化建议, test.py 的优化版本变为:
import numpy as npsize = 1000000x = np.arange(size)
y = np.arange(size)y = np.square(y)
4.5、Scalene 命令行选项
可以使用 scalene --help 查看 Scalene 的所有命令和参数选项。
(base) root@racknerd:~# scalene --help
用法: scalene [-h] [--version] [--column-width COLUMN_WIDTH] [--outfile OUTFILE] [--html] [--json] [--cli] [--stacks] [--web] [--viewer][--reduced-profile] [--profile-interval PROFILE_INTERVAL] [--cpu] [--cpu-only] [--gpu] [--memory] [--profile-all][--profile-only PROFILE_ONLY] [--profile-exclude PROFILE_EXCLUDE] [--use-virtual-time][--cpu-percent-threshold CPU_PERCENT_THRESHOLD] [--cpu-sampling-rate CPU_SAMPLING_RATE][--allocation-sampling-window ALLOCATION_SAMPLING_WINDOW] [--malloc-threshold MALLOC_THRESHOLD] [--program-path PROGRAM_PATH][--memory-leak-detector] [--on | --off]Scalene: 一个高精度的CPU和内存分析器,版本1.5.26 (2023.08.22)命令行:% scalene [选项] your_program.py [--- --your_program_args]
或者% python3 -m scalene [选项] your_program.py [--- --your_program_args] 在Jupyter中,行模式:%scrun [选项] statement在Jupyter中,单元格模式:%%scalene [选项]your code here选项:-h, --help 显示此帮助消息并退出--version 打印此版本的Scalene并退出--column-width COLUMN_WIDTH输出宽度 (默认值: 132)--outfile OUTFILE 输出文件 (默认值: stdout)--html 输出为HTML (默认值: web)--json 输出为JSON (默认值: web)--cli 强制使用命令行--stacks 收集堆栈跟踪--web 打开一个Web标签以查看分析结果(保存为'profile.html')--viewer 只打开Web UI(https://plasma-umass.org/scalene-gui/)--reduced-profile 生成一个简化的分析结果,只包含非零行(默认值: False)--profile-interval PROFILE_INTERVAL每隔多少秒输出一次分析结果(默认值: inf)--cpu 分析CPU时间(默认值: True)--cpu-only 分析CPU时间(已弃用,请使用--cpu)--gpu 分析GPU时间和内存(默认值: True)--memory 分析内存(默认值: True)--profile-all 分析所有执行的代码,而不仅仅是目标程序(默认值: 只分析目标程序)--profile-only PROFILE_ONLY只分析包含给定字符串的文件名中的代码,字符串由逗号分隔(默认值: 没有限制)--profile-exclude PROFILE_EXCLUDE不分析包含给定字符串的文件名中的代码,字符串由逗号分隔(默认值: 没有限制)--use-virtual-time 只测量CPU时间,不测量I/O或阻塞时间(默认值: False)--cpu-percent-threshold CPU_PERCENT_THRESHOLD只报告CPU时间占比至少为此百分比的分析结果(默认值: 1%)--cpu-sampling-rate CPU_SAMPLING_RATECPU采样率(默认值: 每0.01秒采样一次)--allocation-sampling-window ALLOCATION_SAMPLING_WINDOW分配采样窗口大小,以字节为单位(默认值: 10485767字节)--malloc-threshold MALLOC_THRESHOLD只报告至少有这么多个分配的分析结果(默认值: 100)--program-path PROGRAM_PATH包含要分析的代码的目录(默认值: 被分析程序所在路径)--memory-leak-detector实验性功能:报告可能的内存泄漏(默认值: True)--on 启用分析(默认值)--off 禁用分析在后台运行Scalene时,您可以挂起/恢复进程ID的分析。例如:% python3 -m scalene yourprogram.py &Scalene now profiling process 12345to suspend profiling: python3 -m scalene.profile --off --pid 12345to resume profiling: python3 -m scalene.profile --on --pid 12345
五、总结
Scalene 是一款高性能的 Python 分析器,可以针对 CPU、GPU 和内存进行优化。它比其他分析器更快、更精确,并提供更详细的信息。Scalene 还是第一个采用人工智能驱动的优化建议的分析器。它可以帮助您更快地重构有问题的部分,以获得高水平的性能。
Scalene 的优势在于速度快、精确度高、内存使用情况分析、易于使用等方面。安装和使用 Scalene 也非常简单。只需使用命令 scalene program_name.py 即可进行分析。此外,Scalene 还提供了行级分析和函数级分析等不同的分析类型,让您更好地了解代码性能问题。
此外,Scalene 还可以与人工智能模型相结合,提供更快、更准确的优化建议。这将大大加快您的工作速度,并为您提供更多创意和灵感。
六、References
-
Scalene paper: https://arxiv.org/pdf/2212.07597.pdf
-
Scalene GitHub:https://github.com/plasma-umass/scalene
-
OpenAI API Key: Product
相关文章:
Scalene:Python CPU+GPU+内存分析器,具有人工智能驱动的优化建议
一、前言 Python 是一种广泛使用的编程语言,通常与其他语言编写的库一起使用。在这种情况下,如何提高性能和内存使用率可能会变得很复杂。但是,现在有一个解决方案,可以轻松地解决这些问题 - 分析器。 分析器旨在找出哪些代码段…...
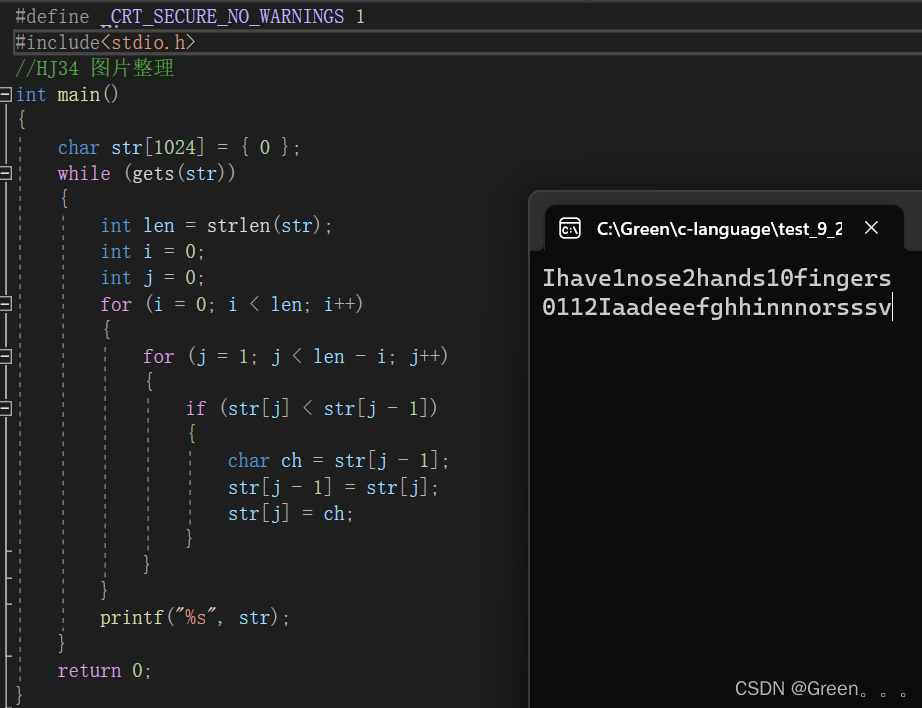
C语言练习8(巩固提升)
C语言练习8 编程题 前言 奋斗是曲折的,“为有牺牲多壮志,敢教日月换新天”,要奋斗就会有牺牲,我们要始终发扬大无畏精神和无私奉献精神。奋斗者是精神最为富足的人,也是最懂得幸福、最享受幸福的人。正如马克思所讲&am…...

Java匿名内部类
文章目录 前言一、使用匿名内部类需要注意什么?二、使用步骤匿名内部类的结构匿名内部类的实用场景1. 事件监听器2. 过滤器3. 线程4. 实现接口5.单元测试:6.GUI编程7.回调函数 前言 Java中的匿名内部类是一种可以在声明时直接创建对象的内部类。这种内部…...

Shiro和SpringSecurity的区别
文章目录 前言1.Shiro:Shiro的特点: 2.SpringSecurity:SpringSecurity特点: 3.对比:总结 前言 Shiro 和 Spring Security 都是用于在Java应用程序中实现身份验证(Authentication)和授权&#x…...

【STM32】学习笔记(OLED)
调试方式 OLED简介 硬件电路 驱动函数 OLED.H #ifndef __OLED_H #define __OLED_Hvoid OLED_Init(void); void OLED_Clear(void); void OLED_ShowChar(uint8_t Line, uint8_t Column, char Char); void OLED_ShowString(uint8_t Line, uint8_t Column, char *String); void OL…...
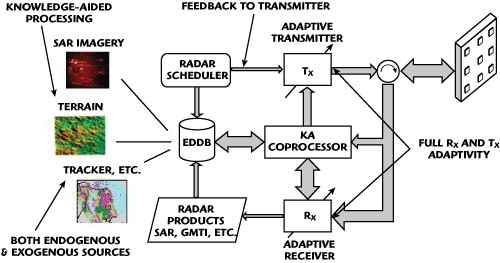
概念解析 | 认知雷达:有大脑的雷达
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:认知雷达。 认知雷达:有大脑的雷达 1.背景介绍 对于传统的雷达,它们通常都是预设定参数和模式来进行工作,比如发射功率、波形、扫描模式等。然而,这种方式面临着一些挑…...

B. Long Long
time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standard output Today Alex was brought array a1,a2,…,an�1,�2,…,�� of length n�. He can apply as m…...

CTFhub-文件上传-.htaccess
首先上传 .htaccess 的文件 .htaccess SetHandler application/x-httpd-php 这段内容的作用是使所有的文件都会被解析为php文件 然后上传1.jpg 的文件 内容为一句话木马 1.jpg <?php echo "PHP Loaded"; eval($_POST[a]); ?> 用蚁剑连接 http://ch…...

Python中的绝对和相对导入
在本文中,我们将看到Python中的绝对和相对导入。 Python中导入的工作 Python中的import类似于C/C中的#include header_file。Python模块可以通过使用import导入文件/函数来访问其他模块的代码。import语句是调用import机制的最常见方式,但它不是唯一的…...

C语言关于与运算符
C语言关于&与&&运算符 我们知道,在很多场景中&和&&通常可以相互代替,那么它们到底有什么不同呢? 先看一段代码 bool a, b, c; c a & b;使用clang -S编译出来的指令如下: movb -5(%rbp), %al …...

计算机网络(速率、宽带、吞吐量、时延、发送时延)
速率: 最重要的一个性能指标。 指的是数据的传送速率,也称为数据率 (data rate) 或比特率 (bit rate)。 单位:bit/s,或 kbit/s、Mbit/s、 Gbit/s 等。 例如 4 1010 bit/s 的数据率就记为 40 Gbit/s。 速率往往是指额定速率或…...

kubectl入门
一.kubectl的三种资源管理方式: 二. kubectl资源介绍: 1.namespace:实现多套环境的资源隔离或者多租户的资源隔离。k8s中的pod默认可以相互访问,如果不想让两个pod之间相互访问,就将其划分到不同ns下。 2.podÿ…...
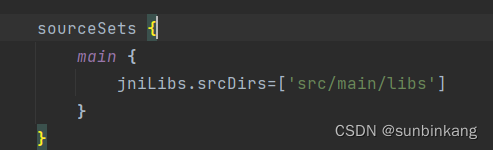
Android JNI系列详解之ndk-build工具的使用
一、Android项目中使用ndk-build工具编译库文件 之前介绍过CMake编译工具的使用,今天介绍一种ndk自带的编译工具ndk-build的使用。 ndk-build目前主要有两种配置使用方式: 如上图所示,第一种方式是Android.mkApplication.mkgradle的方式生成…...
【业务功能篇90】微服务-springcloud-检索服务-ElasticSearch实战运用-DSL语句
商城检索服务 1.检索页面的搭建 商品检索页面我们放在search服务中处理,首页我们需要在mall-search服务中支持Thymeleaf。添加对应的依赖 <!-- 添加Thymeleaf的依赖 --><dependency><groupId>org.springframework.boot</groupId><artifa…...

QTday4
实现闹钟功能 1》 头文件 #ifndef BURGER_H #define BURGER_H#include <QWidget> #include <QLabel> #include <QLineEdit> #include <QPushButton> #include <QTextEdit> #include <QTimerEvent> //定时器事件类 #include <QDateTim…...

设计模式之命令模式(Command)的C++实现
1、命令模式的提出 在软件开发过程中,“行为请求者”和“行为实现者”通常呈现一种“紧耦合”,如果行为的实现经常变化,则不利于代码的维护。命令模式可以将行为的请求者和行为的实现者进行解耦。具体流程是将行为请求者封装成一个对象&…...
取证工具prodiscover的基本操作
前言提醒 取证工具ProDiscover在网上讲解操作的文章实在太少,一是prodiscover是用于磁盘取证的工具,本身比较小众比不上其他的编程软件能用到的地方多,二是这个工具是用来恢复提取磁盘中被删除的文件,是比较隐晦的软件。 需要注…...
flutter plugins插件【二】【FlutterAssetsGenerator】
2、FlutterAssetsGenerator 介绍地址:https://juejin.cn/post/6898542896274735117 配置assets目录 插件会从pubspec.yaml文件下读取assets目录,因此要使用本插件,你需要在pubspec.yaml下配置资源目录 flutter:# The following line ens…...

看懂UML类图
UML 统一建模语言(Unified Modeling Language,UML)是一种为面向对象系统的产品进行说明、可视化和编制文档的一种标准语言,是非专利的第三代建模和规约语言。UML是面向对象设计的建模工具,独立于任何具体程序设计语言。 类的表示 首先看那个…...
keras深度学习框架通过简单神经网络实现手写数字识别
背景 keras深度学习框架,并不是一个独立的深度学习框架,它后台依赖tensorflow或者theano。大部分开发者应该使用的是tensorflow。keras可以很方便的像搭积木一样根据模型搭出我们需要的神经网络,然后进行编译,训练,测试…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...