Stream流
Stream操作流
在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。
1.1 集合的迭代
几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的迭代遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
public class Demo {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张无忌");list.add("周芷若");list.add("赵敏");list.add("张三");list.add("张三丰");for (String name : list) {System.out.println(name);}}
}
这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
循环遍历的弊端
Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
for循环的语法就是“怎么做”for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
- 将集合A根据条件一过滤为子集B;
- 然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:
这段代码中含有三个循环,每一个作用不同:
- 首先筛选所有姓张的人;
- 然后筛选名字有三个字的人;
- 最后进行对结果进行打印输出。
public class DemoFilter {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张无忌");list.add("周芷若");list.add("赵敏");list.add("张三");list.add("张三丰");List<String> zhangList = new ArrayList<>();for (String name : list) {if (name.startsWith("张")) {zhangList.add(name);}}List<String> shortList = new ArrayList<>();for (String name : zhangList) {if (name.length() == 3) {shortList.add(name);}}for (String name : shortList) {System.out.println(name);}}
}
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那,Lambda的衍生物Stream能给我们带来怎样更加优雅的写法呢?
public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张无忌");list.add("周芷若");list.add("赵敏");list.add("阳顶天");list.add("小昭");list.add("杨逍");list.add("杨过");list.add("韦一笑");list.add("谢逊");list.add("灭绝师太");list.add("静虚师太");//获取list的stream流Stream<String> listStream = list.stream();//stream.filter(boolean) 当boolean = true 是保留,false移除//过滤流中的非姓张的人名 //boolean test(T t)Stream<String> zhangStream = listStream.filter(t -> t.startsWith("张"));//姓张 且名字长度是3个字的Stream<String> shortStream = zhangStream.filter(t -> t.length() == 3);//迭代输出 //void accept(T t)shortStream.forEach(t -> System.out.println(t));//等同于list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s));}
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。流式版本比之前的写法要更易于阅读,因为流遵循了"做什么而非怎么做"的原则。
流表面上看起来和集合很类似,都可以让我们转换和获取数据。但是,它们之间存在着显著的差异:
-
流并不存储其元素。这些元素可能存储在底层的集合中,或者是按需生成的。
-
流的操作不会修改其数据源。例如,
filter方法不会从新的流中移除元素,而是会生成一个新的流,其中不包含被过滤掉的元素。 -
流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
例如:
如果我们只想査找前5个长单词而不是所有的长单词,那么filter方法就会在匹配到第 5 个单词后就停止过滤。
1.2 流式思想
注意:请暂时忘记对传统IO流的固有印象!
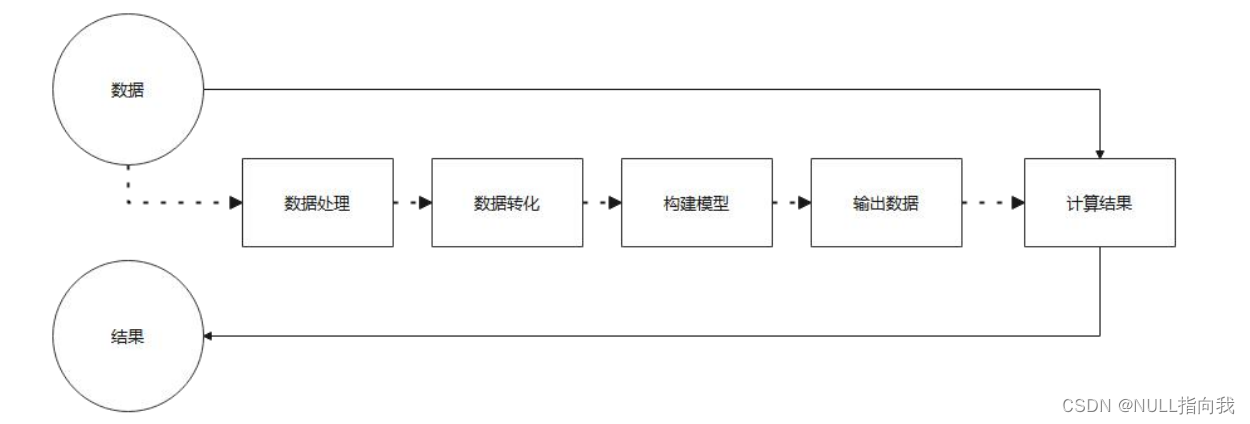
整体来看,流式思想类似于工厂车间的“生产流水线”
当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。
这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 count 执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
1.3 获取流方式
生成Stream流的方式
-
Collection体系集合
使用默认方法stream()生成流, default Stream stream()
-
Map体系集合
把Map转成Set集合,间接的生成流
-
数组
通过Arrays中的静态方法stream生成流
-
同种数据类型的多个数据
通过Stream接口的静态方法of(T… values)生成流
java.util.stream.Stream 是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)
public interface Stream<T> extends BaseStream<T, Stream<T>>
获取一个流非常简单,有以下几种常用的方式:
- 所有的
Collection集合都可以通过stream默认方法获取流; Stream接口的静态方法of可以获取数组对应的流。
**根据Collection获取流 **
首先, java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
public class DemoGetStream {public static void main(String[] args) {/*获取Stream流的方式1.Collection中 方法 Stream stream()2.Stream接口 中静态方法 of(T...t) 向Stream中添加多个数据*/List<String> list = new ArrayList<>();Stream<String> stream1 = list.stream();Set<String> set = new HashSet<>();Stream<String> stream2 = set.stream();}
}
根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法of ,使用很简单:
public static void main(String[] args) {String[] array = { "张无忌", "张翠山", "张三丰", "张翠山" };Stream<String> stream = Stream.of(array);Stream<String> stream3 = Stream.of("张小山");Stream<String> stream4 = Stream.of("张无忌", "张翠山", "张三丰", "张一元");
}
of 方法的参数其实是一个可变参数,所以支持数组。
1.4 常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
-
终结方法:返回值类型不再是
Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。终结方法包括count和forEach等 方法。 -
非终结方法(中间方法):返回值类型仍然是
Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为非终结方法。)备注:除了以下要介绍的方法外还有更多方法,请自行参考API文档。
| 方法名 | 说明 |
|---|---|
| Stream filter(Predicate predicate) | 用于对流中的数据进行过滤 |
| Stream limit(long maxSize) | 返回此流中的元素组成的流,截取前指定参数个数的数据 |
| Stream skip(long n) | 跳过指定参数个数的数据,返回由该流的剩余元素组成的流 |
| static Stream concat(Stream a, Stream b) | 合并a和b两个流为一个流 |
| Stream distinct() | 返回由该流的不同元素(根据Object.equals(Object) )组成的流 |
filter:过滤
可以通过 filter 方法将一个流转换成另一个子集流。方法声明:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda)作为筛选条件。
public static void main(String[] args) {Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");Stream<String> result = original.filter((String s) -> s.startsWith("张"));}
limit:取用前几个
limit 方法可以对流进行截取,只取用前n个。方法:
Stream<T> limit(long maxSize)
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
public static void main(String[] args) {Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");Stream<String> result = original.limit(2);System.out.println(result.count()); // 2
}
skip:跳过前几个
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
Stream<T> skip(long n)
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
public static void main(String[] args) {Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");Stream<String> result = original.skip(2);System.out.println(result.count()); // 1
}concat:组合
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法concat:
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
public static void main(String[] args) {Stream<String> streamA = Stream.of("张无忌");Stream<String> streamB = Stream.of("张翠山");Stream<String> result = Stream.concat(streamA, streamB);
}distinct: 去重
public static void main(String[] args) {//创建一个集合,存储多个字符串元素ArrayList<String> list = new ArrayList<String>();list.add("林青霞");list.add("张曼玉");list.add("王祖贤");list.add("柳岩");list.add("张敏");list.add("张无忌");// 取前4个数据组成一个流Stream<String> s1 = list.stream().limit(4);// 跳过2个数据组成一个流Stream<String> s2 = list.stream().skip(2);Stream.concat(s1,s2).distinct().forEach(s-> System.out.println(s));}
终结方法:
forEach : 逐一处理
虽然方法名字叫 forEach ,但是与for循环中的for-each不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的。
void forEach(Consumer<? super T> action);
该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。例如:
public class DemoForEach {public static void main(String[] args) {Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");stream.forEach((String str)->{System.out.println(str);});}
}
在这里,lambda表达式 (String str)->{System.out.println(str);} 就是一个Consumer函数式接口的示例。
count:统计个数
正如旧集合 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数:
long count();
此处方法返回值是long而不是int
public static void main(String[] args) {Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");Stream<String> result = original.filter((String s) -> s.startsWith("张"));System.out.println(result.count()); // 2
}
在上述介绍的各种方法中,凡是返回值仍然为 Stream 接口的为函数拼接方法,它们支持链式调用;而返回值不再为Stream 接口的为终结方法,不再支持链式调用。
Files.lines : 方法
Files.lines 是 Java 8 中的一个方法,用于读取文件中的所有行并返回为一个流(Stream)对象。
使用 Files.lines 方法可以方便地逐行读取文本文件。下面是一个示例代码:
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.stream.Stream;public class FileLinesExample {public static void main(String[] args) {String filename = "path/to/file.txt";try (Stream<String> lines = Files.lines(Paths.get(filename))) {lines.forEach(System.out::println);} catch (IOException e) {e.printStackTrace();}}
}
在这个示例中,我们使用 Paths.get 方法来获取文件路径,并将其传递给 Files.lines 方法。然后使用 try-with-resources 语句来确保在读取完成后关闭流。在 lines.forEach(System.out::println) 中,我们遍历每一行并打印到控制台上。
请注意,你需要替换 filename 变量的值为实际的文件路径。此外,使用 Files.lines 时要注意处理可能抛出的 IOException 异常。
常见末端方法:
| 返回类型 | 方法名 | 方法签名 | 描述 |
|---|---|---|---|
| void | forEach | void forEach(Consumer<? super T> action) | 对流中的每个元素执行给定的操作 |
| void | forEachOrdered | void forEachOrdered(Consumer<? super T> action) | 保证按照流中元素的遍历顺序执行给定的操作 |
| long | count | long count() | 返回流中的元素数 |
| Optional<T> | findFirst | Optional findFirst() | 返回流中的第一个元素 |
| Optional<T> | findAny | Optional findAny() | 返回流中的任意一个元素 |
| boolean | allMatch | boolean allMatch(Predicate<? super T> predicate) | 检查流中的所有元素是否都满足给定的谓词 |
| boolean | anyMatch | boolean anyMatch(Predicate<? super T> predicate) | 检查流中是否有任意一个元素满足给定的谓词 |
| boolean | noneMatch | boolean noneMatch(Predicate<? super T> predicate) | 检查流中的所有元素是否都不满足给定的谓词 |
| Optional<T> | max | Optional max(Comparator<? super T> comparator) | 返回流中根据给定比较器最大的元素 |
| Optional<T> | min | Optional min(Comparator<? super T> comparator) | 返回流中根据给定比较器最小的元素 |
| T | reduce | T reduce(T identity, BinaryOperator accumulator) | 根据给定的起始值和累加函数将流中的所有元素聚合成一个结果 |
| Optional<T> | reduce | Optional reduce(BinaryOperator accumulator) | 根据给定的累加函数将流中的所有元素聚合成一个结果 |
| R | collect | R collect(Collector<? super T, A, R> collector) | 将流中的所有元素收集到一个容器中 |
| IntStream | mapToInt | IntStream mapToInt(ToIntFunction<? super T> mapper) | 将流中的元素映射为 int 值,返回一个 IntStream |
| LongStream | mapToLong | LongStream mapToLong(ToLongFunction<? super T> mapper) | 将流中的元素映射为 long 值,返回一个 LongStream |
| DoubleStream | mapToDouble | DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper) | 将流中的元素映射为 double 值,返回一个 DoubleStream |
| Stream<T> | distinct | Stream distinct() | 返回一个去除重复元素之后的新流 |
| Stream<T> | sorted | Stream sorted() | 返回一个根据自然顺序升序排序后的新流 |
| Stream<T> | sorted | Stream sorted(Comparator<? super T> comparator) | 返回一个根据给定比较器排序后的新流 |
| Stream<T> | skip | Stream skip(long n) | 返回一个丢弃前 n 个元素后的新流 |
| Stream<T> | limit | Stream limit(long maxSize) | 截取前 maxSize 个元素返回一个新流 |
Stream流的收集操作【应用】
-
概念
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中
-
常用方法
方法名 说明 R collect(Collector collector) 把结果收集到集合中 -
工具类Collectors提供了具体的收集方式
方法名 说明 public static Collector toList() 把元素收集到List集合中 public static Collector toSet() 把元素收集到Set集合中 public static Collector toMap(Function keyMapper,Function valueMapper) 把元素收集到Map集合中 -
代码演示
// toList和toSet方法演示
public class MyStream7 {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();for (int i = 1; i <= 10; i++) {list1.add(i);}list1.add(10);list1.add(10);list1.add(10);list1.add(10);list1.add(10);//filter负责过滤数据的.//collect负责收集数据.//获取流中剩余的数据,但是他不负责创建容器,也不负责把数据添加到容器中.//Collectors.toList() : 在底层会创建一个List集合.并把所有的数据添加到List集合中.List<Integer> list = list1.stream().filter(number -> number % 2 == 0).collect(Collectors.toList());System.out.println(list);Set<Integer> set = list1.stream().filter(number -> number % 2 == 0).collect(Collectors.toSet());System.out.println(set);
}
}
/**
Stream流的收集方法 toMap方法演示
创建一个ArrayList集合,并添加以下字符串。字符串中前面是姓名,后面是年龄
"zhangsan,23"
"lisi,24"
"wangwu,25"
保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
*/
public class MyStream8 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("zhangsan,23");list.add("lisi,24");list.add("wangwu,25");Map<String, Integer> map = list.stream().filter(s -> {String[] split = s.split(",");int age = Integer.parseInt(split[1]);return age >= 24;}// collect方法只能获取到流中剩余的每一个数据.//在底层不能创建容器,也不能把数据添加到容器当中//Collectors.toMap 创建一个map集合并将数据添加到集合当中// s 依次表示流中的每一个数据//第一个lambda表达式就是如何获取到Map中的键//第二个lambda表达式就是如何获取Map中的值).collect(Collectors.toMap(s -> s.split(",")[0],s -> Integer.parseInt(s.split(",")[1]) ));System.out.println(map);}
}
Stream流综合练习
案例需求
-
现在有两个ArrayList集合,分别存储6名男演员名称和6名女演员名称,要求完成如下的操作
- 男演员只要名字为3个字的前三人
- 女演员只要姓林的,并且不要第一个
- 把过滤后的男演员姓名和女演员姓名合并到一起
- 把上一步操作后的元素作为构造方法的参数创建演员对象,遍历数据
演员类Actor已经提供,里面有一个成员变量,一个带参构造方法,以及成员变量对应的get/set方法
-
代码实现
演员类
public class Actor {private String name;public Actor(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;} }测试类
public class StreamTest {public static void main(String[] args) {//创建集合ArrayList<String> manList = new ArrayList<String>();manList.add("周润发");manList.add("成龙");manList.add("刘德华");manList.add("吴京");manList.add("周星驰");manList.add("李连杰");ArrayList<String> womanList = new ArrayList<String>();womanList.add("林心如");womanList.add("张曼玉");womanList.add("林青霞");womanList.add("柳岩");womanList.add("林志玲");womanList.add("王祖贤");//男演员只要名字为3个字的前三人Stream<String> manStream = manList.stream().filter(s -> s.length() == 3).limit(3);//女演员只要姓林的,并且不要第一个Stream<String> womanStream = womanList.stream().filter(s -> s.startsWith("林")).skip(1);//把过滤后的男演员姓名和女演员姓名合并到一起Stream<String> stream = Stream.concat(manStream, womanStream);// 将流中的数据封装成Actor对象之后打印stream.forEach(name -> {Actor actor = new Actor(name);System.out.println(actor);}); }
}
forEachOrdered 和 forEach 区别
forEachOrdered 和 forEach 都是 Java 8 中 Stream API 提供的方法,用于对流中的元素进行迭代操作。它们之间的区别在于元素的处理顺序。
-
forEach方法:它在并行流上不保证元素的处理顺序。在并行流中,元素会按照多个线程处理,可能会导致输出的顺序与源数据的顺序不一致。 -
forEachOrdered方法:它在并行流上保证元素的处理顺序与源数据的顺序一致。无论是串行流还是并行流,forEachOrdered方法都会按照源数据的顺序依次处理元素。
下面是一个示例来演示两者之间的区别:
import java.util.Arrays;
import java.util.concurrent.TimeUnit;public class ForEachExample {public static void main(String[] args) {String[] words = {"apple", "banana", "cherry", "date"};// forEachSystem.out.println("forEach:");Arrays.stream(words).parallel().forEach(System.out::println);// forEachOrderedSystem.out.println("forEachOrdered:");Arrays.stream(words).parallel().forEachOrdered(System.out::println);}
}
在这个示例中,我们创建了一个包含几个单词的字符串数组。然后使用并行流对这些单词进行处理。通过 forEach 方法打印输出时,由于并行流的处理顺序不确定,每次运行结果可能会有所不同。而通过 forEachOrdered 方法打印输出时,无论是串行流还是并行流,都会按照源数据的顺序依次输出单词。
总结来说,forEach 方法适用于不关心元素处理顺序的场景,而 forEachOrdered 方法适用于需要保证元素处理顺序和源数据顺序一致的场景。需要根据具体需求选择使用哪个方法。
相关文章:

Stream流
Stream操作流 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。 1.1 集合的迭代 几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的迭代…...

javaee spring 声明式事务管理方式2 注解方式
spring配置文件 <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xmlns:context"http://www.springframewo…...
基于SpringBoot+微信小程序的智慧医疗线上预约问诊小程序
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 近年来,随…...

注意力机制讲解与代码解析
一、SEBlock(通道注意力机制) 先在H*W维度进行压缩,全局平均池化将每个通道平均为一个值。 (B, C, H, W)---- (B, C, 1, 1) 利用各channel维度的相关性计算权重 (B, C, 1, 1) --- (B, C//K, 1, 1) --- (B, C, 1, 1) --- sigmoid 与原特征相…...

微调 TrOCR – 训练 TrOCR 识别弯曲文本
TrOCR(基于 Transformer 的光学字符识别)模型是性能最佳的 OCR 模型之一。在我们之前的文章中,我们分析了它们在单行打印和手写文本上的表现。然而,与任何其他深度学习模型一样,它们也有其局限性。TrOCR 在处理开箱即用的弯曲文本时表现不佳。本文将通过在弯曲文本数据集上…...
Jetsonnano B01 笔记7:Mediapipe与人脸手势识别
今日继续我的Jetsonnano学习之路,今日学习安装使用的是:MediaPipe 一款开源的多媒体机器学习模型应用框架。可在移动设备、工作站和服务 器上跨平台运行,并支持移动 GPU 加速。 介绍与程序搬运官方,只是自己的学习记录笔记&am…...
vue学习之v-if/v-else/v-else-if
v-else/v-else-if 创建 demo7.html,内容如下 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Docum…...
ansible的安装和简单的块使用
目录 一、概述 二、安装 1、选择源 2、安装ansible 3、模块查看 三、实验 1、拓扑编辑 2、设置组、ping模块 3、hostname模块 4、file模块 编辑 5、stat模块 6、copy模块(本地拷贝到远程) 7、fetch模块与copy模块类似,但作用…...

Android 状态栏显示运营商名称
Android 原生设计中在锁屏界面会显示运营商名称,用户界面中,大概是基于 icon 数量长度显示考虑,对运营商名称不作显示。但是国内基本都加上运营商名称。对图标显示长度优化基本都是:缩小运营商字体、限制字数长度、信号图标压缩上…...
10.Xaml ListBox控件
1.运行界面 2.运行源码 a.Xaml 源码 <Grid Name="Grid1"><!--IsSelected="True" 表示选中--><ListBox x:Name="listBo...

基于vue3和element-plus的省市区级联组件
git地址:https://github.com/ht-sauce/elui-china-area-dht 使用:npm i elui-china-area-dht 默认使用 使用方法 <template><div class"app"><!--默认使用--><elui-china-area-dht change"onChange"></elui-china…...
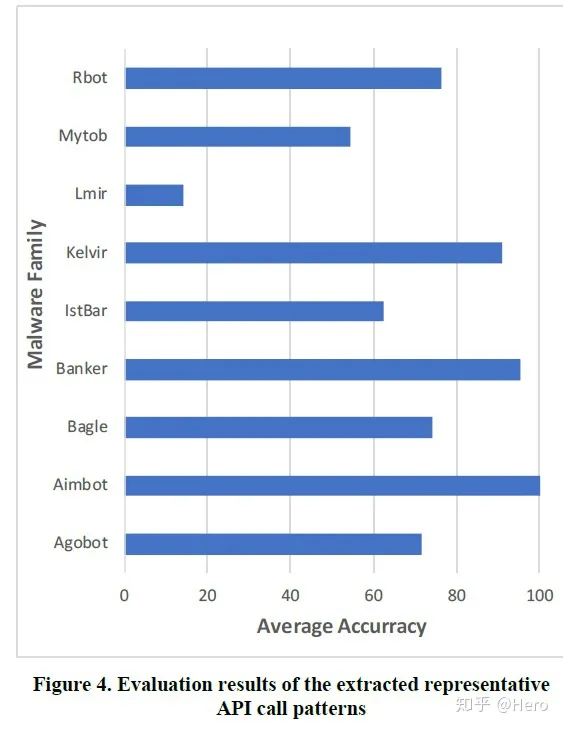
Paper: 利用RNN来提取恶意软件家族的API调用模式
论文 摘要 恶意软件家族分类是预测恶意软件特征的好方法,因为属于同一家族的恶意软件往往有相似的行为特征恶意软件检测或分类方法分静态分析和动态分析两种: 静态分析基于恶意软件中包含的特定签名进行分析,优点是分析的范围覆盖了整个代码…...

sdkman 安装以及 graalvm安装
sdkman安装以及graalvm安装全过程, (可能需要梯子) tiamTiam-Lenovo:~$ curl -s "https://get.sdkman.io" | bash-syyyyyyys:/yho: -yd./yh/ m..oho. hy ..sh/ :N -/…...

如何正确使用 WEB 接口的 HTTP 状态码和业务状态码?
当设计和开发 Web 接口时,必然会和 HTTP 状态码与业务状态码这两个概念打交道。很多同学可能没有注意过这两个概念或者两者的区别,做得稀里糊涂,接下来详细讲解下二者的定义、区别和使用方法。 HTTP 状态码 HTTP 状态码是由 HTTP 协议定义的…...
DataSet】)
Spark【Spark SQL(三)DataSet】
DataSet DataFrame 的出现,让 Spark 可以更好地处理结构化数据的计算,但存在一个问题:编译时的类型安全问题,为了解决它,Spark 引入了 DataSet API(DataFrame API 的扩展)。DataSet 是分布式的数…...

制作立体图像实用软件:3DMasterKit 10.7 Crack
3DMasterKit 软件专为创建具有逼真 3D 和运动效果的光栅图片而设计:翻转、动画、变形和缩放。 打印机、广告工作室、摄影工作室和摄影师将发现 3DMasterKit 是一种有用且经济高效的解决方案,可将其业务扩展到新的维度,提高生成的 3D 图像和光…...

高校 Web 站点网络安全面临的主要的威胁
校园网 Web 站点的主要安全威胁来源于计算机病毒、内部用户恶意攻击和 破坏、内部用户非恶意的错误操作和网络黑客入侵等。 2.1 计算机病毒 计算机病毒是指编制者在计算机程序中插入的破坏计算机功能或者数据, 影响计算机使用并且能够自我复制的一组计算机指令或…...

vue前端解决跨域
1,首先 axios请求,看后端接口路径,http://122.226.146.110:25002/api/xx/ResxxList,所以baseURL地址改成 ‘/api’ let setAxios originAxios.create({baseURL: /api, //这里要改掉timeout: 20000 // request timeout}); export default s…...

【Cicadaplayer】解码线程及队列实现
4.4分支https://github.com/alibaba/CicadaPlayer/blob/release/0.4.4/framework/codec/ActiveDecoder.h对外:送入多个包,获取一个帧 int send_packet(std::unique_ptr<IAFPacket> &packet, uint64_t timeOut) override;int getFrame(std::u...
把文件上传到Gitee的详细步骤
目录 第一步:创建一个空仓库 第二步:找到你想上传的文件所在的地址,打开命令窗口,git init 第三步:git add 想上传的文件 ,git commit -m "给这次提交取个名字" 第四步:和咱们在第…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...