动手学深度学习——Windows下的环境安装流程(一步一步安装,图文并配)
目录
- 环境安装
- 官网步骤图文版
- 安装Miniconda
- 下载包含本书全部代码的压缩包
- 使用conda创建虚拟(运行)环境
- 使用conda创建虚拟环境并安装本书需要的软件
- 激活之前创建的环境
- 打开Jupyter记事本
环境安装
文章参考来源:http://t.csdn.cn/tu8V8
官网步骤图文版
安装Miniconda
根据操作系统下载并安装Miniconda,在安装过程中需要勾选“Add Anaconda to the system PATH environment variable”选项(如当conda版本为4.6.14时)。
- Windows用户就选择Windows版本就可以了,按需选择32位或64位
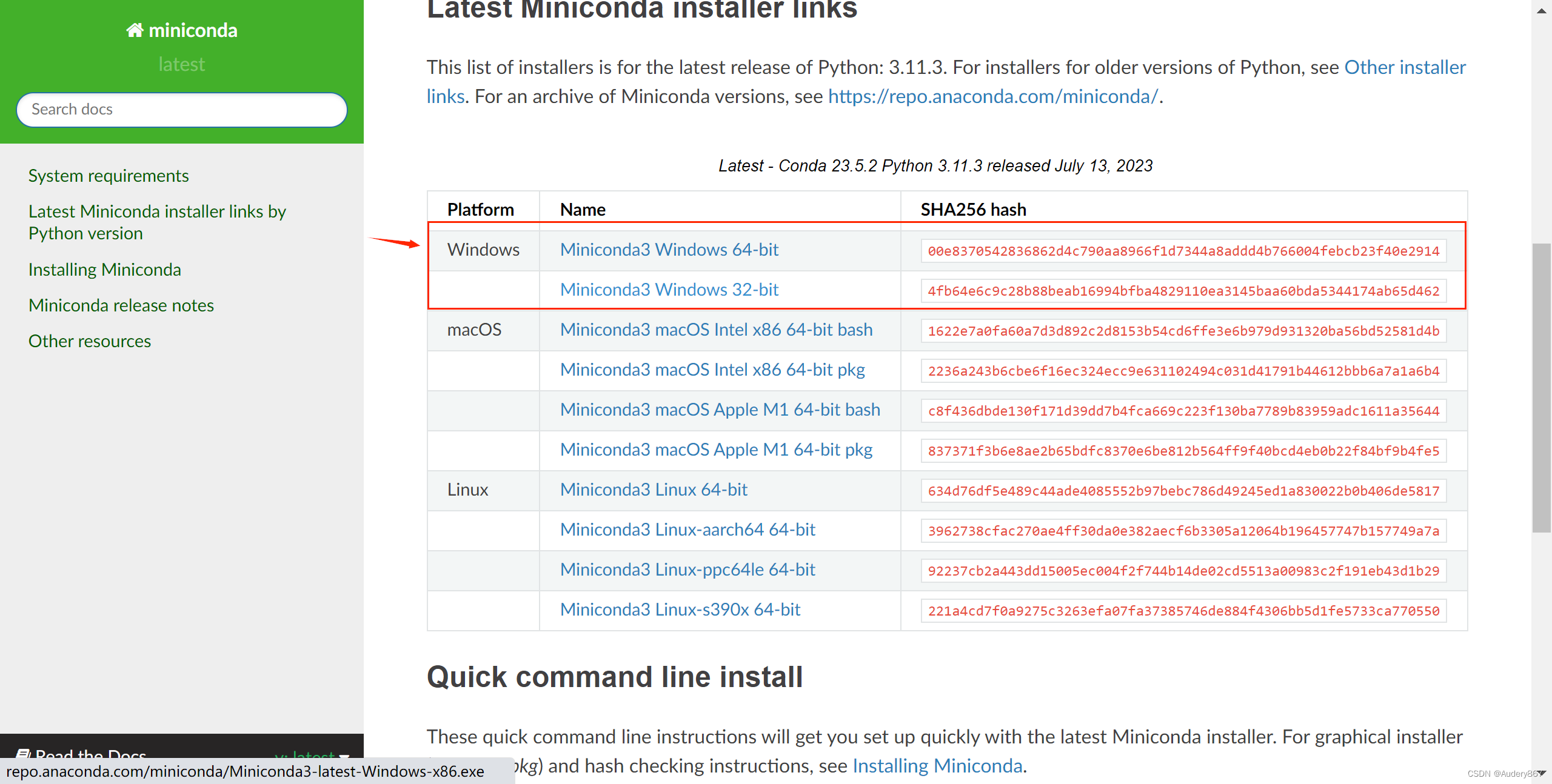
- 安装好后,按下列步骤进行。
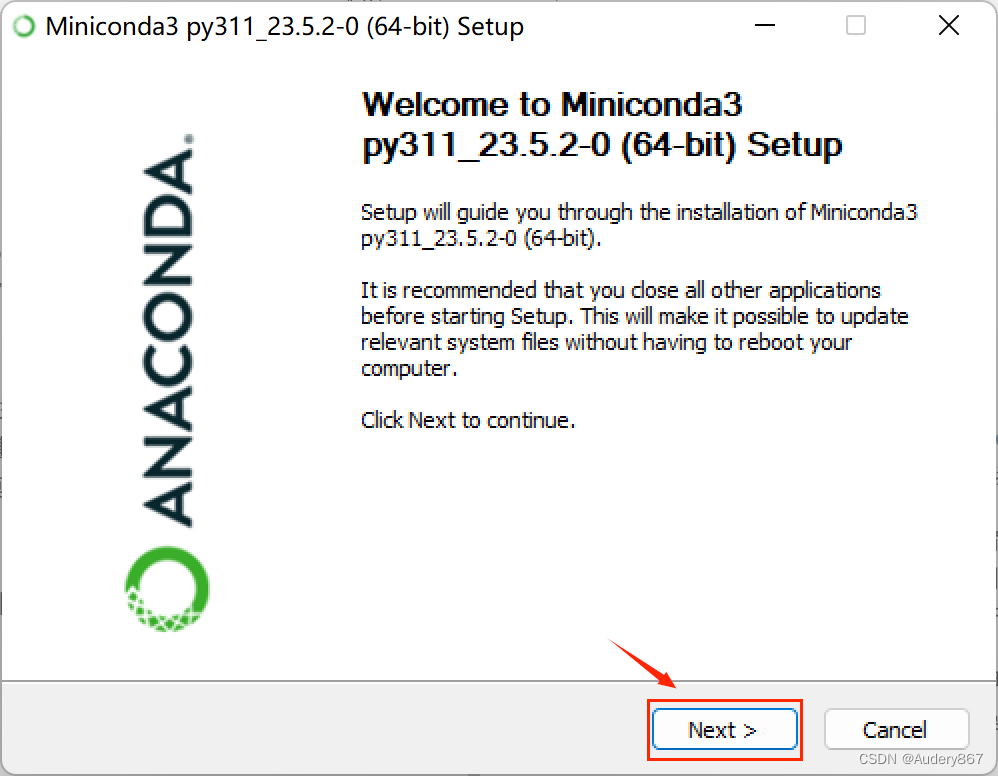
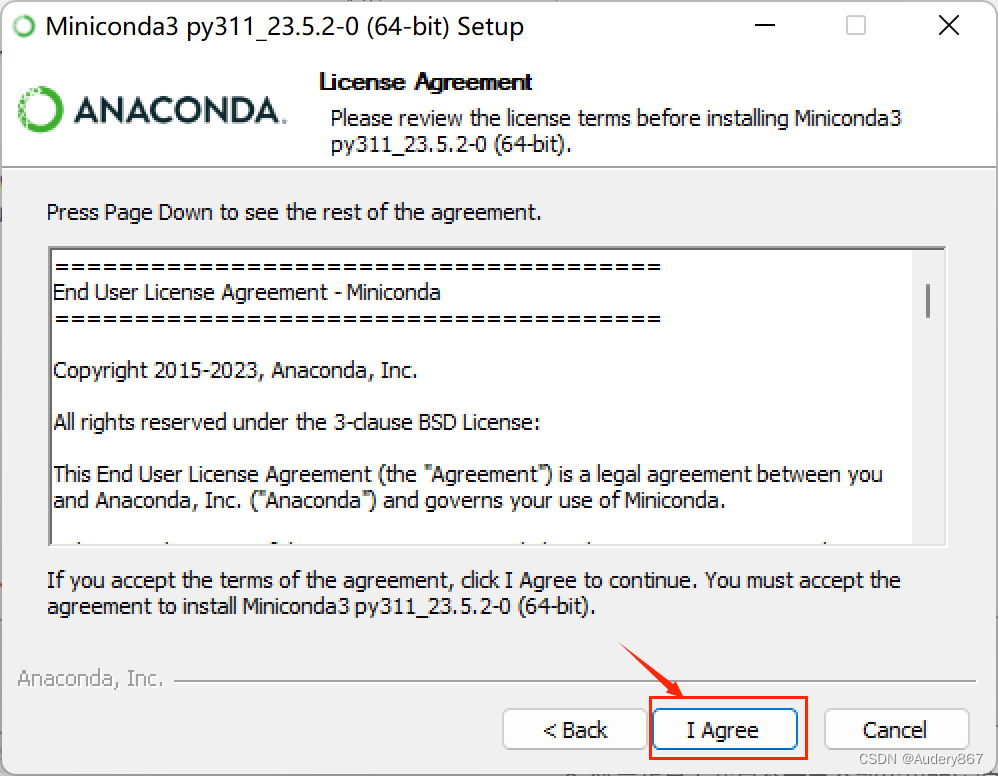

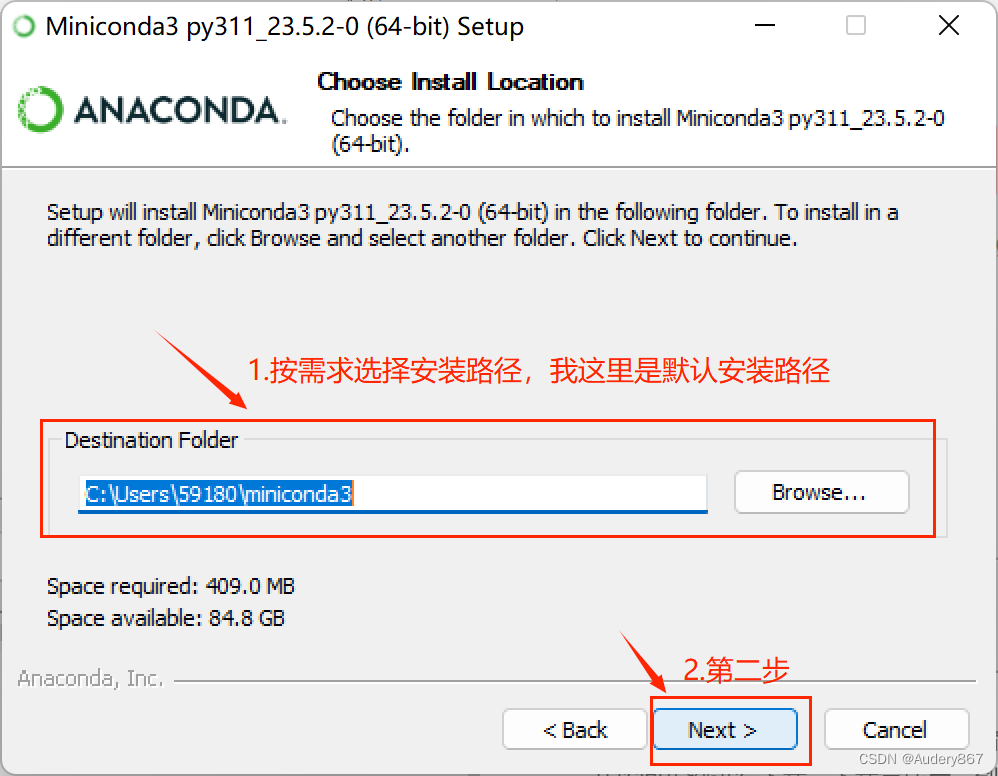
等待安装,安装完成
下载包含本书全部代码的压缩包
第二步是下载包含本书全部代码的压缩包。我们可以在浏览器的地址栏中输入 https://zh.d2l.ai/d2l-zh-1.0.zip 并按回车键进行下载。下载完成后,创建文件夹“d2l-zh”并将以上压缩包解压到这个文件夹。在该目录文件资源管理器的地址栏输入cmd进入命令行模式。
- 解压文件的步骤可根据自己的解压工具来解压,我这里用的是 WinRAR

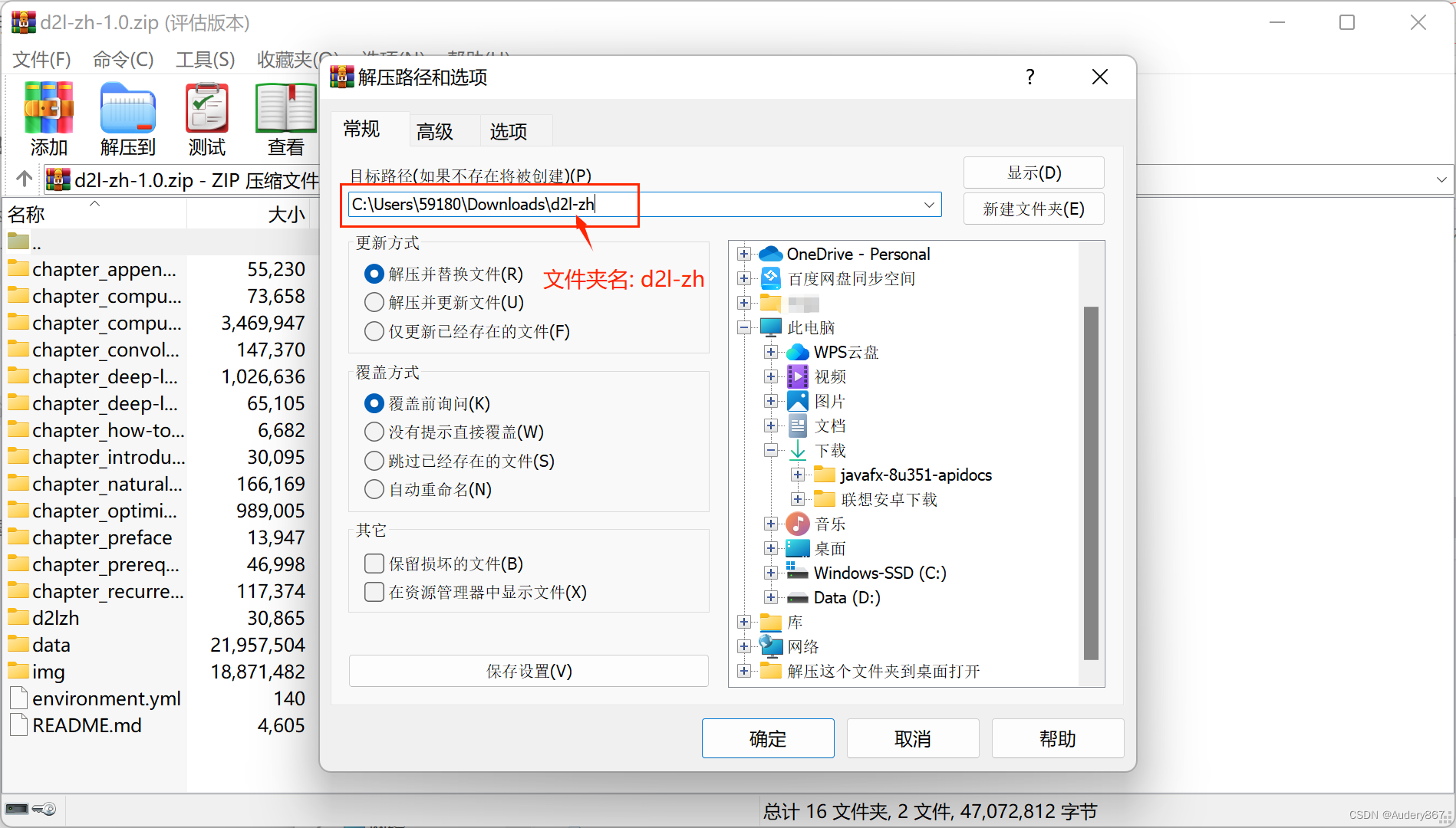

- 打开文件夹,在该目录文件资源管理器的地址栏输入cmd进入命令行模式。
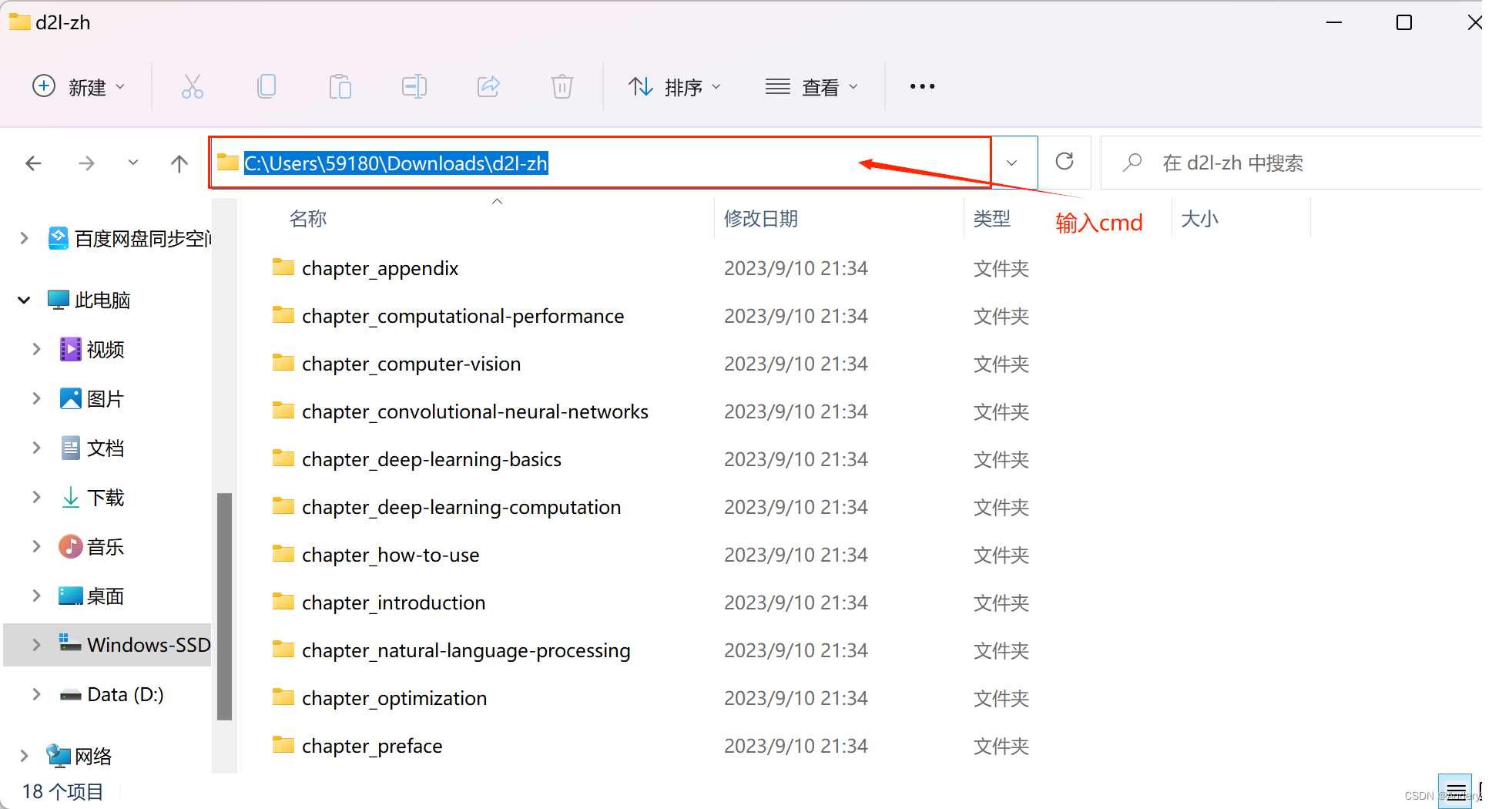
使用conda创建虚拟(运行)环境
第三步是使用conda创建虚拟(运行)环境。conda和pip默认使用国外站点来下载软件,我们可以配置国内清华镜像来加速下载(国外用户无须此操作)。
# 配置清华PyPI镜像(如无法运行,将pip版本升级到>=10.0.0)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
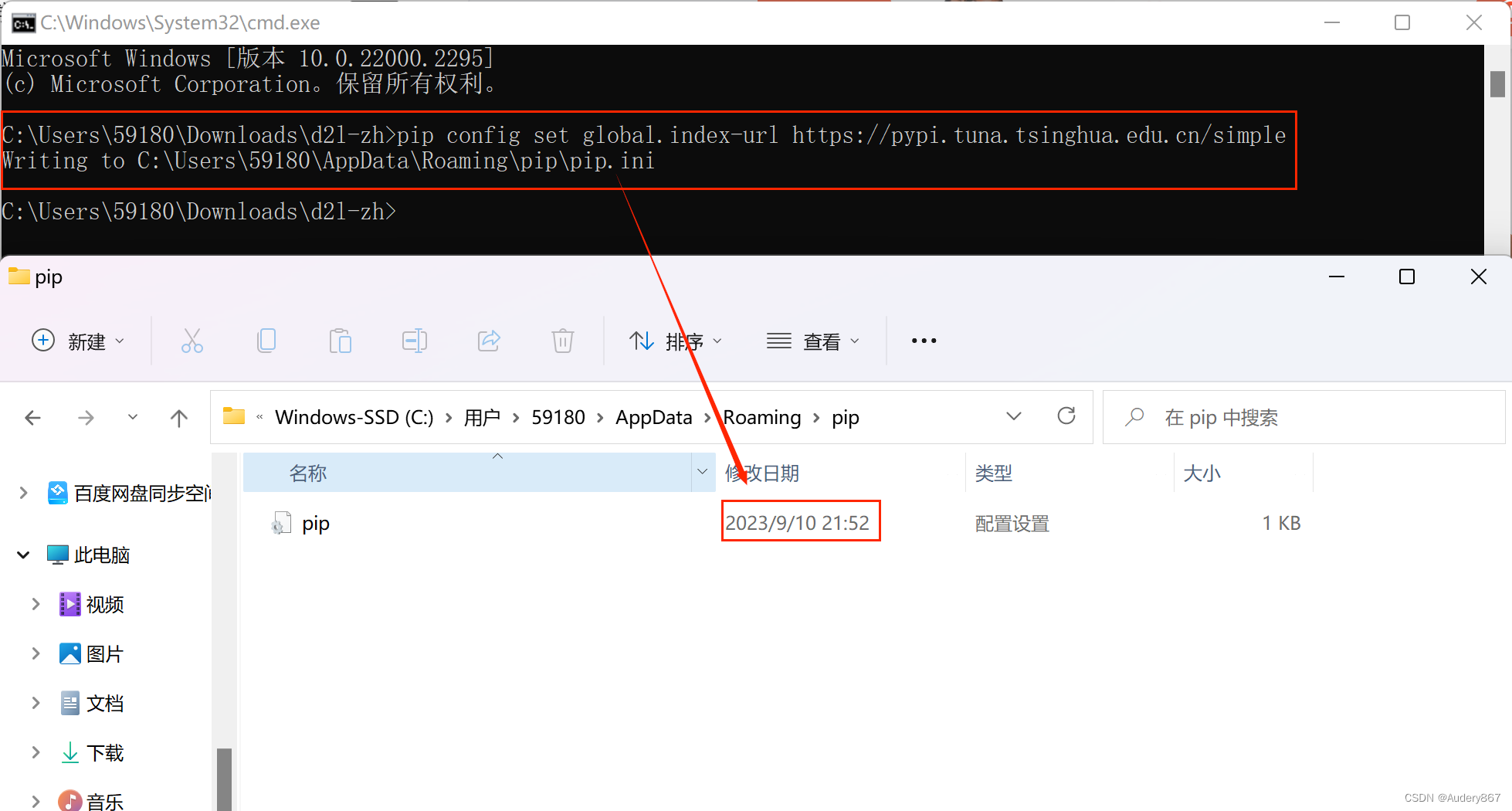
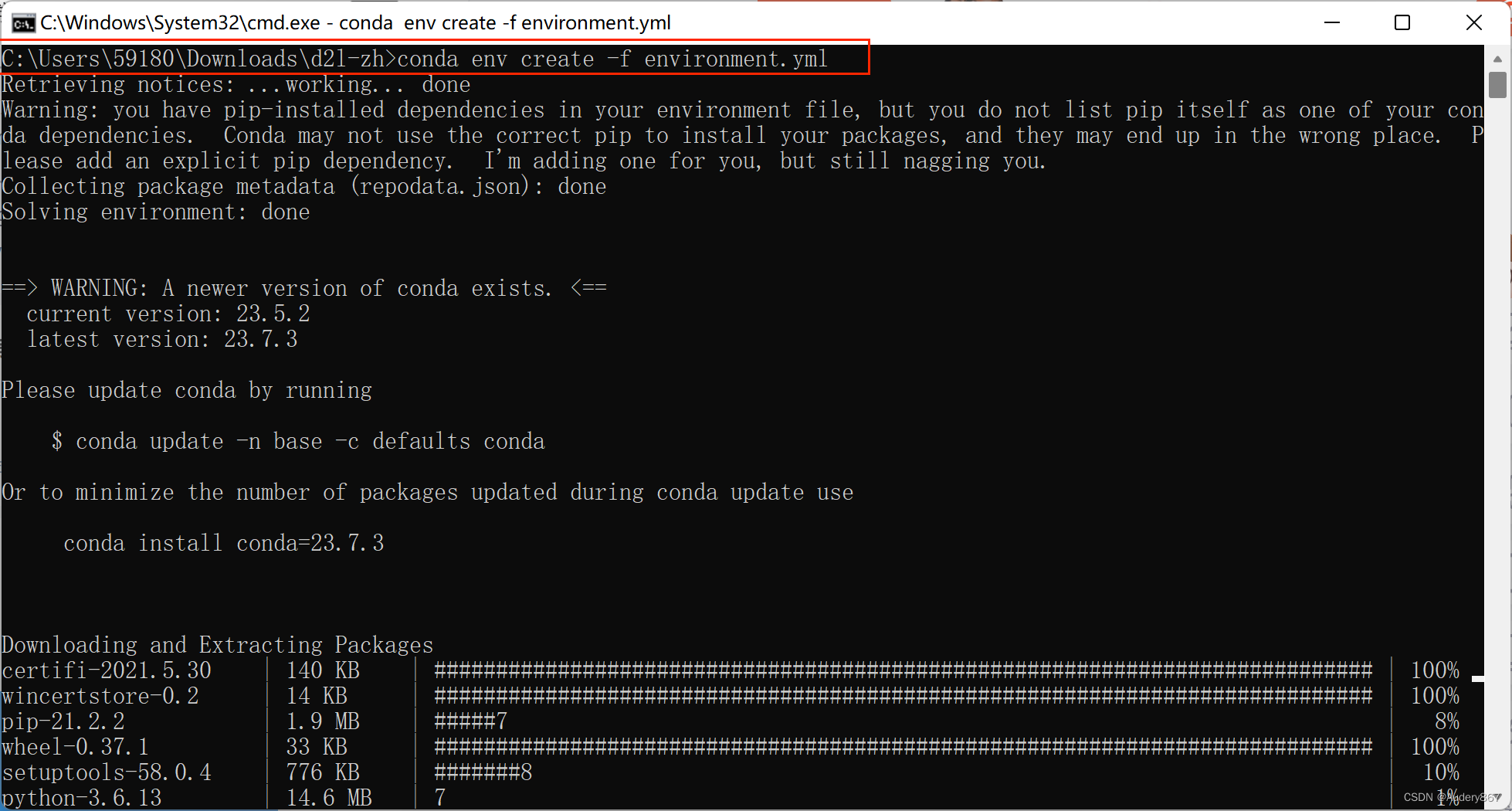
使用conda创建虚拟环境并安装本书需要的软件
这里environment.yml是放置在代码压缩包中的文件。使用文本编辑器打开该文件,即可查看运行压缩包中本书的代码所依赖的软件(如MXNet和d2lzh包)及版本号。
conda env create -f environment.yml
- 如果你的电脑上安装好了cuda(进入cmd,输入nvcc -V能查看版本并且没有报错),那么建议安装GPU版本的MXNet。具体操作:使用文本编辑器打开本书的代码所在根目录下的文件environment.yml,将里面的字符串“mxnet”替换成对应的GPU版本。例如,如果计算机上装的是8.0版本的CUDA,将该文件中的字符串“mxnet”改为“mxnet-cu80”。如果计算机上安装了其他版本的CUDA(如7.5、9.0、9.2等),对该文件中的字符串“mxnet”做类似修改(如改为“mxnet-cu75”“mxnet-cu90”“mxnet-cu92”等)。保存文件后退出。然后再执行
conda env create -f environment.yml
- 如果不小心已经安装好了虚拟环境,那么需要先卸载CPU版本的MXNet:
pip uninstall mxnet
然后再重新更新我们的虚拟环境配置:
conda env update -f environment.yml
- 如果使用国内镜像后出现安装错误,首先取消PyPI镜像配置,即执行命令:
pip config unset global.index-url
然后重试命令:
conda env create -f environment.yml
激活之前创建的环境
第四步是激活之前创建的环境。激活该环境是能够运行本书的代码的前提。激活之后,会在提示符前出现(gluon)字样,表示已经进入了虚拟环境。
conda activate d2l # 若conda版本低于4.4,使用命令activate gluon
如需退出虚拟环境,可使用命令conda deactivate(注意这里没有参数)若conda版本低于4.4,使用命令deactivate。
你还需要安装 d2l 软件包,它封装了本书中常用的函数和类。
# -U:将所有包升级到最新的可用版本
pip install -U d2l
打开Jupyter记事本
安装完成后,我们通过运行以下命令打开 Jupyter 笔记本:
jupyter notebook

《动手学深度学习》一书中若干章节的代码会自动下载数据集和预训练模型,并默认使用美国站点下载。我们可以在运行Jupyter前指定MXNet使用国内站点下载书中的数据和模型(国外用户无需此操作)。
set MXNET_GLUON_REPO=https://apache-mxnet.s3.cn-north-1.amazonaws.com.cn/ jupyter notebook
相关文章:
动手学深度学习——Windows下的环境安装流程(一步一步安装,图文并配)
目录 环境安装官网步骤图文版安装Miniconda下载包含本书全部代码的压缩包使用conda创建虚拟(运行)环境使用conda创建虚拟环境并安装本书需要的软件激活之前创建的环境打开Jupyter记事本 环境安装 文章参考来源:http://t.csdn.cn/tu8V8 官网…...

打印日志遇到的问题,logback与zookeeper冲突
在做项目时需要打印日志引入了logback打印日志,但是一直无法打印,于是一路查找原因。发现zookeeper中默认带的有个logback和我自己引入的logback版本冲突了,这样直接使用exclusions标签将zookeeper中自带的日志框架全部排除即可 按理说到这一…...

【Node.js操作SQLite指南】
Node.js操作SQLite指南 在本篇博客中,我们将学习如何在Node.js中操作SQLite数据库。我们将使用sqlite3模块来创建数据库、创建表以及进行数据的增删改查操作。 文章目录 Node.js操作SQLite指南安装sqlite3模块创建数据库创建表数据的增删改查插入数据查询数据更新…...
PyTorch之张量的相关操作大全 ->(个人学习记录笔记)
文章目录 Torch1. 张量的创建1.1 直接创建1.1.1 torch.tensor1.1.2 torch.from_numpy(ndarray) 1.2 依据数值创建1.2.1 torch.zeros1.2.2 torch.zeros_like1.2.3 torch.ones1.2.4 torch.ones_like1.2.5 torch.full1.2.6 torch.full_like1.2.7 torch.arange1.2.8 torch.linspace…...

ChatGPT生成内容很难脱离标准化,不建议用来写留学文书
ChatGPT无疑是23年留学届的热门话题,也成为了不少留学生再也离不开的万能工具,从总结文献、润色论文、给教授写email似乎无所不能。 各大高校对于学生使用ChatGPT的态度也有所不同。例如,哈佛大学教育代理院长 Anne Harrington 在内部邮件中…...

sqlserver @@ROWCOUNT的使用
T-SQL是一种用于与关系型数据库(如Microsoft SQL Server)交互的SQL(Structured Query Language)方言。 在T-SQL中,ROWCOUNT是一个系统变量,它返回最后执行的语句影响的行数。你提供的代码检查ROWCOUNT的值…...

Hbase批量删除数据
一、TTL机制 HBase的TTL(Time To Live)是一种用于指定数据存活时间的机制。它允许用户为HBase中的数据设置一个固定的生存时间,在达到指定的时间后,HBase会自动删除这些数据。 具体操作如下: 三步走,先禁用…...

飞行动力学 - 第20节-part2-机翼上反及后掠对横向静稳定性的影响 之 基础点摘要
飞行动力学 - 第20节-part2-机翼上反及后掠对横向静稳定性的影响 之 基础点摘要 1. 上反角贡献2. 后掠角贡献3. 参考资料 1. 上反角贡献 对于无后掠、大展弦比带上反的矩形机翼,飞行状态为 α \alpha α, β \beta β及V。 上反角增加稳定性,…...

力扣 -- 1218. 最长定差子序列
参考代码: class Solution { public:int longestSubsequence(vector<int>& arr, int difference) {int narr.size();unordered_map<int,int> hash;//nums[i]绑定dp[i]hash[arr[0]]1;int ret1;for(int i1;i<n;i){int aarr[i];int ba-difference;…...

【程序员装机】在右键菜单中添加Notepad++选项
文章目录 前言在右键菜单中添加Notepad选项的批处理脚本上述批处理脚本的功能包括 总结 前言 本文将介绍如何通过批处理脚本来在Windows右键菜单中添加Notepad选项,使您能够轻松使用Notepad打开各种文件。 在右键菜单中添加Notepad选项的批处理脚本 以下是一个用于…...
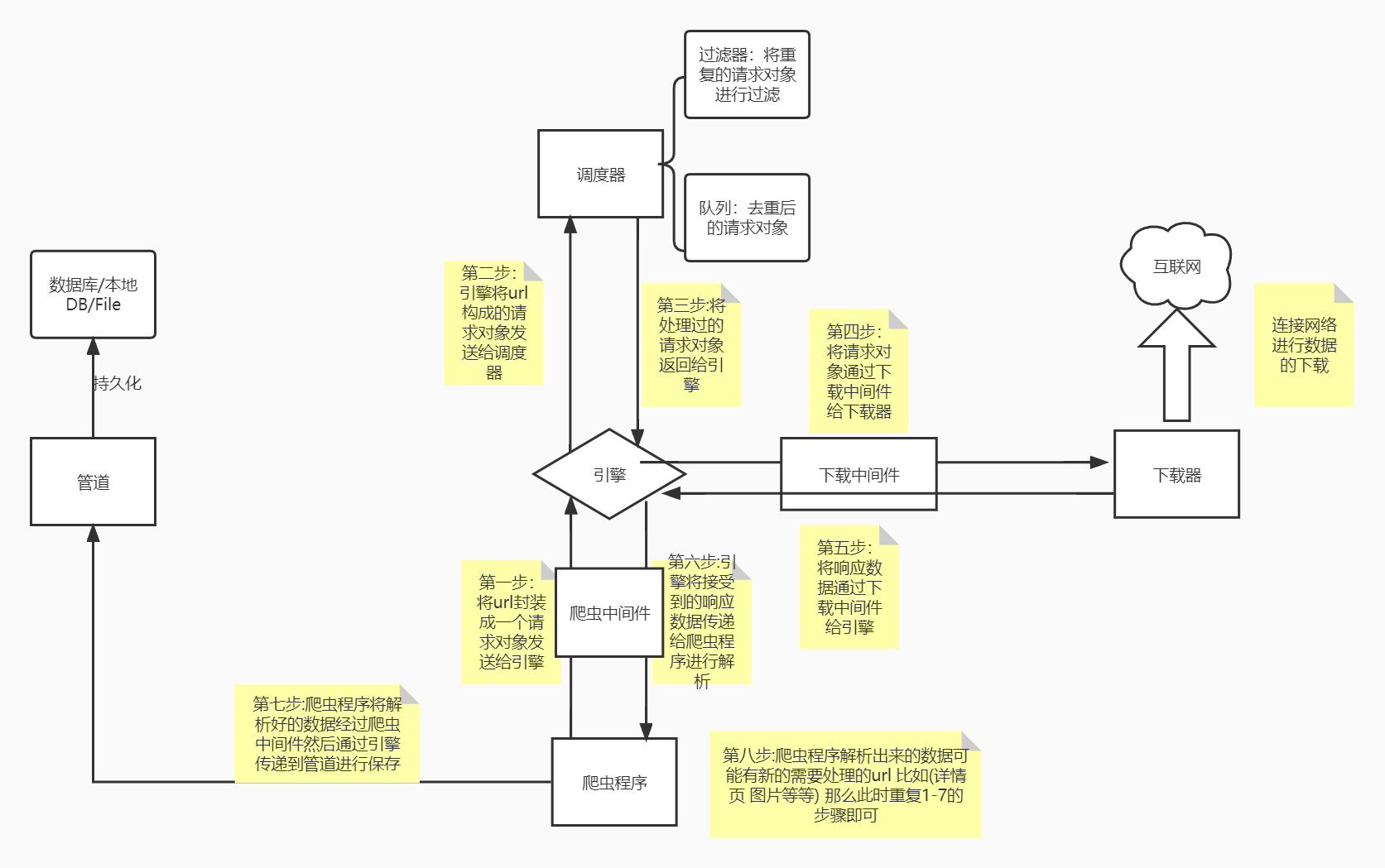
Scrapy的基本介绍、安装及工作流程
一.Scrapy介绍 Scrapy是什么? Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架) 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 Scrapy使用了Twisted异步网络框架&…...

CMS 三色标记【JVM调优】
文章目录 1. 垃圾回收器2. CMS 原理3. 三色标记算法 1. 垃圾回收器 ① Serial:最原始的垃圾回收器,用于新生代,是单线程的,GC 时需要停止其它所有的工作,算法简单,但它只能在内存较小时勉强使用;…...
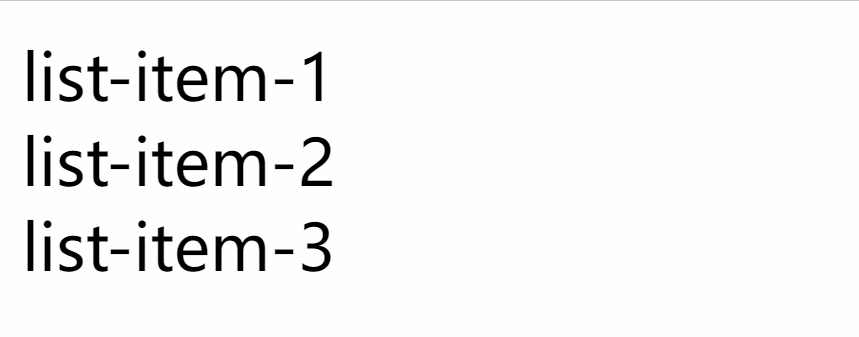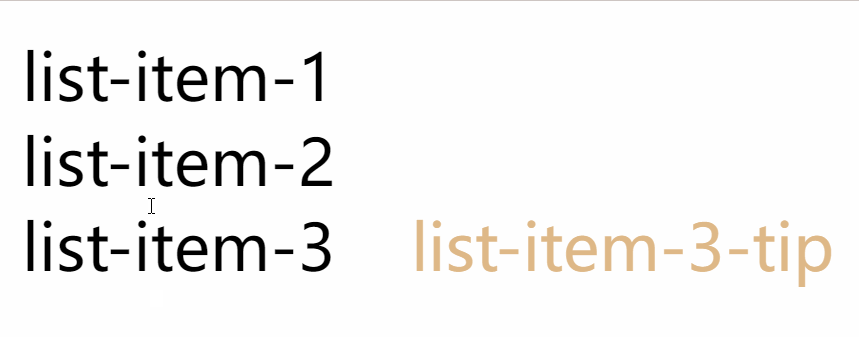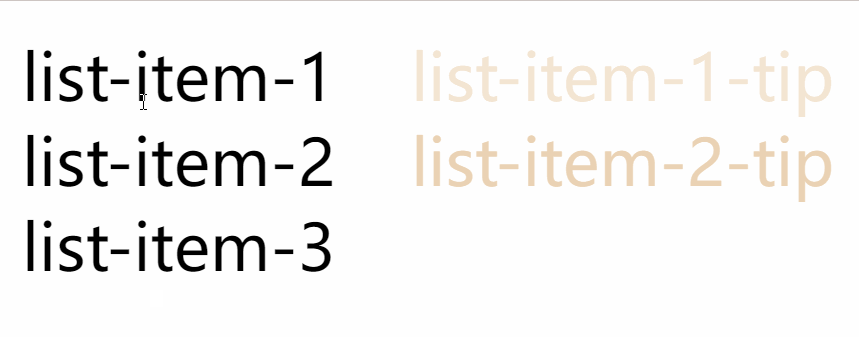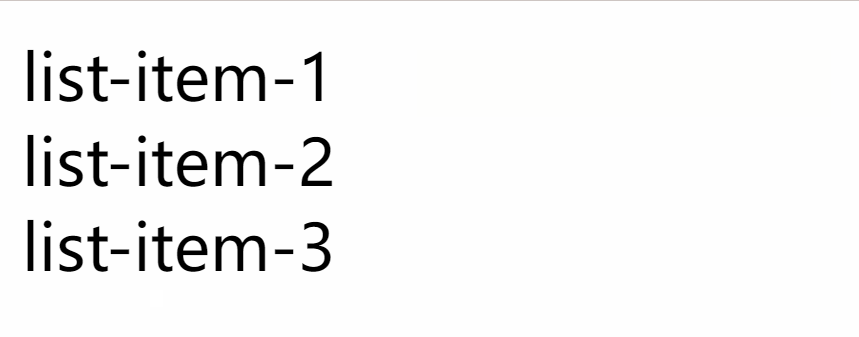
使用 CSS 伪类的attr() 展示 tooltip
效果图: 使用场景: 使用React渲染后台返回的数据, 遍历以列表的形式展示, 可能简要字段内容需要鼠标放上去才显示的 可以借助DOM的自定义属性和CSS伪类的attr来实现 所有代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-…...

在命令窗口便捷快速复制输出结果到剪贴板
在macOS上,将命令的输出结果复制到剪贴板 在日常的工作中, 经常使用命令的小伙伴可能会遇到一个场景, 就是把命令执行的结果复制出来另作它用. 每次都需要通过鼠标进行选择然后复制, 虽然 macOS 的命令行的复制快捷键和普通的复制是一样的, 非常友好, 但是还要选择…...
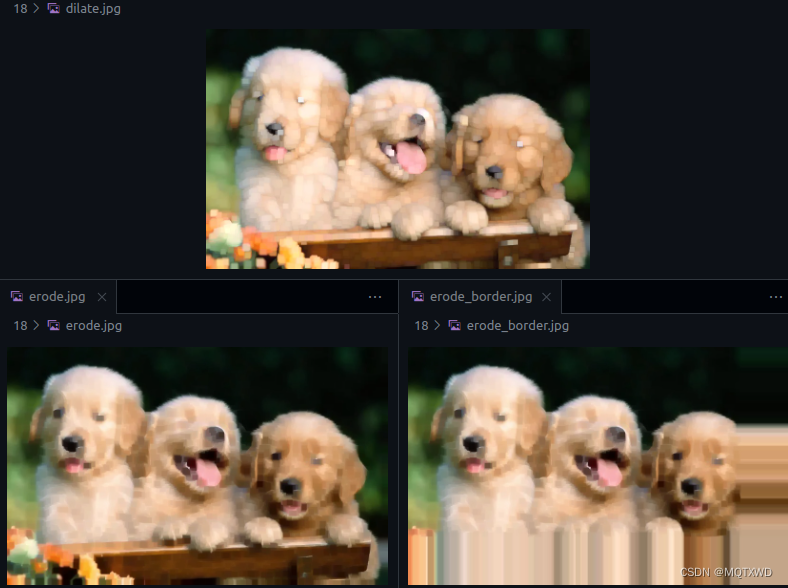
CUDA小白 - NPP(8) 图像处理 Morphological Operations
cuda小白 原始API链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus…...

java获取音频,文本准转语音时长
jar 以上传到资源中 <dependency><groupId>it.sauronsoftware</groupId><artifactId>jave</artifactId><version>1.0.2</version></dependency> mvn install:install-file -DfileD:\xxx\xxx\jave-1.0.2.jar -DgroupIdit.sauro…...
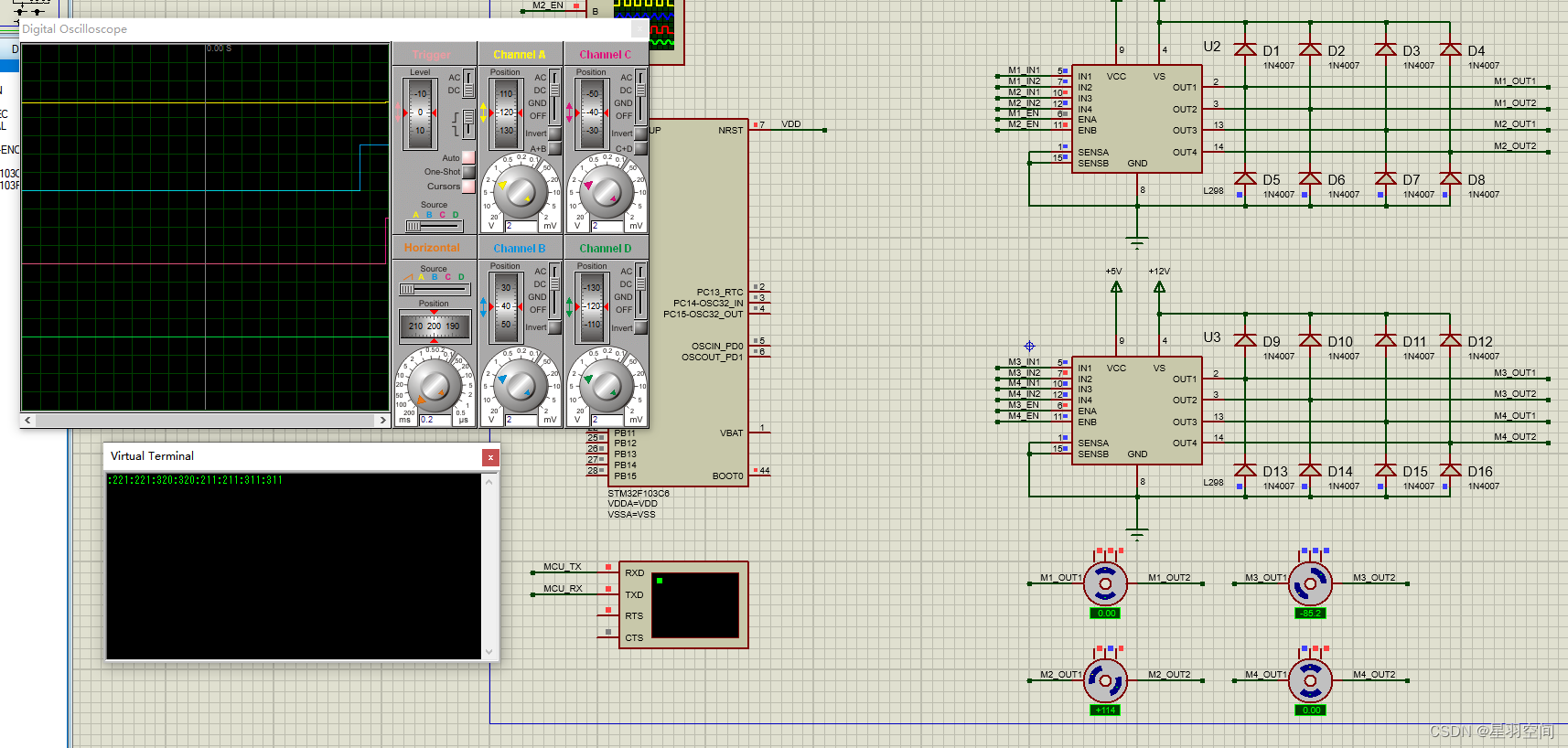
基于串口通讯的多电机控制技术研究
基于STM32CubeMX生成keil工程 基于proteus 8.7版本进行程序验证 采用了简单的串口通讯协议 基本效果如图 先对电机旋转方向进行指令设置 :221 :320 分别实现对第二个电机正转、第三个电机反转设置 为了方便观测,程序对接受到的串口数据会进行回显。 然后使能电…...
【深入解读Redis系列】(五)Redis中String的认知误区,详解String数据类型
有时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,请认准https://blog.zysicyj.top 首发博客地址 系列文章地址 需求描述 现在假设有这样一个需求,我们要开发一个图像存储系统。要求如下: 该系统能快…...

段指导-示例
RDBMS 19.20 参考文档: Database Administrator’s Guide 19 Managing Space for Schema Objects 19.3.2.4 Running the Segment Advisor Manually 针对表SOE.CUSTOMERS进行段指导 -- 创建段指导 variable id number; begindeclarename varchar2(100);descr …...

LeetCode 面试题 04.02. 最小高度树
文章目录 一、题目二、C# 题解 一、题目 给定一个有序整数数组,元素各不相同且按升序排列,编写一个算法,创建一棵高度最小的二叉搜索树。 点击此处跳转题目。 示例: 给定有序数组: [-10,-3,0,5,9], 一个可能的答案是:[0,-3,9,-10…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...