用 TripletLoss 优化bert ranking
下面是 用 TripletLoss 优化bert ranking 的demo
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertModel, BertTokenizer
from sklearn.metrics.pairwise import pairwise_distancesclass TripletRankingDataset(Dataset):def __init__(self, queries, positive_docs, negative_docs, tokenizer, max_length):self.input_ids_q = []self.attention_masks_q = []self.input_ids_p = []self.attention_masks_p = []self.input_ids_n = []self.attention_masks_n = []for query, pos_doc, neg_doc in zip(queries, positive_docs, negative_docs):encoded_query = tokenizer.encode_plus(query, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt')encoded_pos_doc = tokenizer.encode_plus(pos_doc, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt')encoded_neg_doc = tokenizer.encode_plus(neg_doc, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt')self.input_ids_q.append(encoded_query['input_ids'])self.attention_masks_q.append(encoded_query['attention_mask'])self.input_ids_p.append(encoded_pos_doc['input_ids'])self.attention_masks_p.append(encoded_pos_doc['attention_mask'])self.input_ids_n.append(encoded_neg_doc['input_ids'])self.attention_masks_n.append(encoded_neg_doc['attention_mask'])self.input_ids_q = torch.cat(self.input_ids_q, dim=0)self.attention_masks_q = torch.cat(self.attention_masks_q, dim=0)self.input_ids_p = torch.cat(self.input_ids_p, dim=0)self.attention_masks_p = torch.cat(self.attention_masks_p, dim=0)self.input_ids_n = torch.cat(self.input_ids_n, dim=0)self.attention_masks_n = torch.cat(self.attention_masks_n, dim=0)def __len__(self):return len(self.input_ids_q)def __getitem__(self, idx):input_ids_q = self.input_ids_q[idx]attention_mask_q = self.attention_masks_q[idx]input_ids_p = self.input_ids_p[idx]attention_mask_p = self.attention_masks_p[idx]input_ids_n = self.input_ids_n[idx]attention_mask_n = self.attention_masks_n[idx]return input_ids_q, attention_mask_q, input_ids_p, attention_mask_p, input_ids_n, attention_mask_nclass BERTTripletRankingModel(torch.nn.Module):def __init__(self, bert_model_name, hidden_size):super(BERTTripletRankingModel, self).__init__()self.bert = BertModel.from_pretrained(bert_model_name)self.dropout = torch.nn.Dropout(0.1)self.fc = torch.nn.Linear(hidden_size, 1)def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = self.dropout(outputs[1])logits = self.fc(pooled_output)return logits.squeeze()def triplet_loss(anchor, positive, negative, margin):distance_positive = torch.nn.functional.pairwise_distance(anchor, positive)distance_negative = torch.nn.functional.pairwise_distance(anchor, negative)losses = torch.relu(distance_positive - distance_negative + margin)return torch.mean(losses)# 初始化BERT模型和分词器
bert_model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(bert_model_name)# 示例输入数据
queries = ['I like cats', 'The sun is shining']
positive_docs = ['I like dogs', 'The weather is beautiful']
negative_docs = ['Snakes are dangerous', 'It is raining']# 超参数
batch_size = 8
max_length = 128
learning_rate = 1e-5
num_epochs = 5
margin = 1.0# 创建数据集和数据加载器
dataset = TripletRankingDataset(queries, positive_docs, negative_docs, tokenizer, max_length)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 初始化模型并加载预训练权重
model = BERTTripletRankingModel(bert_model_name, hidden_size=model.bert.config.hidden_size)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)# 训练模型
model.train()for epoch in range(num_epochs):total_loss = 0for input_ids_q, attention_masks_q, input_ids_p, attention_masks_p, input_ids_n, attention_masks_n in dataloader:optimizer.zero_grad()embeddings_q = model(inputids_q, attention_masks_q)embeddings_p = model(input_ids_p, attention_masks_p)embeddings_n = model(input_ids_n, attention_masks_n)loss = triplet_loss(embeddings_q, embeddings_p, embeddings_n, margin)total_loss += loss.item()loss.backward()optimizer.step()print(f"Epoch {epoch+1}/{num_epochs} - Loss: {total_loss:.4f}")# 推断模型
model.eval()with torch.no_grad():embeddings = model.bert.embeddings.word_embeddings(dataset.input_ids_q)pairwise_distances = pairwise_distances(embeddings.numpy())# 输出结果
for i, query in enumerate(queries):print(f"Query: {query}")print("Documents:")for j, doc in enumerate(positive_docs):doc_idx = pairwise_distances[0][i * len(positive_docs) + j]doc_dist = pairwise_distances[1][i * len(positive_docs) + j]print(f"Document index: {doc_idx}, Distance: {doc_dist:.4f}")print(f"Document: {doc}")print("")print("---------")相关文章:

用 TripletLoss 优化bert ranking
下面是 用 TripletLoss 优化bert ranking 的demo import torch from torch.utils.data import DataLoader, Dataset from transformers import BertModel, BertTokenizer from sklearn.metrics.pairwise import pairwise_distancesclass TripletRankingDataset(Dataset):def __…...

Tomcat安装及使用
这里写目录标题 Tomcat一.java基础1.java历史2.java组成3.实现动态网页功能serveltjsp 4.jdkJDK 和 JRE 关系安装openjdk安装oracle官方JDK 二.tomcat基础功能1.Tomcat介绍2.安装tomcat二进制安装Tomcat 3.配置文件介绍及核心组件配置文件组件 4.状态页5.常见的配置详解6.tomca…...

法国新法案强迫 Firefox 等浏览器审查网站
导读Mozilla 基金会已发起了一份请愿书,旨在阻止法国政府强迫 Mozilla Firefox 等浏览器审查网站。 据悉,法国政府正在制定一项旨在打击网络欺诈的 SREN 法案 (“Projet de loi Visant scuriser et reguler lespace numrique”),包含大约 2…...

开源电商项目 Mall:构建高效电商系统的终极选择
文章目录 Mall 项目概览前台商城系统后台管理系统系统架构图业务架构图 模块介绍后台管理系统 mall-admin商品管理:功能结构图-商品订单管理:功能结构图-订单促销管理:功能结构图-促销内容管理:功能结构图-内容用户管理࿱…...
QT(9.1)对话框与事件处理
作业: 1. 完善登录框 点击登录按钮后,判断账号(admin)和密码(123456)是否一致,如果匹配失败,则弹出错误对话框,文本内容“账号密码不匹配,是否重新登录”&…...
C++项目实战——基于多设计模式下的同步异步日志系统-③-前置知识补充-设计模式
文章目录 专栏导读六大原则单例模式饿汉模式懒汉模式 工厂模式简单工厂模式工厂方法模式抽象工厂模式 建造者模式代理模式 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计划导师,阿…...

C++ 新旧版本两种读写锁
一、简介 读写锁(Read-Write Lock)是一种并发控制机制,用于多线程环境中实现对共享资源的高效读写操作。读写锁允许多个线程同时读取共享资源,但在有写操作时,需要互斥地独占对共享资源的访问,以确保数据的…...
方法)
ES6 字符串的repeat()方法
repeat() 方法返回一个新字符串,表示将原字符串重复n次 格式:str.repeat(n) 参数n:str需要重复多少次 参数n的取值: n是正整数: x.repeat(3) // 输出结果:"xxx" hello.repeat(2) // 输出结果…...

【车载以太网测试从入门到精通】系列文章目录汇总
【车载以太网测试从入门到精通】——物理层测试 【车载以太网测试从入门到精通】——数据链路层测试 【车载以太网测试从入门到精通】——网络层测试 【车载以太网测试从入门到精通】——传输层测试 【车载以太网测试从入门到精通】——以太网TCP/IP协议自动化测试(…...
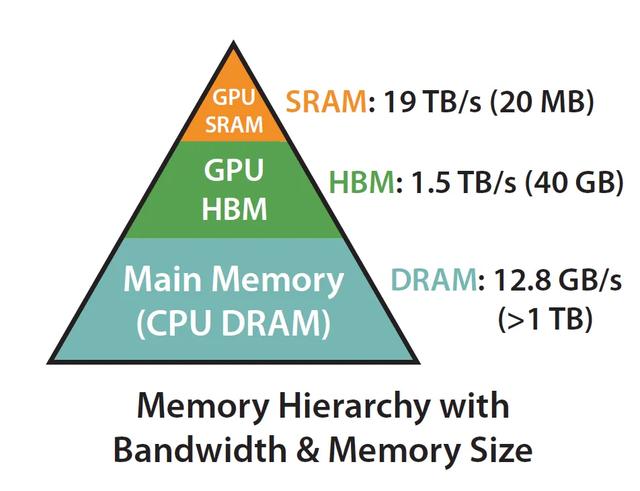
LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA
LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA 随着大模型被越来越多的应用到不同的领域,随之而来的问题是应用过程中的推理优化问题,针对LLM推理性能优化有一些新的方向,最近一直在学习和研究…...
go开发之个微机器人的二次开发
请求URL: http://域名/addRoomMemberFriend 请求方式: POST 请求头Headers: Content-Type:application/jsonAuthorization:login接口返回 参数: 参数名必选类型说明wId是String登录实例标识chatRoom…...

2023国赛数学建模B题思路代码 - 多波束测线问题
# 1 赛题 B 题 多波束测线问题 单波束测深是利用声波在水中的传播特性来测量水体深度的技术。声波在均匀介质中作匀 速直线传播, 在不同界面上产生反射, 利用这一原理,从测量船换能器垂直向海底发射声波信 号,并记录从声波发射到…...
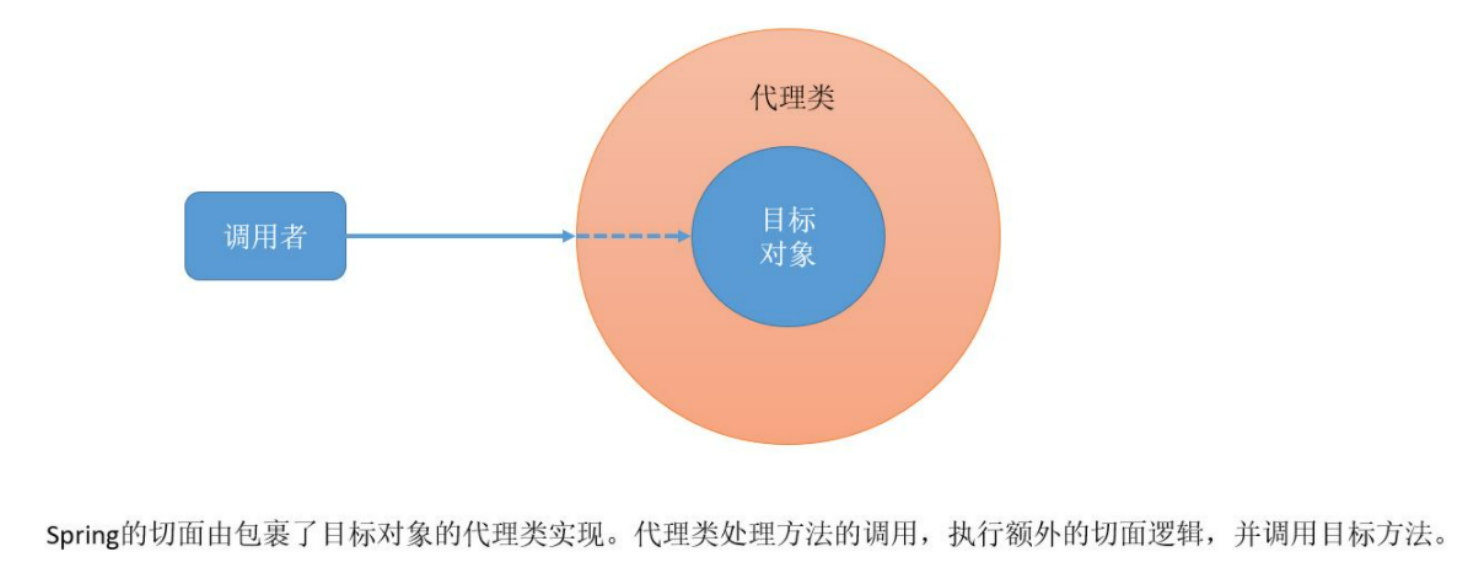
SpringAOP面向切面编程
文章目录 一. AOP是什么?二. AOP相关概念三. SpringAOP的简单演示四. SpringAOP实现原理 一. AOP是什么? AOP(Aspect Oriented Programming):面向切面编程,它是一种编程思想,是对某一类事情的集…...

A Guide to Java HashMap
原文链接: A Guide to Java HashMap → https://www.baeldung.com/java-hashmap 从Map里取值 # 原生方法 Map<String, Integer> map new HashMap<>();// map自身的方法 → 取不到返回null Integer age6 map.get("name"); // Integer时返回null可…...

LeetCode 449. Serialize and Deserialize BST【树,BFS,DFS,栈】困难
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
:IAR中ICF链接文件详解和实例分析)
嵌入式IDE(1):IAR中ICF链接文件详解和实例分析
最近在使用NXP的提供的MCUXPresso IDE,除了Eclipse固有的优点外,我觉得它最大的优点就是在链接脚本的生成上,提供了非常直观的GUI配置界面。但这个IDE仅仅支持NXP相关的产品,而且调试的性能在某些情况下并不理想。而我们用得比较多…...
分布式版本控制工具——git
✅<1>主页::我的代码爱吃辣 📃<2>知识讲解:Linux——git ☂️<3>开发环境:Centos7 💬<4>前言:git是一个开源的分布式版本控制系统,可以有效、高速地处理从很…...
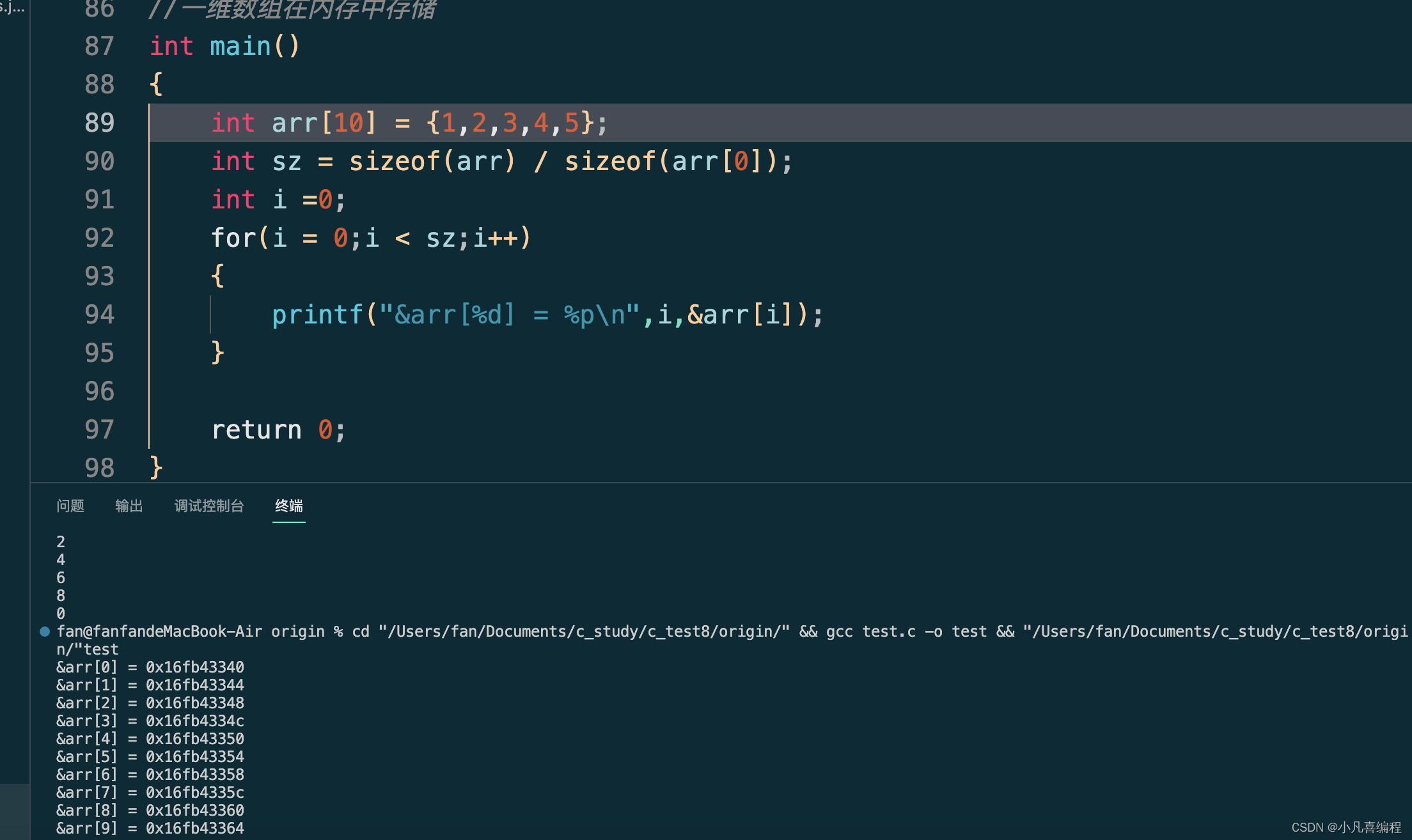
C基础-数组
1.一维数组的创建和初始化 int main() {// int arr1[10];int n 0;scanf("%d",&n);//int count 10;int arr2[n]; //局部的变量,这些局部的变量或者数组是存放在栈区的,存放在栈区上的数组,如果不初始化的话,默认…...

springboot项目配置flyway菜鸟级别教程
1、Flyway的工作原理 Flyway在第一次执行时,会创建一个默认名为flyway_schema_history的历史记录表,这张表会用来跟踪或记录数据库的状态,然后每次项目启动时都会自动扫描在resources/db/migration下的文件的版本号并且通过查询flyway_schem…...

成都精灵云初试
最近参加了成都精灵云的笔试与面试,岗位是c工程师。后面自己复盘了过程,初试部分总结如下,希望能对各位相进该公司以及面试C工程师的同学提供一些参考。这也是博主第一次参加面试,很多东西都还没准备,很多答得不好&…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...